
Deceptive Tricks in Artificial Intelligence: Adversarial Attacks in Ophthalmology

Abstract
:
1. Introduction
2. Adversarial Attacks
Problem Formulation
- The query input is changed from the benign input x to .
- An attack target is set so that the prediction result is no longer y. The loss is changed from to , where .
3. Methodology
4. Challenges in Adversarial Attacks in Medicine
- Typically, medical images have complex biological textures, leading to areas with stronger gradients that are sensitive to small perturbations from attackers.
- State-of-the-art deep neural networks designed for large-scale natural image processing can be reparameterised for medical imaging tasks, resulting in a severe loss of landscape and high susceptibility to AAs.
The Danger of Adversarial Attacks in the Healthcare System
5. Adversarial Attacks in Ophthalmology
6. Specified Adversarial Attacks in Ophthalmology
6.1. Adaptive Segmentation Mask Attack
6.2. HFC
6.3. MSA
6.4. SMIA
6.5. Remarks
7. Regulations
7.1. The European Union
“Cybersecurity plays a crucial role in ensuring that AI systems are resilient against attempts to alter their use, behaviour, performance or compromise their security properties by malicious third parties exploiting the system’s vulnerabilities. Cyberattacks against AI systems can leverage AI specific assets, such as training data sets (e.g., data poisoning) or trained models (e.g., adversarial attacks), or exploit vulnerabilities in the AI system’s digital assets or the underlying ICT infrastructure. To ensure a level of cybersecurity appropriate to the risks, suitable measures should therefore be taken by the providers of high-risk AI systems, also taking into account as appropriate the underlying ICT infrastructure.”
“High-risk AI systems shall be resilient as regards attempts by unauthorised third parties to alter their use or performance by exploiting the system vulnerabilities.The technical solutions aimed at ensuring the cybersecurity of high-risk AI systems shall be appropriate to the relevant circumstances and the risks.The technical solutions to address AI specific vulnerabilities shall include, where appropriate, measures to prevent and control for attacks trying to manipulate the training dataset (‘data poisoning’), inputs designed to cause the model to make a mistake (‘adversarial examples’), or model flaws.”
7.2. The United States of America
“Support regulatory science efforts to develop methodology for the evaluation and improvement of machine learning algorithms, including for the identification and elimination of bias, and for the evaluation and promotion of algorithm robustness.”
7.3. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, S.Y.; Pershing, S.; Lee, A.Y. Big data requirements for artificial intelligence. Curr. Opin. Ophthalmol. 2020, 31, 318–323. [Google Scholar] [CrossRef]
- Cheng, C.Y.; Soh, Z.D.; Majithia, S.; Thakur, S.; Rim, T.H.; Chung, T.Y.; Wong, T.Y. Big Data in Ophthalmology. Asia-Pac. J. Ophthalmol. 2020, 9, 291–298. [Google Scholar] [CrossRef] [PubMed]
- Keenan, T.D.; Chen, Q.; Agrón, E.; Tham, Y.C.; Goh, J.H.L.; Lei, X.; Ng, Y.P.; Liu, Y.; Xu, X.; Cheng, C.Y.; et al. DeepLensNet: Deep Learning Automated Diagnosis and Quantitative Classification of Cataract Type and Severity. Ophthalmology 2022, 129, 571–584. [Google Scholar] [CrossRef] [PubMed]
- Papadopoulos, A.; Topouzis, F.; Delopoulos, A. An Interpretable Multiple-Instance Approach for the Detection of referable Diabetic Retinopathy from Fundus Images. Sci. Rep. 2021, 11, 14326. [Google Scholar] [CrossRef]
