
Machine Learning and Case-Based Reasoning for Real-Time Onboard Prediction of the Survivability of Ships

 ,
,  ,
,  ,
, 
Abstract
:1. Introduction
- (i)
- the ability of the approach to receive and process ‘live data’ of the critical influencing parameters for the assessment of the risk, and
- (ii)
- to have a framework/tool/algorithm in place which can produce predictions and make projections within a short enough period of time so that it can be meaningful for on the spot crisis management support.
2. Materials and Methods
2.1. Architecture
- Database creation and pre-processing (see Section 2.2)
- CBR methodology (see Section 2.4) including:
- Similarity calculation (see Section 2.4.1)
- Adaption of selected case data to a prediction (see Section 2.4.3)
- ML methodology including (see Section 2.6):
- Model fitting and stacking
- Model comparison and tuning
- Model evaluation and selection
- Prediction using ML
- Prediction using CBR
- A time-loop accepting new data for every time step and providing a new outcome
2.2. Database
2.3. CBR Fundamentals
2.4. CBR Implementation
2.4.1. Similarity Functionality
- Room similarity
- Damage similarity
2.4.2. Retrieval of Cases
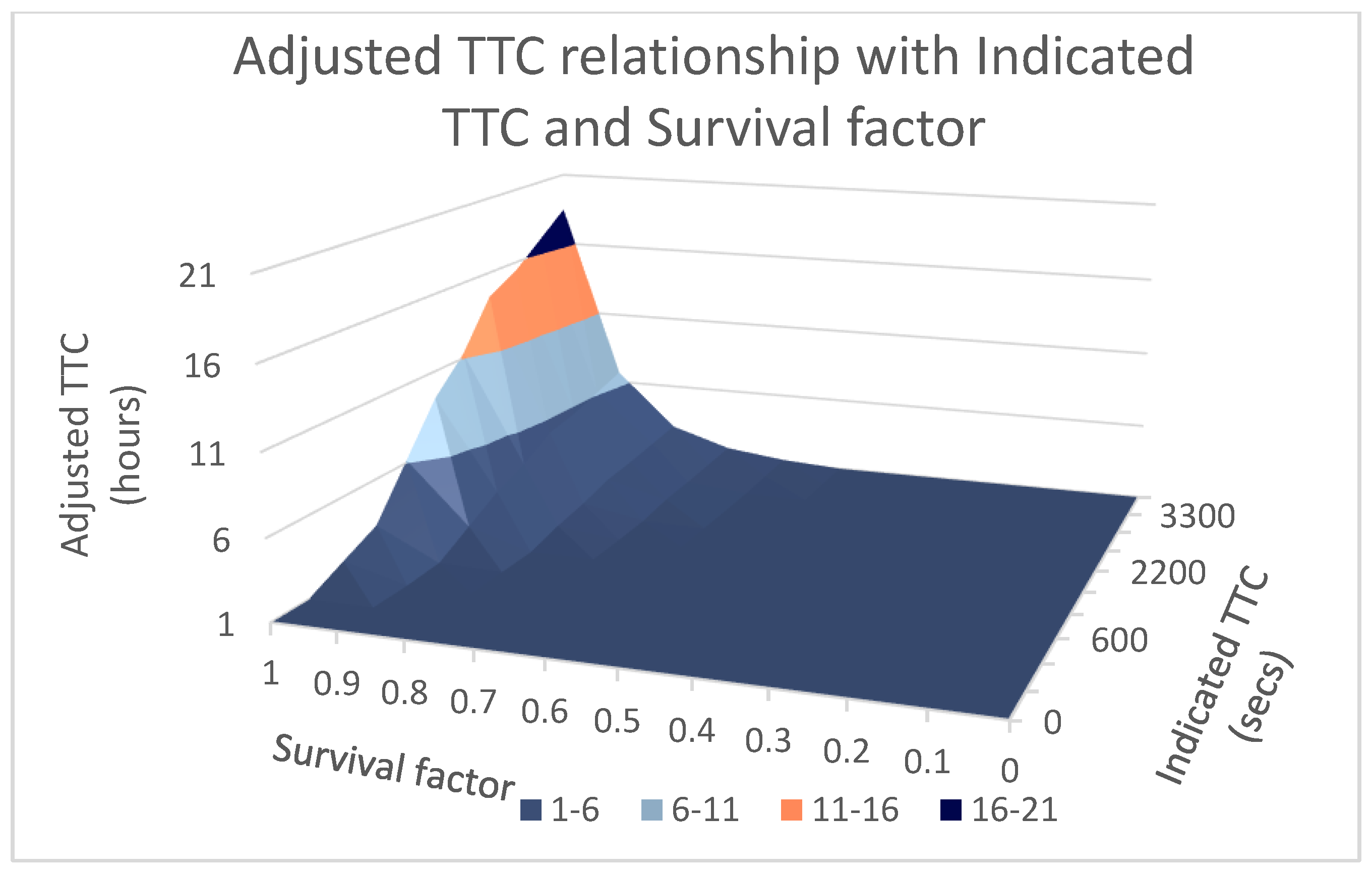
2.4.3. Adaptation
2.5. Machine Learning Fundamentals
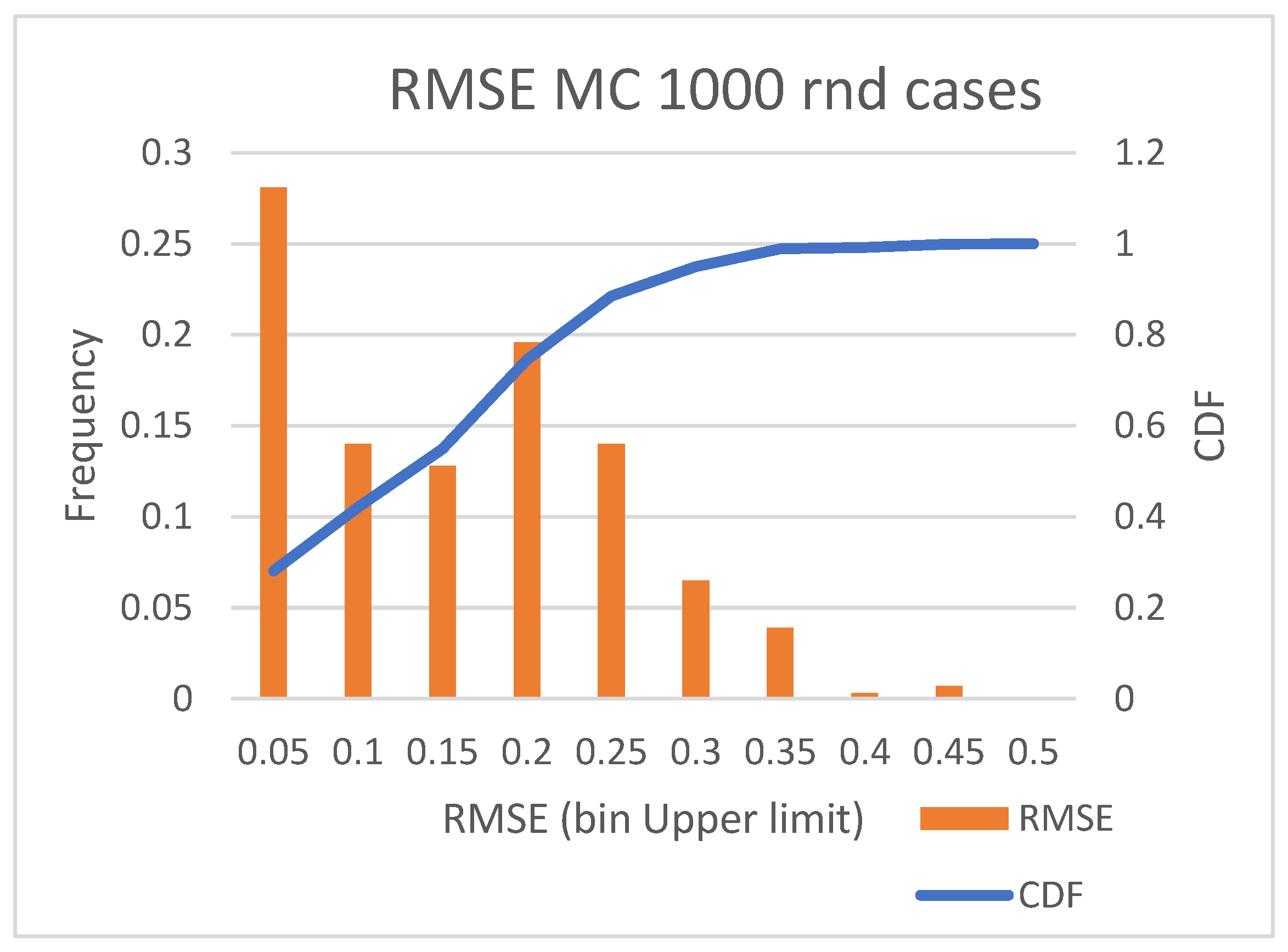
2.5.1. Performance Metrics
2.5.2. Classification
2.5.3. Accuracy
2.5.4. Precision
2.5.5. Recall
2.5.6. F1 Score
2.5.7. Regression
2.5.8. Coefficient of Determination
2.5.9. Mean Absolute Error
2.5.10. Root Mean Square Error
2.6. Machine Learning Implementation
- Provide database of cases (pre-processed).
- Select features from the database and the target feature (objective to be predicted).
- Select a machine learning model, e.g., RandomForestClassifier.
- Choose whether to binarize the target feature.
- Choose the threshold for binarization.
- Choose whether to standardize the data.
- Search for best hyperparameters (grid search).
- Train model.
- Perform K-fold cross validation and display mean and std. of performance metrics (, accuracy etc.).
