In such heavy industries as the aviation industry, the increasingly capable and advanced technologies are demanding, necessitating the reliability, intelligence, and efficiency. Those requirements, however, increase the complexity and the numbers of failure modes of the equipment.
Referring specifically to the phase involved with predicting future behavior, prognostics and health management (PHM) is one of the enablers of the CBM. As a multi-disciplinary high-end technology that includes mechanical, electrical, computer, artificial intelligence, communication, and network, PHM uses sensors to map the equipment’s working condition, surrounding environment, and online or historical operating status, making it possible to monitor the operating status of equipment, model performance degradation, predict remaining life and assess reliability, etc., through feature extraction, signal analysis, and data fusion modeling.
The goals of PHM include maximizing the operational availability, reduction of maintenance costs, and improvement of system reliability and safety by monitoring the facility conditions, and so does prognostics. The focus of prognostics is mainly on predicting the residual lifetime during which a device can perform its intended function, for example, the Remaining Useful Life (RUL) prediction. RUL is not only an estimation of the amount of time that an equipment, component, or system can continue to operate before reaching the replacement threshold, but also the indication of the health status of equipment.
If an equipment has reached the end of its service life, the number and complexity of environmental parameters (e.g., temperature, pressure, vibration levels, etc.), in which the equipment operates can significantly affect the accuracy of the prediction. An accurate RUL prediction is significant to the PHM, since it provides benefits, which, in turn, improve the decision-making for operations and CBM.
1.1. RUL Prediction Based on Physical Models
The degradation trend can be determined by such physical theories as fatigue damage theory and thermodynamics theory. Hoeppner et al. propose a fatigue-crack growth law, combining the knowledge of fracture mechanics to illustrate the application of fatigue-crack growth model [
3]. Contemporary, with the complexity and integration of advanced equipment, the RUL of equipment can be estimated by numerical integration using different fatigue crack growth rate. To overcome such a difficulty, Mohanty et al. propose an exponential model that can be used without integration of fatigue crack growth rate curve [
4]. To analyze the fatigue of pipelines, Divino et al. present a method based on nominal stresses, using a one-dimensional Finite Element mode with the application of stress concentration factors. The results make sense for not only finding the appropriate model, but also predicting the RUL through temperature theory [
5]. By evaluating the axial natural frequency from the motor current signal and axial vibrational signal, Nguyen et al. propose a discrete dynamic model to characterize the degradation level [
6]. The physical-model-based approach is suitable for a specific subject where the failure mechanism is well defined. Once an accurate physical model has been developed based on the system characteristics, the accuracy of the RUL prediction method is high, and the method is highly interpretable because it corresponds to the physical quantities through a mathematical model. However, as the structure of the equipment system becomes more and more complex, those physical models, mainly focusing on exploiting the fault mechanism of the equipment, may not be the most feasible for practical prognostic of complex equipment, for example, the turbofans or the ball screws, since the uncertainty in the machining process and the measurement noise are not incorporated in the physical models, and it is difficult to perform extensive experiments to identify some model parameters.
1.2. RUL Prediction Based on Data-Driven Method
Data-driven methods concentrate on the degradation of equipment from monitoring data instead of building physical models. To monitor the operating condition in all directions, the system is often equipped with a number of measuring sensors, making the data for data-driven methods high dimensional. Yan et al. provided a survey on feature extraction for bearing PHM applications [
7,
8]. High frequency resonance technique (HFRT) is a widely used frequency domain technique for bearing fault diagnosis [
9]. The Hilbert–Huang Transform (HHT) and Multiscale entropy (MSE) are used to extract features and evaluate the degradation levels of the ball screw [
10]. Feature learning is a method which transforms the extracted features into a representation that can be effectively exploited in data-driven methods. Hinton and Salakhutdinov [
11] proposes auto-encoders to learn features of handwriting, which is a commonly used unsupervised method in transfer writing.
According to the characteristics of RUL as a non-linear function, the current data-driven methods for RUL prediction are mainly divided into three branches: statistical model methods, machine learning methods represented by back propagation neural network (BPNN), and deep learning methods represented by long short-term memory (LSTM). The statistical model-based model assumes that the RUL prediction process is a white-box model, by inputting the device history data into the established statistical degradation model, and continuously adjusting the degradation model parameters to update the model accuracy. Based on existing information to establish probability density distributions for battery states, Saha et al. apply Bayesian estimation to battery cycle life prediction to quantify the uncertainty in RUL predictions [
12]. Bressel presents an HMM-based method, from which a state transfer matrix is obtained through matching tracing down [
13].
