DESTINY: A Comprehensive Tool with 3D and Multi-Level Cell Memory Modeling Capability


Abstract
:1. Introduction
- We have presented the motivation behind the development of DESTINY by discussing the design trends in modern processors and the limitations of existing modeling tools (Section 2).
- We have discussed the device-level data storage mechanism of each the memory technology (Section 3).
- We have now added support for modeling new memories (DWM, SOT-RAM) and MLC designs for all NVMs (including Flash). We have discussed their modeling framework and validation (Section 4.2, Section 4.3 and Section 4.4 and Section 5.1, Section 5.2, Section 5.3, Section 5.4, Section 5.5, Section 5.6 and Section 5.7).
- We have now shown the use of DESTINY in performing design-space exploration, for example finding the optimal memory technology for a given optimization target (Section 6.1), finding the optimal number of 3D layers for a given optimization target (Section 6.2), modeling assist structures (Section 6.3), etc.
- We have discussed the usefulness of DESTINY in gaining insights for designing management policies for memory structures such as cache, the register file, etc., using different memory technologies (Section 6.4).
2. Motivation and Related Work
2.1. Motivation behind the Design of DESTINY
2.2. A Comparison of Modeling Tools
3. A Background on Memory Technologies and MLC Design
3.1. Data Storage Mechanism of Memory Technologies
3.2. Multi-Level Cell Memory
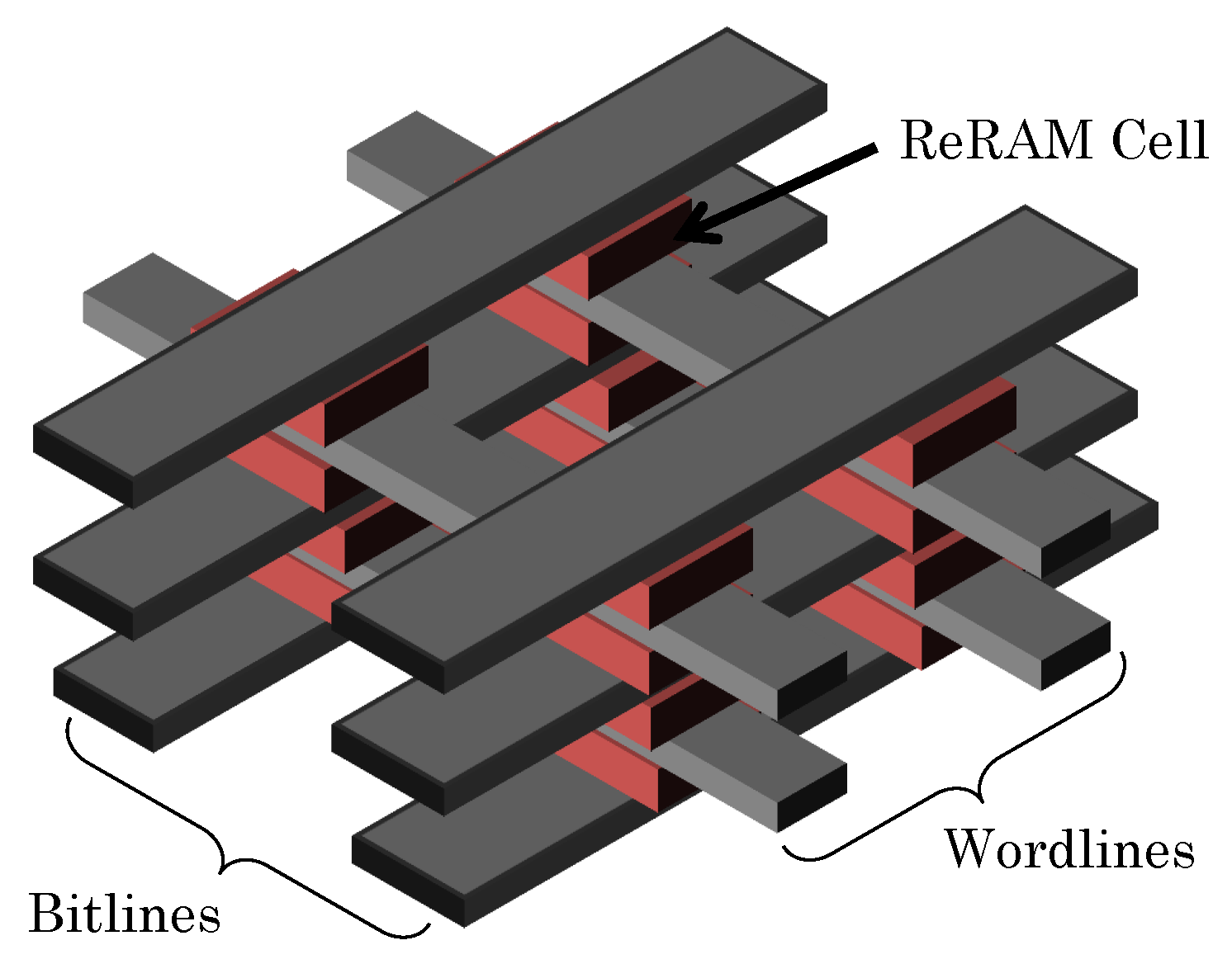
3.2.1. MLC PCM and ReRAM
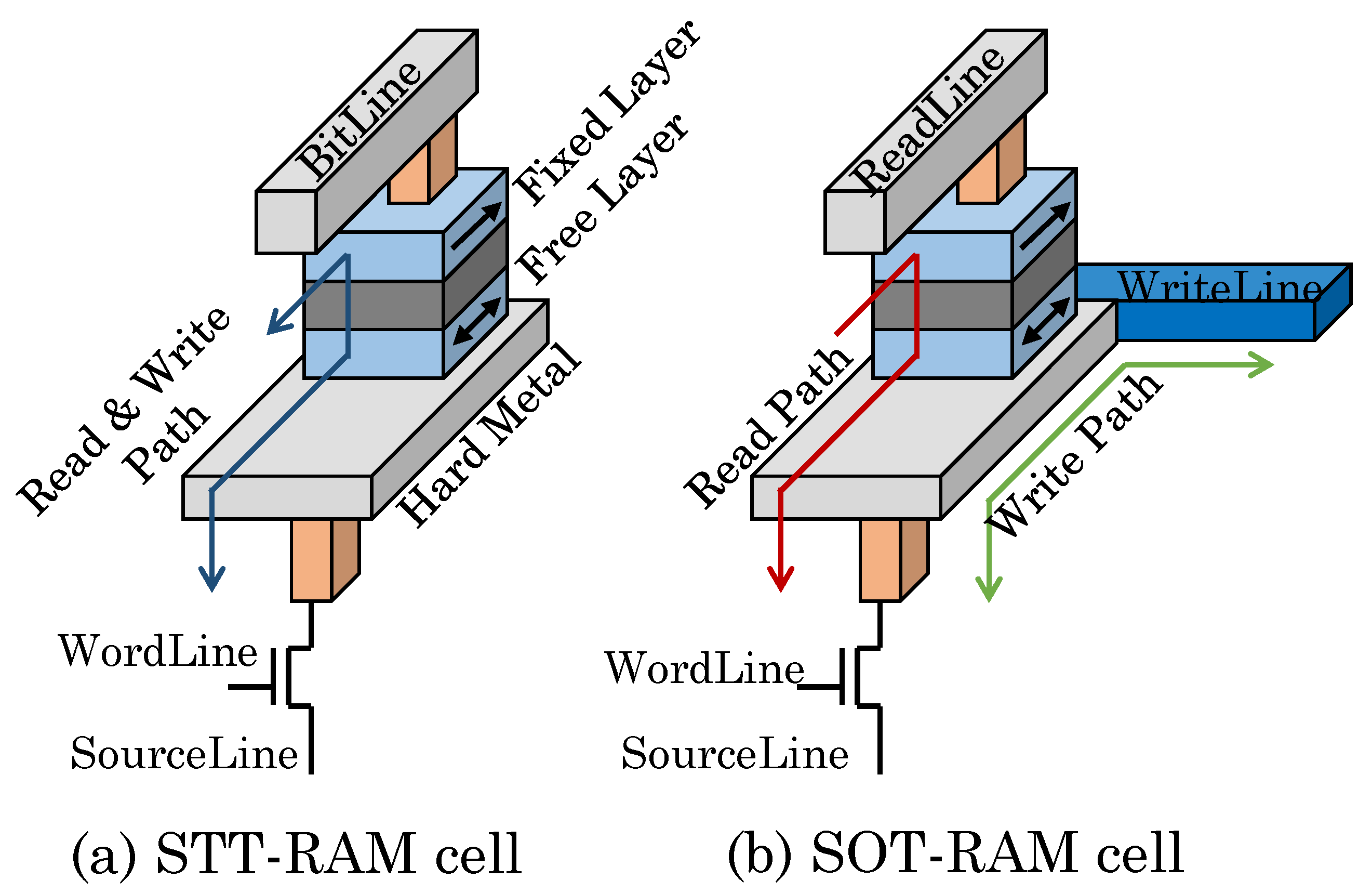
3.2.2. MLC STT-RAM and SOT-RAM
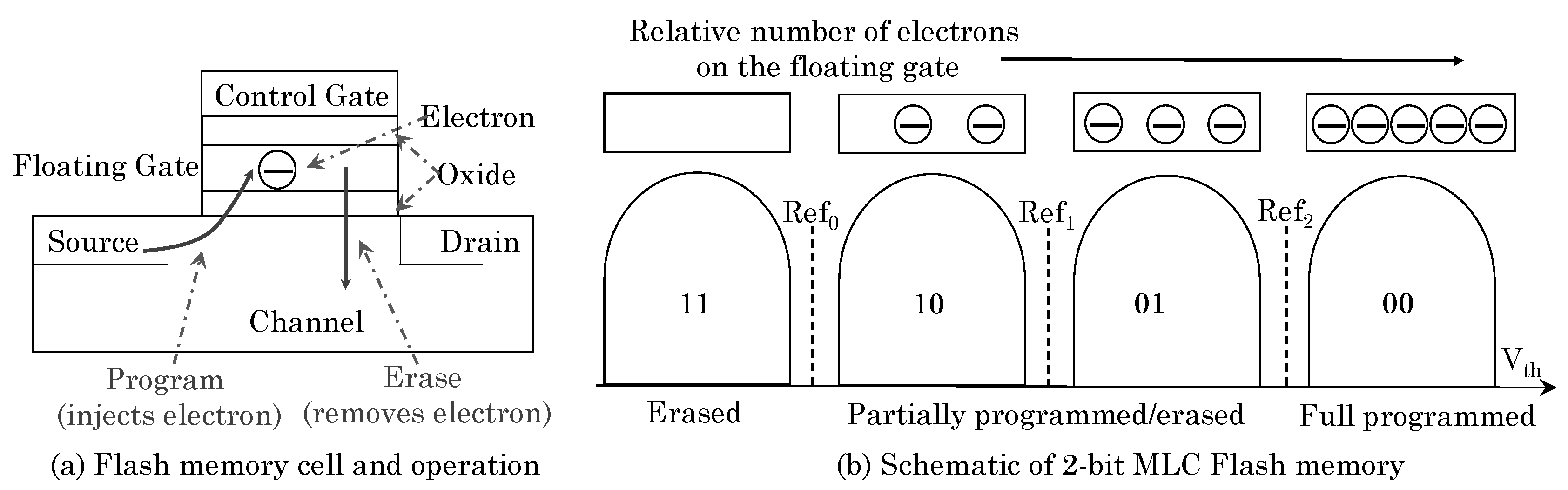
3.2.3. MLC Flash
4. DESTINY Modeling Framework
