
My-Trac: System for Recommendation of Points of Interest on the Basis of Twitter Profiles

 , ,
, , 
Abstract
:1. Introduction
2. Natural Language Processing Techniques Applied to Twitter Profiles
2.1. Word Embedding Techniques
- Bag-of-words. This model allows to extract the characteristics of texts (also images, audios, etc.). It is, therefore, a feature extraction model. The model consists of two parts: a representation of all the words in the text and a vector representing the number of occurrences of each word throughout the text. That is why it is called Bag-of-words. This model completely ignores the structure of the text, it simply counts the number of times words appear in it. It has been implemented through the Genism library [9].
- Term Frequency - Inverse Document Frequency (TF-IDF). This is the product of two measures that indicate, numerically, the degree of relevance that a word has in a document within a collection of documents [10]. It is broken down into two parts:
- –
- Term frequency: Measures the frequency with which certain terms appear in a document. There are several measurement options, the simplest being the gross frequency, i.e., the number of times a term t appears in a document d. However, in order to avoid a predisposition towards long documents, the normalized frequency is used:As shown in Equation (1), the frequency of the term is divided by the maximum frequency of the terms in the document.
- –
- Inverse document frequency: If a term appears very frequently in all of the analyzed documents, its weight is reduced. If it appears infrequently, it is increased.
- Word2vec. This technique uses huge amounts of text as input and is able to identify which words appear to be similar in various contexts [13,14,15]. Once trained on a sufficientñy big dataset, 300-dimensional vectors are generated for each word, forming a new vocabulary where "similar" words are placed close to each other. Pre-trained vectors are used, achieving a wealth of information from which to understand the semantic meaning of the texts.
- Doc2vec. This technique is an extension of Word2Vec and is applied to a document as a whole instead of individual words, it uses an unsupervised learning approach to better understand documents as a whole [16]. Doc2Vec model, as opposed to Word2Vec model [17], is used to create a vectorized representation of a group of words taken collectively as a single unit. It does not only give the simple average of the words in the sentence.
2.2. Topic Modeling
- Latent Dirichlet allocation (LDA). Is a generative statistical model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar [20,21,22]. For example, if observations are collections of words in documents, each document is a mixture of a small number of topics and each word’s presence is attributable to one of the document’s topics. LDA is an example of a topic model and belongs to the machine learning toolbox and in wider sense to the artificial intelligence toolbox.
- Nonnegative Matrix Factorization (NMF). Is an unsupervised learning algorithm belonging to the field of linear algebra. NMF reduces the dimensionality of an input matrix by factoring it in two and approximating it to another of a smaller range. The formula is . Let us suppose, observing Equation (4), a vectorization of P documents with an associated dictionary of N terms (weight). That is, each document is represented as a vector of N dimensions. All documents, therefore, correspond to a V matrixwhere N is the number of rows in the matrix, and each of them represents a term, while P is the number of columns in the matrix and each of them represents a document.Equations (5) and (6) shows matrices W and H. The value r marks the number of topics to be extracted from the texts.Matrix W contains the characteristic vectors that make up these topics. The number of characteristics (dimensionality) of these vectors is identical to that of the data in the input matrix V. Since only a few topic vectors are used to represent many data vectors, it is ensured that these topic vectors discover latent structures in the text.The H-matrix indicates how to reconstruct an approximation of the V-matrix by means of a linear combination with the W-columns.where N is the number of rows in matrix W, and each of them represents a term (weight), and r is the number of columns in matrix W, where r is the number of characteristics to be extracted.where r is the number of rows in matrix H, r is the number of characteristics to be extracted, and P is the number of columns, with one column for each document. The result of the matrix product between W and H is, therefore, a matrix of dimensions corresponding to a compressed version of V.
