Poor Synchronization to Musical Beat Generalizes to Speech †


Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
Procedure Prior to Inclusion of Participants in the Study
2.2. Stimulus Materials
2.3. Design and Procedure
2.4. Data Analyses
2.4.1. Tapping Data Preprocessing
2.4.2. Analysis of Tapping Data
2.4.3. Correlation between Pitch Perception and Tapping to Spoken/Sung Sentences
2.5. Statistical Analyses
3. Results
3.1. Spontaneous Tapping
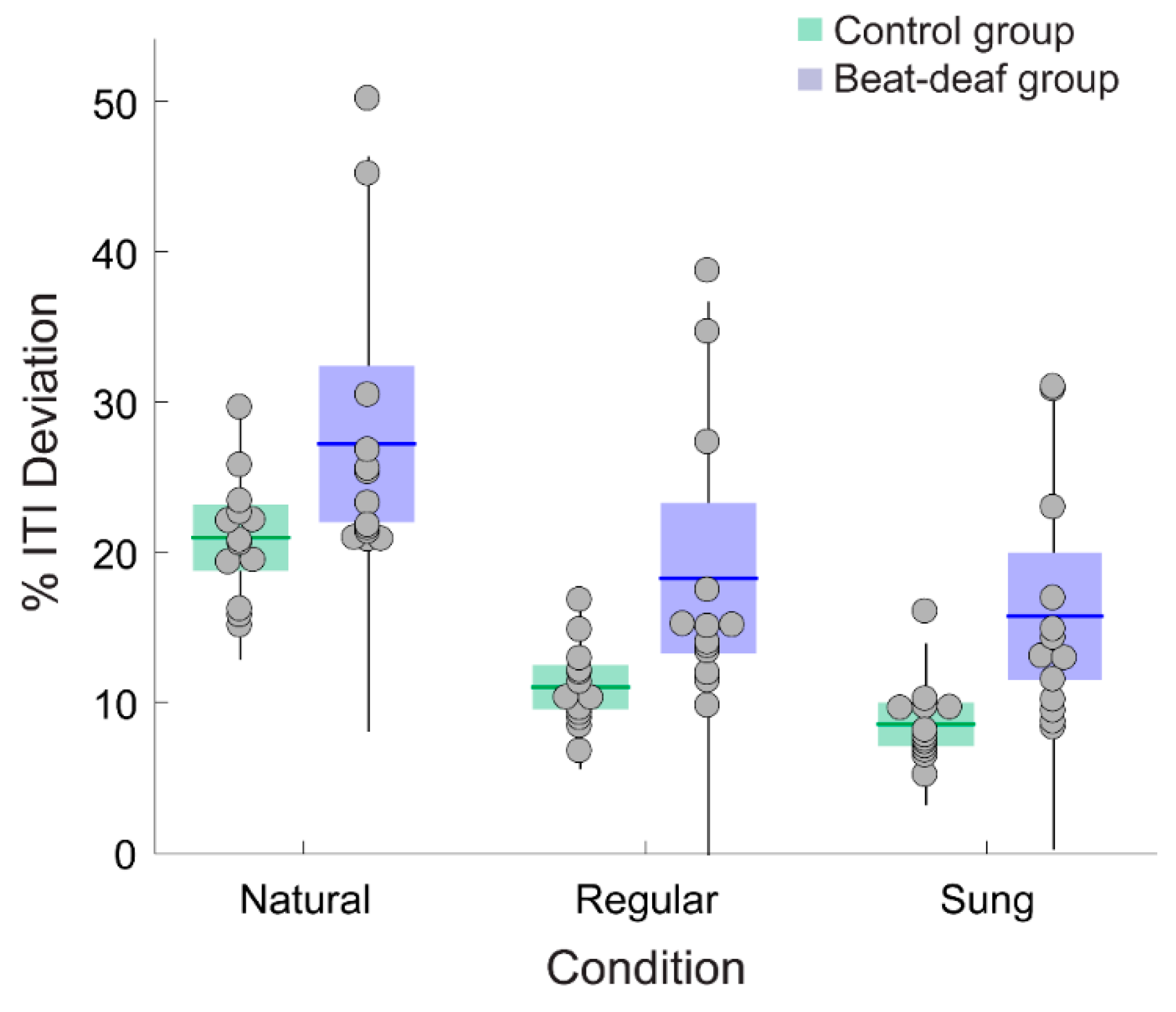
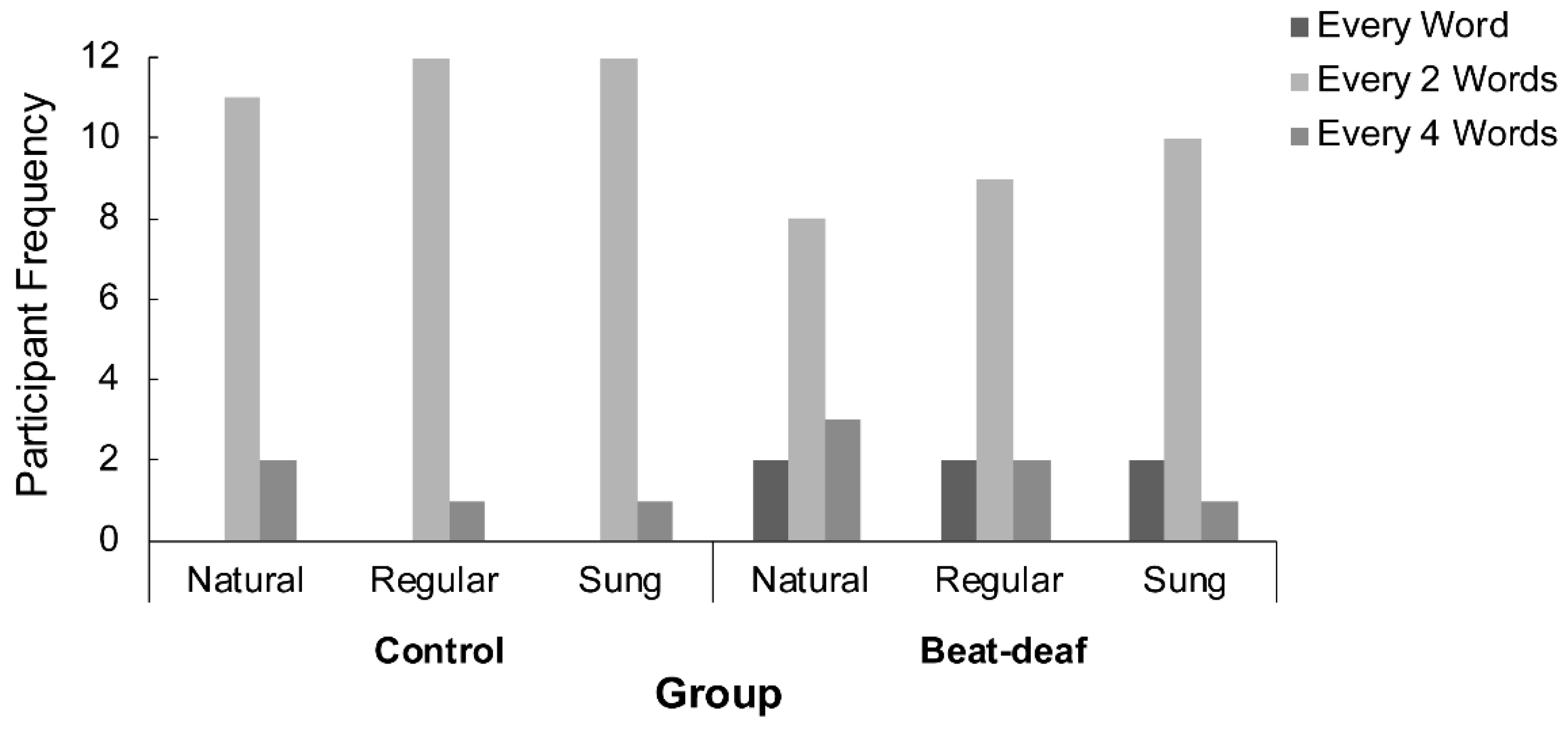
3.2. Tapping to Speech and Song
3.3. Tapping to Metronome
3.4. Contribution of Musical Pitch Perception to Entrainment to Utterances
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zentner, M.; Eerola, T. Rhythmic engagement with music in infancy. Proc. Natl. Acad. Sci. USA 2010, 107, 5768–5773. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Large, E.W.; Jones, M.R. The dynamics of attending: How people track time-varying events. Psychol. Rev. 1999, 106, 119–159. [Google Scholar] [CrossRef]
- Phillips-Silver, J.; Keller, P.E. Searching for Roots of Entrainment and Joint Action in Early Musical Interactions. Front. Hum. Neurosci. 2012, 6, 26. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jones, M.R. Time, our lost dimension: Toward a new theory of perception, attention, and memory. Psychol. Rev. 1976, 83, 323–355. [Google Scholar] [CrossRef] [PubMed]
- Jones, M.R. Dynamic pattern structure in music: Recent theory and research. Percept. Psychophys. 1987, 41, 621–634. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jones, M.R.; Boltz, M. Dynamic attending and responses to time. Psychol. Rev. 1989, 96, 459–491. [Google Scholar] [CrossRef] [PubMed]
- Large, E.W. Resonating to musical rhythm: Theory and experiment. In The Psychology of Time; Grondin, S., Ed.; Emerald Group Publishing: Bingley, UK, 2008; pp. 189–232. [Google Scholar]
- Large, E.W.; Palmer, C. Perceiving temporal regularity in music. Cogn. Sci. 2002, 26, 1–37. [Google Scholar] [CrossRef]
- Large, E.W.; Snyder, J.S. Pulse and Meter as Neural Resonance. Ann. New York Acad. Sci. 2009, 1169, 46–57. [Google Scholar] [CrossRef]
- Cummins, F. Rhythm as entrainment: The case of synchronous speech. J. Phon. 2009, 37, 16–28. [Google Scholar] [CrossRef]
- Cummins, F.; Port, R. Rhythmic constraints on stress timing in English. J. Phon. 1998, 26, 145–171. [Google Scholar] [CrossRef]
- Giraud, A.-L.; Poeppel, D. Cortical oscillations and speech processing: emerging computational principles and operations. Nat. Neurosci. 2012, 15, 511–517. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goswami, U. Entraining the Brain: Applications to Language Research and Links to Musical Entrainment. Empir. Music. Rev. 2012, 7, 57–63. [Google Scholar] [CrossRef] [Green Version]
- Lidji, P.; Palmer, C.; Peretz, I.; Morningstar, M. Listeners feel the beat: Entrainment to English and French speech rhythms. Psychon. Bull. Rev. 2011, 18, 1035–1041. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- O’Dell, M.; Nieminen, T. Coupled oscillator model of speech rhythm. In Proceedings of the XIVth International Congress of Phonetic Sciences, Berkeley, CA, USA, 7 August 1999; Volume 2, pp. 1075–1078. [Google Scholar]
- Peelle, J.E.; Davis, M.H.; Davis, M. Neural Oscillations Carry Speech Rhythm through to Comprehension. Front. Psychol. 2012, 3, 320. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Port, R.F. Meter and speech. J. Phon. 2003, 31, 599–611. [Google Scholar] [CrossRef]