4.1. eDRAM Model
4.2. DWM Model
4.3. SOT-RAM Model
4.4. MLC Model
4.4.1. Read Operation Modeling
4.4.2. Write Operation Modeling for MLC PCM, ReRAM and Flash
4.4.3. Write Operation Modeling for MLC STT-RAM and SOT-RAM
4.5. 3D Model
5. Validation Results
5.1. DWM Validation
5.2. SLC SOT-RAM Validation
5.3. MLC SOT-RAM Validation
5.4. MLC STT-RAM Validation
5.5. MLC PCM Validation
5.6. MLC ReRAM Validation
5.7. MLC Flash Validation
5.8. 3D SRAM Validation
5.9. 2D and 3D eDRAM Validation
5.10. 3D ReRAM Validation
6. Design Space Exploration Using DESTINY
6.1. Finding the Optimal Memory Technology
6.2. Finding the Optimal Layer Count in 3D Stacking
6.3. Modeling Assist Structures
6.4. Gaining Insights for Designing Architectural Techniques
6.4.1. Finding the Best Memory Technology for Processor Components
6.4.2. Designing Architectural Management Techniques for Memory Technologies
7. Future Work and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kurd, N.; Chowdhury, M.; Burton, E.; Thomas, T.P.; Mozak, C.; Boswell, B.; Mosalikanti, P.; Neidengard, M.; Deval, A.; Khanna, A. Haswell: A family of IA 22nm processors. IEEE J. Solid-State Circuits 2015, 50, 49–58. [Google Scholar] [CrossRef]
- Bowhill, B.; Stackhouse, B.; Nassif, N.; Yang, Z.; Raghavan, A.; Morganti, C.; Houghton, C.; Krueger, D.; Franza, O.; Desai, J.; et al. The Xeon® processor E5-2600 v3: A 22 nm 18-core product family. In Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 22–26 February 2015; pp. 1–3. [Google Scholar]
- Vetter, J.S.; Mittal, S. Opportunities for Nonvolatile Memory Systems in Extreme-Scale High Performance Computing. Comput. Sci. Eng. 2015, 17, 73–82. [Google Scholar] [CrossRef]
