BugMiner: Mining the Hard-to-Reach Software Vulnerabilities through the Target-Oriented Hybrid Fuzzer



Abstract
:1. Introduction
- This research presents a novel target-oriented hybrid fuzzing tool named BugMiner, which combines greybox fuzzing and concolic execution engine. It solves the constraints to execute the uncovered complex nested branches and generates more effective test-inputs to dive deep into the program.
- A set of novel methods is proposed to increase the efficiency of the bug hunting approach and decrease the time-consuming preprocessing. More specifically, we implemented a Bug Report Analyzer built on a Machine Learning tool named NLP. The bug report analyzer identifies vulnerable functions and extracts them from bug reports, then builds a specified target database that can be used in further steps. In addition, BugMiner provides three test-case pools (T-Pool) that create an opportunity to add newly generated inputs into different categories based on the priority.
- To enhance target-oriented hybrid fuzzing and overcome the Path Explosion problem of CE, we designed BugMiner with a BranchPruner module that gathers a set of branch addresses not related to the specified target. This allows BugMiner to trigger the hard-to-reach bug without excessive effort. We also significantly reduced the budget for bug hunting time than the existing approaches.
- We validated the effectiveness of BugMiner by carrying out several experiments with different datasets, including LAVA-M, Binutils, LibPNG, OpenSSL, and real-world programs. We compared the capability of BugMiner against the popular software testing tools, such as AFL, AFLFast, AFLGo, Hawkeye, QSYM, and ParmeSan. Comprehensive experiment results demonstrate that the proposed implementation can trigger hard-to-reach bugs faster than baseline tools and scale to several real-world programs. Furthermore, we provide dataset statistics for the comfort of readers.
2. Background
3. Motivation
| Listing 1. Motivation example. |
 |
4. Proposed Methodology
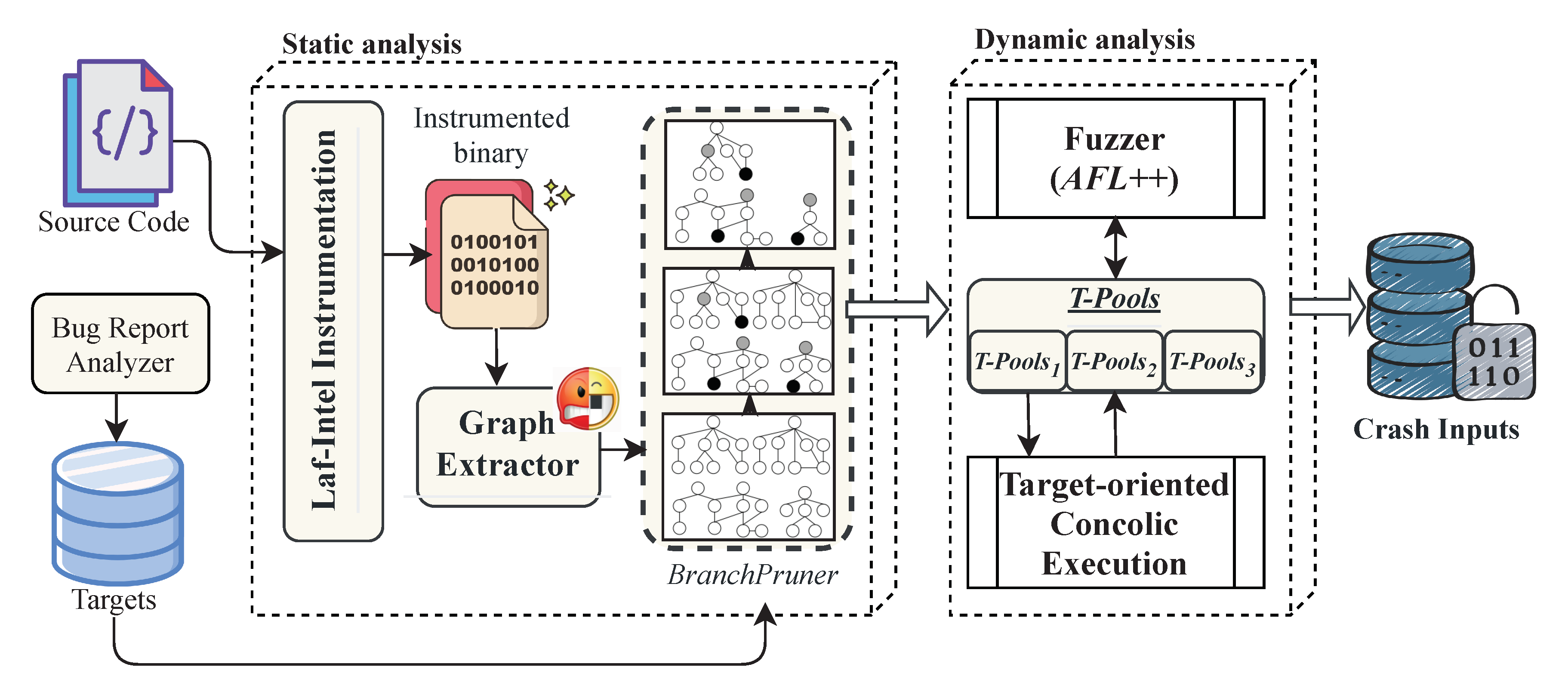
4.1. BugMiner Overview
