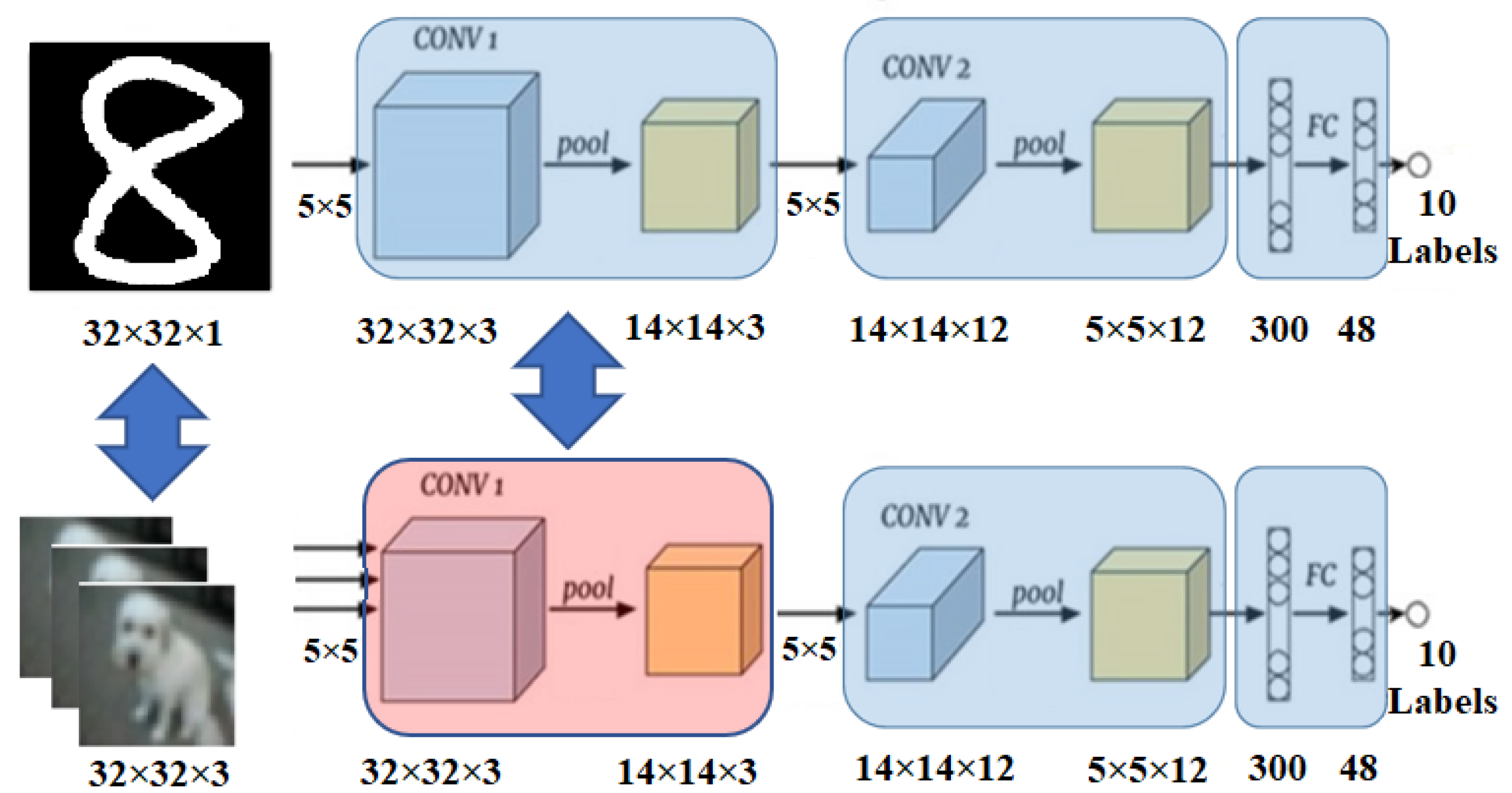
For the proof of concept, two different use cases are implemented on the hardware. In the first use case, three different CNN classifiers trained by three different datasets are designed and switched using DPR for two different scenarios. In the first scenario, a digit classifier trained by the MNIST dataset [
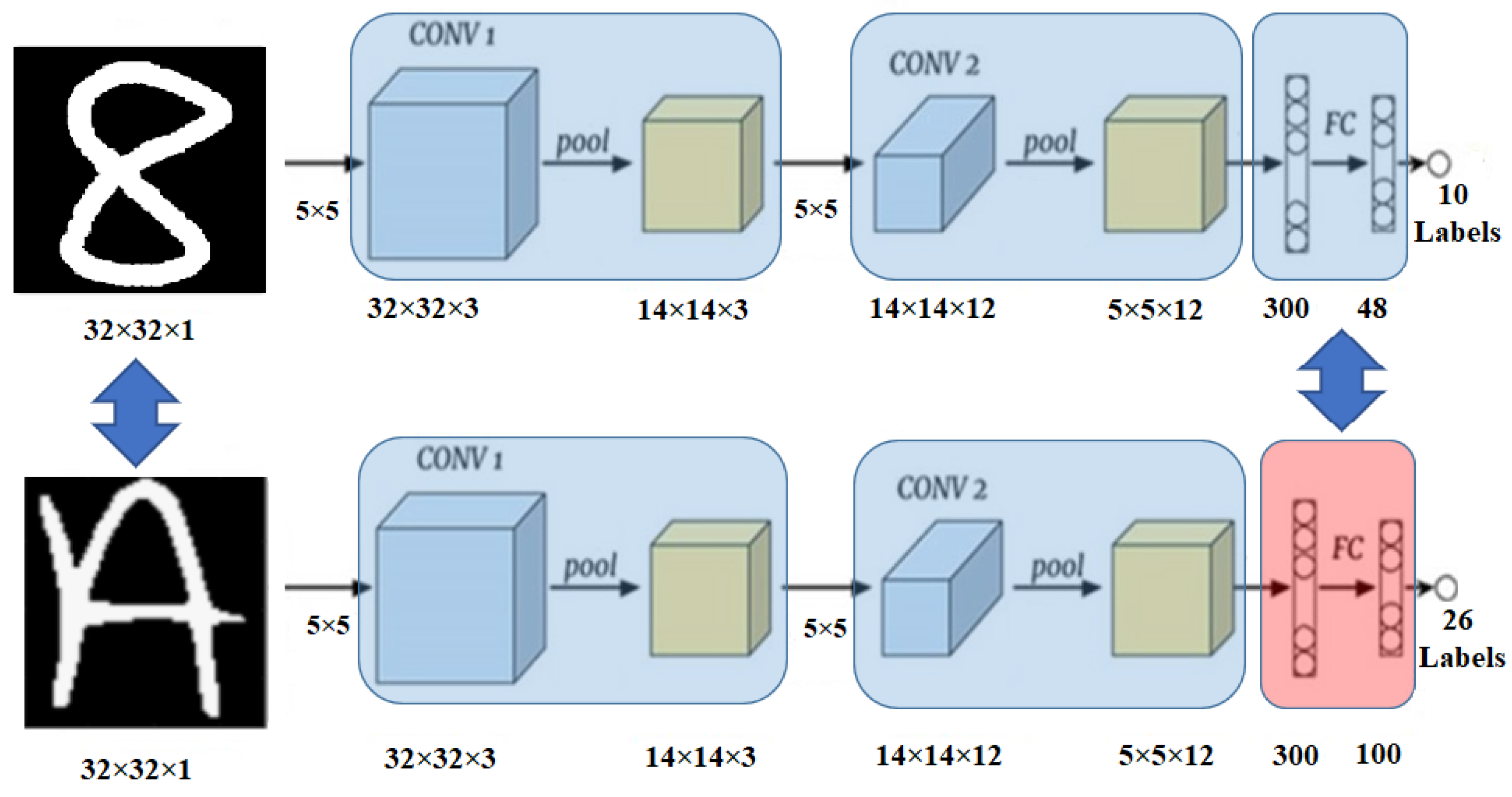
27] and a letter classifier trained by EMNIST dataset [
28] are switched only updating the feedforward layers since the number of classes is different between digit and letter classifiers. In the second scenario, a digit classifier trained by MNIST and an object classifier trained by CIFAR10 dataset [
29] are switched by updating the first convolution layer because the dataset for digit classifier is grayscale whereas the object dataset is an RGB