1. Introduction
The human visual system does not have the same interest in all areas of an image. Visual attention is focused on objects or areas in which visual characteristics such as brightness and color are clear. Using these visual features, it is possible to calculate the degree of focus on a specific pixel in an image, and this is called saliency. There are two ways to extract saliency from an image: a user study method using an eye tracker and a saliency model applying the theory of prior experiments and visual features.
The eye tracker can track the movement of the pupil to the experimenter and measure the time the pupil stays for a specific pixel in the image. Nemoto extracted FDM (Fixation Density Map) from the image by dividing concentration on the sight, simple blinking, and movement of the eye by the time the pupil stays [
1]. When determining the performance of the saliency model, the performance of the model can be determined by using the FDM as ground truth. Since FDM extracts saliency using a user study, it is impossible to calculate saliency for the images unused in a user study. Thus, we use a saliency model that calculates saliency using image pixel values automatically.
A pioneering saliency model is the Itti model [
2]. It extracts color, brightness, and motion as visual features through a Gaussian filter and a Gaber filter using a feature integration theory [
3], which is a biological feature in human vision, and compares the visual features with surrounding pixels to calculate image saliency. Starting with the Itti model, various saliency models, such as CovSal [
4], Judd [
5], and WMAP [
6], have been developed. Among them, the CovSal model is used as a model to extract image saliency in this paper because it has higher saliency extraction performance and lower computational complexity than other models that use relationship to pixel values.
Since the saliency technology complements the limitations of human vision by using information on the location where vision is concentrated, it can be applied in various ways in the military field. In particular, the saliency technology is being used variously in HMD (Head Mounted Display) applications where interactions with the visual system are important. Researchers of the University of Mumbai, India, conducted a study on the Advanced Military Helmet, which displays all information related to the battlefield on a single screen by integrating augmented reality models using various wireless communication technologies and saliency into the helmet [
7]. Researchers of the PLA Army College of Engineering in China proposed an object detection method through the combination of human visual salience and visual psychology to quickly and accurately detect military objects on a vast and complex battlefield [
8]. As such, the saliency technology can be applied to HMD to complement the limitations of human vision and provide integrated battlefield information. However, since soldiers rely on batteries for power supply on the battlefield, a low power technology that maintains saliency is very necessary in mobile devices using batteries such as HMDs.
CURA [
9], the most recently studied low power saliency study, is a mobile display low power technique that divides an image according to saliency and then uses a different display low power constant depending on the area. CURA uses JND (Just Noticeable Difference) to solve the problem of brightness difference caused by the low power technique applied differently for each divided area. When there is a difference in brightness in the area, CURA uses JND to adjust so that the user does not recognize the difference in area. However, if you look at the video provided by CURA, some artifacts, which are made by the difference in brightness between regions, can be seen even if JND is used.
In order to improve such a problem, this paper proposes a new low power method that utilizes a saliency model and an image segmentation algorithm that divides an image into multiple objects. To this end, our method combines two saliency processing levels: saliency level and pixel level synergistically. First, an image is divided into multiple regions with the same saliency level using the saliency model. Second, each saliency region is divided into subregions with the same pixel level using the segmentation algorithm. Then, a low power and high visual-quality pixel conversion is fulfilled using a well-known IQA (image quality assessment) index and gamma correction at all regions with the found both levels adaptively. As a result, our method can achieve low power and high human visual satisfaction and mitigate artifacts unlike CURA.
The rest of this paper is organized as follows.
Section 2 describes related work such as saliency models, segmentation, and low power technology. In
Section 3, the motivation and contributions are remarked. In
Section 4, the proposed low power saliency method is described. In
Section 5, the proposed low power method and existing methods are compared through experiments in the aspect of power saving and distortion. Finally,
Section 6 concludes with a summary.
