
Reliability-Aware Resource Management in Multi-/Many-Core Systems: A Perspective Paper



Abstract
:1. Introduction
1.1. Need of Reliability in Multi/Many-Core Systems
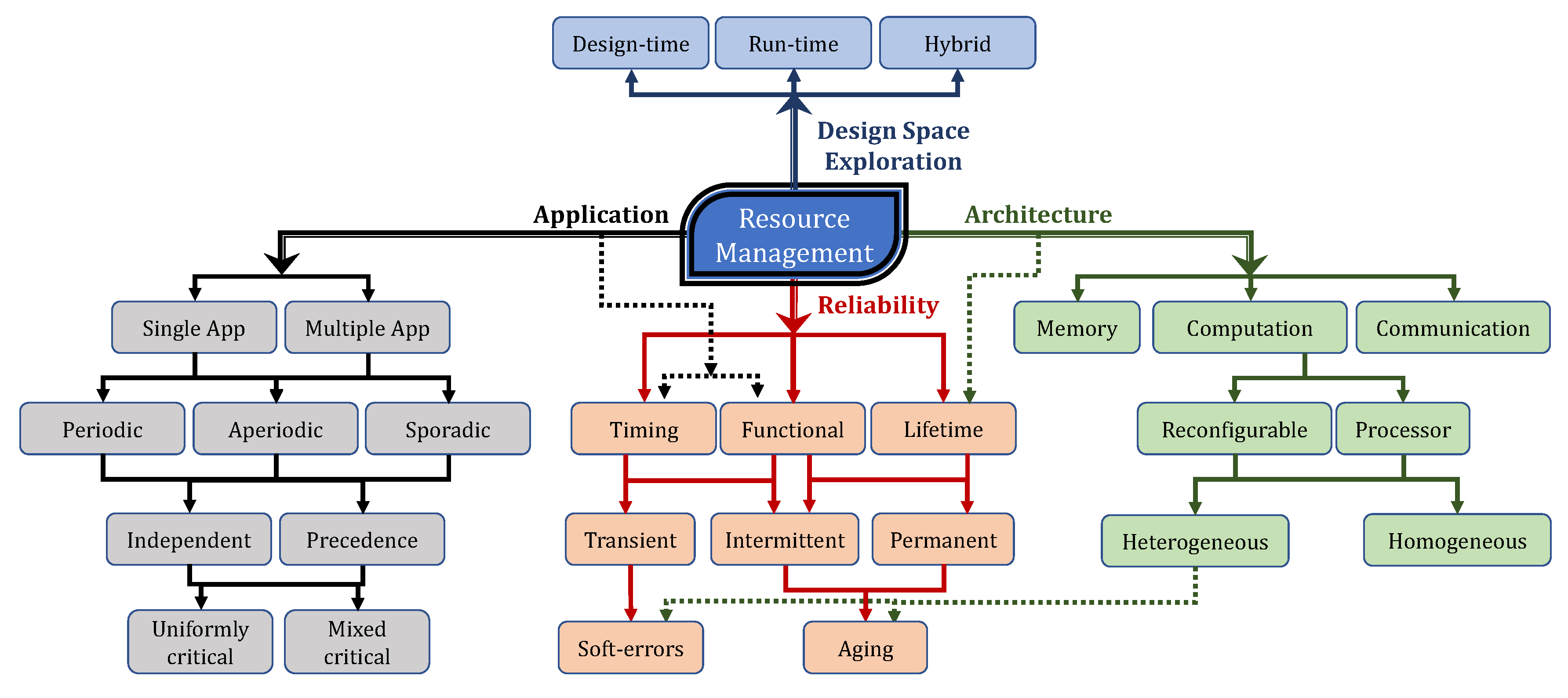
1.2. Reliability-Aware Resource Management in Multi-/Many-Core Systems
- Application Specificity: The varying priority among QoS metrics across different applications presents both a scope for application-specific optimization as well as challenges for ensuring application specific constraints.
- Mixed criticality: Scheduling tasks with different criticality levels on a common platform is challenging, in which executing the tasks must be guaranteed in terms of both safety and real-time aspects to prevent the probability of failure and, consequently, catastrophic consequences.
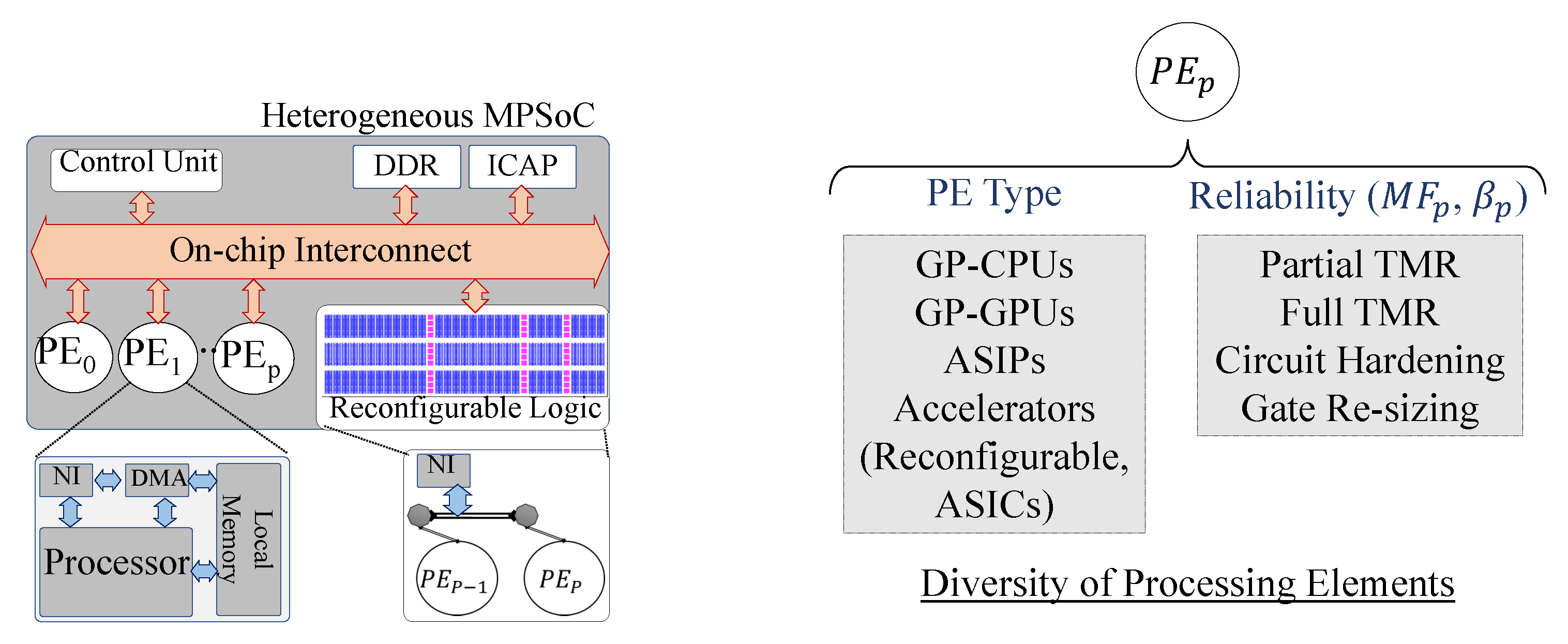
- Resource Heterogeneity: The heterogeneity of cores provides a scope for leveraging the availability of custom hardware implementations. Similarly, the availability of reconfigurable logic provides the scope for implementing accelerators on standard hardware platforms. However, such heterogeneity also introduces additional complexity for ensuring optimal resource sharing.
- Design Space Exploration: All the above aspects introduce additional degrees of freedom in the design space. Consequently, the Design Space Exploration (DSE) for the joint optimization across all these aspects can result in an exponential increase in complexity.
2. Background and Taxonomy for Reliability Management Methodologies
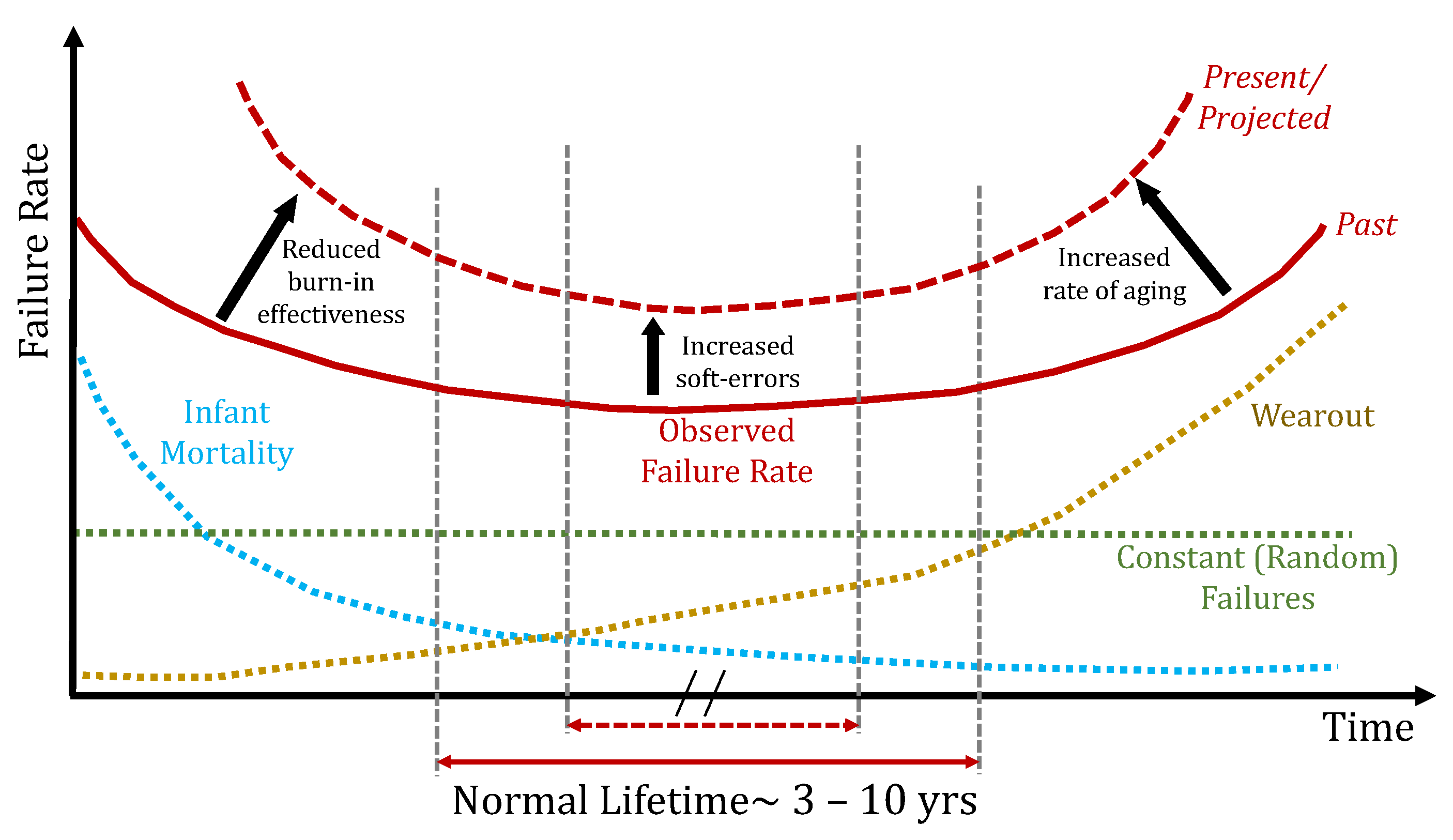
2.1. Reliability in Electronic Systems
2.1.1. Lifetime Reliability
2.1.2. Timing Reliability
2.1.3. Functional Reliability
2.2. Fault Model
- Transient faults occur at a particular time, remain in the system for some period and then disappear. Such faults are initially dormant but can become active at any time. Examples of such faults occur in hardware components which have an adverse reaction to some external interference, such as electrical fields or radioactivity.
