
A Trellis Based Temporal Rate Allocation and Virtual Reference Frames for High Efficiency Video Coding

Abstract
:1. Introduction
1.1. Context and Motivations
1.2. Contributions and Paper Organization
- (i)
- a novel virtual reference frame creation where a multiple hypothesis motion estimation method is used for frame generation;
- (ii)
- an efficient rate allocation algorithm in which the trellis coding method is used to learn the temporal rate allocation.
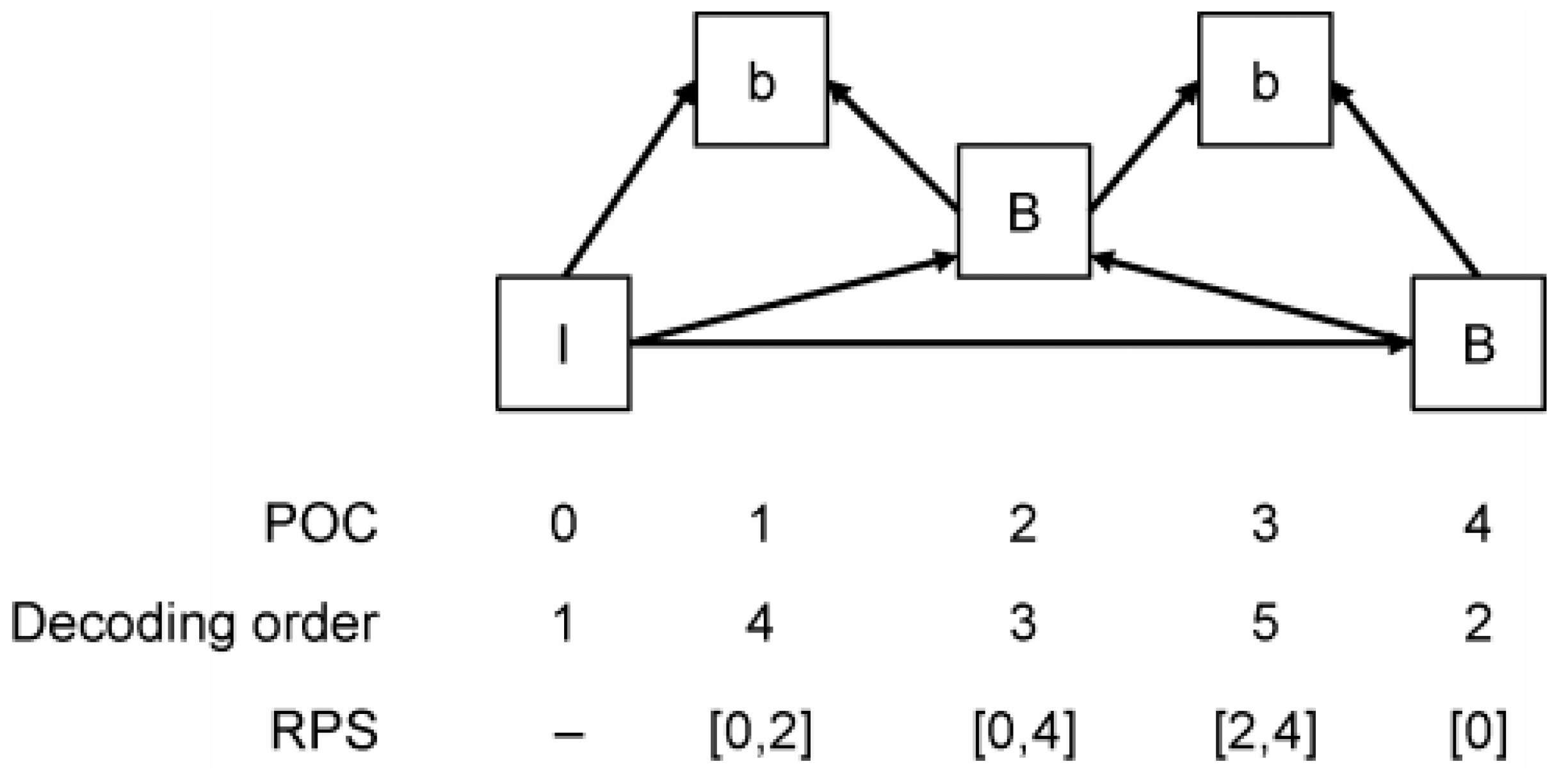
2. Background and Related Works
2.1. HEVC Inter Coding
2.2. HEVC Rate Control
3. Proposed HEVC Improvement Tools
