
Explainable Preoperative Automated Machine Learning Prediction Model for Cardiac Surgery-Associated Acute Kidney Injury
 , , ,
, , ,  ,
,  ,
,  ,
, 
Abstract
:1. Introduction
2. Methods
2.1. Patient Population
2.2. Data Collection
2.3. Feature Selection
2.4. Model Development
2.5. Model Evaluation and Calibration
2.6. Explanations of the Variables in the autoML-Based Prediction Model That Drive Patient-Specific Predictions of CSA-AKI
2.7. Statistical Analysis
3. Results
3.1. Clinical Characteristics
3.2. AutoML Prediction Models for CSA-AKI
3.3. Traditional Logistic Regression Prediction Model for CSA-AKI
3.4. Model Comparison among the Different Models
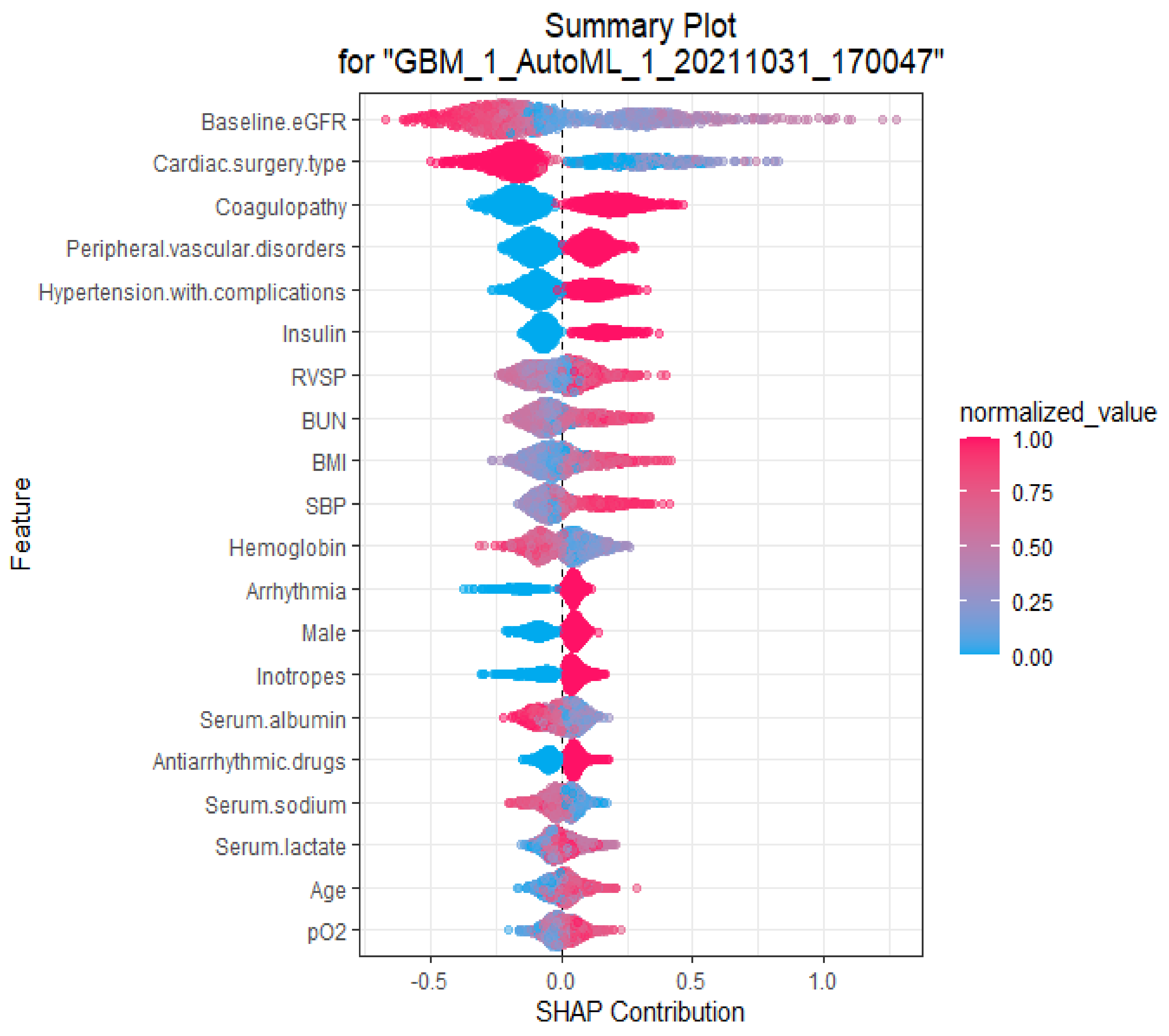
3.5. Explanations of the Variables in the autoML-Based Prediction Model That Drive Patient-Specific Predictions of CSA-AKI
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Robert, A.M.; Kramer, R.S.; Dacey, L.J.; Charlesworth, D.C.; Leavitt, B.J.; Helm, R.E.; Hernandez, F.; Sardella, G.L.; Frumiento, C.; Likosky, D.S.; et al. Cardiac surgery-associated acute kidney injury: A comparison of two consensus criteria. Ann. Thorac. Surg. 2010, 90, 1939–1943. [Google Scholar] [CrossRef]
- Thiele, R.H.; Isbell, J.M.; Rosner, M.H. AKI associated with cardiac surgery. Clin. J. Am. Soc. Nephrol. 2015, 10, 500–514. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hobson, C.E.; Yavas, S.; Segal, M.S.; Schold, J.D.; Tribble, C.G.; Layon, A.J.; Bihorac, A. Acute kidney injury is associated with increased long-term mortality after cardiothoracic surgery. Circulation 2009, 119, 2444–2453. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lau, D.; Pannu, N.; James, M.T.; Hemmelgarn, B.R.; Kieser, T.M.; Meyer, S.R.; Klarenbach, S. Costs and consequences of acute kidney injury after cardiac surgery: A cohort study. J. Thorac. Cardiovasc. Surg. 2021, 162, 880–887. [Google Scholar] [CrossRef] [PubMed]
- Ortega-Loubon, C.; Fernández-Molina, M.; Carrascal-Hinojal, Y.; Fulquet-Carreras, E. Cardiac surgery-associated acute kidney injury. Ann. Card. Anaesth. 2016, 19, 687–698. [Google Scholar] [CrossRef]
- Hobson, C.; Ozrazgat-Baslanti, T.; Kuxhausen, A.; Thottakkara, P.; Efron, P.A.; Moore, F.A.; Moldawer, L.L.; Segal, M.S.; Bihorac, A. Cost and Mortality Associated with Postoperative Acute Kidney Injury. Ann. Surg. 2015, 261, 1207–1214. [Google Scholar] [CrossRef]
- Chertow, G.M.; Levy, E.M.; Hammermeister, K.E.; Grover, F.; Daley, J. Independent association between acute renal failure and mortality following cardiac surgery. Am. J. Med. 1998, 104, 343–348. [Google Scholar] [CrossRef]
- Wong, B.; St Onge, J.; Korkola, S.; Prasad, B. Validating a scoring tool to predict acute kidney injury (AKI) following cardiac surgery. Can. J. Kidney Health Dis. 2015, 2, 3. [Google Scholar] [CrossRef] [Green Version]
- Palomba, H.; de Castro, I.; Neto, A.L.; Lage, S.; Yu, L. Acute kidney injury prediction following elective cardiac surgery: AKICS Score. Kidney Int. 2007, 72, 624–631. [Google Scholar] [CrossRef] [Green Version]
- Thakar, C.V.; Arrigain, S.; Worley, S.; Yared, J.P.; Paganini, E.P. A clinical score to predict acute renal failure after cardiac surgery. J. Am. Soc. Nephrol. 2005, 16, 162–168. [Google Scholar] [CrossRef]