The actual engineering applications in the degradation model, however, often cannot be determined in advance, and different equipment has different working conditions, the inappropriate selection of degradation model will greatly affect the accuracy of the prediction results, thus causing huge economic losses [
14]. Machine learning methods are mostly grey-box models that do not require a prior degradation model, and the input data are not limited to the historical usage data of the device [
15,
16,
17]. Guo et al. propose a rolling bearing RUL prediction method based on improved deep forest, the model first iteratively calculates the equipment usage data by fast Fourier transform, and then replaces the traditional random forest multi-grain scan structure with a convolutional neural network, thus predicting the remaining life of rolling bearings [
18]. Celestino et al. propose a hybrid autoregressive integrated moving average–support vector machine (ARIMA–SVM) model that first extracts features from the input data via the ARIMA part, and then feeds the extracted features into the SVM model to predict the remaining lifetime [
19]. Based on singular value decomposition (SVD), Zhang et al. perform feature extraction of rolling bearing historical data to evaluate bearing degradability [
20]. Yu et al. improve the accuracy of the prediction of bearing remaining life by improving the recurrent neural network (RNN) model by zero-centering rule [
21].
Faced with massive amounts of industrial data, the computing power and accuracy of some machine learning models cannot meet industrial standards [
22]. Hence, deep learning is adopted universally to extract the features in non-linear systems [
23]. Deep learning models, such as LSTM, are widely used for their long-term memory capabilities. Elsheikh et al. combined deep learning with long and short memory to derive a deep long short-term memory (DLSTM) model, which firstly explored the correlation between each input signal through deep learning model, and then introduced random loss strategy to accurately and stably predict the remaining service life of aero-engine rotor blades [
24]. Based on the ordered neurons long short-term memory (ON-LSTM) model, Yan et al. first extracted the health index by calculating the frequency domain features of the original signal; then constructed the ON-LSTM network model to generate the RUL prediction value, which uses the sequential information between neurons and therefore has enhanced prediction capability [
25]. Though effective, RNN derived methods have the problem of gradient explosion, significantly affect the accuracy of the methods. Cho et al. proposed the encoder–decoder structure, which can learn to encode a variable-length sequence into a fixed-length vector representation and decode a given fixed-length vector representation back into a variable-length sequence [
26]. To remedy the gap between the emerging neural network-based methods and the well-established traditional fault diagnosis knowledge because data-driven method generally remains a “black box” to researchers, Li et al. introduce attention mechanism to assist the deep network to locate the informative data segments, extract the discriminative features of inputs, and visualize the learned diagnosis knowledge [
27]. Zhou et al. proposed the attention-mechanism-based convolutional neural network (CNN), with positional encoding, to tackle the problem that RNNs take much time for information to flow through the network for prediction [
28]. The attention mechanism enables the network to focus on specific parts of sequences and positional encoding injects position information while utilizing the parallelization merits of CNN on GPUs. Empirical experiments show that the proposed approach is both time effective and accurate in battery RUL prediction. Louw et al. combine dropout with Gate Recurrent Unit (GRU) and LSTM to predict RUL, obtaining an approximate uncertainty representation of the RUL prediction and validating algorithmically the turbofan engine dataset [
29]. Liao et al. propose a method based on Bootstrap and LSTM, which uses LSTM to train the model and obtains the confidence intervals for RUL predictions [
30].
Admittedly, LSTM has the capability to deal the signal and predict RUL. With the large data and equipment operating under various conditions, the calculating speed and accuracy was undermined because the changeable conditions could influence the prediction and only with faster and more quick-responsible method can we get more accurate RUL prediction results. To achieve more competitive prediction results, Kyunghyun et al. propose a Gate Recurrent Unit (GRU) [
31]. They couple the reset (input) gate to the update (forget) gate and show that this minimal gated unit (MGU) achieves a performance similar to the standard GRU with only two-thirds of the parameters, overcoming the risk of overfitting. GRU is a binary convolutional neural network whose weights are recursively applied to the input sequence until it outputs a single fixed-length vector. Compared to LSTM, GRU only reserves two gates, namely the forget fate and output gate, and has faster calculating speed than that of LSTM.
