1. Introduction
With the development of the marine industry and the rise of AIS data mining, more and more researchers use AIS to analyze maritime traffic problems [
1,
2,
3]. Cluster analysis is to group or cluster data according to the inherent similarity and characteristics between data to achieve the purpose of data mining [
4]. In maritime traffic applications, the clustering results may show the usual route and traffic volume distribution and regularity of marine environmental change [
5,
6,
7]. As a commonly used data mining method, ship trajectory clustering integrates the trajectory data of different ships into different categories or clusters. It’s beneficial for the maritime traffic management stakeholders, such as Maritime Safety Administration (MSA), to obtain insights on the operation status and characteristics of the regional traffic. In the meantime, ship trajectory clustering is one of the fundamental methods for trajectory prediction, anomaly detection, and avoiding ship collision [
8,
9], which draws much attention from academia.
According to the literature, various clustering methods have been proposed to conduct data clustering in multiple disciplines [
10]. Among them, the partition-based approach, the graph-based approach, the hierarchical-based approach, and the density-based approach are the frequently utilized clustering methods. K-means, as a representative of the partition-based clustering methods, have been widely utilized in related works with its simplicity and efficiency. Wang and Bai [
11] applied Min-Max k-means clustering error method to modify the global k-means algorithm, and overcome the effect of bad initialization, through the modified algorithm. Tyagi and Trivedi [
12] proposed a hybrid k-means algorithm to obtain the clustering results of color images, and the clustering results are refined using the Ant Colony Optimization (ACO) algorithm. Roiha et al. [
13] applied the genetic algorithm to find the initial centroid and improve the k-means method. Based on the structure database technology and k-means clustering, Jiang et al. [
14] proposed a classification and identification scheme to monitor the moving targets at sea. However, due to the drawbacks, such as sensitivity to the noises of data and the center of the cluster, such a method does not perform well for the data with noise.
Based on the graph theory, the spectral clustering algorithm transforms the clustering problem into the optimal division of graphs. Using the one-way distance between ship trajectories, Ma et al. [
15] applied the spectral clustering algorithm to extract the regular motion patterns of ships in Qiongzhou Strait, China. Nataliani and Yang [
16] proposed a powered Gaussian kernel function to improve the spectral clustering algorithm. Gao and Shi [
17] proposed a new method for recognizing a unique ship-handling behavior pattern based on multi-step sub-trajectory spectral clustering analysis. However, these improved algorithms have a common drawback, i.e., it is difficult to converge for data sets when the shape of clusters is irregular, and the number of the cluster has to be pre-set before the trajectory clustering, especially for some data with complex sample distribution [
10].
As another alternative for data clustering, density-based clustering is the data clustering method based on the density distribution of samples. Generally, density clustering starts from the perspective of sample density to check the connectivity between samples and continuously expands clustering, based on connectable samples, to obtain the final clustering result. DBSCAN has been widely used as a classic density clustering algorithm. A DBSCAN density clustering algorithm based on statistical methods to determine the parameters is proposed by Zhao et al. [
18], and the trajectory of the ship is clustered in the waters where the trajectory of the ship is unevenly distributed. Similar work was conducted by Zhao and Shi [
5]. The parameters of the DBSCAN algorithm were also determined by statistical methods. A large number of ship trajectories were evaluated and compared in the Beilun-Zhoushan Port of China. Zhao and Shi [
19] adopted a density-based clustering method and recurrent neural network for maritime anomaly detection.
