

Compressive Strength Estimation of Waste Marble Powder Incorporated Concrete Using Regression Modelling

Abstract
:1. Introduction
- Damage to soil due to dumping of waste;
- Degradation of groundwater
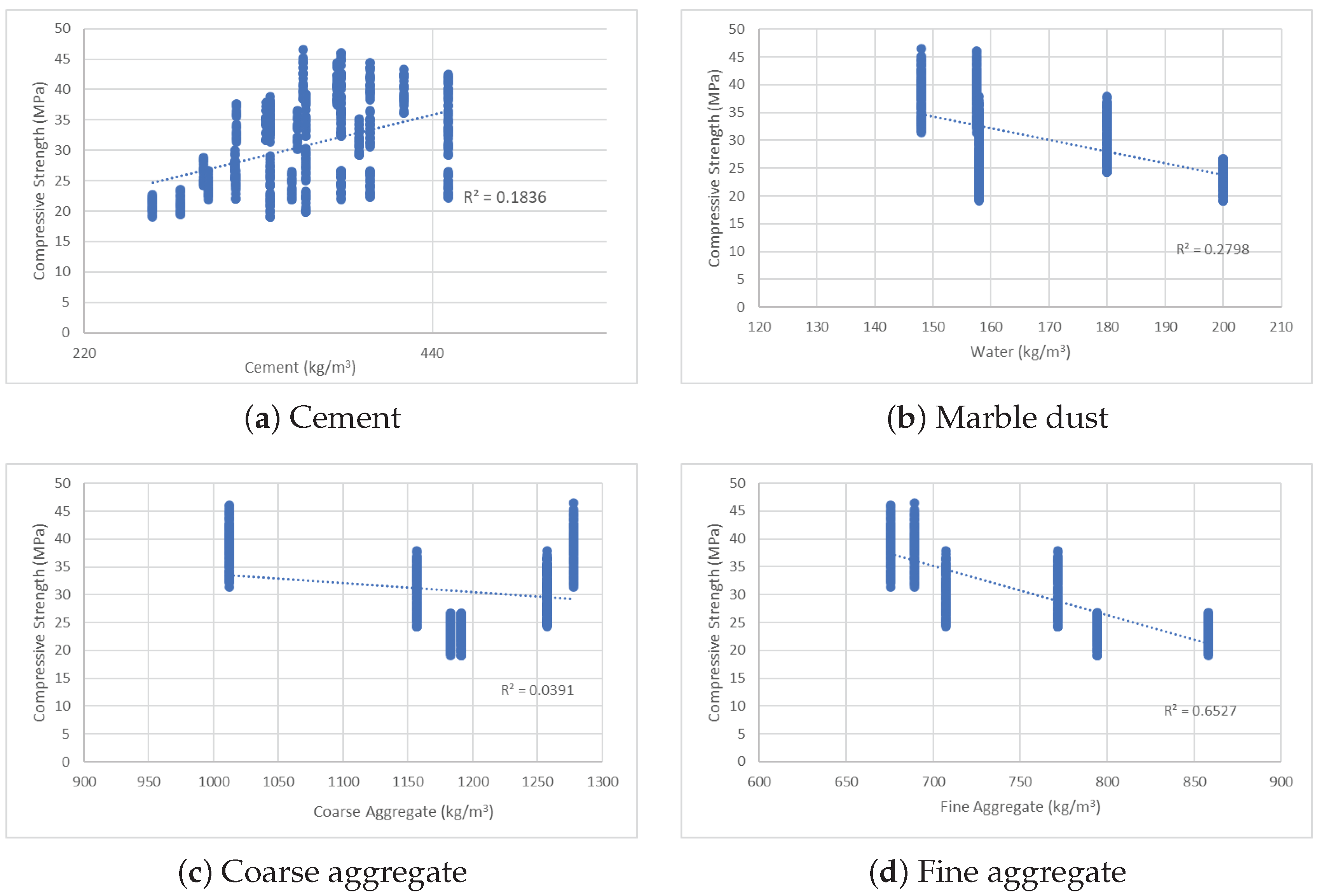
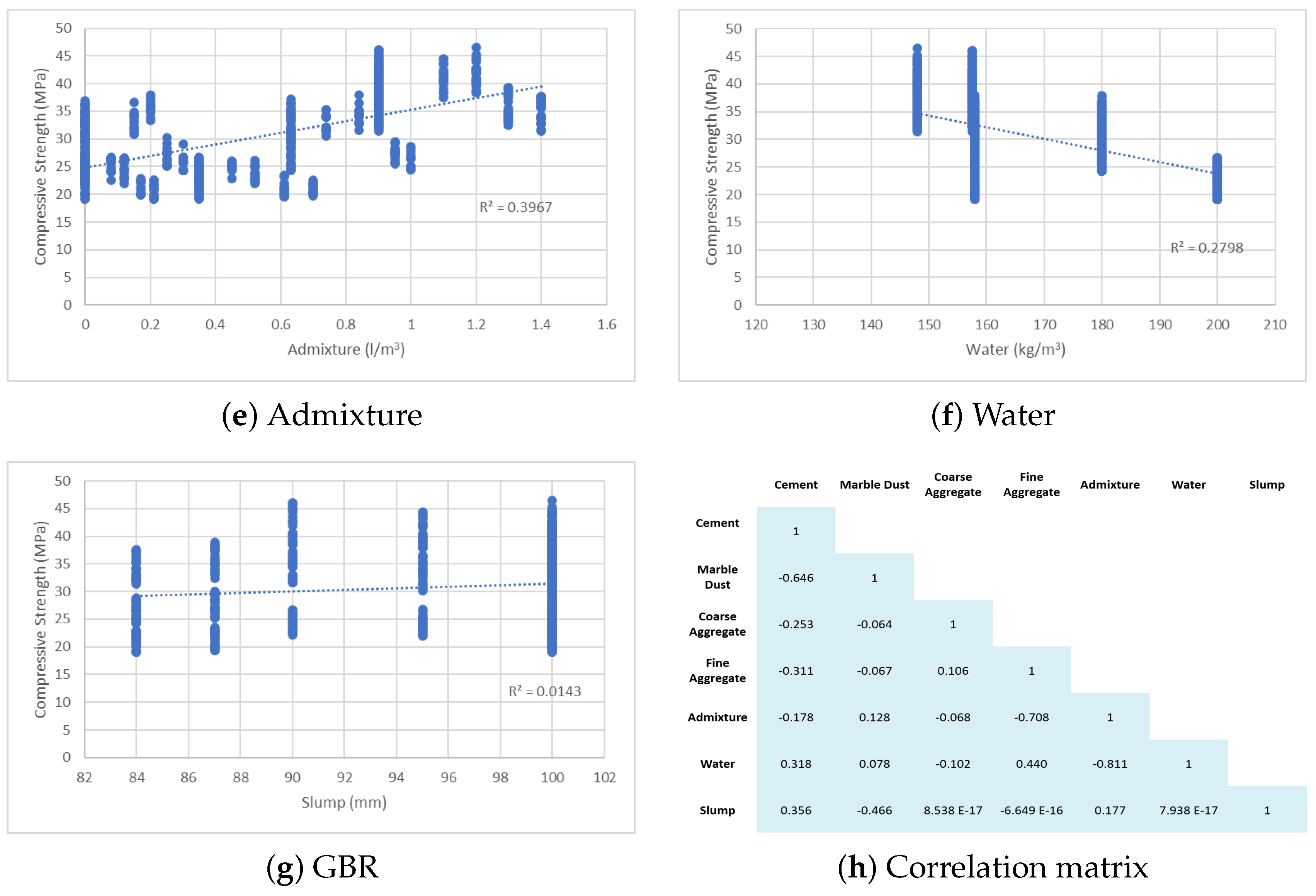
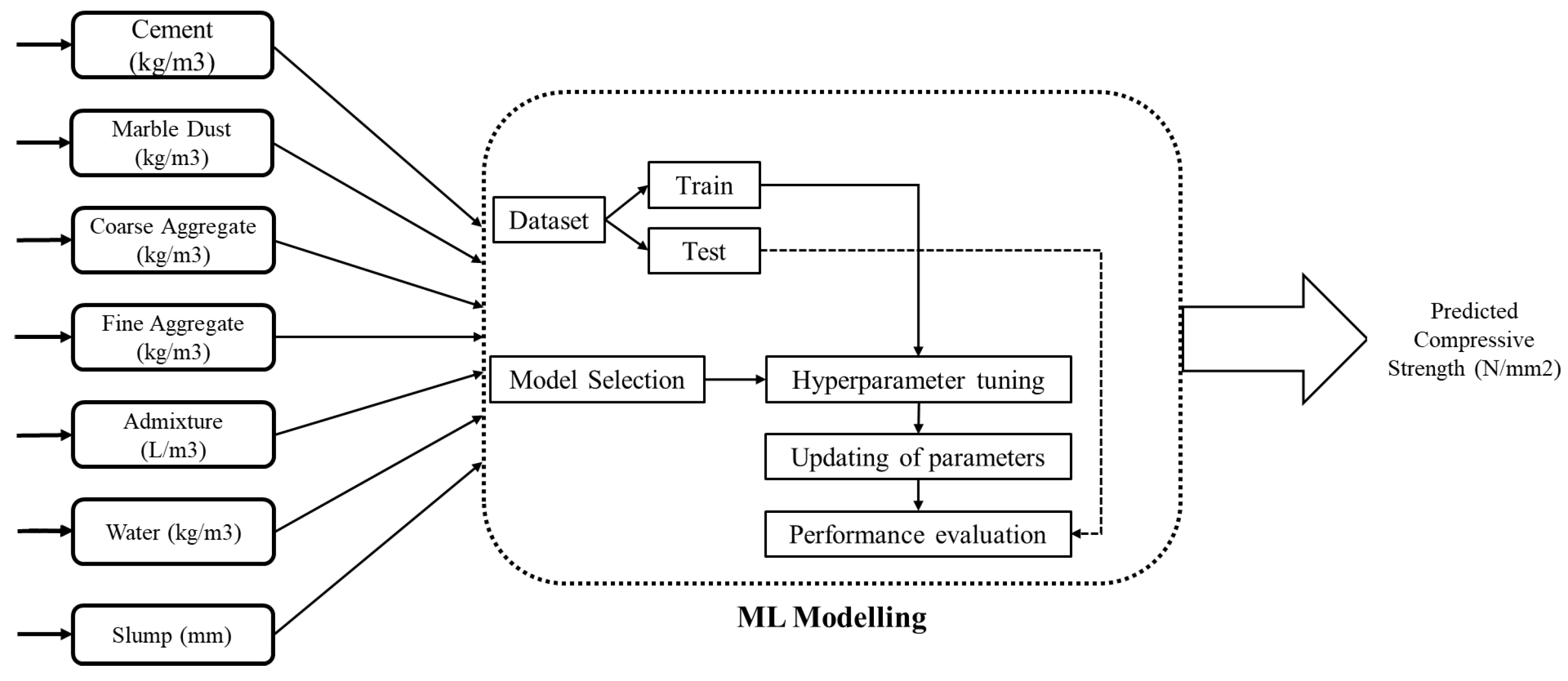
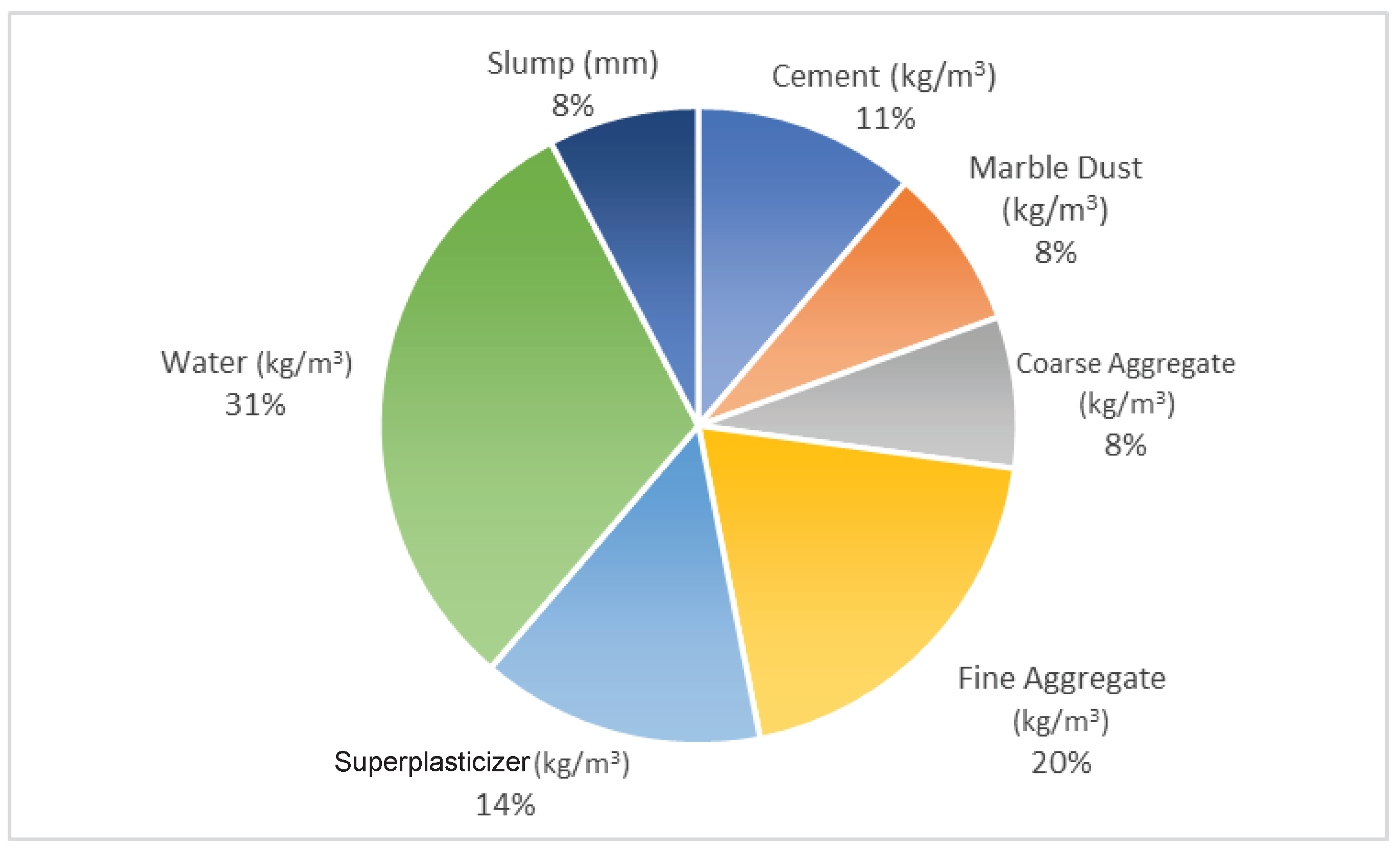
2. Data Collection and Modelling
3. Machine Learning Modelling
3.1. Multiple Linear Regression Model
3.2. K-Nearest Neighbour
3.3. Support Vector Regression
3.4. Decision Tree
3.5. Random Forest
3.6. Extra Trees
3.7. Gradient Boosting
4. Experimental Section and Results
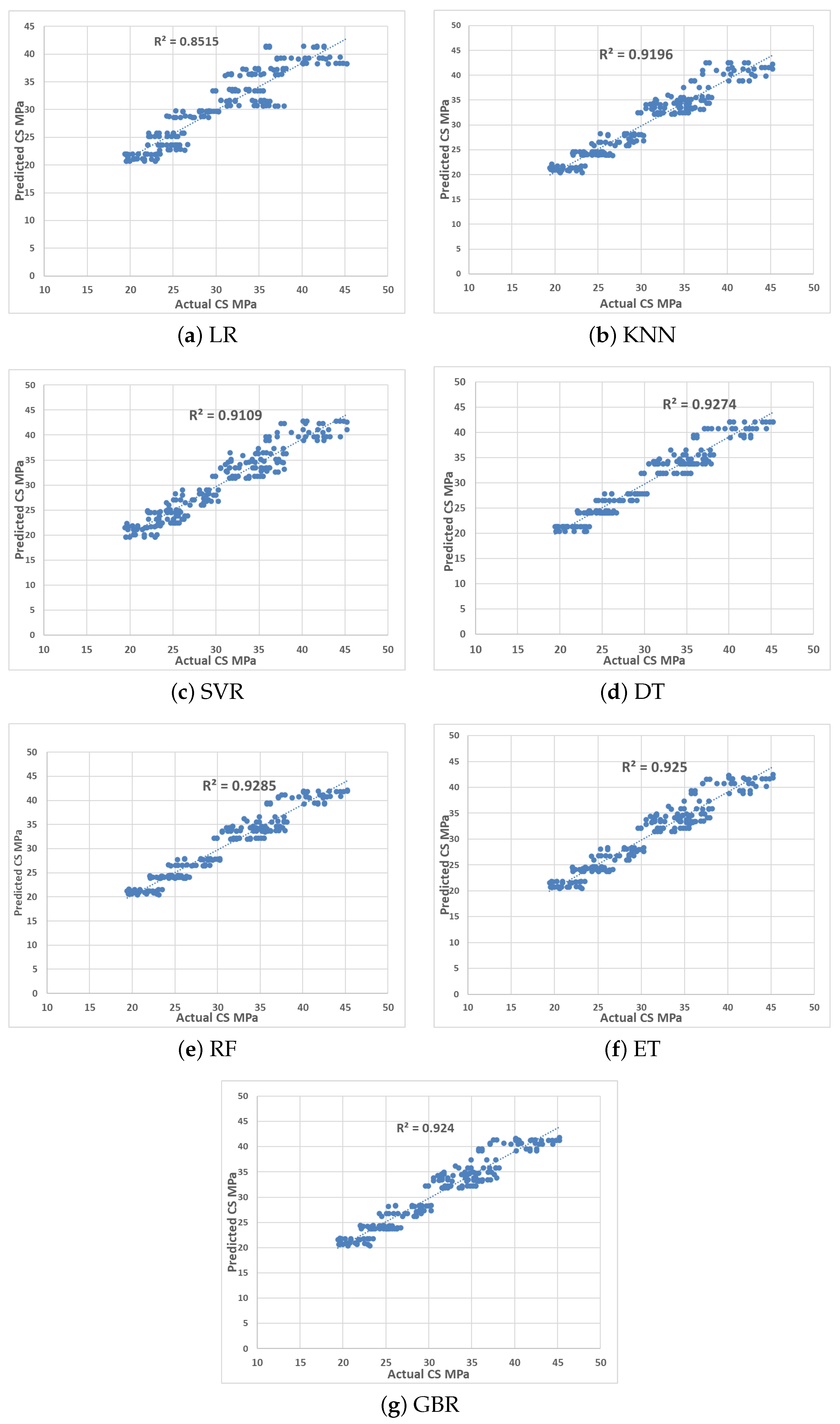
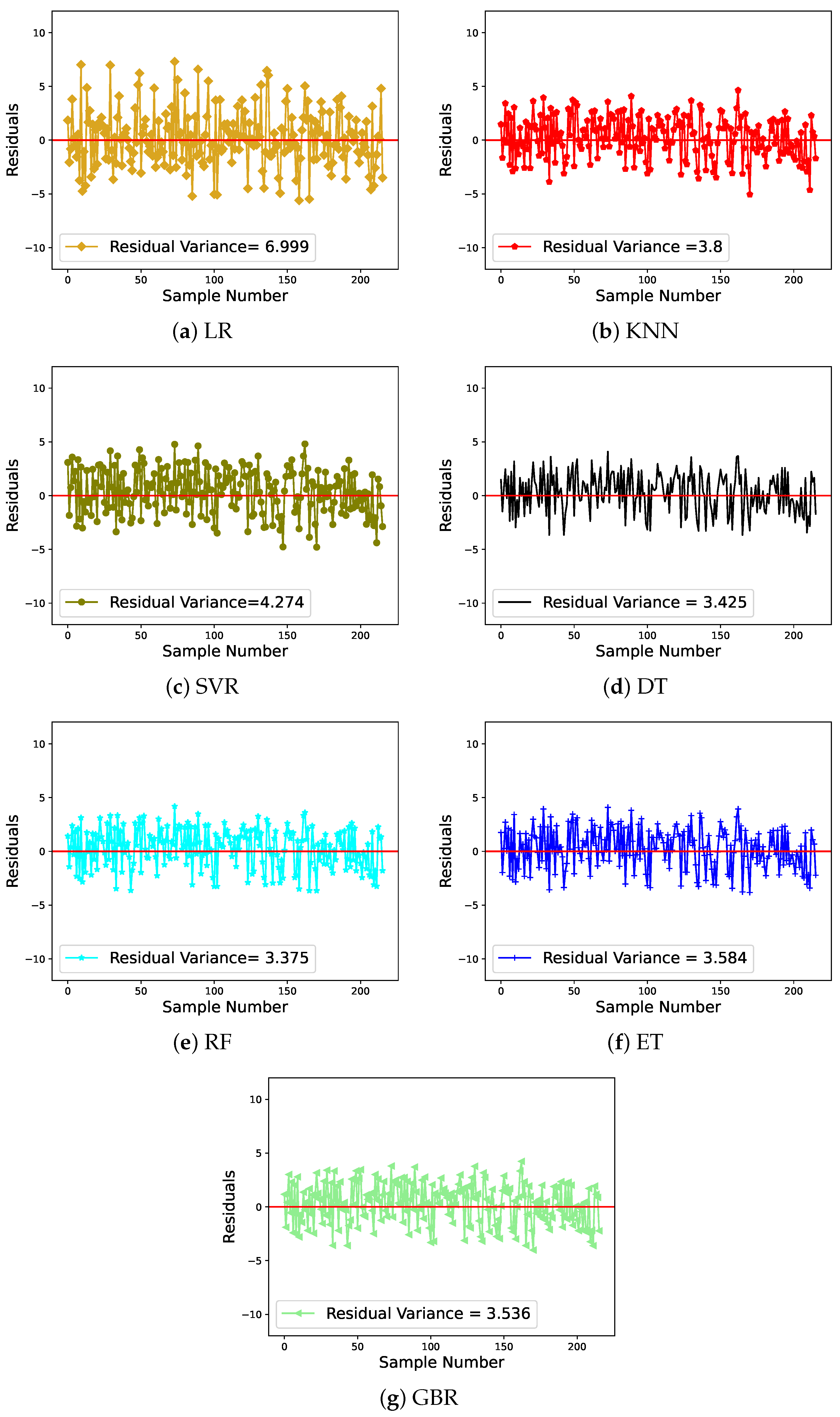
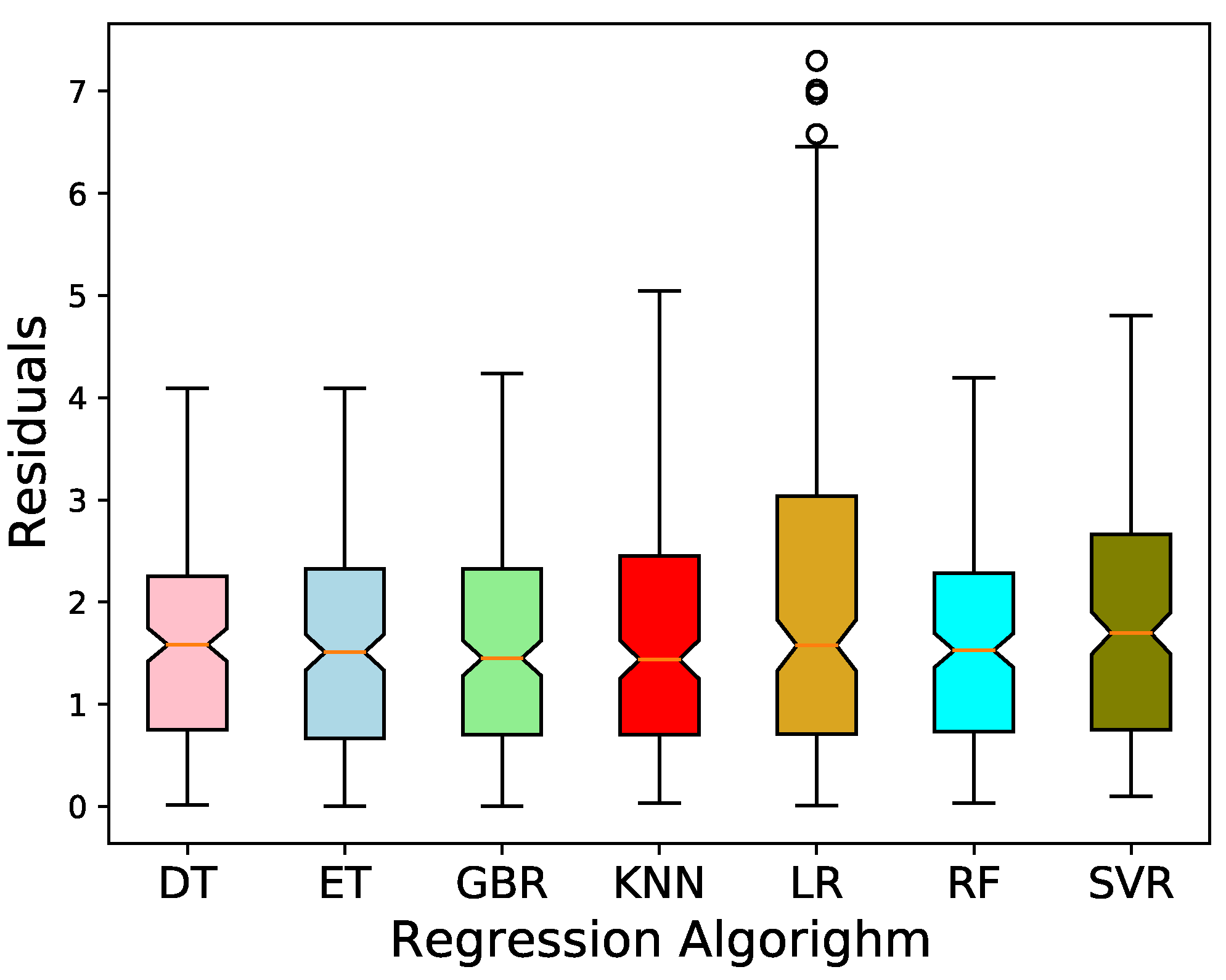
4.1. Results Using Various Regression Models
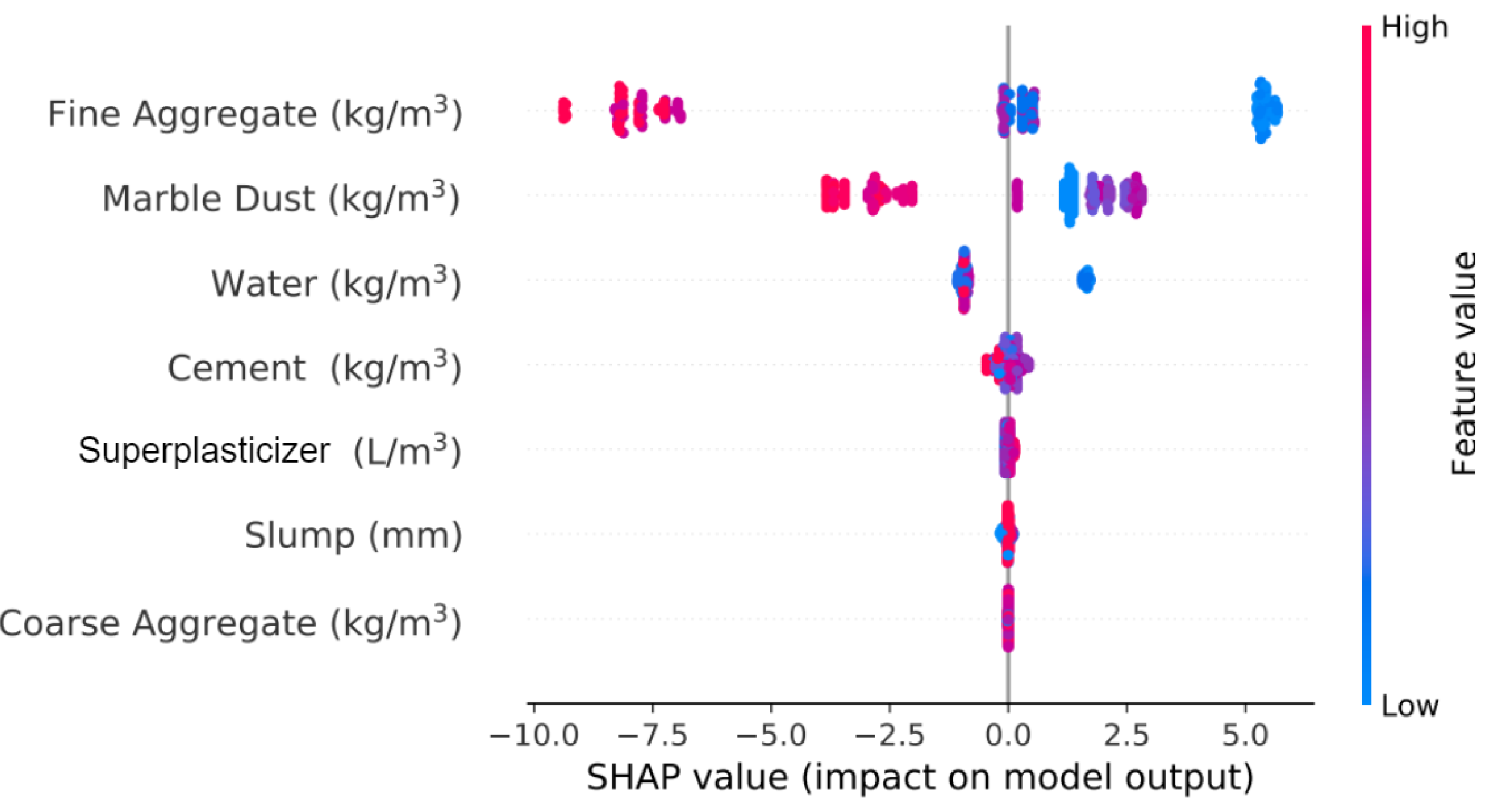
4.2. Analysis of the Best Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| WMP | Waste marble powder |
| ML | Machine learning |
| ANN | Artificial neural network |
| OPC | Ordinary portland cement |
| CS | Compressive strength |
| MLR | Multiple linear regression |
| KNN | K-nearest neighbour |
| SVR | Support vector regression |
| RF | Random forest |
| DT | Decision tree |
| ET | Extra tress |
| GB | Gradient boosting |
| GSS | Grid search strategy |
| MAE | Mean absolute error |
| MSE | Mean squared error |
| RMSE | Root mean squared error |