- Intermittent faults show up in systems from time to time due to some inherent design issue or aging. An example is a hardware component that is heat sensitive—it works for some time, stops working, cools down and then starts to work again.
- Permanent faults such as a broken wire or a software design error show a more persistent behavior than intermittent faults—start at a particular time and remain in the system until they are repaired.
2.2.1. Soft-Errors
2.2.2. Aging
- Bias Temperature Instability (BTI) results in an increase in the threshold voltage, due to the accumulation of charge in the dielectric material of the transistors [17]. The use of high-k dielectrics in lower technology nodes has resulted in an increased contribution of BTI to aging.
- Hot Carrier Injection (HCI) occurs when charge carriers with higher energy than the average stray out of the conductive channel between the source and drain and get trapped in the insulating dielectric [18]. Eventually it leads to building up electric charge within the dielectric layer, increasing the voltage needed to turn the transistor on.
- Time Dependent Dielectric Breakdown (TDDB) comes into play when a voltage applied to the gate creates electrically active defects within the dielectric, known as traps, that can join and form an outright short circuit between the gate and the current channel. Unlike the other aging mechanisms, which cause a gradual decline in performance, the breakdown of the dielectric can lead to the catastrophic failure of the transistor, causing a malfunction in the circuit.
- Electromigration (EM) [19] occurs when a surge of current knocks metal atoms loose and causes them to drift along with the flow of electrons. The thinning of the metal increases the resistance of the connection, sometimes to the point that it can become an open circuit. Similarly, the accumulation of the drifted material can lead to electrical shorts.
3. System Model
3.1. Architecture Model
3.1.1. Computation
3.1.2. Communication
3.1.3. Memory
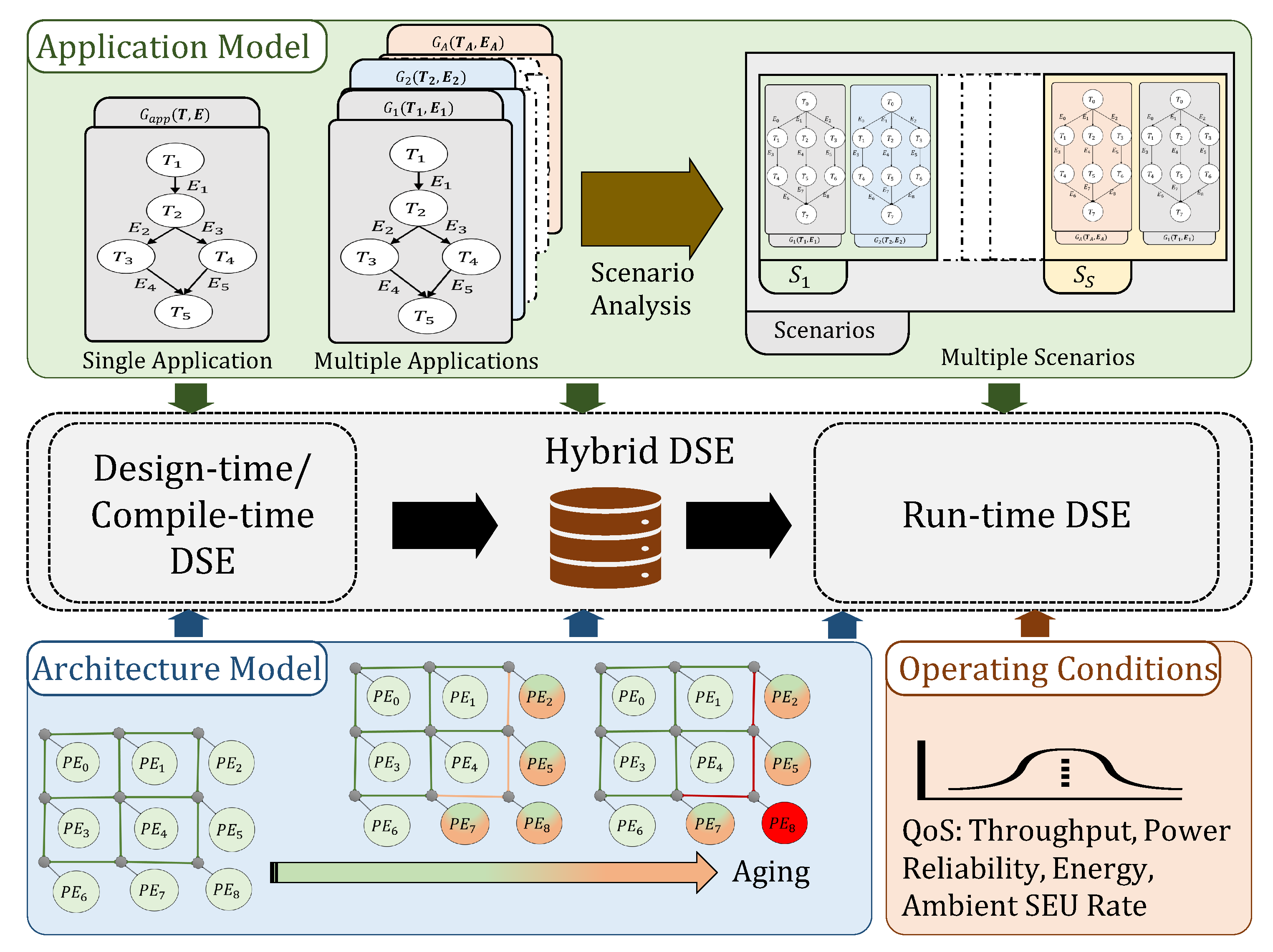
3.2. Application Model
3.2.1. Task Dependencies
3.2.2. Application/Tasks’ Periodicity
3.2.3. Application/Tasks’ Criticality
4. Reliability Management in Multi/Many-Core Systems
4.1. Problem Statement
- Precedence constraints: Any task must start execution only after all its preceding tasks and incoming communication is complete.
- Scheduling constraints: Properties such as each task/actor assigned to a single core, not more than a single task executing on a single core at a time etc. must be satisfied.
- Criticality constraints: PFH and reliability requirements should be corresponded with the criticality levels.
4.2. Classification of Solution Approaches
- Design-/compile-time: In this approach all the design decisions and the related optimizations are performed before the system is deployed. As shown in Figure 7, the related analysis is made under the design-time assumptions regarding both the application workload and the system’s hardware resource availability. This approach allows the designers to generate highly optimized solutions. However, it also limits the adaptability of the system to dynamic operating conditions.
- Run-time: This approach involves implementing all resource allocation decisions only after the deployment of the system. This allows the system to adapt to varying operating conditions—both external and internal. External variations might include changing external radiation, changing workload resulting in varying QoS requirements etc. Internal variations include the changing performance/availability of the cores due to aging, as shown in Figure 7, low energy availability in mobile systems etc. In the run-time DSE approach the dynamic adaptability comes at the cost of result quality. Since all the resource management decisions are determined at run-time, it may result in sub-optimal solutions due to computation and availability constraints.
- Hybrid: The hybrid approach attempts to combine the best of both design-/compile-time and run-time approaches. It usually involves analysing most of the possible run-time operating conditions, finding the optimal solution for each condition of design time and storing the optimal solution to be used for run-time adaptation. As shown in Figure 7, the design-time analysis could involve determining the possible scenarios and determining the optimal solution for each scenario for varying core availability that might change during run-time due to aging and the resulting physical faults.