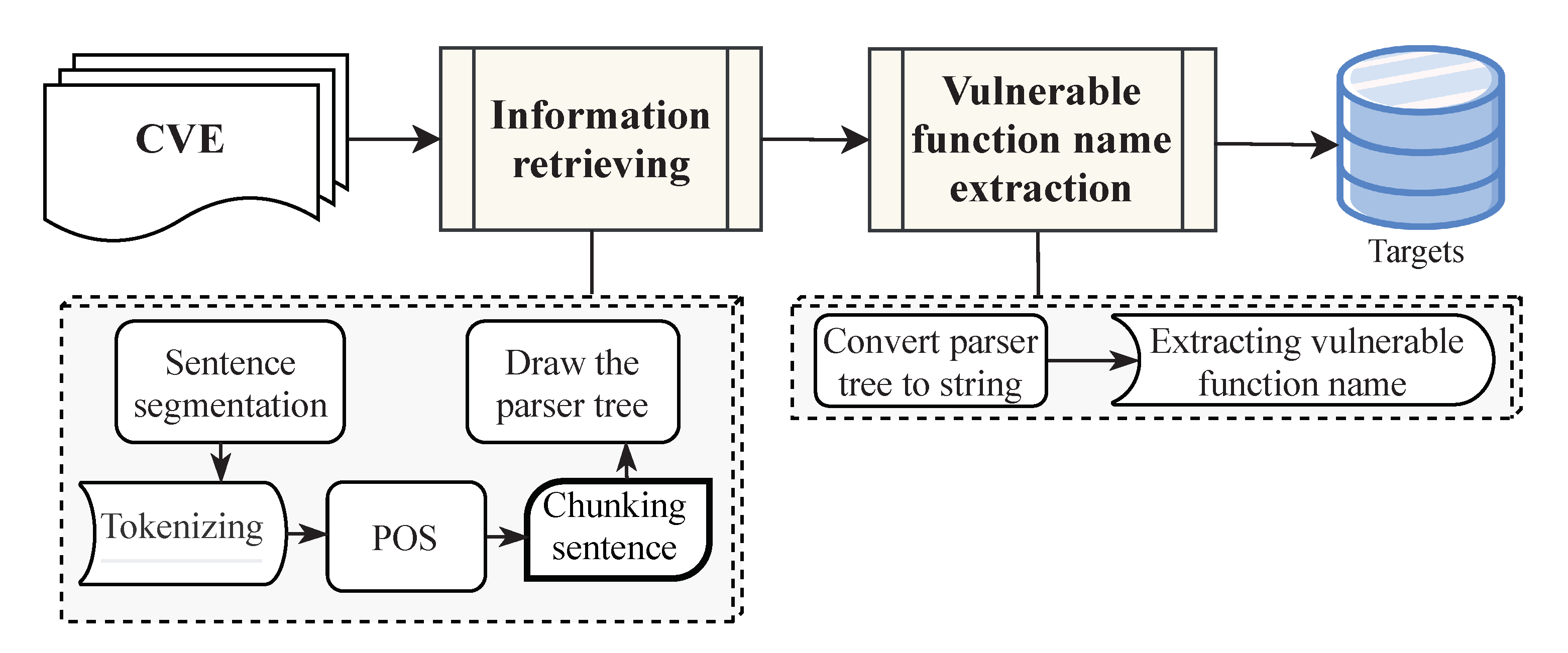
4.2. Bug Report Analyzer
- The AAA function in BBB file (other words) causes CCC (result) via a crafted EEE (method).
- FFF (reason) in the AAA function in BBB component (other words) could cause CCC (result).
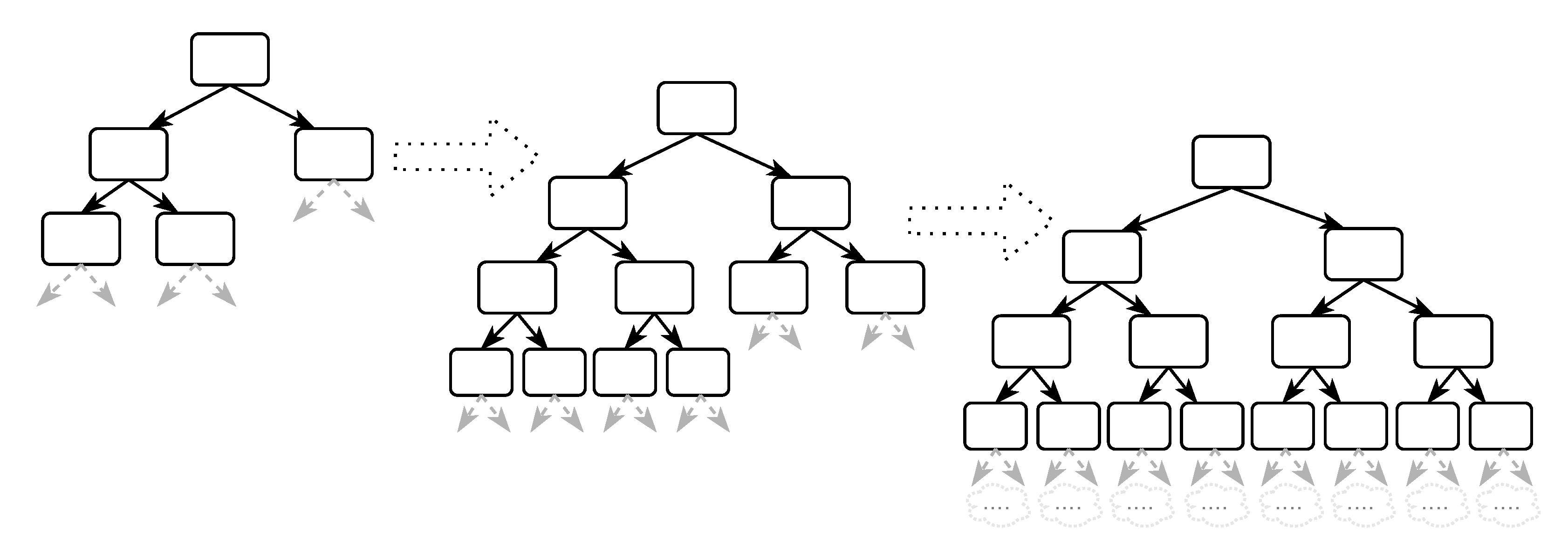
4.3. Static Analysis
4.4. Dynamic Analysis
| Algorithm 1 Branch pruning |
INPUT: PUT (Target Program Binary) & CFG (Control Flow Graph) INPUT: Specified Target Function () 1: ←ø 2: ←Load(PUT) 3: ←.findSymbol(’main’).addr 4: Graph ← Load(CFG) 5: AllBranchAddr ← ExtractAllBranchAddr(Graph) 6: Dis ←get.Disassemble() 7: ←Dis.getBranchAddress() 8: ShortestPathList ←Graph.getShortestPaths(, ) 9: foreach BB ∈ AllBranchAddr do { 10: if BB ∉ ShortestPathList do { 11: ←∪ BB 12: } else { 13: Continue 14: } 15: } OUTPUT: Branch Pruning Addresses (); OUTPUT: Specified Target Branch (); OUTPUT: Entry Point of the PUT (); |
| Algorithm 2 Greybox fuzzing and seed prioritization |
INPUT: PUT (Instrumented program) INPUT: I (Initial Input) 1: ←ø 2: T- & T-←ø 3: while TimeoutNotExhausted do { 4: ← SelectInput (I) 5: E ←AssignEnergy () 6: for i ← 0 to E do { 7: ← mutateInput () 8: if crashes PUT {
9: ← ∪ 10: } else if InputWithNewCoverage () == True { 11: T-←T- ∪ 12: } else { 13: T-←T- ∪ 14: } 15: } 16: } OUTPUT: Bug-triggering crash inputs ; OUTPUT: Newly generated test-inputs T- & T-; |
| Algorithm 3 Target-oriented concolic execution |
INPUT: PUT (Target Program) & (Test Input) INPUT: (BranchPruningAddresses) & ( SpecifiedTargetBranch) INPUT: ( EntryPoint of the PUT) 1: T- (NewTestInputs) ←ø 2: p ← PUT.execute () 3: state ← p.entry () 4: for state to do { 5: node ← getAdress (state) 6: if node ∉ do { 7: while node IsNotReachTo do { 8: Constraint ← p.take (node).getNeighbour() 9: NewTestInput ← solve(Constraint) 10: T-←T- ∪ NewTestInput 11: } 12: } 13: } OUTPUT: Generate new target-oriented test-inputs T- (NewTestInputs); |
5. Implementation
6. Performance Evaluation
6.1. Evaluation Setup
- Is it beneficial to employ bug report analyzer and branch pruner components in our approach?
