The topics we deal with in this work belong to a relatively young research branch involving machine learning and source code. The field of source code analysis has embraced deep learning techniques, and we want to present a historical and rapid review of research works in this field with, firstly, the aim of answering the RQ1: “How, historically, have learning techniques been applied to source code?”. Furthermore, we want to give the reader an overview and historical perception of the improvements made in this research area to better understand the aspects presented in the next section.
2.1. Selection Criteria
In this research timeline, we only considered articles published after the work of Hindle et al. “On the naturalness of software” [
11] which we consider to be the seminal work for the whole research field. The main source from which we selected the articles of interest is a corpus of about 390 papers called ml4code [
12] collected and selected by the community for the initiative of Allamanis M. [
6] and a corpus of 180 other papers obtained using a direct keywords search on Scopus, we will refer to this corpus by the name Corpus 0.
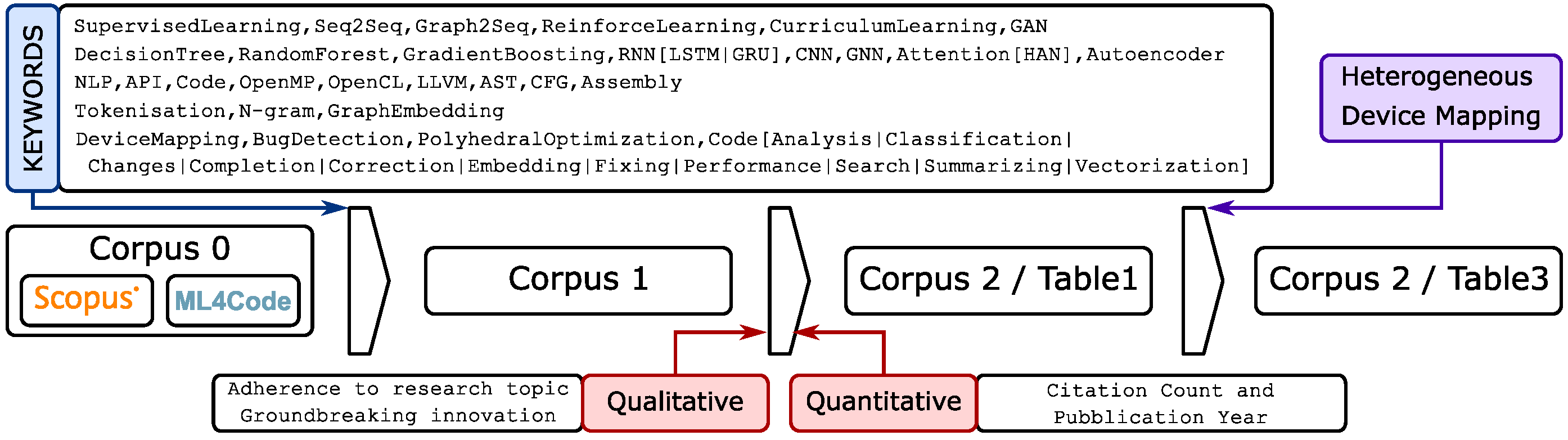
The first phase of the selection process was the following: we defined a set of keywords belonging to machine learning and deep learning techniques. The keywords are listed in the third column of
Table 1, and the complete list is reported in
Figure 1. For each keyword, we selected only the papers that use it in their title or abstract. In this first phase, we reduced the corpus to 94 documents. We will refer to this corpus by the name of Corpus 1.
Then, we identified pioneering articles as those proposing a new machine-learning technique or tackling a new problem. To achieve this, we selected papers from Corpus 1 using qualitative and quantitative metrics. Regarding the qualitative metrics, the selection criteria was the relevance of techniques used and the problems addressed. After this review, among the resulting papers, we selected the ones referred to as seminal works by more recent papers on the same subject (in our case, the source code analysis using deep learning). These are valid candidates to be labelled as pioneering works as they introduced the application of a new approach or solved a problem for the first time.
We also cross-checked the selection results using quantitative metrics. These quantitative metrics are publication year and citation count. Seminal papers should be earlier in terms of publication year and must be consistently cited by the following papers. It must be noted that the selection procedure makes use of our prior knowledge in this area of research, and it is not a mere application of thresholds on selected metrics. The selected papers, that compose the Corpus 2, will be discussed in
Section 2.3. The papers are listed in
Table 1 and 3.
