1. Introduction
The knowledge of the underlying mechanisms of propeller/rotor tip vortex evolution in the far field is an intriguing and still open problem of fluid dynamic research, which plays an important role in many applications of marine, aerospace, and mechanical engineering because of its impact on performance, vibrations, noise, and structural problems. A prominent example is wind parks, where power production, radiated sound, and fatigue lifetime of interior turbines might be significantly affected by the dynamics of the wake vortices released from surrounding turbines, see, e.g., [
1,
2,
3]. Previous studies [
4,
5] have shown that propeller wake instability is driven by mutual inductance mechanisms, which lead adjacent vortex filaments to pair analogously to the leapfrogging motion of two inviscid vortex rings [
6,
7]. Vortex pairing [
4,
8,
9] manifests through a multi-step grouping process that depends on the blade number. This behavior has been highlighted by flow visualizations and phase-locked particle image velocimetry (PIV) measurements in the propeller transitional and far fields [
10,
11]. In spite of these results and to the authors’ best knowledge, rigorous, in-depth analyses focused on classifying the nature of the propeller tip vortex dynamics in the far field are still extremely limited, likely due to the complexity associated with the inherently multi-scale, highly turbulent, strongly unsteady nature of the flow, which makes its survey extremely challenging even using the most advanced experimental and computational tools.
Data science, machine learning, and artificial intelligence have emerged as cutting-edge research fields where rigorous methods and algorithms are developed and applied to gain knowledge from data. In recent years, these methods have been applied in the context of more traditional disciplines to accelerate the experimental/computational analysis process and extract insights from experiments and simulation data. In the field of ship hydrodynamics, supervised machine learning techniques, such as surrogate modeling, regression, and multi-fidelity methods, have been employed to integrate experimental and simulation data. These methods aim to reduce the computational burden associated with design performance assessment and optimization procedures along with facilitating the interpretation of the physics observed. Furthermore, unsupervised machine learning methods, including equivalent approaches to proper orthogonal decomposition (POD) and/or linear/non-linear principal component analysis (PCA), have been utilized to address challenges such as dimensionality reduction, efficient design, and operational space exploration, and gain insights into complex physical phenomena. POD, which is closely related to PCA, has found widespread application in the identification of coherent structures within turbulent flows [
12] and has been employed in the study of various flow configurations, including steady and transient jets [
13,
14] and marine propeller wakes [
5]. By decomposing the flow into a linear combination of orthogonal eigenfunctions, POD provides valuable information about the spatial and temporal structure of the flow, enabling the construction of reduced-order models. However, it is important to note that while POD enjoys established global optimality properties, its effectiveness may be limited when investigating non-linear, transient, non-stationary, and non-ergodic dynamics. To address these limitations, non-linear dimensionality reduction (NLDR) methods have been developed and applied to gain a deeper understanding of data structures and physical phenomena. One straightforward approach to NLDR in conjunction with POD/PCA is to employ data clustering methods and perform POD/PCA within each cluster. This approach allows for a more comprehensive analysis and characterization of the underlying dynamics.
Cluster-based reduced-order modeling through POD/PCA offers valuable insights into complex phenomena by employing local PCA (LPCA), which partitions the dataset into clusters and applies POD/PCA within each cluster, assuming an approximate linear structure within them. The cluster centroids, together with their associated modes, capture relevant flow features in the spatial and temporal domains. Previous studies have demonstrated the application of spatial clustering using the
k-means method with POD/PCA for analyzing a transient buoyant jet [
15] and for characterizing a swirl-stabilized combustor flow through temporal and spatial
k-means clustering [
16]. It is worth noting that the choice of the number of clusters and the similarity metrics used for data clustering significantly impact the quality of the resulting reduced-order/dimensionality model, thereby influencing the extraction of meaningful physical insights from the clustering analysis. Rigorous data-clustering methods have been proposed in various fields to facilitate a deeper understanding of experimental and simulation data. To achieve fully non-linear dimensionality reduction, a promising technique called
t-distributed stochastic neighbor embedding (
t-SNE) has been proposed [
17]. This method allows for embedding and visualizing high-dimensional data in a low-dimensional space and has been successfully applied to turbulence datasets from simulations [
18].