2.7. Classification
2.8. Regression
3. Results
3.1. Classifier Comparison

3.2. Calibration of Models
Receiver Operating Characteristics and Discrimination Threshold
3.3. Regressor Comparison
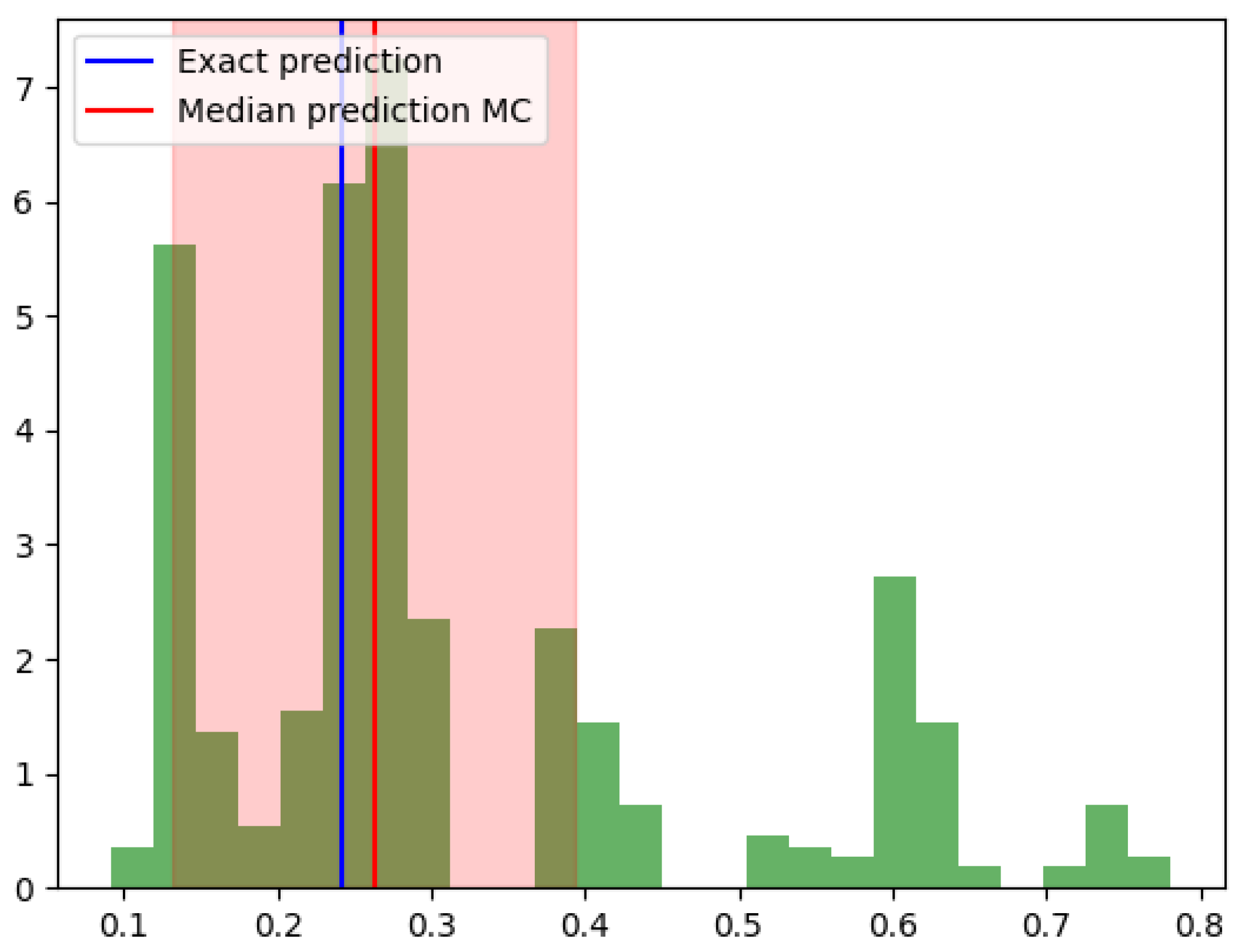
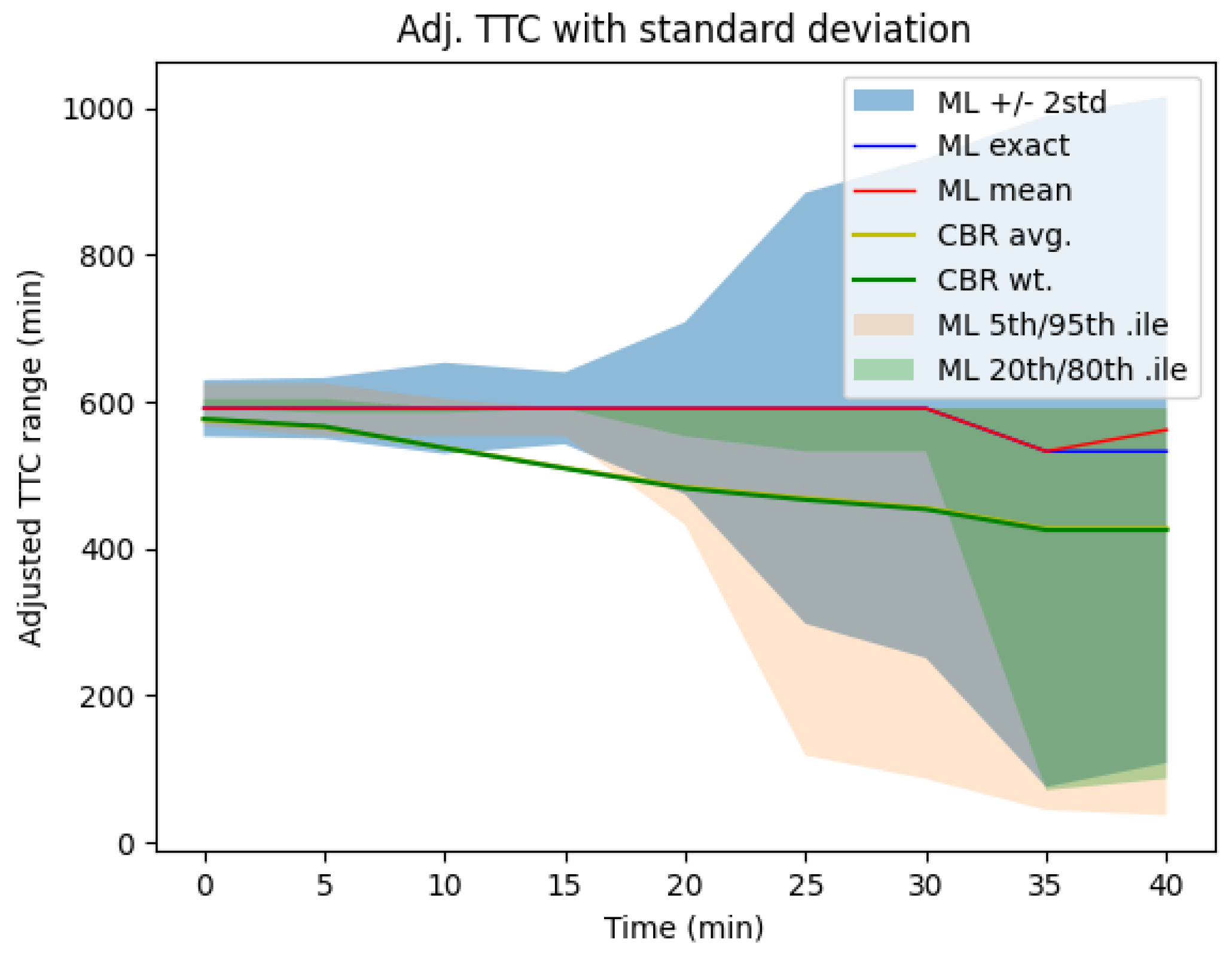
3.4. Uncertainty Quantification for Input Variables
4. Discussion
4.1. Predictions of Selected Variables
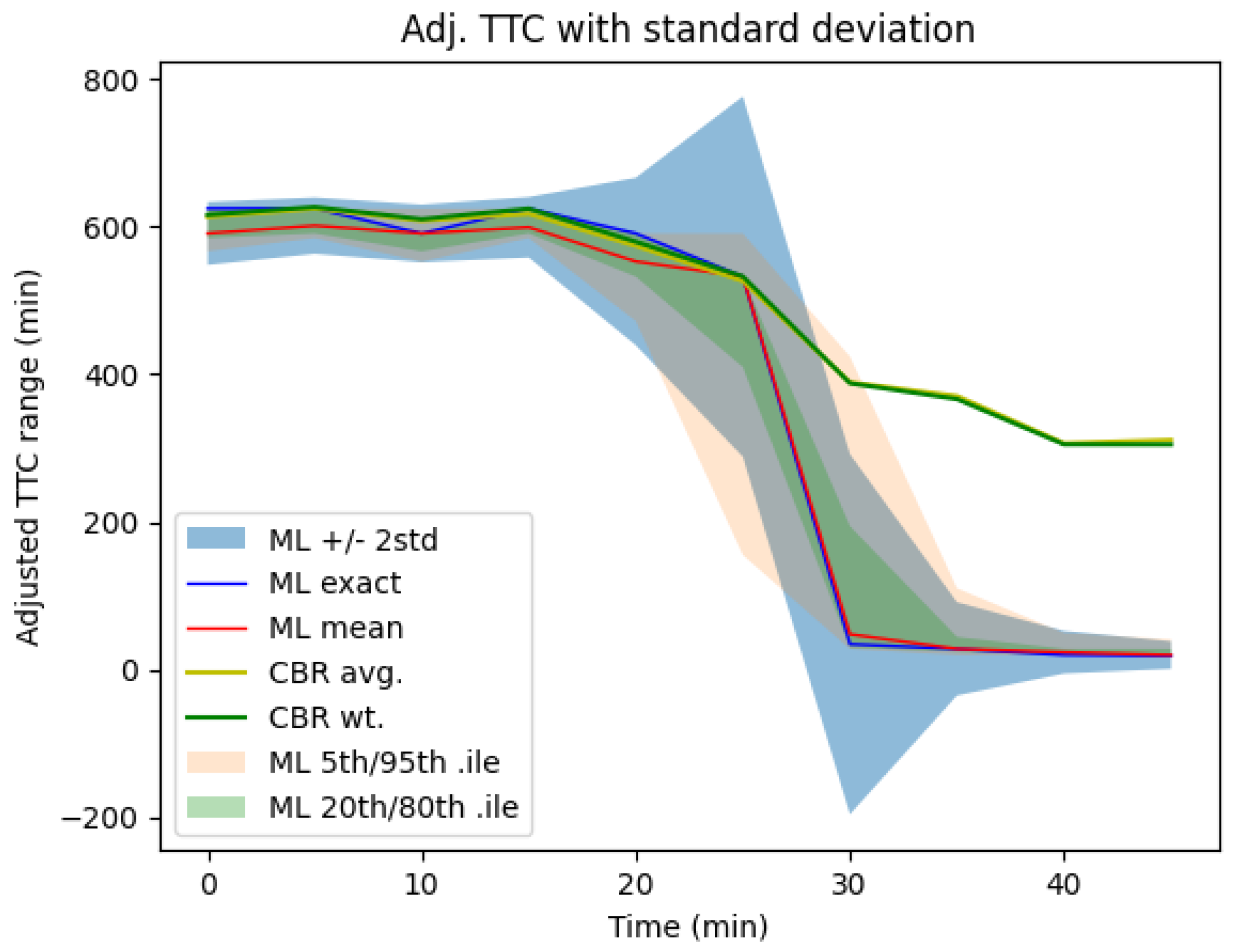
4.2. Prediction on Time to Capsize
4.2.1. Rapid Capsizing
4.2.2. Slow Capsize
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | Figure 1 also contains insets of figures that will be presented further in the methodology for easy reference. |
References
- Kolodner, J.L. An Introduction to Case-Based Reasoning. Artif. Intell. Rev. 1992, 6, 3–34. [Google Scholar] [CrossRef]
- Agnar, A.; Plaza, E. Case-Based Reasoning: Foundational Issues, Methodological Variations, and System Approaches. AI Commun. 1994, 7, 39–59. [Google Scholar] [CrossRef]
- Norwegian Safety Investigation Authority Part Two Report on the Collision between the Frigate ‘Helge Ingstad’ and the Oil Tanker Sola Ts Outside the Sture Terminal in the Hjeltefjord in Hordaland County on 8 November 2018. 2018. Available online: https://mtip.gov.mt/en/Documents/MSIU-by-other-countries/2021_05.pdf (accessed on 10 December 2022).
- Papanikolaou, A.; Spanos, D.; Boulougouris, E.; Eliopoulou, E.; Alissafaki, A. Investigation into the Sinking of the Ro-Ro Passenger Ferry Express Samina. In Proceedings of the 8th International Conference on the Stability of Ships and Ocean Vehicles, Madrid, Spain, 15–19 September 2003. [Google Scholar]
- Jasionowski, A. Decision Support for Ship Flooding Crisis Management. Ocean Eng. 2011, 38, 1568–1581. [Google Scholar] [CrossRef]
- Nordström, J.; Goerlandt, F.; Sarsama, J.; Leppänen, P.; Nissilä, M.; Ruponen, P.; Lübcke, T.; Sonninen, S. Vessel TRIAGE: A Method for Assessing and Communicating the Safety Status of Vessels in Maritime Distress Situations. Saf. Sci. 2016, 85, 117–129. [Google Scholar] [CrossRef]
- Ruponen, P.; Pennanen, P.; Manderbacka, T. On the Alternative Approaches to Stability Analysis in Decision Support for Damaged Passenger Ships. WMU J. Marit. Aff. 2019, 18, 477–494. [Google Scholar] [CrossRef] [Green Version]