- Barth, J.; Plass, D.; Nelson, E.; Hwang, C.; Fredeman, G.; Sperling, M.; Mathews, A.; Kirihata, T.; Reohr, W.; Nair, K.; et al. A 45 nm SOI Embedded DRAM Macro for the POWER Processor 32 MByte On-Chip L3 Cache. IEEE J. Solid-State Circuits 2011, 46, 64–75. [Google Scholar] [CrossRef]
- Barth, J.; Reohr, W.; Parries, P.; Fredeman, G.; Golz, J.; Schuster, S.; Matick, R.E.; Hunter, H.; Tanner, C.; Harig, J.; et al. A 500 MHz Random Cycle, 1.5 ns Latency, SOI Embedded DRAM Macro Featuring a Three-Transistor Micro Sense Amplifier. IEEE J. Solid-State Circuits 2008, 43, 86–95. [Google Scholar] [CrossRef]
- Chen, K.; Li, S.; Muralimanohar, N.; Ahn, J.H.; Brockman, J.B.; Jouppi, N.P. CACTI-3DD: Architecture-level modeling for 3D die-stacked DRAM main memory. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 12–16 March 2012; pp. 33–38. [Google Scholar]
- Wilton, S.J.E.; Jouppi, N. CACTI: An enhanced cache access and cycle time model. IEEE J. Solid-State Circuits 1996, 31, 677–688. [Google Scholar] [CrossRef]
- Dong, X.; Xu, C.; Jouppi, N.; Xie, Y. NVSim: A circuit-level performance, energy, and area model for emerging nonvolatile memory. IEEE Counc. Electron. Des. Autom. 2012, 31, 994–1007. [Google Scholar]
- Syu, S.M.; Shao, Y.-H.; Lin, I.-C. High-endurance hybrid cache design in CMP architecture with cache partitioning and access-aware policy. In Proceedings of the 23rd ACM international conference on Great lakes symposium on VLSI, Paris, France, 2–3 May 2013. [Google Scholar]
- Mittal, S.; Poremba, M.; Vetter, J.; Xie, Y. Exploring Design Space of 3D NVM and eDRAM Caches Using DESTINY Tool; Technical Report ORNL/TM-2014/636; Oak Ridge National Laborator: Oak Ridge, TN, USA, 2014.
