1.1. Background
In world trade, about 90% of freight is transported by ships, and unsafe crew operations have already led to various accidents, including ship collisions, ship grounding, and occupational accidents. The statistics reveal that 80–85% of accidents are directly or indirectly caused by human error or unsafe behavior [
1]. Mooring operations are among the most dangerous tasks carried out aboard ships [
2]. To date, many fatalities and fatal injuries originating from unsafe mooring practices aboard have been reported, with statistics from the European Harbor Masters’ Committee showing that ropes and wires cause 95% of personal injury incidents, and 60% of these injuries happen during mooring operations [
3]. According to the Pilbara ports authority, mooring line failures/parted mooring line incidents pose a significant risk to personnel, infrastructure, and operations in the port. Over the past few years, many mooring line incidents have been reported in the Port of Hedland, forming approximately 20% of all marine incidents [
4]. If the mooring operation is conducted improperly, there is also a risk of the vessel colliding with other ships or damaging the shore structure. Therefore, ensuring safe mooring practices is essential for accident prevention.
Currently, the primary way to ensure safety during mooring and unmooring is to enforce the safety procedures, including proper use of personal protective equipment (PPE) during works on deck, clearance of deck prior to operations, and monitoring of the dangerous zones (e.g., snap-back zones and potential pinch points) and deck activities. The monitoring mainly relies on manual supervision by experienced seafarers, who purposely search for hazards that may cause injury, such as trip and trap hazards and mooring lines under tension, and immediately issue warnings to the crew. However, mooring is a dynamic and complicated process. Thus, in practice, the supervisor is often involved with other operations and cannot monitor effectively. Furthermore, the supervisor has human sensory and attention limitations, potentially delaying the warning.
In the maritime industry, despite the considerable amount of research that has been conducted on unsafe behaviors, the focus is primarily on error-producing conditions for unsafe acts and prediction. One limitation of focusing primarily on error-producing conditions and prediction is that it may not be effective in addressing more complex or dynamic safety issues. In some cases, the factors that contribute to accidents and incidents may be difficult to predict or may involve a combination of individual, organizational, and systemic factors that are difficult to identify and address. Another limitation is that a focus on prediction and prevention may not be sufficient to ensure safety in all circumstances. Even with the best efforts to predict and prevent accidents and incidents, there is always a risk that something unexpected could happen. Therefore, it is important to have monitor systems in place to manage and respond to emergencies when they do occur. For example, Celik and Cebi used the Human Factors Analysis and Classification System (HFACS) to model the factors that affect human errors in ship accidents and found that the technical environment plays the most crucial role [
5]. Moreover, Xue Yang used the Bayesian network and tree-augmented naive Bayes (TAN) search algorithms to build a prediction model to decide the operational limits of a given operation [
6]. Additionally, Ung employed the fuzzy cognitive reliability and error analysis method (CREAM) to analyze accidents caused by personnel factors [
7]. Furthermore, Salihoglu and Bal Beşikçi developed the functional resonance analysis (FRAM) model to analyze offshore oil spill accidents [
8]. All the methods mentioned above analyzed the results to determine the factors causing the accidents and provided suggestions for improving maritime safety.