Examples of data-clustering analysis applied to PIV experimental data are still limited, see, e.g., [
19], where
k-means is applied to study the internal aerodynamics of a Miller cycle gasoline engine. Examples of data-clustering analyses applied to propeller performance and, in general, vortex dynamics are also limited. Calvet et al. [
20] developed an unsupervised machine learning strategy to automatically cluster vortex wakes of bio-inspired propulsors into groups of similar propulsive thrust and efficiency metrics. Doijode et al. [
21] introduced a clustering approach for optimizing propellers by directing the search for the optimal design towards design clusters with good performance, i.e., high propulsive efficiency and low cavitation. Finally, Sharma and Simula [
22] considered computer-generated configurations of quantized vortices in planar superfluid Bose–Einstein condensates, showing how data-clustering approaches can be successfully used for classifying vortex configurations to identify prominent vortex phases of matter.
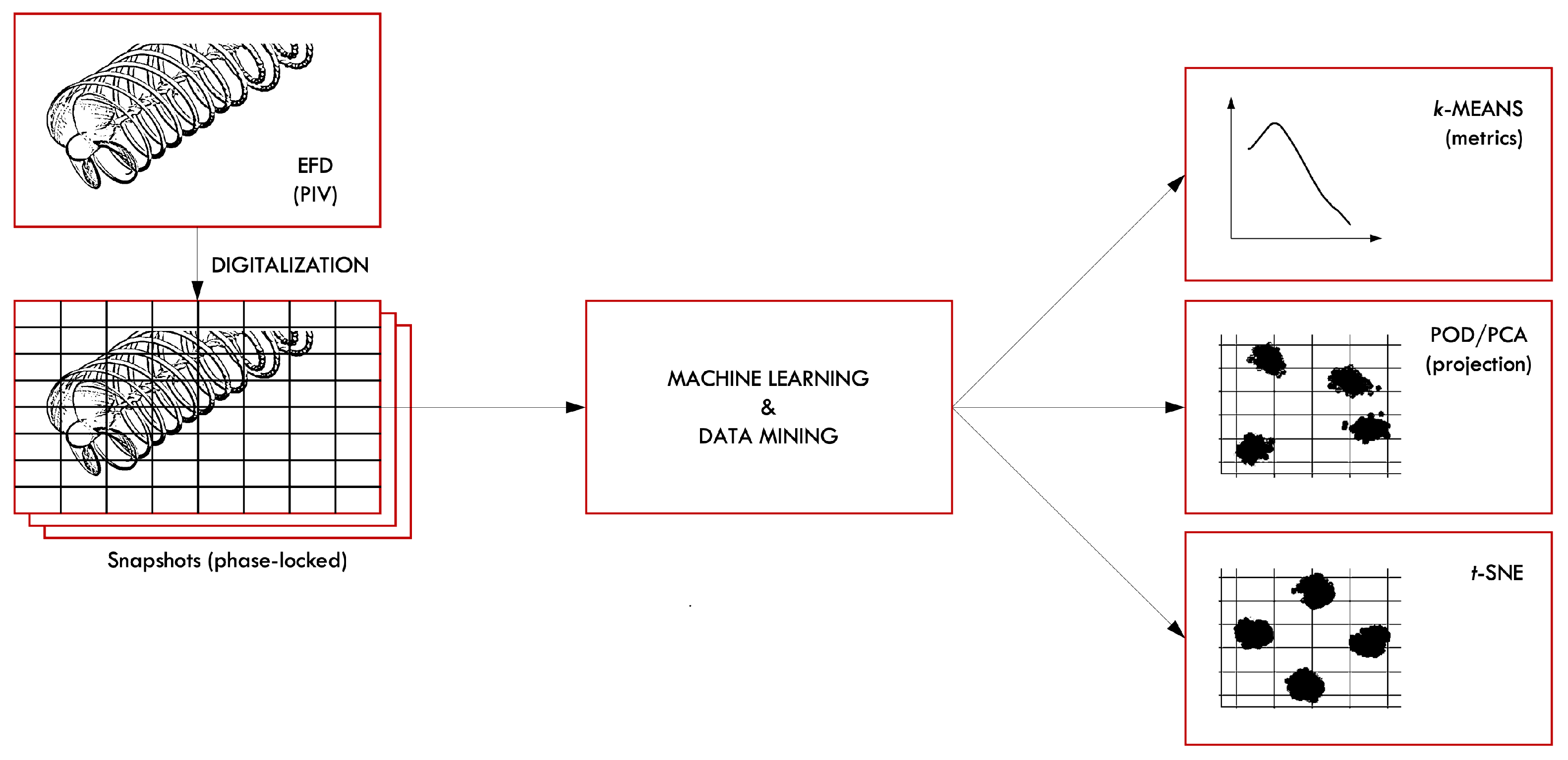
The objective of this study is to establish a systematic approach for conducting a data-clustering analysis of PIV data to gain valuable physical insights into the dynamics of propeller tip vortices. Phase-locked PIV snapshots recorded throughout the transitional and far fields of a propeller wake (see
Figure 1) are used in the clustering analysis.