| MAPE | Mean absolute percentage error |
| MBE | Mean bias error |
| SHAP | SHapley Additive exPlanations |
| VIF | Variance inflation factor |
References
- Kore, S.D.; Vyas, A. Impact of marble waste as coarse aggregate on properties of lean cement concrete. Case Stud. Constr. Mater. 2016, 4, 85–92. [Google Scholar] [CrossRef] [Green Version]
- Pappu, A.; Thakur, V.K.; Patidar, R.; Asolekar, S.R.; Saxena, M. Recycling marble wastes and Jarosite wastes into sustainable hybrid composite materials and validation through Response Surface Methodology. J. Clean. Prod. 2019, 240, 118249. [Google Scholar] [CrossRef]
- Rana, A.; Kalla, P.; Csetenyi, L.J. Sustainable use of marble slurry in concrete. J. Clean. Prod. 2015, 94, 304–311. [Google Scholar] [CrossRef]
- Shamsabadi, E.A.; Roshan, N.; Hadigheh, S.A.; Nehdi, M.L.; Khodabakhshian, A.; Ghalehnovi, M. Machine learning-based compressive strength modelling of concrete incorporating waste marble powder. Constr. Build. Mater. 2022, 324, 126592. [Google Scholar] [CrossRef]
- Karimipour, A.; Jahangir, H.; Eidgahee, D.R. A thorough study on the effect of red mud, granite, limestone and marble slurry powder on the strengths of steel fibres-reinforced self-consolidation concrete: Experimental and numerical prediction. J. Build. Eng. 2021, 44, 103398. [Google Scholar] [CrossRef]
