
An Improved YOLOv5s-Based Scheme for Target Detection in a Complex Underwater Environment

Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Creation
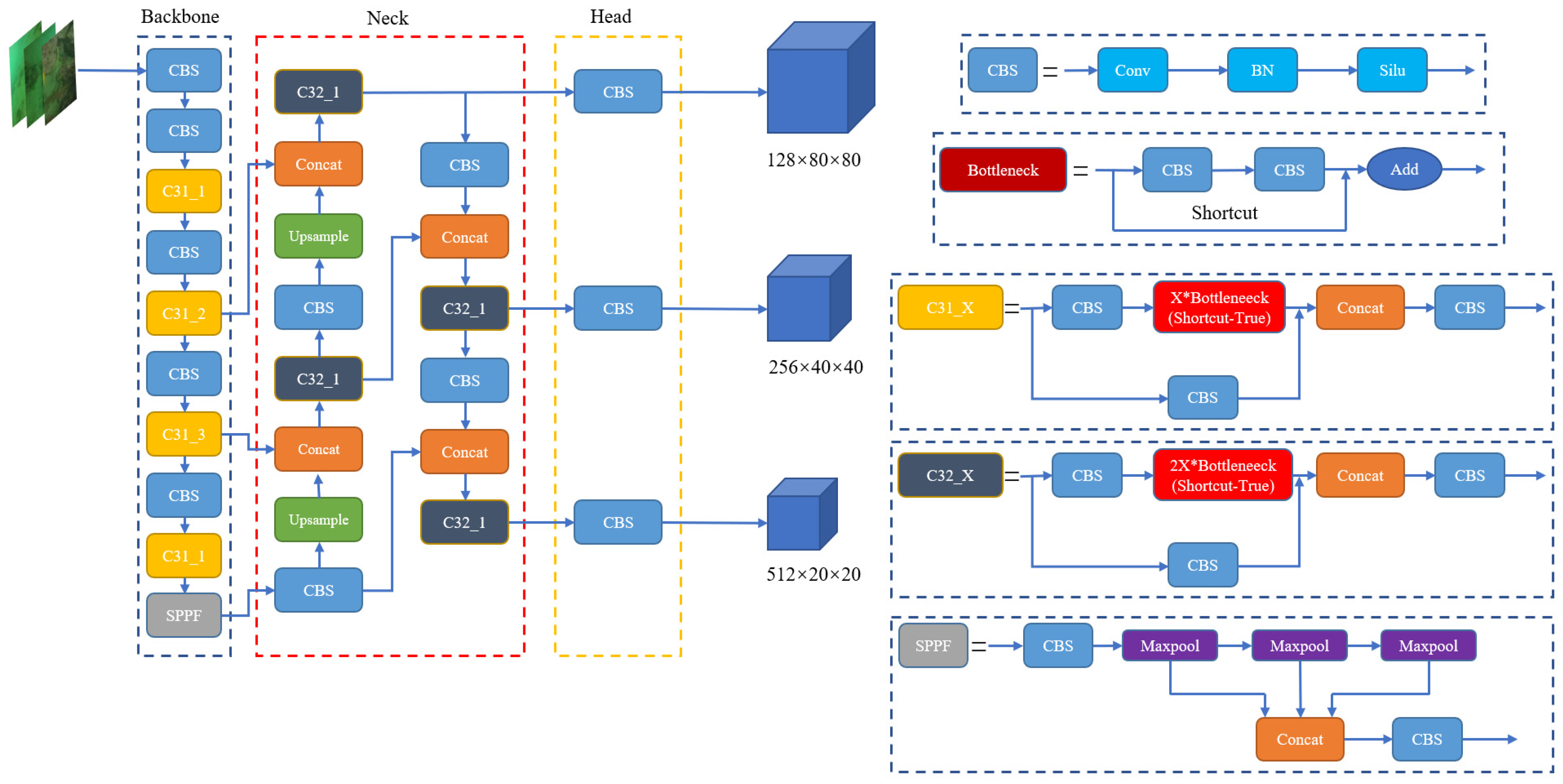
2.2. YOLOv5 Target Detection Algorithm
2.3. Improved YOLOv5s Network Design
2.3.1. Self-Attentive Sub-Layer HorBlock Based on
2.3.2. Hyperparametric Evolution Based on a Genetic Algorithm
2.4. Evaluation Indicators
3. Results and Discussion
3.1. Model Training
3.2. Analysis of Results
3.2.1. Analysis of Ablation Experiments
3.2.2. Comparative Analysis of Model Detection Effects
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guan, Z.G.; Hou, C.L.; Zhou, S.Q.; Guo, Z.Y. Research on Underwater Target Recognition Technology Based on Neural Network. Wirel. Commun. Mob. Comput. 2022, 2022, 4197178. [Google Scholar] [CrossRef]
- Kang, S.; Yu, J.C.; Zhang, J. Research Status of Micro Autonomous Underwater Vehicle. Robot 2023, 2, 218–237. [Google Scholar]
- Li, L.; Yang, X.; Qin, X.J.; Wang, Y.Q. Research Status and Development Trend of Wall-climbing Cleaning Robots. Mach. Build. Autom. 2023, 52, 1–6. [Google Scholar]
- Zhou, J.C.; Pang, L.; Zhang, W.S. Underwater image enhancement method by multi-interval histogram equalization. IEEE J. Ocean. Eng. 2023, 48, 474–488. [Google Scholar] [CrossRef]
- Zhou, J.C.; Zhang, D.H.; Zhang, W.S. Cross-view enhancement network for underwater images. Eng. Appl. Artif. Intell. 2023, 121, 105952. [Google Scholar] [CrossRef]
- Yuan, X.; Guo, L.X.; Luo, C.T.; Zhou, X.; Yu, C. A survey of target detection and recognition methods in underwater turbid areas. Appl. Sci. 2022, 12, 4898. [Google Scholar] [CrossRef]
- Chen, W.; Wei, Q.Y.; Zhang, J.F.; Guo, B.Y. Target detection of underwater vehicle based on RetinaNet. Comput. Eng. Des. 2022, 43, 2959–2967. [Google Scholar]
- Qiang, W.; He, Y.Y.; Guo, Y.J.; Li, B.Q.; Hi, L.J. Exploring Underwater Target Detection Algorithm Based on Improved SSD. J. Northwestern Polytech. Univ. 2020, 38, 747–754. [Google Scholar] [CrossRef]
- Deng, Q.; Lin, M.X. Marine Organism Detection Algorithm Based on Improved SSD. Comput. Technol. Dev. 2022, 32, 51–56. [Google Scholar]
- Wang, X.H.; Zhu, Y.G.; Li, D.Y.; Zhang, G. Underwater Target Detection Based on Reinforcement Learning and Ant Colony Optimization. J. Ocean Univ. China 2022, 21, 323–330. [Google Scholar] [CrossRef]
- Guo, T.T.; Song, Y.Z.; Kong, Z.J.; Lim, E.; López-Benítez, M.; Ma, F.; Yu, L.M. Underwater Target Detection and Localization with Feature Map and CNN-Based Classification. In Proceedings of the 2022 4th IEEE International Conference on Advances in Computer Technology, Information Science and Communications (CTISC), Suzhou, China, 22–24 April 2022; pp. 1–8. [Google Scholar]