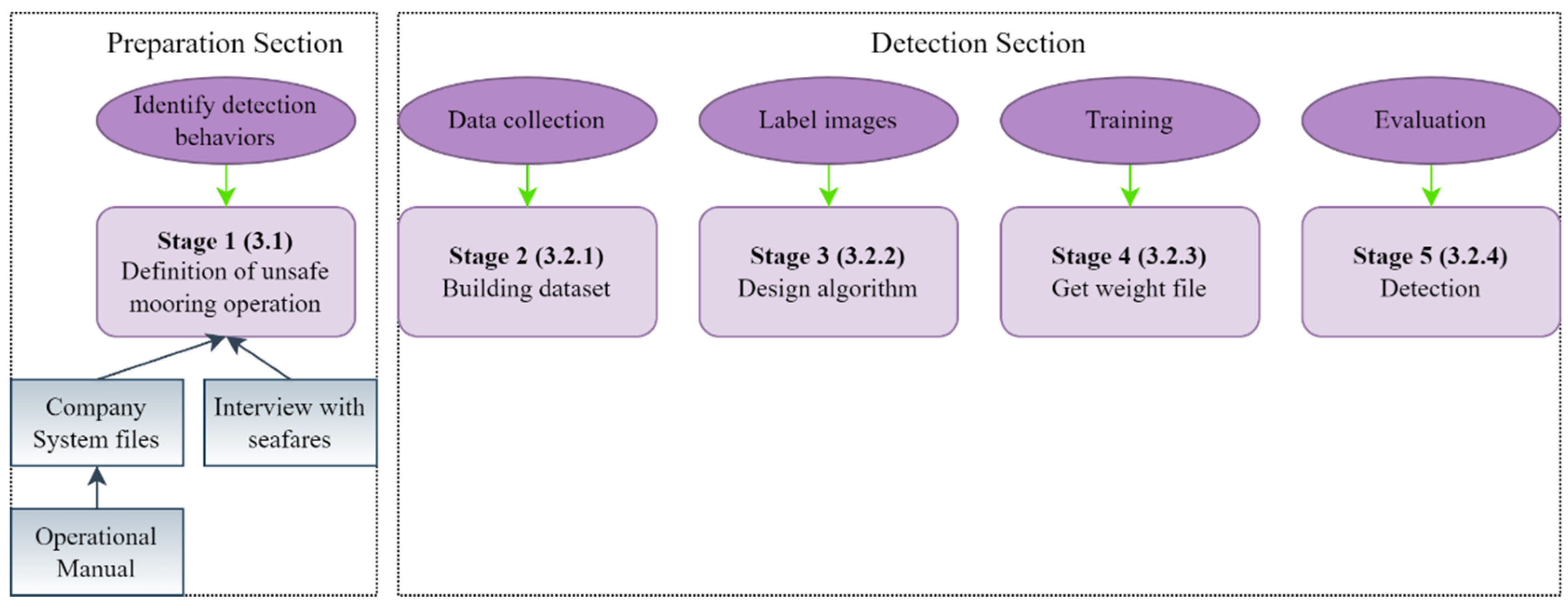
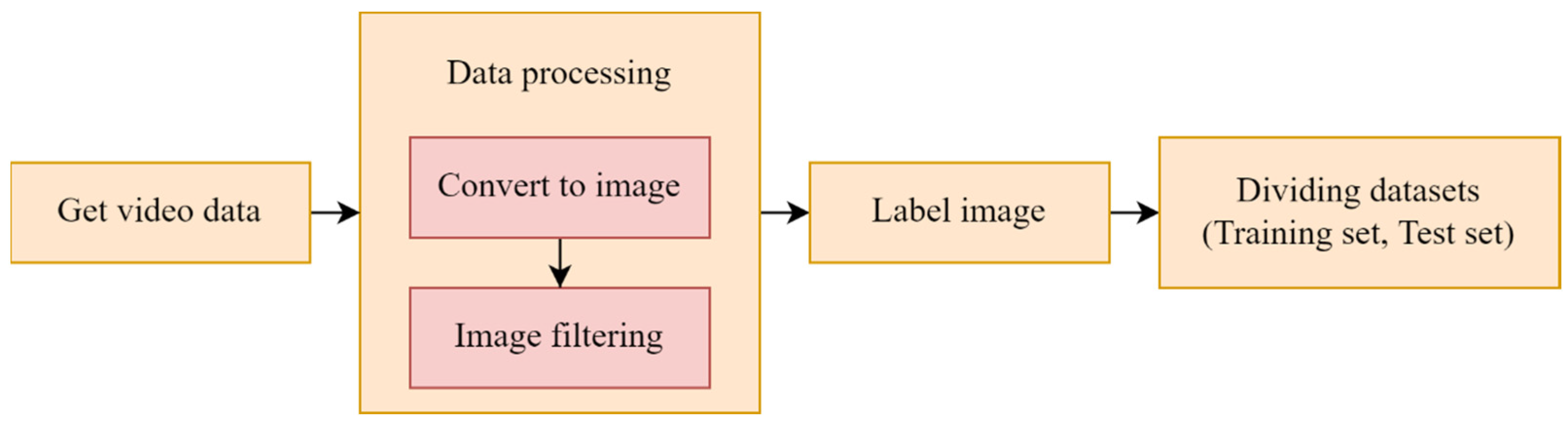
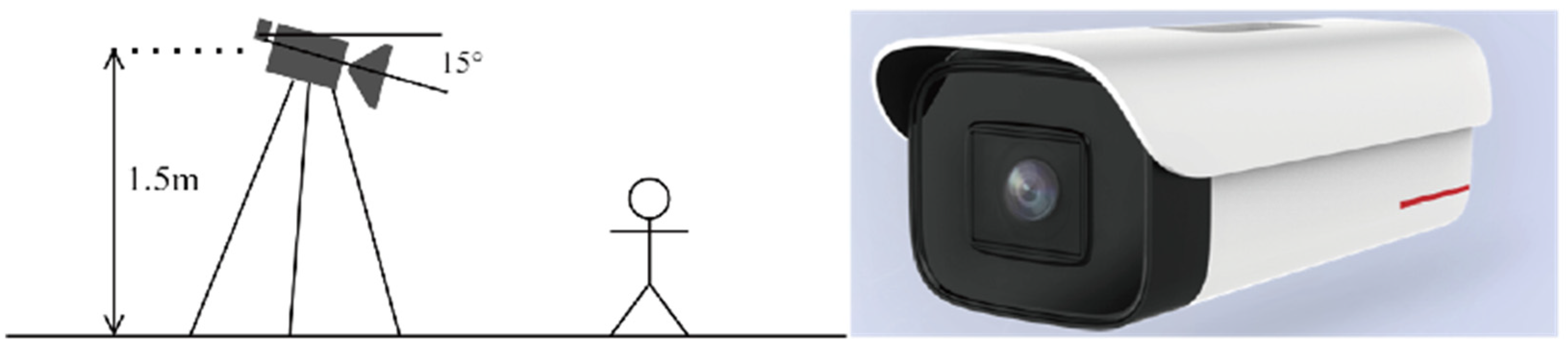
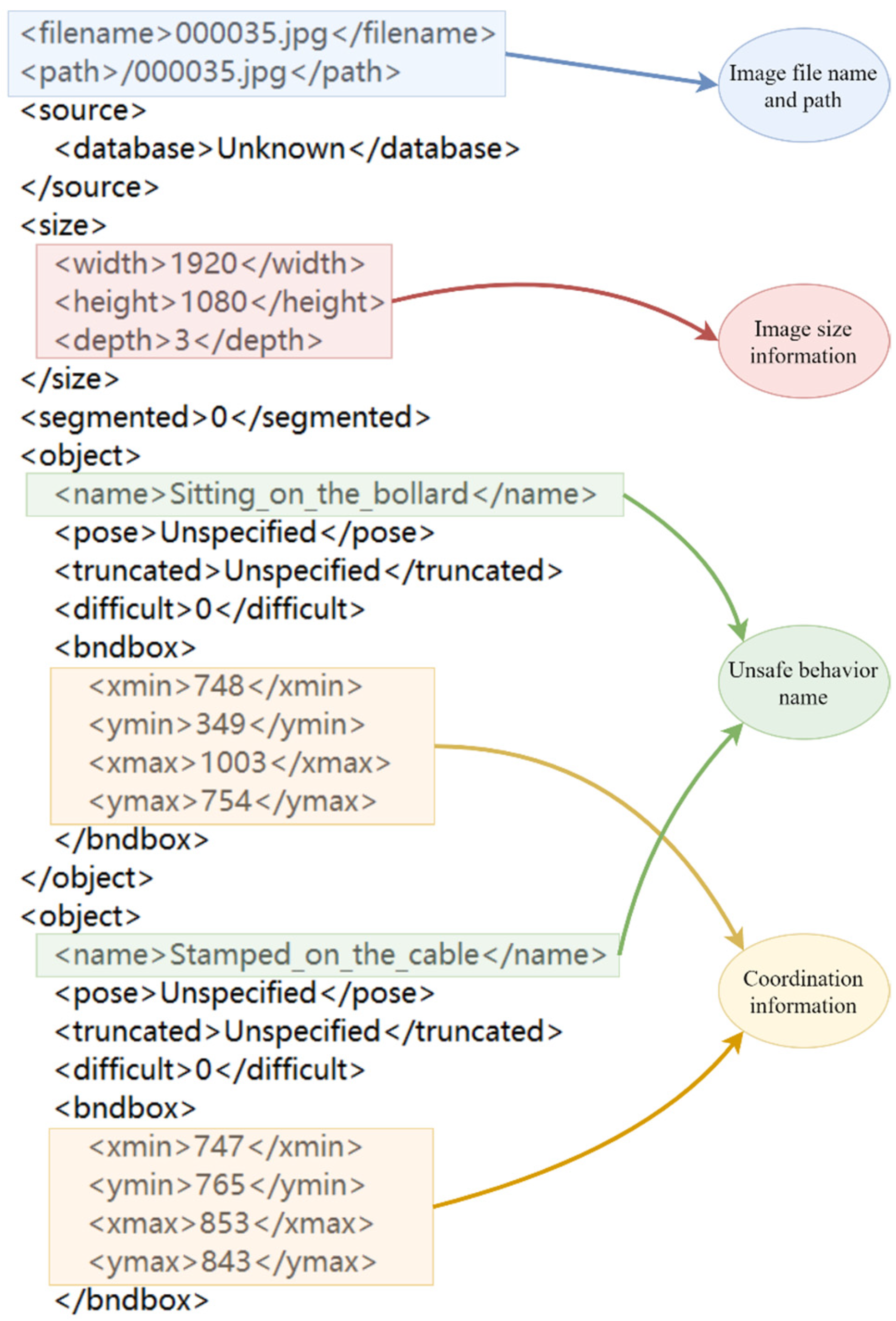
To address the above problems, this paper develops a computer vision approach to monitor the behavior of rope handling on the deck. There are a number of reasons why a computer vision approach to monitoring rope handling on the deck may be considered a better approach:
Automation: It allows for automated tracking and analysis of human behavior, reducing the time and resources required [
9].