- Wilson, M.; Wilson, T.P. An oscillator model of the timing of turn-taking. Psychon. Bull. Rev. 2005, 12, 957–968. [Google Scholar] [CrossRef]
- Lerdahl, F.; Jackendoff, R. An Overview of Hierarchical Structure in Music. Music Percept. Interdiscip. J. 1983, 1, 229–252. [Google Scholar] [CrossRef]
- Repp, B.H. Sensorimotor synchronization: A review of the tapping literature. Psychon. Bull. Rev. 2005, 12, 969–992. [Google Scholar] [CrossRef] [Green Version]
- Repp, B.H.; Su, Y.-H. Sensorimotor synchronization: A review of recent research (2006–2012). Psychon. Bull. Rev. 2013, 20, 403–452. [Google Scholar] [CrossRef]
- Van Der Steen, M.C.; Keller, P.E. The ADaptation and Anticipation Model (ADAM) of sensorimotor synchronization. Front. Hum. Neurosci. 2013, 7, 253. [Google Scholar] [CrossRef] [Green Version]
- Chapin, H.L.; Zanto, T.; Jantzen, K.J.; Kelso, S.J.A.; Steinberg, F.; Large, E.W. Neural Responses to Complex Auditory Rhythms: The Role of Attending. Front. Psychol. 2010, 1, 224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Drake, C.; Jones, M.R.; Baruch, C. The development of rhythmic attending in auditory sequences: Attunement, referent period, focal attending. Cognition 2000, 77, 251–288. [Google Scholar] [CrossRef]
- Large, E.W.; Herrera, J.A.; Velasco, M.J. Neural Networks for Beat Perception in Musical Rhythm. Front. Syst. Neurosci. 2015, 9, 583. [Google Scholar] [CrossRef] [PubMed]
- Palmer, C.; Krumhansl, C.L. Mental representations for musical meter. J. Exp. Psychol. Hum. Percept. Perform. 1990, 16, 728–741. [Google Scholar] [CrossRef] [PubMed]
- Repp, B.H.; Iversen, J.R.; Patel, A.D. Tracking an Imposed Beat within a Metrical Grid. Music Percept. Interdiscip. J. 2008, 26, 1–18. [Google Scholar] [CrossRef]
- London, J. Cognitive Constraints on Metric Systems: Some Observations and Hypotheses. Music Percept. Interdiscip. J. 2002, 19, 529–550. [Google Scholar] [CrossRef]
- McAuley, J.D. Tempo and Rhythm. In Music Perception; Riess Jones, M., Fay, R.R., Popper, A.N., Eds.; Springer: New York, NY, USA, 2010; pp. 165–199. [Google Scholar]
- McAuley, J.D.; Jones, M.R.; Holub, S.; Johnston, H.M.; Miller, N.S. The time of our lives: Life span development of timing and event tracking. J. Exp. Psychol. Gen. 2006, 135, 348–367. [Google Scholar] [CrossRef] [PubMed]
- Repp, B.H. Rate Limits in Sensorimotor Synchronization With Auditory and Visual Sequences: The Synchronization Threshold and the Benefits and Costs of Interval Subdivision. J. Mot. Behav. 2003, 35, 355–370. [Google Scholar] [CrossRef] [PubMed]
- Drake, C.; Penel, A.; Bigand, E. Tapping in Time with Mechanically and Expressively Performed Music. Music Percept. Interdiscip. J. 2000, 18, 1–23. [Google Scholar] [CrossRef]
- Palmer, C. Music performance. Annu. Rev. Psychol. 1997, 48, 115–138. [Google Scholar] [CrossRef]
- Honing, H. Without it no music: Beat induction as a fundamental musical trait. Ann. N. Y. Acad. Sci. 2012, 1252, 85–91. [Google Scholar] [CrossRef] [PubMed]
- Iversen, J.R. In the beginning was the beat. In The Cambridge Companion to Percussion; Hartenberger, R., Ed.; Cambridge University Press: Cambridge, UK, 2016; pp. 281–295. [Google Scholar]
- Brown, S.; Pfordresher, P.Q.; Chow, I. A musical model of speech rhythm. Psychomusicol. Music Mind Brain 2017, 27, 95–112. [Google Scholar] [CrossRef]