image. Thus, the number of input channels is different, and the first convolutional layers are required to be different. In both scenarios, the weights and biases of the structurally identical layers are updated from the memory-mapped interface of the
PEs and the non-identical layers are dynamically partially reconfigured with the corresponding
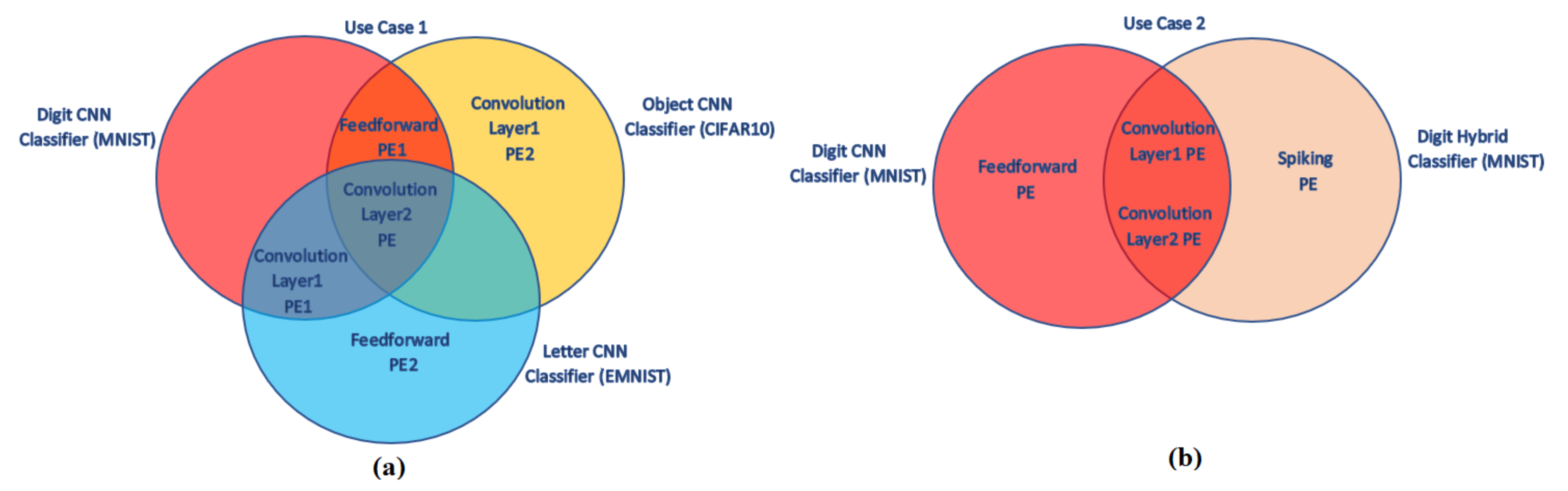
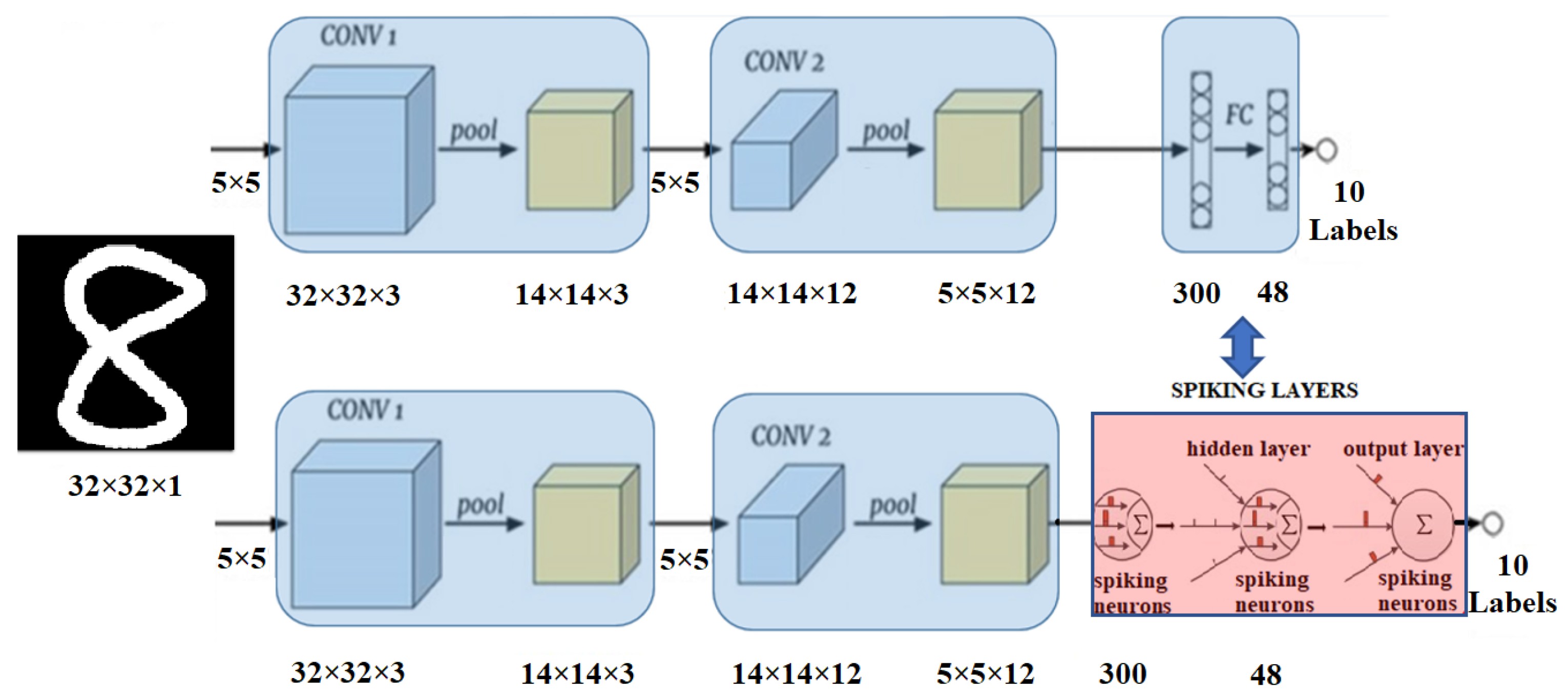
PE. In the second use case, DPR is used to switch between a CNN classifier and a hybrid NN (i.e., consisting of convolutional layers and spiking layers) classifier. Both classifiers are digit classifiers and the convolutional layers of both classifiers have the same structure and use the same weights and bias values. The switching between CNN to hybrid NN is achieved by updating the feedforward layers with spiking layers. The summary of both use cases is given in