- Do our suggested methods increase the software bug hunting process successfully?
- How does our suggested dynamic strategy affect BugMiner’s performance?
- What is the role of BugMiner in achieving the deeply hidden target sites?
- Lava-M dataset [24] is seen as an effective experimental vulnerable programs dataset to detect hard-to-reach bugs in the PUT. To evaluate the bug hunting tools, most of the software security researchers utilize this dataset.
- LibPNG [26] is the official PNG reference library. It employs almost all PNG features, which have been widely used for over 23 years to evaluate software testing tools.
- OpenSSL [27] is a library for programs that provide communication security over computer networks as opposed to eavesdropping.
- Eight popular real-world applications can assist in evaluating the software bug detecting tools.
- AFL [9] is a commonly utilized state-of-the-art fuzzer.
- AFLFast [10] is an efficient greybox fuzzing tool that has optimized AFL with a new proposed power schedule algorithm.
- AFLGo [11] is modern, efficient DGF tool that relies on AFL. In comparison with AFL, it provides information about node distance.
- Hawkeye [17] is also a DGF tool that instruments the program to measure the distance of a certain test input to the target sites. Moreover, Hawkeye advances AFLGo by adding an indirect function call that facilitates the distance calculation of AFLGo.
- QSYM [28] is a current efficient undirected hybrid fuzzing tool that uses the CE to customize unnecessary computations in symbolic interpretations and improve the efficiency of constraint emulation.
- ParmeSan [29] refers to a “Sanitizer-Guided Greybox Fuzzing” (SGGF) tool which applies tripwire sanitization to direct the fuzzer and reveal violations earlier.
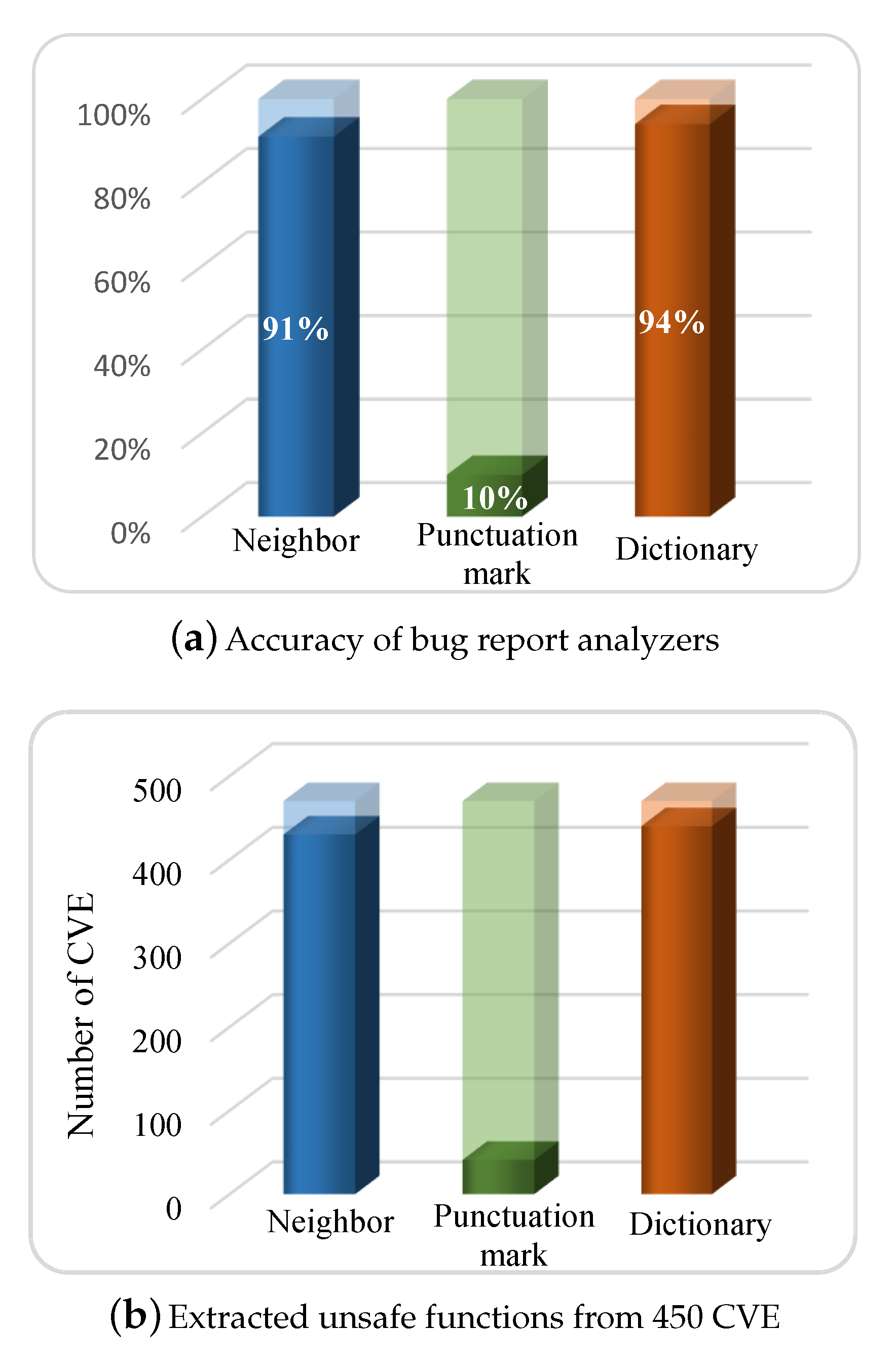
6.2. Bug Report Analyzing
6.3. Bug Reproduction
6.4. BugMiner vs. Directed Fuzzers
6.5. Vulnerabilities Exposure
6.6. Replies to Research Questions
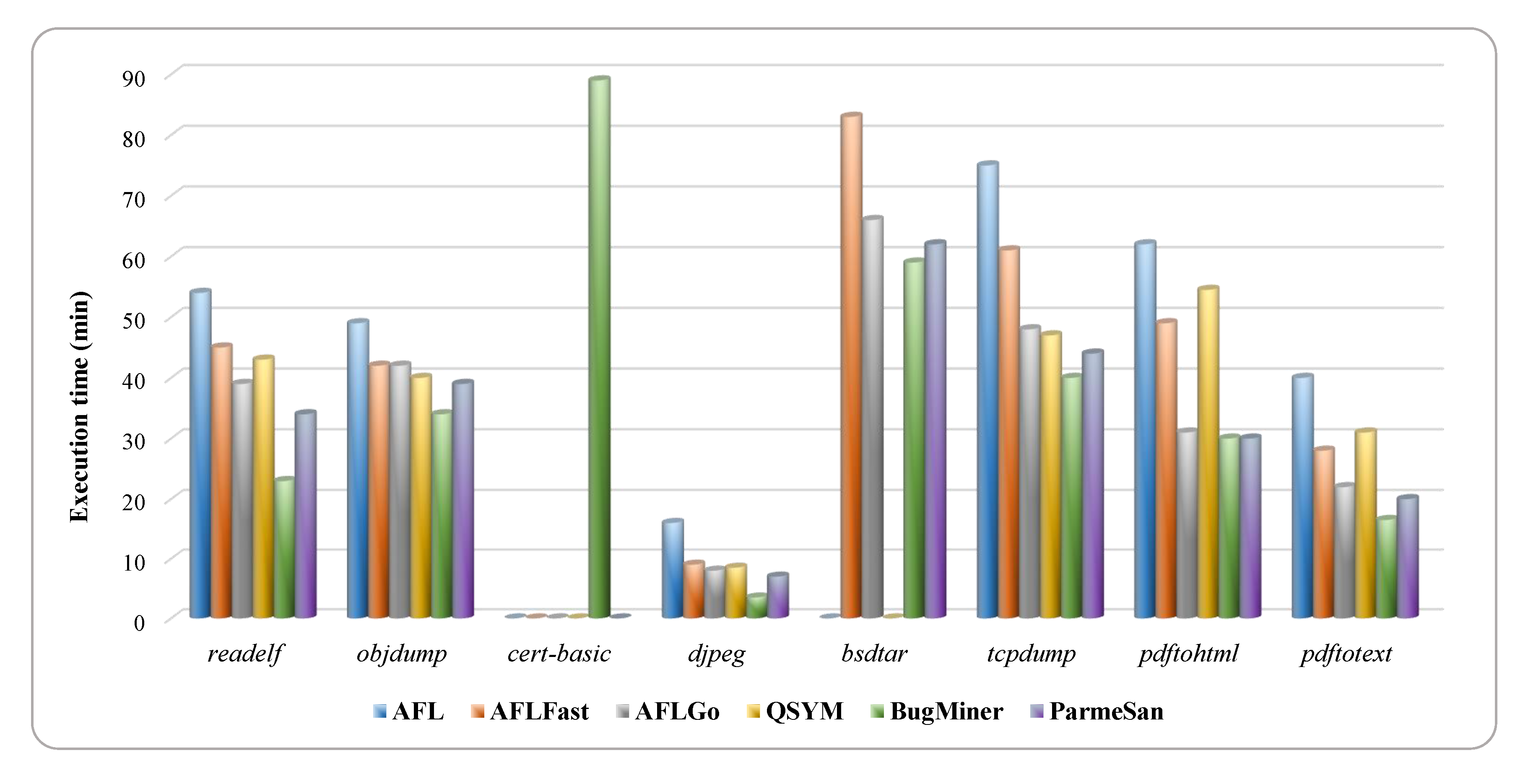
- We believe that Bug Report Analyzer and BranchPruner methods are worth applying. As we can see in Table 5, the BranchPruner method is a better option considering the time cost while fuzzing. To be more precise, AFLGo, ParmeSan, and BugMiner spent an average of 28.6 min, 17.2 min, and 9.4 min, respectively, for preprocessing analysis. The proposed ShortestPathFinder reduces preprocessing time. Instead of making a specified target database manually, retrieving vulnerable functions from the bug reports automatically by utilizing the machine learning technology not only improves the performance of directed testing but also reduces preprocessing time.