- Mehta, R.H.; Grab, J.D.; O’Brien, S.M.; Bridges, C.R.; Gammie, J.S.; Haan, C.K.; Ferguson, T.B.; Peterson, E.D. Bedside tool for predicting the risk of postoperative dialysis in patients undergoing cardiac surgery. Circulation 2006, 114, 2208–2216. [Google Scholar] [CrossRef] [PubMed]
- Wijeysundera, D.N.; Karkouti, K.; Dupuis, J.Y.; Rao, V.; Chan, C.T.; Granton, J.T.; Beattie, W.S. Derivation and validation of a simplified predictive index for renal replacement therapy after cardiac surgery. JAMA 2007, 297, 1801–1809. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aronson, S.; Fontes, M.L.; Miao, Y.; Mangano, D.T. Risk index for perioperative renal dysfunction/failure: Critical dependence on pulse pressure hypertension. Circulation 2007, 115, 733–742. [Google Scholar] [CrossRef] [Green Version]
- Brown, J.R.; Cochran, R.P.; Leavitt, B.J.; Dacey, L.J.; Ross, C.S.; MacKenzie, T.A.; Kunzelman, K.S.; Kramer, R.S.; Hernandez, F., Jr.; Helm, R.E.; et al. Multivariable prediction of renal insufficiency developing after cardiac surgery. Circulation 2007, 116, I139–I143. [Google Scholar] [CrossRef] [Green Version]
- Fortescue, E.B.; Bates, D.W.; Chertow, G.M. Predicting acute renal failure after coronary bypass surgery: Cross-validation of two risk-stratification algorithms. Kidney Int. 2000, 57, 2594–2602. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahmanian, P.B.; Kwiecien, G.; Langebartels, G.; Madershahian, N.; Wittwer, T.; Wahlers, T. Logistic risk model predicting postoperative renal failure requiring dialysis in cardiac surgery patients. Eur. J. Cardiothorac. Surg. 2011, 40, 701–707. [Google Scholar] [CrossRef] [PubMed]
- Jiang, W.; Xu, J.; Shen, B.; Wang, C.; Teng, J.; Ding, X. Validation of Four Prediction Scores for Cardiac Surgery-Associated Acute Kidney Injury in Chinese Patients. Braz. J. Cardiovasc. Surg. 2017, 32, 481–486. [Google Scholar] [CrossRef] [Green Version]
- Kim, W.H.; Lee, J.H.; Kim, E.; Kim, G.; Kim, H.J.; Lim, H.W. Can We Really Predict Postoperative Acute Kidney Injury after Aortic Surgery? Diagnostic Accuracy of Risk Scores Using Gray Zone Approach. Thorac. Cardiovasc. Surg. 2016, 64, 281–289. [Google Scholar] [CrossRef]
- Cho, J.S.; Shim, J.K.; Lee, S.; Song, J.W.; Choi, N.; Lee, S.; Kwak, Y.L. Chronic progression of cardiac surgery associated acute kidney injury: Intermediary role of acute kidney disease. J. Thorac. Cardiovasc. Surg. 2021, 161, 681–688.e3. [Google Scholar] [CrossRef]
- Thongprayoon, C.; Cheungpasitporn, W.; Shah, I.K.; Kashyap, R.; Park, S.J.; Kashani, K.; Dillon, J.J. Long-term Outcomes and Prognostic Factors for Patients Requiring Renal Replacement Therapy After Cardiac Surgery. Mayo Clin. Proc. 2015, 90, 857–864. [Google Scholar] [CrossRef]
- Fröhlich, H.; Balling, R.; Beerenwinkel, N.; Kohlbacher, O.; Kumar, S.; Lengauer, T.; Maathuis, M.H.; Moreau, Y.; Murphy, S.A.; Przytycka, T.M.; et al. From hype to reality: Data science enabling personalized medicine. BMC Med. 2018, 16, 150. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thongprayoon, C.; Mao, S.A.; Jadlowiec, C.C.; Mao, M.A.; Leeaphorn, N.; Kaewput, W.; Vaitla, P.; Pattharanitima, P.; Tangpanithandee, S.; Krisanapan, P.; et al. Machine Learning Consensus Clustering of Morbidly Obese Kidney Transplant Recipients in the United States. J. Clin. Med. 2022, 11, 3288. [Google Scholar] [CrossRef] [PubMed]