- Leong, V.; Stone, M.A.; Turner, R.E.; Goswami, U. A role for amplitude modulation phase relationships in speech rhythm perception. J. Acoust. Soc. Am. 2014, 136, 366–381. [Google Scholar] [CrossRef] [PubMed]
- Meyer, L. The neural oscillations of speech processing and language comprehension: State of the art and emerging mechanisms. Eur. J. Neurosci. 2018, 48, 2609–2621. [Google Scholar] [CrossRef] [PubMed]
- Kotz, S.A.; Schwartze, M. Cortical speech processing unplugged: A timely subcortico-cortical framework. Trends Cogn. Sci. 2010, 14, 392–399. [Google Scholar] [CrossRef] [PubMed]
- Selkirk, E.O. Phonology and Syntax: The Relationship between Sound and Structure; MIT Press: Cambridge, MA, USA, 1986; p. 494. [Google Scholar]
- Turk, A.; Shattuck-Hufnagel, S. What is speech rhythm? A commentary on Arvaniti and Rodriquez, Krivokapić, and Goswami and Leong. Lab. Phonol. J. Assoc. Lab. Phonol. 2013, 4, 93–118. [Google Scholar] [CrossRef]
- Liberman, M.; Prince, A. On Stress and Linguistic Rhythm. Linguist. Inq. 1977, 8, 249–336. [Google Scholar]
- Dauer, R.M. Stress-timing and syllable-timing reanalyzed. J. Phon. 1983, 11, 51–62. [Google Scholar]
- Jadoul, Y.; Ravignani, A.; Thompson, B.; Filippi, P.; De Boer, B. Seeking Temporal Predictability in Speech: Comparing Statistical Approaches on 18 World Languages. Front. Hum. Neurosci. 2016, 10, 351. [Google Scholar] [CrossRef]
- Nolan, F.; Jeon, H.S. Speech rhythm: A metaphor? Philos. Trans. R. Soc. Lond. B. Biol. Sci. 2014, 369, 20130396. [Google Scholar] [CrossRef]
- Patel, A.D. Music, Language, and the Brain; Oxford University Press: New York, NY, USA, 2008; p. 513. [Google Scholar]
- Borrie, S.A.; Liss, J.M. Rhythm as a Coordinating Device: Entrainment with Disordered Speech. J. Speech Lang. Hear. Res. 2014, 57, 815–824. [Google Scholar] [CrossRef] [PubMed]
- Jungers, M.K.; Palmer, C.; Speer, S.R. Time after time: The coordinating influence of tempo in music and speech. Cogn. Process. 2002, 1, 21–35. [Google Scholar]
- Schultz, B.G.; O’Brien, I.; Phillips, N.; McFarland, D.H.; Titone, D.; Palmer, C. Speech rates converge in scripted turn-taking conversations. Appl. Psycholinguist. 2015, 37, 1201–1220. [Google Scholar] [CrossRef]
- Cummins, F. Periodic and Aperiodic Synchronization in Skilled Action. Front. Hum. Neurosci. 2011, 5, 170. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cummins, F. Joint speech: The missing link between speech and music? Percepta 2013, 1, 17. [Google Scholar]
- Cummins, F. On synchronous speech. Acoust. Res. Lett. Online 2002, 3, 7–11. [Google Scholar] [CrossRef] [Green Version]
- Cummins, F. Entraining speech with speech and metronomes. Cadernos de Estudos Lingüísticos 2002, 43, 55–70. [Google Scholar] [CrossRef]
- Cummins, F.; Li, C.; Wang, B. Coupling among speakers during synchronous speaking in English and Mandarin. J. Phon. 2013, 41, 432–441. [Google Scholar] [CrossRef]
- Bella, S.D.; Białuńska, A.; Sowinski, J. Why Movement Is Captured by Music, but Less by Speech: Role of Temporal Regularity. PLOS ONE 2013, 8, e71945. [Google Scholar] [CrossRef]
- Lidji, P.; Palmer, C.; Peretz, I.; Morningstar, M. Entrainment to speech and song. In Proceedings of the International Symposium on Performance Science, Utrecht, The Netherlands, 24 August 2011; pp. 123–128. [Google Scholar]
- Bégel, V.; Benoit, C.-E.; Correa, A.; Cutanda, D.; Kotz, S.A.; Bella, S.D. “Lost in time” but still moving to the beat. Neuropsychology 2017, 94, 129–138. [Google Scholar] [CrossRef]