- Chu, H.H.; Khan, M.A.; Javed, M.; Zafar, A.; Khan, M.I.; Alabduljabbar, H.; Qayyum, S. Sustainable use of fly-ash: Use of gene-expression programming (GEP) and multi-expression programming (MEP) for forecasting the compressive strength geopolymer concrete. Ain Shams Eng. J. 2021, 12, 3603–3617. [Google Scholar] [CrossRef]
- al Swaidani, A.M.; Khwies, W.T. Applicability of artificial neural networks to predict mechanical and permeability properties of volcanic scoria-based concrete. Adv. Civ. Eng. 2018, 2018, 1–16. [Google Scholar] [CrossRef]
- Chithra, S.; Kumar, S.S.; Chinnaraju, K.; Ashmita, F.A. A comparative study on the compressive strength prediction models for High Performance Concrete containing nano silica and copper slag using regression analysis and Artificial Neural Networks. Constr. Build. Mater. 2016, 114, 528–535. [Google Scholar] [CrossRef]
- Eskandari-Naddaf, H.; Kazemi, R. ANN prediction of cement mortar compressive strength, influence of cement strength class. Constr. Build. Mater. 2017, 138, 1–11. [Google Scholar] [CrossRef]
- Naderpour, H.; Rafiean, A.H.; Fakharian, P. Compressive strength prediction of environmentally friendly concrete using artificial neural networks. J. Build. Eng. 2018, 16, 213–219. [Google Scholar] [CrossRef]
- Vakhshouri, B.; Nejadi, S. Prediction of compressive strength of self-compacting concrete by ANFIS models. Neurocomputing 2018, 280, 13–22. [Google Scholar] [CrossRef]