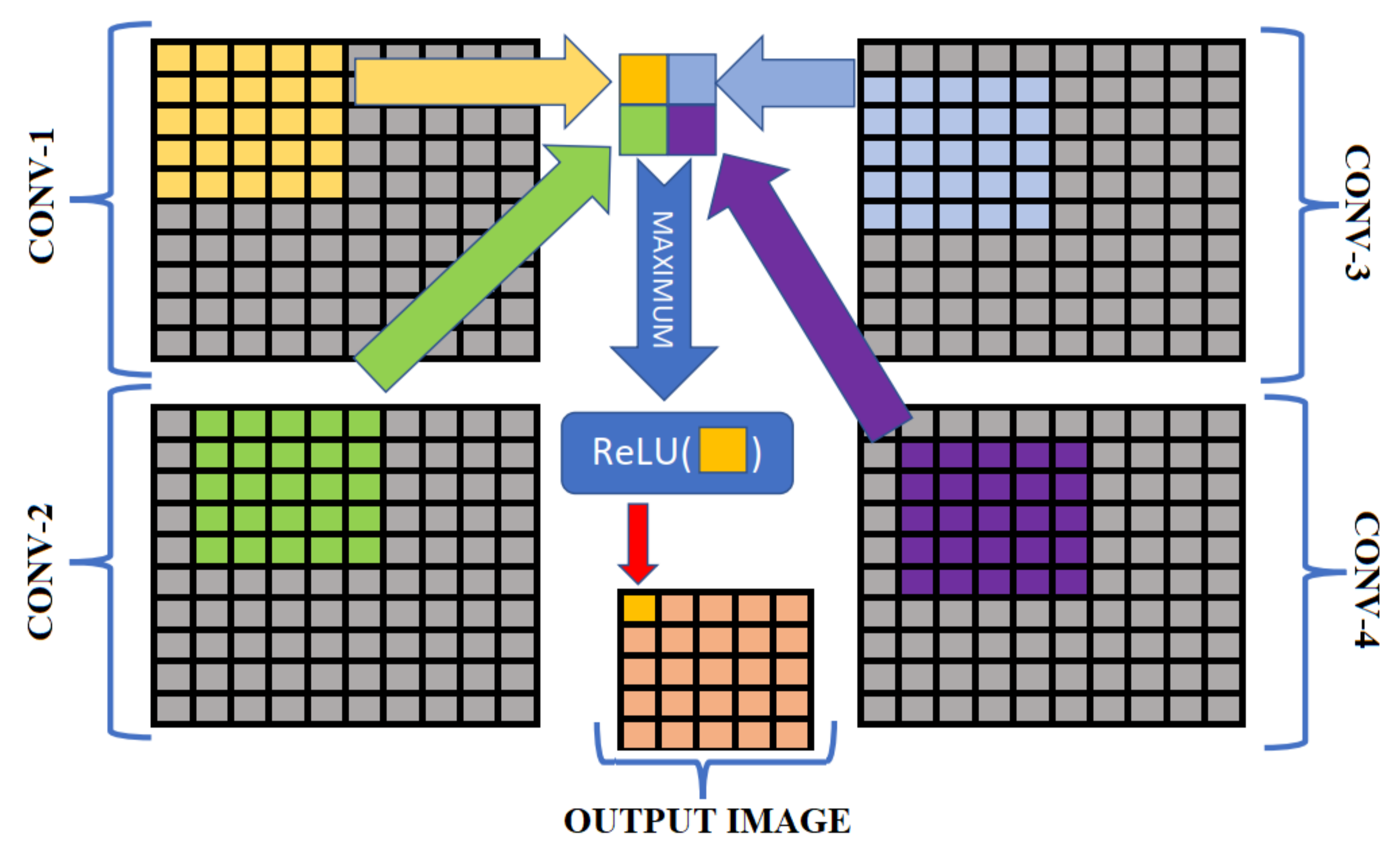
Figure 12. In this figure, intersection parts show the common layers for the classifiers (i.e., static regions) whereas the other parts show the layers specific to the related classifier (i.e., dynamic regions).
3.3. Implementation
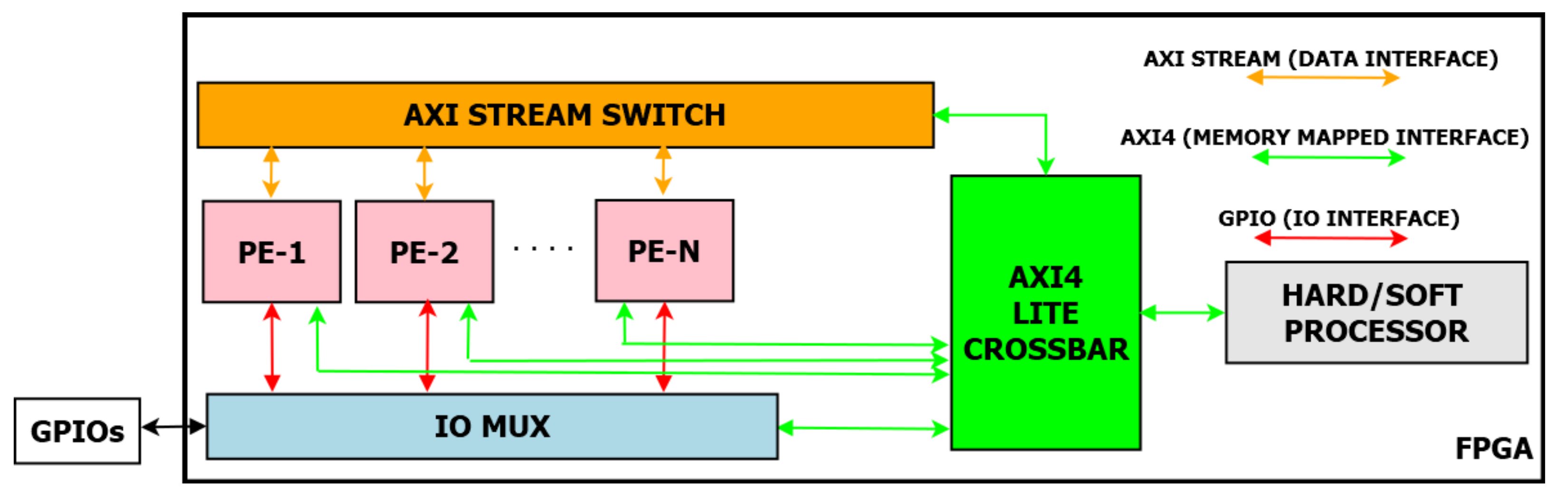
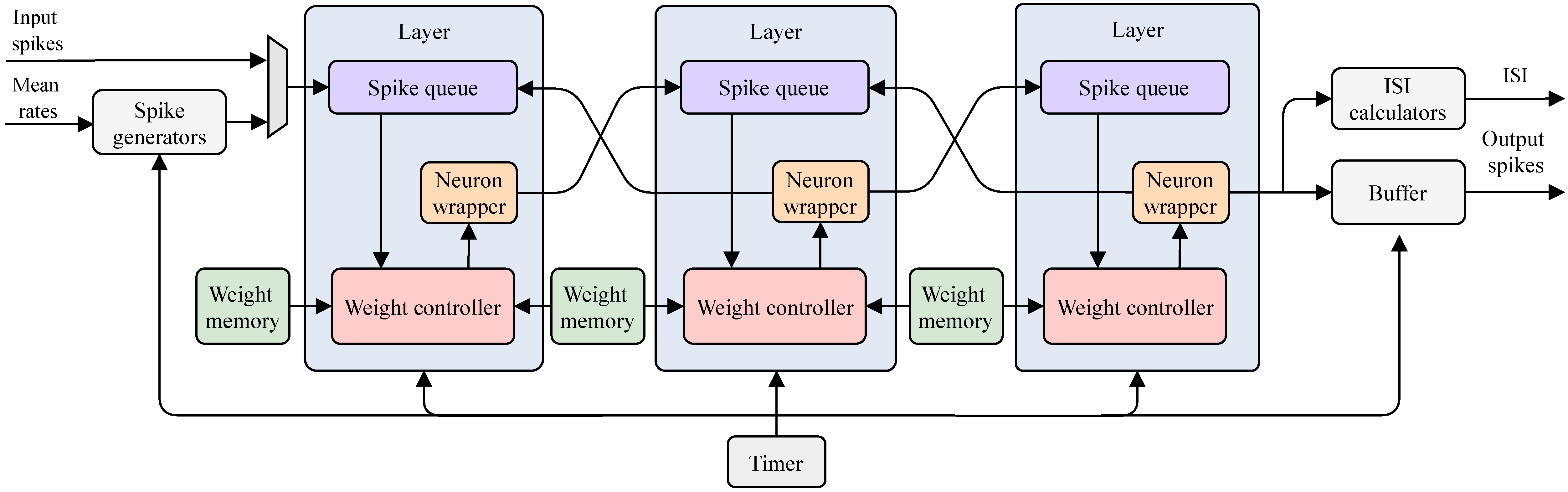
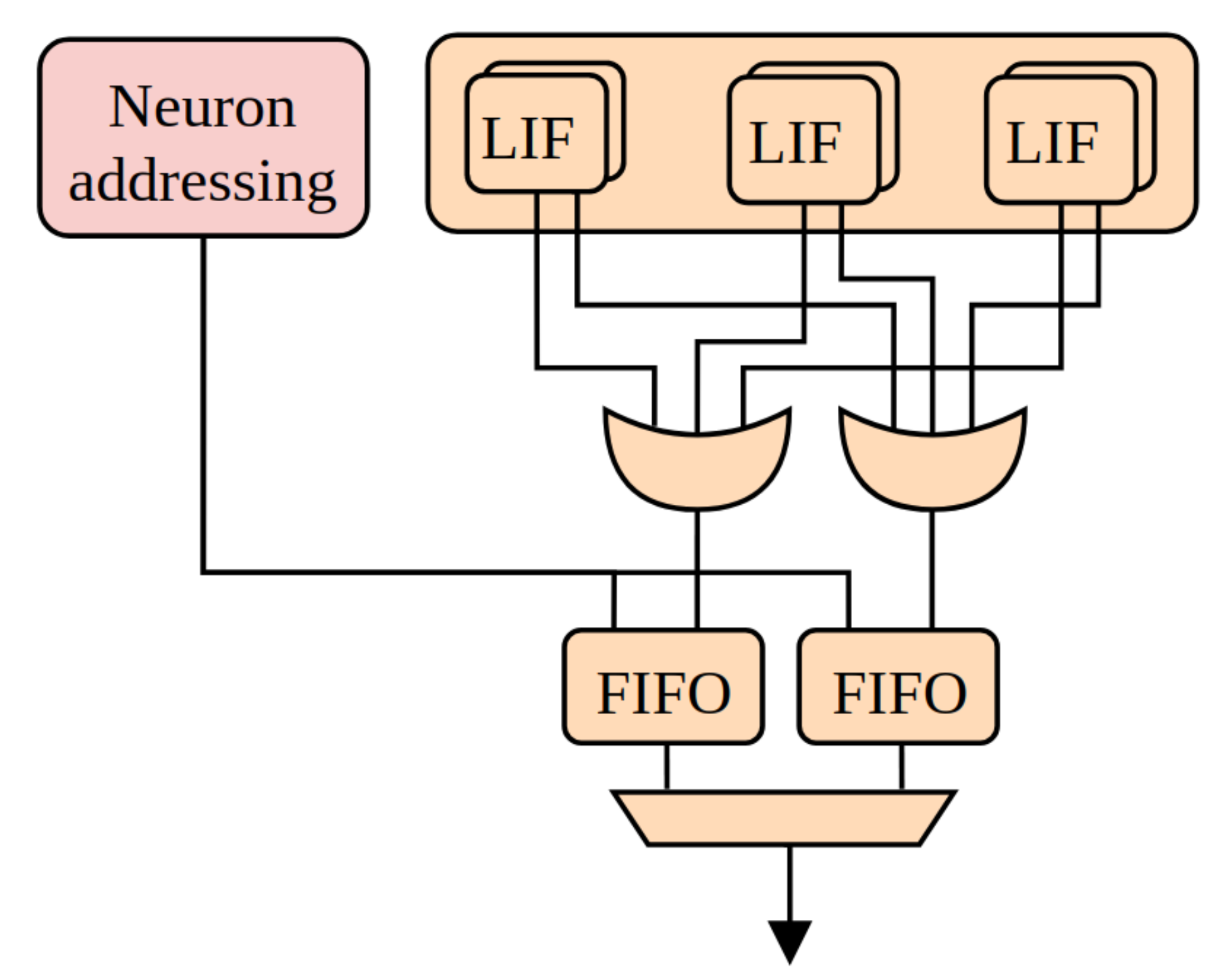
The proposed hardware architecture in
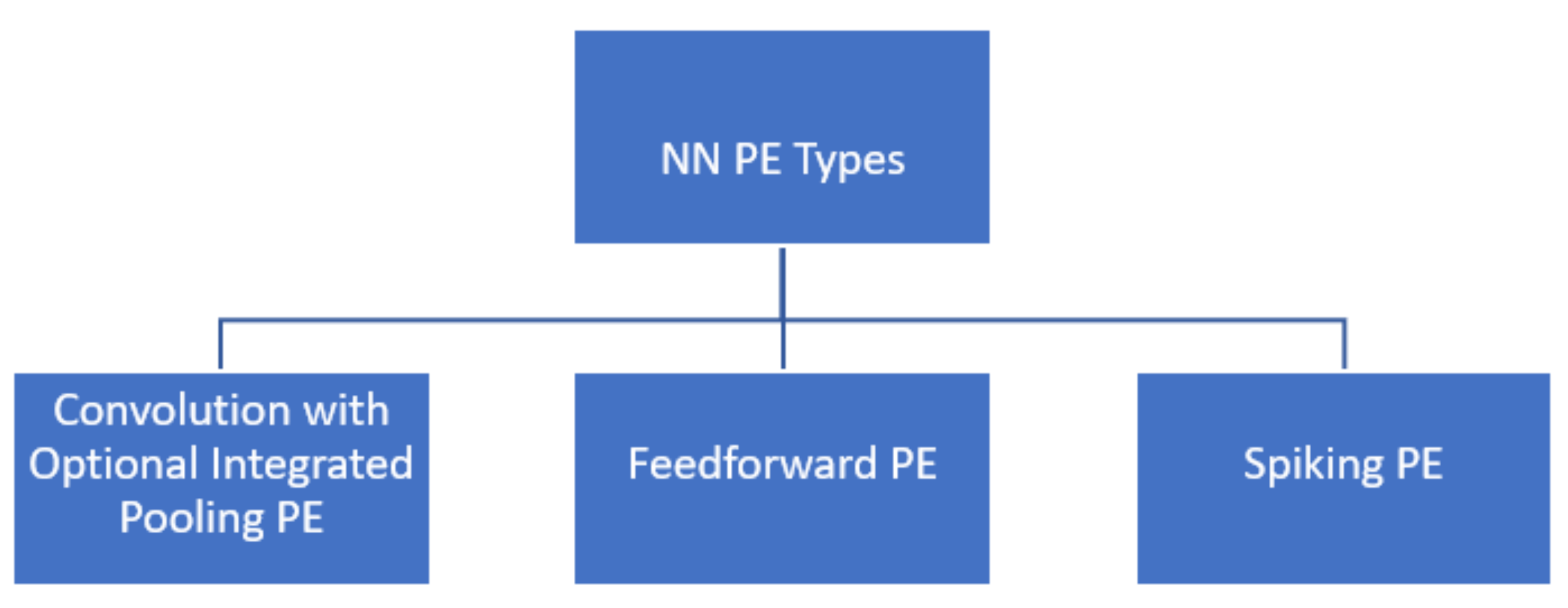
Figure 4 is implemented using Xilinx Vivado 2020.2. Using the proposed hardware architecture, two different use cases and three different scenarios explained in the previous section are implemented. In total, 5 different
PEs are designed to realize those scenarios. Except for the spiking PE which is a pure VHDL design, all PEs are designed using the Vitis HLS tool, which is used to transform C, C++, and System C codes into the register transfer level implementations [
30]. The PE designs are first verified in the simulation environment. Then, they are implemented and tested on a Zedboard FPGA board [
31] which is equipped with a Xilinx Zynq 7020 FPGA. The summary of the resource usage of each
PE can be seen in
Table 1. As shown in
Table 1, the resource usage is dominated by the Convolution PEs in the NN architectures. In addition, Feedforward PEs use moderate DSP usage with the minimum deployment of LUTs and FFs since the main computation is the matrix multiplication in Feedforward PEs. On the other hand, the Spiking PE does not use any DSPs because there is no multiplication in the spiking layers. However, it consumes more logical resources, such as LUTs and FFs.