Specifically, the velocity fields under investigation are obtained from experimental tests with large-scale, phase-locked, PIV measurements. Data were collected in the cavitation tunnel of CNR-INM [
23]. The clustering of PIV data is based on the
k-means algorithm. Data clustering is applied to phase-locked snapshots to gain knowledge on the topology of wake instability and its stochastic realizations. The vorticity is used as a clustering variable. The resulting cluster centroids identify the topology of the instability, where two or more tip vortices interact and coalesce [
4,
11]. Two metrics are used for the identification and assessment of clustering methods, including the selection of the proper number of clusters, namely: (i) within-cluster sum of squares and (ii) average silhouette. Additionally, the embedding of data via POD/PCA and
t-SNE is used to define and visualize data clusters in a reduced dimensionality space. Finally, kernel density estimation (KDE) is applied to POD/PCA and
t-SNE representations to provide continuous data distributions for assessment and discussion. The overall workflow is synthesized in
Figure 2.
The remainder of the paper is organized as follows: experimental details are provided in
Section 2;
Section 3 presents the data analysis methods and metrics; the numerical results are presented in
Section 4; finally, conclusions and future perspectives are given in
Section 5.
2. Experimental Methods
The present study is based on a comprehensive database of flow measurements of the E1658 submarine propeller wake in open water using 2D-PIV [
5,
24], see
Figure 1. The database covers an extensive set of propeller conditions in terms of advance coefficients and blade number configurations, providing a wide range of vortex instability and interaction mechanisms that are crucial for the objectives of the present study. In particular, the present study focuses on a propeller configuration with four blades and one value of the advance ratio, corresponding to a high propeller loading (i.e.,
).
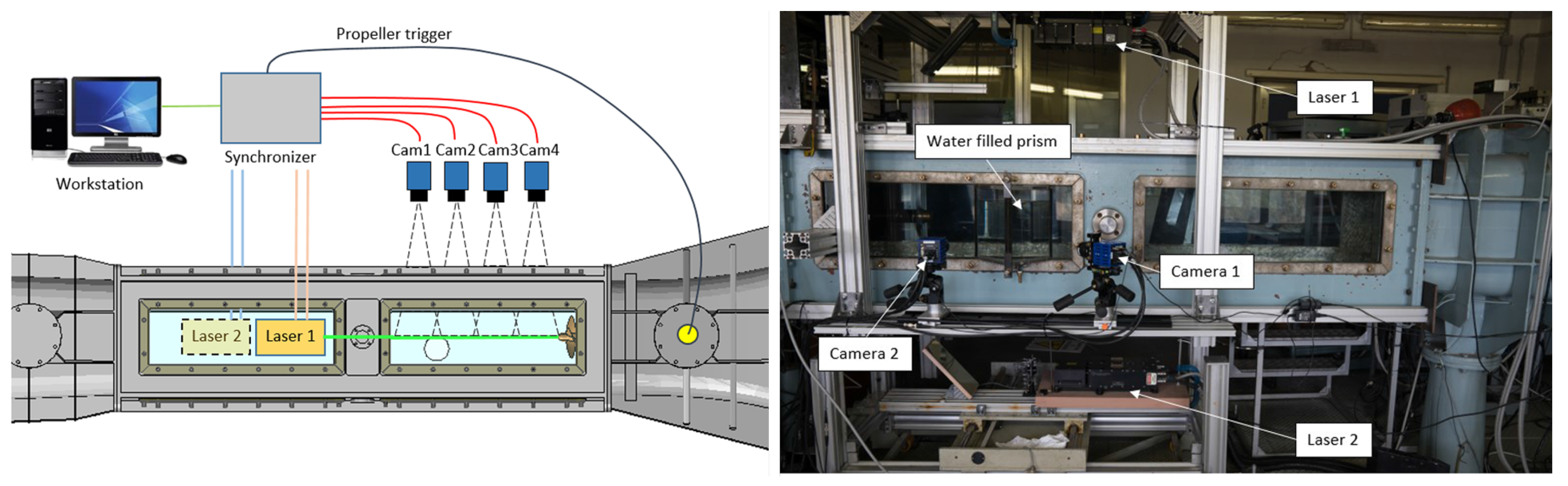
The experimental campaign was carried out at the CNR-INM cavitation tunnel, measuring the propeller wake flow at the vertical center-plane by a 2D-PIV system. The setup consisted of three 5 Mpx sCMOS cameras by PCO and two 200 mJ Nd-Yag Lasers by QUANTEL. Either cameras and lasers were positioned side by side to simultaneously record/illuminate a long portion of the wake flow (i.e., from the propeller plane to 3.3 D downstream, where D is the propeller diameter) at full resolution (4, 22, 23). This arrangement (see
Figure 3), already adopted in other similar experiments [
5,
10,
11], allowed the simultaneous reconstruction of a long portion of the wake flow (i.e., from the propeller plane to 3.3
D downstream, where
D is the propeller diameter) without jeopardizing the spatial resolution.