3. Motivation and Contributions
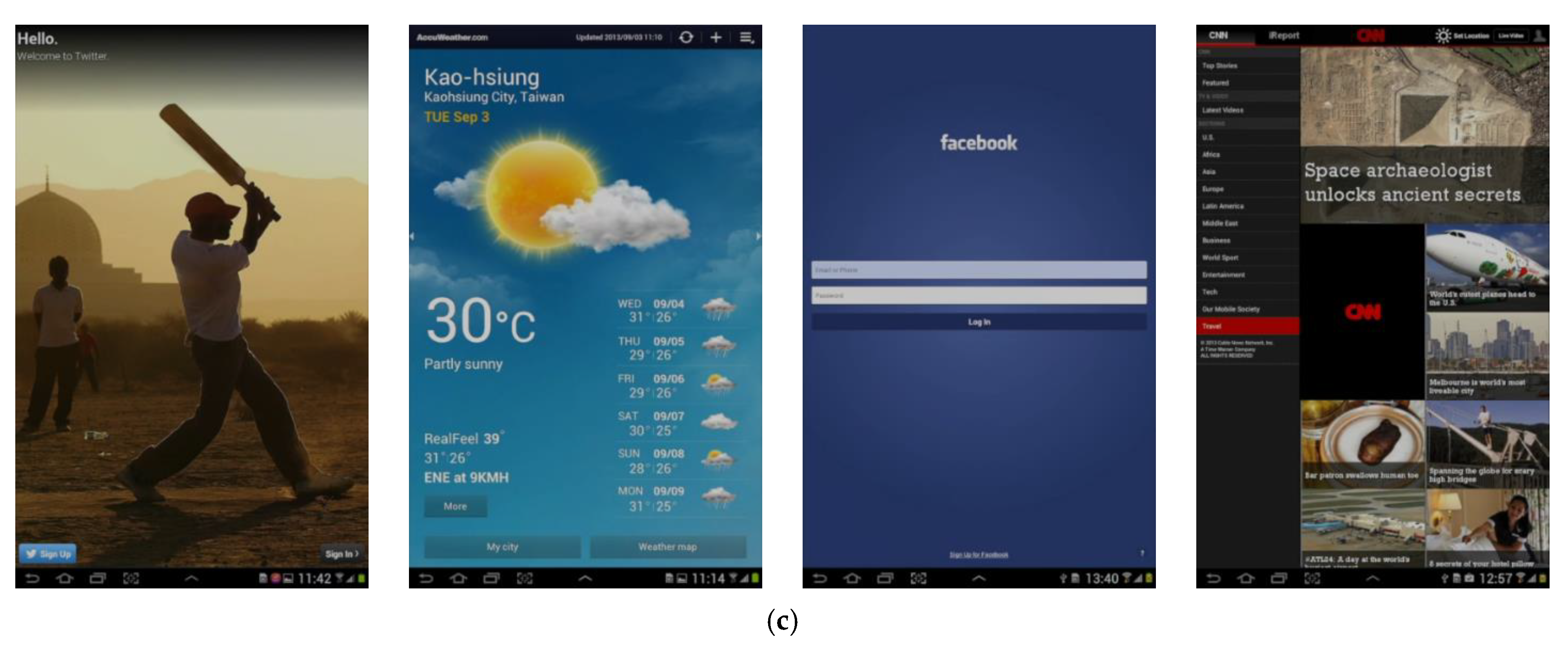
The saliency map calculated using the image pixel values can tell which area the human vision is concentrated. Therefore, there is a need for a study on an efficient method for a low power method that maintains visual satisfaction while dealing with the saliency map information efficiently. Looking at the example image as shown in
Figure 3a, the simplest way to implement low power is to perform global dimming using a single gamma as shown in
Figure 3b. However, since global dimming is a method that ignores saliency, visual satisfaction tends to be low. In addition, even if they have similar visual satisfaction, they have a low power-saving rate because the feature is not considered in the bright area.
Figure 3c is a saliency-aware method for advanced low power and visual satisfaction like CURA. By applying different gammas according to the saliency, the visual satisfaction is high and the power saving rate is high. However, since the saliency-aware method applies a different gamma to each region, it is necessary to adjust the brightness difference between regions resulting from the difference in gamma.