- Thongprayoon, C.; Vaitla, P.; Jadlowiec, C.C.; Leeaphorn, N.; Mao, S.A.; Mao, M.A.; Pattharanitima, P.; Bruminhent, J.; Khoury, N.J.; Garovic, V.D.; et al. Use of Machine Learning Consensus Clustering to Identify Distinct Subtypes of Black Kidney Transplant Recipients and Associated Outcomes. JAMA Surg. 2022, 157, e221286. [Google Scholar] [CrossRef] [PubMed]
- Pattharanitima, P.; Thongprayoon, C.; Kaewput, W.; Qureshi, F.; Qureshi, F.; Petnak, T.; Srivali, N.; Gembillo, G.; O’Corragain, O.A.; Chesdachai, S.; et al. Machine Learning Prediction Models for Mortality in Intensive Care Unit Patients with Lactic Acidosis. J. Clin. Med. 2021, 10, 5021. [Google Scholar] [CrossRef]
- Thongprayoon, C.; Dumancas, C.Y.; Nissaisorakarn, V.; Keddis, M.T.; Kattah, A.G.; Pattharanitima, P.; Petnak, T.; Vallabhajosyula, S.; Garovic, V.D.; Mao, M.A.; et al. Machine Learning Consensus Clustering Approach for Hospitalized Patients with Phosphate Derangements. J. Clin. Med. 2021, 10, 4441. [Google Scholar] [CrossRef]
- Thongprayoon, C.; Kaewput, W.; Kovvuru, K.; Hansrivijit, P.; Kanduri, S.R.; Bathini, T.; Chewcharat, A.; Leeaphorn, N.; Gonzalez-Suarez, M.L.; Cheungpasitporn, W. Promises of Big Data and Artificial Intelligence in Nephrology and Transplantation. J. Clin. Med. 2020, 9, 1107. [Google Scholar] [CrossRef] [Green Version]
- Yun, D.; Cho, S.; Kim, Y.C.; Kim, D.K.; Oh, K.H.; Joo, K.W.; Kim, Y.S.; Han, S.S. Use of Deep Learning to Predict Acute Kidney Injury After Intravenous Contrast Media Administration: Prediction Model Development Study. JMIR Med. Inform. 2021, 9, e27177. [Google Scholar] [CrossRef]
- Scanlon, L.A.; O’Hara, C.; Garbett, A.; Barker-Hewitt, M.; Barriuso, J. Developing an Agnostic Risk Prediction Model for Early AKI Detection in Cancer Patients. Cancers 2021, 13, 4182. [Google Scholar] [CrossRef]
- Mistry, N.S.; Koyner, J.L. Artificial Intelligence in Acute Kidney Injury: From Static to Dynamic Models. Adv. Chronic. Kidney Dis. 2021, 28, 74–82. [Google Scholar] [CrossRef]
- Dong, J.; Feng, T.; Thapa-Chhetry, B.; Cho, B.G.; Shum, T.; Inwald, D.P.; Newth, C.J.L.; Vaidya, V.U. Machine learning model for early prediction of acute kidney injury (AKI) in pediatric critical care. Crit. Care 2021, 25, 288. [Google Scholar] [CrossRef]
- Lee, Y.; Ryu, J.; Kang, M.W.; Seo, K.H.; Kim, J.; Suh, J.; Kim, Y.C.; Kim, D.K.; Oh, K.H.; Joo, K.W.; et al. Machine learning-based prediction of acute kidney injury after nephrectomy in patients with renal cell carcinoma. Sci. Rep. 2021, 11, 15704. [Google Scholar] [CrossRef] [PubMed]
- Penny-Dimri, J.C.; Bergmeir, C.; Reid, C.M.; Williams-Spence, J.; Cochrane, A.D.; Smith, J.A. Machine Learning Algorithms for Predicting and Risk Profiling of Cardiac Surgery-Associated Acute Kidney Injury. Semin. Thorac. Cardiovasc. Surg. 2021, 33, 735–745. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.C.; Yoon, H.K.; Nam, K.; Cho, Y.J.; Kim, T.K.; Kim, W.H.; Bahk, J.H. Derivation and Validation of Machine Learning Approaches to Predict Acute Kidney Injury after Cardiac Surgery. J. Clin. Med. 2018, 7, 322. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thongprayoon, C.; Kaewput, W.; Choudhury, A.; Hansrivijit, P.; Mao, M.A.; Cheungpasitporn, W. Is It Time for Machine Learning Algorithms to Predict the Risk of Kidney Failure in Patients with Chronic Kidney Disease? J. Clin. Med. 2021, 10, 1121. [Google Scholar] [CrossRef] [PubMed]