- Bella, S.D.; Sowinski, J. Uncovering Beat Deafness: Detecting Rhythm Disorders with Synchronized Finger Tapping and Perceptual Timing Tasks. J. Vis. Exp. 2015, 97, 51761. [Google Scholar] [CrossRef] [PubMed]
- Phillips-Silver, J.; Toiviainen, P.; Gosselin, N.; Piché, O.; Nozaradan, S.; Palmer, C.; Peretz, I. Born to dance but beat deaf: A new form of congenital amusia. Neuropsychology 2011, 49, 961–969. [Google Scholar] [CrossRef] [PubMed]
- Sowinski, J.; Bella, S.D. Poor synchronization to the beat may result from deficient auditory-motor mapping. Neuropsychology 2013, 51, 1952–1963. [Google Scholar] [CrossRef] [PubMed]
- Tranchant, P.; Vuvan, D.T.; Peretz, I. Keeping the Beat: A Large Sample Study of Bouncing and Clapping to Music. PLOS ONE 2016, 11, e0160178. [Google Scholar] [CrossRef] [PubMed]
- Palmer, C.; Lidji, P.; Peretz, I. Losing the beat: deficits in temporal coordination. Philos. Trans. R. Soc. B Boil. Sci. 2014, 369, 20130405. [Google Scholar] [CrossRef] [PubMed]
- Tranchant, P.; Peretz, I. Faulty Internal Rhythm in the Beat-based Form of Congenital Amusia. Unpublished work. (in preperation)
- Wechsler, D.; Coalson, D.L.; Raiford, S.E. WAIS-III: Wechsler Adult Intelligence Scale; Psychological Corporation: San Antonio, TX, USA, 1997. [Google Scholar]
- Lagrois, M.-É.; Peretz, I. The co-occurrence of pitch and rhythm disorders in congenital amusia. Cortex 2019, 113, 229–238. [Google Scholar] [CrossRef] [PubMed]
- Tranchant, P.; Lagrois, M.-É.; Bellemare Pépin, A.; Schultz, B.G.; Peretz, I. Beat alignment test of the motor origin of musical entrainment deficits. Neuropsychologia 2019, submitted. [Google Scholar]
- Peretz, I.; Vuvan, D.T. Prevalence of congenital amusia. Eur. J. Hum. Genet. 2017, 25, 625–630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vuvan, D.T.; Paquette, S.; Mignault Goulet, G.; Royal, I.; Felezeu, M.; Peretz, I. The Montreal Protocol for Identification of Amusia. Behav. Res. Methods 2018, 50, 662–672. [Google Scholar] [CrossRef] [PubMed]
- Boersma, P.; Weenink, D. Praat: Doing phonetics by computer [Computer program], Version 6.0.2; 2017. Available online: http://www.praat.org/ (accessed on 17 January 2017).
- Ramus, F.; Nespor, M.; Mehler, J. Correlates of linguistic rhythm in the speech signal. Cognition 1999, 73, 265–292. [Google Scholar] [CrossRef] [Green Version]
- Grabe, E.; Low, E.L. Durational variability in speech and the rhythm class hypothesis. In Laboratory Phonology 7; Gussenhoven, C., Warner, N., Eds.; De Gruyter Mouton: Berlin, Germany, 2002; pp. 515–546. [Google Scholar]
- Schultz, B.G.; van Vugt, F.T. Tap Arduino: An Arduino microcontroller for low-latency auditory feedback in sensorimotor synchronization experiments. Behav. Res. Methods 2016, 48, 1591–1607. [Google Scholar] [CrossRef] [PubMed]
- Van Vugt, F.T.; Schultz, B.G. Taparduino v1.01. Zenodo 16178. 2015. Available online: https://doi.org/10.5281/zenodo.16178 (accessed on 20 March 2015).
- Dalla Bella, S.; Farrugia, N.; Benoit, C.-E.; Begel, V.; Verga, L.; Harding, E.; Kotz, S.A. BAASTA: Battery for the assessment of auditory sensorimotor and timing abilities. Behav. Res. Methods 2017, 49, 1128–1145. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.L.; Penhune, V.B.; Zatorre, R.J. Moving on Time: Brain Network for Auditory-Motor Synchronization is Modulated by Rhythm Complexity and Musical Training. J. Cogn. Neurosci. 2008, 20, 226–239. [Google Scholar] [CrossRef] [PubMed]