CURA [
9], a recently studied low power saliency-aware technique, proposed a saliency-aware low power technique using JND between regions. CURA divides the image into 5 areas using the Itti model [
2] among the saliency models. When dividing the image, the number of pixels in each region is the same. Then, based on SSIM [
30], different low power techniques are implemented in each area. It is claimed that JND solves the artifact problem occurring at the boundary of the regions due to different low power levels. However, as shown in
Figure 4c, the difference in brightness due to the different gammas can be observed between the bat held by the man and the landscape clearly. This observation indicates that there is a limitation of using saliency only for low power and the fine-grained segmentation within a saliency region is highly required.
Thus, in this paper, we tackle proposing a low power mobile display technique that maintains high human visuality and high power saving by dividing an image into saliency regions and their objects through two-level image clustering. We also aim at mitigating artifacts which occurred in prior work. Specifically, we implemented (1) partitioning between saliencies using the CovSal saliency model and (2) partitioning within saliencies using the SLIC superpixel algorithm [
29].
The contributions of this paper are summarized as follows:
We propose the first work combining a saliency level and a pixel level for better both low power and human visual satisfaction;
In order to determine a proper number of saliency clusters in the aspect of low power and computing overhead, we devise four new factors based on the CovSal saliency model;
In order to overcome the limitation that the SLIC superpixel algorithm cannot distinguish the areas divided in a saliency area, we devise a method of adjusting the initial search position in the SLIC algorithm in order to exclude pixels overlapping by other areas for better segmentation in each saliency area;
Compared to prior work, artifacts are suppressed efficiently by using a high-performance saliency model combined with pixel-level segmentation and a well-known image quality assessment index while achieving low power consumption.
4. Proposed Low Power Saliency Method
4.1. Overview of the Proposed Method
Figure 5 shows the overall flow of the proposed low power saliency method. First, our method finds the region of interest in the image using the CovSal saliency model and calculates the following four factors: (1) the sum of the pixel values in the CovSal saliency map; (2) the CovSal saliency map histogram gradient change rate; (3) the highest section pixel in the 10 sections of the CovSal saliency map; (4) the number of pixels with a pixel value of 0 in the CovSal Saliency Map. The image is divided based on these four factors.
Second, our method finds the row and column with color data in the CovSal saliency cluster divided based on the CovSal saliency. Next, it corrects the image by centering the pixel with the color value for the column and setting the pixel value to 0 for the rest of the column. Our method divides the image corrected in the previous step into a 50 × 50 square, and then sets the pixel with color data as the initial search position in the image whose pixel value is corrected at the center of the square. Then, since the image is segmented for the purpose of low power, pixels with zero brightness in the image are excluded because they do not affect the power. As a result, the image is divided into superpixels according to the CovSal saliency to implement two-stage division at the saliency level and the superpixel level.
Finally, SSIM, which is an image quality evaluation index, is set, and the SSIM index for the superpixel is set step by step by dividing it by a log scale in the target SSIM section using the brightness value of each superpixel divided in the CovSal saliency cluster. Then, based on the SSIM index set for each superpixel, the pixel value is compared to the image, and the converted low power coefficient is calculated for the pixel value implementing the target SSIM using a lookup table having the corresponding SSIM index. A low power image is implemented by adjusting the pixel value based on the superpixel using the previously calculated low power coefficient.
4.2. Clustering Based on the CovSal Saliency Model
In this paper, we use the CovSal model to discriminate saliency. This is because it has higher performance in the SIM, CC, and NSS evaluation matrices [
17], which are highly correlated with human visual satisfaction, compared to the Itti model [
2] used in CURA [
9]. The CovSal model extracts the saliency map using the feature covariance calculated by changing the size of the patch by using the absolute value of the pixel Lab value, the pixel top-bottom, and left-right brightness difference as features. In the CovSal saliency map, values 0 to 255 are assigned for each pixel in
Figure 6a as shown in
Figure 6b.
Using CovSal, it is very important to determine the number of proper clusters in the saliency map. If the number is small, we will have little chance for low power. Otherwise, we will have big overheads to make the pixels of many saliency areas into low power ones. Thus, we devise a noble method to determine the number of clusters based on the CovSal model properly. For saliency-based image clustering using CovSal, the number of CovSal saliency clusters is determined by calculating the following four factors: (1) Sum of pixel values in the CovSal saliency map; (2) Gradient of the CovSal saliency map histogram; (3) The number of pixels in the highest section among 10 sections of the CovSal saliency map; (4) The number of pixels with a pixel value of 0 in the CovSal saliency map.