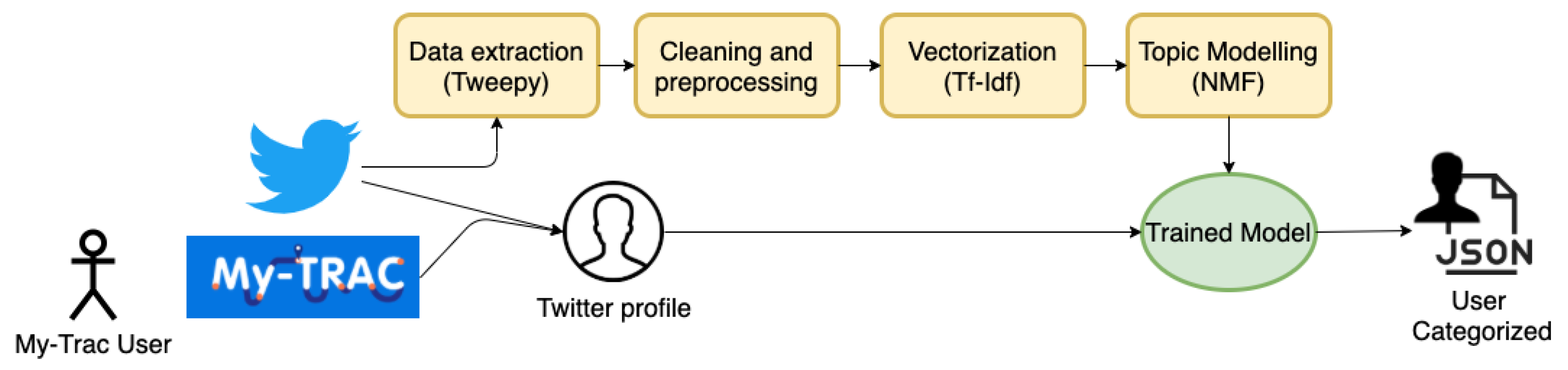
3. Proposal
3.1. Category Definition
3.2. Twitter Data Extraction
3.3. Preprocessing of Tweets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| fromnltk . tokenizeimportword_tokenize import~spacy |
| sp = spacy.load(‘en_core_web_sm’) stopwords_dict = sp.Defaults.stop_words |
| deftweet_preprocessing(tweet): tweet = hashtag_removal(tweet) tweet = mentions_removal(tweet) tweet = url_removal(tweet) tweet = html_removal(tweet) tweet = punctuation_removal(tweet) tweet = emojis_removal(tweet) tweet = word_tokenize(tweet) tweet = [word for word in tweet if not word in stopwords_dict] return tweet |
3.4. Vectorization
| fromsklearn.feature_extraction.textimport~TfidfVectorizer |
| deftfidf_vectorization(tweets): vectorizer = TfidfVectorizer( min_df=100, max_df=0.85, ngram_range=(1, 2), preprocessor=‘⎵’.join, use_idf=True ) vectorized_tweets = vectorizer.fit_transform(tweets) return vectorized_tweets |
3.5. Topic Modeling
| fromsklearn.decomposition import~NMF |
| deftrain_model(vectorized_tweets): nmf_model = NMF(n_components=23, alpha=.1, l1_ratio=.5, init=‘nndsvda’) nmf_model.fit(vectorized_tweets) return nmf_model |
4. Evaluation and Results
5. Final System Integration in My-Trac Application
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ludwig, B.; Zenker, B.; Schrader, J. Recommendation of Personalized Routes with Public Transport Connections. In Proceedings of the International Conference on Intelligent Interactive Assistance and Mobile Multimedia Computing, Rostock-Warnemünde, Germany, 9–11 November 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 97–107. [Google Scholar]
- Cui, G.; Luo, J.; Wang, X. Personalized travel route recommendation using collaborative filtering based on GPS trajectories. Int. J. Digit. Earth 2018, 11, 284–307. [Google Scholar] [CrossRef]
- Briedenhann, J.; Wickens, E. Tourism routes as a tool for the economic development of rural areas—Vibrant hope or impossible dream? Tour. Manag. 2004, 25, 71–79. [Google Scholar] [CrossRef]
- Cea-Morán, J.J.; González-Briones, A.; De La Prieta, F.; Prat-Pérez, A.; Prieto, J. Extraction of Travellers’ Preferences Using Their Tweets. In Proceedings of the International Symposium on Ambient Intelligence, L Aquila, Italy, 17–19 June 2020; pp. 224–235. [Google Scholar]
- De Pessemier, T.; Minnaert, J.; Vanhecke, K.; Dooms, S.; Martens, L. Social recommendations for events. In Proceedings of the CEUR workshop Proceedings, Miami, FL, USA, 1 October 2013; Volume 1066. [Google Scholar]
- Stathopoulos, E.A.; Paliokas, I.; Meditskos, G.; Diplaris, S.; Tsafaras, S.; Valkouma, E.; Pehlivanides, G.; Riggas, C.; Vrochidis, S.; Votis, K.; et al. Smart discovery of cultural and natural tourist routes. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence-Companion, Thessaloniki, Greece, 14–17 October 2019; pp. 208–214. [Google Scholar]