This research timeline is divided into two parts: Relevant related surveys and historical overview of ML and DL techniques for source code. In the first part,
Section 2.2, we present an article that we consider the seminal work for the whole research field on source code analysis [
11] and three most cited surveys on the subject [
6,
7,
8]. We will therefore use this first part to outline the contours of the topic and summarise the fundamental concepts proposed by the authors in their works.
In the second part,
Section 2.3, we describe in detail the most important techniques and intuitions behind models mentioned by previous surveys. We chose to follow a historical timeline useful to emphasise the research improvements over the years and highlight the insights behind the enhanced performance of recent code analysis methods. We describe the selected works and their categorisation alongside topic keywords. The description is a summary of the work with the aim to highlight three research aspects: (i) The abstraction level for source code analysis (e.g., high-level source code, intermediate representation, assembly); (ii) The code representation technique (e.g., token-based stream, abstract syntax tree, control flow graph); (iii) The problem against which the proposed method has been tested.
2.2. Relevant Related Surveys
The following surveys are useful to depict and explain the research field of machine learning on code. They help to identify how scientific research has evolved over the years and the field’s key challenges. The most cited paper in the field that we consider a seminal work is “On the Naturalness of Software” [
11], which, to the best of our knowledge, is one of the first approaches to investigate the source code properties in terms of statistical analysis. The authors view the source code as an act of communication and try to answer the following questions:
Is it [source code, author’s note] driven by the “language instinct”? Do we program as we speak? Is our code largely simple, repetitive, and predictable? Is code natural? … Programming languages, in theory, are complex, flexible and powerful, but, “natural” programs, the ones that real people actually write, are mostly simple and rather repetitive; thus they have usefully predictable statistical properties that can be captured in statistical language models and leveraged for software engineering tasks [11].
Authors suggest that source code presents repetitiveness at multiple levels (lexical, syntactic, semantic). This property can be exploited to improve a wide range of applications they list in their article. Along with the paper, the authors prove this claim and report several examples of application problems. They start by introducing the n-gram model, a statistic-based language model. The goal of the model is to estimate the probability of a token (the smaller part of a string with a lexical meaning) to be present after a sequence of n other tokens using conditional probability. Cross-entropy can be used to measure the goodness of a language model. The main problem of this approach is the high number of coefficients to learn, which grows exponentially.
More formally, the n-gram model can be summarised using the Equation (
1): we have a model
M that gives the N-gram probability
to a document
s. The document consists of a sequence of
n tokens
and has an entropy
. Each token
has the N-gram probability
Using cross-entropy, the authors compared the naturalness of code with “English texts”. Very important in this field is the choice of a dataset. In the following sections, we will see how important and difficult it is to create a good dataset. In [
11], the authors used the Brown and the Gutenberg corpus for the English part. For the source code part, they used a collection of 10 Java projects and a collection of C programs from Ubuntu categorised into 10 applications families.
The first test was the computation of the self cross-entropy, for English and Java datasets, of n-gram models using a different n-gram depth: N from 1 to 10. The cross-entropy for the English dataset is about 10 bit for the n-gram model with and rapidly shrinks to 8 bit when . The cross-entropy for the Java dataset is about 7 bit for the n-gram model with and rapidly shrinks to 3 bit when . This gives two important results: (i) Increasing N decreases cross-entropy (ii) Java has a much lower self cross-entropy than English. The first results suggest that both datasets have some regularities better highlighted using more complex models (increasing N). The second results suggest that source code is more regular than English. Using this evidence, they develop a code-typing suggestion engine in Eclipse using a 3-gram model able to beat the Eclipse standard code typing suggestion engine.
Barr ET. and Devanbu P. authors of “On the Naturalness of Software” [
11] with Allamanis M. and Sutton C. in 2018 published “A Survey of Machine Learning for Big Code and Naturalness” an extensive literature review on the probabilistic model for programming languages [
6]. The aim of [
6] is to provide a guide for navigating the literature and to categorise the design principles of models and applications. Their hypothesis, expressed in their introduction, can be summarised in the following statements: Formal and logic-deductive approaches dominate research in programming languages. The advent of open-source, and the availability of a large corpus of source code and metadata (“big code”), opens to new approaches to develop software tools based on statistical distribution properties. Using Amdahl’s law, they justify the approach to extract knowledge from “thousands of well-written software projects” on which statistical code analysis techniques are applied. By mediating the information extracted from many codes, it is possible to obtain knowledge that then helps to improve the average case. In this work, the authors define the
Naturalness Hypothesis:
Software is a form of human communication; software corpora have similar statistical properties to natural language corpora; and these properties can be exploited to build better software engineering tools [6].