In each scenario, to switch one classifier to the other classifier, only a single
PE is updated using DPR. However, for another application, more than a single
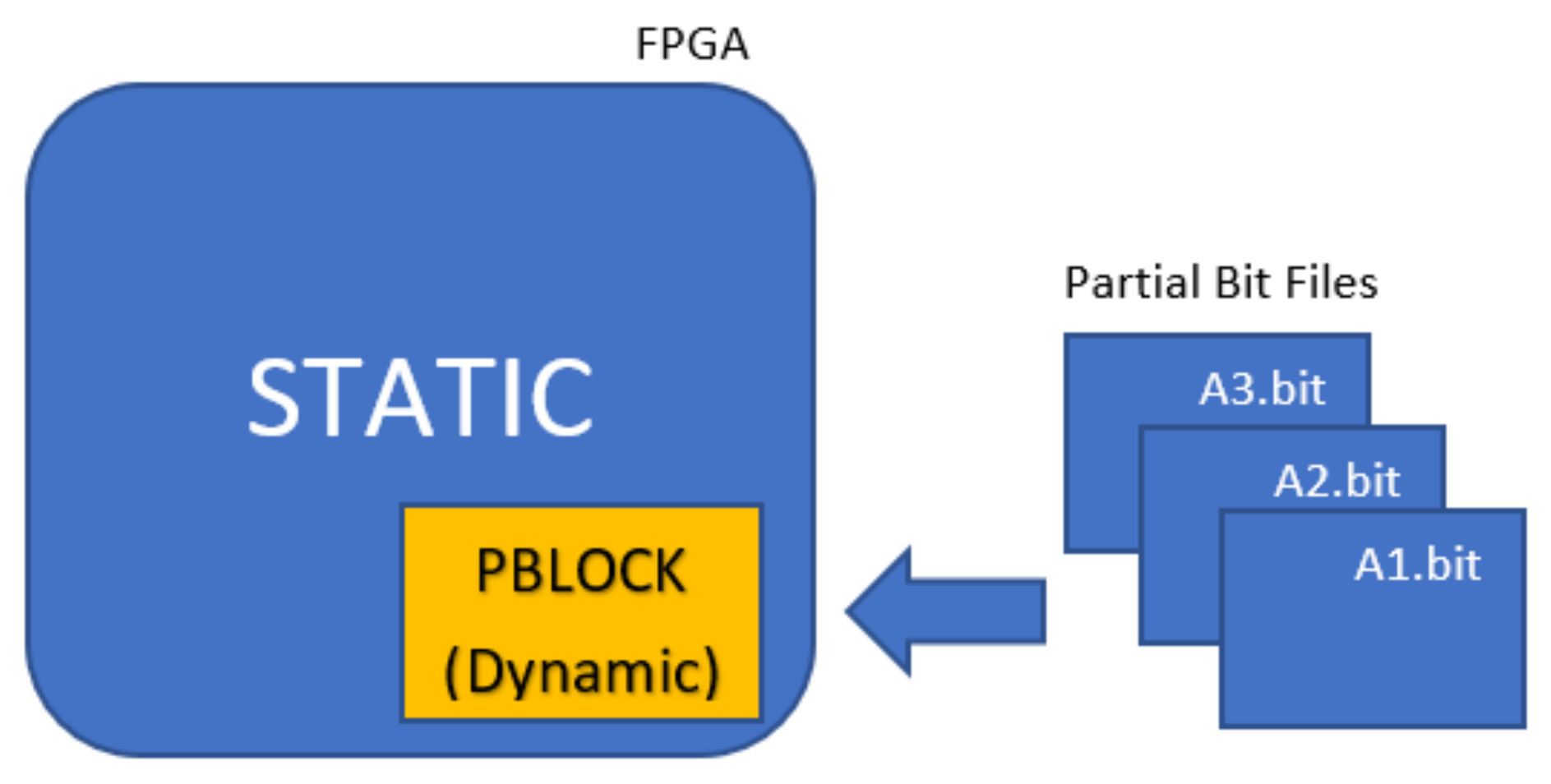
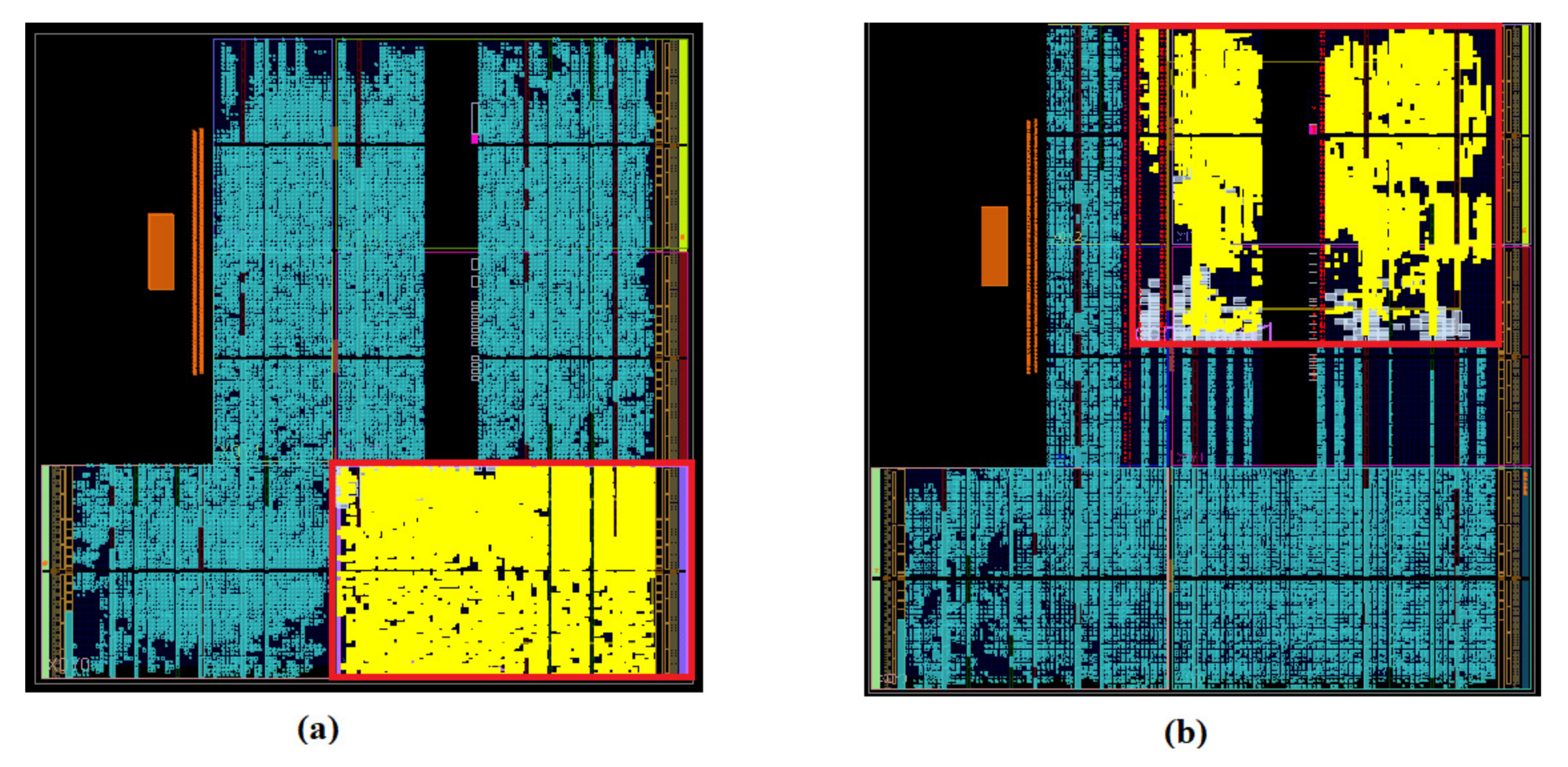
PE could be updated as well. For the DPR, Vivado’s partial reconfiguration flow is used. The size and location of the
Pblock of the corresponding
PE is determined according to the resource utilization of the related layer of the NN accelerator. In the use cases, two different
Pblocks are defined. The first
Pblock is for the last layer of Digit CNN Classifier/Digit Hybrid Classifier/Letter CNN Classifier. The second
Pblock is for the first layer of Digit CNN Classifier/Object CNN Classifier. Except for the
Pblock, the remaining layout of the implementation is static. Thus, only
Pblock is placed and routed again for the new scenario realizations. The layout of the implemented NN classifiers and the location of the related
Pblocks can be seen in
Figure 16.
