
Predicting Six-Month Re-Admission Risk in Heart Failure Patients Using Multiple Machine Learning Methods: A Study Based on the Chinese Heart Failure Population Database
 , , ,
, , ,
Abstract
:1. Introduction
2. Methods
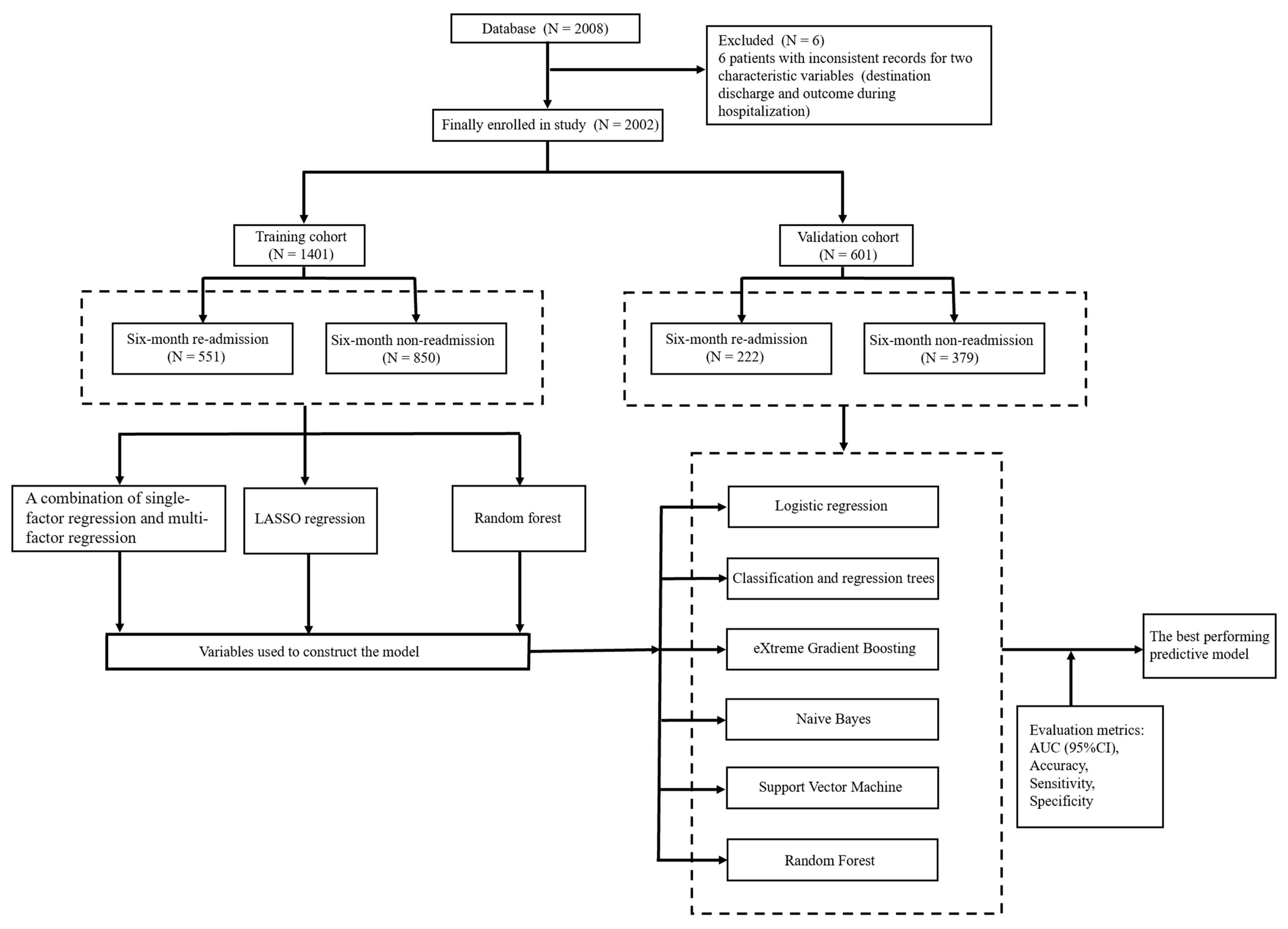
2.1. Sources of Data
2.2. Study Population
2.3. Study Outcome
2.4. Data Pre-Processing
2.5. Variable Selection
2.6. Statistical Analysis
3. Results
3.1. Baseline Characteristics
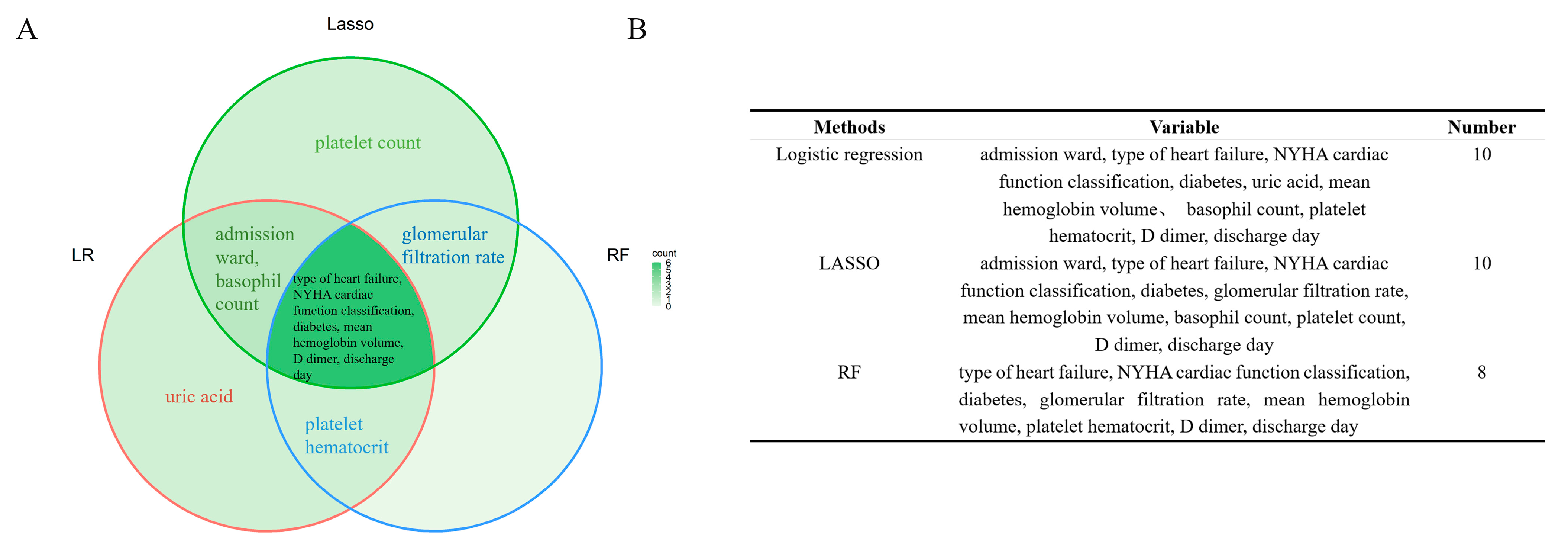
3.2. Variable selection
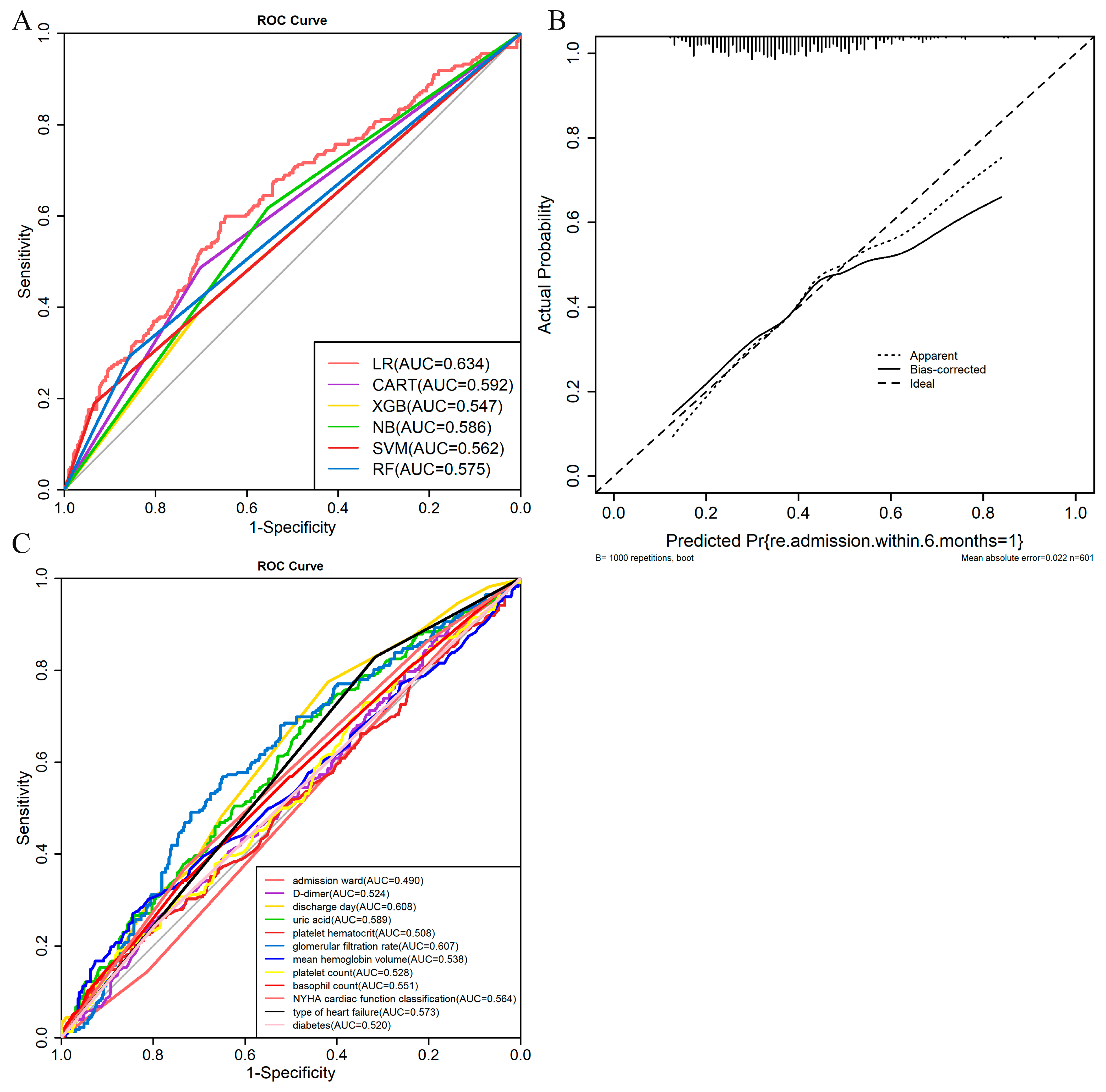
3.3. Model Development and Validation
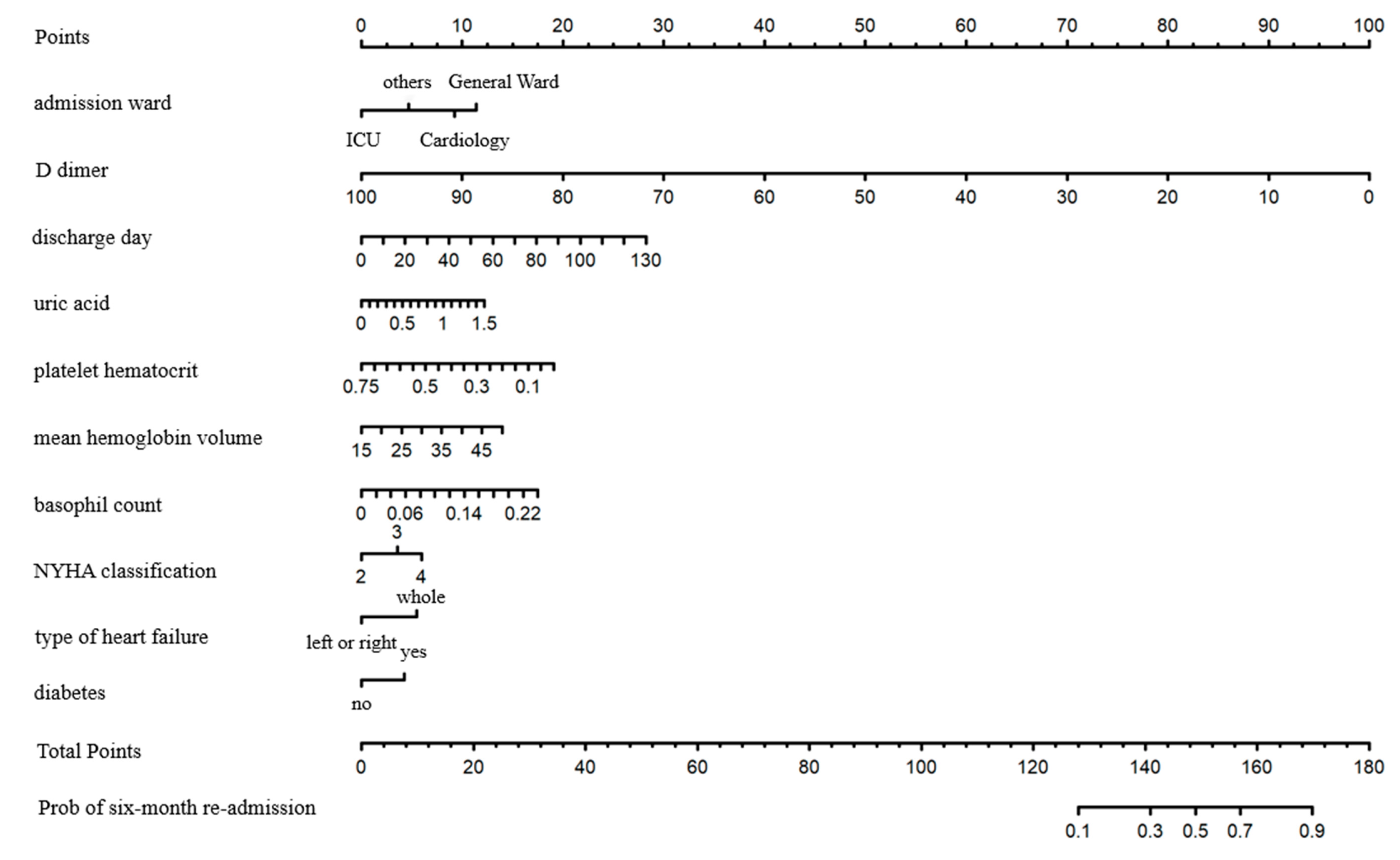
3.4. Establishment of Nomogram
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tsao, C.W.; Aday, A.W.; Almarzooq, Z.I.; Alonso, A.; Beaton, A.Z.; Bittencourt, M.S.; Boehme, A.K.; Buxton, A.E.; Carson, A.P.; Commodore-Mensah, Y.; et al. Heart Disease and Stroke Statistics—2022 Update: A Report From the American Heart Association. Circulation 2022, 145, e153–e639. [Google Scholar] [CrossRef] [PubMed]
- Savarese, G.; Lund, L.H. Global Public Health Burden of Heart Failure. Card. Fail. Rev. 2017, 3, 7–11. [Google Scholar] [CrossRef] [PubMed]
- Savarese, G.; Becher, P.M.; Lund, L.H.; Seferovic, P.; Rosano, G.M.C.; Coats, A.J.S. Global burden of heart failure: A comprehensive and updated review of epidemiology. Cardiovasc. Res. 2022, 118, cvac013. [Google Scholar] [CrossRef] [PubMed]
- Lüscher, T.F. Heart failure: The cardiovascular epidemic of the 21st century. Eur. Heart J. 2015, 36, 395–397. [Google Scholar] [CrossRef] [Green Version]