- Sansonetti, G.; Gasparetti, F.; Micarelli, A.; Cena, F.; Gena, C. Enhancing cultural recommendations through social and linked open data. User Model. User-Adapt. Interact. 2019, 29, 121–159. [Google Scholar] [CrossRef]
- Garcia, A.; Arbelaitz, O.; Linaza, M.T.; Vansteenwegen, P.; Souffriau, W. Personalized tourist route generation. In Proceedings of the International Conference on Web Engineering, Vienna, Austria, 5–9 July 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 486–497. [Google Scholar]
- University, Y. About Yale: Yale Facts. 2017. Available online: https://www.yale.edu/about-yale/yale-facts (accessed on 24 May 2021).
- Demestichas, K.; Kosmides, P. An offline, statistical method for cost efficient design of experiments and field trials involving electric vehicles. In Proceedings of the 11th ITS European Congress, Glasgow, Scotland, 6–9 June 2016. [Google Scholar]
- Ferrari, A.; Donati, B.; Gnesi, S. Detecting domain-specific ambiguities: An NLP approach based on Wikipedia crawling and word embeddings. In Proceedings of the 017 IEEE 25th International Requirements Engineering Conference Workshops (REW), Lisbon, Portugal, 4–8 September 2017; pp. 393–399. [Google Scholar]
- Wallace, E.; Wang, Y.; Li, S.; Singh, S.; Gardner, M. Do nlp models know numbers? Probing numeracy in embeddings. arXiv 2019, arXiv:1909.07940. [Google Scholar]
- Church, K.W. Word2Vec. Nat. Lang. Eng. 2017, 23, 155–162. [Google Scholar] [CrossRef] [Green Version]
- Rong, X. word2vec parameter learning explained. arXiv 2014, arXiv:1411.2738. [Google Scholar]
- Lilleberg, J.; Zhu, Y.; Zhang, Y. Support vector machines and word2vec for text classification with semantic features. In Proceedings of the 2015 IEEE 14th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), Beijing, China, 6–8 July 2015; pp. 136–140. [Google Scholar]
- Bilgin, M.; Şentürk, İ.F. Sentiment analysis on Twitter data with semi-supervised Doc2Vec. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), London, UK, 5–7 July 2017; pp. 661–666. [Google Scholar]
- Chen, Q.; Sokolova, M. Word2Vec and Doc2Vec in unsupervised sentiment analysis of clinical discharge summaries. arXiv 2018, arXiv:1805.00352. [Google Scholar]
- Islam, T. Yoga-veganism: Correlation mining of twitter health data. arXiv 2019, arXiv:1906.07668. [Google Scholar]
- Chen, Y.; Zhang, H.; Liu, R.; Ye, Z.; Lin, J. Experimental explorations on short text topic mining between LDA and NMF based Schemes. Knowl. Based Syst. 2019, 163, 1–13. [Google Scholar] [CrossRef]
- Resnik, P.; Armstrong, W.; Claudino, L.; Nguyen, T.; Nguyen, V.A.; Boyd-Graber, J. Beyond LDA: Exploring supervised topic modeling for depression-related language in Twitter. In Proceedings of the 2nd Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, Denver, CO, USA, 5 June 2015; pp. 99–107. [Google Scholar]
- Mehrotra, R.; Sanner, S.; Buntine, W.; Xie, L. Improving lda topic models for microblogs via tweet pooling and automatic labeling. In Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 889–892. [Google Scholar]