In the hardware tests of the scenarios, the input images are loaded from the serial port of the Zedboard and the results are written to the registers of the final
PE in the chain. The registers are read from the memory-mapped interface of the
PE. In addition, the internal data transfers between
PEs are tested on the system using Vivado Hardware Manager. All the implementations operate at 100-MHz clock frequency.
Table 2 provides resource usages of the classifier accelerator implementations: Digit Classifier (CNN), Letter Classifier (CNN), Object Classifier (CNN), and Digit Classifier (CNN + SNN). In this table, the hybrid classifier DSP usage is the lowest since spiking layers do not use any DSP because there is no multiplication operation in the computation of the spiking layers. However, it consumes more LUTs and FFs since some of the LUTs and FFs are used to convert the feature maps to the spikes in Spiking PE. Moreover, the Digit Classifier CNN uses fewer BRAMs than the other CNNs as it has fewer nodes in the Feedforward
PE for the output layer and fewer channels in the Convolution PE for the input layer. Lastly, the Object classifier has the highest DSP usages among them because three-channel classifiers require more multiplications in the input layer in comparison with the one-channel classifiers.
3.4. Evaluation
To conduct a fair performance evaluation of the proposed architecture, we compare the performance of our digit CNN classifier with three state-of-the-art digit CNN classifiers, trained by the MNIST dataset and using the same CNN architecture (i.e., two convolutional layers, two pooling layers, one hidden layer). The first accelerator is a static CNN accelerator [
32]. In that study, a ZCU102 evaluation board is used for the implementation. For each convolutional layer and pooling layer, separate accelerators are designed. The second accelerator is a DPR design, and according to the energy level of the power source, the processing system uploads the required partial bitstream at run time using ICAP [
17]. The last work is using cascaded connections of processing engines designed to compute the convolution [
33]. Pipelining and tiling techniques are used to improve the performance of that design. The performance comparison with these digit classifier accelerators is given in
Table 3. As can be seen from
Table 3, our proposed digit classifier accelerator has the shortest processing time to complete the classification of an image due to the hardware optimizations in the
PE designs that allow for a considerable throughput improvement with using less number of DSPs in comparison with the other accelerators. However, the LUT usage is slightly higher than the other designs because of the implementation of the components for the flexibility of the proposed hardware architecture.
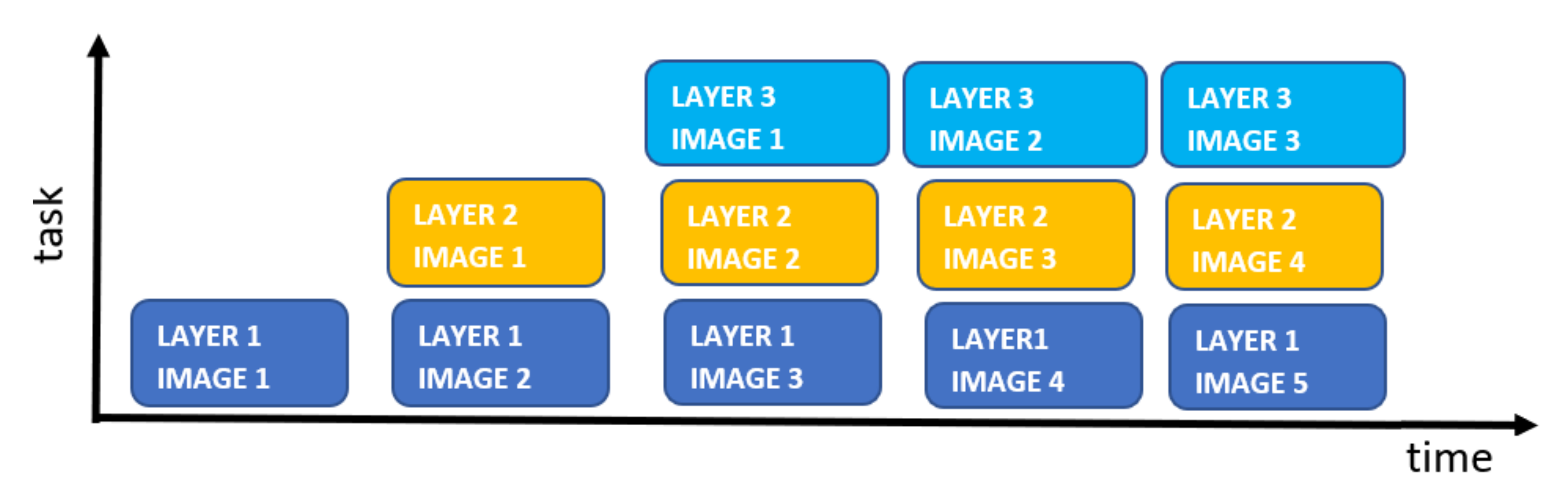
In the proposed architecture, all data is processed in a pipelined manner. Although the total processing time is 62
s for the digit classifier; the accelerator can be fed with a higher frame rate. Every
PE can process new data after finishing its task, i.e., there is no need to wait until the end of the overall processing of one image to proceed with the next. As shown in
Figure 17, the overall frame rate only depends on the processing time of the
PE with the largest delay which is 22
s (processing time of Feedforward
PE for the digit classifier CNN). Therefore, using the pipelining in
Figure 17, the proposed accelerator architecture achieves frame rates of up to 45K images/sec in digit classification which is 7× higher than the state-of-the-art digit classifier accelerators given in
Table 3.
Using the DPR concept in the proposed architecture has two main advantages. Firstly, instead of training different datasets together, realizing specialized classifiers as different NN greatly increases the accuracy in each task.