- Groenewegen, A.; Rutten, F.H.; Mosterd, A.; Hoes, A.W. Epidemiology of heart failure. Eur. J. Heart Fail. 2020, 22, 1342–1356. [Google Scholar] [CrossRef]
- Bragazzi, N.L.; Zhong, W.; Shu, J.; Abu Much, A.; Lotan, D.; Grupper, A.; Younis, A.; Dai, H. Burden of heart failure and underlying causes in 195 countries and territories from 1990 to 2017. Eur. J. Prev. Cardiol. 2021, 28, 1682–1690. [Google Scholar] [CrossRef]
- Hao, G.; Wang, X.; Chen, Z.; Zhang, L.; Zhang, Y.; Wei, B.; Zheng, C.; Kang, Y.; Jiang, L.; Zhu, Z.; et al. Prevalence of heart failure and left ventricular dysfunction in China: The China Hypertension Survey, 2012–2015. Eur. J. Heart Fail. 2019, 21, 1329–1337. [Google Scholar] [CrossRef]
- National Center for Cardiovascular Diseases. Annual Report on Cardiovascular Health and Diseases in China (2020); China Science Publishing & Media Ltd.: Beijing, China, 2021. [Google Scholar]
- Ziaeian, B.; Fonarow, G.C. The Prevention of Hospital Readmissions in Heart Failure. Prog. Cardiovasc. Dis. 2016, 58, 379–385. [Google Scholar] [CrossRef] [Green Version]
- Lim, N.-K.; Lee, S.E.; Lee, H.-Y.; Cho, H.-J.; Choe, W.-S.; Kim, H.; Choi, J.O.; Jeon, E.-S.; Kim, M.-S.; Kim, J.-J.; et al. Risk prediction for 30-day heart failure-specific readmission or death after discharge: Data from the Korean Acute Heart Failure (KorAHF) registry. J. Cardiol. 2019, 73, 108–113. [Google Scholar] [CrossRef] [Green Version]
