Both
-SVR and
-SVR show good prediction performance in the field of ship motion prediction [
20,
21]. However, SVR needs to determine hyperparameters, such as the penalty factor (
). RVM is developed based on SVR. It uses Bayes’ theorem to obtain the probability prediction model without determining
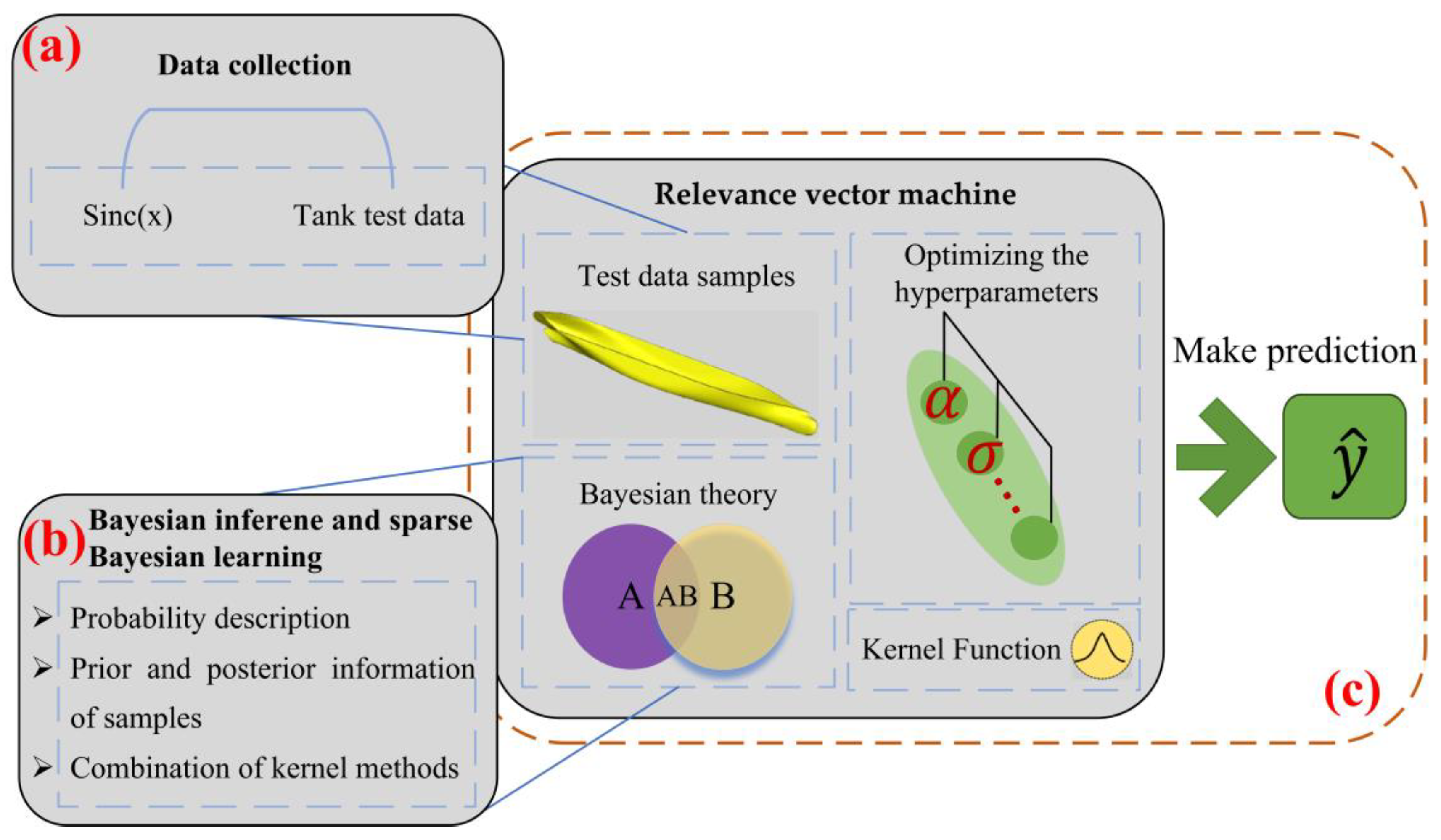
. Because RVM has only one hyperparameter to be tuned, it does not require an optimization algorithm to tune the hyperparameter, unlike SVR. The tuning of hyperparameters depends on the published research results and the swarm intelligence optimization algorithm. This study chooses the former. RVM’s feature is sparsity, which can improve prediction performance and efficiency. In the aspect of regression, the prediction model obtained by RVM is generally sparser than that obtained by SVR. Therefore, the speed can be improved when predicting test datasets. The structure of this research for RVM identification modeling is shown in
Figure 2.