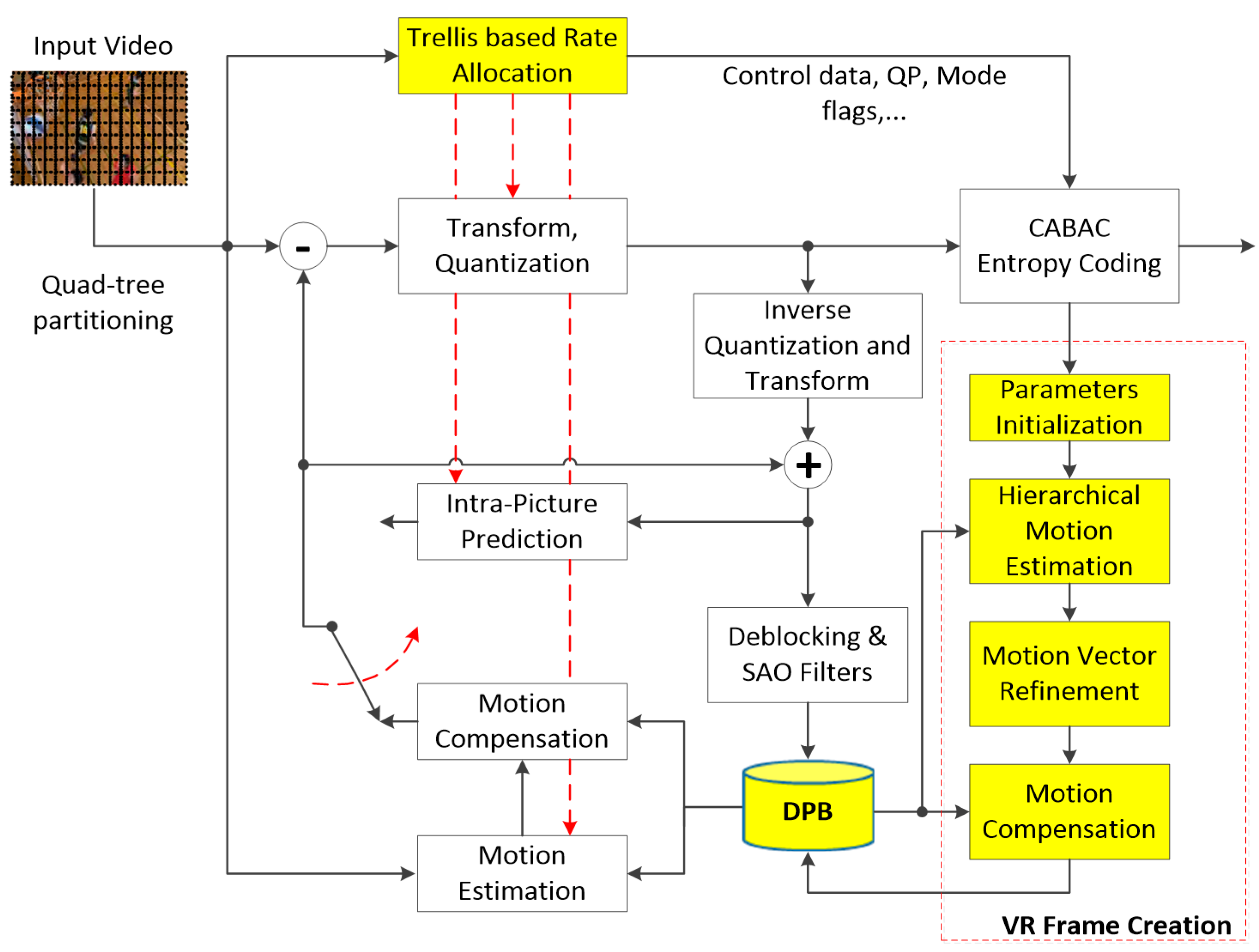
3.1. Proposed HEVC Architecture
3.1.1. Virtual Reference Frame Creation
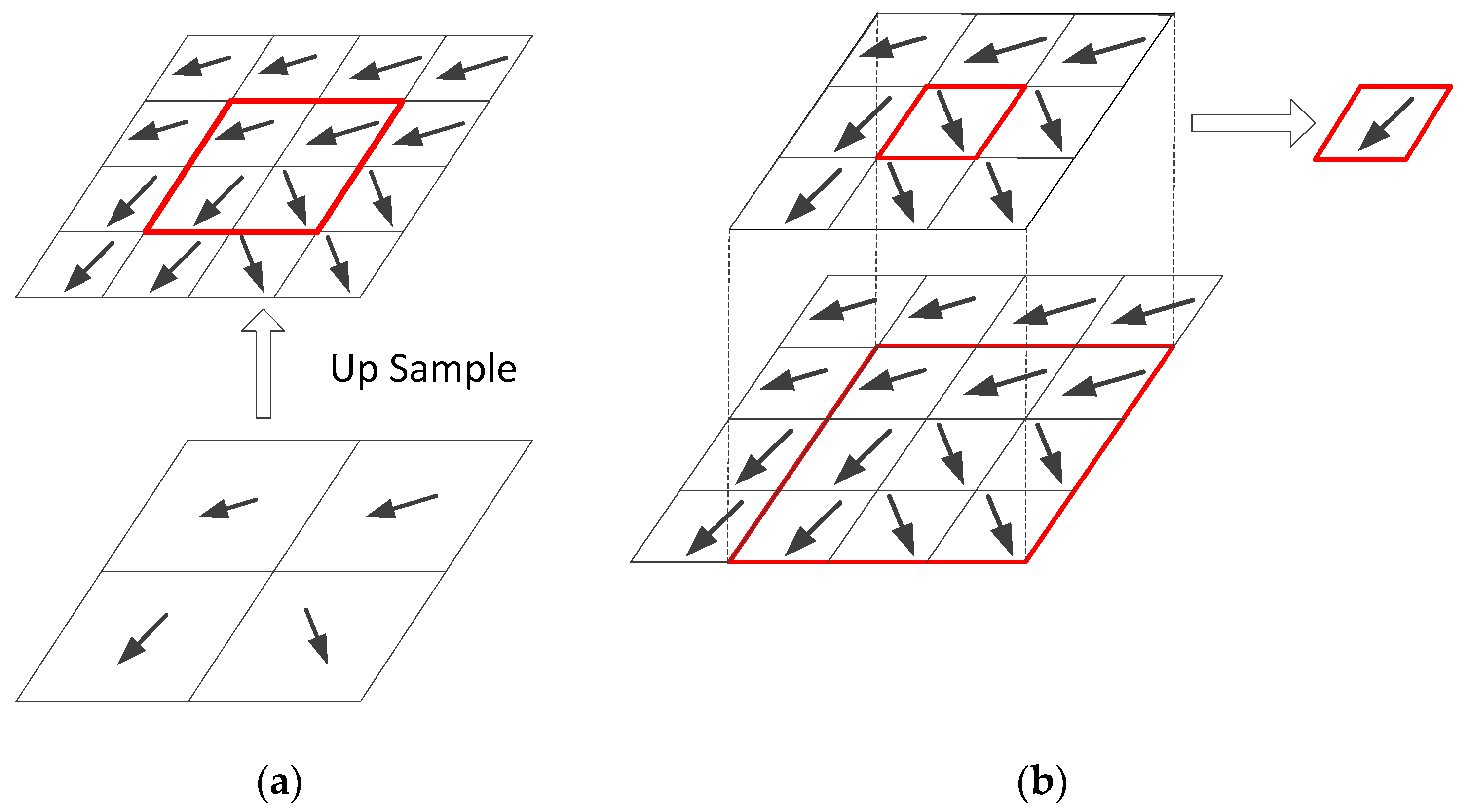
- Hierarchical ME: First, decoded frames obtained from two reference lists, list 0 and list 1, are low pass filtered and used as references in a motion estimation process. Our proposed VR frame creation uses both forward and backward ME to generate the forward interpolated frame and the backward interpolated frame. In these modules, a block matching algorithm is used to estimate the motion between the next and previous decoded frames.