- Braidotti, L.; Mauro, F. A Fast Algorithm for Onboard Progressive Flooding Simulation. J. Mar. Sci. Eng. 2020, 8, 369. [Google Scholar] [CrossRef]
- Braidotti, L.; Marino, A.; Bucci, V. On the Effect of Uncertainties on Onboard Progressive Flooding Simulation; IOS Press: Amsterdam, The Netherlands, 2019. [Google Scholar] [CrossRef]
- Gao, Z.; Vassalos, D.; Gao, Q. Numerical Simulation of Water Flooding into a Damaged Vessel’s Compartment by the Volume of Fluid Method. Ocean Eng. 2010, 37, 1428–1442. [Google Scholar] [CrossRef] [Green Version]
- Gao, Z.L.; Vassalos, D. The Dynamics of the Floodwater and the Damaged Ship in Waves. J. Hydrodyn. 2015, 27, 689–695. [Google Scholar] [CrossRef] [Green Version]
- Kara, F.; Shigunov, V.; Vassalos, D.; Gao, Q.; Kara, F.; Shigunov, V.; Vassalos, D. Numerical Simulation of Damage Ship Flooding FLOWMART View Project Development of Dynamic Stability Criteria for Ship Motions in Seaway Considering Current Discussion State at IMO View Project Numerical Simulation of Damage Ship Flooding. In Proceedings of the 7th Numerical Towing Tank Symposium, Hamburg, Germany, 23–25 September 2004. [Google Scholar] [CrossRef]
- Ruponen, P. Pressure-Correction Method for Simulation of Progressive Flooding and Internal Air Flows. Ship Technol. Res. 2006, 53, 63–73. [Google Scholar] [CrossRef]
- Ruponen, P. Progressive Flooding of a Damaged Passenger Ship; Helsinki University of Technology: Helsinki, Finland, 2007. [Google Scholar]
- Ruponen, P. Adaptive Time Step in Simulation of Progressive Flooding. Ocean Eng. 2014, 78, 35–44. [Google Scholar] [CrossRef]
- Ruponen, P.; Sundell, T.; Larmela, M. Validation of Simulation Method for Progressive Flooding. Int. Shipbuild. Prog. 2007, 54, 305–321. [Google Scholar]
- Ruponen, P.; Kurvinen, P.; Saisto, I.; Harras, J. Experimental and Numerical Study on Progressive Flooding in Full-Scale. Trans. R. Inst. Nav. Archit. Part A Int. J. Marit. Eng. 2010, 152, A-197. [Google Scholar] [CrossRef]
- Ruponen, P. On the Effects of Non-Watertight Doors on Progressive Flooding in a Damaged Passenger Ship. Ocean Eng. 2017, 130, 115–125. [Google Scholar] [CrossRef]