- Zhang, C.; Sun, G.; Zhang, W.; Mi, F.; Li, H.; Zhao, W. Quantitative modeling of racetrack memory, a tradeoff among area, performance, and power. In Proceedings of the 20th Asia and South Pacific Design Automation Conference (ASP-DAC), Chiba, Japan, 19–22 January 2015; pp. 100–105. [Google Scholar]
- Sun, G.; Dong, X.; Xie, Y.; Li, J.; Chen, Y. A novel architecture of the 3D stacked MRAM L2 cache for CMPs. In Proceedings of the IEEE 15th International Symposium on High Performance Computer Architecture, Raleigh, NC, USA, 14–18 February 2009; pp. 239–249. [Google Scholar]
- Sun, Z.; Bi, X.; Wu, W.; Yoo, S.; Li, H.H. Array organization and data management exploration in racetrack memory. IEEE Trans. Comput. 2016, 65, 1041–1054. [Google Scholar] [CrossRef]
- Tsai, Y.F.; Xie, Y.; Vijaykrishnan, N.; Irwin, M.J. Three-Dimensional Cache Design Exploration Using 3DCacti. In Proceedings of the International Conference on Computer Design (ICCD), San Jose, CA, USA, 2–5 October 2005; pp. 519–524. [Google Scholar]
- Prenat, G.; Jabeur, K.; Vanhauwaert, P.; Pendina, G.; Oboril, F.; Bishnoi, R.; Garello, K.; Gambardella, P.; Tahoori, M.; Gaudin, G. Ultra-Fast and High-Reliability SOT-MRAM: From Cache Replacement to Normally-off Computing. IEEE Trans. Multi-Scale Comput. Syst. 2016, 2, 49–60. [Google Scholar] [CrossRef]
- Kim, Y.; Fong, X.; Kwon, K.W.; Chen, M.C.; Roy, K. Multilevel Spin-Orbit Torque MRAMs. IEEE Trans. Electron Devices 2015, 62, 561–568. [Google Scholar] [CrossRef]
- Hong, S.; Lee, J.; Kim, S. Ternary cache: Three-valued MLC STT-RAM caches. In Proceedings of the International Conference on Computer Design (ICCD), Seoul, Korea, 19–22 October 2014; pp. 83–89. [Google Scholar]
- Zhao, M.; Xue, Y.; Hu, J.; Yang, C.; Liu, T.; Jia, Z.; Xue, C.J. State Asymmetry Driven State Remapping in Phase Change Memory. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2017, 36, 27–40. [Google Scholar] [CrossRef]
- Sheu, S.S.; Chang, M.F.; Lin, K.F.; Wu, C.W.; Chen, Y.S.; Chiu, P.F.; Kuo, C.C.; Yang, Y.S.; Chiang, P.C.; Lin, W.P.; et al. A 4 Mb embedded SLC resistive-RAM macro with 7.2 ns read-write random-access time and 160 ns MLC-access capability. In Proceedings of the IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 20–24 February 2011; pp. 200–202. [Google Scholar]
- Golz, J.; Safran, J.; He, B.; Leu, D.; Yin, M.; Weaver, T.; Vehabovic, A.; Sun, Y.; Cestero, A.; Himmel, B.; et al. 3D stackable 32 nm High-K/Metal Gate SOI embedded DRAM prototype. In Proceedings of the Symposium on VLSI Circuits (VLSIC), Kyoto, Japan, 15–17 June 2011; pp. 228–229. [Google Scholar]
- Klim, P.; Barth, J.; Reohr, W.; Dick, D.; Fredeman, G.; Koch, G.; Le, H.; Khargonekar, A.; Wilcox, P.; Golz, J.; et al. A one MB cache subsystem prototype with 2 GHz embedded DRAMs in 45 nm SOI CMOS. In Proceedings of the 2008 IEEE Symposium on VLSI Circuits, Honolulu, HI, USA, 18–20 June 2008; pp. 206–207. [Google Scholar]
- Kawahara, A.; Azuma, R.; Ikeda, Y.; Kawai, K.; Katoh, Y.; Tanabe, K.; Nakamura, T.; Sumimoto, Y.; Yamada, N.; Nakai, N.; et al. An 8 Mb multi-layered cross-point ReRAM macro with 443 MB/s write throughput. IEEE J. Solid-State Circuits 2013, 48, 178–185. [Google Scholar] [CrossRef]
- Hsu, C.L.; Wu, C.F. High-performance 3D-SRAM architecture design. In Proceedings of the IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Kuala Lumpur, Malaysia, 6–9 December 2010; pp. 907–910. [Google Scholar]