4.1. Prediction Results of the Sinc Function Dataset
To validate the sparsity and prediction accuracy of the RVM, the Sinc function dataset with added interference is used as the verification sample. The interference is white noise with a mean of 0 and a variance of 0.02. Equation (19) lists the expression of the Sinc function. When
= 0, define Sinc(0) = 1. Take the independent variable
as the input data and the dependent variable
as the output data. The independent variable and dependent variable are scalars. The value range of
is [−20, 20]. The sampling interval is 0.2. The number of data samples is 201. A processed data sample is shown in
Figure 4.
In order to reasonably divide the training and test datasets, this research takes the odd numbered data samples as the training dataset and the even numbered samples as the test dataset. The number of training and test datasets is 101 and 100, respectively. In general, the training and test sets of the Sinc function dataset are divided in a 70%/30% ratio. Because three algorithms all have small sample learning ability, this study divides the Sinc function dataset into training and test datasets in the 50%/50% ratio. The training dataset is different from the test dataset.
Figure 4 shows that the processed data sample has certain noise interference. For
-SVR, the number of support vectors (SVs) depends on the setting of the insensitive factor (
). In general, the smaller the
, the higher the prediction performance. However, a decrease in
will cause an increase in the number of SVs and low calculation efficiency. For
-SVR, the setting of the parameter
can adaptively adjust the number of SVs without adjusting the
[
21]. To compare the experiment results, the three algorithms are set to different hyperparameter values [
20,
38]. In addition, compared with SVR, RVM only needs to set the kernel function parameter (
