2.1. State of the Art on the Assessment of Planning Skills and Fluid Intelligence
EFs are high-level mental abilities that regulate lower-level processes [
6,
7]. They allow individuals to plan and organize thoughts in a goal-directed manner, to understand complex or abstract concepts, to evaluate and make decisions, and to suppress inappropriate behaviors [
6,
7,
8]. For these reasons, EFs contribute to individual adaptations to the environment, daily life, and academic and professional successes [
8].
Among EFs, planning plays a central role. It is regarded as the ability to identify and organize the sequence of steps required to achieve a goal, typically without a predetermined path [
27,
28]. Traditional planning tasks, such as tower tests, like the Tower of London (ToL; [
15]) and Tower of Hanoi [
29], are commonly used in neuropsychological assessments. These tasks involve moving objects from one position to another with specific rules and constraints [
30]. Therefore, they require individuals to visualize the necessary course of action before manipulating the materials [
31]. Successful completion of these tasks involves the ability to consider the overall situation, define sub-goals, and generate a sequence of moves to achieve them.
Tower tasks have been widely used in research on the planning skills of individuals with typical development [
27,
32] or clinical conditions, such as neurodevelopmental disorders, focal brain lesions, frontal lobe dementia, Parkinson’s and Huntington’s diseases, and psychiatric disorders [
6,
13,
14,
33,
34]. Among tower tests, ToL is likely the most used with individuals of different chronological ages and conditions.
Despite the popularity of the ToL task in cognitive and clinical studies of EFs and some attempts at standardization (see, e.g., [
24,
35,
36,
37]), the literature shows a notable lack of uniformity in the procedure across studies [
38]. Several variants of the ToL have been introduced and used to examine planning abilities in different populations [
39,
40]. Although some of them are close to the original version, others have implemented major changes concerning, for example, the administration procedure, outcome measures, the number of items, and the material itself, so that the comparison of results across studies is challenging [
35,
36,
38,
41].
A growing interest has been placed on the computerized versions of these tests. One widely used computerized version of the ToL is the Stockings of Cambridge (SOC) task, a test of the Cambridge neuropsychological test automated battery (CANTAB; [
42]). Despite the advantages of computerized ToL tasks (e.g., ease of presentation, ease of use, and accurate data acquisition), they involve critical differences in the task itself, both physically and conceptually. Moreover, computerized versions proposed so far do not solve the “inefficiency issue” that can significantly affect specific clinical populations. This issue concerns the fact that individuals are asked to answer all the test questions. Conversely, adaptive assessment allows for the personalization of administration by using stimuli that dynamically adapt to an individual’s appropriate challenge level. They offer the potential to shorten test times, improve test accuracy, and reduce the effect of irrelevant variance caused by the frustration of having to answer items that are too difficult [
43].
Only a few attempts have been made to develop adaptive tools for the assessment of EFs, particularly planning tasks. For example, in a recent study, a novel adaptive battery for the assessment of EFs, composed of eight tasks, was tested with individuals in middle childhood to measure working memory, context monitoring, and interference resolution, but not planning ability [
22]. On the contrary, [
21] developed the Tower of London Adaptive Test (ToLA) to efficiently and accurately assess planning in individuals with neurodevelopmental disorders. However, the stimuli presented are apparently different compared to Shallice’s one. To develop the test, the authors first created a precisely calibrated item bank using item response theory and then set a suitable algorithm capable of estimating the participant’s skill level during the test. Unfortunately, the version was only designed but was not subjected to clinical studies.
Concerning FI, its assessment generally occurs through reasoning ability tests, which are considered more culture-fair and less affected by differences in learning experiences, test familiarity, or sociocultural status [
44,
45]. One of the most well-known tests of this type is the Raven’s Matrices test [
18]. This test requires the individual to identify the piece that best completes a visual-spatial matrix from a series of given options. Currently, the Raven’s Matrices test is available in three forms, each composed of stimuli that differ in number and type, and presented in a booklet format. Colored progressive matrices (CPM; [
19]) consist of 36 colored items and are intended for kindergarten to middle school-aged children and the elderly; standard progressive matrices (SPM; [
18]) are composed of 60 black and white items, designed for individuals from 6 years old and above. Advanced progressive matrices (APM; [
19]) are composed of 48 more complex items, allowing for the differentiation of individuals with high cognitive abilities, and are intended for adolescents and adults. Within each form, stimuli are placed in order of increasing difficulty and are organized into different series, assessing specific competencies. For instance, CPM are organized into three series, which evaluate the ability to identify similarities (based on shape, dimension, direction, quantity, orientation, figure/background, and density criteria), the ability to detect symmetry, and conceptual thinking skills (i.e., detection of abstract relations according to ‘operant-deductive’ logic and their retention in working memory), respectively [
46].