- Puttaswamy, K.; Loh, G. 3D-Integrated SRAM Components for High-Performance Microprocessors. Comput. IEEE Trans. 2009, 58, 1369–1381. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.H.; Park, K.T.; Kwak, P.; Kwon, O.; Kim, C.; Lee, Y.; Park, S.; Kim, K.; Cho, D.; et al. A 159 mm2 32 nm 32 Gb MLC NAND-flash memory with 200 MB/s asynchronous DDR interface. In Proceedings of the IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Fransico, CA, USA, 7–11 February 2010; pp. 442–443. [Google Scholar]
- Cernea, R.; Pham, L.; Moogat, F.; Chan, S.; Le, B.; Li, Y.; Tsao, S.; Tseng, T.Y.; Nguyen, K.; Li, J.; et al. A 34 MB/s-program-throughput 16Gb MLC NAND with all-bitline architecture in 56 nm. In Proceedings of the IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 3–7 February 2008; pp. 420–624. [Google Scholar]
- Mittal, S. A Survey of Techniques for Architecting TLBs. Concurr. Comput.: Pract. Exper. 2017, 29, 10. [Google Scholar] [CrossRef]
- Poremba, M.; Mittal, S.; Li, D.; Vetter, J.S.; Xie, Y. DESTINY: A Tool for Modeling Emerging 3D NVM and eDRAM caches. In Proceedings of the Design Automation and Test in Europe (DATE), Grenoble, France, 9–13 March 2015. [Google Scholar]
- Kalla, R.; Sinharoy, B.; Starke, W.J.; Floyd, M. Power7: IBM’s next-generation server processor. IEEE Micro 2010, 30, 7–15. [Google Scholar] [CrossRef]
- Zyuban, V.; Taylor, S.; Christensen, B.; Hall, A.; Gonzalez, C.; Friedrich, J.; Clougherty, F.; Tetzloff, J.; Rao, R. IBM POWER7+ design for higher frequency at fixed power. IBM J. Res. Dev. 2013, 57, 1. [Google Scholar] [CrossRef]
- Fluhr, E.J.; Friedrich, J.; Dreps, D.; Zyuban, V.; Still, G.; Gonzalez, C.; Hall, A.; Hogenmiller, D.; Malgioglio, F.; Nett, R.; et al. POWER8: A 12-core server-class processor in 22 nm SOI with 7.6 Tb/s off-chip bandwidth. In Proceedings of the IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 9–13 February 2014; pp. 96–97. [Google Scholar]
- Mittal, S. A Survey of Architectural Techniques For Improving Cache Power Efficiency. Sustain. Comput. Inform. Syst. 2014, 4, 33–43. [Google Scholar] [CrossRef]
- Mittal, S. A Survey of Techniques for Architecting and Managing GPU Register File. IEEE Trans. Parallel Distrib. Syst. 2016, 28, 16–28. [Google Scholar] [CrossRef]
- Mamidipaka, M.; Dutt, N. eCACTI: An Enhanced Power Estimation Model for On-Chip Caches; Technical Report, TR-04-28; UC Irvine: Irvine, CA, USA, 2004. [Google Scholar]
- Li, S.; Chen, K.; Ahn, J.H.; Brockman, J.B.; Jouppi, N.P. CACTI-P: Architecture-level Modeling for SRAM-based Structures with Advanced Leakage Reduction Techniques. In Proceedings of the International Conference on Computer-Aided Design, San Jose, CA, USA, 7–10 November 2011; pp. 694–701. [Google Scholar]
- Mittal, S.; Vetter, J.S.; Li, D. A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 1524–1537. [Google Scholar] [CrossRef]
- Mittal, S. A Survey of Techniques for Architecting Processor Components using Domain Wall Memory. ACM J. Emerg. Technol. Comput. Syst. 2016, 13. [Google Scholar] [CrossRef]
- Mittal, S.; Vetter, J. Reliability Tradeoffs in Design of Volatile and Non-volatile Caches. J. Circuits Syst. Comput. 2016, 25, 1650139. [Google Scholar] [CrossRef]
- Xu, C.; Niu, D.; Muralimanohar, N.; Jouppi, N.P.; Xie, Y. Understanding the trade-offs in multi-level cell ReRAM memory design. In Proceedings of the Design Automation Conference (DAC), Austin, TX, USA, 29 May–7 June 2013; pp. 1–6. [Google Scholar]