- McCabe, N.; Butler, J.; Dunbar, S.B.; Higgins, M.; Reilly, C. Six-minute walk distance predicts 30-day readmission after acute heart failure hospitalization. Heart Lung 2017, 46, 287–292. [Google Scholar] [CrossRef]
- Zheng, L.; Smith, N.J.; Teng, B.Q.; Szabo, A.; Joyce, D.L. Predictive Model for Heart Failure Readmission Using Nationwide Readmissions Database. Mayo Clin. Proc. Innov. Qual. Outcomes 2022, 6, 228–238. [Google Scholar] [CrossRef]
- Awan, S.E.; Bennamoun, M.; Sohel, F.; Sanfilippo, F.; Dwivedi, G. Machine learning-based prediction of heart failure readmission or death: Implications of choosing the right model and the right metrics. ESC Heart Fail. 2019, 6, 428–435. [Google Scholar] [CrossRef]
- Adler, E.D.; Voors, A.A.; Klein, L.; Macheret, F.; Braun, O.O.; Urey, M.A.; Zhu, W.; Sama, I.; Tadel, M.; Campagnari, C.; et al. Improving risk prediction in heart failure using machine learning. Eur. J. Heart Fail. 2019, 22, 139–147. [Google Scholar] [CrossRef] [PubMed]
- Pishgar, M.; Theis, J.; Del Rios, M.; Ardati, A.; Anahideh, H.; Darabi, H. Prediction of unplanned 30-day readmission for ICU patients with heart failure. BMC Med Informatics Decis. Mak. 2022, 22, 117. [Google Scholar] [CrossRef] [PubMed]
- Bradford, C.; Shah, B.M.; Shane, P.; Wachi, N.; Sahota, K. Patient and clinical characteristics that heighten risk for heart failure readmission. Res. Soc. Adm. Pharm. 2017, 13, 1070–1081. [Google Scholar] [CrossRef] [PubMed]