- Rampasek, L.; Goldenberg, A. Learning from Everyday Images Enables Expert-like Diagnosis of Retinal Diseases. Cell 2018, 172, 893–895. [Google Scholar] [CrossRef] [PubMed]
- Ishii, K.; Asaoka, R.; Omoto, T.; Mitaki, S.; Fujino, Y.; Murata, H.; Onoda, K.; Nagai, A.; Yamaguchi, S.; Obana, A.; et al. Predicting intraocular pressure using systemic variables or fundus photography with deep learning in a health examination cohort. Sci. Rep. 2021, 11, 3687. [Google Scholar] [CrossRef]
- Kermany, D.; Goldbaum, M.; Cai, W.; Valentim, C.; Liang, H.Y.; Baxter, S.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell 2018, 172, 1122–1131.e9. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, J.; Zhou, Y.; Wang, W.; Zhao, J.; Yu, W.; Zhang, D.; Ding, D.; Li, X.; Chen, Y. Prediction of OCT images of short-term response to anti-VEGF treatment for neovascular age-related macular degeneration using generative adversarial network. Br. J. Ophthalmol. 2020, 104, 1735–1740. [Google Scholar] [CrossRef]
- Liu, T.; Farsiu, S.; Ting, D. Generative adversarial networks to predict treatment response for neovascular age-related macular degeneration: Interesting, but is it useful? Br. J. Ophthalmol. 2020, 104, 1629–1630. [Google Scholar] [CrossRef]
- Burlina, P.; Paul, W.; Mathew, P.; Joshi, N.; Pacheco, K.; Bressler, N. Low-Shot Deep Learning of Diabetic Retinopathy With Potential Applications to Address Artificial Intelligence Bias in Retinal Diagnostics and Rare Ophthalmic Diseases. JAMA Ophthalmol. 2020, 138, 1070–1077. [Google Scholar] [CrossRef]
- Cen, L.P.; Ji, J.; Lin, J.W.; Ju, S.; Lin, H.J.; Li, T.P.; Wang, Y.; Yang, J.F.; Liu, Y.F.; Tan, S.; et al. Automatic detection of 39 fundus diseases and conditions in retinal photographs using deep neural networks. Nat. Commun. 2021, 12, 4828. [Google Scholar] [CrossRef]
- Zheng, C.; Xie, X.; Zhou, K.; Chen, B.; Chen, J.; Ye, H.; Li, W.; Qiao, T.; Gao, S.; Yang, J.; et al. Assessment of Generative Adversarial Networks Model for Synthetic Optical Coherence Tomography Images of Retinal Disorders. Transl. Vis. Sci. Technol. 2020, 9, 29. [Google Scholar] [CrossRef]
- Shekar, S.; Satpute, N.; Gupta, A. Review on diabetic retinopathy with deep learning methods. J. Med. Imaging 2021, 8, 060901. [Google Scholar] [CrossRef]
- Zhao, X.; Lv, B.; Meng, L.; Xia, Z.; Wang, D.; Zhang, W.; Wang, E.; Lv, C.; Xie, G.; Chen, Y. Development and quantitative assessment of deep learning-based image enhancement for optical coherence tomography. BMC Ophthalmol. 2022, 22, 139. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Liu, X.; Glocker, B.; McCradden, M.M.; Ghassemi, M.; Denniston, A.K.; Oakden-Rayner, L. The medical algorithmic audit. Lancet Digit. Health 2022, 4, e384–e397. [Google Scholar] [CrossRef]
- Mahmood, K.; Mahmood, R.; van Dijk, M. On the Robustness of Vision Transformers to Adversarial Examples. 2021. Available online: https://openaccess.thecvf.com/content/ICCV2021/papers/Mahmood_On_the_Robustness_of_Vision_Transformers_to_Adversarial_Examples_ICCV_2021_paper.pdf (accessed on 25 April 2023).
- Hu, H.; Lu, X.; Zhang, X.; Zhang, T.; Sun, G. Inheritance Attention Matrix-Based Universal Adversarial Perturbations on Vision Transformers. IEEE Signal Process. Lett. 2021, 28, 1923–1927. [Google Scholar] [CrossRef]
- Naseer, M.; Ranasinghe, K.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Intriguing Properties of Vision Transformers. 2021. Available online: https://proceedings.neurips.cc/paper/2021/file/c404a5adbf90e09631678b13b05d9d7a-Paper.pdf (accessed on 25 April 2023).
- Wang, Z.; Ruan, W. Understanding Adversarial Robustness of Vision Transformers via Cauchy Problem. 2022. Available online: https://arxiv.org/abs/2208.00906 (accessed on 22 April 2023).