- MV refinement: To achieve better motion field, a motion vector refinement (MVR) process is employed. In MVR, the temporal bidirectional ME (BiME) and the spatial weighted vector median filtering (WVMF) are chosen to refine the motion information derived from the hierarchical ME stage [22,23]. In BiME, the motion vectors of each interpolated block are refined in a small search area and following an assumption that the motion trajectory between consecutive frames is linear. While the spatial WVMF improves the motion field spatially coherent by looking, for each interpolated block, a candidate motion vector at neighboring blocks can better represent the motion trajectory. This filter is also adjustable by a set of weights, controlling the filter strength and depending on the block distortion for each candidate motion vector. Since the quality of decoded references and video content highly affect the final VR frame quality, we adopted a statistical learning-based parameter optimization solution to initialize the block size, search range, and search refinement areas for the proposed MCTI method [24].
- Motion compensation: Finally, the motion compensation process is applied to the decoded frames and obtained MV to achieve the VR frames.
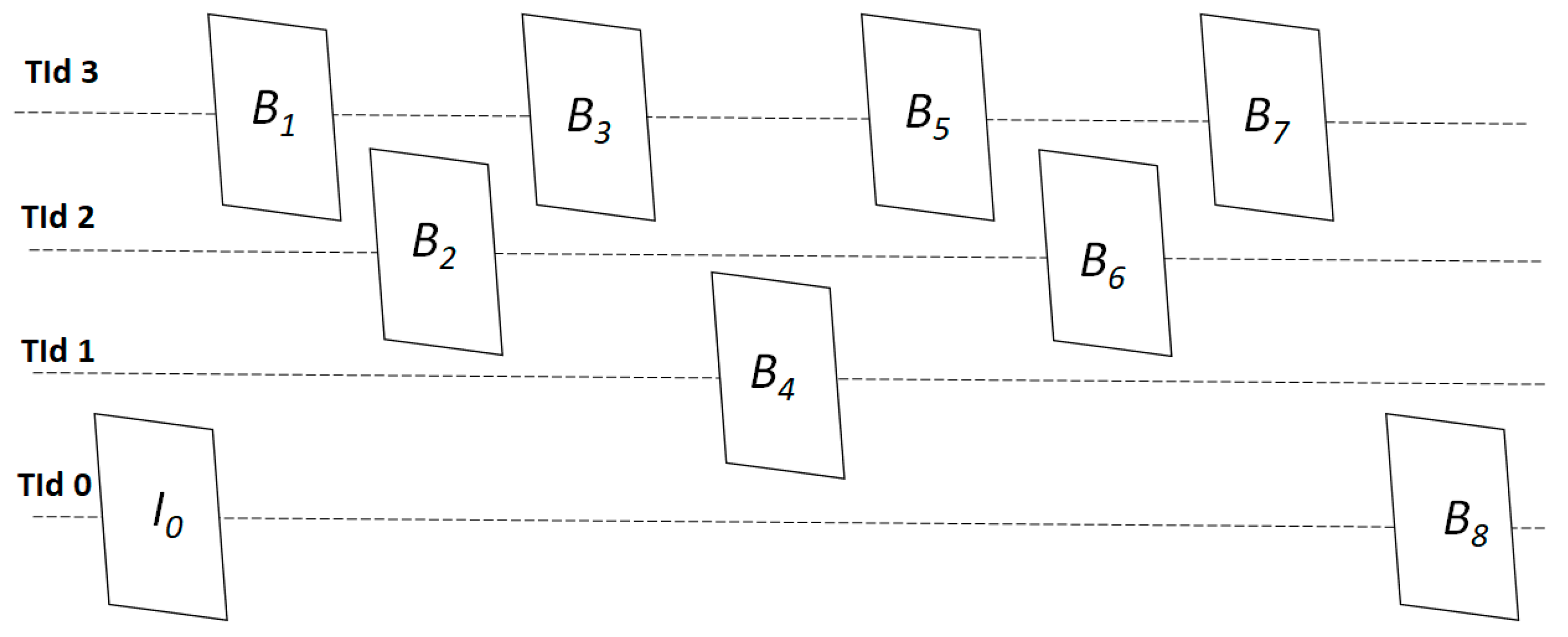
3.1.2. Virtual Reference Frame Exploitation
3.2. Trellis-Based Rate Allocation (TRA)
| Algorithm 1 Proposed trellis-based bitrate allocation algorithm. | |
| # | Detail Descriptions |
| 1 | Initialize offset , max range , No. iteration , excluding test |
| 2 | For in # Phase loop |
| 3 | For in {0, 1, …} # Iter loop |
| 4 | For in {0, 1, 2, 3} # Tid loop |
| 5 | Find exclude candidate |
| 6 | Current candidate |
| 7 | Find the best at w.r.t BDBR |
| 8 | Add exclude candidates: |
| 9 | Output |
4. Performance Evaluation
4.1. Training and Testing Conditions
4.2. Compression Performance Assessment
- Overall, the compression performance of the HEVC with proposed TRA and VRF methods outperforms both HEVC with and without QPA benchmarks;
- The HEVC with TRA and VRF methods achieved a significant coding improvement for all test sequences, notably by 5.2% and 2.7% of BDBR on average for the low and high rates regions, respectively;
- The TRA method provides around 1.55% and 0.82% of BDBR saving for test sequences at the low and high rate regions, respectively, while the VRF method provides around 3.32% and 1.86% of BDBR saving;
- The proposed methods, both TRA and VRF, achieve better compression performance for the low rate region than for the high rate region;
- In most cases, the combination of TRA and VRF methods achieves even better compression performance than a simple addition method where the compression gain of TRA is added with that of VRF. This composed effect motivates the use of both TRA and VRF in improving HEVC performance;
- Experimental results also show that no compression gain is achieved for screen content videos such as SlideEditing. This may come from the fact that the training set does not include any video with this content, and the VRF creation may also not work well for screen-captured videos;
