


Pareto Optimized Adaptive Learning with Transposed Convolution for Image Fusion Alzheimer’s Disease Classification

Abstract
:1. Introduction
Background
- The proposed model examined the effectiveness of the pareto optimized VGG model vs. traditional VGG variants in extracting significant features from MRI and PET data to assess how well these deep learning models can extract important features.
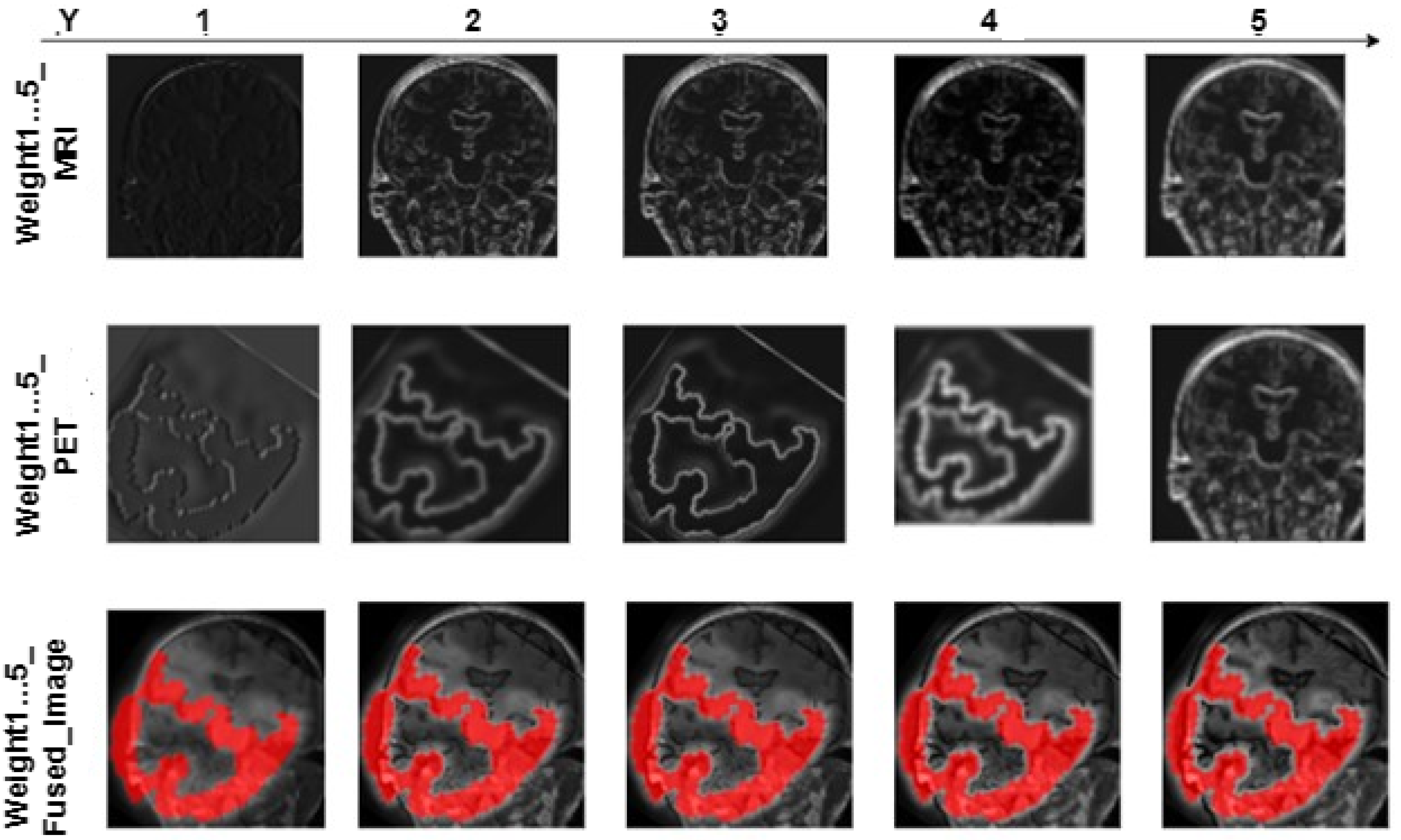
- Each convolution layer is examined to know the layer that produces the feature map with the best image quality.
- To enhance the effectiveness of VGG models, a pareto optimization and transposed convolution layer has been incorporated to enable the restoration of the feature map’s proportions while concurrently preserving spatial information.
- The incorporation of transposed convolution enhances the representation of the fused image, leading to an overall improvement in the effectiveness of the models.