- Thongprayoon, C.; Hansrivijit, P.; Bathini, T.; Vallabhajosyula, S.; Mekraksakit, P.; Kaewput, W.; Cheungpasitporn, W. Predicting Acute Kidney Injury after Cardiac Surgery by Machine Learning Approaches. J. Clin. Med. 2020, 9, 1767. [Google Scholar] [CrossRef]
- Raita, Y.; Goto, T.; Faridi, M.K.; Brown, D.F.M.; Camargo, C.A., Jr.; Hasegawa, K. Emergency department triage prediction of clinical outcomes using machine learning models. Crit. Care 2019, 23, 64. [Google Scholar] [CrossRef] [Green Version]
- Manz, C.R.; Chen, J.; Liu, M.; Chivers, C.; Regli, S.H.; Braun, J.; Draugelis, M.; Hanson, C.W.; Shulman, L.N.; Schuchter, L.M.; et al. Validation of a Machine Learning Algorithm to Predict 180-Day Mortality for Outpatients with Cancer. JAMA Oncol. 2020, 6, 1723–1730. [Google Scholar] [CrossRef]
- Johnson, A.E.; Ghassemi, M.M.; Nemati, S.; Niehaus, K.E.; Clifton, D.A.; Clifford, G.D. Machine Learning and Decision Support in Critical Care. Proc. IEEE Inst. Electr. Electron. Eng. 2016, 104, 444–466. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, A.B.; Thorsen-Meyer, H.-C.; Belling, K.; Nielsen, A.P.; Thomas, C.E.; Chmura, P.J.; Lademann, M.; Moseley, P.L.; Heimann, M.; Dybdahl, L. Survival prediction in intensive-care units based on aggregation of long-term disease history and acute physiology: A retrospective study of the Danish National Patient Registry and electronic patient records. Lancet Digit. Health 2019, 1, e78–e89. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, L.; Pilastri, A.; Martins, C.; Santos, P.; Cortez, P. A Scalable and Automated Machine Learning Framework to Support Risk Management. In Proceedings of the International Conference on Agents and Artificial Intelligence, Valletta, Malta, 22–24 February 2020; pp. 291–307. [Google Scholar]
- Celik, B.; Vanschoren, J. Adaptation Strategies for Automated Machine Learning on Evolving Data. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3067–3078. [Google Scholar] [CrossRef]
- Escalante, H.J. Automated Machine Learning—A Brief Review at the End of the Early Years. In Automated Design of Machine Learning and Search Algorithms; Springer: Cham, Switzerland, 2021; pp. 11–28. [Google Scholar]
- Lee, Y.S. Analysis on Trends of Automated Machine Learning. Int. J. New Innov. Eng. Technol. 2018, 9, 32–35. [Google Scholar]
- Waring, J.; Lindvall, C.; Umeton, R. Automated machine learning: Review of the state-of-the-art and opportunities for healthcare. Artif. Intell. Med. 2020, 104, 101822. [Google Scholar] [CrossRef] [PubMed]
- Kellum, J.A.; Lameire, N.; Aspelin, P.; Barsoum, R.S.; Burdmann, E.A.; Goldstein, S.L.; Herzog, C.A.; Joannidis, M.; Kribben, A.; Levey, A.S. Kidney disease: Improving global outcomes (KDIGO) acute kidney injury work group. KDIGO clinical practice guideline for acute kidney injury. Kidney Int. Suppl. 2012, 2, 1–138. [Google Scholar]