). In terms of tuning hyperparameters, RVM also shows certain advantages. For the three algorithms, this research mainly designed three different experiments (as shown in
Table 2). The experiment results of three algorithms are shown in
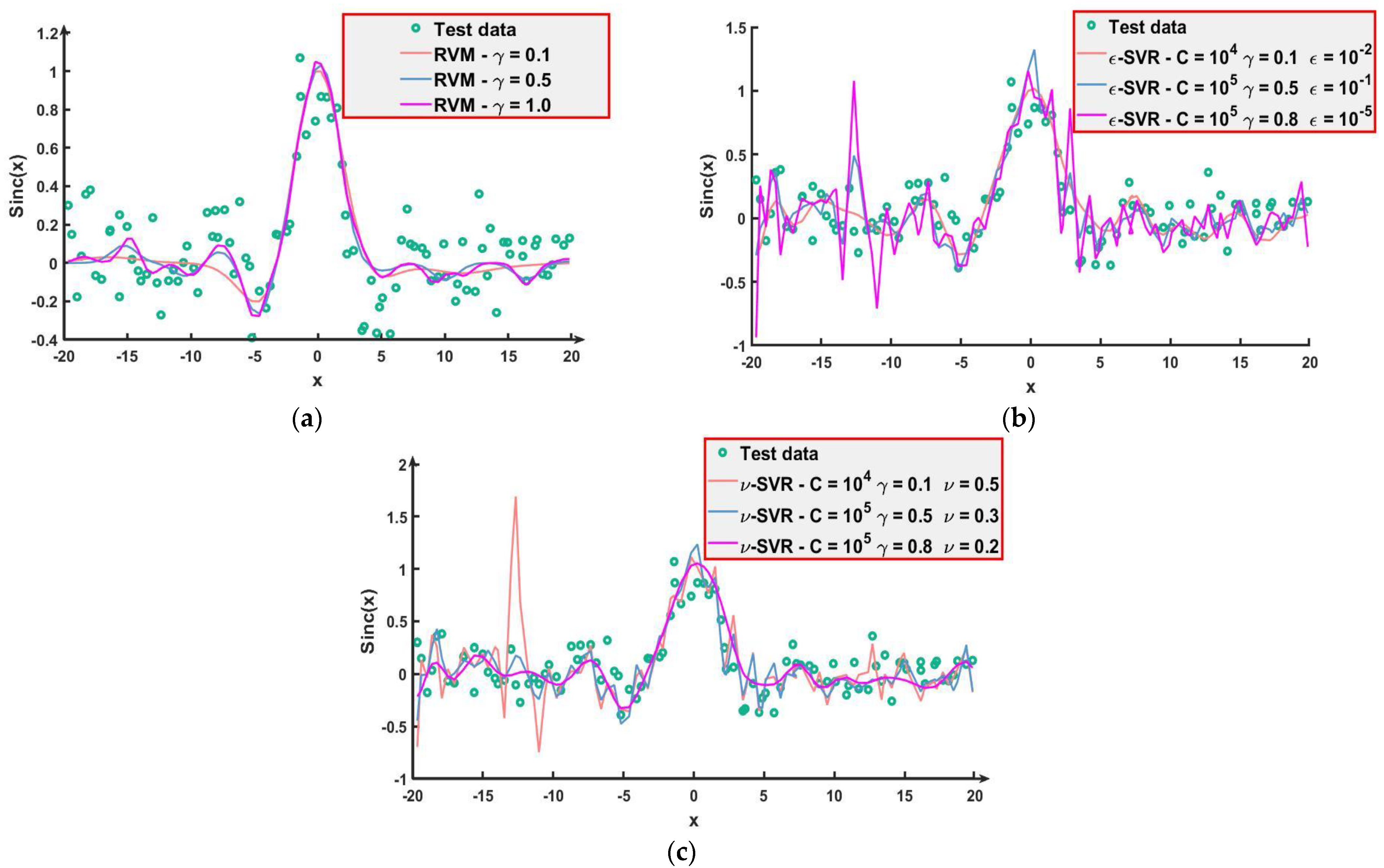
Figure 5.
Figure 5a shows that the prediction results of three experiments are smooth and fit the Sinc(x) test dataset for RVM well. In contrast, since three hyperparameters need to be set, the prediction accuracy of SVR is restricted. As can be seen from
Figure 5b,c, when the hyperparameters are set differently, the prediction results of SVR differ greatly.
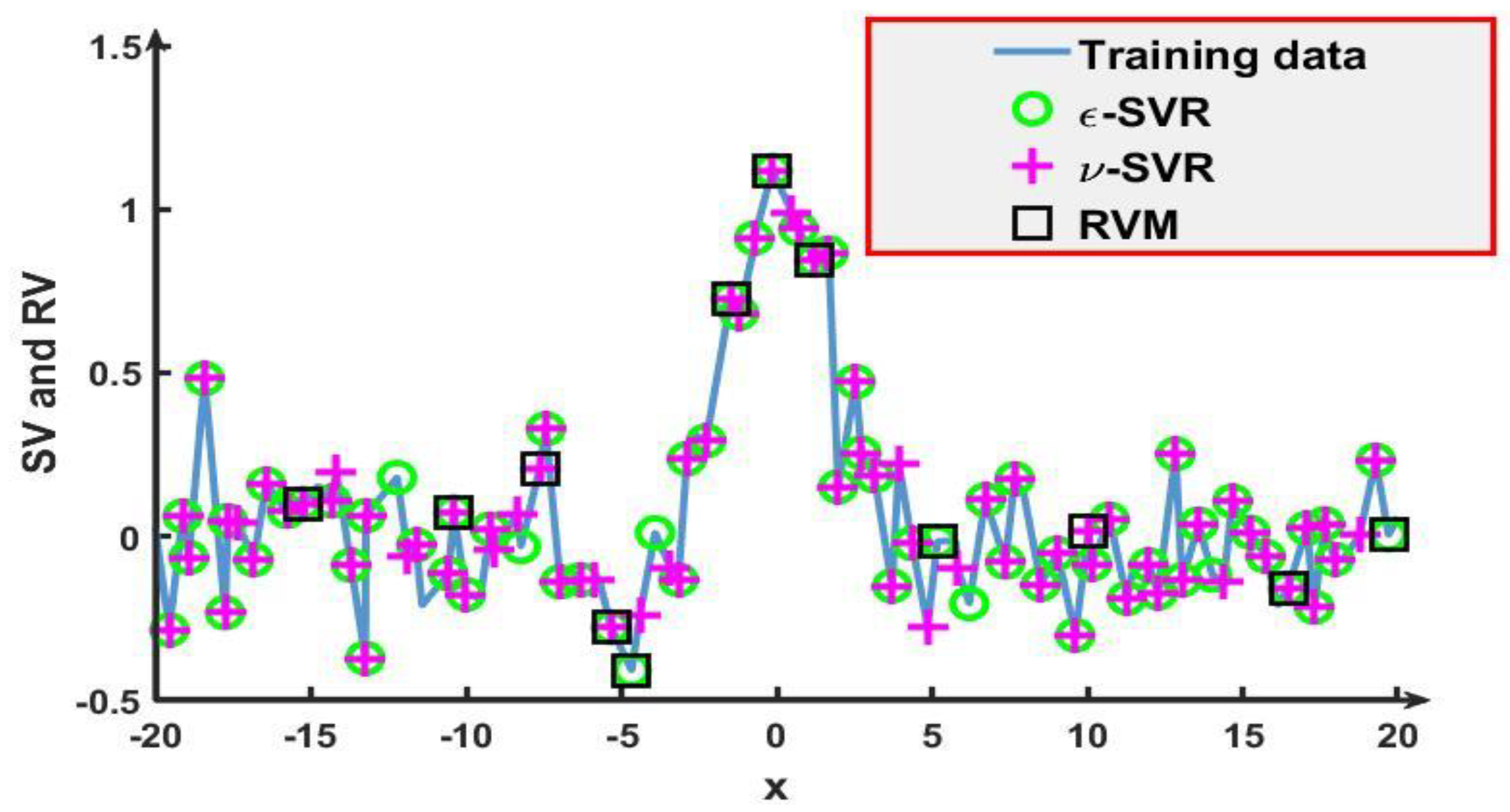
Table 3 shows the number of RVs and SVs in three experiments. To test the sparsity of the trained prediction model, the number of RVs and SVs in experiment (2) is compared. The comparison result is shown in
Figure 6.
Figure 6 shows that the number of RVs is less than the number of SVs in experiment (2). In the trained model, it can be seen from
Table 3 that the number of RVs is far less than the number of SVs for the three experiments. The average percentage of RVs is 11.56%. The average percentage of SVs is at least 6.8 times that of RVs. In addition, the highest percentage of RVs in the training sample is 16.83%. Compared with
-SVR and
-SVR, the results verify the sparsity of RVM, i.e., RVM can attain sparser prediction models. In terms of time consumption, RVM spends a total of 0.286 s on training and predicting. However, SVR takes relatively more time, especially
-SVR. The mean square error (MSE) is used as the evaluation criteria to verify the prediction performance.
Table 4 lists the MSEs of prediction results for the three experiments. As can be seen from
Table 4, the three algorithms all have good prediction effect in the Sinc function dataset, but the prediction accuracy obtained by RVM is better compared with SVR.