- Chi, J.; Chen, F.; Zhang, J.; Niu, X.; Tao, H.; Ruan, H.; Jin, L.; Wang, Y. Frailty is associated with 90-day unplanned readmissions and death in patients with heart failure: A longitudinal study in China. Heart Lung 2022, 53, 25–31. [Google Scholar] [CrossRef]
- Ziaeian, B.; Kominski, G.F.; Ong, M.K.; Mays, V.M.; Brook, R.H.; Fonarow, G.C. National Differences in Trends for Heart Failure Hospitalizations by Sex and Race/Ethnicity. Circ. Cardiovasc. Qual. Outcomes 2017, 10, e003552. [Google Scholar] [CrossRef] [Green Version]
- Sidey-Gibbons, J.A.M.; Sidey-Gibbons, C.J. Machine learning in medicine: A practical introduction. BMC Med. Res. Methodol. 2019, 19, 64. [Google Scholar] [CrossRef] [Green Version]
- Kalafi, E.Y.; Nor, N.A.M.; Taib, N.A.; Ganggayah, M.D.; Town, C.; Dhillon, S.K. Machine Learning and Deep Learning Approaches in Breast Cancer Survival Prediction Using Clinical Data. Folia Biol. 2019, 65, 212–220. [Google Scholar]
- Chen, P.; Dong, W.; Wang, J.; Lu, X.; Kaymak, U.; Huang, Z. Interpretable clinical prediction via attention-based neural network. BMC Med. Informatics Decis. Mak. 2020, 20 (Suppl. S3), 131. [Google Scholar] [CrossRef]
- Heo, J.; Yoon, J.; Park, H.; Kim, Y.D.; Nam, H.S.; Heo, J.H. Machine Learning–Based Model for Prediction of Outcomes in Acute Stroke. Stroke 2019, 50, 1263–1265. [Google Scholar] [CrossRef]
- Guo, C.-Y.; Wu, M.-Y.; Cheng, H.-M. The Comprehensive Machine Learning Analytics for Heart Failure. Int. J. Environ. Res. Public Health 2021, 18, 4943. [Google Scholar] [CrossRef] [PubMed]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, E215–E220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Z.; Cao, L.; Chen, R.; Zhao, Y.; Lv, L.; Xu, Z.; Xu, P. Electronic healthcare records and external outcome data for hospitalized patients with heart failure. Sci. Data 2021, 8, 46. [Google Scholar] [CrossRef] [PubMed]