- Tajbakhsh, M.S.; Bagherzadeh, J. Semantic knowledge LDA with topic vector for recommending hashtags: Twitter use case. Intell. Data Anal. 2019, 23, 609–622. [Google Scholar] [CrossRef]
- Wang, H.; Can, D.; Kazemzadeh, A.; Bar, F.; Narayanan, S. A system for real-time twitter sentiment analysis of 2012 us presidential election cycle. In Proceedings of the ACL 2012 System Demonstrations. Association for Computational Linguistics, Jeju Island, Korea, 8–14 July 2012; pp. 115–120. [Google Scholar]
- Cotelo, J.M.; Cruz, F.L.; Enríquez, F.; Troyano, J. Tweet categorization by combining content and structural knowledge. Inf. Fusion 2016, 31, 54–64. [Google Scholar] [CrossRef]
- Lee, K.; Palsetia, D.; Narayanan, R.; Patwary, M.M.A.; Agrawal, A.; Choudhary, A. Twitter trending topic classification. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11 December 2011; pp. 251–258. [Google Scholar]
- IAB Categories | MoPub Publisher UI | MoPub Developers. Available online: https://developers.mopub.com/publishers/ui/iab-category-blocking/ (accessed on 4 May 2021).
- Tweepy. Available online: https://www.tweepy.org/ (accessed on 4 May 2021).








| Title / Publication | Functionality | Advantages | Shortcomings |
|---|---|---|---|
| ROSE (ROuting SErvice) [1] | Mobile phone application that suggests events and places to the user and guides them via public transport. | The current systems utilize a set of information initially entered into the application which is not updated afterwards. | There is no system that combines event recommendation and pedestrian navigation with (real-time) public transport. It does not employ multi-modal navigation between different public transport modes (bus, train, carpooling, plane, etc.) in different countries and that would use information from the user’s social network profile. |
| Systems for city-based tourism [2] | A personalized travel route recommendation based on the road networks and users’ travel preferences. | The experimental results show that the proposed methods achieve better results for travel route recommendations compared with the shortest distance path method. | It does not use information from public transport services in route recommendations. |
| Tourism routes as a tool for the economic development of rural areas—vibrant hope or impossible dream? [3] | This paper argues that the clustering of activities and attractions, and the development of rural tourism routes, stimulates co-operation and partnerships between local areas. The paper further discusses the development of rural tourism routes in South Africa and highlights the factors critical to its success. | The article analyzes the realization of routes that include activities and attractions in a way that encourages and enhances rural development in Africa. | Preliminary project that requires public cooperation (institutions, transport, services) for a comprehensive improvement of the proposal. |