Among the four values, the number of pixels with a pixel value of 0 in the saliency map is applied as a factor that decreases the number of CovSal saliency clusters when the number is large. When there are multiple objects that attract attention in the CovSal saliency map, the movement of the gaze is frequent, and thus pixels with a pixel value of 0 are rare in the saliency map. If there are many pixels with a pixel value of 0 in the saliency map, there are few objects that attract attention, so the movement of the gaze is small. Since there is little gaze movement, a small number of CovSal saliency clusters is suitable. Specifically, in order to determine the number of clusters through a lot of experiments, we suggest that the number of pixels whose pixel value of the CovSal saliency map is 0 in the data set is divided by the resolution of the image and standardized. In our algorithm, if the number of pixels with a pixel value of 0 in the standardized CovSal saliency map is greater than the average in the Nemoto [
1] data set, the number of clusters divided using the CovSal saliency map is reduced.
Conversely, the remaining three factors are applied so that they increase the number of saliency clustering when their values are large. That the sum of pixel values in the CovSal saliency map is large means that the gaze is not concentrated in one place, and there are several objects that attract the gaze, so gaze is concentrated across multiple areas. Since various objects exist in the image, the number of CovSal saliency clustering must be increased. In addition, in general, the histogram on the CovSal saliency map has a downward sloping shape. This is because there are few areas of the image that attract attention and are mostly backgrounds. Therefore, if there is an upward sloping shape instead of a downward sloping one in the histogram, this means that there are many objects that attract attention, so the number of CovSal saliency clustering should be increased. Finally, when the CovSal saliency map is divided into 10 sections, the last section becomes a section with a pixel value of 231 to 255. The large number of pixels with pixel values in this section means that the gaze is concentrated in several places; therefore, the number of CovSal saliency clustering should be increased. To determine a specific number of CovSal saliency clustering, the three factors are normalized when divided by the resolution and compared to the values in the data set. The number of CovSal saliency clustering increases when the value of the three factors in the image is larger than the average of the values of the three factors in the Nemoto [
1] data set.
Using the four factors described above, CovSal saliency map clusters are divided into from 3 to 7 levels. In the CovSal saliency map, the number of pixels with a pixel value of 0 tends to be larger than that of pixels with a non-zero pixel value. Therefore, in CovSal saliency clustering, except for pixels with a pixel value of 0, the other clusters are adjusted so that the number of pixels in each cluster is similar.
Figure 7 shows an image segmented by using the proposed CovSal saliency clustering method. It is divided into four clusters based on the four factors described above. The number of CovSal saliency clusters, which is the division criterion, is adjusted so that the number of pixels is similar for each divided cluster. Among the four images, the cluster has a higher saliency level from left to right. The leftmost cluster has more pixels than other clusters because saliency includes an area with a pixel value of 0.