- Penttilä, P.; Ruponen, P. Use of Level Sensors in Breach Estimation for a Damaged Ship. In Proceedings of the 5th International Conference on Collision and Grounding of Ships, Espoo, Finland, 14–16 July 2010. [Google Scholar]
- Ruponen, P. Required Flooding Sensor Arrangement for Reliable Automatic Damage Detection. In Proceedings of the RINA Smart Ship, London, UK, 24–25 January 2017. [Google Scholar]
- Karolius, K.B. Risk-Based, Sensor-Fused Detection of Flooding Casualties for Emergency Response. Ph.D. Thesis, University of Strathclyde, Glasgow, UK, 2019. [Google Scholar]
- Jasionowski, A. An Integrated Approach to Damage Ship Survivability Assessment. Ph.D. Thesis, University of Strathclyde, Glasgow, UK, 2001. [Google Scholar]
- Varela, J.M.; Rodrigues, J.M.; Guedes Soares, C. On-Board Decision Support System for Ship Flooding Emergency Response. Procedia Comput. Sci. 2014, 29, 1688–1700. [Google Scholar] [CrossRef] [Green Version]
- Vassalos, D. Damage Stability and Survivability—“Nailing” Passenger Ship Safety Problems. Ships Offshore Struct. 2014, 9, 237–256. [Google Scholar] [CrossRef]
- Santos, T.A.; Guedes Soares, C. Study of Damaged Ship Motions Taking into Account Floodwater Dynamics. J. Mar. Sci. Technol. 2008, 13, 291–307. [Google Scholar] [CrossRef]
- Ruponen, P.; Valanto, P.; Acanfora, M.; Dankowski, H.; Lee, G.J.; Mauro, F.; Murphy, A.; Rosano, G.; van’t Veer, R. Results of an International Benchmark Study on Numerical Simulation of Flooding and Motions of a Damaged Ropax Ship. Appl. Ocean Res. 2022, 123, 103153. [Google Scholar] [CrossRef]
- Van Walree, F.; Papanikolaou, A. Benchmark Study of Numerical Codes for the Prediction of Time to Flood of Ships: Phase I. In Proceedings of the 9th International Ship Stability Workshop, Hamburg, Germany, 30–31 August 2007. [Google Scholar]
- Boulougouris, E.; Vassalos, D.; Stefanidis, F.; Karaseitanidis, I.; Karagiannidis, L.; Admitis, A.; Ventikos, N.; Kanakidis, D.; Petrantonakis, D.; Liston, P. SafePASS -Transforming Marine Accident Response. In Proceedings of the 8th Transport Research Arena (TRA 2020), Helsinki, Finland, 27–30 April 2020. [Google Scholar] [CrossRef]
- Fotios, S.; Evangelos, S.; Evangelos, B.; Lazaros, K.; Panagiotis, S.; Emmanouil, A.; Olivier, B.; Panagiotis, V. SafePASS: A New Chapter for Passenger Ship Evacuation and Marine Emergency Response. In Proceedings of the Transport Research Arena (TRA), Lisbon, Portugal, 14–17 November 2022. [Google Scholar] [CrossRef]