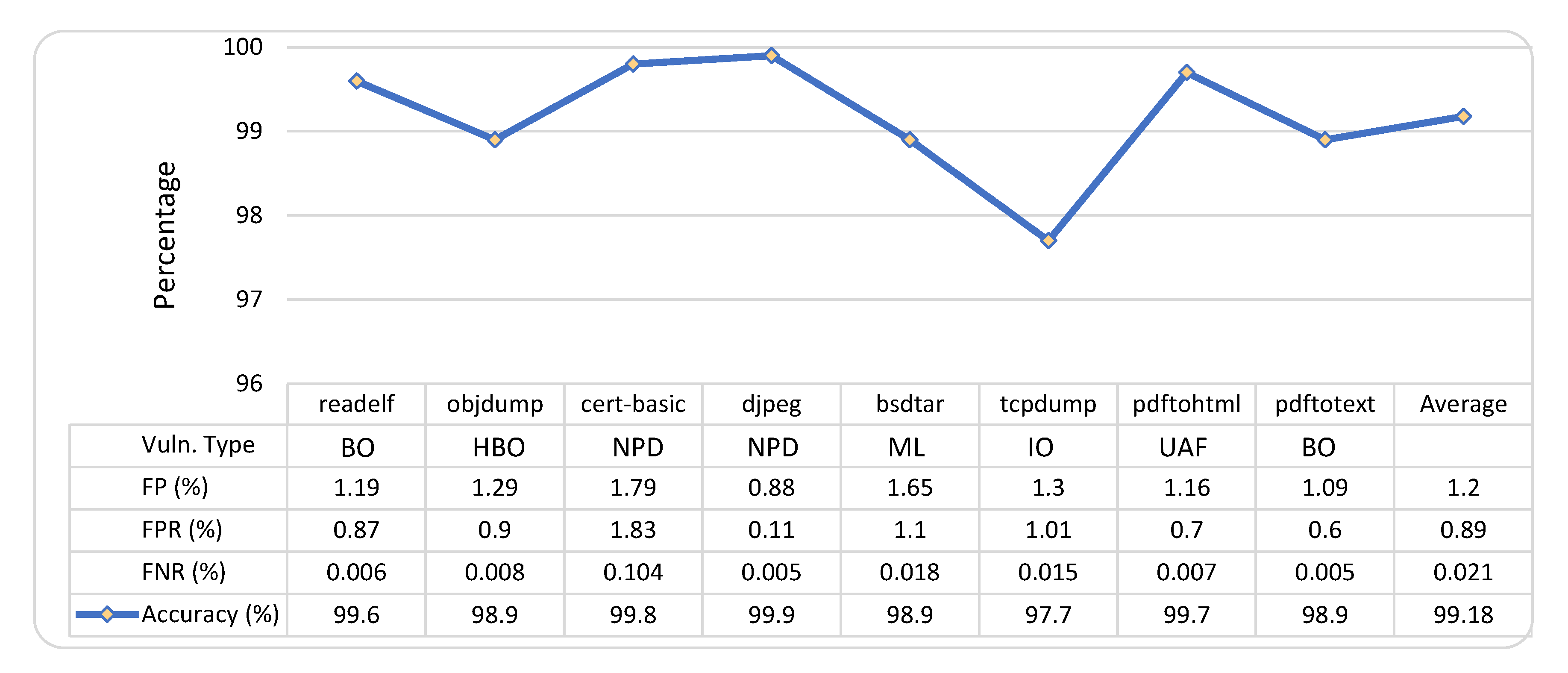
- The dynamic analysis methods utilized in BugMiner are highly effective. It is proven that BugMiner outperforms other fuzzing tools in all experiments we conducted. In particular, the experiment involving comparisons with the DGFs. Table 5 and Figure 5 indicate that the combination of fuzzing, TOCE, and input prioritization methods increase BugMiner’s speed, which gives an advantage over DGFs, hybrid fuzzer, and greybox fuzzers. In addition, BugMiner achieved 99.18% accuracy on average.
- Based on the results in Figure 5, we believe that BugMiner affords an opportunity to achieve specified targets rapidly. In addition, our implementation is scalable and can analyze both coreutil programs and real-world programs.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CE | Concolic Execution |
| SE | Symbolic Execution |
| PUT | Program Under Test |
| DGF | Directed Grey-box Fuzzing |
| CVE | Common Vulnerabilities and Exposures |
| NLP | Natural Language Processing |
| TOHF | Target-Oriented Hybrid Fuzzer |
| TOCE | Target-Oriented Concolic Execution |
| DFA | Data-Flow Analysis |
| UAF | User-After-Free |
| CFG | Control Flow Graph |
| TTE | Time-To-Exposure |
| SGGF | Sanitizer-Guided Greybox Fuzzing |
| BO | Buffer Overflow |
| HBO | Heap Buffer Overflow |
| NPD | NULL Pointer Dereference |
| ML | Memory Leak |
| IO | Integer Overflow |
| FPR | False Positive Rate |
| FNR | False Negative Rate |
References
- Eoin, K. 2019 Vulnerability Statistics Report. Available online: https://www.edgescan.com/wp-content/uploads/2019/02/edgescan-Vulnerability-Stats-Report-2019.pdf (accessed on 29 April 2020).
- Shirey, R. Internet Security Glossary. Available online: https://tools.ietf.org/html/rfc2828 (accessed on 29 April 2020).
- Takanen, A.; DeMott, J.; Miller, C.; Kettunen, A. Fuzzing for Security Testing and Quality Assurance, 2nd ed.; Artech House: London, UK, 2018; pp. 1–2. ISBN 9781608078509. [Google Scholar]
- Valentin, J.; HyungSeok, H.; Choongwoo, H.; Sang, K.C.; Manuel, E.; Edward, J.S.; Maverick, W. The art, science, and engineering of fuzzing: A survey. IEEE Trans. Softw. Eng. 2019. [Google Scholar] [CrossRef] [Green Version]
- Microsoft. Project Springfield. Available online: https://www.microsoft.com/en-us/security-risk-detection/ (accessed on 30 April 2020).
- OSS-Fuzz: Continuous Fuzzing Framework for Open-Source Projects. Available online: https://github.com/google/oss-fuzz/ (accessed on 30 April 2020).
- Crawford, J.B. A Survey of Some Free Fuzzing Tools. Available online: https://lwn.net/Articles/744269/ (accessed on 1 May 2020).
- Chen, C.; Baojiang, C.; Jinxin, M.; Runpu, W.; Jianchao, G.; Wenqian, L. A systematic review of fuzzing techniques. Comput. Secur. 2018, 75, 118–137. [Google Scholar] [CrossRef]
- Zalewski, M. American Fuzzy Lop (AFL), README. Available online: http://icamtuf.coredump.cx/afl/ (accessed on 2 May 2020).