2. Methods
2.1. Preprocessing of MRI and PET Images
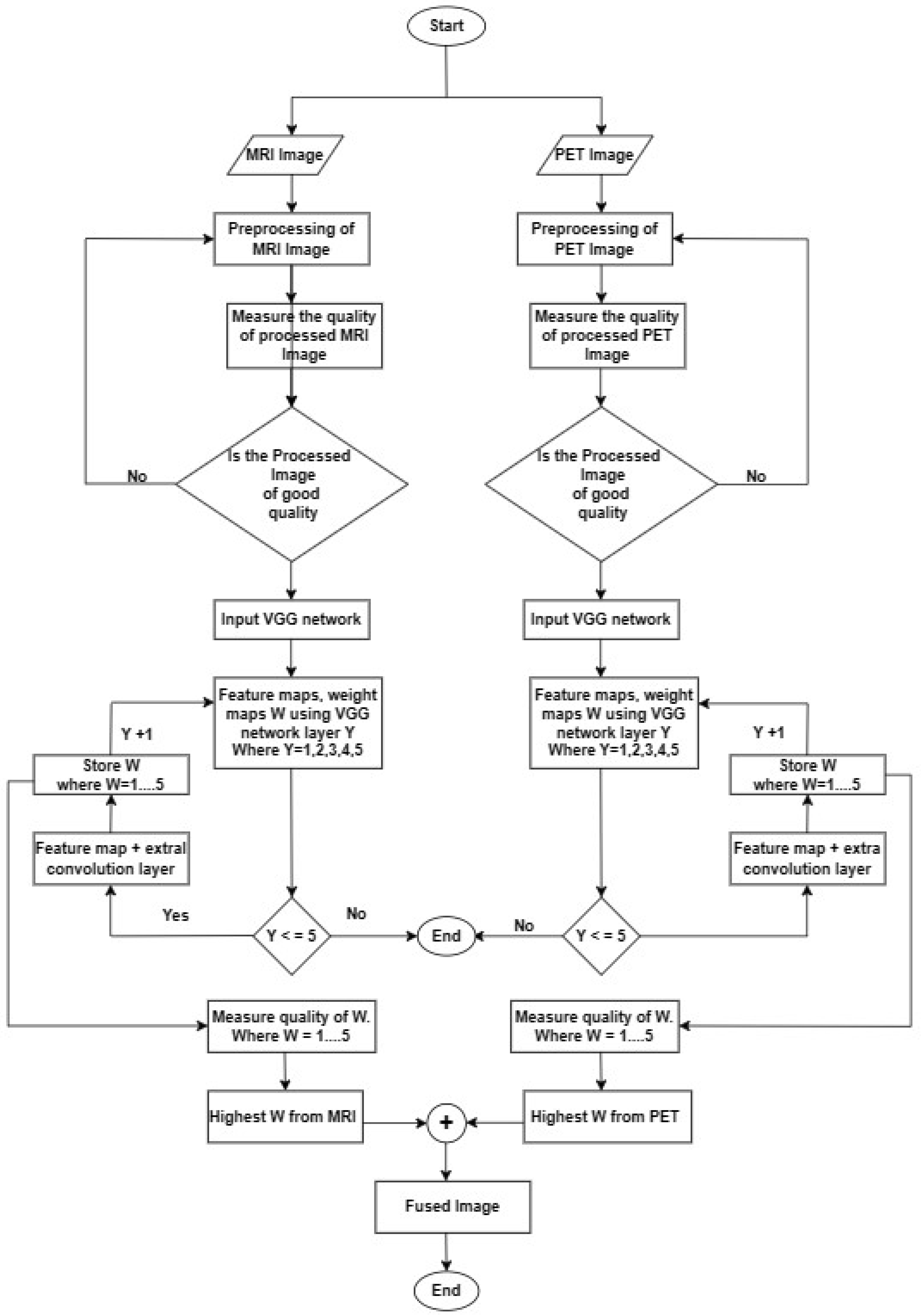
2.2. Proposed Fusion Technique of MRI and PET
2.3. VGG Convolutional Network Architecture
2.4. Transposed Convolution
2.5. Pareto Optimality
- (1)
- Feasibility: satisfies any constraints imposed on the hyperparameters.
- (2)
- Pareto Optimality: There does not exist another set of hyperparameters such that for all i, with at least one strict inequality. In other words, the hyperparameters are Pareto optimal if there is no other set of hyperparameters that can achieve better values for all the objectives simultaneously.