The camera acquisition process was synchronized with the propeller reference blade at a specific angular position, facilitated by the coordination of four cameras and two lasers with a TTL OPR (Once Per Revolution) signal. This signal was generated by a rotary incremental encoder mounted on the propeller dynamometer, providing a frequency of 3600 pulses per second.
Hollow glass spheres, featuring a nominal diameter of 10 μm and a specific weight of 1.05 g/cm
3, were utilized as tracers in the experiment. The acquired images underwent pre-processing using a local background subtraction routine with a 4 × 4 px
2 kernel. This pre-processing step effectively eliminated unwanted reflections and improved the signal-to-noise ratio. The vector calculation was performed using the advanced iterative multi-pass, multi-grid, image deformation algorithm [
25]. Leveraging the GPU architecture of the workstation and the PIV algorithm, a combination of direct cross-correlation and parallel processing was employed, enabling both accurate and efficient evaluation of the images. The interrogation windows were iteratively reduced to a final size of 32 × 32 px
2, with a 50% overlap between adjacent windows.
4. Results
POD/PCA implementation for the propeller wake uses the following decomposition of the vorticity
where
is the vorticity
z-component (out of plane) and
x and
y are the axial/horizontal and vertical coordinates, respectively. Overbar and prime characters indicate time average and fluctuations, respectively.
Snapshot clustering is performed using vorticity snapshots following clustering variables as
Data sets are organized in phase-locked snapshots, where each phase is typically observed hundreds of times.
The
data matrix
D is defined as
where
collects the discretized vorticity fluctuations,
represents the
i-th node of the spatial discretization,
P is the spatial discretization size, superscript
, with
, indicates the
i-th time realization (snapshot), and finally,
. Data analysis is performed using in-house Python scripts based on the Scikit-learn library [
38].
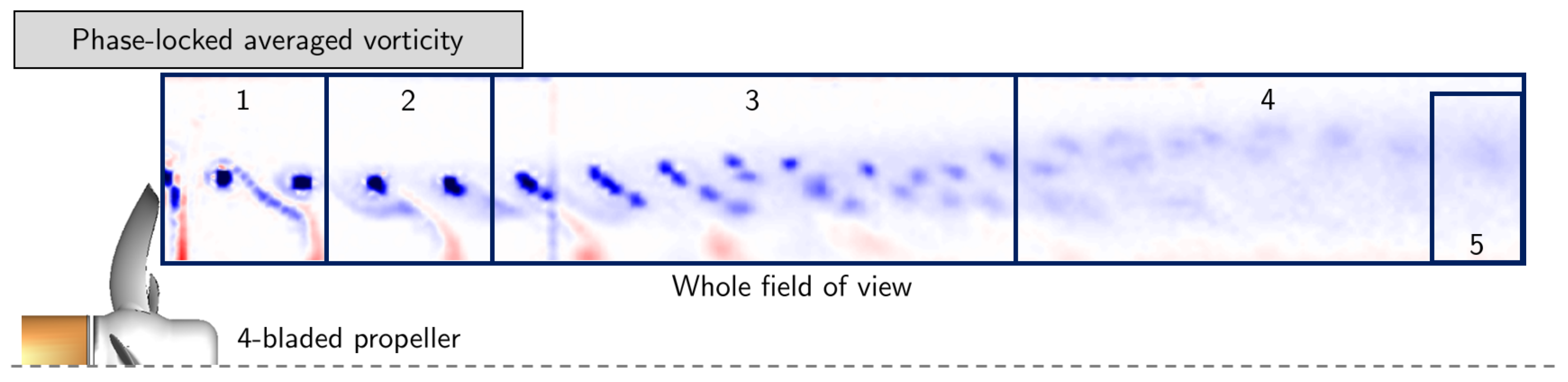
Four phase-locked vorticity data sets (0, 90, 180, and 270 deg) are used, where each phase is observed 250 times for a total of 1000 snapshots. The snapshots are organized (subsampled) in a
array, ranging axially from 0 to 3.3
D, and radially from 0.3 to 0.8
D, focusing on the tip vortex only (see
Figure 4). The data matrix has a dimension equal to 6000 × 1000. It may be noted that once the data matrix is formed, the information on the phase is lost (as this information is not included in the data matrix).