- Böhme, M.; Pham, V.T.; Roychoudhury, A. Coverage-based Greybox Fuzzing as Markov Chain. In Proceedings of the 23rd ACM Conference on Computer and Communications Security (CCS), Vienna, Austria, 24–28 October 2016. [Google Scholar]
- Böhme, M.; Pham, V.T.; Manh-Dung, N.; Roychoudhury, A. Directed Greybox Fuzzing (CCS ’17). In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 30 October–3 November 2017; pp. 2329–2344. [Google Scholar]
- Chen, P.; Chen, H. Angora: Efficient fuzzing by principled search. In Proceedings of the IEEE Symposium on Security and Privacy 39th IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 711–725. [Google Scholar]
- Shuitao, G.; Chao, Z.; Xiaojun, Q.; Xuwen, T.; Kang, L.; Zhongyu, P.; Zuoning, C. CollAFL: Path Sensitive Fuzzing. In Proceedings of the 39th IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 1–12. [Google Scholar]
- Ganesh, V.; Leek, T.; Rinard, M.C. Taint-based directed whitebox fuzzing. In Proceedings of the 31st International Conference on Software Engineering, ICSE, Washington, DC, USA, 16–24 May 2009; pp. 474–484. [Google Scholar]
- Wang, T.; Wei, T.; Gu, G.; Zou, W. TaintScope: A checksum-aware directed fuzzing tool for automatic software vulnerability detection. In Proceedings of the IEEE Symposium on Security and Privacy, Berkeley/Oakland, CA, USA, 16–19 May 2010. [Google Scholar]
- Vuagnoux, M. Autodafe: An act of software torture. In Proceedings of the 22nd Chaos Communications Congress, Berlin, Germany, 27–30 December 2005; pp. 47–58. [Google Scholar]
- Hongxu, C.; Yinxing, X.; Yuekang, L.; Bihuan, C.; Xiaofei, X.; Xiuheng, W.; Yang, L. Hawkeye: Towards a desired directed grey-box fuzzer. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 2095–2108. [Google Scholar]
- Wei, J.; Alessandro, O. Bugredux: Reproducing field failures for in-house debugging. In Proceedings of the 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, 2–9 June 2012. [Google Scholar]
- Andrew, F.; Tim, L.; Brendan, D.G.; Josh, B. The rode0day to less-buggy programs. IEEE Secur. Privacy 2019, 17, 84–88. [Google Scholar]
- Paul, D.M.; Cristian, C. Katch: High-coverage testing of software patches. In Proceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering, Saint Petersburg, Russia, 18–26 August 2013. [Google Scholar]
- Jiaqi, P.; Feng, L.; Bingchang, L.; Lili, X.; Binghong, L.; Kai, C.; Wei, H. 1dvul: Discovering 1-day vulnerabilities through binary patches. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Portland, OR, USA, 24–27 June 2019. [Google Scholar]
- What Is CVE, Its Definition and Purpose? Available online: https://www.csoonline.com/article/3204884/what-is-cve-its-definition-and-purpose.html (accessed on 21 May 2020).
- Hardeniya, N.; Perkins, J.; Chopra, D. Natural Language Processing: Python and NLTK; Packt Publishing Ltd.: Birmingham, UK, 2016; pp. 96–178. [Google Scholar]
- Dolan-Gavitt, B.; Hulin, P.; Kirda, E.; Leek, T.; Mambretti, A.; Robertson, W.; Ulrich, F.; Whelan, R. Lava: Large-scale automated vulnerability addition. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), IEEE, San Jose, CA, USA, 22–26 May 2016; pp. 110–121. [Google Scholar]
- Binutils Source Code. Available online: https://ftp.gnu.org/gnu/binutils/ (accessed on 23 March 2020).
- LibPNG—A Library for Processing PNG Files. Available online: http://www.libpng.org/pub/png/libpng.html (accessed on 29 April 2020).
- OpenSSL-Cryptography and SSL/TLS Toolkit. Available online: https://ftp.openssl.org/source/old/1.0.1/ (accessed on 20 April 2020).
- Yun, I.; Lee, S.; Xu, M.; Jang, Y.; Kim, T. QSYM: A practical concolic execution engine tailored for hybrid fuzzing. In Proceedings of the 27th USENIX Conference on Security Symposium, USENIX Association, Baltimore, MD, USA, 15–17 August 2018; pp. 745–761. [Google Scholar]
- Osterlund, S.; Razavi, K.; Bos, H.; Giuffrida, C. ParmeSan: Sanitizer-guided Greybox Fuzzing. In Proceedings of the 29th USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020. [Google Scholar]
- Cadar, C.; Dunbar, D.; Engler, D. KLEE: Unassisted and automatic generation of high-coverage tests for complex systems programs. In Proceedings of the 8th USENIX Symposium on Operating Systems Design and Implementation, USENIX Association, Berkeley, CA, USA, 8–10 December 2008; pp. 209–224. [Google Scholar]
- Godefroid, P.; Levin, M.Y.; Molnar, D.A. Automated whitebox fuzz testing. In Proceedings of the Network and Distributed System Security Symposium (NDSS), Reston, VA, USA, 10–13 February 2008. [Google Scholar]
- Phil, M. Search-based software test data generation: A survey: Research articles. Softw. Test. Verif. Reliab. 2004, 14, 105–156. [Google Scholar]
- Rawat, S.; Jain, V.; Kumar, A.; Cojocar, L.; Giuffrida, C.; Bos, H. VUzzer: Application-aware evolutionary fuzzing. In Proceedings of the 2017 Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 26 Febuary–1 March 2017. [Google Scholar]