Remark 2. In this section, the research utilizes the prediction results of the Sinc function dataset to verify the performance of RVM. In the setting of the hyperparameters, the research designs different experiments according to the role of hyperparameters. In the process of experiments, the settings of , , and have a great effect on the prediction accuracy and time consumed. After comparison, the prediction model obtained by RVM is relatively sparse (the number of training samples is 101). In Section 4.2, this research increases the number of training samples to further verify the sparsity and prediction performance. 4.2. Prediction Results of Tank Test Dataset for KCS
In
Section 4.1, using the Sinc function dataset, the sparsity and prediction performance of RVM are verified by the three experiments. The KCS is taken as the main research plant to further verify the sparsity and generalization of RVM. By dividing the training dataset and selecting the hyperparameters reasonably, the 3 DOF motion prediction models of KCS are obtained. The tank test data for the KCS is from the SIMMAN 2020 workshop [
37]. It has some noise interference, so there is no need to add the noise interference.
Table 5 shows the main particulars of KCS.
In the SIMMAN 2020 workshop, the tank tests of KCS include the −10°/−10°, 20°/20°, −20°/−20° zigzag maneuvers, and the −35° turning maneuver. Due to the effect of sensors and other factors, the test datasets have noise interference [
37]. In addition, the training dataset should reflect more dynamic information of the KCS. Therefore, a small part of the −10°/−10° and −20°/−20° zigzag maneuver data is used to construct the training dataset. The 20°/20° zigzag maneuver data and −35° turning maneuver data are taken as test datasets. The number of training and test datasets is shown in
Table 6.