- Giovannelli, F.; Innocenti, I.; Rossi, S.; Borgheresi, A.; Ragazzoni, A.; Zaccara, G.; Viggiano, M.P.; Cincotta, M. Role of the dorsal premotor cortex in rhythmic auditory-motor entrainment: A perturbational approach by rTMS. Cereb. Cortex 2014, 24, 1009–1016. [Google Scholar] [CrossRef] [PubMed]
- Leow, L.-A.; Parrott, T.; Grahn, J.A. Individual Differences in Beat Perception Affect Gait Responses to Low- and High-Groove Music. Front. Hum. Neurosci. 2014, 8, 811. [Google Scholar] [CrossRef] [PubMed]
- Berens, P. CircStat: A MATLAB Toolbox for Circular Statistics. J. Stat. Softw. 2009, 31, 1–21. [Google Scholar] [CrossRef]
- Wilkie, D. Rayleigh Test for Randomness of Circular Data. J. R. Stat. Soc. Ser. C Applied Stat. 1983, 32, 311. [Google Scholar] [CrossRef]
- Dalla Bella, S.; Sonja, K. Method and apparatus for the synchronization of data sequences including filtering. Google Patents US20180199859A1, 2018. [Google Scholar]
- Nozaradan, S.; Peretz, I.; Keller, P.E. Individual Differences in Rhythmic Cortical Entrainment Correlate with Predictive Behavior in Sensorimotor Synchronization. Sci. Rep. 2016, 6, 20612. [Google Scholar] [CrossRef]
- Thabane, L.; Mbuagbaw, L.; Zhang, S.; Samaan, Z.; Marcucci, M.; Ye, C.; Thabane, M.; Giangregorio, L.; Dennis, B.; Kosa, D.; et al. A tutorial on sensitivity analyses in clinical trials: The what, why, when and how. BMC Med. Res. Methodol. 2013, 13, 92. [Google Scholar] [CrossRef]
- Kover, S.T.; Atwood, A.K. Establishing Equivalence: Methodological Progress in Group-Matching Design and Analysis. Am. J. Intellect. Dev. Disabil. 2013, 118, 3–15. [Google Scholar] [CrossRef]
- Ammirante, P.; Thompson, W.F.; Russo, F.A. Ideomotor effects of pitch on continuation tapping. Q. J. Exp. Psychol. 2011, 64, 381–393. [Google Scholar] [CrossRef] [PubMed]
- Boasson, A.D.; Granot, R. Melodic direction’s effect on tapping. In Proceedings of the 12th International Conference on Music Perception and Cognition, Thessaloniki, Greece, 23–28 July 2012. [Google Scholar]
- Ellis, R.J.; Jones, M.R. The role of accent salience and joint accent structure in meter perception. J. Exp. Psychol. Hum. Percept. Perform. 2009, 35, 264–280. [Google Scholar] [CrossRef] [PubMed]
- Hannon, E.E.; Snyder, J.S.; Eerola, T.; Krumhansl, C.L. The Role of Melodic and Temporal Cues in Perceiving Musical Meter. J. Exp. Psychol. Hum. Percept. Perform. 2004, 30, 956–974. [Google Scholar] [CrossRef] [PubMed]
- Jones, M.R.; Pfordresher, P.Q. Tracking musical patterns using joint accent structure. Can. J. Exper. Psychol. 1997, 51, 271–291. [Google Scholar] [CrossRef]
- McKinney, M.F.; Moelants, D. Ambiguity in Tempo Perception: What Draws Listeners to Different Metrical Levels? Music. Percept. Interdiscip. J. 2006, 24, 155–166. [Google Scholar] [CrossRef]
- Pfordresher, P.Q. The Role of Melodic and Rhythmic Accents in Musical Structure. Music. Percept. Interdiscip. J. 2003, 20, 431–464. [Google Scholar] [CrossRef] [Green Version]
- Prince, J.B. The integration of stimulus dimensions in the perception of music. Q. J. Exp. Psychol. 2011, 64, 2125–2152. [Google Scholar] [CrossRef]
- Prince, J.B. Pitch structure, but not selective attention, affects accent weightings in metrical grouping. J. Exp. Psychol. Hum. Percept. Perform. 2014, 40, 2073–2090. [Google Scholar] [CrossRef]