With the increase in port cargo throughput, the form of water transportation has become more and more complex, which poses a challenge to the management of the maritime transportation system. The classic density-based clustering algorithms, such as DBSCAN, are difficult to obtain expected results for clustering ship trajectories with different densities. To do this in this research, we applied HDBSCAN, which is a hierarchical-density-based approach to conduct the clustering of ship trajectories with improvements on the algorithm to better adjust to AIS data. Campello et al. [
20] proposed a hierarchical clustering method that provides a clustering hierarchy from which a simplified tree of significant clusters can be constructed, and a novel cluster stability measurement to formalize the problem of maximizing the overall stability of selected clusters, and provides interpretable dendrogram plots. Zhang et al. [
21], Ghamarian and Marquis [
22], Lentzakis et al. [
23] and Ibrahim, et al. [
24] used HDBSCAN in their research and their conclusions prove that HDBSCAN has good results for clustering with different densities. Wilson et al. [
25] applied HDBSCAN on the trajectory clustering of flight data in the United States, within which a distance geometry is integrated into the method to cluster the flight trajectory with their shape characteristics. Wang et al. [
26] combined Dynamic Time Warping (DTW) and HDBSCAN to identify the main routes and speed profiles of water transportation in Shanghai and Ningbo ports. The results of the aforementioned researches have proved that the HDBSCAN method can perform well on trajectory clustering with noise. However, there are still some issues, for such methods, in practices with trajectory data containing complicated shape characteristics. Besides, the optimization of clustering performance and determination of number of clustering should also be improved.
In this research, an HDBSCAN-based ship trajectory clustering algorithm is adopted to propose a new ship trajectory clustering method with better performance and clustering flexibility compared with previous works. With the integration of the Hausdorff distance metric, the similarity between ship trajectories can be measured from the shape perspective. Besides, a new determination method on the number of clusters is also proposed to find the optimized number of clustering, based on comprehensive clustering performance metrics, to evaluate the clustering results. With such improvements, the HDBSCAN-based approach, proposed in our work, can have better performance on the ship trajectories data set where the traffic is complicated and can adaptively determine the optimized clustering number.
The contents of the paper are arranged as follows:
Section 2 briefly describes the methodology of this research, followed by a detailed description of the method and models utilized in
Section 3. On this basis,
Section 4 applies the algorithm model to a case study of ship trajectories in the research waters. Then, it is discussed in
Section 5 and is compared with some classic existing clustering algorithms. The results, discussion, and implication of the proposed method are concluded in
Section 6.
3. Model Design
3.1. Definition of Ship Trajectory
In this research, the Maritime Mobile Service Identifier (MMSI) is utilized to distinguish different ship trajectories. The trajectory of one ship can be described by a set
, where
is the trajectory of
ship i and
n is the number of ships, and the trajectory of ship
i is defined in Equation (1):
where
k is the sequence index number of a ship trajectory length, m is the total length of a ship trajectory during the analysis period, and
is the state vector of ship
i at time
,
and
are the coordinates of ship
i at time
.
3.2. Trajectory Data Preprocessing
The objective of this step is to preprocess the trajectory data obtained from the AIS. The first step is Mercator coordinate transformation, which transforms the spherical coordinates into the geodetic coordinates.
The second step is abnormal trajectory trimming with a time threshold. When analyzing the quality of the AIS data, there is a phenomenon that two trajectories of one ship, with a significantly large time difference, could be merged as one trajectory, which would hinder the results of the clustering. To avoid such an influence, a time threshold is utilized to differentiate these data. In the meantime, to improve the data quality, among all trajectory data traversal, trajectories will be cut into two segments if, and only if, the time interval among the datapoints exceeds the set threshold. The trajectory data will be separated into sub trajectories with a difference in the MMSI setting, i.e., the first part of the data continues to use the original MMSI and the second part of the data after the time difference is distinguished by a new artificial name, such as “MMSI” (e.g., the former MMSI is ‘431XXX431’, and after trajectory trimming, two substitutes could be found for MMSI—‘431XXX431’ and ‘431XXX431’).
The third step is to compress the data, based on the DP compression algorithm, to improve the clustering efficiency without losing the shape characteristics. The details of the algorithm setting in this research are as follows: For a curve composed of points, the first step is to set the distance threshold
D, the second step is to connect the first and last two points of the curve line to find a straight-line segment, the third step is to calculate the Euclidean distance, from each point on the broken line, to the constructed straight-line segment to find the maximum value
, and record the maximum point as P. if
, the curve segment is divided into two parts with P as the boundary; if
all points except the first and last points are deleted, and the third step is repeated until the curve can no longer be divided, the result is the simplified curve.