- Collins, G.S.; Reitsma, J.B.; Altman, D.G.; Moons, K.G. Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD): The TRIPOD Statement. Br. J. Surg. 2015, 102, 148–158. [Google Scholar] [CrossRef] [Green Version]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Truong, A.; Walters, A.; Goodsitt, J.; Hines, K.; Bruss, C.B.; Farivar, R. Towards automated machine learning: Evaluation and comparison of AutoML approaches and tools. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1471–1479. [Google Scholar]
- LeDell, E.; Poirier, S. H2o automl: Scalable automatic machine learning. In Proceedings of the AutoML Workshop at ICML, Virtual, 18 July 2020. [Google Scholar]
- Muchlinski, D.; Siroky, D.; He, J.; Kocher, M. Comparing random forest with logistic regression for predicting class-imbalanced civil war onset data. Political Anal. 2016, 24, 87–103. [Google Scholar] [CrossRef]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–14 December 2011; Volume 24. [Google Scholar]
- McGee, S. Simplifying likelihood ratios. J. Gen. Intern. Med. 2002, 17, 647–650. [Google Scholar] [CrossRef] [Green Version]
- Zou, K.H.; O’Malley, A.J.; Mauri, L. Receiver-operating characteristic analysis for evaluating diagnostic tests and predictive models. Circulation 2007, 115, 654–657. [Google Scholar] [CrossRef] [Green Version]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [Green Version]
- DeLong, E.R.; DeLong, D.M.; Clarke-Pearson, D.L. Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef]
- Huang, Y.; Li, W.; Macheret, F.; Gabriel, R.A.; Ohno-Machado, L. A tutorial on calibration measurements and calibration models for clinical prediction models. J. Am. Med. Inform. Assoc. 2020, 27, 621–633. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you? In ” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-agnostic interpretability of machine learning. arXiv 2016, arXiv:1606.05386. [Google Scholar]
- Stekhoven, D.J.; Bühlmann, P. MissForest—Non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef]
- Tseng, P.Y.; Chen, Y.T.; Wang, C.H.; Chiu, K.M.; Peng, Y.S.; Hsu, S.P.; Chen, K.L.; Yang, C.Y.; Lee, O.K. Prediction of the development of acute kidney injury following cardiac surgery by machine learning. Crit. Care 2020, 24, 478. [Google Scholar] [CrossRef]
- Li, Y.; Xu, J.; Wang, Y.; Zhang, Y.; Jiang, W.; Shen, B.; Ding, X. A novel machine learning algorithm, Bayesian networks model, to predict the high-risk patients with cardiac surgery-associated acute kidney injury. Clin. Cardiol. 2020, 43, 752–761. [Google Scholar] [CrossRef]
- Hickey, G.L.; Grant, S.W.; Bridgewater, B. Validation of the EuroSCORE II: Should we be concerned with retrospective performance? Eur. J. Cardiothorac. Surg. 2013, 43, 655. [Google Scholar] [CrossRef] [Green Version]
- Mikkelsen, M.M.; Johnsen, S.P.; Nielsen, P.H.; Jakobsen, C.J. The EuroSCORE in western Denmark: A population-based study. J. Cardiothorac. Vasc. Anesth. 2012, 26, 258–264. [Google Scholar] [CrossRef]
- Lipton, Z.C. The mythos of model interpretability. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Abdul, A.; Vermeulen, J.; Wang, D.; Lim, B.Y.; Kankanhalli, M. Trends and trajectories for explainable, accountable and intelligible systems: An hci research agenda. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–18. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | All | Training | Validation | Testing | p-Value |