They view software as the connection between two worlds: The human mind and computers. This bimodal property of the code defines the similarity and the differences between natural languages and programming languages. The main differences are the following properties of code:
Executability A small change in the code produces a big change in the code meaning. Thus, a probabilistic model requires formal constraints to reduce the noise introduced. Moreover, the executability property determines the presence of two forms of code analysis, static and dynamic.
Formality Unlike natural languages, programming languages are not written in stone and do not evolve over centuries. They are built as mathematical models that can change drastically over time. Moreover, the formality property does not avoid the semantic ambiguity of some languages due to some design choices (such as polymorphism and weak typing).
Cross-Channel Interaction The source code has two channels: algorithmic and explanatory. These channels are sometimes fused (e.g., explanatory identifiers). A model can exploit this property to build more robust knowledge.
The authors, then, provide a taxonomy of probabilistic models of code. They define three groups: Code-generating models, Representational models, Pattern mining models. The models of the first group aim to learn a probability distribution of code components and use this knowledge to generate new code. While the goal of the first group is to generate something (code, documentation, etc.), the second group aims to create a representation of the code to provide some information or prediction to the user. Instead, the pattern mining models try to infer the latent structure of the code to expose patterns and other information in an unsupervised fashion.
In the first category, code-generating models, the authors view the models as a probability distribution that describe a stochastic process for generating code. Equation (
2) formalises this concept, where
is a conditional probability distribution given a dataset
D,
c is a code representation and
is a code context.
They distinguish the models based on how the source code is represented and the type of context information provided. The source code can be represented using the following abstraction level: Sequences (Token-level Models), Trees (Syntactic Models), and Graphs (Semantic Models). A large portion of identified works use Token-level Models (character or token). Some works use Syntactic Models or a hybrid composition of Syntactic and Token-level Models. Furthermore, considering a graph as a natural representation of code, they did not find works using Semantic Models for this category.
The context information can be mathematically described using a context function. The context function identifies three model categories: (i) The model is a pure “language model” when (no external information is provided) (ii) The model is a “transducer model” when is itself code (iii) The model is a “code-generative multimodal model” if the context is provided but it is not code.
In the second category, representational models, authors collected methods capable of transforming a code into a representation that describes their properties. Equation (
3) formalises this concept, where
is a conditional probability distribution,
is a feature vector and
is a function that maps the code
c to a representation.
They define two independent categories for the identified models: (i) Models able to obtain distributed representations of the code and (ii) models able to obtain a structured code prediction. A single model may belong to both categories. The first category aims at representing source code in algebraic structures as vectors or matrices. In this way, the information is projected in a multidimensional metric space. In these methods, the function is defined as where d is the number of dimensions of the representation vector and C is the set of source code. This category consists mainly of deep learning models. In fact, most deep learning models work on algebraic representations of data, on which operators can be easily applied, and the gradients can be conveniently calculated. The structured prediction models instead generalise the classification task. A model that belongs to this category can classify portions of the input, taking into account the inherent structural relations (and structural constraints) of the input data and the desired output, such as during grammatical analysis of the text.
On the other hand, the third category (pattern-mining) includes models that can discover patterns in the code in an unsupervised manner. Equation (
4) formalises this concept, where
is a conditional probability distribution,
is a function that maps the code
c to a representation,
is a function that extracts partial information from the code and
X is the latent representation set that the model wants to learn.
The authors highlight the difficulty in building models belonging to this category, given the unsupervised nature of the task and the requirements of models (belonging eventually to other categories), helping to provide a definition of and .
In conclusion, the authors provided a good classification of statistical models for source code analysis and manipulation. Their taxonomies can be helpful to clarify the advantages and disadvantages of each model and when it can be used, or how it can be adapted for a specific problem or application.
In contrast to the Allamanis et al. survey, the work of Ashouri AH. Killian W. Cavazos J. and Palermo G. entitled “A Survey on Compiler Autotuning using Machine Learning” [
7] is more focused on machine learning techniques applied to compiler problems such as auto-tuning. Their aim is not to categorise a broad spectrum of models but to focus on the works facing optimisation-selection and phase-ordering problems of compilers.