- Bolierakis, S.N.; Nousis, V.; Karagiannidis, L.; Karaseitanidis, G.; Amditis, A. Exploiting Augmented Reality for Improved Training and Safety Scenarios for Large Passenger Ships. In Proceedings of the EuroVR 2020 Application, Exhibition & Demo Track: Virtual EuroVR Conference, Valencia, Spain, 25–27 November 2020. [Google Scholar] [CrossRef]
- Mitro, N.; Argyri, K.; Pavlopoulos, L.; Kosyvas, D.; Karagiannidis, L.; Kostovasili, M.; Misichroni, F.; Ouzounoglou, E.; Amditis, A. AI-Enabled Smart Wristband Providing Real-Time Vital Signs and Stress Monitoring. Sensors 2023, 23, 2821. [Google Scholar] [CrossRef]
- Ventikos, N.P.; Zagkliveri, T.I.; Kopsacheilis, I.; Annetis, M.; Pollalis, C.D.; Sotiralis, P. Reducing Ship Evacuation Time: The Case of a Rail Platform for Integrating Novel Lifeboats on Ship Architectural Structures. In Proceedings of the 1st International Conference on the Stability and Safety of Ships and Ocean Vehicles, Glasgow, UK, 6–11 June 2021. [Google Scholar] [CrossRef]
- Sotiralis, P.; Rammos, A.; Trifonopoulos, L.; Karaseitanidis Amditis, G.A.; Karagiannidis, L. A Critical Review of the Evacuation Process Due to Fire or Flooding from Cruise Vessels and Large Ropax Cessels and the Future Challenges and Developments. In Proceedings of the Sustainable and Safe Passenger Ships, Athens, Greece, 4 March 2020. [Google Scholar]
- Choudhury, N.; Begum, S.A. A Survey on Case-Based Reasoning in Medicine. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 136–144. [Google Scholar] [CrossRef] [Green Version]
- Ölçer, A.I.; Majumder, J. A Case-Based Decision Support System for Flooding Crises Onboard Ships. Qual. Reliab. Eng. Int. 2006, 22, 59–78. [Google Scholar] [CrossRef]
- Siciliano, B.; Khatib, O. Springer Handbook of Robotics; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Rebala, G.; Ravi, A.; Churiwala, S. An Introduction to Machine Learning; Springer International Publishing: Cham, Switzerland, 2019; ISBN 978-3-030-15728-9. [Google Scholar]
- Scikit-Learn. Available online: https://scikit-learn.org/stable/index.html (accessed on 5 September 2022).