2.6. Summary
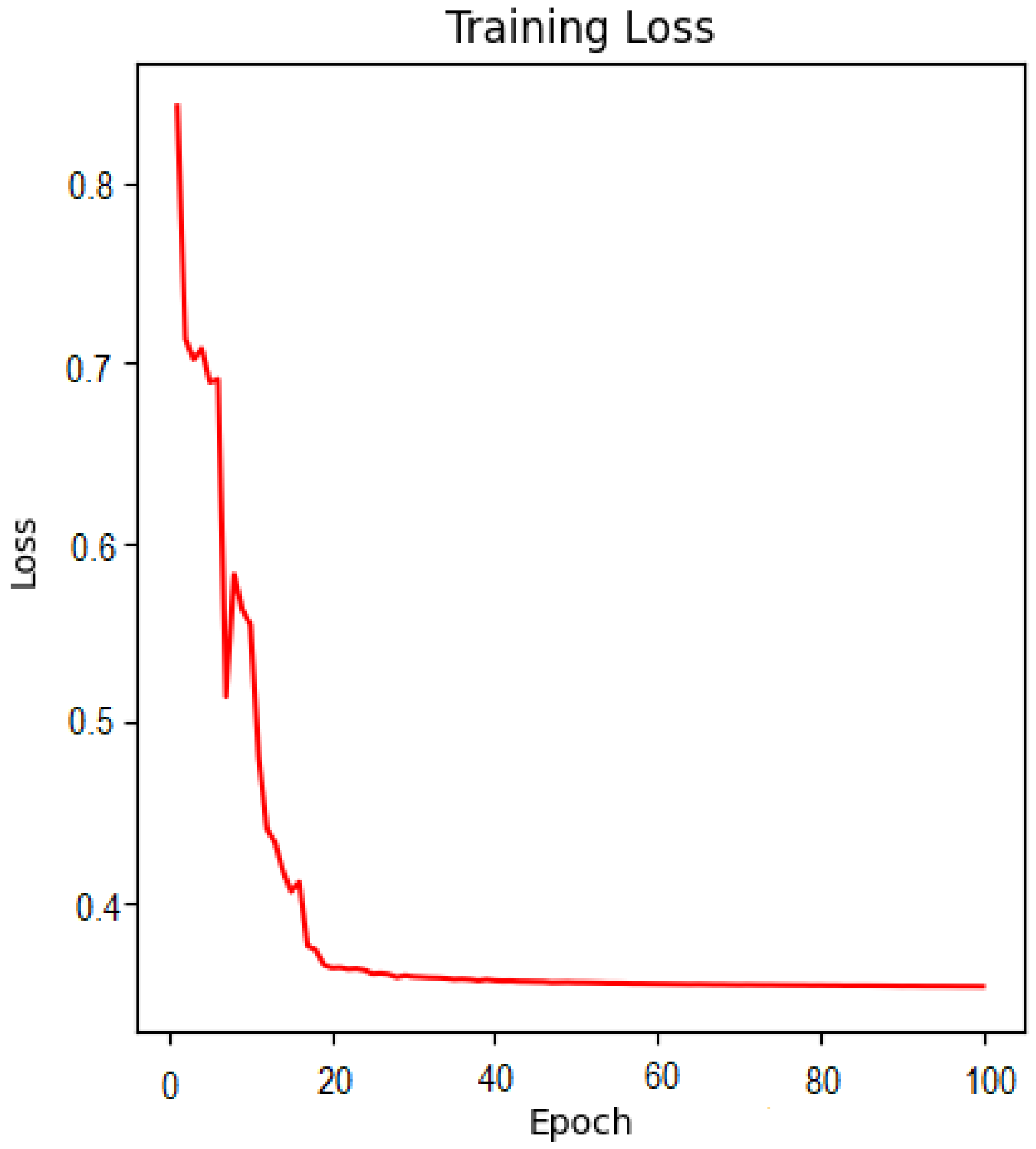
3. Experiments
4. Result
5. Discussion
5.1. Comparison to Other Image Fusion Techniques
5.2. Limitations
- The effectiveness of proposed method in extracting significant features from MRI and PET data may be limited to the specific datasets used in the study. It is important to assess its performance on a broader range of datasets to evaluate its generalizability to different imaging modalities and clinical settings.