5. Lifetime Reliability Management in Multi/Many-Core Processors
5.1. Design-Time Strategies
5.2. Run-Time Strategies
5.3. Hybrid Strategies
5.4. Critique and Perspectives
6. Timing and Functional Reliability Management in Multi/Many-Core Processors
6.1. Design-Time Strategies
6.1.1. Multi-Core Platform Used for Spatial and Temporal Redundancy
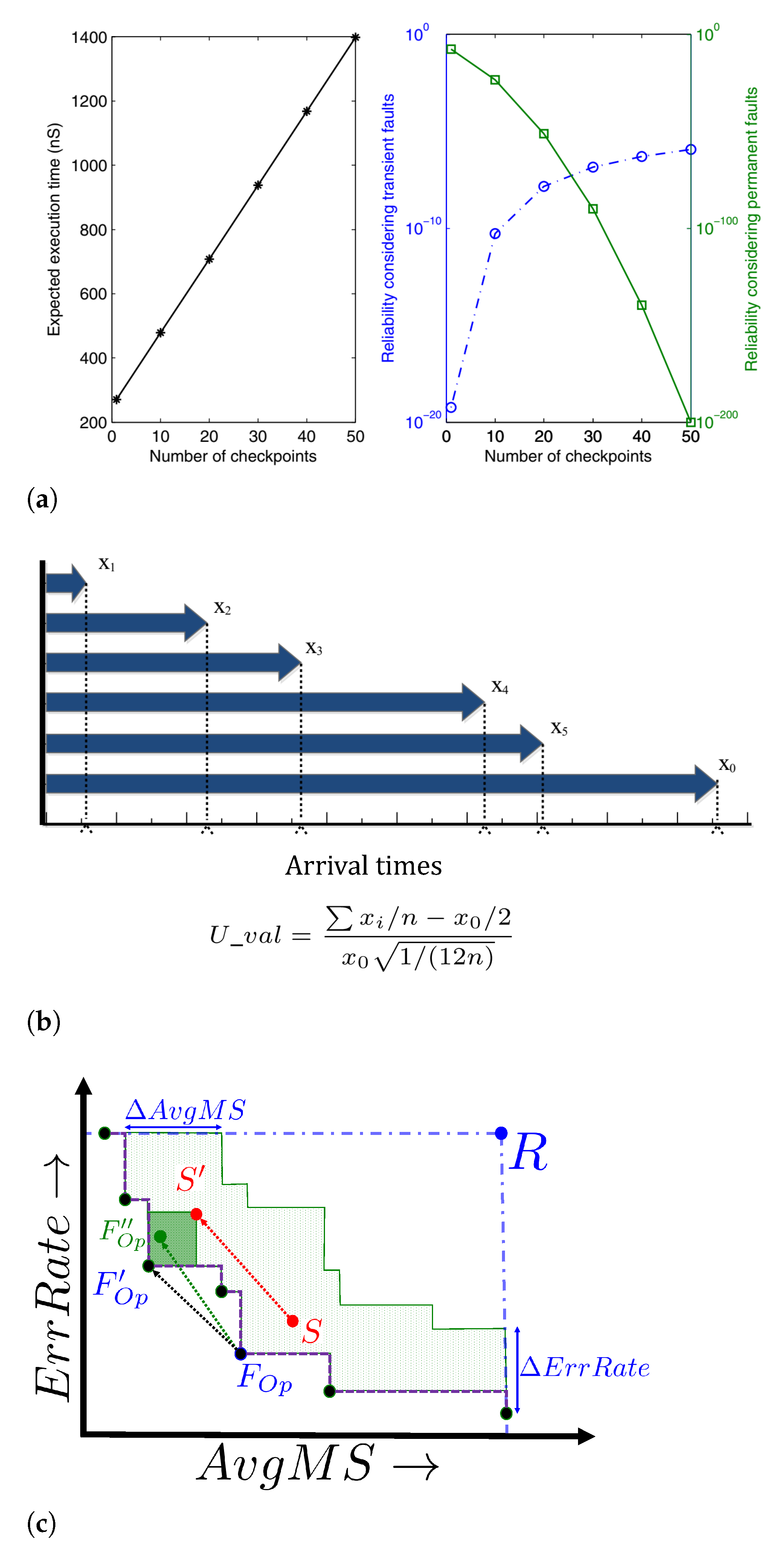
6.1.2. Timing Redundancy with Check-Pointing and Rollback Recovery
6.1.3. Information Redundancy, Mitigating Soft Errors by Using Parity
6.1.4. Task Reliability-Aware Mapping
6.2. Run-Time Strategies
6.3. Hybrid Strategies
6.4. Critique and Perspectives
7. Reliability Management in Reconfigurable Architectures
8. Upcoming Trends and Open Challenges
- Cross-layer Reliability: Most of the research articles discussed in this survey employ/select different redundancy-based methods to improve the system’s reliability. Similarly, there is an increasing trend of using multiple layers of the system stack in the design for reliability [73,118]. This is unlike the traditional approach of mitigating each fault-mechanism at the hardware layer and providing a fault-free abstraction to the other layers. Although this phenomenon-based approach makes the design process simpler for the non-hardware layers, the high cost of hardware-based fault-mitigation can make this approach infeasible for resource-constrained systems. In contrast, the cross-layer approach involves multiple layers sharing the fault-mitigation activities during run-time [119]. Similarly, various methods of leveraging at cross-layer reliability at design-time have been proposed [50].One of the major advantages of the cross-layer approach is the inherent suitability for application-specific optimizations. Since the overheads of fault-tolerance varies with the type of redundancy being used, application-specific tolerances to degradation in some form of reliability can be used to improve other reliability metrics. Further, with the cross-layer approach, the implicit masking of multiple layers can be used to provide low-cost fault-tolerance [120]. However, the joint optimization across multiple layers increases the design space considerably. Recently there have been multiple works that try to provide efficient DSE for cross-layer reliability for various system-level design tasks such as task mapping [37], hardware-hardware partitioning [121], run-time adaptation [40], hardware design [72] etc. However, most of the works assume rather simplistic reliability models such as the one shown in Figure 12a where each layer is limited to a specific type of redundancy [37,40,121]. A more holistic approach to the design of cross layer reliability is necessary for more realistic reliability models that integrate multiple reliability methods at each layer. As shown in Figure 12b having reliability interfaces, similar to those used for functionality and performance, can enable far better DSE than current state-of-the-art works. An interface for functional reliability was proposed by [80] that used Architectural Vulnerability Factor (AVF), Instruction Vulnerability Index (IVI) and Function Vulnerability Index (FVI) for characterising different implementations of an embedded processor, instruction set and function libraries, respectively. However, similar interfaces for timing and lifetime reliability need to be developed for designing efficient cross-layer reliability.
- Self-Aware System Design: In general, design-time approaches are applied to optimize resource usage and guarantee the reliability in the worst-case scenarios. However, due to the various run-time behaviors of applications and fault occurrence, we cannot efficiently manage the reliability, especially lifetime reliability and system utilization. Therefore, run-time system monitoring and optimization are essential to control and have a reliable operation of applications, especially mixed-criticality applications, and efficient resource management of multi/many-core platforms [122]. IPF paradigm is recently used to manage the system dynamically, according to the changes in system and workload [98,123]. This self-aware paradigm improves the reliability and resource utilization by combining different techniques in different hierarchical layers. As a result, the online optimization based on the current state and variations in applications and system by monitoring the hardware and software components, and using the IPF to conquer the complexity is essential, especially for safety-critical systems.
- Reliable Communication and Data Sharing: Safety and dependability are critical issues in designing the mixed-criticality systems on multi/many-core platforms, in which data are shared between concurrent execution of tasks with different criticality [124]. The strict control of data (critical and non-critical), communication, sharing, and storage in such systems for safety assurance, e.g., in medical devices, is crucial. Most state-of-the-art works have concentrated on the reliability management of tasks in processors of multi/many-core systems regardless of safe data sharing among communication and memories. As a result, safe mixed-criticality system design considering all system resources, like communications, and memory access, and processors are needed.
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ACO | Ant Colony Optimization |
| AVF | Architectural Vulnerability Factor |
| AxC | Approximate Computing |
| BTI | Bias Temperature Instability |
| DAG | Directed Acyclic Graph |
| DEC | Double-bit-Error-Correcting |
| DED | Double-bit-Error-Detecting |
| DMR | Dual Modular Redundancy |
| DPR | Dynamic Partial Reconfiguration |
| DRAM | Dynamic Random Access Memory |
| DSE | Design Space Exploration |
| DVFS | Dynamic Voltage and Frequncy Scaling |
| ECC | Error Checking and Correcting |
| EM | Electromigration |
| FPGA | Field Programmable Gate Array |
| FVI | Function Vulnerability Index |
| HCI | Hot Carrier Injection |
| ICs | integrated circuits |
| ILP | Instruction Level Parallelism |
| IoT | Internet of Thing |
| IPF | Information Processing Factory |
| IVI | Instruction Vulnerability Index |
| MAB | Multi-Armed Bandit |
| MCS | Monte-Carlo Simulations |
| MILP | Mixed Integer Linear Programming |
| MOEA | Multi-Objective Evolutionary Algorithms |
| MPSoC | Multi-Processor System-on-Chip |
| MTBF | Mean Time between Failures |
| MTTC | Mean Time To Crash |
| MTTF | Mean Time To Failure |
| NBTI | Negative Bias Temperature Instability |
| NoC | Network-on-Chip |
| PE | Processing Element |
| PFH | Probability-of-Failure-per-Hour |
| PRR | Partially Reconfigurable Region |
| QoS | Quality of Service |
| RL | Reinforcement Learning |
| RMT | Redundant Multi-Threading |
| SA | Simulated Annealing |
| SDFG | Synchronous Data Flow Graph |
| SEC | Single-bit-Error-Correcting |
| SER | Soft Error Rate |
| SEU | Single Event Upset |
| SRAM | Static Random Access Memory |
| TDDB | Time Dependent Dielectric Breakdown |
| TED | Triple-bit-Error-Detecting |
| TMR | Triple Modular Redundancy |
| WCET | Worst-case Execution Time |
References
- Coombs, A.W.M. The Making of Colossus. Ann. Hist. Comput. 1983, 5, 253–259. [Google Scholar] [CrossRef]
- Dennard, R.H.; Gaensslen, F.H.; Rideout, V.L.; Bassous, E.; LeBlanc, A.R. Design of ion-implanted MOSFET’s with very small physical dimensions. IEEE J. Solid State Circuits 1974, 9, 256–268. [Google Scholar] [CrossRef] [Green Version]
- Patterson, D.A.; Hennessy, J.L. Computer Organization and Design ARM Edition: The Hardware Software Interface; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Rupp, K. 42 Years of Microprocessor Trend Data. Available online: https://www.karlrupp.net/2018/02/42-years-of-microprocessor-trend-data/ (accessed on 12 December 2020).
- ARM. big. LITTLE Technology: The Future of Mobile. Available online: https://img.hexus.net/v2/press_releases/arm/big.LITTLE.Whitepaper.pdf (accessed on 12 December 2020).