Efforts to limit administration times have led to the testing of reduced versions with adults [
47,
48,
49,
50,
51,
52], high school and university students [
53], and individuals of developmental age [
54,
55], as well as versions with a fixed administration time [
56].
Other attempts have been made to automate the administration of Raven’s Matrices, mainly to standardize administration and scoring procedures. The initial efforts involved automating the SPM using slides and a projector, where the exact same stimuli of the original SPM were used. The selected response to each item was indicated by pressing a button. The time and accuracy of each response were registered [
57,
58,
59]. Later on, SPM [
60,
61,
62] and CPM [
63] were administered using computers to school-aged children, high school students, psychiatric patients, federal employees, and undergraduate students. These automated versions differed only in their presentation format from the original ones, hence providing no advantages regarding the test length and the duration of attention focus required to the test-takers.
Attempts to create computerized adaptive versions of Raven’s Matrices date back to the 1980s and 1990s [
59,
64], and continue today, since computerized adaptive testing provides more accurate FI estimations using a reduced number of administered items (see, e.g., [
65]). For instance [
64], using Rasch models, created a unique test with SPM and APM items for individuals aged 10 to 16. This version consisted of five practice items from SPM followed by the first test item that was relatively easy for that person’s chronological age. If the individual responded incorrectly to this first item, then the second one—in order of difficulty—was presented. Conversely, the algorithm skipped to the third item, and so on, ending the test when the person answered five items incorrectly in a row.
Using item response theory, the Hansen Research Services Matrix Adaptive Test (HRS-MAT) was developed specifically for individuals with autism spectrum disorder, but is also usable with the general population [
66]. It measures nonverbal intelligence using tasks similar to Raven’s Matrices. Similar to the tool developed by [
64], the instrument’s adaptive algorithm selects items to administer that are appropriate for the participant’s age (children or adults) and ability level, taking no more than 15 min to complete. However, this HRS-MAT is only available for research purposes and it is not used in clinical settings.
To conclude, given the importance of planning skills and FI and the evaluation of their manifestations in both clinical and non-clinical populations, having precise and efficient tools for their assessment is highly relevant. Furthermore, a helpful resource would be a tool with clear standard administration and scoring procedures that is applicable to different types of populations and capable of adapting to the characteristics of the individuals.
2.2. Knowledge Space Theory, Procedural Knowledge Space Theory, and Adaptive Assessment Algorithms
Knowledge space theory (KST, see, e.g., [
23,
67,
68]) is a mathematical theory developed for the efficient assessment of knowledge and personalized learning. One of the most prominent features of KST is that no attempt is made to compute linearly ordered numerical scores for sorting individuals. Rather, the goal of the assessment is to describe “what an individual masters”, which is their
knowledge state, and “what they are ready to learn”, which is named the
outer fringe of their knowledge state. Formally, a knowledge state is the set
of items that an individual masters in a particular knowledge domain
Q, and the outer fringe of a knowledge state
K is the set of all problems in
, such that
is a knowledge state. From a pedagogical point of view, the outer fringe is the set of all problems that the individual can learn individually, allowing for the increase of their own knowledge state.
The collection of all knowledge states existing in a population of individuals is the so-called knowledge structure ). The knowledge structure reflects the precedence relations (e.g., prerequisites) existing among the problems in Q. Thus, is a subset of the power set (i.e., the collection of all the subsets of Q) of problems. Let ≺ be a precedence relation defined on Q. A subset of Q is a knowledge state whenever, for every pair of problems, if and then . From a practical point of view, this means that r is a prerequisite of q. As a consequence, the state containing r but not q does not exist.