| Title / Publication | Functionality | Advantages | Shortcomings |
|---|---|---|---|
| Social Recommendations for Events [5] | Outlife recommender assists in finding the ideal event by providing recommendations based on the user’s personal preferences. | In addition to the user’s preferences, the recommender uses information from the user’s group of friends to make event recommendations more satisfactory. | Although it uses information from the user’s groups of friends, no use is made of information from the user’s social networks to complement the analysis and recommendation. |
| Smart Discovery of Cultural and Natural Tourist Routes [6] | This paper presents a system designed to utilize innovative spatial interconnection technologies for sites and events of environmental, cultural and tourist interests. The system discover and consolidate semantic information from multiple sources, providing the end-user the ability to organize and implement integrated and enhanced tours. | The system adapts the services offered to meet the needs of specific individuals, or groups of users who share similar characteristics, such as visual, acoustic, or motor disabilities. Personalization is done in a dynamic way that takes place at the time and place of the service. | The very comprehensive system that uses external services, scraping, crawling, geo-positioning but does not include information from social networks to complement the analysis and recommendation of events. |
| Enhancing cultural recommendations through social and linked open data [7] | Hybrid recommender system (RS) in the artistic and cultural heritage area, which takes into account the activities on social media performed by the target user and her friends | The system integrates collaborative filtering and community-based algorithms with semantic technologies to exploit linked open data sources in the recommendation process. Furthermore, the proposed recommender provides the active user with personalized and context-aware itineraries among cultural points of interest. | The main drawback is the absence of extensive control over the semantics that are not taken into account. It generates difficulties in justifying, explaining, and hence analyzing the resulting scores. |
| Personalized Tourist Route Generation [8] | Intelligent routing system able to generate and customize personalized tourist routes in real-time and taking into account public transportation. | We have modeled the tourist planning problem, integrating public transportation, as the Time Dependent Team Orienteering Problem with Time Windows (TDTOPTW). We have designed a heuristic able to solve it in real time, precalculating the average travel times between each pair of POIs in a preprocessing step. | Future works consists on extending the system to more cities with a different public transport network topology. The next one consists on integrating an advanced recommendation system in a wholly functional PET. The systema don’t use social network capabilities, that allows to store, share and add travel experiences to better help tourists on the destination. |