Authors introduce the concept of the compiler optimisation phase as a subsequent ordered application of a certain number of optimisation steps at different levels of compiler layers (front-end, intermediate-representation (IR), and backend) to transform the code into an enhanced version of itself. The “enhanced version of code” is such if some performance metric is optimised, for example: Execution time, code size, or power consumption. They highlight key problems in this field; the optimisation steps can be language or architectural specific, an optimisation step can degrade the performance of the code if it is applied with wrong parameters or in the wrong order. For these motivations, they identify two major problem sets: Optimisation selecting (which optimisation step to use and which parameters to use) and Phase-ordering (in which order to apply the selected optimisation steps). The first problem has an exploration space where m is the number of parameters of an optimisation step and n is the number of optimisation steps. The second problem has an exploration space where n is the number of optimisation steps and L the maximum sequence length desired, with repetitions allowed.
The authors then introduce the concept of an auto-tuning framework. From a corpus of code divided into training-set and test-set, the training-set is compiled using a sequence of optimisations (chosen by an “optimisation design” component) and executed to evaluate the “objective metrics”. These metrics are then used to train a machine-learning algorithm, which is fed by the source code features extracted by a feature-extraction procedure. The machine learning algorithm is then tested using the test set. The first step, as already discussed in [
6] is to extract a feature vector for the source code. The authors divide the techniques into three categories: Static, Dynamic, Hybrid. The static analysis includes features based on source code information extracted directly from the text or provided from compilers and features based on graph structure of the code (Data Dependency Graph, Control Flow Graph), again extracted using compiler tools. Instead, dynamic features can depend on the execution flow in specific hardware (architecture-dependent) or can be extracted using specific code instrumentation to obtain architecture-independent features.
Then, the authors of [
7] categorise some models based on the learning paradigm. In the unsupervised category, they identify two subcategories: Clustering and Evolutionary Algorithms. Of particular interest to the community is the second category, to which Neuro Evolution of Augmenting Topologies (NEAT) and other genetic algorithms (GA) belong [
34]. In the supervised category, we can find well-known machine learning models such as Bayesian Networks, Linear Models and SVMs, Decision Trees and Random Forests, and Graph Kernels. Therefore, this work makes it possible to define better the context of code analysis research for compiler optimisations and collects works by target architecture (Embedded, Desktop, HPC) and compiler (GCC, LLVM, ICC, etc.). More details, in this specific field, can be found in [
7].
Contemporary to [
7], Wang Z. and O’Boyle M. in “Machine learning in compiler optimisation” [
8] also provided a survey on the specific area of compiler optimisation. In the introduction of [
8], the authors pointed out that the translation carried out by a compiler is a complex task. There are several ways to translate (compile) a code. The objective is to find the optimal translation that maximises evaluation metrics. Here, they emphasise that the term optimal is a misnomer. Indeed, when we refer to an optimal solution, we mean a sub-optimal solution obtained through heuristics. Their primary aims are to demystify the machine learning approach for compilers and demonstrate how this can lead to new and interesting research areas.
The authors summarise in three steps the integration of a machine learning pipeline in a compiler: Feature Engineering, Learning a Model, Deployment. Along with the discussion, they explain that there is not yet the ability to determine which ML model is the most suitable for a specific task. Some models such as Support Vector Machine (SVM) or Artificial Neural Network (ANN) can work with high-dimensional feature space but require a big dataset to work, and deep learning methods require even more data. Instead, more simple models such as Decision Tree (DT) or Gaussian Processes Classifier (GPC) can work with smaller datasets but manage fewer features. This work answers the question: How can machine learning be applied to compilers? What are the main applications? They identified two main categories: Optimising sequential programs and optimising parallel programs. Examples of applications in the first category are optimal loop unroll factor and function inlining, whereas examples in the second category are heterogeneous device mapping, scheduling and thread mapping.
In particular, we are interested in the heterogeneous device mapping problem owing to the relatively extended research paper corpus. Because of the effort required to create, build and profile different versions of the same algorithm for the corresponding heterogeneous targets, a single dataset is used by almost all of these works, presented for the first time in [
35]. On the other hand, the use of a common dataset helps to facilitate comparisons between techniques.
A third category incorporates several works not categorised, such as comment generation and mining API as we have seen in [
6]. Please refer to chapter VI of the survey [
8] for a complete list of works identified by the authors. In conclusion, in [
8] the authors hope that research in this area will lead, in the future, to a better definition of code representation, i.e., one capable of identifying a metric of the distance between programs. The same should be carried out to obtain a representation of the computing capacities of the hardware. In this way, it would be possible to identify relationships between these representations: enabling more effective decisions at the compilation stage.







{kind=link}
{kind=link}