- Prince, J.B.; Pfordresher, P.Q. The role of pitch and temporal diversity in the perception and production of musical sequences. Acta Psychol. 2012, 141, 184–198. [Google Scholar] [CrossRef] [Green Version]
- Palmer, C.; Krumhansl, C.L. Pitch and temporal contributions to musical phrase perception: Effects of harmony, performance timing, and familiarity. Percept. Psychophys. 1987, 41, 505–518. [Google Scholar] [CrossRef]
- Snyder, J.; Krumhansl, C.L. Tapping to Ragtime: Cues to Pulse Finding. Music Percept. Interdiscip. J. 2001, 18, 455–489. [Google Scholar] [CrossRef]
- Nobre, A.C.; van Ede, F. Anticipated moments: Temporal structure in attention. Nat. Rev. Neurosci. 2018, 19, 34–48. [Google Scholar] [CrossRef] [PubMed]
- Di Liberto, G.M.; O’Sullivan, J.A.; Lalor, E.C. Low-Frequency Cortical Entrainment to Speech Reflects Phoneme-Level Processing. Curr. Boil. 2015, 25, 2457–2465. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ding, N.; Simon, J.Z. Cortical entrainment to continuous speech: functional roles and interpretations. Front. Hum. Neurosci. 2014, 8, 311. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghitza, O. Linking speech perception and neurophysiology: Speech decoding guided by cascaded oscillators locked to the input rhythm. Front. Psychol. 2011, 2, 130. [Google Scholar] [CrossRef] [PubMed]
- Ghitza, O. The theta-syllable: A unit of speech information defined by cortical function. Front. Psychol. 2013, 4, 138. [Google Scholar] [CrossRef]
- Gross, J.; Hoogenboom, N.; Thut, G.; Schyns, P.; Panzeri, S.; Belin, P.; Garrod, S. Speech Rhythms and Multiplexed Oscillatory Sensory Coding in the Human Brain. PLoS Boil. 2013, 11, e1001752. [Google Scholar] [CrossRef]
- Kayser, S.J.; Ince, R.A.; Gross, J.; Kayser, C. Irregular Speech Rate Dissociates Auditory Cortical Entrainment, Evoked Responses, and Frontal Alpha. J. Neurosci. 2015, 35, 14691–14701. [Google Scholar] [CrossRef] [Green Version]
- Peelle, J.E.; Gross, J.; Davis, M.H. Phase-locked responses to speech in human auditory cortex are enhanced during comprehension. Cereb. Cortex 2013, 23, 1378–1387. [Google Scholar] [CrossRef]
- Zhang, W.; Ding, N. Time-domain analysis of neural tracking of hierarchical linguistic structures. NeuroImage 2017, 146, 333–340. [Google Scholar] [CrossRef]
- Doelling, K.B.; Poeppel, D. Cortical entrainment to music and its modulation by expertise. Proc. Natl. Acad. Sci. USA 2015, 112, E6233–E6242. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mai, G.; Minett, J.W.; Wang, W.S.-Y. Delta, theta, beta, and gamma brain oscillations index levels of auditory sentence processing. NeuroImage 2016, 133, 516–528. [Google Scholar] [CrossRef] [PubMed]
- Nozaradan, S. Exploring how musical rhythm entrains brain activity with electroencephalogram frequency-tagging. Philos. Trans. R. Soc. B Boil. Sci. 2014, 369, 20130393. [Google Scholar] [CrossRef] [PubMed]
- Nozaradan, S.; Peretz, I.; Missal, M.; Mouraux, A. Tagging the neuronal entrainment to beat and meter. J. Neurosci. 2011, 31, 10234–10240. [Google Scholar] [CrossRef] [PubMed]
- Stupacher, J.; Wood, G.; Witte, M. Neural Entrainment to Polyrhythms: A Comparison of Musicians and Non-musicians. Front. Mol. Neurosci. 2017, 11, 208. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tal, I.; Large, E.W.; Rabinovitch, E.; Wei, Y.; Schroeder, C.E.; Poeppel, D.; Golumbic, E.Z. Neural Entrainment to the Beat: The “Missing-Pulse” Phenomenon. J. Neurosci. 2017, 37, 6331–6341. [Google Scholar] [CrossRef] [PubMed]