| Topics |
|---|
| Arts & Entertainment |
| Automotive |
| Business |
| Careers |
| Education |
| Family & Parenting |
| Health & Fitness |
| Food & Drink |
| Hobbies & Interests |
| Home & Garden |
| Law, Gov’t & Politics |
| News |
| Personal Finance |
| Society |
| Science |
| Pets |
| Sports |
| Style & Fashion |
| Technology & Computing |
| Travel |
| Real Estate |
| Shopping |
| Religion & Spirituality |
| Text | Nltk_tokenized | |
|---|---|---|
| 0 | Read This Before Taking a Road Trip with a Pet | [read, taking, road, trip, pet] |
| 1 | @kenwardskorner @Senators @Canucks In addition, does … | [also, name, imply, take, acid, road, trips, I…] |
| 2 | Our Art is our Passion \n#apnatruckart #truck | [art, passion, apnatruckart, truck, art, uniqu…] |
| 3 | Lelang drop acc budget 40–50 k dong? | [lelang, drop, acc, budget, dong] |
| 4 | We agree…and want everyone to know that ou | [agree, want, everyone, know, tours, relaxed, … |
| 5 | Choosing a hotel for a break away with the fam… | [choosing, hotel, break, away, family, special… |
| 6 | @_JassyJass Are you,camping? | [camping] |
| 7 | How to Pack Your Electronics for Air Travel ht | [pack, electronics, air, travel] |
| 8 | Dasar low budget! https://t.co/2YUmUrGjj5 | [dasar, low, budget] |
| Topic | Top 10 Words | |
|---|---|---|
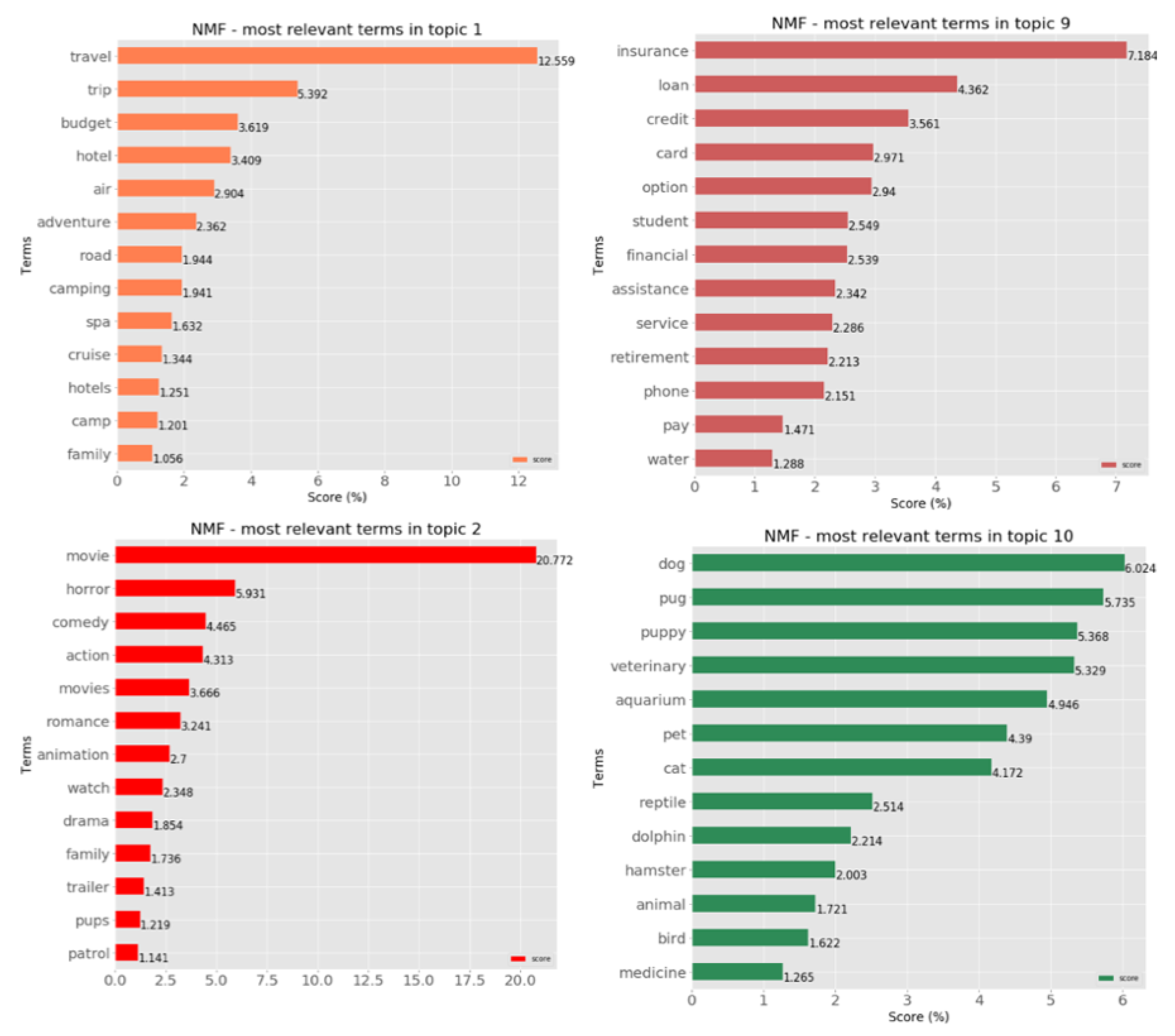
| 1 | Travel | travel, trip, budget, air, hotel, adventure, road, camp, family, day |
| 2 | Movies | movie, horror, action, comedy, movies, romance, watch, animation, family, drama |
| 3 | Videogames | game, xbox, pc, mmo, nintendo, videogame, esport, rpg, play, console |
| 4 | Careers | apprenticeship, internship, job, search, career, interview, vocational, training, remote, advice |
| 5 | Events | amusement, concert, cinema, restaurant, birthday, match, holiday, football, funeral, park |
| 6 | Health & Fitness | health, nutrition, therapy, physical, fitness, workout, exercise, wellness, medicine, weight |
| 7 | Religion & Spirituality | islam, christianity, hinduism, judaism, buddhism, spirituality, religion, astrology, atheism, sikhism |
| 8 | Shopping | grocery, lotto, shopping, gift, discount, sale, card, coupon, sales, code |
| 9 | Personal Finance | insurance, loan, credit, option, card, student, financial, service, assistance, phone |
| 10 | Pets | veterinary, dog, pug, puppy, aquarium, pet, cat, reptile, dolphin, hamster |
| 11 | Automotive | truck, car, auto, motorcycle, tesla, van, scooter, pickup, luxury, minivan |
| 12 | Science | chemistry, geography, geology, biology, physics, genetic, astronomy, environment, math, science |
| 13 | Law, Gov’t & Politics | election, political, law, issue, vote, news, state, people, country, trump |
| 14 | Education | preschool, college, university, exam, electoral, education, homework, student, school, language |