Figure 2 shows an example of the process:
3.3. Similarity Measures
The critical step for trajectory clustering is the similarity measurement. In this part, The first stage is calculating the Hausdorff distances between ship trajectories to obtain the distance measurements, based on which, a similarity matrix of ship trajectories is obtained by a similarity function introduced.
3.3.1. Hausdorff Distance
For two coordinate-based trajectories represented by
and
, their Hausdorff distance is calculated as Equation (2):
where
‖·‖ represents the Euclidean distance between a coordinate point in ship trajectory
A and a coordinate point in ship trajectory
B. In this research, the relative distance between the data points is in the Marcato projection system.
is the basic form of Hausdorff distance, which is the maximum between
and
. In such a design, the shape similarity between the two trajectories can be obtained without considering their lengths. An example of Hausdorff distance is shown in
Figure 3:
3.3.2. A Similarity Function with Adaptive Scale Parameters
To enlarge the similarity between the ship trajectory, after the Hausdorff distance calculation, a similarity function is applied [
27] as Equation (3):
where
and
are the mean values of Hausdorff distance between trajectory
i,
j, and other trajectories, and
is the final similarity matrix.
3.4. Ship Trajectory Clustering with HDBSCAN
Clustering often does not have an optimization goal and learning process such as classification, but rather a statistical method that separates data based on their similarity characteristics. A good clustering algorithm should have a certain stability, and the results will not change greatly due to a few samples. Besides, the algorithm should also minimize manual intervention to ensure the objectivity of clustering.
HDBSCAN, based on density clustering, combining with hierarchical analysis, meets this requirement to a large extent. Based on the original literature, the input parameters are
min_cluster_size and
min_samples [
20]. The former represents the minimum size of clusters and is the core parameter of HDBSCAN. The larger this parameter is, the smaller the final number of clustering species will be, and fewer points than this will be considered ‘noise.’ The latter is
min_samples, which defines the number of samples in a neighborhood for a point to be considered a core point. In this research, the parameters are selected, with statistical methods, in
Section 4. Besides this, there are some key definitions in the HDBSCAN method, which are as follows: (1)
Core distance: the distance between the sample point and the
nearest sample point; and (2)
mutual reachability distance: the value is the maximum value of the core distance of two sample points and the distance between two sample points. The mutual reachability distance can be obtained with Equation (4):
where
is the Euclidean distance between point
a and point
b. The advantage of this is that the sample distance in the dense region is not affected, while the distance between the sample points in the sparse region and other sample points is enlarged, which increases the robustness of the algorithm to noise points. On this basis, the procedure of utilizing HDBSCAN for ship trajectory clustering in our research is as follows:
First, establish a minimum spanning tree, with the mutual reachable distance between sample points as the edge, and transform the tree into a hierarchical structure. Next, use the input parameter min_cluster_size to find the compressed cluster tree. Finally, the density-adaptive clustering result is obtained through a stability function.
3.5. Clustering Performance Metrics
To evaluate the clustering results, this research proposes a synthetical clustering performance metrics for the clustering results produced by HDBSCAN. Considering practicability and objectivity of clustering performance metrics, two standard internal evaluation indices, the Silhouette Coefficient (SC) [
29] and the Davies-Bouldin index (DBI) [
30] are integrated to evaluate the performance of the clustering method.
SC measures the compactness of points in the same class compared with points in different classes. The SC value is within [–1, 1], as Equation (5) shows, closing to 1 means that the sample is far away from the adjacent class, which means it has a good clustering effect and high recognition rate. 0 means that the sample is almost on the decision boundary of two adjacent classes, and a negative value means that the sample is divided into the wrong class.
For given clusters,
, the sum of the average distance between the samples of two clusters is divided by the distance between the center points of two clusters,
. The smaller the average value of each cluster sample is (that is, the samples within the cluster are very close), the smaller the DBI is, and the better the clustering effect is. Then SC and DBI are defined as Equations (5) and (6), respectively.
where,
is the cohesion, which measures the average distance between data points within the cluster and
represents separation, which measures the minimum average distance of data points to other clusters.
Based on this, a comprehensive clustering performance metrics (CCPM) is proposed to evaluate the clustering results, Then CCPM is defined as Equation (7):
and the larger the CCPM value is, the better the clustering effect is.