- Ventikos, N.P.; Sotiralis, P.; Annetis, M.; Podimatas, V.C.; Boulougouris, E.; Stefanidis, F.; Chatzinikolaou, S.; Maccari, A. The Development and Demonstration of an Enhanced Risk Model for the Evacuation Process of Large Passenger Vessels. J. Mar. Sci. Eng. 2023, 11, 84. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Adapted Range | Comments |
|---|---|---|
| Length | As is | |
| Location | −10–+10 | 1 to 10 according to location on vessel with 5 being midships, 1 stern, and 10 bow. Positive for starboard and negative for port |
| Penetration | 1–3 | Incremental increases in penetration up to a maximum of 3, which corresponds to B/2 penetration. |
| Z centre (height of damage centroid) | 1–4 | Distributed evenly across the depth of the ship |
| Z height (Height of damage opening) | 1–5 | According to limits (0, 2, 4, 6, 8) |
| Rooms | N/A | Names of rooms known to be open to the sea in the simulation |
| Heel (static & time-domain) | 0–30 | Capped to prevent erroneous data. |
| Roll | 0–60 | Capped at 60 to prevent large numbers due to capsizing. |
| Draft | As is | |
| Trim | As is | |
| Survival factor (SFAC) | 0, 1 | Adapted to reduce the problem to classification. The threshold used ranges from 0.7 to 0.9. |
| GZMAXR | As is | Max GZ from equilibrium to downflooding angle |
| Range effective (RANGEF) | As is | Effective range of positive stability from equilibrium to downflooding angle |
| BreachIndex | 9703 | BreachIndex | 9703 |
|---|---|---|---|
| SIDE | SB | Location | −106.684 |
| T | 6.480678 | Location_side | 6 |
| TR | 1.019261 | Z_centre | 3 |
| HEEL | −11.5121 | Z_height | 5 |
| GZMAXR | 0.026673 | Roll at End Sim Time | 175.371 |
| GZMAXSOL | 0.026673 | Sim End Time | 53.196 |
| RANGEF | 5.023143 | Time at Max Roll Angle | 53.196 |
| SFACSOL | 0.786584 | Max Roll Angle | 60 |
| PFAC | 0.0008 | Max Roll within 3 min | 60 |
| Breach Side | −1 | Time at Max Roll within 3 min | 53.196 |
| BreachXc | 106.6844 | Capsize | 1 |
| Length | 26.13059 | HEEL (abs) | 11.51213 |
| Pen | 1 | Location(abs) | 6 |
| Zmin | 3.956142 | Max Roll within 3 min (no capsize) | [ ] |
| Zmax | 18.37559 | TTC | 53.196 |
| IntT | 6.209 | TTC True | 53.196 |
| Rooms [‘AC020301’, ‘R150401_N’, ‘SL1_L’, …] | Adjusted TTC 145.5538 | ||
| Name | Sample | Method |
|---|---|---|
| Simple average | Selected cases (by percentile similarity cut-off) | |