- Tierney, A.; Kraus, N. Auditory-motor entrainment and phonological skills: precise auditory timing hypothesis (PATH). Front. Hum. Neurosci. 2014, 8, 949. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Corriveau, K.H.; Goswami, U. Rhythmic motor entrainment in children with speech and language impairments: Tapping to the beat. Cortex 2009, 45, 119–130. [Google Scholar] [CrossRef]
- Cumming, R.; Wilson, A.; Leong, V.; Colling, L.J.; Goswami, U. Awareness of Rhythm Patterns in Speech and Music in Children with Specific Language Impairments. Front. Hum. Neurosci. 2015, 9, 200. [Google Scholar] [CrossRef]
- Flaugnacco, E.; Lopez, L.; Terribili, C.; Zoia, S.; Buda, S.; Tilli, S.; Monasta, L.; Montico, M.; Sila, A.; Ronfani, L.; et al. Rhythm perception and production predict reading abilities in developmental dyslexia. Front. Hum. Neurosci. 2014, 8. [Google Scholar] [CrossRef]
- Thomson, J.M.; Fryer, B.; Maltby, J.; Goswami, U.; Thomson, J.; Fryer, B. Auditory and motor rhythm awareness in adults with dyslexia. J. Res. Read. 2006, 29, 334–348. [Google Scholar] [CrossRef]
- Thomson, J.M.; Goswami, U.; Thomson, J. Rhythmic processing in children with developmental dyslexia: Auditory and motor rhythms link to reading and spelling. J. Physiol. 2008, 102, 120–129. [Google Scholar] [CrossRef] [PubMed]
- Bonacina, S.; Krizman, J.; White-Schwoch, T.; Kraus, N. Clapping in time parallels literacy and calls upon overlapping neural mechanisms in early readers. Ann. New York Acad. Sci. 2018, 1423, 338–348. [Google Scholar] [CrossRef] [PubMed]
- Tierney, A.T.; Kraus, N. The ability to tap to a beat relates to cognitive, linguistic, and perceptual skills. Brain Lang. 2013, 124, 225–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carr, K.W.; Fitzroy, A.B.; Tierney, A.; White-Schwoch, T.; Kraus, N. Incorporation of feedback during beat synchronization is an index of neural maturation and reading skills. Brain Lang. 2017, 164, 43–52. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Falk, S.; Müller, T.; Bella, S.D. Non-verbal sensorimotor timing deficits in children and adolescents who stutter. Front. Psychol. 2015, 6, 847. [Google Scholar] [CrossRef] [PubMed]
- Gracco, V.L.; Van De Vorst, R. Atypical non-verbal sensorimotor synchronization in adults who stutter may be modulated by auditory feedback. J. Fluen. Disord. 2017, 53, 14–25. [Google Scholar]
- Cutler, A. Listening to a second language through the ears of a first. Interpreting. Int. J. Res. Pr. Interpreting 2000, 5, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Iversen, J.R.; Patel, A.D.; Ohgushi, K. Perception of rhythmic grouping depends on auditory experience. J. Acoust. Soc. Am. 2008, 124, 2263–2271. [Google Scholar] [CrossRef] [Green Version]
- Friederici, A.D.; Hahne, A.; Mecklinger, A. Temporal structure of syntactic parsing: Early and late event-related brain potential effects. J. Exp. Psychol. Learn. Mem. Cogn. 1996, 22, 1219–1248. [Google Scholar] [CrossRef]
- Kutas, M.; Hillyard, S. Reading senseless sentences: brain potentials reflect semantic incongruity. Science 1980, 207, 203–205. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Beat-deaf (SD) n = 13 | Control (SD) n = 13 | ||
|---|---|---|---|---|
| Age (years) | 37.4 | (17.6) | 38.7 | (17.8) |
| Education (years) | 18.2 | (2.2) | 17.6 | (3.2) |
| Musical Training (years) | 1.0 | (2.3) | 1.1 | (2.1) |