- Chen, Y.; Li, P.; Xu, J.; Guo, S.; Zhou, R.; Zhang, Y.; Wei, T.; Lu, L. Savior: Towards bug-driven hybrid testing. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), Los Alamitos, CA, USA, 18–21 May 2020. [Google Scholar]
- Rustamov, F.; Kim, J.; Yun, J. DeepDiver: Diving into abysmal depth of the binary for hunting deeply hidden software vulnerabilities. Future Internet 2020, 12, 74. [Google Scholar] [CrossRef] [Green Version]
- Stephens, N.; Grosen, J.; Salls, C.; Dutcher, A.; Wang, R.; Corbetta, J.; Shoshitaishvili, Y.; Kruegel, C.; Vigna, G. Driller: Augmenting Fuzzing Through Selective Symbolic Execution. In Proceedings of the NDSS, San Diego, CA, USA, 21–24 February 2016. [Google Scholar]
- Zhao, L.; Duan, Y.; Yin, H.; Xuan, J. Send hardest problems my way: Probabilistic path prioritization for hybrid fuzzing. In Proceedings of the NDSS, San Diego, CA, USA, 24–27 February 2019. [Google Scholar]
- Maria, C.; Peter, M.; Valentin, W. Guiding dynamic symbolic execution toward unverified program executions. In Proceedings of the 38th International Conference on Software Engineering (ICSE), Austin, TX, USA, 14–22 May 2016; pp. 144–155. [Google Scholar]
- Do, T.; Fong, A.; Pears, R. Dynamic Symbolic Execution Guided by Data Dependency Analysis for High Structural Coverage. In Proceedings of the Evaluation of Novel Approaches to Software Engineering—7th International Conference (ENASE), Warsaw, Poland, 29–30 June 2012; pp. 3–15. [Google Scholar]
- Ge, X.; Taneja, K.; Xie, T.; Tillmann, N. DyTa: Dynamic symbolic execution guided with static verification results. In Proceedings of the 33rd International Conference on Software Engineering (ICSE), Waikiki, HI, USA, 21–28 May 2011; pp. 992–994. [Google Scholar]
- McMinn, P.; Holcombe, M. Evolutionary Testing Using an Extended Chaining Approach. Evol. Comput. 2006, 14, 41–64. [Google Scholar] [CrossRef] [PubMed]
- Dinges, P.; Agha, G. Targeted Test Input Generation Using Symbolic-concrete Backward Execution. In Proceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering, ASE ’14, New York, NY, USA, 15–19 September 2014; pp. 31–36. [Google Scholar]
- Bohme, M.; Paul, S. A Probabilistic Analysis of the Efficiency of Automated Software Testing. IEEE Trans. Softw. Eng. 2016, 42, 345–360. [Google Scholar] [CrossRef]
- Liang, H.; Zhang, Y.; Yu, Y.; Xie, Z.; Jiang, L. Sequence coverage directed greybox fuzzing. In Proceedings of the 27th International Conference on Program Comprehension, ICPC 2019, Montreal, QC, Canada, 25–31 May 2019; pp. 249–259. [Google Scholar]
- Zong, P.; Lv, T.; Wang, D.; Deng, Z.; Liang, R.; Chen, K. FuzzGuard: Filtering out Unreachable Inputs in Directed Grey-box Fuzzing through Deep Learning. In Proceedings of the 29th USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020. [Google Scholar]
- Serebryany, K.; Bruening, D.; Potapenko, A.; Vyukov, D. Addresssanitizer: A fast address sanity checker. In Proceedings of the USENIX Annual Technical Conference, Boston, MA, USA, 13–15 June 2012. [Google Scholar]
- CVE-2018-11237. Available online: https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-11237 (accessed on 30 May 2020).
- Rustamov, F.; Choi, M.; Yun, J. Search-based Concolic Execution for SW Vulnerability Discovery. IEICE Trans. Inf. Syst. 2018, 101, 2526–2529. [Google Scholar]
- Yan, S.; Ruoyu, W.; Christopher, S.; Nick, S.; Mario, P.; Andrew, D.; John, G.; Siji, F.; Christopher, H.; Christopher, K.; et al. (State of) The Art of War: Offensive Techniques in Binary Analysis. In Proceedings of the IEEE Symposium on Security and Privacy, San Jose, CA, USA, 23–25 May 2016. [Google Scholar]
- Deng, Y.; Chen, Y.; Zhang, Y.; Mahadevan, S. Fuzzy Dijkstra algorithm for shortest path problem under uncertain environment. Appl. Soft Comput. 2012, 12, 1231–1237. [Google Scholar] [CrossRef]
- Darpa Cyber Grand Challenge. Available online: http://archive.darpa.mil/cybergrandchallenge/ (accessed on 30 May 2020).
- Fioraldi, A.; Maier, D.; Eißfeldt, H.; Heuse, M. AFL++: Combining incremental steps of fuzzing research. In Proceedings of the 14th USENIX Workshop on Offensive Technologies (WOOT 20), USENIX Security ’20, Boston, MA, USA, 11 August 2020. [Google Scholar]
- LibFuzzer—A Library for Coverage-Guided Fuzz Testing. Available online: https://llvm.org/docs/LibFuzzer.html (accessed on 30 April 2020).
- American Fuzzy Lop Plus Plus (afl++). Available online: https://github.com/AFLplusplus/AFLplusplus (accessed on 30 March 2020).
- Cadar, C.; Sen, K. Symbolic execution for software testing: Three decades later. Commun. ACM 2013, 56, 82–90. [Google Scholar] [CrossRef]
- Libksba Source Code. Available online: https://fossies.org/linux/privat/libksba-1.3.5.tar.gz/ (accessed on 29 April 2020).
- Libjpeg Source Code. Available online: https://www.ijg.org/files (accessed on 20 April 2020).
- Libarchive Source Code. Available online: https://libarchive.org/downloads/ (accessed on 20 April 2020).
- Tcpdump Source Code. Available online: http://www.tcpdump.org/release/ (accessed on 21 April 2020).