|---|---|---|---|---|---|
| (n = 13,158) | (n = 9244) | (n = 1967) | (n = 1947) | ||
| Age (years) | 65 ± 15 | 65 ± 15 | 65 ± 15 | 65 ± 15 | 0.67 |
| Male sex | 8642 (66) | 6066 (66) | 1335 (68) | 1241 (64) | 0.02 |
| Race | 0.49 | ||||
| White | 12,460 (95) | 8753 (95) | 1857 (94) | 1850 (95) | |
| Black | 164 (1) | 112 (1) | 23 (1) | 29 (2) | |
| Asian | 213 (2) | 155 (2) | 29 (2) | 29 (1) | |
| Other | 321 (2) | 224 (2) | 58 (3) | 39 (2) | |
| Body mass index (kg/m2) | 29.7 ± 6.5 | 29.7 ± 6.5 | 29.6 ± 6.3 | 29.9 ± 6.8 | 0.31 |
| Admission type | 0.72 | ||||
| Elective | 11,020 (84) | 7728 (83) | 1659 (84) | 1633 (84) | |
| Urgent | 1396 (11) | 988 (11) | 195 (10) | 213 (11) | |
| Emergent | 742 (5) | 528 (6) | 113 (6) | 101 (5) | |
| Cardiac surgery type | 0.11 | ||||
| CABG | 2308 (18) | 1592 (17) | 357 (18) | 359 (18) | |
| Valve surgery | 7920 (60) | 5575 (60) | 1145 (58) | 1200 (62) | |
| CABG + valve surgery | 2503 (19) | 1765 (19) | 408 (21) | 330 (17) | |
| Heart transplant | 109 (1) | 79 (1) | 16 (1) | 14 (1) | |
| Pericardiectomy | 318 (2) | 233 (3) | 41 (2) | 44 (2) | |
| Comorbidity | |||||
| Congestive heart failure | 9658 (73) | 6804 (74) | 1429 (73) | 1425 (73) | 0.67 |
| Arrhythmia | 10,370 (79) | 7279 (79) | 1535 (78) | 1556 (80) | 0.34 |
| Valvular disease | 11,144 (85) | 7854 (85) | 1649 (84) | 1641 (84) | 0.39 |
| Peripheral vascular disease | 6281 (48) | 4456 (48) | 903 (46) | 922 (47) | 0.17 |
| Hypertension; uncomplicated | 2643 (20) | 1857 (20) | 418 (21) | 368 (19) | 0.19 |
| Hypertension; complicated | 5334 (40) | 3806 (41) | 740 (38) | 788 (40) | 0.01 |
| Paralysis | 182 (1) | 130 (1) | 24 (1) | 28 (1) | 0.79 |
| Neurological disorders | 390 (3) | 281 (3) | 65 (3) | 44 (2) | 0.11 |
| COPD | 3049 (23) | 2139 (23) | 443 (22) | 467 (24) | 0.55 |
| Diabetes; no complications | 2573 (20) | 1807 (19) | 392 (20) | 374 (19) | 0.85 |
| Diabetes; complications | 2011 (15) | 1412 (15) | 292 (15) | 307 (16) | 0.72 |
| Hypothyroidism | 2025 (15) | 1417 (15) | 294 (15) | 314 (16) | 0.57 |
| Liver disease | 663 (5) | 482 (5) | 87 (4) | 94 (5) | 0.31 |
| Peptic ulcer disease | 77 (1) | 51 (1) | 15 (1) | 11 (1) | 0.53 |
| Lymphoma | 132 (1) | 89 (1) | 19 (1) | 24 (1) | 0.55 |
| Solid cancer | 285 (2) | 202 (2) | 43 (2) | 40 (2) | 0.93 |
| Connective tissue disease | 639 (5) | 448 (5) | 78 (4) | 113 (6) | 0.03 |
| Coagulopathy | 5651 (43) | 4035 (44) | 849 (43) | 767 (39) | 0.003 |
| Obesity | 3713 (28) | 2585 (28) | 559 (28) | 569 (29) | 0.52 |
| Weight loss | 263 (2) | 167 (2) | 50 (2) | 46 (2) | 0.04 |
| Blood loss anemia | 152 (1) | 112 (1) | 20 (1) | 20 (1) | 0.65 |
| Anemia | 600 (5) | 415 (4) | 95 (5) | 90 (5) | 0.8 |
| Drug abuse | 200 (1) | 146 (2) | 26 (1) | 28 (1) | 0.66 |
| Psychosis | 57 (0) | 39 (0) | 12 (1) | 6 (0) | 0.34 |
| Depression | 1683 (13) | 1175 (13) | 258 (13) | 250 (13) | 0.88 |
| Echo finding | |||||
| LVEF | 57.8 ± 9.4 | 57.8 ± 9.5 | 57.8 ± 9.5 | 57.9 ± 9.3 | 0.85 |
| RVSP | 38.5 ± 10.9 | 38.5 ± 11.0 | 38.3 ± 10.9 | 38.4 ± 10.7 | 0.54 |
| Systolic blood pressure (mmHg) | 130.4 ± 17.4 | 130.3 ± 17.6 | 130.0 ± 16.9 | 130.9 ± 17.3 | 0.14 |
| Diastolic blood pressure (mmHg) | 72.8 ± 11.8 | 72.8 ± 11.8 | 72.9 ± 11.7 | 72.8 ± 11.7 | 0.9 |