- Ma, X.; Niu, Y.; Gu, L.; Wang, Y.; Zhao, Y.; Bailey, J.; Lu, F. Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems. Pattern Recognit. 2020, 110, 107332. [Google Scholar] [CrossRef]
- Paschali, M.; Conjeti, S.; Navarro, F.; Navab, N. Generalizability vs. Robustness: Adversarial Examples for Medical Imaging. arXiv 2018, arXiv:1804.00504. [Google Scholar]
- Avramidis, K.; Rostami, M.; Chang, M.; Narayanan, S. Automating Detection of Papilledema in Pediatric Fundus Images with Explainable Machine Learning. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022. [Google Scholar] [CrossRef]
- Kind, A.; Azzopardi, G. An Explainable AI-Based Computer Aided Detection System for Diabetic Retinopathy Using Retinal Fundus Images. In Proceedings of the Computer Analysis of Images and Patterns; Vento, M., Percannella, G., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 457–468. [Google Scholar]
- Chetoui, M.; Akhloufi, M.A. Explainable Diabetic Retinopathy using EfficientNET. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montréal, QC, Canada, 20–24 July 2020; pp. 1966–1969. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Finlayson, S.G.; Bowers, J.D.; Ito, J.; Zittrain, J.L.; Beam, A.L.; Kohane, I.S. Adversarial attacks on medical machine learning. Science 2019, 363, 1287–1289. [Google Scholar] [CrossRef]
- Finlayson, S.G.; Kohane, I.S.; Beam, A.L. Adversarial Attacks Against Medical Deep Learning Systems. arXiv 2018, arXiv:1804.05296. [Google Scholar]
- Shah, A.; Lynch, S.; Niemeijer, M.; Amelon, R.; Clarida, W.; Folk, J.; Russell, S.; Wu, X.; Abràmoff, M.D. Susceptibility to misdiagnosis of adversarial images by deep learning based retinal image analysis algorithms. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 1454–1457. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Abràmoff, M.D.; Lou, Y.; Erginay, A.; Clarida, W.; Amelon, R.; Folk, J.C.; Niemeijer, M. Improved Automated Detection of Diabetic Retinopathy on a Publicly Available Dataset Through Integration of Deep Learning. Investig. Ophthalmol. Vis. Sci. 2016, 57, 5200–5206. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Cuadros, J.; Bresnick, G. EyePACS: An Adaptable Telemedicine System for Diabetic Retinopathy Screening. J. Diabetes Sci. Technol. 2009, 3, 509–516. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Buckman, J.; Roy, A.; Raffel, C.; Goodfellow, I. Thermometer Encoding: One Hot Way To Resist Adversarial Examples. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Yoo, T.K.; Choi, J.Y. Outcomes of Adversarial Attacks on Deep Learning Models for Ophthalmology Imaging Domains. JAMA Ophthalmol. 2020, 138, 1213–1215. [Google Scholar] [CrossRef] [PubMed]
- Lal, S.; Rehman, S.U.; Shah, J.H.; Meraj, T.; Rauf, H.T.; Damaševičius, R.; Mohammed, M.A.; Abdulkareem, K.H. Adversarial Attack and Defence through Adversarial Training and Feature Fusion for Diabetic Retinopathy Recognition. Sensors 2021, 21, 3922. [Google Scholar] [CrossRef]
- Hirano, H.; Minagi, A.; Takemoto, K. Universal adversarial attacks on deep neural networks for medical image classification. BMC Med. Imaging 2020, 21, 9. [Google Scholar] [CrossRef]
- Ozbulak, U.; Van Messem, A.; De Neve, W. Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation. arXiv 2019, arXiv:1907.13124. [Google Scholar] [CrossRef]
- Yao, Q.; He, Z.; Lin, Y.; Ma, K.; Zheng, Y.; Zhou, S.K. A Hierarchical Feature Constraint to Camouflage Medical Adversarial Attacks. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2021; de Bruijne, M., Cattin, P.C., Cotin, S., Padoy, N., Speidel, S., Zheng, Y., Essert, C., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 36–47. [Google Scholar]
- Shao, M.; Zhang, G.; Zuo, W.; Meng, D. Target attack on biomedical image segmentation model based on multi-scale gradients. Inf. Sci. 2021, 554, 33–46. [Google Scholar] [CrossRef]
- Qi, G.; Gong, L.; Song, Y.; Ma, K.; Zheng, Y. Stabilized Medical Image Attacks. 2021. Available online: https://arxiv.org/abs/2103.05232 (accessed on 25 April 2023).