First, the
k-means is applied to the whole field of view (see
Figure 4).
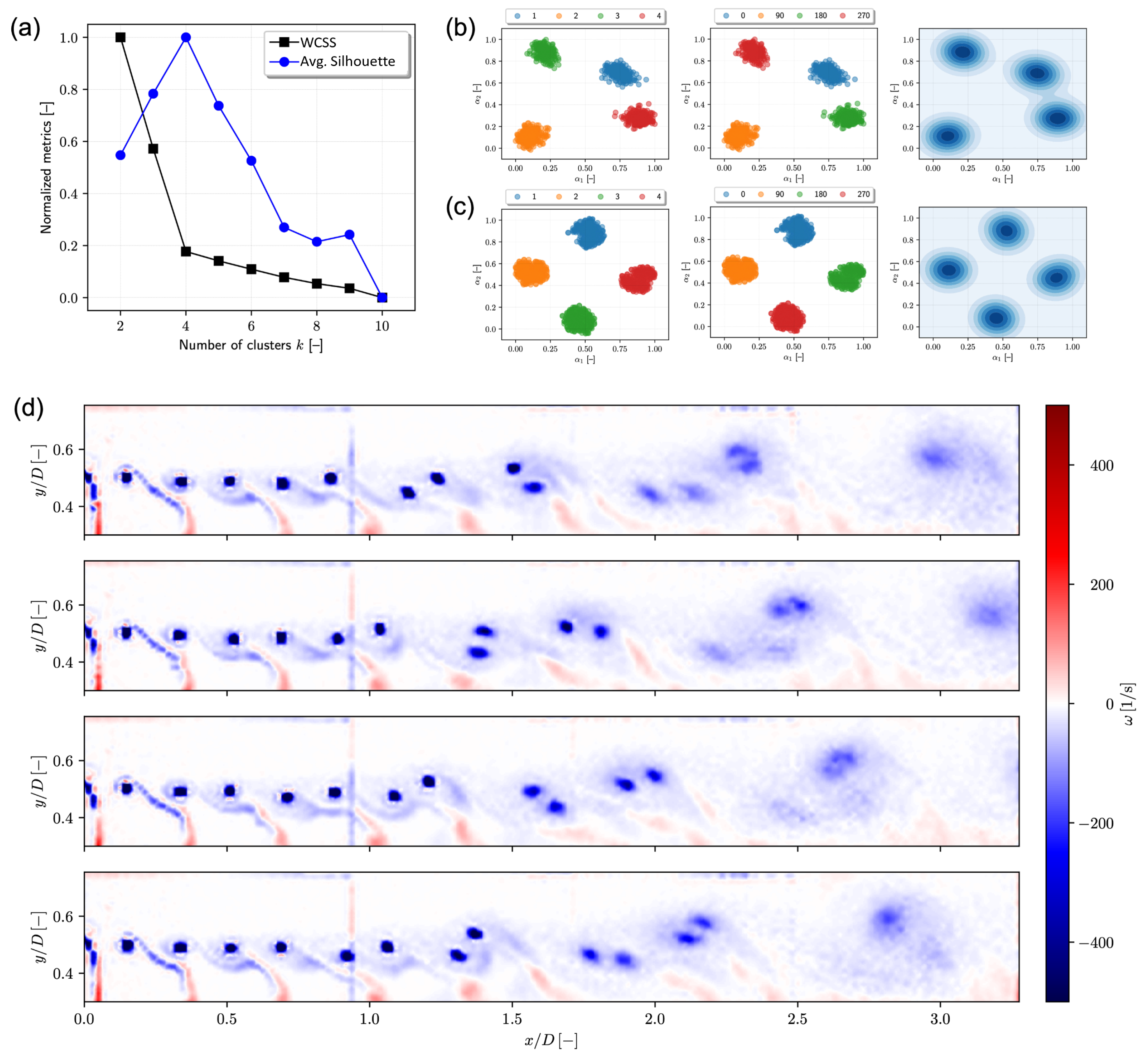
Figure 5a shows that four clusters emerge from the data set. Specifically, WCSS shows a clear elbow corresponding to
. The average silhouette exhibits a clear maximum corresponding to
.