- The proposed method should address the interpretability aspect to gain insights into the specific features extracted by the model and their clinical relevance.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fan, Z.; Li, Z.; Zhang, B.; Du, H.; Wang, B.; Zhang, X. Multi-modal deep learning model for auxiliary diagnosis of Alzheimer’s disease. Neurocomputing 2019, 361, 185–195. [Google Scholar] [CrossRef]
- Weiner, V.D.P.M.W.; Aisen, P.S.; Beckett, L.A.; DeCarli, C.; Green, R.C.; Harvey, D. Using the Alzheimer’s Disease Neuroimaging Initiative to improve early detection, diagnosis, and treatment of Alzheimer’s disease. J. Alzheimer’s Assoc. 2022, 18, 824–857. [Google Scholar] [CrossRef]
- Juan, S.; Zheng, J.; Li, P.; Lu, X.; Zhu, G.; Shen, P. An effective multimodal image fusion method using MRI and PET for Alzheimer’s disease diagnosis. Front. Digit. Health 2021, 3, 637386. [Google Scholar] [CrossRef]
- Ismail, W.N.; Rajeena, P.P.F.; Ali, M.A. MULTforAD: Multimodal MRI Neuroimaging for Alzheimer’s Disease Detection Based on a 3D Convolution Model. Electronics 2022, 11, 3893. [Google Scholar] [CrossRef]
- Ramya, J.; Maheswari, B.U.; Rajakumar, M.P.; Sonia, R. Alzheimer’s Disease Segmentation and Classification on MRI Brain Images Using Enhanced Expectation Maximization Adaptive Histogram (EEM-AH) and Machine Learning. Inf. Technol. Control 2022, 51, 786–800. [Google Scholar] [CrossRef]
- Odusami, M.; Maskeliūnas, R.; Damaševičius, R. An Intelligent System for Early Recognition of Alzheimer’s Disease Using Neuroimaging. Sensors 2022, 22, 740. [Google Scholar] [CrossRef] [PubMed]
- Morteza, A.; Pedram, M.M.; Moradi, A.; Jamshidi, M.; Ouchani, M. Single and Combined Neuroimaging Techniques for Alzheimer’s Disease Detection. Comput. Intell. Neurosci. 2021, 2021, e9523039. [Google Scholar] [CrossRef]
- Odusami, M.; Maskeliūnas, R.; Damaševičius, R. Pixel-Level Fusion Approach with Vision Transformer for Early Detection of Alzheimer’s Disease. Electronics 2023, 12, 1218. [Google Scholar] [CrossRef]
- Odusami, M.; Maskeliūnas, R.; Damaševičius, R.; Misra, S. Explainable Deep-Learning-Based Diagnosis of Alzheimer’s Disease Using Multimodal Input Fusion of PET and MRI Images. J. Med. Biol. Eng. 2023, 43, 291–302. [Google Scholar] [CrossRef]
- Bibo, S.; Chen, Y.; Zhang, P.; Smith, C.D.; Liu, J. Nonlinear feature transformation and deep fusion for Alzheimer’s Disease staging analysis. Pattern Recognit. 2017, 63, 487–498. [Google Scholar] [CrossRef] [Green Version]
- Xiaoke, H.; Bao, Y.; Guo, Y.; Yu, M.; Zhang, D.; Risacher, S.L.; Saykin, A.J.; Yao, X.; Shen, L.; Alzheimer’s Disease Neuroimaging Initiative. Multi-modal neuroimaging feature selection with consistent metric constraint for diagnosis of Alzheimer’s disease. Med. Image Anal. 2020, 60, 101625. [Google Scholar] [CrossRef]
- Manhua, L.; Cheng, D.; Wang, K.; Wang, Y.; Alzheimer’s Disease Neuroimaging Initiative. Multi-Modality Cascaded Convolutional Neural Networks for Alzheimer’s Disease Diagnosis. Neuroinformatics 2018, 16, 295–308. [Google Scholar] [CrossRef]
- Heung-I, S.; Lee, S.W.; Shen, D.; Alzheimer’s Disease Neuroimaging Initiative. Deep sparse multi-task learning for feature selection in Alzheimer’s disease diagnosis. Brain Struct. Funct. 2016, 221, 2569–2587. [Google Scholar] [CrossRef] [Green Version]
- Lei, B.; Yang, P.; Wang, T.; Chen, S.; Ni, D. Relational-Regularized Discriminative Sparse Learning for Alzheimer’s Disease Diagnosis. IEEE Trans. Cybern. 2017, 47, 1102–1113. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, Y.; Chen, B.Y.; Shen, L.; He, L. Sparse Interpretation of Graph Convolutional Networks for Multi-modal Diagnosis of Alzheimer’s Disease. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2022: 25th International Conference, Singapore, 18–22 September 2022; Proceedings, Part VIII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 469–478. [Google Scholar]