- Compared to other frame-based QPA algorithms, the proposed method achieved better BDBR (see Table 5). It should be noted that the QPA proposed in [35] was mainly designed for surveillance video content and its high-order polynomial model is highly sensitive to the selected parameters. Similarly, the QP- λ linear model proposed in [34] is also unable to achieve good BDBR performance even with the original model parameters used in [34] or our new parameters;
- A similar compression achievement is also observed for the BDPSNR comparison.
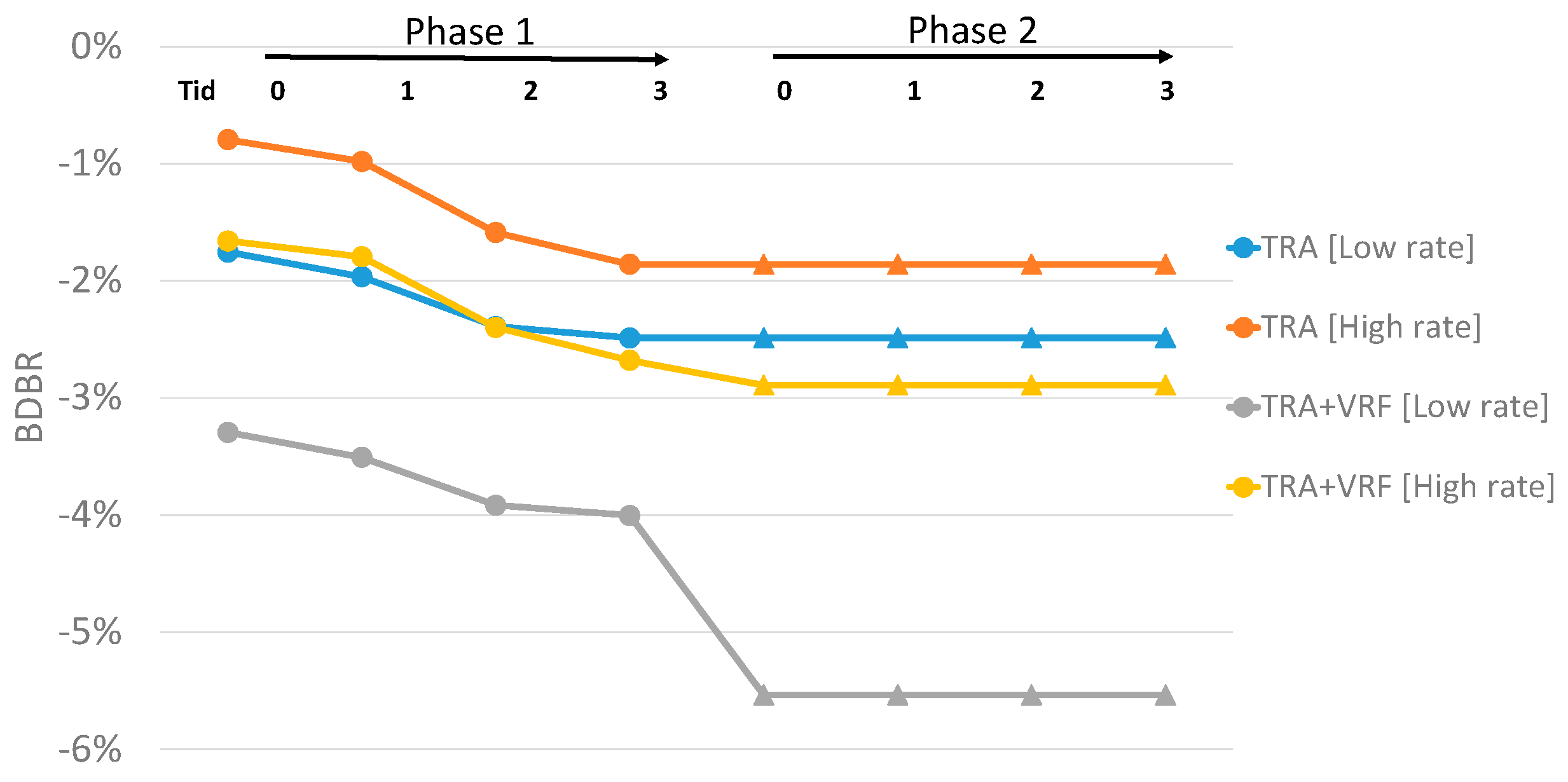
4.3. Rate Allocation Asessment
4.4. Complexity Assessment
4.5. VRF Assessment
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sullivan, G.J.; Ohm, J.-R.; Han, W.-J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bross, B.; Chen, J.; Ohm, J.-R.; Sullivan, G.J.; Wang, Y.-K. Developments in International Video Coding Standardization after AVC, With an Overview of Versatile Video Coding (VVC). Proc. IEEE 2020. [Google Scholar] [CrossRef]
- Papadopoulos, M.A.; Zhang, F.; Agrafiotis, D.; Bull, D. An adaptive QP offset determination method for HEVC. In Proceedings of the IEEE Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 4220–4224. [Google Scholar]
- Chen, Y.; Murherjee, D.; Han, J.; Grange, A.; Xu, Y.; Liu, Z.; Parker, S.; Chen, C.; Su, H.; Joshi, U.; et al. An Overview of Core Coding Tools in the AV1 Video Codec. In Proceedings of the Picture Coding Symposium (PCS), San Francisco, CA, USA, 24–27 June 2018; pp. 41–45. [Google Scholar]
- Xu, M.; Canh, T.N.; Jeon, B. Simplified Rate-Distortion Optimized Quantization for HEVC. In Proceedings of the IEEE 2018 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Valencia, Spain, 6–8 June 2018; pp. 1–6. [Google Scholar]
- Zhang, Y.; Tian, R.; Liu, J.; Wang, N. Fast rate distortion optimized quantization for HEVC. In Proceedings of the 2015 Visual Communications and Image Processing (VCIP), Singapore, 13–16 December 2015; pp. 1–4. [Google Scholar]
- Sun, L.; Au, O.C.; Zhao, C.; Huang, F.H. Rate distortion modeling and adaptive rate control scheme for high efficiency video coding (HEVC). In Proceedings of the 2014 IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, VIC, Australia, 1–5 June 2014; pp. 1933–1936. [Google Scholar]
- Zhao, L.; Wang, S.; Zhang, X.; Wang, S.; Ma, S.; Gao, W. Enhanced Motion-Compensated Video Coding With Deep Virtual Reference Frame Generation. IEEE Trans. Image Process. 2019, 28, 4832–4844. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhang, C.; Fan, R. Fast Motion Estimation in HEVC Inter Coding: An Overview of Recent Advances. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 49–56. [Google Scholar]
- Djelouah, A.; Campos, J.; Schaub-Meyer, S.; Schroers, C. Neural Inter-Frame Compression for Video Coding. In Proceedings of the IEEE International Conference Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6420–6428. [Google Scholar]
- Zhao, L.; Wang, S.; Zhang, X.; Wang, S.; Ma, S.; Gao, W. Enhanced Ctu-Level Inter Prediction with Deep Frame Rate Up-Conversion for High Efficiency Video Coding. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 206–210. [Google Scholar]