Figure 5b shows the projection of the data set onto the first two POD/PCA modes. Data are labeled both by cluster and phase, showing that the method is able to recover phase information, and the data set is clearly clustered by phase. A similar analysis and visualization is shown using
t-SNE in
Figure 5c, confirming the POD/PCA result. Finally,
Figure 5b,c (right side) provide joint and marginal probability density functions of POD/PCA and
t-SNE coefficients
and
given by KDE, confirming the data have four clusters of equal size. The corresponding cluster centroids are presented in
Figure 5d, showing that the mechanism of vortex coupling and convection downstream is globally (for the large scale) deterministic throughout the investigated wake region and depends mainly on the phase. This result is consistent with the literature (see, e.g., [
8]) and further strengthens the conjecture that the far-field evolution of the propeller wake structures exhibits a deterministic behavior at the macro-scale and a chaotic nature at the micro-scale.
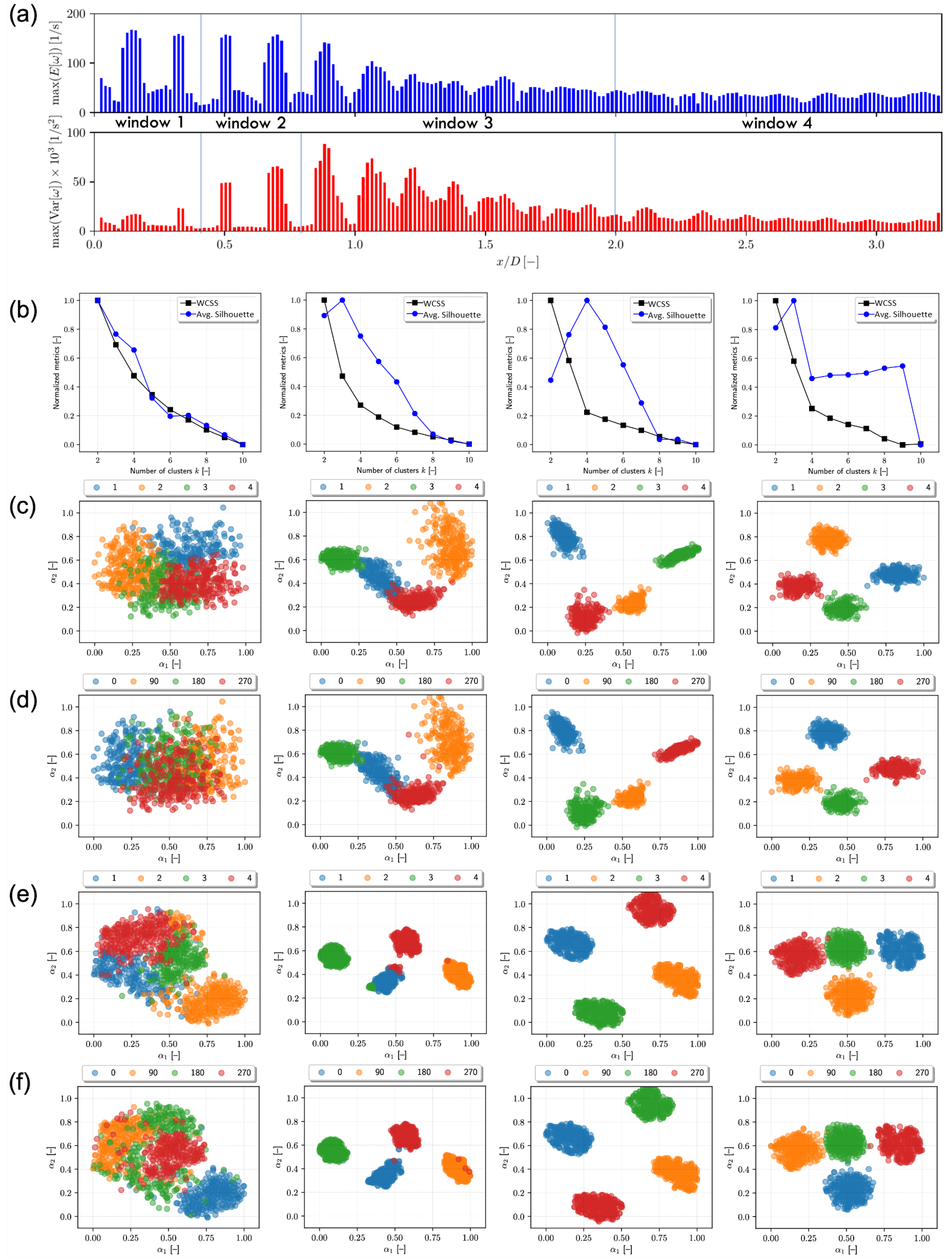
A second analysis is performed, dividing the field of view into several windows (local region of flow field), based on the vorticity mean and variance associated with each cross-section.