| 15 | Food & Drink | coffee, vegetarian, beer, eat, vegan, cook, drink, wine, tea, dining |
| 16 | Family & Parenting | marriage, parent, single, baby, daycare, teen, date, life, toddler, adopt |
| 17 | Style & Fashion | wear, beauty, clothing, perfume, deodorant, wallet, casual, fashion, shave, trainer |
| 18 | Technology & Computing | software, app, developer, mongodb, database, email, android, internet, computer, ai |
| 19 | Hobbies & Interests | meme, draw, puzzle, collect, comic_strip, antique, guitar, art, woodworke, painting |
| 20 | Sports | martial, rugby, golf, sport, climb, pool, racing, cricket, skating, basketball |
| 21 | Business | industry, agriculture, construction, startup, recall, economy, business, automotive, butterball, turkey |
| 22 | Medicine & Health | vaccine, menopause, pregnancy, health, mental, surgery, injury, disease, psychology, substance |
| 23 | Music | music, radio, rock, funk, pop, soul, classic, songwriter, listen, classical |
| Cat 1 | Cat 2 | Cat 2 | |
|---|---|---|---|
| Pontifex | Religion & Spirituality | Family & Parenting | Tech & Computing |
| Tesla | Automotive | Tech & Computing | Travel |
| BBCNews | Law, Gov’t & Politics | Sports | Family & Parenting |
| NintendoAmerica | Videogames | Hobbies & Interests | Sports |
| Theresa_may | Law, Gov’t & Politics | Business | Personal Finance |
| Oprah | Events | Family & Parenting | Sports |
| SkyFootball | Sports | Events | Hobbies & Interests |
| ScuderiaFerrari | Sports | Automotive | Law, Gov’t & Politics |
| IMDb | Events | Movies | Hobbies & Interests |
| ScienceMagazine | Science | Medicine & Health | Tech & Computing |
| Spotify | Music | Hobbies & Interests | Family & Parenting |
| Airbnb | Travel | Events | Careers |
| First Category | Second Category | Third Category | |
|---|---|---|---|
| Tesla | Automotive (70.92%) | Tech & Computing (10.07%) | Travel (3.86%) |
| RealDonaldTrump | Law, Gov’t & Politics (28.02%) | Business (11.36%) | Sports (8.02%) |
| ScienceMagazine | Science (24.41%) | Medicine & Health (16.73%) | Tech & Computing (12.03%) |
| NintendoAmerica | Videogames (41.65%) | Hobbies & Interests (12.19%) | Sports (9.74%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rivas, A.; González-Briones, A.; Cea-Morán, J.J.; Prat-Pérez, A.; Corchado, J.M. My-Trac: System for Recommendation of Points of Interest on the Basis of Twitter Profiles. Electronics 2021, 10, 1263. https://doi.org/10.3390/electronics10111263
Rivas A, González-Briones A, Cea-Morán JJ, Prat-Pérez A, Corchado JM. My-Trac: System for Recommendation of Points of Interest on the Basis of Twitter Profiles. Electronics. 2021; 10(11):1263. https://doi.org/10.3390/electronics10111263
Chicago/Turabian StyleRivas, Alberto, Alfonso González-Briones, Juan J. Cea-Morán, Arnau Prat-Pérez, and Juan M. Corchado. 2021. "My-Trac: System for Recommendation of Points of Interest on the Basis of Twitter Profiles" Electronics 10, no. 11: 1263. https://doi.org/10.3390/electronics10111263