- Ponikowski, P.; Voors, A.A.; Anker, S.D.; Bueno, H.; Cleland, J.G.; Coats, A.J.; Falk, V.; González-Juanatey, J.R.; Harjola, V.P.; Jankowska, E.A.; et al. 2016 ESC Guidelines for the diagnosis and treatment of acute and chronic heart failure: The Task Force for the diagnosis and treatment of acute and chronic heart failure of the European Society of Cardiology (ESC). Developed with the special contribution of the Heart Failure Association (HFA) of the ESC. Eur. J. Heart Fail. 2016, 18, 891–975. [Google Scholar]
- Bat-Erdene, B.-I.; Zheng, H.; Son, S.H.; Lee, J.Y. Deep learning-based prediction of heart failure rehospitalization during 6, 12, 24-month follow-ups in patients with acute myocardial infarction. Health Inform. J. 2022, 28, 14604582221101529. [Google Scholar] [CrossRef]
- Feola, M.; Rossi, A.; Testa, M.; Ferreri, C.; Palazzuoli, A.; Pastorini, G.; Ruocco, G. Six-Month Predictive Value of Diuretic Resistance Formulas in Discharged Heart Failure Patients after an Acute Decompensation. J. Clin. Med. 2020, 9, 2932. [Google Scholar] [CrossRef]
- Frizzell, J.D.; Liang, L.; Schulte, P.J.; Yancy, C.W.; Heidenreich, P.A.; Hernandez, A.F.; Bhatt, D.L.; Fonarow, G.C.; Laskey, W.K. Prediction of 30-Day All-Cause Readmissions in Patients Hospitalized for Heart Failure: Comparison of Machine Learning and Other Statistical Approaches. JAMA Cardiol. 2017, 2, 204–209. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.M.; Zhao, P.; Yang, Y.H.; Wang, J.X.; Yan, H.; Chen, F.Y. Simulation study on missing data imputation methods for longitudinal data in cohort studies. Chin. J. Epidemiol. 2021, 42, 1889–1894. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Torgo, L. Data Mining with R, Learning with Case Studies, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2016; Available online: http://ltorgo.github.io/DMwR2 (accessed on 6 November 2022).
- Zhou, X.; Obuchowski, N.; McClish, D. Statstical Methods in Diagnostic Medicine, 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2011; pp. 103–191. [Google Scholar]
- Therneau, T.; Atkinson, B. rpart: Recursive Partitioning and Regression Trees. 2022; R Package Version 4.1.16. Available online: https://CRAN.R-project.org/package=rpart (accessed on 6 November 2022).
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. xgboost: Extreme Gradient Boosting. 2022; R Package Version 1.6.0.1. Available online: https://CRAN.R-project.org/package=xgboost (accessed on 6 November 2022).
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.-C.; Müller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef] [PubMed]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions ofthe Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien. 2022; R Package Version 1.7-11. Available online: https://CRAN.R-project.org/package=e1071 (accessed on 6 November 2022).