- Duan, Z.H.; Kou, S.C.; Poon, C.S. Using artificial neural networks for predicting the elastic modulus of recycled aggregate concrete. Constr. Build. Mater. 2013, 44, 524–532. [Google Scholar] [CrossRef]
- Deng, F.; He, Y.; Zhou, S.; Yu, Y.; Cheng, H.; Wu, X. Compressive strength prediction of recycled concrete based on deep learning. Constr. Build. Mater. 2018, 175, 562–569. [Google Scholar] [CrossRef]
- Ly, H.B.; Nguyen, T.A.; Tran, V.Q. Development of deep neural network model to predict the compressive strength of rubber concrete. Constr. Build. Mater. 2021, 301, 124081. [Google Scholar] [CrossRef]
- Nunez, I.; Marani, A.; Flah, M.; Nehdi, M.L. Estimating compressive strength of modern concrete mixtures using computational intelligence: A systematic review. Constr. Build. Mater. 2021, 310, 125279. [Google Scholar] [CrossRef]
- Mansouri, I.; Ozbakkaloglu, T.; Kisi, O.; Xie, T. Predicting behavior of FRP-confined concrete using neuro fuzzy, neural network, multivariate adaptive regression splines and M5 model tree techniques. Mater. Struct. 2016, 49, 4319–4334. [Google Scholar] [CrossRef]
- Sahoo, S.; Mahapatra, T.R. ANN Modeling to study strength loss of Fly Ash Concrete against Long term Sulphate Attack. Mater. Today: Proc. 2018, 5, 24595–24604. [Google Scholar] [CrossRef]