- Xu, M.; Canh, T.N.; Jeon, B. Simplified Level Estimation for Rate-Distortion Optimized Quantization of HEVC. IEEE Trans. Broadcast. 2019, 66, 88–99. [Google Scholar] [CrossRef]
- Xu, M.; Canh, T.N.; Jeon, B. Rate-Distortion Optimized Quantization: A Deep Learning Approach. In Proceedings of the IEEE High Performance Extreme Computing Conference, Waltham, MA, USA, 25–27 September 2018. [Google Scholar]
- Choi, H.; Yoo, J.; Nam, J.; Sim, D.-G. Pixel-wise unified rate-quantization model for multi-level rate control. IEEE J. Sel. Top. Signal Process. 2013, 7, 1112–1123. [Google Scholar] [CrossRef]
- Wang, S.; Ma, S.; Wang, S.; Zao, D.; Gao, W. Quadratic Rho-domain based rate control algorithm for HEVC. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Li, B.; Li, H.; Li, L.; Zhang, J. λ domain rate control algorithm for high efficiency video coding. IEEE Trans. Image Process. 2014, 23, 3841–3854. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Ngan, K.N.; Li, H. An efficient frame-content based intra frame rate control for high efficiency video coding. IEEE Signal Process. Lett. 2014, 22, 896–900. [Google Scholar] [CrossRef]
- Li, S.; Xu, M.; Deng, X.; Wang, Z. Weight-based R-λ rate control for perceptual HEVC coding on conversational videos. Signal Process. Image Commun. 2015, 38, 127–140. [Google Scholar] [CrossRef]
- Gao, W.; Kwong, S.; Zhou, Y.; Yuan, H. SSIM-based game theory approach for rate-distortion optimized intra frame CTU-level bit allocation. IEEE Trans. Multimed. 2016, 18, 988–999. [Google Scholar] [CrossRef]
- Yan, T.; Ra, I.-H.; Zhang, Q.; Xu, H.; Huang, L. A Novel Rate Control Algorithm Based on ρ Model for Multiview High Efficiency Video Coding. Electronics 2020, 9, 166. [Google Scholar] [CrossRef] [Green Version]
- Yuanzhi, Z.; Chao, L. A Highly Parallel Hardware Architecture of Table – Based CABAC Bitrate Estimator in an HEVC Intra Encoder. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 1544–1558. [Google Scholar]
- Ascenso, J.; Brites, C.; Pereira, F. Improving frame interpolation with spatial motion smoothing for pixel domain distributed video coding. In Proceedings of the Conference on Speech and Image Process, Multimedia Communication and Services, Smolenice, Slovak, 29 June–2 July 2005. [Google Scholar]
- Jeong, S.-G.; Lee, C.; Kim, C.-S. Motion-Compensated Frame Interpolation based Multihypothesis Motion Estimation and Texture Optimization. IEEE Trans. Image Process. 2013, 22, 4497–4505. [Google Scholar] [CrossRef] [PubMed]
- Hoangvan, X. Statistical search range adaptation solution for effective frame rate up-conversion. IET Image Process. 2018, 12, 113–120. [Google Scholar] [CrossRef]
- HoangVan, X.; Ascenso, J.; Pereira, F. Improving predictive video coding performance with decoder side information. In Proceedings of the IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012. [Google Scholar]
- Fischer, T.R. Joint trellis coded quantization/modulation. IEEE Trans. Commun. 1991, 39, 17–176. [Google Scholar] [CrossRef]
- Karczewicz, M.; Ye, Y.; Chong, I. Rate Distortion Optimized Quantization. In Proceedings of the ITU-T VCEG Meeting, Antalya, Turkey, 12–13 January 2008. [Google Scholar]