- Zeng, L.C.; Sun, B.; Zhu, D.Q. Underwater target detection based on Faster R-CNN and adversarial occlusion network. Eng. Appl. Artif. Intell. 2021, 100, 104190. [Google Scholar] [CrossRef]
- Li, J.F.; Zhu, Y.W.; Chen, M.X.; Wang, Y.L.; Zhou, Z.Q. Research on Underwater Small Target Detection Algorithm Based on Improved YOLOv3. In Proceedings of the 2022 16th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 21–24 October 2022; pp. 76–80. [Google Scholar]
- Guo, T.X.; Wei, Y.H.; Shao, H.; Ma, B.Y. Research on Underwater Target Detection Method Based on Improved MSRCP and YOLOv3. In Proceedings of the 2021 IEEE International Conference on Mechatronics and Automation (ICMA), Takamatsu, Japan, 8–11 August 2021; pp. 1158–1163. [Google Scholar]
- Zhang, M.H.; Xu, S.B.; Song, W.; He, Q.; Wei, Q.M. Lightweight Underwater Object Detection Based on YOLOv4 and Multi-Scale Attentional Feature Fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Chen, L.Y.; Zheng, M.C.; Duan, S.Q.; Luo, W.L.; Yao, L.G. Underwater Target Recognition Based on Improved YOLOv4 Neural Network. Electronics 2021, 10, 1634. [Google Scholar] [CrossRef]
- Li, S.S.; Li, C.; Yang, Y.; Zhang, Q.; Wang, Y.H.; Guo, Z.Y. Underwater scallop recognition algorithm using improved YOLOv5. Aquac. Eng. 2022, 98, 102273. [Google Scholar] [CrossRef]
- Li, Y.; Bai, X.Y.; Xia, C.L. An Improved YOLOV5 Based on Triplet Attention and Prediction Head Optimization for Marine Organism Detection on Underwater Mobile Platforms. J. Mar. Sci. Eng. 2022, 10, 1230. [Google Scholar] [CrossRef]
- Li, J.Y.; Liu, C.N.; Lu, X.C.; Wu, B.L. CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets. Water 2022, 14, 2412. [Google Scholar] [CrossRef]
- Cao, J.R.; Zhuang, Y.; Wang, M.; Han, F.T.; Zheng, X.H.; Gao, H. ECA-based YOLOv5 Underwater Fish Target Detection. Comput. Syst. Appl. 2023, 32, 1–8. [Google Scholar]
- Lei, F.; Tang, F.F.; Li, S.H. Underwater Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2022, 10, 310. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. Pattern Anal. Mach. Intell. IEEE Trans. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Rao, Y.M.; Zhao, W.L.; Tang, Y.S.; Zhou, J.; Lim, S.-N.; Lu, J.W. Hornet: Efficient high-order spatial interactions with recursive gated convolutions. arXiv 2022, arXiv:2207.14284. [Google Scholar]
- Bert, D.B.; Xu, J.; Tinne, T.; Luc, V.G. Dynamic fifilter networks. Adv. Neural Inf. Process. Syst. 2016, 29, 1–14. [Google Scholar]