As can be seen from
Table 6, the number of training datasets is 465. This is about five times the number of training datasets in the Sinc function dataset. This research further verifies the sparsity of RVM from the perspective of KCS motion prediction. It is essential to determine the hyperparameters of the three algorithms to make the motion prediction results more accurate. These hyperparameters are set according to previous research [
20,
21,
39]. For the prediction of
,
, and
, the hyperparameters of
-SVR,
-SVR, and RVM are set to different values. The setting values of the hyperparameters are shown in
Table 7.
Remark 3. Compared to -SVR and -SVR, RVM only has one parameter to tune, and no optimization algorithm is needed for further optimization. This also reflects the advantages of RVM from the perspective of hyperparameter tuning. For SVR, the settings of , , and have a great influence on the results of ship motion prediction. Sometimes, the larger the , the less accurate the prediction will be.
According to the training datasets and the setting of hyperparameters, the motion prediction models of KCS are obtained. The test datasets are −35° turning maneuver data and 20°/20° zigzag maneuver data, respectively. The prediction models trained by the three algorithms are compared to verify the sparsity. For the prediction models of
,
, and
, the number of RVs and SVs is shown in
Table 8.
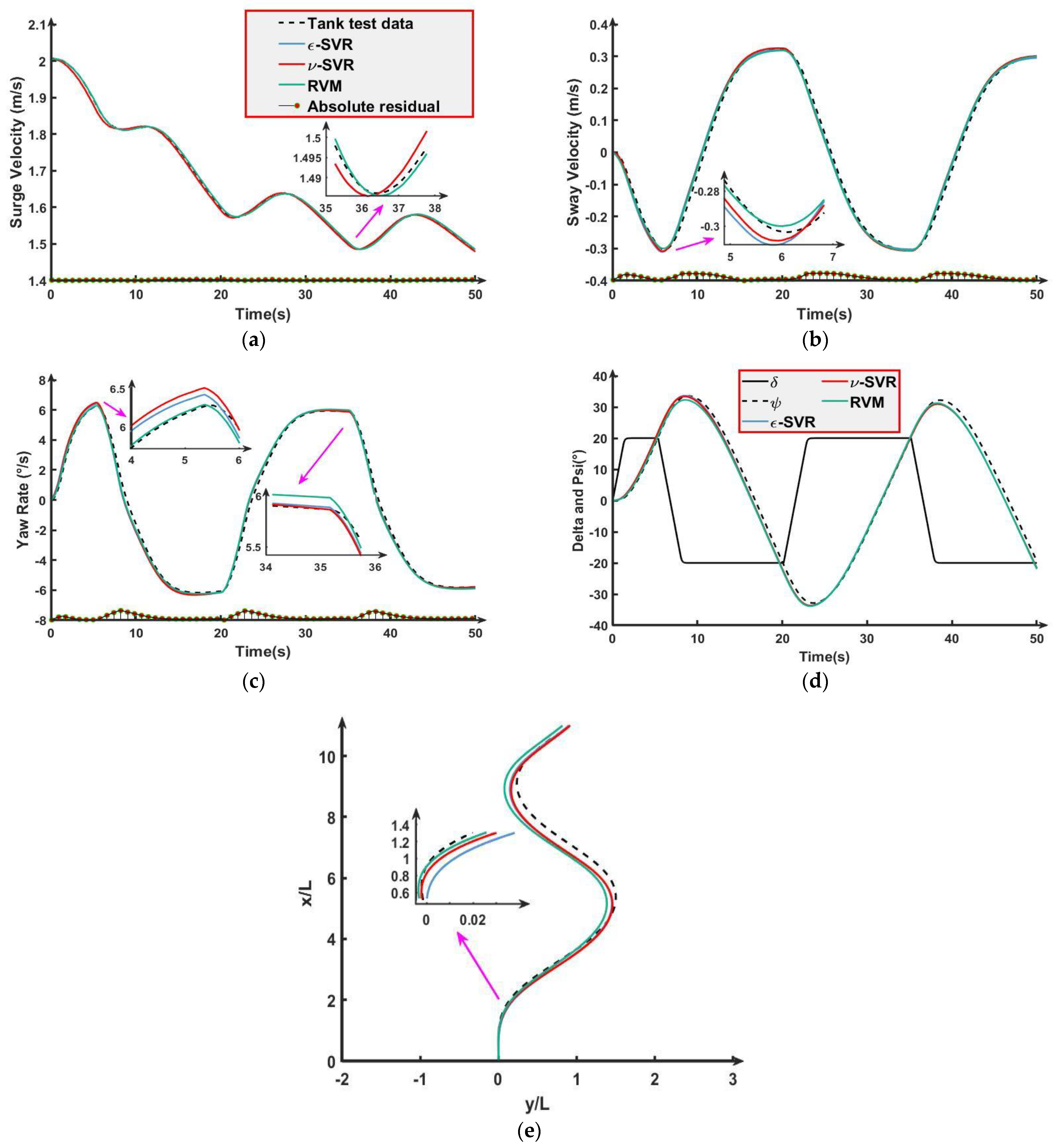
Figure 7 shows the prediction results of −35° turning maneuver data.