To further develop the value of gates of recursive convolutional neural network, a two-phase deep-learning-model attention-convolutional forget-gate recurrent network (AM-ConvFGRNET) for RUL prediction is proposed. The first phase, forget-gate recurrent network (FGRNET) is based on a one-dimensional analog LSTM, which removes all the gates except the forget gate and uses chrono-initialized biases [
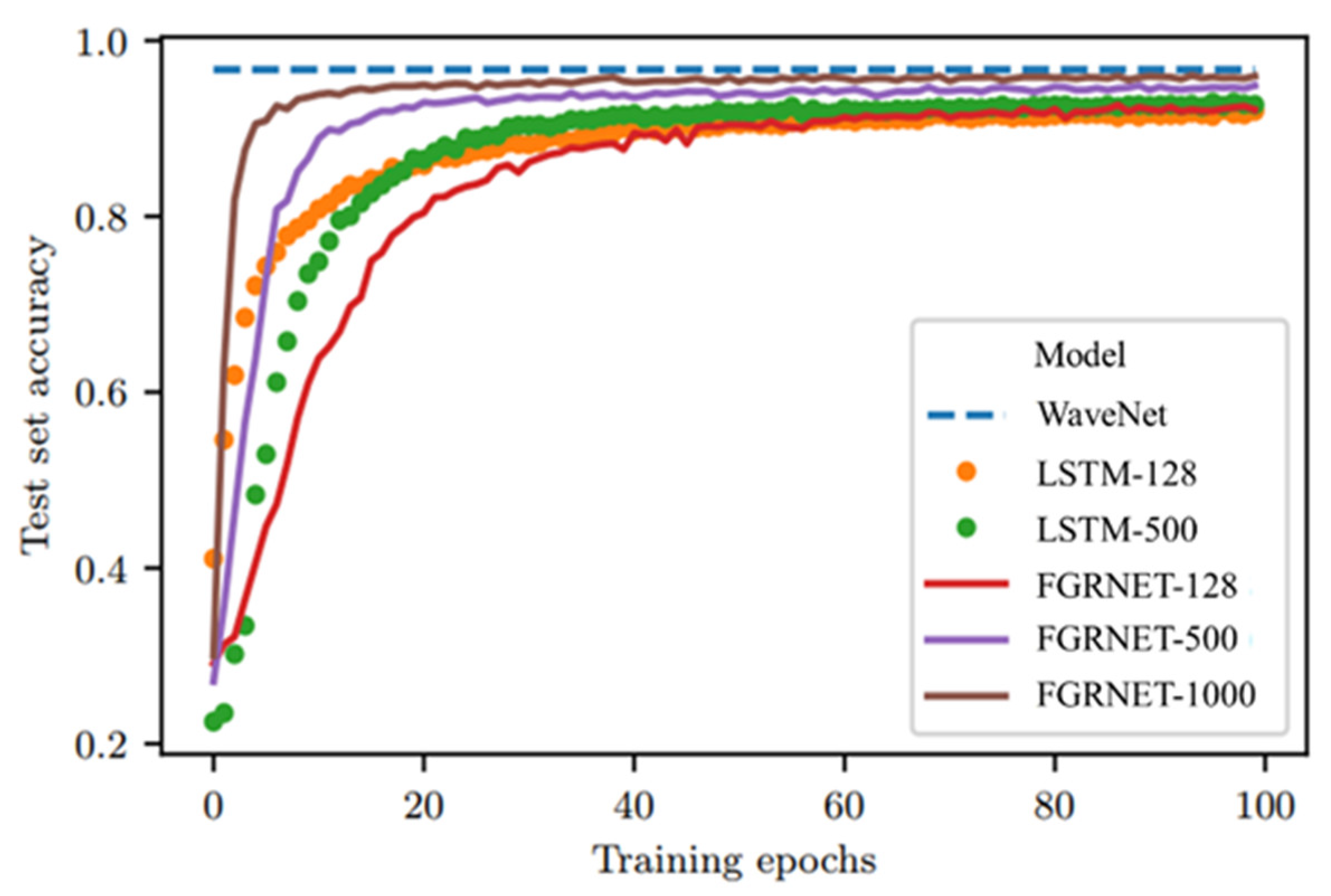
32]. The combination of fewer nonlinearities and chrono-initialization enables skip connections over entries in the input sequence. The skip connections created by the long-range cells allow information to flow unimpeded from the elements at the start of the sequence to memory cells at the end of the sequence. For the standard LSTM, however, these skip connections are less apparent and an unimpeded propagation of information is unlikely due to the multiple possible transformations at each time step. The fully connected layer is then added into the FGRNET model to assimilate temporal relationships in a group of time series. The FGRNET model is transformed into ConvFGRNET. The second phase is the Attention Mechanism: The lower part is the encoder structure which employs bi-directional recurrent neural network (RNN), the upper part is the decoder structure, and the middle part is the attention mechanism. The proposed model is capable of extracting more specific features for generating an output, compensating the drawbacks of the ConvFGRNET that it is a black box model and improving the interpretability. Hence, a two-phase model is proposed to predict the RUL of equipment. To comprehensively evaluated the performance of the proposed method, the ability of classification of FGRNET is first tested on MNIST (a database of handwritten digits performed) dataset [
33], whose result is then compared with RNN, LSTM and WaveNet [
34]. Then, the strengthen of RUL prediction is demonstrated through experiments dependent on a widely used dataset, and comparisons with other methods. To further evaluate, an experiment based on ball screw is conducted and proposed method is tested.
The main innovations of the proposed model are summarized as follows:
The proposed AM-ConvFGRNET simplifies the original LSTM model, in which the input and output gates are removed and only a forget gate is retained to correlate data accumulation and deletion. The simplified gate structure ensures the model could construct complex correlations between device history data and its remaining life, and to achieve faster gradient descent and increased computing power.
The attention mechanism is embedded into the ConvFGRNET model, which can increase the receptive field for feature extraction, increasing the prediction accuracy.
The article is developed as follows. The AM-ConvFGRNET is discussed in
Section 2. The data features and the data processing are discussed in
Section 3. The experiments and validation of the model is discussed in
Section 4. The conclusion is addressed in
Section 5.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}