Figure 6a shows the maximum mean and variance of cross-sections along the propeller axis. Four windows are selected, as shown in
Figure 6a: (1)
, where the maximum variance is low and the wake is stable; (2)
, where the maximum variance starts increasing and the wake destabilizes; (3)
, where the maximum variance reaches its own maximum and starts decreasing along with the maximum mean and the wake experiences a fully developed tip vortex interaction; (4)
, where variance and mean are almost constant and a fully turbulent wake is observed. This second analysis is used to investigate if global wake behaviors are also present in local regions, or if the latter are dominated by some local behaviors of the wake.
In
Figure 6b, the first column, shows the WCSS and silhouette for window 1. In
Figure 6c–f, the first column shows the POD/PCA (c,d) and
t-SNE (e, f) coefficients labeled by cluster (c, e) and phase (d, f) for the same window. In
Figure 7a,b, the first column shows the density functions of the corresponding coefficients. As expected, no significant structures are observed. The
t-SNE highlights some structure and hints of data clustering. Nevertheless, these are not significant and the data can be interpreted as a single cluster. Consequently, no cluster centroid is shown in
Figure 7c. Similarly, the second column of
Figure 6b–f and
Figure 7a,b provide the results for window 2. The clustering results are ambiguous since four and three clusters are identified by WCSS and silhouette, respectively. POD/PCA coefficients show two or three main clusters whereas the
t-SNE clearly identifies four clusters associated with the propeller phases.
The results for windows 3 and 4 are presented in the third and fourth column of
Figure 6b–f and
Figure 7a,b, respectively, where four clusters are clearly identified with a one-to-one association to the phase. It may be noted how a high degree of determinism is still present far downstream of the propeller. It may be also noted how window 4
t-SNE analysis presents some hints of transition towards a different clustering structure.
Figure 7c shows the cluster centroids associated with windows 2, 3, and 4, where rows represent clusters and columns represent windows. As discussed earlier, these centroids also represent phase-locked averages. The unsupervised association of clusters to phases by
k-means indicates that the destabilization (and coupling) of tip vortices progresses following mechanisms governed by deterministic chaos.
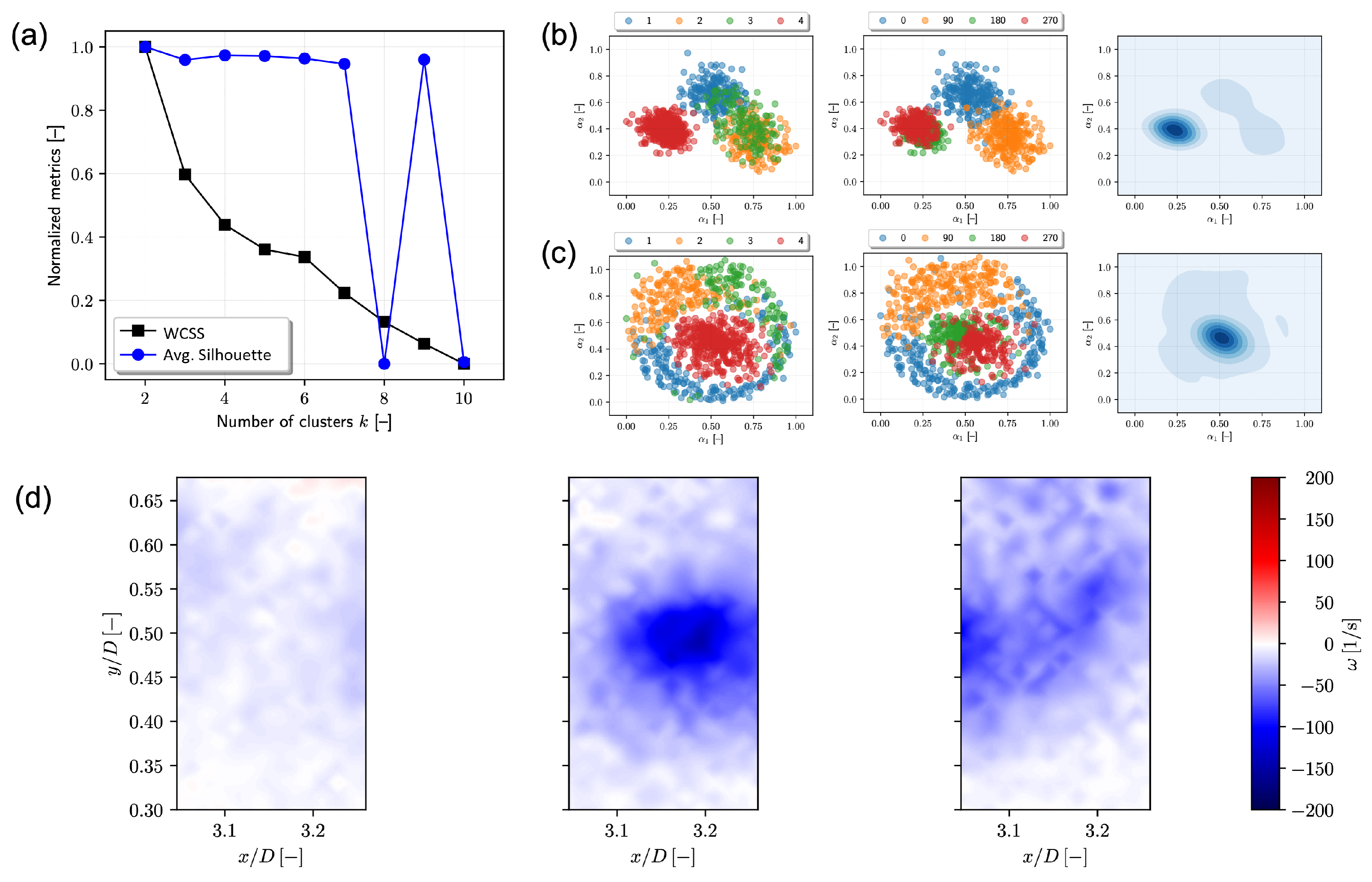
Finally, the same analysis is performed for window 5, which bounds more closely to a single vortex (see
Figure 8). The clustering results are ambiguous in this region (see