- Khan, M.A.; Zafar, A.; Farooq, F.; Javed, M.F.; Alyousef, R.; Alabduljabbar, H.; Khan, M.I. Geopolymer concrete compressive strength via artificial neural network, adaptive neuro fuzzy interface system, and gene expression programming with K-fold cross validation. Front. Mater. 2021, 8, 621163. [Google Scholar] [CrossRef]
- Aliabdo, A.A.; Abd Elmoaty, M.; Auda, E.M. Re-use of waste marble dust in the production of cement and concrete. Constr. Build. Mater. 2014, 50, 28–41. [Google Scholar] [CrossRef]
- Santos, T.; Gonçalves, J.P.; Andrade, H. Partial replacement of cement with granular marble residue: Effects on the properties of cement pastes and reduction of CO2 emission. SN Appl. Sci. 2020, 2, 1–12. [Google Scholar] [CrossRef]
- Singh, M.; Srivastava, A.; Bhunia, D. An investigation on effect of partial replacement of cement by waste marble slurry. Constr. Build. Mater. 2017, 134, 471–488. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, United States, 2020. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J.; DATA, M. Practical machine learning tools and techniques. In Proceedings of the Data Mining; Elsevier International Publishing: Amsterdam, The Netherlands, 2005; Volume 2. [Google Scholar]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Basu, V. Prediction of Stellar Age with the Help of Extra-Trees Regressor in Machine Learning. In Proceedings of the International Conference on Innovative Computing & Communications (ICICC), West Bengal, India, 29 March 2020. [Google Scholar]