- Chen, T.; Raghavan, R.; Dale, J.N.; Iwata, E. Cell Broadband Engine Architecture and its first implementation–A performance view. IBM J. Res. Dev. 2007, 51, 559–572. [Google Scholar] [CrossRef]
- Borkar, S. Designing reliable systems from unreliable components: The challenges of transistor variability and degradation. IEEE Micro 2005, 25, 10–16. [Google Scholar] [CrossRef]
- Shivakumar, P.; Kistler, M.; Keckler, S.W.; Burger, D.; Alvisi, L. Modeling the effect of technology trends on the soft error rate of combinational logic. In Proceedings of the International Conference on Dependable Systems and Networks, Washington, DC, USA, 23–26 June 2002; pp. 389–398. [Google Scholar] [CrossRef] [Green Version]
- Nightingale, E.B.; Douceur, J.R.; Orgovan, V. Cycles, Cells and Platters: An Empirical Analysisof Hardware Failures on a Million Consumer PCs. In Proceedings of the Sixth Conference on Computer Systems, Salzburg, Austria, 10–13 April 2011; ACM: New York, NY, USA, 2011; pp. 343–356. [Google Scholar] [CrossRef]
- Liu, J.W.S. Real-Time Systems; Prentice Hall: Upper Saddle River, NJ, USA, 2000. [Google Scholar]
- Halang, W.A.; Gumzej, R.; Colnaric, M.; Druzovec, M. Measuring the performance of real-time systems. Real Time Syst. 2000, 18, 59–68. [Google Scholar] [CrossRef]
- Das, A.K.; Kumar, A.; Veeravalli, B.; Catthoor, F. Reliable and Energy Efficient Streaming Multiprocessor Systems; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Avizienis, A.; Laprie, J.; Randell, B.; Landwehr, C. Basic concepts and taxonomy of dependable and secure computing. IEEE Trans. Dependable Secur. Comput. 2004, 1, 11–33. [Google Scholar] [CrossRef] [Green Version]
- May, T.C.; Woods, M.H. Alpha-particle-induced soft errors in dynamic memories. IEEE Trans. Electron Devices 1979, 26, 2–9. [Google Scholar] [CrossRef]
- Ziegler, J.F.; Lanford, W.A. Effect of Cosmic Rays on Computer Memories. Science 1979, 206, 776–788. [Google Scholar] [CrossRef]
- Keane, J.; Kim, C.H. An odomoeter for CPUs. IEEE Spectr. 2011, 48, 28–33. [Google Scholar] [CrossRef]
- Zhang, J.F.; Eccleston, W. Positive bias temperature instability in MOSFETs. IEEE Trans. Electron Devices 1998, 45, 116–124. [Google Scholar] [CrossRef]
- Takeda, E.; Suzuki, N.; Hagiwara, T. Device performance degradation to hot-carrier injection at energies below the Si-SiO2energy barrier. In Proceedings of the 1983 International Electron Devices Meeting, Washington, DC, USA, 5–7 December 1983; pp. 396–399. [Google Scholar] [CrossRef]
- Black, J.R. Electromigration: A brief survey and some recent results. IEEE Trans. Electron Devices 1969, 16, 338–347. [Google Scholar] [CrossRef] [Green Version]
- Benini, L.; De Micheli, G. Networks on chips: A new SoC paradigm. Computer 2002, 35, 70–78. [Google Scholar] [CrossRef] [Green Version]
- Radetzki, M.; Feng, C.; Zhao, X.; Jantsch, A. Methods for Fault Tolerance in Networks-on-chip. ACM Comput. Surv. 2013, 46, 8:1–8:38. [Google Scholar] [CrossRef]
- Postman, J.; Chiang, P. A Survey Addressing On-Chip Interconnect: Energy and Reliability Considerations. Available online: https://www.hindawi.com/journals/isrn/2012/916259/ (accessed on 12 December 2020).
- Hamming, R.W. Error detecting and error correcting codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]
- Hsiao, M.Y. A Class of Optimal Minimum Odd-weight-column SEC-DED Codes. IBM J. Res. Dev. 1970, 14, 395–401. [Google Scholar] [CrossRef]
- Das, A.; Kumar, A. Fault-aware task re-mapping for throughput constrained multimedia applications on NoC-based MPSoCs. In Proceedings of the IEEE International Symposium on Rapid System Prototyping (RSP), Tampere, Finland, 11–12 October 2012. [Google Scholar]
- Das, A.; Kumar, A.; Veeravalli, B. Aging-aware hardware-software task partitioning for reliable reconfigurable multiprocessor systems. In Proceedings of the International Conference on Compilers, Architectures and Synthesis for Embedded Systems (CASES), Montreal, QC, Canada, 29 September–4 October 2013; pp. 1–10. [Google Scholar] [CrossRef]
- Medina, R.; Borde, E.; Pautet, L. Availability enhancement and analysis for mixed-criticality systems on multi-core. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018. [Google Scholar]
- Ranjbar, B.; Safaei, B.; Ejlali, A.; Kumar, A. FANTOM: Fault Tolerant Task-Drop Aware Scheduling for Mixed-Criticality Systems. IEEE Access 2020, 8, 187232–187248. [Google Scholar] [CrossRef]
- Johnson, L.A. DO-178B, Software considerations in airborne systems and equipment certification. Crosstalk Oct. 1998, 199, 11–20. [Google Scholar]
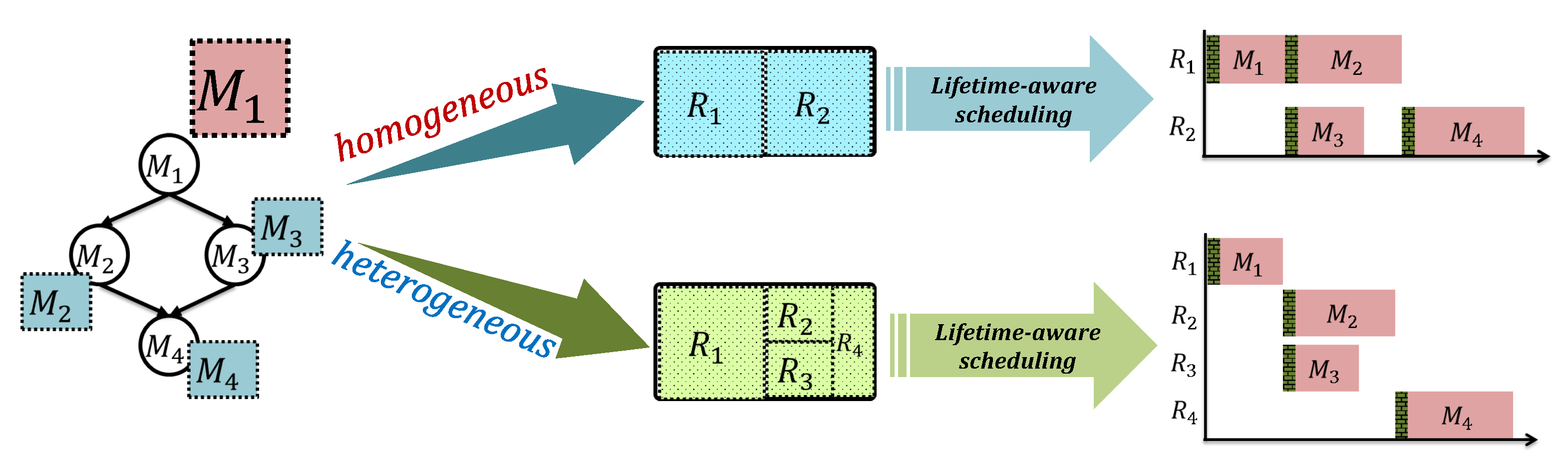
- Hartman, A.S.; Thomas, D.E.; Meyer, B.H. A Case for Lifetime-Aware Task Mapping in Embedded Chip Multiprocessors. In Proceedings of the IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis (CODES), CODES/ISSS ’10, Scottsdale, AZ, USA, 24–29 October 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 145–154. [Google Scholar] [CrossRef]
- Meyer, B.H.; Hartman, A.S.; Thomas, D.E. Cost-effective slack allocation for lifetime improvement in NoC-based MPSoCs. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 8–12 March 2010; pp. 1596–1601. [Google Scholar] [CrossRef]
- Meyer, B.H.; Hartman, A.S.; Thomas, D.E. Cost-Effective Lifetime and Yield Optimization for NoC-Based MPSoCs. ACM Trans. Des. Autom. Electron. Syst. 2014, 19. [Google Scholar] [CrossRef]
- Ma, C.; Mahajan, A.; Meyer, B.H. Multi-armed bandits for efficient lifetime estimation in MPSoC design. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 1540–1545. [Google Scholar] [CrossRef]
- Xiang, Y.; Chantem, T.; Dick, R.P.; Hu, X.S.; Shang, L. System-level reliability modeling for MPSoCs. In Proceedings of the IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis (CODES), Scottsdale, AZ, USA, 24–29 October 2010; pp. 297–306. [Google Scholar]
- Das, A.; Kumar, A.; Veeravalli, B.; Bolchini, C.; Miele, A. Combined DVFS and Mapping Exploration for Lifetime and Soft-Error Susceptibility Improvement in MPSoCs. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 24–28 March 2014; European Design and Automation Association: Leuven, Belgium, 2014. [Google Scholar]
- Das, A.; Kumar, A.; Veeravalli, B. Temperature aware energy-reliability trade-offs for mapping of throughput-constrained applications on multimedia MPSoCs. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 24–28 March 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Sahoo, S.S.; Veeravalli, B.; Kumar, A. CL(R)Early: An Early-stage DSE Methodology for Cross-Layer Reliability-aware Heterogeneous Embedded Systems. In Proceedings of the Design Automation Conference (DAC), San Francisco, CA, USA, 19–22 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Kakoee, M.R.; Bertacco, V.; Benini, L. ReliNoC: A reliable network for priority-based on-chip communication. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Grenoble, France, 14–18 March 2011; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Sahoo, S.S.; Kumar, A.; Veeravalli, B. Design and evaluation of reliability-oriented task re-mapping in MPSoCs using time-series analysis of intermittent faults. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 798–803. [Google Scholar]
- Sahoo, S.S.; Veeravalli, B.; Kumar, A. A Hybrid Agent-Based Design Methodology for Dynamic Cross-Layer Reliability in Heterogeneous Embedded Systems. In Proceedings of the Design Automation Conference (DAC), Las Vegas, NV, USA, 2–6 June 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Hartman, A.S.; Thomas, D.E. Lifetime Improvement through Runtime Wear-Based Task Mapping. In Proceedings of the IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis (CODES), CODES + ISSS ’12, Tampere, Finland, 7–12 October 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 13–22. [Google Scholar] [CrossRef]
- Duque, L.A.R.; Diaz, J.M.M.; Yang, C. Improving MPSoC reliability through adapting runtime task schedule based on time-correlated fault behavior. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 818–823. [Google Scholar]
- Rathore, V.; Chaturvedi, V.; Singh, A.K.; Srikanthan, T.; Shafique, M. Life Guard: A Reinforcement Learning-Based Task Mapping Strategy for Performance-Centric Aging Management. In Proceedings of the Design Automation Conference (DAC), Las Vegas, NA, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Venkataraman, S.; Santos, R.; Kumar, A.; Kuijsten, J. Hardware task migration module for improved fault tolerance and predictability. In Proceedings of the International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation (SAMOS), Samos, Greece, 19–23 July 2015; pp. 197–202. [Google Scholar] [CrossRef]