Objectivity: Analysis is not influenced by human biases, providing accurate and consistent results [
10].
Non-intrusive: Monitoring can be performed through cameras or other image-capturing devices, minimizing disturbance to workers [
11].
Computer vision, also known as machine vision, is a field of artificial intelligence (AI) enabling computers and systems to derive meaningful information from digital images, video, and other visual inputs and then take actions or make suggestions based on that information. In recent years, computer vision-based approaches and deep learning techniques have been widely applied in high-risk industries to improve onsite safety by recognizing and warning against unsafe behaviors. For instance, Fang developed a computer vision scheme to monitor the unsafe behavior of workers passing through the scaffolding during the construction of the engineering structure [
12]. Additionally, Lee used a camera to detect pedestrian behaviors for early accident prevention in an advanced driver assistance system (ADAS) [
13], and Luo used real-time intelligent video surveillance to prevent people from entering hazardous work areas during the construction of projects in urban areas [
14]. Additionally, Cyganek and Gruszczyński built a system for driver eye recognition and fatigue monitoring, ensuring traffic safety [
15].
With the development of video surveillance technology and convolutional neural networks, video monitoring has been widely applied for safety monitoring [
16]. For example, Han and Lee utilized computer vision to monitor people’s unsafe behavior by developing a framework for unsafe behavior detection and monitoring [
17]. This computer vision-based method included two CNN models to monitor whether safety belts were appropriately used while workers were working at heights [
18]. An image-skeleton-based method to monitor construction workers’ unsafe behaviors has also been proposed [
19], and the detection algorithm comprises two modules. The first module predicts the bounding boxes of the driver’s right hand and right ear from RGB images. The second module takes the bounding boxes as input and predicts the type of distraction. This method efficiently detects normal driving, using a touchscreen, and talking to a phone. Additionally, Pramanik proposed a video surveillance-based system for improving road safety [
20]. The system integrates five algorithms within one surveillance system to detect traffic pre-events. These algorithms combine spatial and temporal features and thus are more informative than solely relying on spatial or temporal features. This method generates an alarm in the control room to allow precautionary measures to be taken and improve road safety.
The video surveillance technology and machine learning approaches applied for automatic unsafe behavior detection and recognition in various industries have the following merits:
Noncontact and safer measurement, avoiding damaging the observer and the observed objects/personnel, reducing the risk of injury due to participating in the monitoring process.
Working stably for a long time. It is difficult for humans to observe the same object for a long time due to fatigue and distractions, while machine vision can measure, analyze, and recognize an object for a long time.
Reduced cost. The machine vision system improves the recognition speed and reduces the labor in monitoring, significantly reducing the overall cost.
Despite the above merits, research on mooring operation monitoring in the maritime industry has not been investigated yet. However, intelligent monitoring will significantly improve crew safety, assist the shipping companies’ safety management systems, and reduce the supervisors’ stress and help them focus more on their work, reducing the risk caused by fatigue and distraction during mutual supervision. At the same time, monitoring mooring can also provide early warnings in situations with fewer crew members than required on the deck.