4.3. SLIC Superpixel Segmentation
When SLIC [
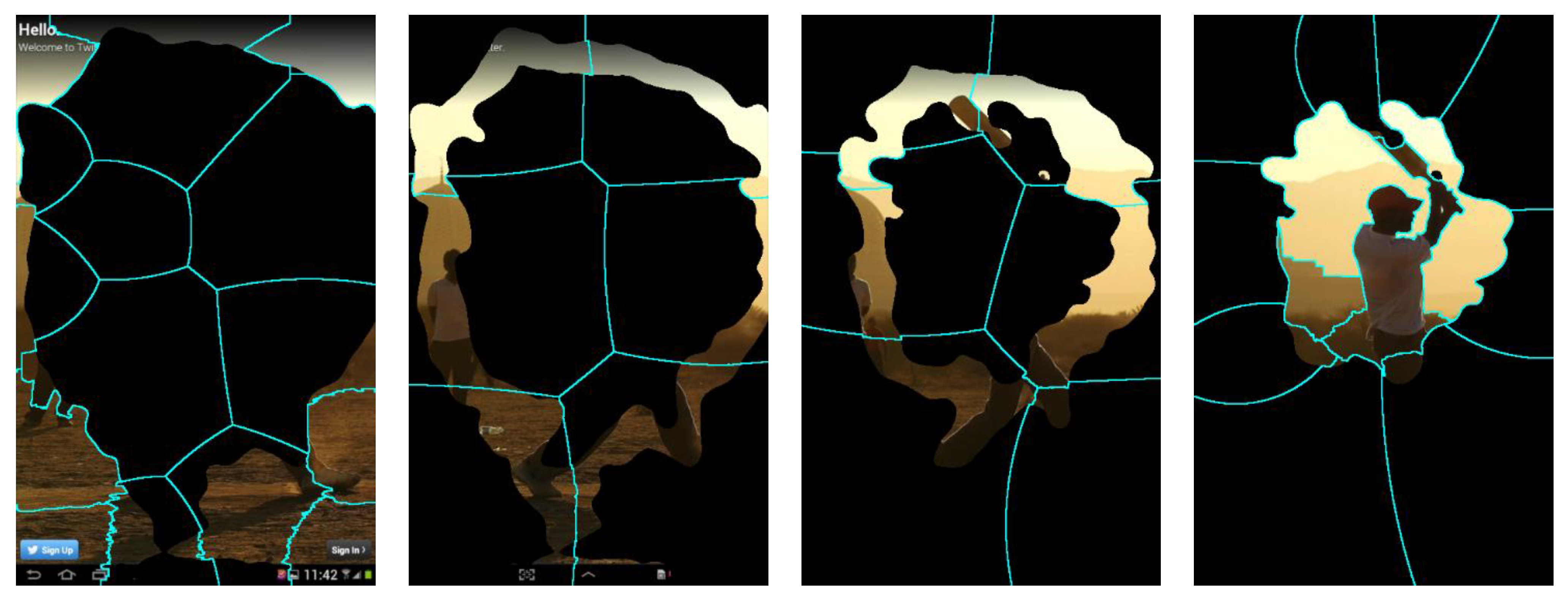
29] is performed in the region divided by CovSal, pixels of the region divided by each CovSal saliency cluster are not excluded from the search process of SLIC. This is because the pixels in the different CovSal saliency cluster are considered to be black pixels (i.e., pixels with a pixel value of 0) in the SLIC algorithm. In addition, the initial search position of the SLIC algorithm is centered on each square after dividing the image into squares by the number of inputs. Therefore, if the search center is a different saliency area, the pixels of the corresponding area may not be clustered. As can be seen from
Figure 8, the original SLIC algorithm cannot be divided according to color in the saliency clusters divided by CovSal. Since the original SLIC superpixel algorithm does not recognize the area divided by CovSal saliency and divides the image based on color, the area divided into other clusters is recognized and divided as an area with a pixel value of 0 as shown in
Figure 8. The first and fourth images are divided to some extent based on color because the image is concentrated at the border or center. However, in the second and third images, the saliency clusters of the pixels are formed in a ring shape, so the result of applying the SLIC superpixel cannot be divided according to the color, which means that each superpixel has different color pixels.
In order to overcome the limitations of the SLIC algorithm [
29] in the CovSal saliency cluster, it is necessary to perform segmentation by separating pixels in each cluster from pixels with 0 values during the segmentation process. In addition, the initial search location should be set within the divided area through CovSal saliency clustering rather than in the entire image as is done by SLIC.
Table 1 is a CovSal clustering compression algorithm that removes regions without color values in the middle because they have different saliency levels. After finding the row and column with color data in each CovSal saliency cluster (lines 1–3), this algorithm finds the width of the row of the region with color values in the cluster and set it as the width of a compressed image which will be created. For each row of the region with color values, the number of columns of the region with color values is calculated and the maximum number of columns is set as the height of a compress image (lines 4–6). Since the number of columns of the region with color values is different for each row, it places the color value in the middle (lines 7–9) and fills the rest with 0 to create a compressed image of the CovSal saliency cluster, as shown in
Figure 9.