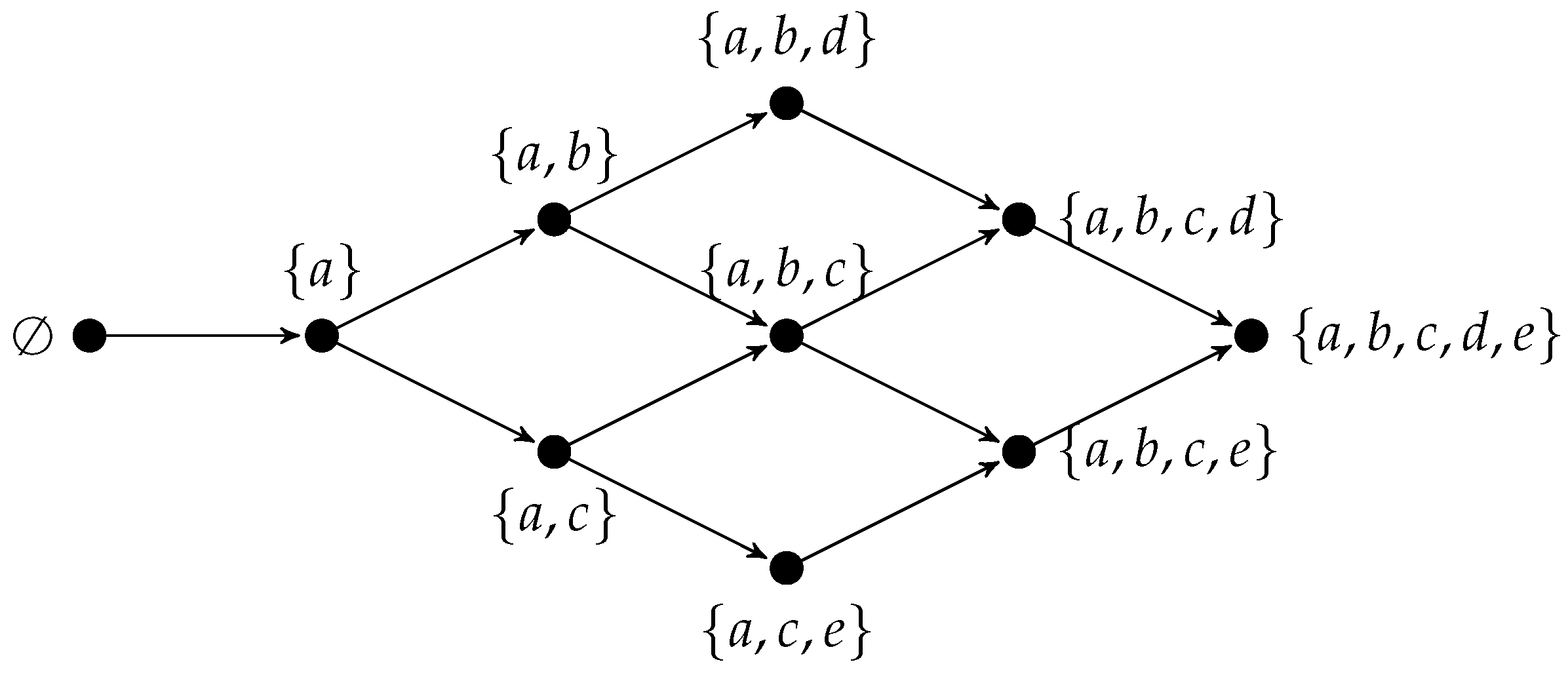
To provide an example, consider the knowledge domain
composed of five problems, and assume a precedence relation ≺ for which
and
. The following knowledge structure contains all those subsets of
Q that are consistent with the precedence relation ≺:
Figure 1 shows the Hasse diagram of
. In the diagram, each node represents a knowledge state, and an arrow from a left node to a right node indicates that the state on the left is a subset of the state to the right.
It can be noted that the empty set (i.e., the situation in which an individual cannot solve any problem) and the full set Q (i.e., the situation in which an individual knows everything) are knowledge states. Moreover, among the different subsets that can be formed with the 5 problems in Q, only 10 belong to . Given that , all states containing b also contain a, and all states containing d also contain both . A similar reasoning is applied to the other precedence relations.
Assuming that the knowledge state of an individual is , its outer fringe gives information about what the individual is ready to learn (i.e., problems c and d). Thus, the outer fringe is useful for personalizing learning, and reaching the educational needs of each individual.
Knowledge structures can be empirically validated via probabilistic models. Several probabilistic models are available in the literature [
69,
70,
71,
72,
73,
74,
75,
76,
77] that can be used, depending on the particular application context. Almost all of them are generalizations of the so-called basic local independence model (BLIM; [
78]). BLIM is a latent class model, where the latent classes are knowledge states. What is observed is a response pattern (i.e., the subset
R of items correctly solved) for each individual. The prediction of the knowledge state behind a response pattern is provided by estimating two parameters for each item
, representing the careless error (i.e.,
) and the lucky guess (i.e.,
) probabilities. Throughout the years, BLIM was studied in depth from both theoretical [
79,
80,
81,
82] and practical/application [
83,
84,
85] perspectives.