- Poppler Source Code. Available online: https://poppler.freedesktop.org/releases.html (accessed on 19 April 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Vulnerability | Unsafe Function Name |
|---|---|
| Format string | dprintf, vasprintf, vsnprintf, asprintf, vdprintf, snprintf, fprintf, printf, sprintf, vfprintf, vprintf, vsprintf, syslog, vsyslog |
| Buffer overflow | strcpy, stpcpy, strecpy, strcat, streadd, sprint, vprintf, gets, fscanf, vsscanf, vfscanf, realpath, wcscpy, wcpcpy, memcpy, getwd |
| Multiple command injection | popen, fexecve, execle, execvp, execvpe, system, execve, execv, execl, execlp |
| DOS overflow | memmove, glob, getaddrinfo, getbyname, gethostbyname, getifaddrs |
| Program | T/Bugs | Edges | Nodes | Instructions | Test Options |
|---|---|---|---|---|---|
| md5sum | 57 | 1560 | 1013 | 7397 | -c |
| uniq | 28 | 1407 | 890 | 5285 | |
| who | 2136 | 3332 | 1831 | 84,648 | |
| base64 | 44 | 1308 | 822 | - | -d |
| Program | TTE (min) | |||||||
|---|---|---|---|---|---|---|---|---|
| AFL | BugMiner | AFLFast | QSYM | |||||
| Bug 1 | Bug 2 | Bug 1 | Bug 2 | Bug 1 | Bug 2 | Bug 1 | Bug 2 | |
| md5sum | 14.25 | 13.51 | 10.49 | 09.53 | 15.07 | 13.59 | 14.08 | 12.56 |
| uniq | 29.32 | 31.09 | 18.35 | 20.41 | 29.09 | 30.56 | 28.45 | 30.01 |
| who | 67.32 | 52.32 | 51.30 | 47.53 | 59.28 | 51.39 | 50.12 | 46.23 |
| base64 | 33.45 | 34.02 | 20.45 | 18.03 | 30.36 | 32.14 | 28.23 | 21.54 |
| Program | CVE-ID | Type of Vulnerability |
|---|---|---|
| OpenSSL | CVE-2014-0160 | Buffer Overflow |
| LibPNG | CVE-2011-2501 | Buffer Overflow |
| LibPNG | CVE-2011-3328 | Division by Zero |
| LibPNG | CVE-2015-8540 | Buffer Overflow |
| Binutils | CVE-2016-4487 | Invalid Write |
| Binutils | CVE-2016-4488 | Invalid Write |
| Binutils | CVE-2016-4489 | Invalid Write |
| Binutils | CVE-2016-4491 | Stack Corruption |
| Binutils | CVE-2016-4492 | Write Access Violation |
| Binutils | CVE-2016-4493 | Write Access Violation |
| CVE ID | Fuzzer | Runs | TTE (min) | Pre-Process (min) |
|---|---|---|---|---|
| OpenSSL | ||||
| 2014–0160 | AFLGo | 20 | 20.54 | 31.24 |
| Hawkeye | - | - | - | |
| ParmeSan | 25 | 5.35 | 16.21 | |
| BugMiner | 20 | 3.25 | 6.09 | |
| LibPNG | ||||
| 2011–2501 | AFLGo | 20 | 6.32 | 26.21 |
| Hawkeye | - | - | - | |
| ParmeSan | 20 | 6.02 | 18.54 | |
| BugMiner | 20 | 4.29 | 9.01 | |
| 2011–3328 | AFLGo | 20 | 42.01 | 29.39 |
| Hawkeye | - | - | - | |
| ParmeSan | 20 | 31.56 | 22.45 | |
| BugMiner | 20 | 28.59 | 12.47 | |
| 2011–8540 | AFLGo | 20 | 2.01 | 15.08 |
| Hawkeye | - | - | ||
| ParmeSan | 20 | 4.51 | 11.57 | |
| BugMiner | 20 | 3.12 | 4.23 | |
| CVE ID | Fuzzer | Runs | TTE (min) | Pre-Process (min) |
| Binutils | ||||
| 2016–4487 2016–4488 | AFLGo | 20 | 6.09 | 27.45 |
| Hawkeye | 20 | 2.57 | - | |
| ParmeSan | 20 | 1.05 | 21.35 | |
| BugMiner | 20 | 1.06 | 14.02 | |
| 2016–4489 | AFLGo | 20 | 3.02 | 19.27 |
| Hawkeye | 20 | 3.26 | - | |
| ParmeSan | 20 | 1.08 | 12.56 | |
| BugMiner | 20 | 1.09 | 3.59 | |
| 2016–4491 | AFLGo | 5 | 385 | 59.54 |
| Hawkeye | 9 | 312 | - | |
| ParmeSan | 10 | 71 | 25.21 | |
| BugMiner | 13 | 66 | 20.49 | |
| 2016–4492 2016–4493 | AFLGo | 20 | 8.45 | 21.09 |
| Hawkeye | 20 | 7.57 | - | |
| ParmeSan | 20 | 2.56 | 10.24 | |
| BugMiner | 20 | 2.21 | 5.54 | |
| Package | Target Programs | Version | Bug Type | Class Type | Basic Blocks | Edges | Input Format | Test Options | Source |
|---|---|---|---|---|---|---|---|---|---|
| binutils | readelf | 2.30 | BO | dev | 21,249 | 31,086 | binary | -a | [25] |
| binutils | objdump | 2.30 | HBO | dev | 43,935 | 74,313 | binary | -d | [25] |
| libksba | cert-basic | 1.3.5 | NPD | crypto | 9958 | 14,120 | crt | [56] | |
| libjpeg | djpeg | 9c | NPD | image | 4844 | 6776 | jpg | [57] | |
| libarchive | bsdtar | 3.3.2 | ML | archive | 31,379 | 43,390 | tar | [58] | |
| tcpdump | tcpdump | 4.9.2 | IO | net | 33,743 | 48,791 | pcap | -r/-nr | [59] |
| poppler | pdftohtml | 0.22.5 | UAF | doc | 54,596 | 71,945 | html/pdf | [60] | |
| poppler | pdftotext | 0.22.5 | BO | doc | 49,867 | 62,391 | pdf/txt | [60] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rustamov, F.; Kim, J.; Yu, J.; Kim, H.; Yun, J. BugMiner: Mining the Hard-to-Reach Software Vulnerabilities through the Target-Oriented Hybrid Fuzzer. Electronics 2021, 10, 62. https://doi.org/10.3390/electronics10010062
Rustamov F, Kim J, Yu J, Kim H, Yun J. BugMiner: Mining the Hard-to-Reach Software Vulnerabilities through the Target-Oriented Hybrid Fuzzer. Electronics. 2021; 10(1):62. https://doi.org/10.3390/electronics10010062
Chicago/Turabian StyleRustamov, Fayozbek, Juhwan Kim, Jihyeon Yu, Hyunwook Kim, and Joobeom Yun. 2021. "BugMiner: Mining the Hard-to-Reach Software Vulnerabilities through the Target-Oriented Hybrid Fuzzer" Electronics 10, no. 1: 62. https://doi.org/10.3390/electronics10010062