- Mittal, S.; Vetter, J.S. A Survey of Software Techniques for Using Non-Volatile Memories for Storage and Main Memory Systems. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1537–1550. [Google Scholar] [CrossRef]
- Mittal, S. A Survey of Power Management Techniques for Phase Change Memory. Int. J. Comput. Aided Eng. Technol. 2016, 8, 424–444. [Google Scholar] [CrossRef]
- Byeon, D.S.; Lee, S.S.; Lim, Y.H.; Kang, D.; Han, W.k.; Kim, D.H.; Suh, K.D. A comparison between 63 nm 8 Gb and 90 nm 4 Gb multi-level cell NAND flash memory for mass storage application. In Proceedings of the IEEE Asian Solid-State Circuits Conference, Hsinchu, Taiwan, 1–3 November 2005; pp. 13–16. [Google Scholar]
- Seong, N.H.; Yeo, S.; Lee, H.H.S. Tri-level-cell phase change memory: Toward an efficient and reliable memory system. In Proceedings of the International Symposium on Computer Architecture, Tel-Aviv, Israel, 23–27 June 2013; pp. 440–451. [Google Scholar]
- Ishigaki, T.; Kawahara, T.; Takemura, R.; Ono, K.; Ito, K.; Matsuoka, H.; Ohno, H. A multi-level-cell spin-transfer torque memory with series-stacked magnetotunnel junctions. In Proceedings of the Symposium on VLSI Technology, Honolulu, HI, USA, 15–17 June 2010. [Google Scholar]
- Wen, W.; Zhang, Y.; Mao, M.; Chen, Y. State-restrict MLC STT-RAM designs for high-reliable high-performance memory system. In Proceedings of the Design Automation Conference (DAC), San Francisco, CA, USA, 1–5 June 2014; pp. 1–6. [Google Scholar]
- Mittal, S. A Survey of Soft-Error Mitigation Techniques for Non-Volatile Memories. Computers 2017, 6, 8. [Google Scholar] [CrossRef]
- Kirihata, T.; Parries, P.; Hanson, D.; Kim, H.; Golz, J.; Fredeman, G.; Rajeevakumar, R.; Griesemer, J.; Robson, N.; Cestero, A.; et al. An 800MHz embedded DRAM with a concurrent refresh mode. IEEE Int. Solid-State Circuits 2005, 40, 1377–1387. [Google Scholar] [CrossRef]
- Jiang, L.; Zhao, B.; Zhang, Y.; Yang, J. Constructing large and fast multi-level cell STT-MRAM based cache for embedded processors. In Proceedings of the Design Automation Conference (DAC), San Francisco, CA, USA, 3–7 June 2012; pp. 907–912. [Google Scholar]
- Black, B.; Nelson, D.; Webb, C.; Samra, N. 3D processing technology and its impact on iA32 microprocessors. In Proceedings of the IEEE International Conference on Computer Design, San Jose, CA, USA, 11–13 October 2004; pp. 316–318. [Google Scholar]
- Patti, R. Three-Dimensional Integrated Circuits and the Future of System-on-Chip Designs. Proc. IEEE 2006, 94, 1214–1224. [Google Scholar] [CrossRef]
- Chen, Y.; Wong, W.F.; Li, H.; Koh, C.K. Processor caches built using multi-level spin-transfer torque RAM cells. In Proceedings of the Low Power Electronics and Design (ISLPED), Fukuoka, Japan, 1–3 August 2011; pp. 73–78. [Google Scholar]
- Mittal, S. A Survey of Techniques for Designing and Managing CPU Register File. Concurr. Comput.: Pract. Exper. 2016, 29, e3906. [Google Scholar] [CrossRef]
- Mittal, S. A Survey Of Cache Bypassing Techniques. J. Low Power Electron. Appl. 2016, 6, 5. [Google Scholar] [CrossRef]
- Mittal, S.; Vetter, J. A Survey Of Architectural Approaches for Data Compression in Cache and Main Memory Systems. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1524–1536. [Google Scholar] [CrossRef]
- Mittal, S.; Vetter, J. A Technique For Improving Lifetime of Non-volatile Caches using Write-minimization. J. Low Power Electron. Appl. 2016, 6, 1. [Google Scholar] [CrossRef]