- Wang, L.; Lv, P.; Liu, L.; Han, J.; Leung, H.; Wang, X.; Yin, S.; Wei, S.; Mak, T. A Lifetime Reliability-Constrained Runtime Mapping for Throughput Optimization in Many-Core Systems. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2019, 38, 1771–1784. [Google Scholar] [CrossRef]
- Haghbayan, M.; Miele, A.; Rahmani, A.M.; Liljeberg, P.; Tenhunen, H. A lifetime-aware runtime mapping approach for many-core systems in the dark silicon era. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 854–857. [Google Scholar]
- Haghbayan, M.; Miele, A.; Rahmani, A.M.; Liljeberg, P.; Tenhunen, H. Performance/Reliability-Aware Resource Management for Many-Cores in Dark Silicon Era. IEEE Trans. Comput. 2017, 66, 1599–1612. [Google Scholar] [CrossRef] [Green Version]
- Rathore, V.; Chaturvedi, V.; Singh, A.K.; Srikanthan, T.; Rohith, R.; Lam, S.; Shafique, M. HiMap: A hierarchical mapping approach for enhancing lifetime reliability of dark silicon manycore systems. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 991–996. [Google Scholar] [CrossRef]
- Raparti, V.Y.; Kapadia, N.; Pasricha, S. ARTEMIS: An Aging-Aware Runtime Application Mapping Framework for 3D NoC-Based Chip Multiprocessors. IEEE Trans. Multi-Scale Comput. Syst. 2017, 3, 72–85. [Google Scholar] [CrossRef]
- Bauer, L.; Henkel, J.; Herkersdorf, A.; Kochte, M.A.; Kühn, J.M.; Rosenstiel, W.; Schweizer, T.; Wallentowitz, S.; Wenzel, V.; Wild, T.; et al. Adaptive multi-layer techniques for increased system dependability. It-Inf. Technol. 2015, 57, 149–158. [Google Scholar] [CrossRef]
- Das, A.; Kumar, A.; Veeravalli, B. Reliability-driven task mapping for lifetime extension of networks-on-chip based multiprocessor systems. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Grenoble, France, 18–22 March 2013; pp. 689–694. [Google Scholar] [CrossRef] [Green Version]
- Das, A.; Kumar, A.; Veeravalli, B. Reliability and Energy-Aware Mapping and Scheduling of Multimedia Applications on Multiprocessor Systems. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 869–884. [Google Scholar] [CrossRef] [Green Version]
- Das, A.; Kumar, A.; Veeravalli, B. Communication and migration energy aware design space exploration for multicore systems with intermittent faults. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Grenoble, France, 18–22 March 2013; pp. 1631–1636. [Google Scholar] [CrossRef]
- Bolchini, C.; Carminati, M.; Miele, A.; Das, A.; Kumar, A.; Veeravalli, B. Run-time mapping for reliable many-cores based on energy/performance trade-offs. In Proceedings of the IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFTS), New York, NY, USA, 2–4 October 2013; pp. 58–64. [Google Scholar] [CrossRef]
- Namazi, A.; Safari, S.; Mohammadi, S.; Abdollahi, M. SORT: Semi Online Reliable Task Mapping for Embedded Multi-Core Systems. ACM Trans. Model. Perform. Eval. Comput. Syst. 2019, 4. [Google Scholar] [CrossRef]
- Kriebel, F.; Rehman, S.; Shafique, M.; Henkel, J. AgeOpt-RMT: Compiler-Driven Variation-Aware Aging Optimization for Redundant Multithreading. In Proceedings of the Design Automation Conference (DAC), DAC ’16, Austin, TX, USA, 5–9 June 2016; Association for Computing Machinery: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Nahar, B.; Meyer, B.H. RotR: Rotational redundant task mapping for fail-operational MPSoCs. In Proceedings of the IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFTS), Amherst, MA, USA, 12–14 October 2015; pp. 21–28. [Google Scholar] [CrossRef]
- Axer, P.; Sebastian, M.; Ernst, R. Reliability Analysis for MPSoCs with Mixed-Critical, Hard Real-Time Constraints. In Proceedings of the IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis (CODES), Taipei Taiwan, 9–14 October 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 149–158. [Google Scholar] [CrossRef]
- Pathan, R.M. Real-time scheduling algorithm for safety-critical systems on faulty multicore environments. Real Time Syst. 2017, 53, 45–81. [Google Scholar] [CrossRef] [Green Version]
- Safari, S.; Hessabi, S.; Ershadi, G. LESS-MICS: A Low Energy Standby-Sparing Scheme for Mixed-Criticality Systems. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2020, 39, 4601–4610. [Google Scholar] [CrossRef]
- Saraswat, P.K.; Pop, P.; Madsen, J. Task Migration for Fault-Tolerance in Mixed-Criticality Embedded Systems. SIGBED Rev. 2009, 6. [Google Scholar] [CrossRef]
- Liu, G.; Lu, Y.; Wang, S. An Efficient Fault Recovery Algorithm in Multiprocessor Mixed-Criticality Systems. In Proceedings of the IEEE International Conference on High Performance Computing and Communications (HPCC)/IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Zhangjiajie, China, 13–15 November 2013; pp. 2006–2013. [Google Scholar]
- Ranjbar, B.; Nguyen, T.D.A.; Ejlali, A.; Kumar, A. Online Peak Power and Maximum Temperature Management in Multi-core Mixed-Criticality Embedded Systems. In Proceedings of the Euromicro Conference on Digital System Design (DSD), Chalkidiki, Greece, 28–30 August 2019; pp. 546–553. [Google Scholar]
- Iacovelli, S.; Kirner, R.; Menon, C. ATMP: An Adaptive Tolerance-based Mixed-criticality Protocol for Multi-core Systems. In Proceedings of the International Symposium on Industrial Embedded Systems (SIES), Graz, Austria, 6–8 June 2018; pp. 1–9. [Google Scholar]
- Al-bayati, Z.; Meyer, B.H.; Zeng, H. Fault-tolerant scheduling of multicore mixed-criticality systems under permanent failures. In Proceedings of the IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Storrs, CT, USA, 19–20 September 2016; pp. 57–62. [Google Scholar]
- O’Connor, P.P.; Kleyner, A. Practical Reliability Engineering, 5th ed.; Wiley Publishing: Hoboken, NJ, USA, 2012. [Google Scholar]
- Esmaeilzadeh, H.; Blem, E.; Amant, R.S.; Sankaralingam, K.; Burger, D. Dark silicon and the end of multicore scaling. In Proceedings of the 2011 38th Annual International Symposium on Computer Architecture (ISCA), San Jose, CA, USA, 4–8 June 2011; Association for Computing Machinery: New York, NY, USA, 2011. [Google Scholar]
- Buttazzo, G.C. Hard Real-Time Computing Systems: Predictable Scheduling Algorithms and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011; Volume 24. [Google Scholar]
- Ranjbar, B.; Nguyen, T.D.A.; Ejlali, A.; Kumar, A. Power-Aware Run-Time Scheduler for Mixed-Criticality Systems on Multi-Core Platform. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2020. [Google Scholar] [CrossRef]
- Sahoo, S.S.; Veeravalli, B.; Kumar, A. Markov Chain-based Modeling and Analysis of Checkpointing with Rollback Recovery for Efficient DSE in Soft Real-time Systems. In Proceedings of the IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Frascati, Italy, 19–21 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Manolache, S.; Eles, P.; Peng, Z. Task Mapping and Priority Assignment for Soft Real-Time Applications under Deadline Miss Ratio Constraints. ACM Trans. Embed. Comput. Syst. 2008, 7. [Google Scholar] [CrossRef] [Green Version]
- Cheng, E.; Mirkhani, S.; Szafaryn, L.G.; Cher, C.Y.; Cho, H.; Skadron, K.; Stan, M.R.; Lilja, K.; Abraham, J.A.; Bose, P.; et al. CLEAR: Cross-Layer Exploration for Architecting Resilience - Combining Hardware and Software Techniques to Tolerate Soft Errors in Processor Cores. In Proceedings of the Design Automation Conference (DAC), Austin, TX, USA, 5–9 June 2016; Association for Computing Machinery: New York, NY, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Henkel, J.; Bauer, L.; Zhang, H.; Rehman, S.; Shafique, M. Multi-Layer Dependability: From Microarchitecture to Application Level. In Proceedings of the Design Automation Conference (DAC), San Francisco, CA, USA, 1–5 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Frantz, A.P.; Cassel, M.; Kastensmidt, F.L.; Cota, E.; Carro, L. Crosstalk- and SEU-Aware Networks on Chips. IEEE Des. Test 2007, 24, 340–350. [Google Scholar] [CrossRef]
- Lehtonen, T.; Liljeberg, P.; Plosila, J. Online Reconfigurable Self-Timed Links for Fault Tolerant NoC. Available online: https://www.hindawi.com/journals/vlsi/2007/094676/ (accessed on 12 December 2020).