- Mahajan, S.; Burman, P.; Hogarth, M. Analyzing 30-Day Readmission Rate for Heart Failure Using Different Predictive Models. Stud. Health Technol. Inform. 2016, 225, 143–147. [Google Scholar] [PubMed]
- Global BMI Mortality Collaboration; Di Angelantonio, E.; Bhupathiraju, S.h.N.; Wormser, D.; Gao, P.; Kaptoge, S.; Berrington de Gonzalez, A.; Cairns, B.J.; Huxley, R.; Jackson, C.h.L.; et al. Body-mass index and all-cause mortality: Individual-participant-data meta-analysis of 239 prospective studies in four continents. Lancet 2016, 388, 776–786. [Google Scholar] [CrossRef] [Green Version]
- Benjamin, E.J.; Muntner, P.; Alonso, A.; Bittencourt, M.S.; Callaway, C.W.; Carson, A.P.; Chamberlain, A.M.; Chang, A.R.; Cheng, S.; Das, S.R.; et al. Heart Disease and Stroke Statistics-2019 Update: A Report from the American Heart Association. Circulation 2019, 139, e56–e528. [Google Scholar] [CrossRef] [PubMed]
- Yang, M.; Tao, L.; An, H.; Liu, G.; Tu, Q.; Zhang, H.; Qin, L.; Xiao, Z.; Wang, Y.; Fan, J.; et al. A novel nomogram to predict all-cause readmission or death risk in Chinese elderly patients with heart failure. ESC Heart Fail. 2020, 7, 1015–1024. [Google Scholar] [CrossRef] [Green Version]
- Huynh, Q.L.; Negishi, K.; Blizzard, L.; Sanderson, K.; Venn, A.J.; Marwick, T.H. Predictive Score for 30-Day Readmission or Death in Heart Failure. JAMA Cardiol. 2016, 1, 362–364. [Google Scholar] [CrossRef] [Green Version]
- McDowell, K.; Welsh, P.; Docherty, K.F.; Morrow, D.A.; Jhund, P.S.; de Boer, R.A.; O’Meara, E.; Inzucchi, S.E.; Køber, L.; Kosiborod, M.N.; et al. Dapagliflozin reduces uric acid concentration, an independent predictor of adverse outcomes in DAPA-HF. Eur. J. Heart Fail. 2022, 24, 1066–1076. [Google Scholar] [CrossRef]
- Huang, W.-M.; Hsu, P.-F.; Cheng, H.-M.; Lu, D.-Y.; Cheng, Y.-L.; Guo, C.-Y.; Sung, S.-H.; Yu, W.-C.; Chen, C.-H. Determinants and Prognostic Impact of Hyperuricemia in Hospitalization for Acute Heart Failure. Circ. J. 2016, 80, 404–410. [Google Scholar] [CrossRef] [Green Version]
- Yamamoto, H.; Nagatomo, Y.; Mahara, K.; Yoshikawa, T. In-Hospital Serum Uric Acid Change Predicts Adverse Outcome in Patients with Heart Failure. J. Card. Fail. 2020, 26, 968–976. [Google Scholar] [CrossRef] [PubMed]
- Davison, B.A.; Metra, M.; Senger, S.; Edwards, C.; Milo, O.; Bloomfield, D.M.; Cleland, J.G.; Dittrich, H.C.; Givertz, M.M.; O’Connor, C.M.; et al. Patient journey after admission for acute heart failure: Length of stay, 30-day readmission and 90-day mortality. Eur. J. Heart Fail. 2016, 18, 1041–1050. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Keeney, T.; Jette, D.U.; Cabral, H.; Jette, A.M. Frailty and Function in Heart Failure: Predictors of 30-Day Hospital Readmission? J. Geriatr. Phys. Ther. 2021, 44, 101–107. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Names | AUC (95%CI) | p-Value | Accuracy | Sensitivity (%) | Specificity (%) |
|---|---|---|---|---|---|
| LR | 0.634 (0.599–0.646) | p < 0.001 | 0.652 | 32.4 | 84.4 |
| CART | 0.594 (0.486–0.702) | p < 0.001 | 0.622 | 48.6 | 70.2 |
| XGBoost | 0.547 (0.387–0.707) | p = 0.019 | 0.589 | 38.7 | 70.7 |
| NB | 0.586 (0.554–0.617) | p < 0.001 | 0.577 | 61.7 | 55.4 |