| Dance Training (years) | 1.3 | (3.0) | 1.8 | (3.1) |
| WAIS-III Digit Span (ss) | 10.0 | (3.0) | 11.0 | (3.0) |
| WAIS-III Matrix Reasoning (ss) a | 13.0 | (3.0) | 14.0 | (1.0) |
| Group | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Beat-Deaf | Control (n = 13) | |||||||||||||||
| Participant | B1 | B2 | B3 | B4 | B5 | B6 | B7 † | B8 † | B9 † | B10 † | B11 † | B12 † | B13 † | M | M | SD |
| Online test | ||||||||||||||||
| Scale (22/30) | 23 | 24 | 23 | 23 | 23 | 24 | 21 † | 21 † | 20 † | 22 † | 19 † | 18 † | 22 † | 21.8 | 27.7 | 2.2 |
| Off-key (16/24) | 20 | 14 † | 19 | 14 † | 16 † | 14 † | 13 † | 16 † | 15 † | 9 † | 13 † | 14 † | 13 † | 14.6 | 19.8 | 2.2 |
| Off-beat (17/24) | 23 | 21 | 19 | 17 † | 20 | 16 † | 15 † | 17 † | 18 | 17 † | 18 | 18 | 19 | 18.3 | 19.8 | 1.4 |
| Original Tempo | Slowed Tempo | |||
|---|---|---|---|---|
| Condition | Control | Beat-Deaf | Control | Beat-Deaf |
| Naturally Spoken Sentences (SE) | 480.00 (7.70) | 489.80 (12.80) | 591.77 (8.90) | 585.58 (11.70) |
| Regularly Spoken Sentences (SE) | 497.43 (6.52) | 522.15 (12.83) | 615.20 (4.97) | 632.00 (17.69) |
| Sung Sentences (SE) | 488.70 (4.28) | 517.08 (13.39) | 611.24 (4.12) | 664.25 (17.30) |
| Variable | Naturally Spoken Sentences (SE) | Regularly Spoken Sentences (SE) | Sung Sentences (SE) | |||
|---|---|---|---|---|---|---|
| Mean IVI (ms) | 458.00 | (10.00) * | 503.00 | ( 3.00 ) | 501.00 | (1.000) |
| V-nPVI | 49.40 | ( 2.50 ) * | 42.30 | ( 2.00 ) * | 31.10 | (1.800) |
| CV(IVI) | 0.21 | ( 0.02 ) * | 0.08 | ( 0.01 ) * | 0.05 | (0.004) * |
| Beat Asynchrony from Vowel Onset (ms) | - | 14.00 | (11.00) | −2.00 | (5.000) | |
| Group | Spontaneous Tapping-Pre | Spontaneous Tapping-Post | ||
|---|---|---|---|---|
| Mean ITI a | CV | Mean ITI a | CV | |
| Control (SE) | 603 (56) | 0.06 (0.003) | 565 (57) | 0.06 (0.004) |
| Beat-deaf (SE) | 680b(47) | 0.08b (0.01) | 659 (80) | 0.08 (0.01) |
| Variable | Scale Test | Off-Key Test | Off-Beat Test | CV M-BAT Production Test | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CV—natural sentences | −0.20 a | −0.10 c | −0.15 d | −0.22 a | −0.06 c | −0.53 d | −0.12 a | 0.12 c | −0.25 d | 0.47 a | 0.78 c | 0.14 d |
| CV—regular sentences | −0.24 a | −0.42 c | −0.27 d | −0.29 a | −0.41 c | −0.48 d | −0.03 a | 0.03 c | 0.08 d | 0.32 a | 0.79 c | −0.19 d |
| CV—sung sentences | −0.26 a | −0.15 c | −0.11 d | −0.35 a | −0.16 c | −0.37 d | −0.24 a | −0.05 c | −0.24 d | 0.31 a | 0.43 c | −0.11 d |
| %ITI deviation—natural | −0.30 b | −0.01 c | 0.08 e | −0.34 b | −0.39 c | −0.01 e | 0.11 b | 0.30 c | 0.17 e | - | - | - |
| %ITI deviation—regular | −0.32 b | 0.30 c | −0.18 e | −0.55 b | −0.35 c | −0.12 e | −0.19 b | 0.05 c | 0.17 e | - | - | - |
| %ITI deviation—sung | −0.54 b | −0.05 c | −0.61 e | −0.43 b | −0.21 c | 0.43 e | −0.21 b | 0.26 c | 0.12 e | - | - | - |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lagrois, M.-É.; Palmer, C.; Peretz, I. Poor Synchronization to Musical Beat Generalizes to Speech. Brain Sci. 2019, 9, 157. https://doi.org/10.3390/brainsci9070157
Lagrois M-É, Palmer C, Peretz I. Poor Synchronization to Musical Beat Generalizes to Speech. Brain Sciences. 2019; 9(7):157. https://doi.org/10.3390/brainsci9070157
Chicago/Turabian StyleLagrois, Marie-Élaine, Caroline Palmer, and Isabelle Peretz. 2019. "Poor Synchronization to Musical Beat Generalizes to Speech" Brain Sciences 9, no. 7: 157. https://doi.org/10.3390/brainsci9070157