- Vitkovskiy, A.; Soteriou, V.; Nicopoulos, C. A fine-grained link-level fault-tolerant mechanism for networks-on-chip. In Proceedings of the IEEE International Conference on Computer Design, Amsterdam, The Netherlands, 3–6 October 2010; pp. 447–454. [Google Scholar] [CrossRef]
- Wells, P.M.; Chakraborty, K.; Sohi, G.S. Adapting to Intermittent Faults in Multicore Systems. SIGOPS Oper. Syst. Rev. 2008, 42, 255–264. [Google Scholar] [CrossRef]
- Lehtonen, T.; Wolpert, D.; Liljeberg, P.; Plosila, J.; Ampadu, P. Self-Adaptive System for Addressing Permanent Errors in On-Chip Interconnects. IEEE Trans. Very Large Scale Integr. Syst. 2010, 18, 527–540. [Google Scholar] [CrossRef]
- Yu, Q.; Ampadu, P. Transient and Permanent Error Co-management Method for Reliable Networks-on-Chip. In Proceedings of the ACM/IEEE International Symposium on Networks-on-Chip, Grenoble, France, 3–6 May 2010; pp. 145–154. [Google Scholar] [CrossRef]
- Rehman, S.; Chen, K.; Kriebel, F.; Toma, A.; Shafique, M.; Chen, J.; Henkel, J. Cross-Layer Software Dependability on Unreliable Hardware. IEEE Trans. Comput. 2016, 65, 80–94. [Google Scholar] [CrossRef]
- Weichslgartner, A.; Wildermann, S.; Gangadharan, D.; Glaß, M.; Teich, J. A Design-Time/Run-Time Application Mapping Methodology for Predictable Execution Time in MPSoCs. ACM Trans. Embed. Comput. Syst. 2018, 17. [Google Scholar] [CrossRef] [Green Version]
- Pourmohseni, B.; Wildermann, S.; Glaß, M.; Teich, J. Hard Real-Time Application Mapping Reconfiguration for NoC-Based Many-Core Systems. Real Time Syst. 2019, 55, 433–469. [Google Scholar] [CrossRef]
- Safari, S.; Ansari, M.; Ershadi, G.; Hessabi, S. On the Scheduling of Energy-Aware Fault-Tolerant Mixed-Criticality Multicore Systems with Service Guarantee Exploration. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 2338–2354. [Google Scholar] [CrossRef]
- Rambo, E.A.; Ernst, R. Replica-Aware Co-Scheduling for Mixed-Criticality. In Proceedings of the Euromicro Conference on Real-Time Systems (ECRTS); Leibniz International Proceedings in Informatics (LIPIcs); Bertogna, M., Ed.; Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik: Dagstuhl, Germany, 2017; Volume 76, pp. 20:1–20:20. [Google Scholar] [CrossRef]
- Bolchini, C.; Miele, A. Reliability-Driven System-Level Synthesis for Mixed-Critical Embedded Systems. IEEE Trans. Comput. 2013, 62, 2489–2502. [Google Scholar] [CrossRef]
- Kang, S.; Yang, H.; Kim, S.; Bacivarov, I.; Ha, S.; Thiele, L. Reliability-aware mapping optimization of multi-core systems with mixed-criticality. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 24–28 March 2014; pp. 1–4. [Google Scholar]
- Kang, S.h.; Yang, H.; Kim, S.; Bacivarov, I.; Ha, S.; Thiele, L. Static Mapping of Mixed-Critical Applications for Fault-Tolerant MPSoCs. In Proceedings of the Design Automation Conference (DAC), San Francisco, CA, USA, 1–5 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Choi, J.; Yang, H.; Ha, S. Optimization of Fault-Tolerant Mixed-Criticality Multi-Core Systems with Enhanced WCRT Analysis. ACM Trans. Des. Autom. Electron. Syst. 2018, 24. [Google Scholar] [CrossRef]
- Jiang, W.; Hu, H.; Zhan, J.; Jiang, K. Work-in-Progress: Design of Security-Critical Distributed Real-Time Applications with Fault-Tolerant Constraint. In Proceedings of the International Conference on Embedded Software (EMSOFT), Torino, Italy, 30 September–5 October 2018; pp. 1–2. [Google Scholar]
- Zeng, L.; Huang, P.; Thiele, L. Towards the Design of Fault-Tolerant Mixed-Criticality Systems on Multicores. In Proceedings of the International Conference on Compilers, Architectures and Synthesis for Embedded Systems (CASES), Pittsburgh, PA, USA, 2–7 October 2016; Association for Computing Machinery: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Caplan, J.; Al-bayati, Z.; Zeng, H.; Meyer, B.H. Mapping and Scheduling Mixed-Criticality Systems with On-Demand Redundancy. IEEE Trans. Comput. 2018, 67, 582–588. [Google Scholar] [CrossRef]
- Saraswat, P.K.; Pop, P.; Madsen, J. Task Mapping and Bandwidth Reservation for Mixed Hard/Soft Fault-Tolerant Embedded Systems. In Proceedings of the IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Stockholm, Sweden, 12–15 April 2010; pp. 89–98. [Google Scholar]
- Bagheri, M.; Jervan, G. Fault-Tolerant Scheduling of Mixed-Critical Applications on Multi-processor Platforms. In Proceedings of the IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Milano, Italy, 25–29 August 2014; pp. 25–32. [Google Scholar]
- Kajmakovic, A.; Diwold, K.; Kajtazovic, N.; Zupanc, R.; Macher, G. Flexible Soft Error Mitigation Strategy for Memories in Mixed-Critical Systems. In Proceedings of the IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Berlin, Germany, 28–31 October 2019; pp. 440–445. [Google Scholar]
- Liu, Y.; Xie, G.; Tang, Y.; Li, R. Improving Real-Time Performance Under Reliability Requirement Assurance in Automotive Electronic Systems. IEEE Access 2019, 7, 140875–140888. [Google Scholar] [CrossRef]
- Thekkilakattil, A.; Dobrin, R.; Punnekkat, S. Mixed criticality scheduling in fault-tolerant distributed real-time systems. In Proceedings of the International Conference on Embedded Systems (ICES), Coimbatore, India, 3–5 July 2014; pp. 92–97. [Google Scholar]
- Koc, H.; Karanam, V.K.; Sonnier, M. Latency Constrained Task Mapping to Improve Reliability of High Critical Tasks in Mixed Criticality Systems. In Proceedings of the IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), British Columbia, VA, Canada, 17–19 October 2019; pp. 0320–0324. [Google Scholar]
- Rambo, E.A.; Donyanavard, B.; Seo, M.; Maurer, F.; Kadeed, T.M.; De Melo, C.B.; Maity, B.; Surhonne, A.; Herkersdorf, A.; Kurdahi, F.; et al. The Self-Aware Information Processing Factory Paradigm for Mixed-Critical Multiprocessing. IEEE Trans. Emerg. Top. Comput. 2020. [Google Scholar] [CrossRef]
- LogiCORE IP. Soft Error Mitigation Controller v3. 4. Available online: https://www.xilinx.com/support/answers/54733.html (accessed on 12 December 2020).
- Santos, R.; Venkataraman, S.; Kumar, A. Scrubbing Mechanism for Heterogeneous Applications in Reconfigurable Devices. ACM Trans. Des. Autom. Electron. Syst. 2017, 22. [Google Scholar] [CrossRef]
- Koch, D.; Haubelt, C.; Teich, J. Efficient Hardware Checkpointing: Concepts, Overhead Analysis, and Implementation. In Proceedings of the International Symposium on Field Programmable Gate Arrays (FPGA), Monterey, CA, USA, 18–20 February 2007. [Google Scholar]
- Lee, G.; Agiakatsikas, D.; Wu, T.; Cetin, E.; Diessel, O. TLegUp: A TMR code generation tool for SRAM-based FPGA applications using HLS. In Proceedings of the International Symposium on Field-Programmable Custom Computing Machines (FCCM), Napa, CA, USA, 30 April–2 May 2017; pp. 129–132. [Google Scholar]
- Srinivasan, S.; Krishnan, R.; Mangalagiri, P.; Xie, Y.; Narayanan, V.; Irwin, M.J.; Sarpatwari, K. Toward Increasing FPGA Lifetime. IEEE Trans. Dependable Secur. Comput. 2008, 5, 115–127. [Google Scholar] [CrossRef]
- Stott, E.; Cheung, P.Y.K. Improving FPGA Reliability with Wear-Levelling. In Proceedings of the International Conference on Field Programmable Logic and Applications (FPL), Chania, Crete, Greece, 5–7 September 2011; pp. 323–328. [Google Scholar] [CrossRef]
- Angermeier, J.; Ziener, D.; Glaß, M.; Teich, J. Stress-Aware Module Placement on Reconfigurable Devices. In Proceedings of the International Conference on Field Programmable Logic and Applications (FPL), Chania, Crete, Greece, 5–7 September 2011; pp. 277–281. [Google Scholar] [CrossRef]