| Weighted similarity average | Selected cases (by percentile similarity cut-off) | |
| Weighted posterior probability average | Selected cases (by percentile similarity cut-off) | |
| Top case | Top case by similarity | Top case feature value |
| Name | Value |
|---|---|
| Simple average | 0.96 |
| Weighted similarity average | 0.9669 |
| Weighted posterior probability average | 0.990 |
| Truth | 1 |
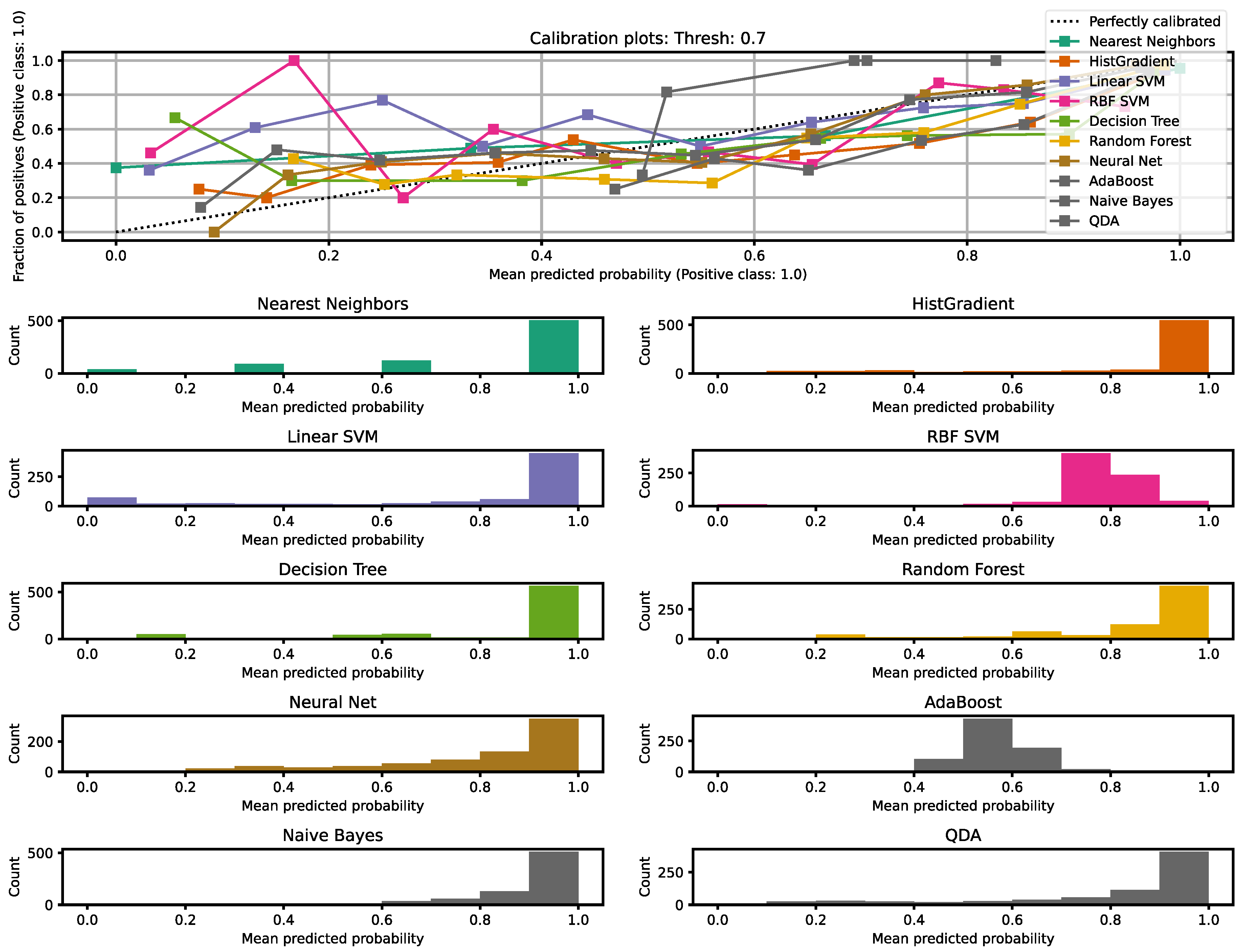
| Model | Accuracy Score |
|---|---|
| Nearest Neighbors | 0.82 |
| HistGradient | 0.84 |
| Linear SVM | 0.81 |
| Neural Net | 0.83 |
| AdaBoost | 0.85 |
| Naive Bayes | 0.81 |
| RBF SVM | 0.81 |
| Decision Tree | 0.84 |
| Random Forest | 0.83 |
| QDA | 0.82 |
| Stacked model | 0.83 |
| CBR Approach | ML | Truth | ||
|---|---|---|---|---|
| Similarity weighted predicted | Posterior probability weighted | Machine learning prediction | ||
| Heel | 0.66 | 0.12 | 1.21 | −0.02 |
| GZMAXR | 0.3 | 0.33 | 0.32 | 0.29 |
| SFAC classifier | 0.94 | 0.98 | 0.79 | 0.98 |
| SFAC continuous | 0.94 | 0.98 | 0.67 | 0.98 |
| Index | Length | Pen | Z_Centre | Z_Height | Location_Side |
|---|---|---|---|---|---|
| 1 | 5 | 1 | 2 | 2 | −5 |
| 2 | 5 | 2 | 2 | 2 | −4 |
| 3 | 5 | 2 | 2 | 2 | −6 |
| 4 | 7 | 1 | 2 | 2 | −5 |
| 5 | 15 | 1 | 2 | 3 | −5 |
| 6 | 21 | 1 | 2 | 3 | −5 |
| 7 | 30 | 2 | 2 | 3 | −6 |
| 8 | 35 | 3 | 2 | 3 | −6 |
| 9 | 40 | 3 | 2 | 3 | −6 |
| 10 | 53 | 3 | 2 | 3 | −6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Louvros, P.; Stefanidis, F.; Boulougouris, E.; Komianos, A.; Vassalos, D. Machine Learning and Case-Based Reasoning for Real-Time Onboard Prediction of the Survivability of Ships. J. Mar. Sci. Eng. 2023, 11, 890. https://doi.org/10.3390/jmse11050890
Louvros P, Stefanidis F, Boulougouris E, Komianos A, Vassalos D. Machine Learning and Case-Based Reasoning for Real-Time Onboard Prediction of the Survivability of Ships. Journal of Marine Science and Engineering. 2023; 11(5):890. https://doi.org/10.3390/jmse11050890
Chicago/Turabian StyleLouvros, Panagiotis, Fotios Stefanidis, Evangelos Boulougouris, Alexandros Komianos, and Dracos Vassalos. 2023. "Machine Learning and Case-Based Reasoning for Real-Time Onboard Prediction of the Survivability of Ships" Journal of Marine Science and Engineering 11, no. 5: 890. https://doi.org/10.3390/jmse11050890