- Chen, Y.P.; Dai, X.Y.; Liu, M.C.; Chen, D.D.; Yuan, L.; Liu, Z.C. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, P. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2020, 80, 8091–8126. [Google Scholar] [CrossRef]
- Aszemi, N.M.; Dominic, P.D.D. Hyperparameter optimization in convolutional neural network using genetic algorithms. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 269–278. [Google Scholar] [CrossRef]
- Bochinski, E.; Senst, T.; Sikora, T. Hyper-parameter optimization for convolutional neural network committees based on evolutionary algorithms. In Proceedings of the 2017 IEEE international conference on image processing (ICIP), Beijing, China, 17−20 September 2017; pp. 3924–3928. [Google Scholar]
- Du, W.S.; Zhu, Y.J.; Li, S.S.; Liu, P. Spikelets detection of table grape before thinning based on improved YOLOV5s and Kmeans under the complex environment. Comput. Electron. Agric. 2022, 203, 107432. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | |||
|---|---|---|---|
| Category | Training set (Original/Augmentation) | Validation set (Original/Augmentation) | Test set (Original/Augmentation) |
| Sea Cucumber | 2771/15774 | 801/4482 | 446/2276 |
| Sea Urchin | 4403/22374 | 1339/6918 | 644/3016 |
| Layer Number | Network Layer | Input Dimension | Stride |
|---|---|---|---|
| 0 | Conv 6 × 6 | 3 × 640 × 640 | 2 |
| 1 | Conv 3 × 3 | 32 × 320 × 320 | 2 |
| 2 | C3 | 64 × 160 × 160 | - |
| 3 | HorBlock | 64 × 160 × 160 | - |
| 4 | Conv 3 × 3 | 64 × 160 × 160 | 2 |
| 5 | C3 | 128 × 80 × 80 | - |
| 6 | HorBlock | 128 × 80 × 80 | - |
| 7 | Conv 3 × 3 | 128 × 80 × 80 | 2 |
| 8 | C3 | 256 × 40 × 40 | - |
| 9 | HorBlock | 256 × 40 × 40 | - |
| 10 | Conv 3 × 3 | 256 × 40 × 40 | 2 |
| 11 | C3 | 512 × 20 × 20 | - |
| 12 | HorBlock | 512 × 20 × 20 | - |
| 13 | SPPF | 512 × 20 × 20 | - |
| 14 | Conv 1 × 1 | 512 × 20 × 20 | 1 |
| 15 | nn.Upsample | 256 × 20 × 20 | - |
| 16 | Concat | 256 × 40 × 40 | - |
| 17 | C3 | 512 × 40 × 40 | - |
| 18 | Conv 1 × 1 | 512 × 40 × 40 | 1 |
| 19 | nn.Upsample | 128 × 40 × 40 | - |
| 20 | Concat | 128 × 80 × 80 | - |
| 21 | C3 | 256 × 80 × 80 | - |
| 22 | Conv 3 × 3 | 128 × 80 × 80 | 2 |
| 23 | Concat | 128 × 40 × 40 | - |
| 24 | C3 | 256 × 40 × 40 | - |
| 25 | Conv 3 × 3 | 256 × 40 × 40 | 2 |
| 26 | Concat | 256 × 20 × 20 | - |
| 27 | C3 | 512 × 20 × 20 | - |
| 128 × 80 × 80 | |||
| 28 | Detect | 256 × 40 × 40 | - |
| 512 × 20 × 20 |
| Parameter | lr0 | lrf | Momentum | Weight Decay | Warmup Epochs | Warmup Momentum | Warmup Bias lr | Box | cls | cls pw | |