- Zhang, H.; Bauer, L.; Kochte, M.A.; Schneider, E.; Braun, C.; Imhof, M.E.; Wunderlich, H.; Henkel, J. Module diversification: Fault tolerance and aging mitigation for runtime reconfigurable architectures. In Proceedings of the IEEE International Test Conference (ITC), Anaheim, CA, USA, 6–13 September 2013; pp. 1–10. [Google Scholar] [CrossRef]
- Zhang, H.; Kochte, M.A.; Schneider, E.; Bauer, L.; Wunderlich, H.; Henkel, J. STRAP: Stress-aware placement for aging mitigation in runtime reconfigurable architectures. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Austin, TX, USA, 2–6 November 2015; pp. 38–45. [Google Scholar] [CrossRef]
- Ghaderi, Z.; Bozorgzadeh, E. Aging-aware high-level physical planning for reconfigurable systems. In Proceedings of the Asia and South Pacific Design Automation Conference (ASP-DAC), Macao, China, 25–28 January 2016; pp. 631–636. [Google Scholar] [CrossRef]
- Dumitriu, V.; Kirischian, L.; Kirischian, V. Run-Time Recovery Mechanism for Transient and Permanent Hardware Faults Based on Distributed, Self-Organized Dynamic Partially Reconfigurable Systems. IEEE Trans. Comput. 2016, 65, 2835–2847. [Google Scholar] [CrossRef]
- Sahoo, S.S.; Nguyen, T.D.A.; Veeravalli, B.; Kumar, A. Lifetime-aware design methodology for dynamic partially reconfigurable systems. In Proceedings of the Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju Island, Korea, 22–25 January 2018; pp. 393–398. [Google Scholar]
- Sahoo, S.; Nguyen, T.; Veeravalli, B.; Kumar, A. Multi-objective design space exploration for system partitioning of FPGA-based Dynamic Partially Reconfigurable Systems. Integration 2019, 67, 95–107. [Google Scholar] [CrossRef]
- Santos, R.; Venkataraman, S.; Das, A.; Kumar, A. Criticality-aware scrubbing mechanism for SRAM-based FPGAs. In Proceedings of the International Conference on Field Programmable Logic and Applications (FPL), Munich, Germany, 2–4 September 2014; pp. 1–8. [Google Scholar]
- Santos, R.; Venkataraman, S.; Kumar, A. Dynamically adaptive scrubbing mechanism for improved reliability in reconfigurable embedded systems. In Proceedings of the Design Automation Conference (DAC), San Francisco, CA, USA, 7–11 June 2015; pp. 1–6. [Google Scholar]
- Ahmadian, H.; Nekouei, F.; Obermaisser, R. Fault recovery and adaptation in time-triggered Networks-on-Chips for mixed-criticality systems. In Proceedings of the International Symposium on Reconfigurable Communication-centric Systems-on-Chip (ReCoSoC), Madrid, Spain, 12–17 July 2017; pp. 1–8. [Google Scholar]
- Guha, K.; Majumder, A.; Saha, D.; Chakrabarti, A. Reliability Driven Mixed Critical Tasks Processing on FPGAs Against Hardware Trojan Attacks. In Proceedings of the Euromicro Conference on Digital System Design (DSD), Prague, Czech Republic, 29–31 August 2018; pp. 537–544. [Google Scholar]
- Mandal, S.; Sarkar, S.; Ming, W.M.; Chattopadhyay, A.; Chakrabarti, A. Criticality Aware Soft Error Mitigation in the Configuration Memory of SRAM Based FPGA. In Proceedings of the International Conference on VLSI Design and International Conference on Embedded Systems (VLSID), Delhi, India, 5–9 January 2019; pp. 257–262. [Google Scholar]
- Heiner, J.; Sellers, B.; Wirthlin, M.; Kalb, J. FPGA partial reconfiguration via configuration scrubbing. In Proceedings of the International Conference on Field Programmable Logic and Applications (FPL), Prague, Czech Republic, 31 August–2 September 2009; pp. 99–104. [Google Scholar] [CrossRef]
- Sahoo, S.S.; Veeravalli, B.; Kumar, A. Cross-layer fault-tolerant design of real-time systems. In Proceedings of the IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Storrs, CT, USA, 19–20 September 2016; pp. 63–68. [Google Scholar] [CrossRef]
- Carter, N.P.; Naeimi, H.; Gardner, D.S. Design techniques for cross-layer resilience. In Proceedings of the Design, Automation Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 8–12 March 2010; pp. 1023–1028. [Google Scholar] [CrossRef]
- Santini, T.; Rech, P.; Sartor, A.; Corrêa, U.B.; Carro, L.; Wagner, F.R. Evaluation of Failures Masking Across the Software Stack. Available online: http://www.median-project.eu/wp-content/uploads/12_II-1_median2015.pdf (accessed on 12 December 2020).
- Sahoo, S.S.; Nguyen, T.D.A.; Veeravalli, B.; Kumar, A. QoS-Aware Cross-Layer Reliability-Integrated FPGA-Based Dynamic Partially Reconfigurable System Partitioning. In Proceedings of the International Conference on Field-Programmable Technology (FPT), Naha, Japan, 11–15 December 2018; pp. 230–233. [Google Scholar]
- Götzinger, M.; Rahmani, A.M.; Pongratz, M.; Liljeberg, P.; Jantsch, A.; Tenhunen, H. The Role of Self-Awareness and Hierarchical Agents in Resource Management for Many-Core Systems. In Proceedings of the IEEE International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSOC), Hanoi, Vietnam, 12–14 September 2018; pp. 53–60. [Google Scholar] [CrossRef]
- Rambo, E.A.; Kadeed, T.; Ernst, R.; Seo, M.; Kurdahi, F.; Donyanavard, B.; de Melo, C.B.; Maity, B.; Moazzemi, K.; Stewart, K.; et al. The Information Processing Factory: A Paradigm for Life Cycle Management of Dependable Systems. In Proceedings of the IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis (CODES), New York, NY, USA, 13–18 October 2019; pp. 1–10. [Google Scholar]
- Burns, A.; Davis, R.I. A Survey of Research into Mixed Criticality Systems. ACM Comput. Surv. 2017, 50. [Google Scholar] [CrossRef] [Green Version]
- Mittal, S. A Survey of Techniques for Approximate Computing. ACM Comput. Surv. 2016, 48. [Google Scholar] [CrossRef] [Green Version]
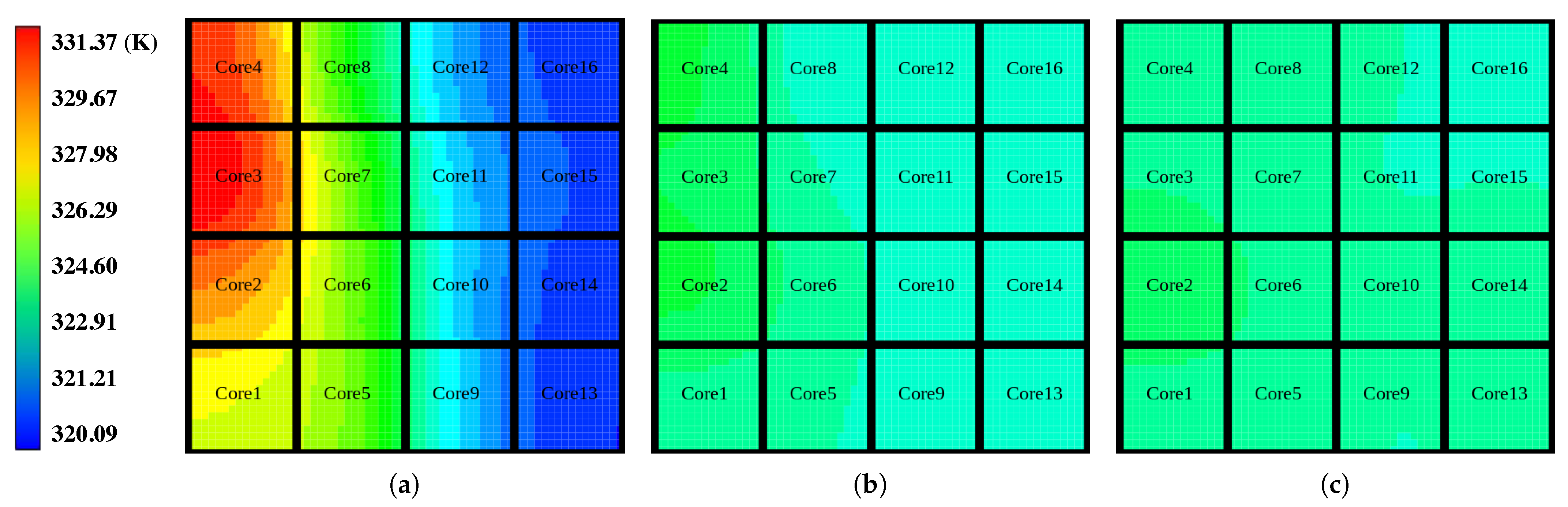
- Das, A.; Shafik, R.A.; Merrett, G.V.; Al-Hashimi, B.M.; Kumar, A.; Veeravalli, B. Reinforcement Learning-Based Inter- and Intra-Application Thermal Optimization for Lifetime Improvement of Multicore Systems. In Proceedings of the Design Automation Conference (DAC), San Francisco, CA, USA, 1–5 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Sadiqbatcha, S.; Gao, Y.; O’Dea, M.; Yu, N.; Tan, S.X.D. HAT-DRL: Hotspot-Aware Task Mapping for Lifetime Improvement of Multicore System Using Deep Reinforcement Learning. In Proceedings of the ACM/IEEE Workshop on Machine Learning for CAD, Virtual Event, Iceland, 16–20 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 77–82. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x | A | B | C | D | E |
|---|---|---|---|---|---|
| < | < | < | ≥ | - | |
| Failure Condition | Catastrophic | Hazardous | Major | Minor | No Effect |
| Fault Model | App. Model | System Model | Imp. | DSE | Technique | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Transient | Intermittent | Permanent | Criticality | Dependency | Periodicity | Communication | Computation | Memory | Heterogeneity | Real Board | Real App. | |||
| Hartman’10 [30] | × | × | ✓ | × | D | P | × | ✓ | × | Het. | × | ✓ | D.T | Task Mapping |
| Meyer’10 [31] | × | × | ✓ | × | D | P | ✓ | ✓ | ✓ | Het. | × | ✓ | D.T | Slack Allocation |
| Meyer’14 [32] | × | × | ✓ | × | D | P | ✓ | ✓ | ✓ | Het. | × | ✓ | D.T | Slack Allocation, Yield |
| Ma’17 [33] | × | × | ✓ | × | D | P | ✓ | ✓ | × | Het. | × | ✓ | D.T | MAB Simulation |
| Das’14 [35] | ✓ | × | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | D.T | Task Mapping |
| Das’13 [26] | ✓ | × | ✓ | × | D | P | × | ✓ | × | Het. | × | ✓ | D.T | Task Mapping |