- Bjontegaard, G. Calculation of average PSNR differences between RD curves. In Proceedings of the 13th ITU-T VCEG Meeting, Austin, TX, USA, 2–4 April 2001. [Google Scholar]
- Bossen, F. Common HM Test Conditions and Software Reference Configuration. In Proceedings of the 14th meeting of the Joint Collaborative Team on Video Coding (JCT-VC), Vienna, Austria, 25 July–2 August 2013. [Google Scholar]
- HEVC Reference Software. Available online: https://hevc.hhi.fraunhofer.de/svn/svn_HEVCSoftware/ (accessed on 8 June 2021).
- Video Test Sequences. Available online: ftp://hevc@ftp.tnt.uni-hannover.de/testsequences/ (accessed on 20 November 2020).
- Available online: ftp://vqeg.its.bldrdoc.gov (accessed on 27 November 2020).
- Xiph.org Video Test Media. Available online: https://media.xiph.org/video/derf/ (accessed on 20 November 2020).
- Li, B.; Xu, J.; Zhang, D.; Li, H. QP refinement according to lagrange multiplier for high efficiency video coding. In Proceedings of the IEEE International Symposium on Circuits and Systems, Beijing, China, 19–23 May 2013. [Google Scholar]
- HoangVan, X. Adaptive Quantization Parameter Estimation for HEVC Based Surveillance Scalable Video Coding. Electronics 2020, 9, 915. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolutions | Training Sequences | Testing Sequences |
|---|---|---|
| 1080p and Class A | ParkScene, BQTerrace, SnakeNDry, ReadySteadyGo | BasketballDrive, Kimono, Cactus, PeopleOnStreet, Traffic |
| 720p and Class F | Parkjoy, InToTree, DucksTakeOff, Johnny | FourPeople, KristenAndSara, Vidyo1, Vidyo3, Vidyo4, ChinaSpeed, SlideEditing |
| 480p | RaceHorses, BasketballDrill | BQMall, PartyScene, BasketballDrillText |
| 4SIF | Crew, Harbour | Ice |
| 240p | RaceHorses, BQSquare | BasketballPass, BlowingBubbles |
| CIF | Akiyo, City | Hall, Foreman, Football |
| Resolutions | ||||||||
|---|---|---|---|---|---|---|---|---|
| Phase 1: ±1, 0 | Phase 2: ±2, ±1, 0 | Phase 1: ±1, 0 | Phase 2: ±2, ±1, 0 | |||||
| TRA | TRA + VRF | TRA | TRA + VRF | TRA | TRA + VRF | TRA | TRA + VRF | |
| 1080p | −2.49/−1.86 | −4.00/−2.68 | −2.53/−2.03 | −4.05/−2.85 | −2.49/−1.86 | −4.00/−2.68 | −3.77/−2,25 | −5.27/−3.12 |
| 720p | −1.48/−0.84 | −2.18/−0.84 | −1.72/−1.53 | −2.43/−1.50 | −0.36/−0.72 | −1.12/−0.84 | −2.53/−1.50 | −2.43/−1.50 |
| 480p | −1.44/−1.13 | −3.38/−2.02 | −1.49/−1.50 | −3.38/−2.43 | −1.44/−1.13 | −3.38/−2.02 | −2.03/−1.41 | −4.08/−1.93 |
| 4SIF | −1.25/−3.40 | −3.40/−1.00 | −1.56/−0.60 | −3.78/−1.56 | −1.07/−0.55 | −3.14/−1.48 | −2.03/−0.41 | −4.08/−1.93 |
| 240p | −0.76/−0.33 | −3.49/−1.49 | −1.05/−0.84 | −3.54/−1.59 | −0.83/−0.76 | −3.40/−1.69 | −1.63/−0.96 | −4.10/−1.72 |
| CIF | −1.21/−0.84 | −2.67/−1.23 | −1.26/−1.16 | −2.71/−1.43 | −1.07/−0.95 | −2.67/−1.23 | −1.68/−1.35 | −1.53/−1.45 |
| Average | −1.58/−1.01 | −3.17/−1.61 | −1.73/−1.40 | −3.30/−1.96 | −1.26/−1.07 | −2.85/−1.68 | −2.50/−1.45 | −3.80/−1.96 |
| Low Rate (QP = 32, 37, 42, 45) | High Rate (QP = 22, 27, 32, 37) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| QPA [3] | TRA | VRF | TRA + VRF | QPA [3] | TRA | VRF | TRA + VRF | ||
| Class A and Class B | BasketballDrive | −0.44 | −1.38 | −1.84 | −3.64 | −0.43 | −1.51 | −0.91 | −2.21 |