3.6. Design of the Algorithm
The whole process of an HDBSCAN-based ship trajectory clustering method algorithm is implemented by Python.
Figure 4 shows the flowchart of the whole algorithm:
5. Discussion
In the previous section, a series of case studies are conducted to illustrate the process of the HDBSCAN algorithm on trajectory clustering in the area of ship complex confluence. In this section, the algorithm will be discussed in the comparison with the classic DBSCAN algorithm, k-means algorithm, and spectral clustering algorithm. Put forward the solution of a problem that trajectory clusters merge, since the similarity distance between clusters of some trajectories is too small, and the choice of the parameters min_cluster_size for HDBSCAN-based trajectory clustering.
5.1. Comparison with Other Clustering Algorithm
As a comparison, three cases of trajectory clustering with k-means spectral clustering and classic DBSCAN algorithms are shown in
Figure 10,
Figure 11 and
Figure 12, respectively, which use the same AIS data and same similarity matrix.
Table 3 gives the description of each method.
To select the best clustering sets of k-means, spectral clustering, and DBSCAN, the method based on the clustering performance metrics CCPM in
Section 4.3 is applied, and CCPM change graphs of different algorithms are shown in
Figure 10a,
Figure 11a and
Figure 12a, respectively.
According to the aforementioned figures, the CCPM scores of k-means and spectral clustering algorithms show a downward trend accompanied by oscillation, which means the trend of clustering results are worse with the value of parameter increasing. While the scores of DBSCAN and HDBSCAN both show intermediate peaks, which means both of them may have the best clustering result at the peak point. To prevent the occurrence of local optima, there are clustering results of the highest scoring point and the peak point of oscillation presented, respectively.
It can be seen, from the figures, that the four clustering algorithms all give the final clustering results, but due to the problem of data accuracy, and the character of the partition-based algorithm, they cannot identify the abnormal data and always deal with all data, the clustering effect using k-means and spectral clustering algorithms is not effective, i.e., they are not very good for the AIS trajectory of ships whose data quality is not very high (e.g., it can be seen from
Figure 10b–d). Whatever the input parameter
n_clusters is set, the clusters are always interspersed with each other, which is reflected, visually, that the colors are very mottled. The spectral clustering shows the same result (
Figure 11b,c), but a little better than k-means. In contrast, the DBSCAN and HDBSCAN (
Figure 7) mentioned in the case study, the clustering effect is effective, since they are density-based clustering algorithms and have a certain degree of robustness to noisy data, which means they have a better effect on low-quality data clustering (e.g., as shown in
Figure 12b,c, there is almost no mottled color anymore, and those abnormal trajectories are either removed or merged into clusters.). Although both algorithms are based on density, the classification of HDSBCAN is clearer than that of DBSCAN. Under the best CCPM, the numbers of clusters of HDBSCAN and DBSCAN are 13 (
Figure 9) and 10 (
Figure 12a), respectively. This is because the density field parameter
eps, used by DBSCAN, is a global variable, while HDBSCAN is density adaptive, that is, under different densities, the density field of HDBSCAN is self-adjusting, which is equivalent to a local variable. The trajectories at the bottom left of the graph are separated by HDBSCAN (
Figure 7), which is hard to find with DBSCAN. During the clustering process, DBSCAN is not as robust to data as HDBSCAN. The DBSCAN algorithm treats more trajectories as noise during the clustering process, while HDBSCAN is more tolerant of trajectories. There are a lot of noise trajectories in the actual environment, and due to the accuracy of AIS data, the higher the effect of trajectory clustering and the greater the utilization of data, the more water information we can obtain from it. This demonstrates that the advantages of the HDBSCAN algorithm are self-evident.