| SVM | 0.562 (0.189–0.934) | p < 0.001 | 0.659 | 18.9 | 93.4 |
| RF | 0.575 (0.293–0.858) | p < 0.001 | 0.649 | 29.3 | 85.8 |
| Variables | Re-Admission within 6 Months (Training Cohort) | |||
|---|---|---|---|---|
| Non-Readmission (N = 850) | Re-Admission (N = 551) | Univariable OR(95% CI, p-Value) | Multivariable OR(95% CI, p-Value) | |
| Admission ward | ||||
| Cardiology | 658 (77.4%) | 446 (80.9%) | ||
| General Ward | 91 (10.7%) | 68 (12.3%) | 1.10 (0.79–1.54, p = 0.570) | 1.26 (0.88–1.80, p = 0.213) |
| ICU | 7 (0.8%) | 1 (0.2%) | 0.21 (0.03–1.72, p = 0.146) | 0.38 (0.05–3.19, p = 0.372) |
| Others | 94 (11.1%) | 36 (6.5%) | 0.57 (0.38–0.85, p = 0.005) | 0.62 (0.40–0.95, p = 0.026) |
| D dimer/(mg/L) | 1.31(0.84,2.27) | 1.17(0.81,2.00) | 0.91 (0.87–0.96, p < 0.001) | 0.90 (0.85–0.95, p < 0.001) |
| Discharge day | 7 (5,10) | 8 (6,11) | 1.02 (1.01–1.04, p = 0.002) | 1.02 (1.01–1.04, p = 0.005) |
| Uric acid (mmol/L) | 0.45 (0.36,0.56) | 0.47 (0.38,0.60) | 2.57 (1.36–4.85, p = 0.004) | 2.35 (1.18–4.70, p = 0.017) |
| Platelet hematocrit/% | 0.17(0.13,0.21) | 0.17 (0.13, 0.21) | 0.09 (0.02–0.51, p = 0.006) | 0.07 (0.01–0.44, p = 0.004) |
| Mean hemoglobin volume/(pg) | 30.5(28.6,31.8) | 30.4(28.5,31.9) | 1.05 (1.01–1.08, p = 0.006) | 1.04 (1.01–1.08, p = 0.015) |
| Basophil count/(×109/L) | 0.020(0.020,0.040) | 0.030 (0.020, 0.040) | 1020.57 (12.03,86551.15, p = 0.002) | 2127.57 (16.84–268814.95, p = 0.002) |
| NYHA cardiac function classification | ||||
| Class 2 | 172 (20.2%) | 72 (13.1%) | ||
| Class 3 | 443 (52.1%) | 286 (51.9%) | 1.54 (1.13–2.11, p = 0.007) | 1.46 (1.06–2.02, p = 0.022) |
| Class 4 | 235 (27.6%) | 193 (35%) | 1.96 (1.40–2.74, p < 0.001) | 1.88 (1.32–2.66, p < 0.001) |
| Type of heart failure | ||||
| Left or right | 258(30.4%) | 110 (20%) | ||
| Whole | 592 (69.6%) | 441 (80%) | 1.75 (1.35–2.25, p < 0.001) | 1.77 (1.36–2.31, p < 0.001) |
| Diabetes | ||||
| No | 676 (79.5%) | 392 (71.1%) | ||
| Yes | 174 (20.5%) | 159 (28.9%) | 1.58 (1.23–2.02, p < 0.001) | 1.57 (1.21–2.03, p < 0.001) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Hu, W.; Yang, Y.; Cai, J.; Luo, Y.; Gong, L.; Li, Y.; Si, A.; Zhang, Y.; Liu, S.; et al. Predicting Six-Month Re-Admission Risk in Heart Failure Patients Using Multiple Machine Learning Methods: A Study Based on the Chinese Heart Failure Population Database. J. Clin. Med. 2023, 12, 870. https://doi.org/10.3390/jcm12030870
Chen S, Hu W, Yang Y, Cai J, Luo Y, Gong L, Li Y, Si A, Zhang Y, Liu S, et al. Predicting Six-Month Re-Admission Risk in Heart Failure Patients Using Multiple Machine Learning Methods: A Study Based on the Chinese Heart Failure Population Database. Journal of Clinical Medicine. 2023; 12(3):870. https://doi.org/10.3390/jcm12030870
Chicago/Turabian StyleChen, Shiyu, Weiwei Hu, Yuhui Yang, Jiaxin Cai, Yaqi Luo, Lingmin Gong, Yemian Li, Aima Si, Yuxiang Zhang, Sitong Liu, and et al. 2023. "Predicting Six-Month Re-Admission Risk in Heart Failure Patients Using Multiple Machine Learning Methods: A Study Based on the Chinese Heart Failure Population Database" Journal of Clinical Medicine 12, no. 3: 870. https://doi.org/10.3390/jcm12030870