| Kimono | −0.49 | −0.99 | −3.09 | −4.82 | −1.69 | −1.14 | −1.75 | −2.65 | |
| Cactus | −0.17 | −1.69 | −3.33 | −6.06 | −0.09 | −1.20 | −1.87 | −2.96 | |
| PeopleOnStreet | N/A | −1.11 | −8.35 | −9.67 | N/A | −1.28 | −4.56 | −5.69 | |
| Traffic | N/A | −1.89 | −4.14 | −7.98 | N/A | −1.95 | −4.05 | −4.68 | |
| HD 720p | FourPeople | −0.71 | −1.67 | −2.71 | −4.53 | −0.68 | −0.40 | −2.38 | −3.02 |
| KristenAndSara | −0.66 | −1.75 | −2.56 | −4.37 | −0.56 | −0.68 | −1.92 | −2.77 | |
| Vidyo1 | −0.70 | −2.03 | −4.45 | −6.43 | −0.88 | −0.55 | −3.26 | −4.03 | |
| Vidyo3 | −0.73 | −2.24 | −3.35 | −5.83 | −0.61 | −0.63 | −1.85 | −2.70 | |
| Vidyo4 | −0.90 | −1.48 | −3.23 | −4.92 | −0.64 | −0.29 | −1.84 | −2.35 | |
| ChinaSpeed | N/A | −1.98 | −1.60 | −3.65 | N/A | −0.81 | −0.64 | −1.44 | |
| SlideEditing | N/A | −0.01 | 0.02 | 0.07 | N/A | 0.27 | −0.06 | 0.26 | |
| Class C 480p | BQMall | −0.77 | −1.39 | −3.96 | −5.33 | −0.88 | −0.94 | −1.86 | −2.78 |
| PartyScene | −0.57 | −2.80 | −1.70 | −4.44 | −0.61 | −1.18 | −0.65 | −1.83 | |
| BasketballDrillText | N/A | −2.24 | −2.22 | −4.37 | N/A | −1.61 | −1.11 | −2.69 | |
| 4SIF | Ice | −0.68 | −0.80 | −9.33 | −9.90 | −0.97 | −0.77 | −4.23 | −4.60 |
| Class D | BasketballPass | −0.43 | −0.81 | −4.52 | −5.99 | 0.84 | 0.27 | −1.80 | −2.33 |
| BlowingBubbles | −0.57 | −2.42 | −1.49 | −4.63 | 0.26 | 0.71 | −0.65 | −1.00 | |
| CIF | Hall | −0.68 | −2.07 | −2.04 | −4.30 | −0.88 | −1.92 | −0.92 | −3.21 |
| Foreman | −0.41 | −1.48 | −4.03 | −5.50 | −0.49 | −1.25 | −2.12 | −3.49 | |
| Football | −0.82 | −0.41 | −1.89 | −2.99 | −0.72 | −0.45 | −0.56 | −1.07 | |
| Average | −0.61 | −1.55 | −3.32 | −5.20 | −0.56 | −0.82 | −1.86 | −2.73 | |
| Low Rate (QP = 32, 37, 42, 45) | High Rate (QP = 22, 27, 32, 37) | ||||||
|---|---|---|---|---|---|---|---|
| TRA | VRF | TRA + VRF | TRA | VRF | TRA + VRF | ||
| Class A and Class B | BasketballDrive | 0.04 | 0.06 | 0.12 | 0.03 | 0.02 | 0.05 |
| Kimono | 0.03 | 0.11 | 0.17 | 0.03 | 0.05 | 0.08 | |
| Cactus | 0.06 | 0.11 | 0.21 | 0.02 | 0.04 | 0.07 | |
| PeopleOnStreet | 0.05 | 0.40 | 0.46 | 0.06 | 0.20 | 0.25 | |
| Traffic | 0.08 | 0.16 | 0.34 | 0.07 | 0.31 | 0.16 | |
| HD 720p | FourPeople | 0.09 | 0.14 | 0.24 | 0.02 | 0.09 | 0.11 |
| KristenAndSara | 0.09 | 0.13 | 0.22 | 0.02 | 0.06 | 0.09 | |
| Vidyo1 | 0.10 | 0.22 | 0.33 | 0.02 | 0.11 | 0.13 | |
| Vidyo3 | 0.11 | 0.17 | 0.30 | 0.02 | 0.06 | 0.09 | |
| Vidyo4 | 0.06 | 0.14 | 0.22 | 0.01 | 0.06 | 0.07 | |
| ChinaSpeed | 0.09 | 0.07 | 0.16 | 0.04 | 0.03 | 0.08 | |
| SlideEditing | 0.00 | 0.00 | -0.01 | -0.04 | 0.01 | -0.04 | |
| Class C 480p | BQMall | 0.06 | 0.17 | 0.23 | 0.04 | 0.07 | 0.11 |
| PartyScene | 0.10 | 0.06 | 0.16 | 0.05 | 0.03 | 0.08 | |
| BasketballDrillText | 0.10 | 0.10 | 0.19 | 0.07 | 0.05 | 0.12 | |
| 4SIF | Ice | 0.04 | 0.44 | 0.46 | 0.03 | 0.14 | 0.16 |
| Class D | BasketballPass | 0.03 | 0.18 | 0.24 | -0.01 | 0.09 | 0.11 |
| BlowingBubbles | 0.08 | 0.06 | 0.16 | -0.03 | 0.03 | 0.04 | |
| CIF | Hall | 0.11 | 0.11 | 0.23 | 0.06 | 0.03 | 0.10 |
| Foreman | 0.06 | 0.17 | 0.23 | 0.05 | 0.09 | 0.15 | |
| Football | 0.01 | 0.07 | 0.11 | 0.02 | 0.03 | 0.06 | |
| Average | 0.07 | 0.15 | 0.23 | 0.03 | 0.08 | 0.10 | |