5.2. Analysis of the Clustering Results
As shown in
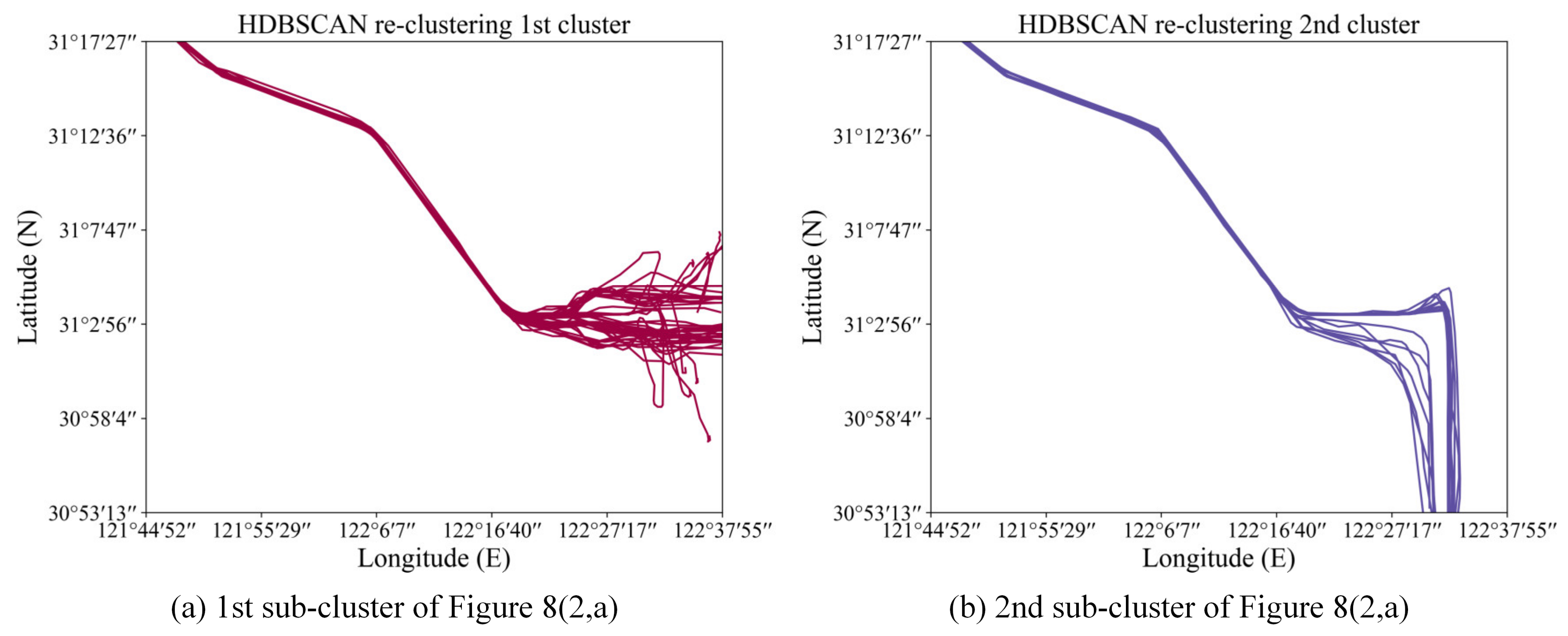
Figure 8, the clusters of those similar, but different, trajectories are hard to separate, as mentioned in some cases. In this part, aiming at the problem of it, a method of re-clustering is proposed to optimize the clustering results.
Obviously, the problem is caused by the trajectory similarity scaling, which cannot reach the desired effect. Without adjusting the similarity measure, it may be able to indirectly separate clusters of particularly similar but different trajectories by changing the clustering global variable min_cluster_size. The specific method is to extract those trajectory cluster data based on the results of the first trajectory clustering. Then repeat the clustering work. However, in this process, in order to identify multiple trajectory clusters that cannot be distinguished by the previous clustering, we need to adjust the clustering parameter min_cluster_size according to the actual situation.
This method re-clusters the clustering results below as
Figure 8 shows. The trajectory data in
Figure 8(2a) is re-clustered first. As can be seen from
Figure 8(2a), since the first half of the trajectory is close together, the two trajectory clusters, that should have been separated, have merged. Through the re-clustering method of trajectories, it optimized the clustering results to distinguish the original two overlapping trajectory segments as
Figure 13 shows. The re-clustering result of merged trajectory clusters in
Figure 8(2b) is shown in
Figure 14. In the process, the only change is resetting the input parameter
min_cluster_size and the values of each class are both 4.