Each image in
Figure 9 is the result when the algorithm in
Table 1 is applied to each one in
Figure 7. Previously,
Figure 8 shows that the original SLIC superpixel algorithm tries to segment according to color, but it fails to consider color in each CovSal saliency cluster. To overcome such problem,
Figure 9 shows the result of correcting the image by applying the algorithm in
Table 1 to improve the segmentation performance of the original SLIC superpixel algorithm. As a result of the correction, the image was divided into different regions, connecting the upper and lower pixels to the pixel with a pixel value of 0, forming an image as if it was pressed from the top. The fourth image is similar to that of
Figure 7 because there are few areas divided into other areas in the middle of the image, but the other images have big differences from those of
Figure 7.
Table 2 shows an algorithm for adjusting the initial search position in the process of segmenting an image using superpixels in a compressed CovSal cluster. First, with the CovSal cluster compression algorithm, the compressed image from which the pixels with different saliency levels are removed is divided into a 50 × 50 pixel square (lines 1–2). Based on the center of the square, the algorithm checks whether the area in the compressed image has no color value and sets the center as that of the search position (lines 3–9). From a low power point of view, pixels with zero brightness in the image are excluded from the superpixel search process because they do not consume power.
Figure 10 shows the result of segmenting an image, according to saliency and color, using both the cluster compression algorithm applied to the clusters divided by CovSal and the initial position search algorithm for superpixels in each CovSal cluster. Unlike the existing SLIC superpixel algorithm [
29], it can be seen that the image is divided according to color in the same cluster area divided by CovSal saliency.
Figure 10 shows the result of dividing the image according to color using the proposed superpixel algorithm for clusters separated by the CovSal saliency model. Compared with
Figure 8, it can be seen that the segmentation performance according to color is improved. In particular, it can be seen that each cluster is well divided based on color compared to
Figure 8 in the cluster areas divided according to the CovSal saliency model in the latter three images, which are divided into different areas and have a lot of pixels with the value 0. Now, it is possible to implement a low power technique in which applies different low power policies according to different colors within each cluster region while its saliency is maintained.
4.4. Low Power Image Generation
After dividing the image into CovSal saliency areas and then segmenting each saliency area into multiple superpixels based on color, different low power policies are implemented for each superpixel according to the saliency level, brightness, and average values of R, G, and B. For fair comparison with CURA [
9], the image distortion degree by the low power technique is evaluated by the SSIM [
30] index in the same way as CURA. Using multiple grayscale images, the SSIM indices are calculated to make up lookup tables according to the degree of pixel value change while their brightness changes. The lookup table is used to calculate a low power constant for gamma correction, which corresponds to the desired SSIM index. Since an image has different power consumption depending on the R, G, and B channel values, a low power constant is calculated in consideration of this. Especially, human vision is sensitive to changes in bright areas, and sensitivity decreases in a log scale as brightness decreases [
31]. Therefore, the minimum and maximum SSIM values are set for the degree of distortion according to the number of saliency clusters and a required SSIM value is calculated in a log scale according to the saliency level. For R, G, and B channels, each required SSIM value are calculated in the same way and then each low power constant is calculated using the overall SSIM value and SSIM value per channel by reflecting the ratio of brightness of each channel over luminance.
6. Conclusions
In this paper, we proposed a new segmentation-based saliency-aware low power approach by dividing images into saliencies using the CovSal saliency model and then dividing each saliency into superpixels using the SLIC superpixel algorithm. Through experiments, the proposed method shows bigger FSIMc indices and higher power saving rates than the global dimming and saliency-aware methods. Compared to CURA, the proposed method considers the image quality better by applying a technique that minimizes the distortion of the image quality and color change within the saliency areas. As a result, the proposed method shows better image quality, higher power saving rates, and no artifacts unlike CURA.
As future work, we plan to implement the proposed method in HMDs and tackle performance improvement in the aspect of a system. Especially, we will focus on improving the performance of SLIC superpixels. Also, we will consider using instance segmentation techniques such as YOLACT [
33].


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}