| IABP use | 242 (2) | 173 (2) | 33 (2) | 36 (2) | 0.84 |
| Medications | |||||
| Aspirin | 2257 (17) | 1565 (17) | 351 (18) | 341 (17) | 0.56 |
| Beta-blockers | 2739 (21) | 1914 (21) | 436 (22) | 389 (20) | 0.22 |
| Digoxin | 180 (1) | 123 (1) | 27 (1) | 30 (1) | 0.77 |
| Anti-anginal medications | 1666 (13) | 1163 (13) | 254 (13) | 249 (13) | 0.91 |
| Anti-arrhythmic medications | 7296 (55) | 5154 (56) | 1075 (55) | 1067 (55) | 0.55 |
| Statins | 1843 (14) | 1282 (14) | 293 (15) | 268 (14) | 0.46 |
| ACEIs | 695 (5) | 499 (5) | 117 (6) | 79 (4) | 0.02 |
| ARBs | 300 (2) | 212 (2) | 44 (2) | 44 (2) | 0.99 |
| NSAIDs | 868 (7) | 626 (7) | 114 (6) | 128 (7) | 0.28 |
| Benzodiazepine | 7990 (61) | 5658 (61) | 1172 (60) | 1160 (60) | 0.22 |
| Vancomycin | 11 (0) | 8 (0) | 2 (0) | 1 (0) | 0.85 |
| Contrast | 730 (5) | 518 (6) | 113 (6) | 99 (5) | 0.61 |
| Diuretics | 1569 (12) | 1105 (12) | 230 (12) | 234 (12) | 0.94 |
| Calcium channel blockers | 886 (7) | 620 (7) | 136 (7) | 130 (7) | 0.94 |
| Vasopressors/inotropes | 9232 (70) | 6488 (70) | 1401 (71) | 1343 (69) | 0.31 |
| Insulin | 3899 (30) | 2756 (30) | 580 (29) | 563 (29) | 0.21 |
| Laboratory data | |||||
| Sodium (mEq/L) | 137.6 ± 3.7 | 137.6 ± 3.7 | 137.4 ± 3.7 | 137.7 ± 3.7 | 0.04 |
| Potassium (mEq/L) | 4.2 ± 0.6 | 4.3 ± 0.6 | 4.3 ± 0.6 | 4.3 ± 0.6 | 0.96 |
| Chloride (mEq/L) | 101.7 ± 3.0 | 101.7 ± 3.0 | 101.7 ± 3.0 | 101.9 ± 3.0 | 0.18 |
| Bicarbonate (mEq/L) | 25.3 ± 2.5 | 25.3 ± 2.5 | 25.3 ± 2.4 | 25.2 ± 2.5 | 0.5 |
| BUN (mg/dL) | 20.2 ± 10.0 | 20.2 ± 10.0 | 19.8 ± 9.3 | 20.5 ± 10.6 | 0.09 |
| Ionized calcium (mmol/L) | 4.4 ± 0.4 | 4.4 ± 0.4 | 4.4 ± 0.4 | 4.4 ± 0.4 | 0.96 |
| Glucose (mg/dL) | 117.8 ± 32.5 | 117.5 ± 32.4 | 118.6 ± 33.1 | 118.3 ± 32.5 | 0.32 |
| Albumin (g/dL) | 4.1 ± 0.3 | 4.1 ± 0.4 | 4.1 ± 0.4 | 4.1 ± 0.4 | 0.82 |
| pH | 7.4 ± 0.1 | 7.4 ± 0.1 | 7.4 ± 0.1 | 7.4 ± 0.1 | 0.84 |
| pO2 (mmHg) | 275.2 ± 98.4 | 275.2 ± 98.2 | 274.3 ± 98.2 | 276.4 ± 99.4 | 0.8 |
| hemoglobin (g/dL) | 11.5 ± 2.0 | 11.5 ± 2.0 | 11.5 ± 2.0 | 11.5 ± 2.0 | 0.9 |
| WBC (109 cells/L) | 7.1 ± 3.4 | 7.1 ± 3.4 | 7.1 ± 2.7 | 7.2 ± 3.7 | 0.34 |
| Platelet (109 cells/L) | 214.0 ± 70.2 | 213.7 ± 70.7 | 212.5 ± 68.1 | 216.6 ± 70.1 | 0.16 |
| INR | 1.2 ± 0.3 | 1.2 ± 0.3 | 1.2 ± 0.3 | 1.2 ± 0.3 | 0.43 |
| Lactate (mmol/L) | 1.2 ± 0.6 | 1.2 ± 0.6 | 1.2 ± 0.6 | 1.2 ± 0.7 | 0.9 |
| eGFR (mL/min/1.73 m2) | 69.2 ± 21.2 | 69.1 ± 21.3 | 69.8 ± 20.8 | 68.7 ± 21.2 | 0.24 |
| positive blood culture | 59 (0) | 46 (0) | 9 (0) | 4 (0) | 0.21 |
| Outcome | |||||
| Acute Kidney Injury | 4745 (36) | 3342 (36) | 716 (36) | 687 (35) | 0.73 |
| Rank | Model ID | AUROC | Log loss |
|---|---|---|---|
| 1 | StackedEnsemble_AllModels_3_AutoML_1_20211031_170047 | 0.777477459373283 | 0.546459347839992 |
| 2 | StackedEnsemble_AllModels_2_AutoML_1_20211031_170047 | 0.773762554202448 | 0.541472780910445 |
| 3 | StackedEnsemble_AllModels_1_AutoML_1_20211031_170047 | 0.773350035055754 | 0.541923951699646 |
| 4 | StackedEnsemble_BestOfFamily_1_AutoML_1_20211031_170047 | 0.773241741802089 | 0.541880114043628 |
| 5 | StackedEnsemble_BestOfFamily_3_AutoML_1_20211031_170047 | 0.772737675781163 | 0.543015006080206 |