Table 4 shows the accuracy of three different implementations. In this table, the Character Classifier-1 is a mixed static CNN accelerator trained with both letter and digit datasets together. On the other hand, Digit Classifier and Letter Classifier in
Figure 13 are two distinct CNNs. The switching between the digit classifier and the letter classifier is achieved using DPR, reconfiguring only some network layers. The accuracy of the Character Classifier-1 drops by 5% and 10% compared to the specialized letter and the digit neural network models. The increased difficulty causes this drop in performance for a single neural network that needs to learn multiple tasks.
The second advantage of using DPR is the reduction in power consumption. Without sacrificing the accuracy and throughput, a NN design can be realized by using separate Feedforward PEs for digit classifier and letter classifier respectively. Since the proposed architecture allows to change the connection at run time, the classifier can be switched to the related Feedforward PE by updating the connections in the AXI stream switch in the proposed architecture. Thus, the accuracy and execution times remain the same as the digit and letter classifiers given in
Figure 13. However, instantiating both Feedforward PEs in the same implementation results in an increase in resource usage and power consumption compared with the DPR implementations as shown in
Table 5. In the table, Character Classifier-2 is a classifier design instantiating the Feedforward PEs of the digit classifier and letter classifier in the same implementation. Thus, as clearly seen from
Table 5, using DPR makes the design more energy- and resource-efficient compared with the design having both Feedforward PEs. There is a 7% and a 10% decrease in the power consumption of programmable logic in DPR designs as compared to the static design having digit and letter classifiers together. For the power consumption of the processor side, since the processor is running with the same frequency with the same software architecture, the power consumption is 1528 mW and is the same for all classifiers. These consumptions are taken by Vivado’s power report of the implemented (i.e., post-routed) design.
There are also some disadvantages of using DPR. First of all, using DPR increases the difficulty of the design process. The size of the
Pblock is to be defined well considering the resource usage of the related
PEs. Moreover, defining multiple
Pblocks requires a careful placement that should allow easy routing and prevent congestion. However, these design difficulties are coped with only once and the location and size of the
Pblocks will probably not be updated unless there are major changes in the design. Besides, another disadvantage of the DPR can be the power overhead during partial reconfiguration. However, as compared with the total reconfiguration of the FPGA, DPR has negligible overhead in terms of power consumption [
34]. Similarly, in [
35], different experiments were conducted to evaluate the power consumption overhead of DPR for Zynq devices and measurements were done for the processor and the hardware logic fabrics in real-time. In that paper, it is noticed that the power consumed by the FPGA is almost unaffected when applying DPR. Thus, it can be concluded that the proposed method has no significant power or energy overhead while realizing different NN accelerators using DPR.
Lastly, in the proposed architecture, the switch time between digit and letter classifiers (i.e., DPR time) is 9.4 ms, and the switch time between digit and object classifiers is 17.1 ms since the PCAP throughput is 145 MB/s [
36] and the partial bit file sizes are 1.37 MB and 2.48 MB for the
Pblocks given in
Figure 16, respectively. However, for full configuration time of Zedboard is around 250 ms [
31]. Therefore, the proposed method can be effectively used, especially in time-critical applications, without wasting the time for updating the whole bitstream. The system can be switched in a very short period of time between digit and letter classifiers only updating the partial bitstream. To do so, in a short response time, the characters can be identified with higher accuracy as compared to the static character classifier designs. However, when the switching between different classifiers is very frequent, the throughput performance may be degraded by the DPR overhead. Since the size of the partial bistream is directly proportional to the size of the region it is reconfiguring, using smaller
Pblock may help to decrease the DPR time. In addition, DPR overhead can also be decreased using compressed partial bit files. Yet, these optimizations have limited improvement on DPR overhead and in order to preserve higher overall throughput, the number of switchings between different classifiers should be kept minimal.
3.5. Evaluation of the Spiking PE
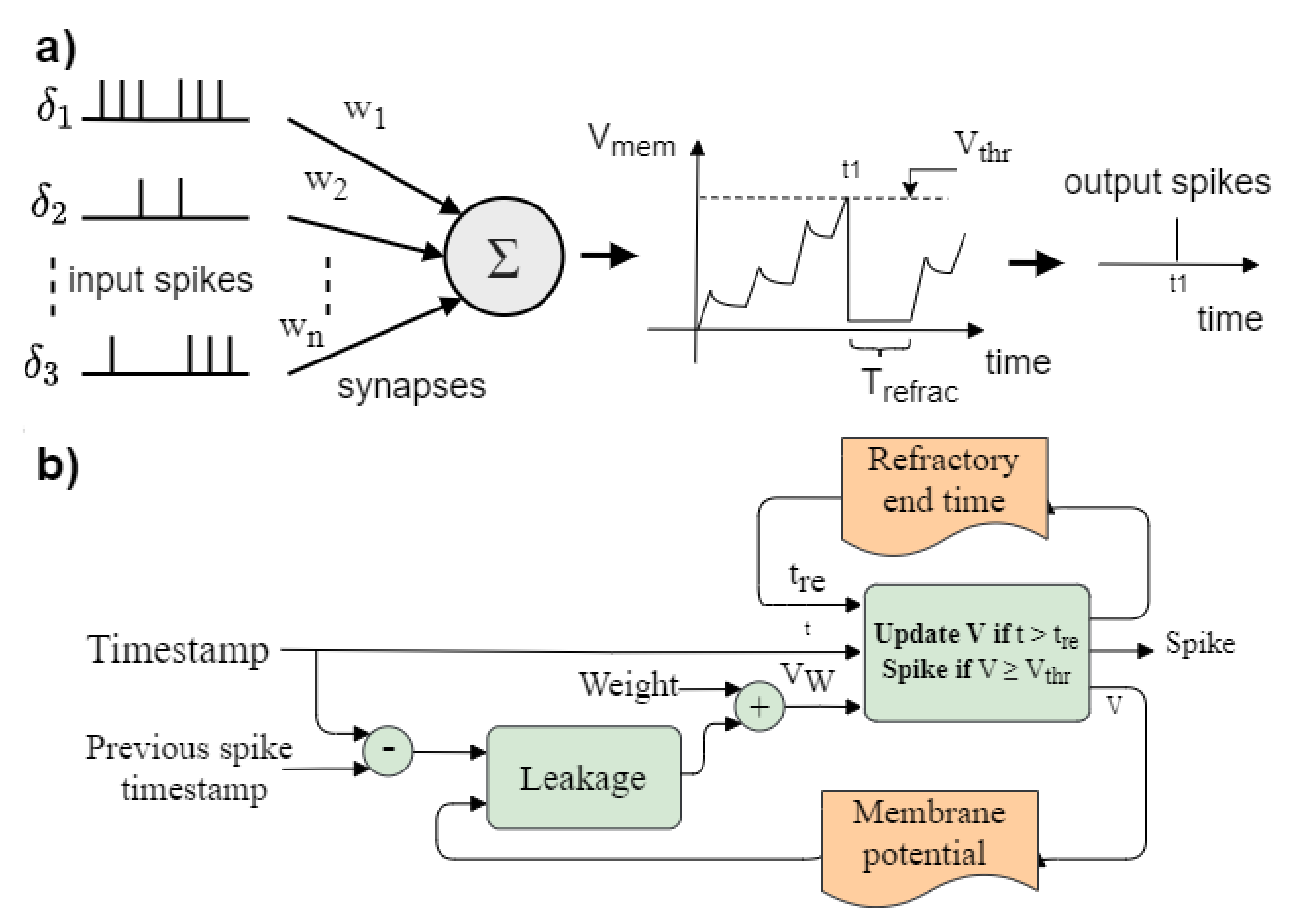
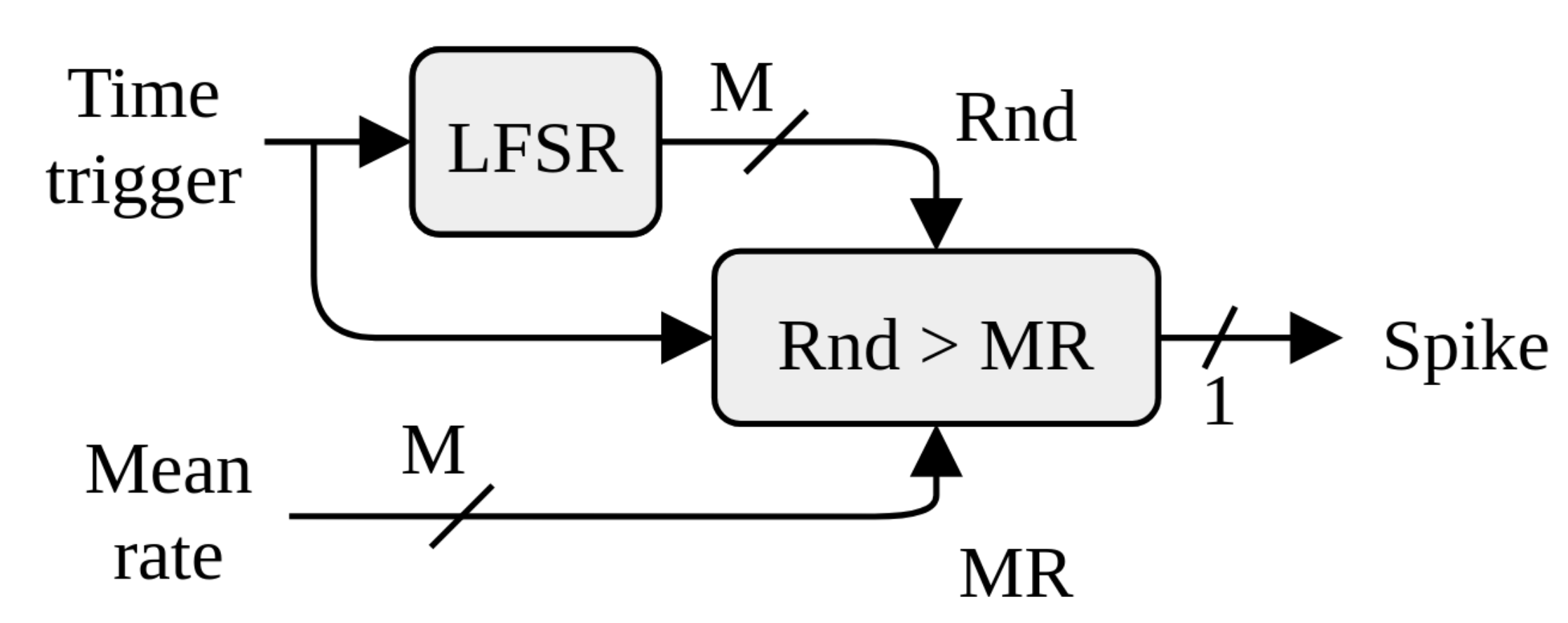