The above results can prove that the re-clustering method is feasible. To a certain extent, this method solves the problem of insufficient cluster classification and optimizes the results of clustering.
5.3. Parameter Selection and Sensitivity Analysis
HDBSCAN is a clustering algorithm that combines hierarchy and density. Similar to the classic density-based clustering algorithm DBSCAN, HDBSCAN cannot directly determine the number of clusters through input parameters.
For the parameter
min_cluster_size, it can directly control the number of samples of the smallest cluster. From the results of the HDBSCAN clustering analysis, the clustering results are not very sensitive to the minimum cluster size parameter, as long as this parameter is selected small enough to cover all cluster sizes in the data set and large enough to generate between clusters and noise to make a meaningful difference. The change graph of the cluster number
n_clusters relative to the HDBSCAN input parameter
min_cluster_size provides a relatively simple method. It can determine the appropriate interval of the minimum cluster parameter value through the change in the slope of the scatter plot (
Figure 15).
Figure 15 indicates that, when the HDBSCAN input parameter is the only
min_cluster_size, and its value interval is defined as (2, 100) (considering that the total number of ship trajectories participating in the clustering is 710, the upper limit of the value of
min_cluster_size is set to 100), the changing trend of the number of clusters in the clustering result with the value of this parameter.
As can be seen from the figure, as the parameter value increases, the number of clusters decreases sharply at first, then, at the curve, a turning point appears and stabilizes a distance between (13, 25), and the number of clusters is around 8 at this time. Then the curve continues downward, and then no matter how the parameter value increases, the curve tends to be flat. In the initial change of the curve, because the parameter is too small, the algorithm cannot separate the cluster and the noise, resulting in an excessive number of clusters. When the parameter value exceeds 25, the cluster basically tends to remain unchanged because the parameter is too large, and the algorithm has difficulty separating different clusters. Therefore, for this set of data, the value interval of the parameter
min_cluster_size should be (13, 25), and the clustering result when the parameter value is 18 is shown in
Figure 16.
Under normal circumstances, it is not enough to only determine the size of the smallest cluster, because too large
min_cluster_size may merge some similar clusters (
Figure 16). In this case, we can reduce the value of the second parameter
min_samples (the default is equal to the parameter
min_cluster_size) to separate similar clusters (e.g., when we set its value as 4, the clustering result is shown in
Figure 7).
6. Conclusions
Ship trajectory records the navigation process and corresponding behavior characteristics of the ship. Through ship trajectory clustering, the behavior of ships can be further analyzed to provide empirical support for various applications, such as path planning and anomaly detection. In this paper, to ensure that trajectory clustering can be robust to noisy data, and to detect clusters with different densities in the process, an HDBSCAN-based ship trajectory clustering method is proposed. Then this method is tested by the AIS data from the Waters of the Yangtze River Estuary. To improve the objectivity of the clustering results and reduce the interference of human factors, based on the SC and the DBI, a clustering performance metrics CCPM is proposed to select clustering results. Moreover, in view of the problem that some clusters are difficult to distinguish, due to the inconspicuous contrast, a re-clustering method is applied to optimize the clustering results.
Besides, three cases based on k-means, spectral clustering, and DBSCAN algorithms of ship trajectory clustering are conducted. Based on the comparison, the advantage of HDBSCAN is proving with strong clustering scalability, which integrates both the advantages of density-based clustering algorithm and hierarchical analysis (i.e., It can not only identify the noise but also cluster ships trajectory of different densities). Besides, the selection method of clustering parameters still has certain limitations (the result is not one, but a series of clustering results), it needs to choose the best combination with the actual water traffic conditions. In the next stage, we will seek the HDBSCAN-based trajectory clustering method with adaptive input parameters.
Through the proposed HDBSCAN-based ship trajectory clustering method, this paper provides a new perspective for extracting the main routes of ships in the waters and seeking trajectory clusters in areas with different ship densities, which can better analyze the traffic conditions of ships in complex waters and facilitate maritime supervision.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}