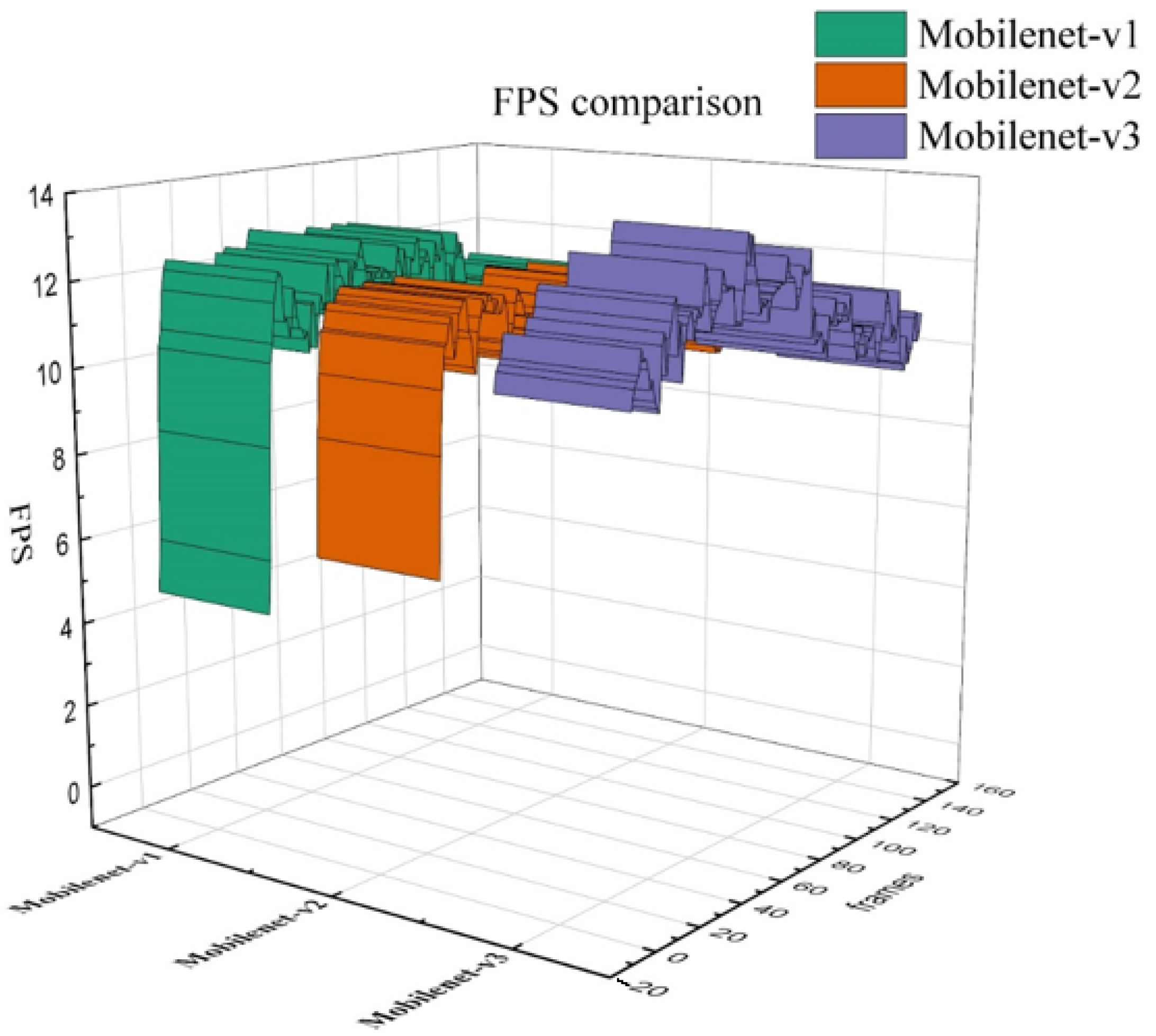
You Only Look Once version 4 (YOLO-v4) is a real-time object detection algorithm that uses a single CNN to identify objects within an image; it is known for its high accuracy and fast processing speed. It uses a multi-scale architecture and anchor boxes to improve detection performance and adjust the size and shape of the predicted bounding boxes. Arunabha M. Roy presents an improved version of the YOLO-v4 algorithm for high-performance real-time fine-grain object detection in plant disease detection that addresses obstacles such as dense distribution, irregular morphology, multi-scale object classes, and textural similarity, resulting in better detection accuracy and speed than existing state-of-the-art models [
21]. Arunabha M. Roy presents a high-performance real-time fine-grain object detection framework, based on an improved YOLO-v4 algorithm, that addresses several obstacles in plant disease detection, providing an effective and efficient method for detecting different plant diseases in complex scenarios that can be extended to different fruit and crop detection, generic disease detection, and various automated agricultural detection processes [
22]. Arunabha M. Roy presents WilDect-YOLO, resulting in superior detection of endangered wildlife under challenging environments with a mean average precision (mAP) value of 96.89%, F1 score of 97.87%, and precision value of 97.18% at a detection rate of 59.20 FPS, outperforming current state-of-the-art models [
23].