- Zhang, Y.; Haghani, A. A gradient boosting method to improve travel time prediction. Transp. Res. Part Emerg. Technol. 2015, 58, 308–324. [Google Scholar] [CrossRef]
- Bonavetti, V.; Rahhal, V.; Irassar, E. Studies on the carboaluminate formation in limestone filler-blended cements. Cem. Concr. Res. 2001, 31, 853–859. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chemical Composition | OPC (%) | Marble Dust (%) | Physical Properties | OPC (%) | Marble Dust (%) |
|---|---|---|---|---|---|
| SiO | 20.27 | 3.86 | |||
| AlO | 5.32 | 4.62 | |||
| FeO | 3.56 | 0.78 | Specific gravity | 3.15 | 2.67 |
| CaO | 60.41 | 28.63 | |||
| MgO | 2.46 | 16.9 | Fineness (m/kg) | 313 | 250 |
| SO | 3.17 | - | |||
| LOI | 3.55 | 43.3 |
| Water–Binder Ratio | Cement (kg/m) | Marble Dust (%) | Marble Dust (kg/m) | Coarse Aggregate (kg/m) | Fine Aggregate (kg/m) | Superplasticizer (L/m) | Water (kg/m) |
|---|---|---|---|---|---|---|---|
| 0.35 | 422 | 0 | 0 | 1278 | 689 | 0.9 | 148 |
| 0.35 | 400.9 | 5 | 21.1 | 1278 | 689 | 1 | 148 |
| 0.35 | 379.8 | 10 | 42.2 | 1278 | 689 | 1.1 | 148 |
| 0.35 | 358.7 | 15 | 63.3 | 1278 | 689 | 1.2 | 148 |
| 0.35 | 337.6 | 20 | 84.4 | 1278 | 689 | 1.3 | 148 |
| 0.35 | 316.5 | 25 | 105.5 | 1278 | 689 | 1.4 | 148 |
| 0.4 | 394 | 0 | 0 | 1257.2 | 707.2 | 0.63 | 158 |
| 0.4 | 374.3 | 5 | 19.7 | 1257.2 | 707.2 | 0.67 | 158 |
| 0.4 | 354.6 | 10 | 39.4 | 1257.2 | 707.2 | 0.74 | 158 |
| 0.4 | 334.9 | 15 | 59.1 | 1257.2 | 707.2 | 0.84 | 158 |