This section compares the spiking PE alone when solving MNIST digit recognition with other spike-based neural network implementations in FPGA. We have implemented a feed-forward network of four layers connected to the 784 input pixels from the MNIST images. The layer size is 784-720-720-720-10. Input has been provided with the mean-rate generators on board, and the outputs have been evaluated by means of the ISI calculators blocks. The spiking PE achieves an accuracy of
and a peak-throughput of 40.71 Giga Synaptic Operation Per second (GSOPS) with an efficiency of 0.050 nJ/SO. For comparison,
Table 6 shows a list of recently reported spiking neural networks implemented in FPGA. The Bluehive project [
37] from Cambridge University implemented 256,000 Izhikevich neurons with 1000 synapses each by interconnecting four FPGAs that each contains 64,000 neurons. Minitaur [
9] and its improved version n-Minitaur [
38] build upon [
39] and operate event-driven. They both time-multiplex 32 physical Leaky-Integrate-and-Fire (LIF) neurons to emulate at a maximum of 65,536 neurons. Note that this is the only purely event-driven implementation in the reported work. In [
40] the Efficient Neuron Architecture (ENA) is proposed, which consists of layers of neurons that communicate using packets. Using the LIF model and 32-bit precision, it promises to emulate 3982 neurons and 400 k synapses. The authors implemented only three neurons, though. In [
41] an FPGA Design Framework (FDF) is proposed that time-multiplexes up to 200,000 neurons with one physical conductance-based neuron. Furthermore, a network is presented that consists of 1.5 M neurons and 92 G synapses on an FPGA. Only the most significant bits of the exponential decay are stored to reduce memory usage, and the least significant bits are stochastically generated. The same authors emulate 20 M to 2.6 B neurons in a so-called Neuromorphic Cortex Simulator (NCS) [
42] using only one FPGA. There is a significant drop in performance, which is likely a result of using off-chip memory, but that increases the supported network size.
Digital ASIC implementations supporting spiking networks and can be extremely power- and energy-efficient [
45,
46,
47]. In ODIN [
45], an open-source digital implementation of a spiking neural network core is presented. ODIN’s design only supports one physical neuron core, but many (virtual) neurons can be simulated. Neuron states, as well as synaptic weights, are stored in an on-chip SRAM memory. A state machine takes care of time-multiplexing multiple virtual neurons and executes them in one physical core sequentially. This choice results in a low-area and low power design with the number of events per Synaptic Operation (SOP), which is in the order of ∼10 pJ/SOP at about 100 Mhz. ODIN has demonstrated an accuracy of
on MNIST using 4-bit synapses and one physical neuron simulating 256 virtual neurons. In contrast, our spiking PE achieved
accuracy on MNIST—a significantly better result achieved through the fully parameterized digital implementation tailored to high-level abstraction designs. The behavior agreement on application and RTL level allows the application specialist to optimize the number of bits per synaptic contact, threshold parameters, and network structure (number of neurons and layers) for better accuracy with fewer resources. Special attention is paid to the memory allocation of synaptic weights to provide the required throughput with minimal resources. Another recent digital ASIC has been presented by Intel [
46], and it is named Loihi neuromorphic processor. The Loihi processor exploits a similar concept in which a neuron core emulates many (virtual) up to 1024 neurons and many (virtual) synaptic connections. Time-multiplexing methods exploit timing slack provided by digital silicon speed and constantly shuffle neuron’s membrane potential and synaptic weight memory from/to a central memory. The Loihi architecture hosts multi-neuron cores whose role is the emulation of a part of the network, e.g., a layer, which can exchange spikes asynchronously in a packet-switched form through a network-on-chip (NoC). The advantage of the time-multiplexing approach is a higher neuron and synapse density because the computational core is implemented only once, and the neuron states and synaptic weights are stored in very dense memories. However, in contrast to distributed neuron networks, time-multiplexed networks’ performance and energy efficiency are limited by memory bandwidth and lack of parallelism. The distributed neurons offer a high degree of parallelism and reduce the overhead of data movement caused by shuffling of neuron’s membrane potential in exchange for manageable area overhead. Furthermore, the low-power functionality can also be achieved with distributed neurons through voltage scaling, power gating, and clock gating. For these reasons, our spiking PE architecture does not time-multiplex neurons and exploits a layered organization. Another recent digital spiking neural network architecture called
Brain has been presented in [
47]. The
Brain also physically implements each neuron and does not use time-multiplexing, achieving microwatt power consumption for an always-on system of 336 neurons with 19,878 synapses while performing MNIST or radar-based gesture classification tasks.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}