- Commision, E. Regulation of the European Parliament and of the Council Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act) and Amending Certain Union Legislative Acts. 2021. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:52021PC0206&from=EN (accessed on 22 April 2023).
- Food and Drug Administration Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) Action Plan. 2021. Available online: https://www.fda.gov/media/145022/download (accessed on 25 April 2023).
- Carlini, N.; Wagner, D.A. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, SP 2017, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of the Attack | Characteristics |
|---|---|
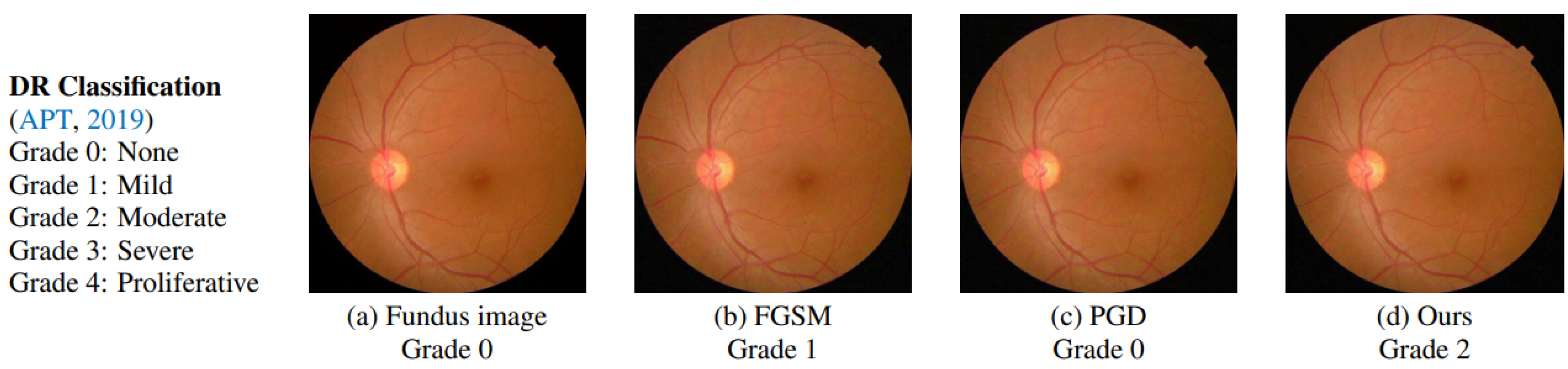
| I-FGSM [29,33] | FGSM iteratively adds the noise (not random noise) whose direction is the same as the gradient of the cost function concerning the data. |
| PGD [28,36] | Initialises the attack to a random point in the ball of interest and performs random restarts. |
| FGSM [21,36,38] | Adds the noise (not random noise) whose direction is the same as the gradient of the cost function concerning the data. |
| BIM [21,33] | A simple extension of the FGSM where, rather than taking one significant step, it performs an iterative procedure by using FGSM numerous times on an image. |
| C&W [21,47] | A regularisation-based attack with some necessary modifications that can resolve the unboundedness issue. |