| Das’14 [36] | × | × | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | D.T | Task Mapping |
| Sahoo’20 [37] | ✓ | × | ✓ | × | D | P | × | ✓ | × | Het. | × | × | D.T | Task Mapping |
| Kakoee’11 [38] | ✓ | × | ✓ | × | × | × | ✓ | × | × | × | × | ✓ | D(R).T | Hardware Redundancy |
| Hartman’12 [41] | × | × | ✓ | × | D | P | ✓ | ✓ | × | Het. | × | ✓ | R.T | Task (Re)-Mapping |
| Duque’15 [42] | × | ✓ | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | R.T | Task (Re)-Mapping |
| Sahoo’16 [39] | × | ✓ | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | R.T | Task (Re)-Mapping |
| Rathore’19 [43] | × | × | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | R.T | Task (Re)-Mapping |
| Venkataraman’15 [44] | × | × | ✓ | × | D | P | × | ✓ | × | Hom. | × | × | R.T | Hardware Migration |
| Wang’19 [45] | × | × | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | R.T | Task (Re)-Mapping |
| Haghbayan’16 [46] | × | × | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | R.T | Task (Re)-Mapping |
| Haghbayan’17 [47] | × | × | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | R.T | Task (Re)-Mapping |
| Rathore’18 [48] | × | × | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | R.T | Task (Re)-Mapping |
| Raparti’17 [49] | × | × | ✓ | × | D | P | ✓ | ✓ | × | Hom. | × | ✓ | R.T | (3D) Task Mapping |
| Bauer’15 [50] | ✓ | ✓ | ✓ | × | D | P | ✓ | ✓ | × | Het. | × | ✓ | R.T | Multi-layer |
| Das’13 [51] | × | × | ✓ | × | D | P | ✓ | ✓ | × | Hom. | × | ✓ | H | Task (Re)-Mapping |
| Das’16 [52] | × | × | ✓ | × | D | P | ✓ | ✓ | × | Hom. | × | ✓ | H | Task (Re)-Mapping |
| Das’13 [53] | × | ✓ | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | H | Task (Re)-Mapping |
| Bolchini’13 [54] | × | × | ✓ | × | D | P | ✓ | ✓ | × | Hom. | × | ✓ | H | Task (Re)-Mapping |
| Namazi’19 [55] | ✓ | × | ✓ | × | D | P | ✓ | ✓ | × | Hom. | × | ✓ | H | Task (Re)-Mapping |
| Kriebel’16 [56] | ✓ | × | ✓ | × | D | P | ✓ | ✓ | × | Hom. | × | ✓ | H | Task (Re)-Mapping |
| Nahar’15 [57] | ✓ | × | ✓ | × | D | P | ✓ | ✓ | × | Hom. | × | ✓ | H | Redundancy |
| Sahoo’19 [40] | ✓ | × | ✓ | × | D | P | × | ✓ | × | Het. | × | × | H | Task (Re)-Mapping |
| Axer’11 [58] | ✓ | × | ✓ | ✓ | I | P | × | ✓ | × | Hom. | × | × | D.T | Redundancy |
| Pathan’17 [59] | ✓ | × | ✓ | ✓ | I | S | × | ✓ | × | Hom. | × | × | D.T | Redundancy |
| Safari’20 [60] | ✓ | × | ✓ | ✓ | D | P | × | ✓ | × | Hom. | × | × | D.T | Redundancy |
| Saraswat’09 [61] | ✓ | × | ✓ | ✓ | I | P | ✓ | ✓ | ✓ | Het. | × | ✓ | R.T | Task Re-Mapping |
| Liu’13 [62] | × | × | ✓ | ✓ | I | P | × | ✓ | × | Hom. | × | × | R.T | Task Re-Mapping |
| Ranjbar’19 [63] | × | × | × | ✓ | D | P | × | ✓ | × | Hom. | × | ✓ | R.T | Thermal Management |
| Iacovelli’18 [64] | × | × | ✓ | ✓ | I | P | × | ✓ | × | Hom. | × | × | H | Task (Re)-Mapping |
| Bayati’16 [65] | × | × | ✓ | ✓ | I | S | × | ✓ | × | Hom. | × | × | H | Task (Re)-Mapping |
| Fault Model | App. Model | System Model | Imp. | DSE | Technique | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Transient | Intermittent | Permanent | Criticality | Dependency | Periodicity | Communication | Computation | Memory | Heterogeneity | Real Board | Real App. | ✓ | ✓ | |
| Manolache’08 [71] | × | × | × | × | D | P | ✓ | ✓ | × | Het. | × | ✓ | D.T | Task Mapping |
| Das’14 [35] | ✓ | × | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | D.T | Task-Replication |
| Bauer’15 [50] | ✓ | ✓ | ✓ | × | D | P | ✓ | ✓ | × | Het. | × | ✓ | R.T | Hardware blackundancy |
| Das’13 [26] | ✓ | × | ✓ | × | D | P | × | ✓ | × | Het. | × | ✓ | D.T | Checkpointing |
| Sahoo’20 [37] | ✓ | × | ✓ | × | D | P | × | ✓ | × | Het. | × | × | D.T | Cross-layer Redundancy |
| Frantz’07 [74] | ✓ | × | × | × | × | × | ✓ | × | × | × | × | ✓ | D.T | HW/SW Redundancy |
| Lehtonen’07 [75] | ✓ | ✓ | ✓ | × | × | × | ✓ | × | × | × | × | ✓ | D.T | Fault-spec. Opt. |
| Vitkovskiy’10 [76] | × | × | ✓ | × | × | × | ✓ | × | × | × | × | ✓ | D(R).T | Latency Reduction |
| Kakoee’11 [38] | ✓ | × | ✓ | × | × | × | ✓ | × | × | × | × | ✓ | D(R).T | Hardware Redundancy |
| Duque’15 [42] | × | ✓ | ✓ | × | D | P | × | ✓ | × | Hom. | × | ✓ | R.T | Task (Re)-Mapping |
| Wells’08 [77] | × | ✓ | × | × | I | S | × | ✓ | × | Hom. | × | ✓ | R.T | Hardware Redundancy |
| Lehtonen’10 [78] | × | × | ✓ | × | × | × | ✓ | × | × | × | × | ✓ | R.T | Online Testing |
| Yu’10 [79] | ✓ | × | ✓ | × | × | × | ✓ | × | × | × | × | ✓ | R.T | Hardware Redundancy |
| Rehman’16 [80] | ✓ | × | × | × | D | A | × | ✓ | × | Hom. | × | ✓ | H | Cross-layer |
| Weichslgartner’18 [81] | × | × | × | × | D | A | ✓ | ✓ | ✓ | Het. | × | ✓ | H | Task Mapping |
| Sahoo’19 [40] | ✓ | × | ✓ | × | D | P | × | ✓ | × | Het. | × | × | H | Cross-layer Redundancy |
| Pourmohseni’19 [82] | × | × | × | × | D | P | ✓ | ✓ | × | Het. | × | ✓ | H | Task Mapping |
| Pathan’17 [59] | ✓ | × | ✓ | ✓ | I | S | × | ✓ | × | Hom. | × | × | D.T | Hardware Redundancy |
| Safari’20 [60] | ✓ | × | ✓ | ✓ | D | P | × | ✓ | × | Hom. | × | × | D.T | Hardware Redundancy |
| Safari’19 [83] | ✓ | × | × | ✓ | I | P | × | ✓ | × | Hom. | × | × | D.T | Hardware Redundancy |
| Rambo’17 [84] | ✓ | × | × | ✓ | I | P | ✓ | ✓ | × | Hom. | × | × | D.T | Hardware Redundancy |
| Bolchini’13 [85] | ✓ | × | × | ✓ | D | P | ✓ | ✓ | × | Het. | × | × | D.T | Hardware Redundancy |
| Kang’14 [86] | ✓ | × | × | ✓ | D | P | ✓ | ✓ | × | Hom. | × | ✓ | D.T | Hardware Redundancy |
| Kang’14a [87] | ✓ | × | × | ✓ | D | P | ✓ | ✓ | × | Het. | × | ✓ | D.T | Hardware Redundancy |
| Choi’18 [88] | ✓ | × | × | ✓ | D | P/S | × | ✓ | × | Hom. | × | ✓ | D.T | Hardware Redundancy |
| Jiang’18 [89] | ✓ | × | × | ✓ | D | P | ✓ | ✓ | × | Hom. | × | × | D.T | Hardware Redundancy |
| Zeng’16 [90] | ✓ | × | × | ✓ | I | S | × | ✓ | × | Hom. | × | ✓ | D.T | Hardware Redundancy |
| Caplan’17 [91] | ✓ | × | × | ✓ | I | S | × | ✓ | × | Hom. | × | × | D.T | Hardware Redundancy |
| Axer’11 [58] | ✓ | × | ✓ | ✓ | I | P | × | ✓ | × | Hom. | × | × | D.T | Timing Redundancy |
| Saraswat’09 [61] | ✓ | × | ✓ | ✓ | I | P | ✓ | ✓ | ✓ | Het. | × | ✓ | D.T | Timing Redundancy |
| Saraswat’10 [92] | ✓ | × | × | ✓ | I | P | ✓ | ✓ | ✓ | Het. | × | × | D.T | Timing Redundancy |
| Bagheri’14 [93] | ✓ | × | × | ✓ | D | - | ✓ | ✓ | × | Hom. | × | × | D.T | Timing Redundancy |
| Kajmakovic’19 [94] | ✓ | × | × | ✓ | × | × | × | × | ✓ | × | ✓ | × | D.T | Information Redundancy |
| Liu’19 [95] | ✓ | × | × | ✓ | D | P | ✓ | ✓ | × | Het. | × | × | D.T | Rel.-Aware Mapping |
| Thekkilakattil’14 [96] | ✓ | × | × | ✓ | I | P | × | ✓ | × | Hom. | × | × | H | Mapping & Redundancy |
| Koc’19 [97] | × | × | × | ✓ | D | P | × | ✓ | × | Het. | × | × | H | Mapping & Redundancy |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sahoo, S.S.; Ranjbar, B.; Kumar, A. Reliability-Aware Resource Management in Multi-/Many-Core Systems: A Perspective Paper. J. Low Power Electron. Appl. 2021, 11, 7. https://doi.org/10.3390/jlpea11010007
Sahoo SS, Ranjbar B, Kumar A. Reliability-Aware Resource Management in Multi-/Many-Core Systems: A Perspective Paper. Journal of Low Power Electronics and Applications. 2021; 11(1):7. https://doi.org/10.3390/jlpea11010007
Chicago/Turabian StyleSahoo, Siva Satyendra, Behnaz Ranjbar, and Akash Kumar. 2021. "Reliability-Aware Resource Management in Multi-/Many-Core Systems: A Perspective Paper" Journal of Low Power Electronics and Applications 11, no. 1: 7. https://doi.org/10.3390/jlpea11010007