| 0.4 | 315.2 | 20 | 78.8 | 1257.2 | 707.2 | 0.95 | 158 |
| 0.4 | 295.5 | 25 | 98.5 | 1257.2 | 707.2 | 1 | 158 |
| 0.45 | 351 | 0 | 0 | 1183 | 858 | 0.35 | 158 |
| 0.45 | 333.45 | 5 | 17.5 | 1183 | 858 | 0.39 | 158 |
| 0.45 | 315.9 | 10 | 35.1 | 1183 | 858 | 0.45 | 158 |
| 0.45 | 298.35 | 15 | 52.6 | 1183 | 858 | 0.52 | 158 |
| 0.45 | 280.8 | 20 | 70.2 | 1183 | 858 | 0.61 | 158 |
| 0.45 | 263.25 | 25 | 87.7 | 1183 | 858 | 0.7 | 158 |
| Variables | Minimum | Maximum |
|---|---|---|
| Cement (kg/m3) | 263.25 | 450 |
| Marble dust (kg/m) | 0 | 112 |
| Water (kg/m) | 148 | 200 |
| Superlasticizer (kg/m) | 0 | 1.4 |
| Slump (mm) | 84 | 199 |
| Aggregate (kg/m) | 1011.9 | 1278 |
| Sand (kg/m) | 675 | 858 |
| Compressive strength (MPa) | 21.23 | 42.67 |
| Metric | Formula | Description |
|---|---|---|
| R | Coefficient of determination: Measure of goodness of the fit | |
| MSE | Mean squared error: Measures closeness of the fitted line to the data points | |
| RMSE | Root mean squared error: Measures spread of the residuals | |
| MAE | Mean absolute error: Measures average of absolute differences between true and predicted values | |
| MAPE | Mean absolute percentage error: Measures average of absolute percentage differences between true and predicted values | |
| MBE | Mean bias error: Measures average of differences between true and predicted values | |