It is worth noting that the original development of KST is useful when dichotomous (correct/wrong) responses are available, and it is specifically meant for the knowledge assessment field of study. In recent years, some extensions of KST were proposed in order to generalize the theory to different fields of applications and different response type formats. For example, the polytomous KST [
86,
87,
88,
89,
90] allows for nominal, ordered, and partially ordered polytomous response scales.
An extension of KST that is relevant to the project presented in this paper is termed the
procedural knowledge space theory (PKST; [
26]). PKST is useful for the assessment of human problem-solving skills. To this aim, the novelty of the approach consists of modeling the whole solution process made by a problem solver, rather than considering the problem’s accuracy only. PKST is based on both problem space theory [
91] and KST. In fact, it provides a formal representation of the notion of
problem space and makes an algorithm for deriving a knowledge structure starting from a problem space available. The main concepts at the basis of the theory are briefly introduced below.
In PKST, all the problems in
Q are pairs
, and the objective is to transform an initial configuration
s into a target configuration
g. In a problem space, a solution path for a problem
is a pair
where
is the sequence of observable operations required to transform
s into
g. It is worth mentioning that a problem
may have multiple alternative solution paths. Moreover, the solution paths that solve the problems in
Q are partially ordered. In particular, a solution path
is a subpath of another solution path
, denoted as
if there are two sequences of operations
, and
, such that
is the sequence
, and the sequence
transforms
t into
s. The psychological interpretation of the relationship between a solution path and its subpaths is that “if an individual knows a solution path, then they also know all of its subpaths”. This interpretation is named the
problem–subproblem assumption. The straightforward implication is that an individual who knows how to solve problem
through the solution path
knows how to solve all the problems that are solved by any subpaths of
. A whole description of the deterministic foundation of PKST can be found in [
26] and in [
92].
Just like KST, the deterministic models of PKST need to be empirically validated. The latent class Markov solution process model (MSPM; [
92]) can be used for this purpose. The MSPM is useful for making predictions on both the observable solution process and the unobservable knowledge state (the latent class) on which the solution process is built. Under the MSPM, the probability of moving from one configuration of the problem to another one might take one of two alternative forms. One of them is conditional to the belonging of a problem to the knowledge state (i.e., the problem solver is able to plan at least one of the problem’s solution paths) and the other one is conditional to the ‘non-belonging’ of a problem to the knowledge state (i.e., the problem solver is not able to plan any of the problem’s solution paths).
One of the main fields of application of both KST and PKST is the adaptive assessment of knowledge. In this respect, precedence relations in KST and the problem–sub-problem assumptions in PKST play a central role. In brief, an adaptive assessment consists of administering items selected on previously observed responses. This has the effect of personalizing the assessment and minimizing the number of questions. In the KST framework, an example is as follows: If and an individual provides a correct answer for problem b, then it is plausible to assume (in a situation without noise) that she is able to solve item a. In the PKST framework, an example is as follows: if problem is solved by the path , and (i.e., is a subpath of ), then an individual who is able to solve is able to solve all those problems that are solved by . Precedent relations, on the one hand, and problem–subproblem assumptions, on the other hand, allow for the prediction of the answer.
In the KST framework, several types of adaptive algorithms have been proposed (see, e.g., [
78,
93,
94,
95,
96,
97]). The most used one is the continuous Markov procedure proposed by [
97]. The basic idea is that a likelihood function over the knowledge structure expresses the plausibility of the states. At each step of the assessment process, the likelihood function is updated according to the observed correct or wrong answer via a Bayesian rule that takes into account the careless error and lucky guess parameters of the items. The assessment terminates when the mass of the likelihood is concentrated on a single state, which is regarded as the uncovered state of the individual.
A similar algorithm was proposed by [
98] in the PKST framework. The main difference between the KST-based and the PKST-based algorithms is that the latter updates the likelihood on the basis of the whole observed solution process instead of using only the correct/wrong answer. In [
98], it was shown that the PKST-based algorithm outperforms the KST-based algorithm in terms of efficiency and accuracy since the former one employs more information from the observed data than the latter one.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}