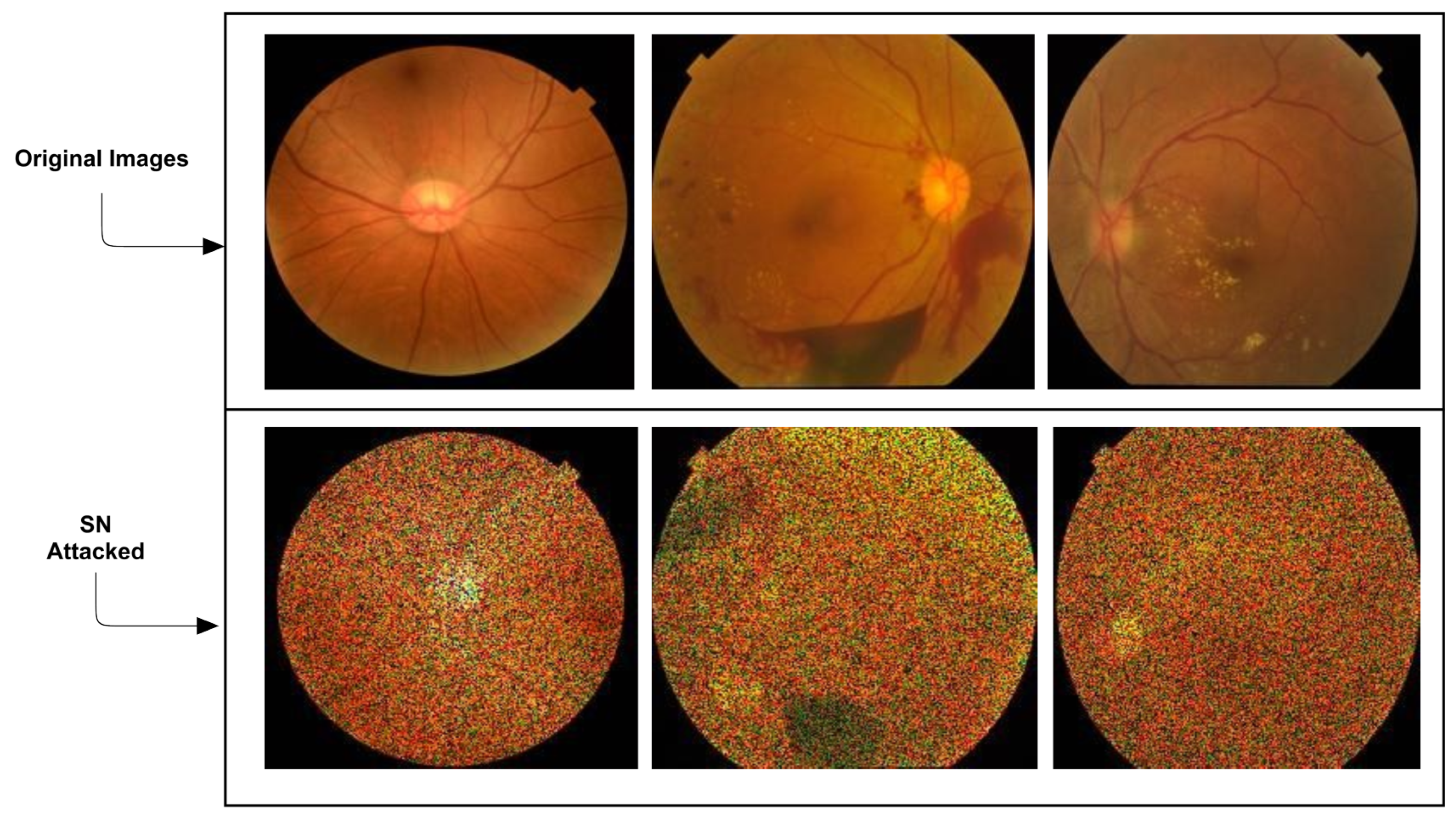
| SN [39] | The gritty salt-and-pepper pattern seen in radar imaging or a granular ‘noise’ that appears fundamentally in ultrasound. |
| UAP [40,48] | Leads to DNN failure in most image classification tasks. |
| Type of the Attack | Characteristics |
|---|---|
| AMSA [41] | Can produce AAs with realistic prediction masks. |
| HFC [42] | Enables hiding the adversarial representation in normal feature distribution. |
| SMIA [44] | The method iteratively generates AAs by maximising the deviation loss term and minimising the loss stabilisation term. |
| MSA [43] | Based on AMSA and multi-scale gradients. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zbrzezny, A.M.; Grzybowski, A.E. Deceptive Tricks in Artificial Intelligence: Adversarial Attacks in Ophthalmology. J. Clin. Med. 2023, 12, 3266. https://doi.org/10.3390/jcm12093266
Zbrzezny AM, Grzybowski AE. Deceptive Tricks in Artificial Intelligence: Adversarial Attacks in Ophthalmology. Journal of Clinical Medicine. 2023; 12(9):3266. https://doi.org/10.3390/jcm12093266
Chicago/Turabian StyleZbrzezny, Agnieszka M., and Andrzej E. Grzybowski. 2023. "Deceptive Tricks in Artificial Intelligence: Adversarial Attacks in Ophthalmology" Journal of Clinical Medicine 12, no. 9: 3266. https://doi.org/10.3390/jcm12093266