| Original | 0.001 | 0.01 | 0.937 | 0.0005 | 3.0 | 0.8 | 0.1 | 0.05 | 0.5 | 1.0 | |
| After Evolution | 0.00886 | 0.01 | 0.85395 | 0.0004 | 3.0549 | 0.84169 | 0.06114 | 0.10873 | 0.2 | 1.0017 | |
| Parameter | obj | obj pw | iou t | anchor t | fl gamma | hsv h | hsv s | hsv v | degrees | ||
| Original | 1.0 | 1.0 | 0.20 | 4.0 | 0.0 | 0.015 | 0.7 | 0.4 | 0.0 | ||
| After Evolution | 1.0651 | 0.75344 | 0.2 | 3.2016 | 0.0 | 0.01024 | 0.36303 | 0.18256 | 0.0 | ||
| Parameter | translate | scale | shear | perspective | flipud | fliplr | mosaic | mixup | copy paste | anchors | |
| Original | 0.1 | 0.5 | 0.0 | 0.0 | 0.0 | 0.5 | 1.0 | 0.0 | 0.0 | 3 | |
| After Evolution | 0.14064 | 0.39425 | 0.0 | 0.0 | 0.0 | 0.5 | 1.0 | 0.0 | 0.0 | 3.9496 | |
| Item | Parameter |
|---|---|
| Operating System | Windows 10 |
| Central Processing Unit | Intel(R) Core(TM) i5-11400F |
| GPU | GeForce RTX 3090 |
| Graphics Card Driver | CUDA 11.1 |
| Software Environment | OpenCV-Python 4.5.5.62 |
| Deep Learning Framework | PyTorch 1.10.2 |
| HorBlock | Hyperparametric Evolution | Offline Data Augmentation | mAP/% | Parameters/M | Average Detection Time/ms |
|---|---|---|---|---|---|
| 89.5 | 7.02 | 7.09 | |||
| √ | 90.4 | 11.19 | 14.09 | ||
| √ | √ | 91.5 | 11.20 | 11.54 | |
| √ | √ | √ | 94.0 | 11.20 | 11.18 |
| Models | Sea Cucumber AP/% | Sea Urchin AP/% | mAP/% | Parameters/M | Average Detection Time/ms |
|---|---|---|---|---|---|
| RetinaNet | 72.23 | 92.27 | 82.25 | 36.1 | 105.02 |
| SSD | 78 | 90 | 83.69 | 24.5 | 4.89 |
| YOLOv4 | 77 | 95 | 85.92 | 64.36 | 17.64 |
| YOLOv5s | 83.9 | 95.1 | 89.5 | 7.02 | 7.09 |
| YOLOv5m | 87.0 | 94.6 | 90.8 | 20.88 | 17.81 |
| YOLOv5l | 86.5 | 95.2 | 90.9 | 46.14 | 17.36 |
| YOLOv5x | 87.3 | 94.8 | 91.0 | 86.18 | 13.81 |
| Improved YOLOv5s | 91.2 | 96.7 | 94.0 | 11.20 | 11.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, C.; Guan, Z.; Guo, Z.; Zhou, S.; Lin, M. An Improved YOLOv5s-Based Scheme for Target Detection in a Complex Underwater Environment. J. Mar. Sci. Eng. 2023, 11, 1041. https://doi.org/10.3390/jmse11051041
Hou C, Guan Z, Guo Z, Zhou S, Lin M. An Improved YOLOv5s-Based Scheme for Target Detection in a Complex Underwater Environment. Journal of Marine Science and Engineering. 2023; 11(5):1041. https://doi.org/10.3390/jmse11051041
Chicago/Turabian StyleHou, Chenglong, Zhiguang Guan, Ziyi Guo, Siqi Zhou, and Mingxing Lin. 2023. "An Improved YOLOv5s-Based Scheme for Target Detection in a Complex Underwater Environment" Journal of Marine Science and Engineering 11, no. 5: 1041. https://doi.org/10.3390/jmse11051041