- Mittal, S.; Vetter, J.S. AYUSH: A Technique for Extending Lifetime of SRAM-NVM Hybrid Caches. IEEE Comput. Arch. Lett. 2015, 14, 115–118. [Google Scholar] [CrossRef]
- Mittal, S. A Survey Of Architectural Techniques for Managing Process Variation. ACM Comput. Surv. 2016, 48, 54. [Google Scholar] [CrossRef]
- Mittal, S. A Survey Of Architectural Techniques for Near-Threshold Computing. ACM J. Emerg. Tech. Comput. Syst. 2015, 12, 46. [Google Scholar] [CrossRef]
- Mittal, S. A Survey Of Techniques for Approximate Computing. ACM Comput. Surv. 2016, 48, 62. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CACTI | NVSim |
|---|---|
| Area: 14.90 mm | Area: 6.75 mm |
| Leakage: 0.574 W | Leakage: 0.395 W |
| Access and random cycle time: 0.634 and 3.119 ns | Hit/miss/write latency: 2.009, 0.314 and 1.079 ns |
| Read dynamic energy: 0.182 nJ | Hit/miss/write dynamic energy: 0.388, 0.032, 0.363 nJ |
| Tools | SRAM | eDRAM | PCM | STT-RAM | ReRAM | SOT-RAM | Flash | DWM |
|---|---|---|---|---|---|---|---|---|
| CACTI(3DD) | 2D | 2D/3D | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| NVSim | 2D | ✗ | 2D, SLC | ✗ | ||||
| DESTINY | 2D/3D | 2D/3D, SLC/MLC | 2D, SLC/MLC | |||||
| Metric | Actual | DESTINY | Error |
|---|---|---|---|
| Area (mm) | 6.89 | 7.954 | 15.44% |
| Read Latency (ns) | 5.83 | 4.424 | −24.12% |
| Write Latency (ns) | 12.49 | 12.635 | 1.16% |
| Shift Latency (ns) | 5.31 | 4.878 | −8.14% |
| Read Energy (pJ) | 236.63 | 257.582 | 8.85% |
| Write Energy (pJ) | 1032 | 1145 | 10.95% |
| Shift Energy (pJ) | 214.61 | 230 | 7.17% |
| Leakage Power (mW) | 163.72 | 147 | −10.21% |
| Metric | Actual | DESTINY | Error |
|---|---|---|---|
| Read Latency (ns) | 3.8 | 3.87 | 1.84% |
| Write Latency (ns) | 2.8 | 2.562 | −8.50% |
| Metric | Actual | DESTINY | Error |
|---|---|---|---|
| Write Energy (pJ) | 1.8–3.8 | 2.29–3.25 | — |
| Metric | Actual | DESTINY | Error% |
|---|---|---|---|
| Area (mm) | 3.42 | 3.68 | 7.69% |
| Read Latency (ns) | 4.8 | 4.83 | 0.67% |
| Write Latency (ns) | 21.2 | 20.46 | −3.48% |
| Read Energy (pJ) | 181.01 | 192.00 | 6.07% |
| Write Energy (pJ) | 349.64 | 378.00 | 8.11% |
| Leakage Power (mW) | 324.54 | 324.50 | −0.01% |
| Metric | Actual | DESTINY | Error |
|---|---|---|---|
| Write Latency (ns) | 696 | 696.96 | 0.14% |
| Write Energy (pJ) | 122.92 | 122.92 | 0% |
| Metric | Actual | DESTINY | Error |
|---|---|---|---|
| Write Latency (ns) | 160 | 157.823 | −1.36% |
| Metric | Actual | DESTINY | Error (%) |
|---|---|---|---|
| 32 nm 32 Gb MLC Flash prototype [25] | |||
| Area (mm) | 159 | 148.12 | −6.84% |
| 56 nm 16 Gb MLC Flash [26] | |||
| Area (mm) | 182 | 183.54 | 0.84% |
| Design | Metric | Actual | DESTINY | Error |
|---|---|---|---|---|
| 1 MB [23] 2 layers | Latency | 1.85 ns | 1.91 ns | 3.54% |
| Energy | 5.10 nJ | 5.05 nJ | −0.98% | |
| 1 MB [23] 4 layers | Latency | 1.75 ns | 1.80 ns | 2.68% |
| Energy | 4.5 nJ | 4.51 nJ | 0.18% | |
| 4 MB [24] 2 layers | Latency | 7.85 ns | 7.23 ns | −7.91% |
| Energy | 0.13 nJ | 0.13 nJ | −2.59% | |
| 4 MB [24] 4 layers | Latency | 6.10 ns | 6.95 ns | 14.03% |
| Energy | 0.12 nJ | 0.13 nJ | 4.75% | |
| 2 MB [24] 2 layers | Latency | 5.77 ns | 5.78 ns | 0.05% |
| Energy | 0.12 nJ | 0.13 nJ | 2.74% | |
| 2 MB [24] 4 layers | Latency | 4.88 ns | 5.53 ns | 13.5% |
| Energy | 0.12 nJ | 0.13 nJ | 8.46% | |
| 1 MB [24] 2 layers | Latency | 3.95 ns | 3.90 ns | −1.11% |
| Energy | 0.11 nJ | 0.11 nJ | −0.13% | |
| 1 MB [24] 4 layers | Latency | 3.07 ns | 3.04 ns | −0.85% |
| Energy | 0.11 nJ | 0.11 nJ | −0.89% |