| Sequence | QPA [35] | QP—λ [34] (a = 4.2005, b = 13.7112) | QP—λ [34] (a = 4.2005, b = 9.7112) | QPA [3] | TRA_0 | Proposed TRA |
|---|---|---|---|---|---|---|
| BasketballPass | 3.01 | 11.89 | 3.58 | −0.43 | −0.60 | −0.81 |
| BlowingBubbles | 5.16 | 8.39 | 3.37 | −0.57 | −1.48 | −2.42 |
| Football | 2.37 | 15.65 | 3.72 | −0.82 | −0.22 | −0.41 |
| Foreman | 3.90 | 10.59 | 2.63 | −0.41 | −1.35 | −1.48 |
| Hall | 5.39 | 7.27 | 2.91 | −0.68 | −1.62 | −2.07 |
| Average | 3.97 | 10.76 | 3.24 | −0.58 | −1.05 | −1.44 |
| Tid | HEVC | HEVC + Proposed Methods | |||
|---|---|---|---|---|---|
| VRF | TRA | TRA + VRF | |||
| HR | 0–I | 23.95 | 24.07 | 30.06 | 30.23 |
| 0–P | 32.03 | 32.19 | 33.43 | 33.61 | |
| 1–B | 17.27 | 17.27 | 16.43 | 16.41 | |
| 2–B | 20.27 | 20.16 | 11.69 | 11.57 | |
| 3–B | 6.50 | 6.30 | 8.39 | 8.19 | |
| LR | 0–I | 45.78 | 46.27 | 51.44 | 52.04 |
| 0–P | 34.57 | 34.94 | 31.24 | 31.58 | |
| 1–B | 8.20 | 8.17 | 7.42 | 7.36 | |
| 2–B | 7.82 | 7.51 | 5.81 | 5.48 | |
| 3–B | 3.63 | 3.11 | 4.09 | 3.54 | |
| Class | Low Rate | High Rate | ||
|---|---|---|---|---|
| TRA | TRA + VRF | TRA | TRA + VRF | |
| 1080p | 99.7 | 675.90 | 99.1 | 561.5 |
| 720p | 100.8 | 447.10 | 101.9 | 463.2 |
| 480p | 87.0 | 231.30 | 85.6 | 281.7 |
| 4SIF | 105.9 | 231.19 | 96.9 | 243.4 |
| 240p | 109.3 | 148.55 | 106.9 | 166.7 |
| CIF | 96.1 | 165.50 | 96.9 | 180.8 |
| Average | 99.8 | 316.60 | 97.9 | 316.2 |
| Video | ||||
|---|---|---|---|---|
| BasketballDrive | 12.71 | 96.06 | 2.37 | 1.56 |
| Kimono | 12.41 | 96.09 | 2.38 | 1.53 |
| Cactus | 14.12 | 96.03 | 2.37 | 1.59 |
| PeopleOnStreet | 14.17 | 96.85 | 1.87 | 1.28 |
| Traffic | 18.47 | 96.81 | 1.86 | 1.33 |
| FourPeople | 13.70 | 95.21 | 2.85 | 1.94 |
| KristenAndSara | 12.71 | 96.06 | 2.37 | 1.56 |
| Vidyo1 | 13.72 | 95.22 | 2.82 | 1.96 |
| Vidyo3 | 13.15 | 95.26 | 2.82 | 1.93 |
| Vidyo4 | 13.24 | 95.24 | 2.85 | 1.91 |
| ChinaSpeed | 10.24 | 95.24 | 2.87 | 1.89 |
| SlideEditing | 13.73 | 95.22 | 2.83 | 1.95 |
| BQMall | 10.12 | 94.90 | 3.10 | 2.00 |
| PartyScene | 8.68 | 94.83 | 3.15 | 2.02 |
| BasketballDrillText | 9.75 | 94.84 | 3.13 | 2.02 |
| Ice | 10.71 | 94.76 | 3.11 | 2.12 |
| BasketballPass | 10.26 | 94.24 | 3.50 | 2.26 |
| BlowingBubbles | 8.13 | 94.33 | 3.46 | 2.21 |
| Hall | 10.85 | 94.25 | 3.28 | 2.46 |
| Foreman | 9.00 | 94.36 | 3.53 | 2.12 |
| Football | 5.85 | 94.30 | 3.42 | 2.28 |
| Average | 11.70 | 95.24 | 2.85 | 1.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
HoangVan, X.; Dao Thi Hue, L.; Nguyen Canh, T. A Trellis Based Temporal Rate Allocation and Virtual Reference Frames for High Efficiency Video Coding. Electronics 2021, 10, 1384. https://doi.org/10.3390/electronics10121384
HoangVan X, Dao Thi Hue L, Nguyen Canh T. A Trellis Based Temporal Rate Allocation and Virtual Reference Frames for High Efficiency Video Coding. Electronics. 2021; 10(12):1384. https://doi.org/10.3390/electronics10121384
Chicago/Turabian StyleHoangVan, Xiem, Le Dao Thi Hue, and Thuong Nguyen Canh. 2021. "A Trellis Based Temporal Rate Allocation and Virtual Reference Frames for High Efficiency Video Coding" Electronics 10, no. 12: 1384. https://doi.org/10.3390/electronics10121384