The current work proposes a real-time object detection framework Dense-YOLO-v4 that includes DenseNet in the backbone and a modified path aggregation network (PANet) to preserve fine-grain localized information, which has been applied to detect different growth stages of mango with a high degree of occultation in a complex orchard scenario and different automated agricultural applications.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
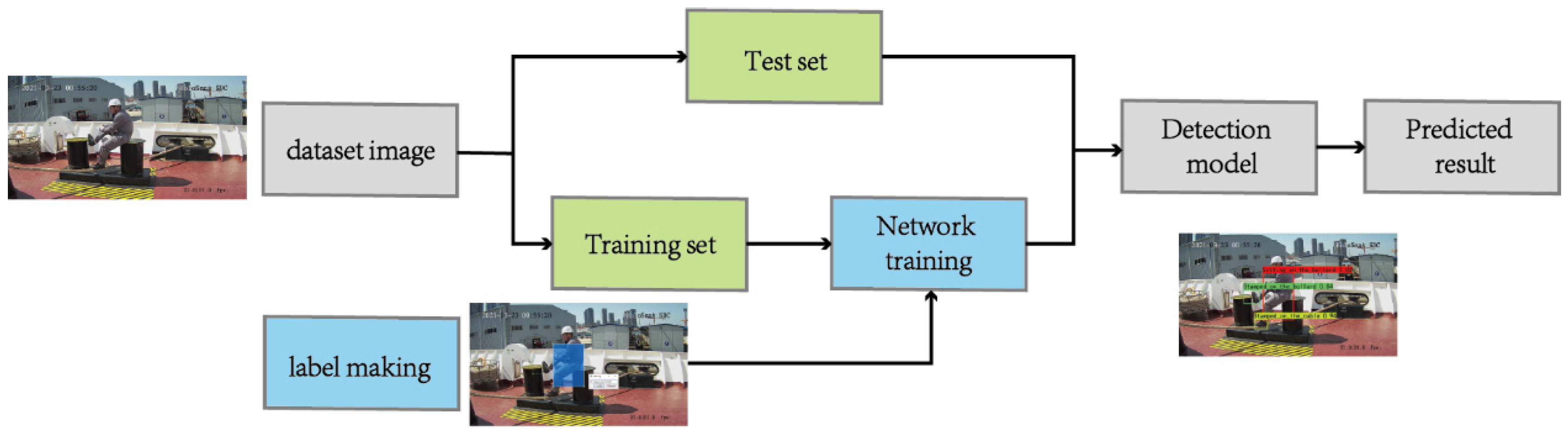{kind=link}