| Design | Metric | Actual | DESTINY | Error |
|---|---|---|---|---|
| 2D 2 Mb 65 nm [5] | Latency | <2 ns | 1.46 ns | — |
| Area | 0.665 mm | 0.701 mm | 5.42% | |
| 2D 1 Mb 45 nm [4] | Latency | 1.7 ns | 1.73 ns | 1.74% |
| Area | 0.239 mm | 0.234 mm | −2.34% | |
| 2D 2.25 Mb 45 nm [21] | Latency | 1.8 ns | 1.75 ns | −2.86% |
| Area | 0.420 mm | 0.442 mm | 5.31% | |
| 3D 1 Mb 2-layers[20] | Latency | <1.5 ns | 1.42 ns | — |
| Area | 0.139 mm | 0.149 mm | 9.32% |
| Metric | Actual | DESTINY | Error (%) |
|---|---|---|---|
| Read latency (ns) | 25 | 24.16 | 3.36 |
| Read bandwidth (MB/s) | 305 | 315.786 | −3.54 |
| Write latency (MB/s) | 17.2 | 20.13 | −17.03 |
| Write bandwidth (MB/s) | 443.56 | 379 | 14.55 |
| Optimization Target | Optimal Technology | Area (mm) | Read Lat. (ns) | Write Lat. (ns) | Read En. (nJ) | Write En. (nJ) | Read EDP | Write EDP | Leakage Pw. (mW) |
|---|---|---|---|---|---|---|---|---|---|
| Area | MLC PCM | 0.376968 | 231.679 | 1806.28 | 0.956917 | 427.855 | 221.697 | 772,826 | 3.39841 |
| Read Latency | SOT-RAM | 5.41092 | 2.18991 | 1.55141 | 0.270523 | 0.368301 | 0.592421 | 0.571385 | 223.238 |
| Write Latency | SOT-RAM | 4.48621 | 2.5709 | 1.43888 | 0.300592 | 0.384013 | 0.772791 | 0.552548 | 234.453 |
| Read Energy | eDRAM | 4.96351 | 15.9016 | 15.8517 | 0.0621384 | 1.83554 | 0.988099 | 29.0964 | 12.0347 |
| Write Energy | SRAM | 22.528 | 275.116 | 274.083 | 0.681917 | 0.032005 | 187.606 | 8.77202 | 1303.36 |
| Read EDP | SOT-RAM | 3.73355 | 2.44682 | 1.58979 | 0.214578 | 0.310745 | 0.525035 | 0.494018 | 169.274 |
| Write EDP | SOT-RAM | 3.73355 | 2.44682 | 1.58979 | 0.214578 | 0.310745 | 0.525035 | 0.494018 | 169.274 |
| Leakage | MLC RRAM | 0.581464 | 124.354 | 529.061 | 0.608305 | 11.9998 | 75.6454 | 6348.61 | 3.51614 |
| Optimization Target | Optimal D | Area (mm) | Read Lat. (ns) | Write Lat. (ns) | Read En. (nJ) | Write En. (nJ) | Read EDP | Write EDP | Leakage Pw. (mW) |
|---|---|---|---|---|---|---|---|---|---|
| Area | 16 | 2.6614 | 119.2630 | 125.6090 | 2.9371 | 3.1065 | 350.2820 | 390.2090 | 34.2075 |
| Read Latency | 16 | 3.6750 | 3.2444 | 10.7870 | 3.1518 | 3.2280 | 10.2257 | 34.8209 | 1281.6100 |
| Write Latency | 16 | 3.9662 | 3.3027 | 10.7563 | 3.3282 | 3.3734 | 10.9921 | 36.2853 | 2477.7100 |
| Read Energy | 2 | 9.0916 | 127.2620 | 131.9070 | 0.2395 | 0.4362 | 30.4805 | 57.5427 | 30.0845 |
| Write Energy | 2 | 13.7392 | 503.1190 | 509.8560 | 0.4479 | 0.3271 | 225.3390 | 166.7570 | 57.0693 |
| Read EDP | 4 | 7.5184 | 4.4265 | 11.6705 | 0.5698 | 0.6816 | 2.5222 | 7.9541 | 787.0820 |
| Write EDP | 4 | 8.0937 | 4.7674 | 11.8760 | 0.5439 | 0.6348 | 2.5929 | 7.5393 | 431.0840 |
| Leakage Pw. | 1 | 16.8930 | 1813.0100 | 1810.2800 | 0.6430 | 0.6009 | 1165.6900 | 1087.8700 | 7.8901 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mittal, S.; Wang, R.; Vetter, J. DESTINY: A Comprehensive Tool with 3D and Multi-Level Cell Memory Modeling Capability. J. Low Power Electron. Appl. 2017, 7, 23. https://doi.org/10.3390/jlpea7030023
Mittal S, Wang R, Vetter J. DESTINY: A Comprehensive Tool with 3D and Multi-Level Cell Memory Modeling Capability. Journal of Low Power Electronics and Applications. 2017; 7(3):23. https://doi.org/10.3390/jlpea7030023
Chicago/Turabian StyleMittal, Sparsh, Rujia Wang, and Jeffrey Vetter. 2017. "DESTINY: A Comprehensive Tool with 3D and Multi-Level Cell Memory Modeling Capability" Journal of Low Power Electronics and Applications 7, no. 3: 23. https://doi.org/10.3390/jlpea7030023