| 6 | StackedEnsemble_BestOfFamily_2_AutoML_1_20211031_170047 | 0.772442939503146 | 0.542787093883418 |
| 7 | GBM_1_AutoML_1_20211031_170047 | 0.771870771539193 | 0.545029939918007 |
| 8 | GBM_grid_1_AutoML_1_20211031_170047_model_2 | 0.77171223914723 | 0.544501614697186 |
| 9 | GBM_grid_1_AutoML_1_20211031_170047_model_11 | 0.770116309187287 | 0.546966245682808 |
| 10 | GBM_grid_1_AutoML_1_20211031_170047_model_16 | 0.769074126173921 | 0.545687661410384 |
| 11 | GBM_grid_1_AutoML_1_20211031_170047_model_6 | 0.768387524617178 | 0.546875946078973 |
| 12 | GBM_5_AutoML_1_20211031_170047 | 0.767743347221664 | 0.547846265522666 |
| 13 | GBM_grid_1_AutoML_1_20211031_170047_model_14 | 0.765551804366563 | 0.55048346881313 |
| 14 | GBM_grid_1_AutoML_1_20211031_170047_model_7 | 0.764637452049534 | 0.551072950563168 |
| 15 | GBM_3_AutoML_1_20211031_170047 | 0.763708027991015 | 0.549131275569399 |
| 16 | GBM_grid_1_AutoML_1_20211031_170047_model_1 | 0.763258108596921 | 0.549864223764978 |
| 17 | GBM_2_AutoML_1_20211031_170047 | 0.761695113183196 | 0.553063273816373 |
| 18 | GBM_grid_1_AutoML_1_20211031_170047_model_10 | 0.75964423991533 | 0.553470882528734 |
| 19 | GBM_grid_1_AutoML_1_20211031_170047_model_9 | 0.759394718861782 | 0.554178650562614 |
| 20 | GBM_grid_1_AutoML_1_20211031_170047_model_12 | 0.757099906666845 | 0.555638148301273 |
| Model | Error Rate of Test Data Set | Accuracy | Precision | MCC | F1 Score | AUROC in the Test Set | Brier Score |
|---|---|---|---|---|---|---|---|
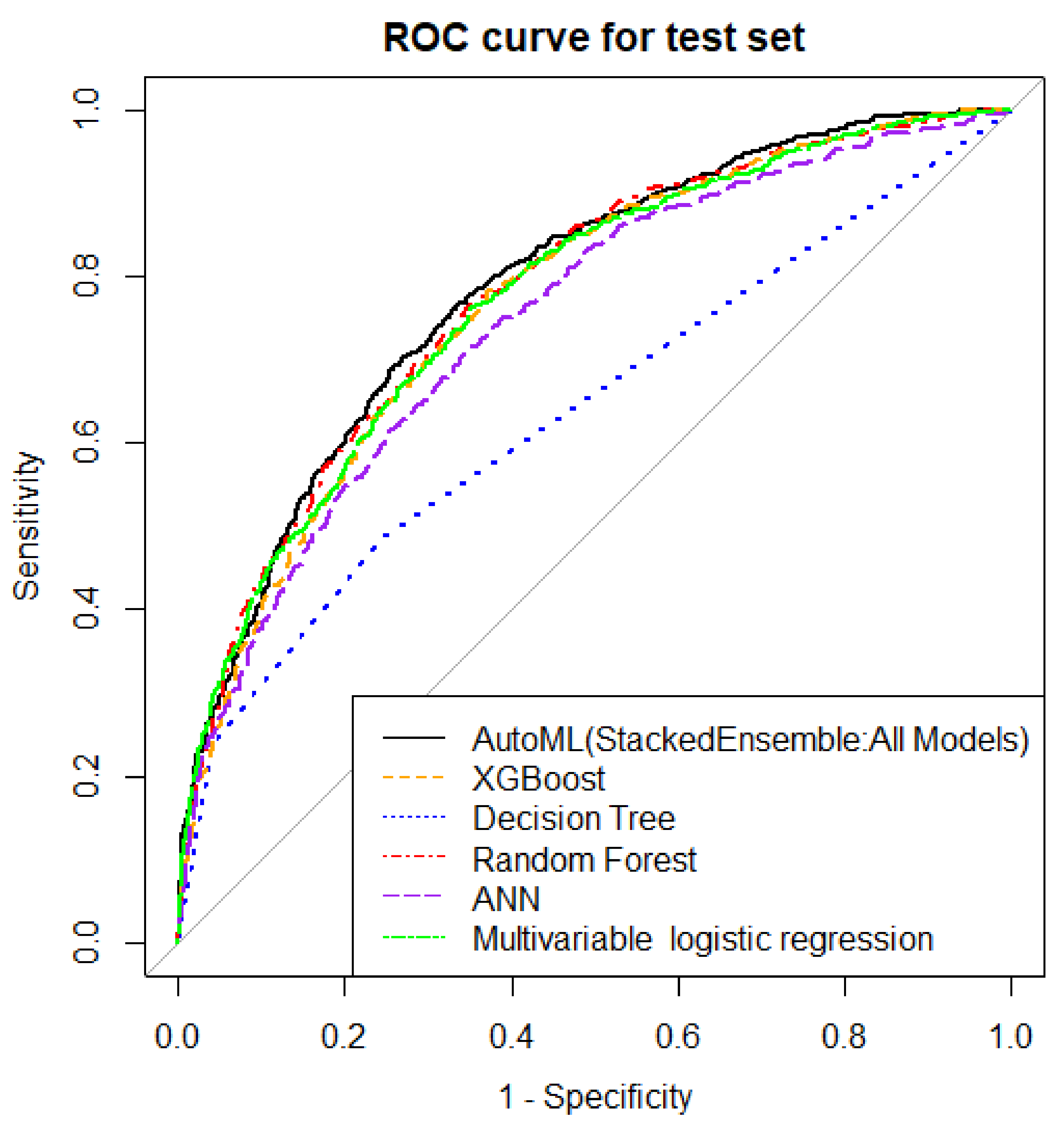
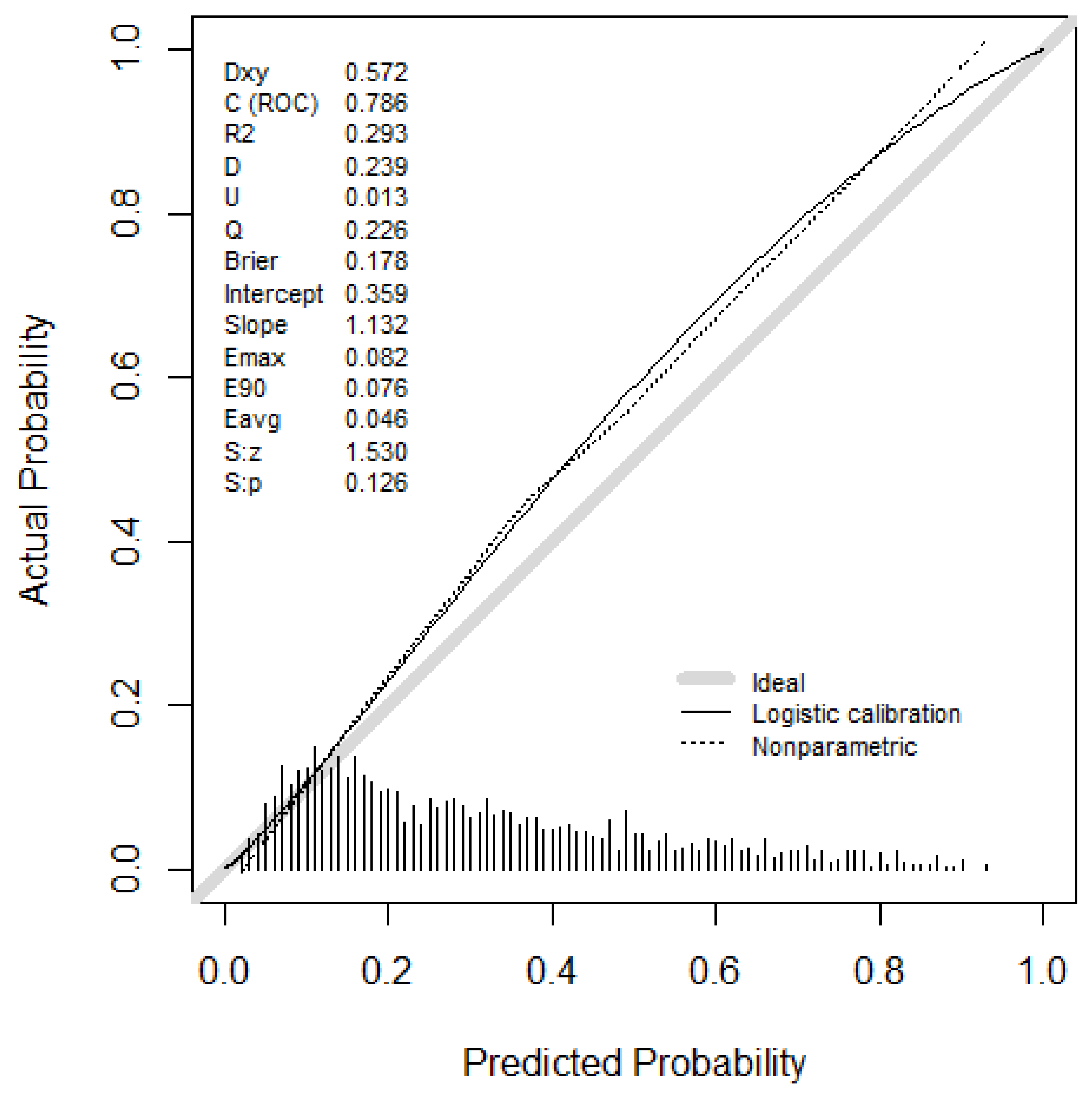
| AutoML (StackedEnsemble_AllModels_3_AutoML_1_20211031_170047) | 27.6% | 0.72 | 0.71 | 0.35 | 0.49 | 0.79 (0.77–0.81) | 0.18 |
| Random forest model | 26.4% | 0.74 | 0.71 | 0.39 | 0.54 | 0.78 (0.76–0.80) | 0.18 |
| Decision tree | 29.6% | 0.70 | 0.75 | 0.30 | 0.36 | 0.64 (0.62–0.66) | 0.21 |
| XGBoost | 27.8% | 0.72 | 0.65 | 0.36 | 0.53 | 0.77 (0.75–0.79) | 0.19 |
| ANN | 29.1% | 0.71 | 0.78 | 0.32 | 0.37 | 0.75 (0.72–0.77) | 0.19 |
| Multivariable logistic regression | 27.0% | 0.73 | 0.67 | 0.38 | 0.54 | 0.77 (0.75–0.79) | 0.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thongprayoon, C.; Pattharanitima, P.; Kattah, A.G.; Mao, M.A.; Keddis, M.T.; Dillon, J.J.; Kaewput, W.; Tangpanithandee, S.; Krisanapan, P.; Qureshi, F.; et al. Explainable Preoperative Automated Machine Learning Prediction Model for Cardiac Surgery-Associated Acute Kidney Injury. J. Clin. Med. 2022, 11, 6264. https://doi.org/10.3390/jcm11216264
Thongprayoon C, Pattharanitima P, Kattah AG, Mao MA, Keddis MT, Dillon JJ, Kaewput W, Tangpanithandee S, Krisanapan P, Qureshi F, et al. Explainable Preoperative Automated Machine Learning Prediction Model for Cardiac Surgery-Associated Acute Kidney Injury. Journal of Clinical Medicine. 2022; 11(21):6264. https://doi.org/10.3390/jcm11216264
Chicago/Turabian StyleThongprayoon, Charat, Pattharawin Pattharanitima, Andrea G. Kattah, Michael A. Mao, Mira T. Keddis, John J. Dillon, Wisit Kaewput, Supawit Tangpanithandee, Pajaree Krisanapan, Fawad Qureshi, and et al. 2022. "Explainable Preoperative Automated Machine Learning Prediction Model for Cardiac Surgery-Associated Acute Kidney Injury" Journal of Clinical Medicine 11, no. 21: 6264. https://doi.org/10.3390/jcm11216264