Table 9 shows the MSEs of motion prediction results for the −35° turning maneuver.
RVM constructs a learning machine based on Bayes’ theorem rather than the structural risk minimization principle. As the number of training samples increases, it can be seen from
Table 8 that the number of RVs is far less than the number of SVs. This further verifies the sparsity of the proposed algorithm. For the trained model obtained by
-SVR,
is set as 0.5 [
21]. However, the sparsity of
-SVR is worse than that of
-SVR. In
Figure 7, the length of the absolute residual represents the prediction error. Moreover, only the absolute residuals of the ship motion prediction are presented.
Figure 7a,b show that the prediction error of the three algorithms is small. As can be seen from
Figure 7c, the three algorithms all have some prediction errors. For the prediction results of RVM, the maximum absolute residual is 0.52°. In the later stage of yaw angle prediction, the three algorithms all have certain deviations from
Figure 7d. In the prediction results of the KCS motion trajectory, the degree of coincidence between the results predicted by the RVM and the tank test data is higher. For the time required to predict
,
, and
, RVM,
-SVR, and
-SVR took the total of 0.749 s, 4.307 s, and 3.985 s, respectively.
Table 9 shows the MSEs of the prediction results. For the prediction results of
, the percentage errors for
-SVR and
-SVR are 29.62% and 56.01%, respectively. Using the proposed algorithm, the accuracy of other prediction results can be improved by more than 22.22%. The generalization of RVM is demonstrated from the data prediction results. The 20°/20° zigzag maneuver data of the KCS is taken as another data sample to further validate the generalization of RVM. Although there are some similarities between the 20°/20° zigzag maneuver data and the −20°/−20° zigzag maneuver data, there are some differences, such as the opposite excitation of the input rudder angle. The hyperparameter settings of the three algorithms are shown in
Table 7. The prediction results of the 20°/20° zigzag maneuver are shown in
Figure 8.
Table 10 shows the MSEs of the prediction results for the 20°/20° zigzag maneuver.
It can be seen from
Figure 8 that the three algorithms have high accuracy for motion prediction of the 20°/20° zigzag maneuver due to certain similarities between the test data and the training data. In
Figure 8c,e, the prediction results of RVM have certain deviations in the later stage. However, as can be seen from
Table 10, the overall prediction results of the KCS motion based on RVM are better than SVR. For the final prediction result, the accuracy can be improved by more than 14.04% with the proposed algorithm. For the time required to predict
,
, and
, RVM,
-SVR, and
-SVR took the total of 0.746 s, 4.152 s, and 3.952 s, respectively. In addition, the three algorithms have high accuracy for
. The first overshoot angle of the KCS is 33.56°. The first overshoot angle predicted by the proposed algorithm is 32.28°.
RVM is an algorithm that combines kernel methods and Bayes’ theorem. Under the structure of a priori parameter, the automatic relevance determination is used to remove the irrelevant sample points to obtain a sparse model. The sparse model simplifies the model and can avoid overfitting to some extent. The reason is that it retains the explanatory variable most relevant to the response variable. In the prediction of −35° turning maneuver data and 20°/20° zigzag maneuver data, the prediction models obtained by RVM have good sparsity and prediction accuracy.
Remark 4. In this section, the research utilizes the prediction results of the tank test dataset to further verify the sparsity, effectiveness, and generalization of RVM. From the perspective of the trained model, as the number of training samples increases, the RVM can still maintain a certain degree of sparsity. Although there are certain prediction errors, the overall prediction curve of RVM fits the tank test data curve well.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}