Figure 8a), even if some patterns are identified by both POD/PCA and
t-SNE coefficients, where a pairwise mixture of phases 0–90 and 180–270 is present (see
Figure 8b,c). Cluster centroids are shown in
Figure 8d, where each column represents a centroid. In this case, the centroids cannot be associated with the phase-locked averages and their interpretation needs further investigation.
5. Conclusions and Future Work
A snapshot clustering approach was presented and discussed for PIV data of a 4-bladed propeller wake. Data clustering was performed using the k-means algorithm, and the optimal number of clusters was determined by evaluating two metrics: the within-cluster sum of squares and average silhouette. The focus of the snapshot clustering was on the vorticity field of the phase-locked propeller’s wake data, specifically targeting the tip vortices. To visually analyze and discuss the data clusters, a two-dimensional visualization was generated using POD/PCA, t-SNE embedding, and KDE.
The propeller wake clustering of phase-locked snapshots produced no clusters (meaning only one cluster) for the near-field data window. Clusters with a one-to-one association to the phase were found for other data windows. Specifically, this was clearly observed for the whole field of view as well as for windows covering the region where the wake transitions to unstable regimes and windows in the far field. Clustering results suggested that the wake instability and subsequent progression of tip vortices are characterized by mechanisms governed by deterministic chaos also in the far field. This result is consistent with the results of the experimental study conducted by [
8], which highlights a deterministic behavior of the propeller tip vortices at the macro-scale and chaotic dynamics at the micro-scale. Finally, it can be highlighted that the use of phase-locked measurements, in combination with machine learning and data mining approaches, has allowed us to deeply investigate the propeller wake behaviors, without bothering the use of time-resolved measurements, which are definitely more challenging and expensive.
Ongoing and future work includes extending the analysis of clustering approaches to cover both spatial and temporal clustering with comparison and discussion of the results. The idea is to combine spatial/temporal clustering to fully exploits data reduction and visualization techniques to provide a physical characterization of zones and intervals in space and time domain, respectively. Furthermore, a systematic analysis of POD/PCA modes for the whole and clusterized data set will be performed. Extensions to dynamic mode decomposition [
39] are also part of the ongoing research.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