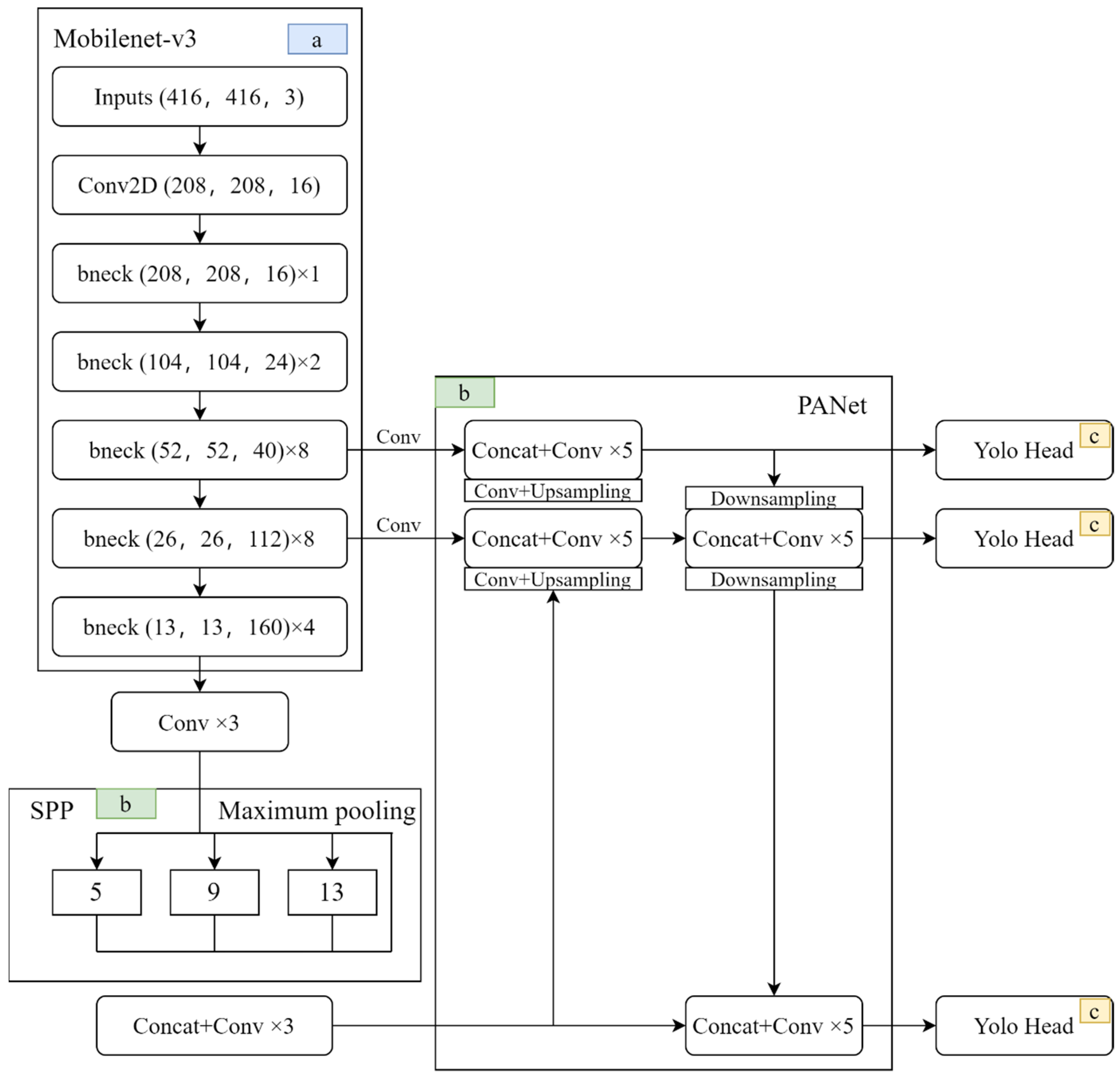{kind=link}
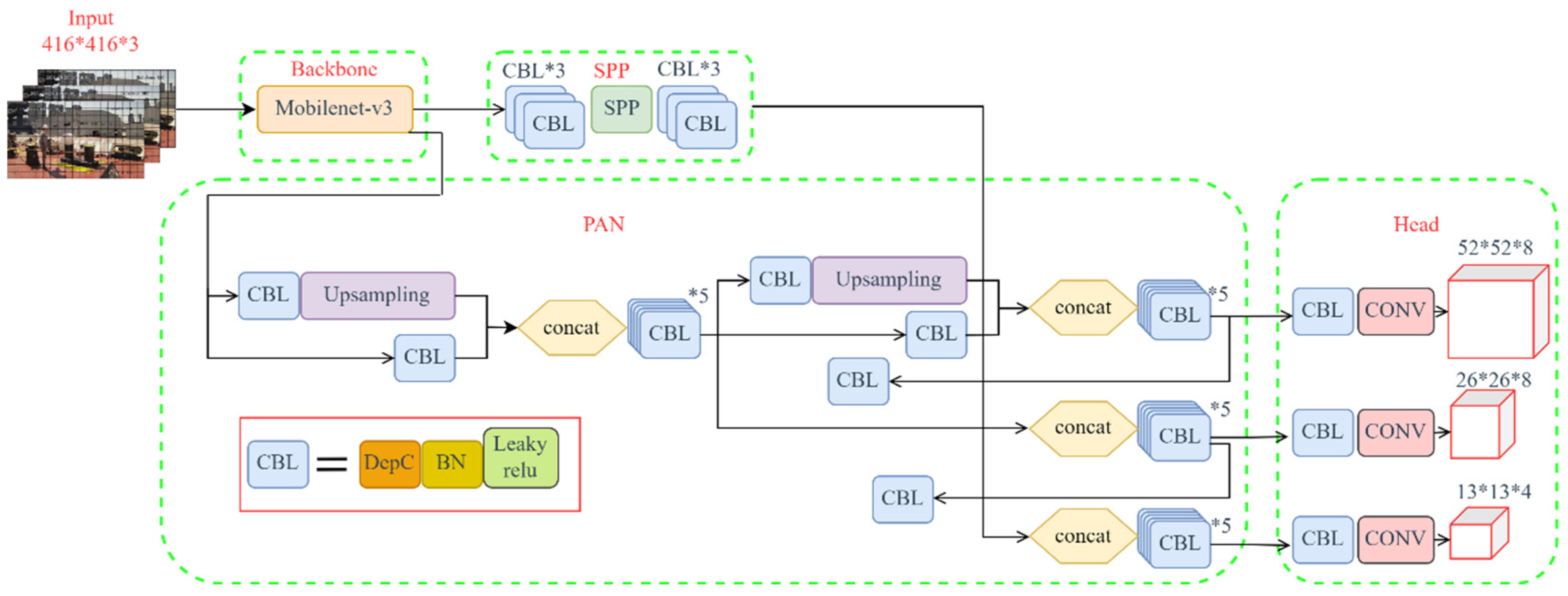{kind=link}
{kind=link}
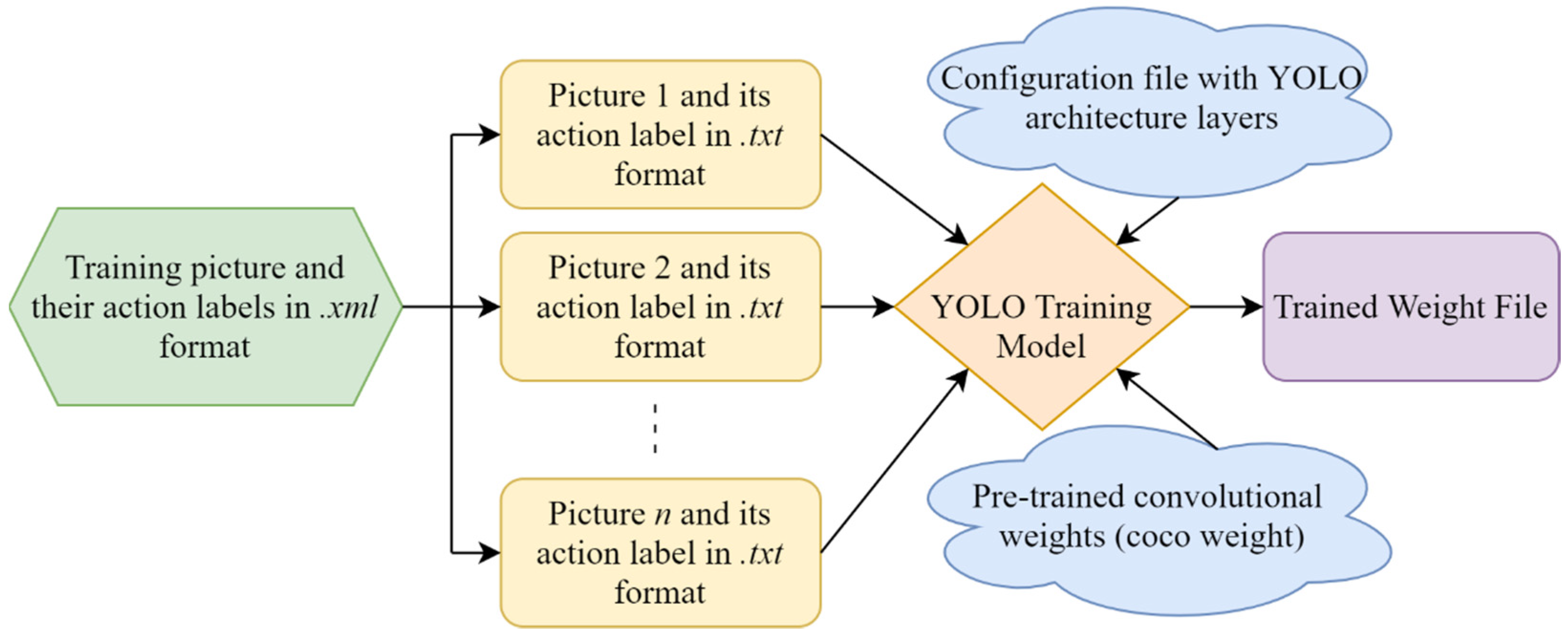{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}