| T | t-statistic test: Measures significance of the differences between true and predicted values |
| Method | R Score | MAE | MSE | RMSE | MAPE | MBE | t-Stat |
|---|---|---|---|---|---|---|---|
| MLR | 0.852 | 2.095 | 7.152 | 9.455 | 6.819 | 0.007 | 0.191 |
| KNN | 0.919 | 1.655 | 3.914 | 9.692 | 5.427 | 0.028 | 0.155 |
| SVR | 0.911 | 1.747 | 4.380 | 9.660 | 5.761 | 0.048 | 0.175 |
| DT | 0.924 | 1.632 | 3.679 | 9.685 | 5.370 | 0.050 | 0.130 |
| RF | 0.926 | 1.608 | 3.561 | 9.679 | 5.291 | 0.051 | 0.126 |
| ET | 0.924 | 1.612 | 3.668 | 9.649 | 5.315 | 0.017 | 0.149 |
| GB | 0.923 | 1.621 | 3.719 | 9.650 | 5.333 | 0.037 | 0.100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, M.; Choudhary, P.; Bedi, A.K.; Yadav, S.; Chhabra, R.S. Compressive Strength Estimation of Waste Marble Powder Incorporated Concrete Using Regression Modelling. Coatings 2023, 13, 66. https://doi.org/10.3390/coatings13010066
Singh M, Choudhary P, Bedi AK, Yadav S, Chhabra RS. Compressive Strength Estimation of Waste Marble Powder Incorporated Concrete Using Regression Modelling. Coatings. 2023; 13(1):66. https://doi.org/10.3390/coatings13010066
Chicago/Turabian StyleSingh, Manpreet, Priyankar Choudhary, Anterpreet Kaur Bedi, Saurav Yadav, and Rishi Singh Chhabra. 2023. "Compressive Strength Estimation of Waste Marble Powder Incorporated Concrete Using Regression Modelling" Coatings 13, no. 1: 66. https://doi.org/10.3390/coatings13010066