- Zhou, T.; Thung, K.H.; Liu, M.; Shi, F.; Zhang, C.; Shen, D. Multi-modal latent space inducing ensemble SVM classifier for early dementia diagnosis with neuroimaging data. Med. Image Anal. 2020, 60, 101630. [Google Scholar] [CrossRef] [PubMed]
- Youssofzadeh, V.; McGuinness, B.; Maguire, L.P.; Wong-Lin, K. Multi-Kernel Learning with Dartel Improves Combined MRI-PET Classification of Alzheimer’s Disease in AIBL Data: Group and Individual Analyses. Front. Hum. Neurosci. 2017, 11, 380. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y.; Zu, C.; Hong, M.; Zhou, L.; Wang, L.; Wu, X.; Zhou, J.; Zhang, D.; Wang, Y. ASMFS: Adaptive-similarity-based multi-modality feature selection for classification of Alzheimer’s disease. Pattern Recognit. 2022, 126, 108566. [Google Scholar] [CrossRef]
- Pan, Z.W.; Shen, H.L. Multispectral Image Super-Resolution via RGB Image Fusion and Radiometric Calibration. IEEE Trans. Image Process. 2018, 28, 1783–1797. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, J.; Wang, Z. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, J.; Wang, Z. Multimodality Alzheimer’s Disease Analysis in Deep Riemannian Manifold. Inf. Process. Manag. 2022, 59, 102965. [Google Scholar] [CrossRef]
- Dwivedi, S.; Goel, T.; Tanveer, M.; Murugan, R.; Sharma, R. Multi-modal fusion based deep learning network for effective diagnosis of Alzheimers disease. IEEE Multimed. 2022, 29, 45–55. [Google Scholar] [CrossRef]
- Wang, S.; Celebi, M.E.; Zhang, Y.D.; Yu, X.; Lu, S.; Yao, X.; Zhou, Q. Advances in Data Preprocessing for Biomedical Data Fusion: An Overview of the Methods, Challenges, and Prospects. Inf. Fusion 2021, 76, 376–421. [Google Scholar] [CrossRef]
- Li, W.; Wang, Y.; Su, Y.; Li, X.; Liu, A.A.; Zhang, Y. Multi-Scale Fine-Grained Alignments for Image and Sentence Matching. IEEE Trans. Multimed. 2023, 25, 543–556. [Google Scholar] [CrossRef]
- Rallabandi, V.S.; Seetharaman, K. Deep learning-based classification of healthy aging controls, mild cognitive impairment and Alzheimer’s disease using fusion of MRI-PET imaging. Biomed. Signal Process. Control. 2023, 80, 104312. [Google Scholar] [CrossRef]
- Tirupal, T.; Vaishnavi, T.N.; Anitha, K.; Lavanya, K.; Sandhya, E. Medical Image Fusion using Undecimated Discrete Wavelet Transform for Analysis and Detection of Alzheimer’s Disease. Elixir Comput. Eng. 2019, 137, 53905–53910. [Google Scholar]
- Panigrahy, C.; Seal, A.; Gonzalo-Martín, C.; Pathak, P.; Jalal, A.S. Parameter adaptive unit-linking pulse coupled neural network based MRI–PET/SPECT image fusion. Biomed. Signal Process. Control 2023, 83, 104659. [Google Scholar] [CrossRef]
- Ouerghi, H.; Mourali, O.; Zagrouba, E. Non-subsampled shearlet transform based MRI and PET brain image fusion using simplified pulse coupled neural network and weight local features in YIQ colour space. IET Image Process. 2018, 12, 1873–1880. [Google Scholar] [CrossRef]
- Liu, Z.; Song, Y.; Sheng, V.S.; Xu, C.; Maere, C.; Xue, K.; Yang, K. MRI and PET image fusion using the nonparametric density model and the theory of variable-weight. Comput. Methods Programs Biomed. 2019, 175, 73–82. [Google Scholar] [CrossRef]
- Li, Y.; Sun, Y.; Huang, X.; Qi, G.; Zheng, M.; Zhu, Z. An image fusion method based on sparse representation and sum modified-Laplacian in NSCT domain. Entropy 2018, 20, 522. [Google Scholar] [CrossRef] [Green Version]
- Saleh, M.A.; Ali, A.A.; Ahmed, K.; Sarhan, A.M. A Brief Analysis of Multimodal Medical Image Fusion Techniques. Electronics 2022, 12, 97. [Google Scholar] [CrossRef]
- Ge, Y.r.; Li, X.n. Image fusion algorithm based on pulse coupled neural networks and nonsubsampled contourlet transform. In Proceedings of the 2010 Second International Workshop on Education Technology and Computer Science, Wuhan, China, 6–7 March 2010; Volume 3, pp. 27–30. [Google Scholar] [CrossRef]
- Wang, Z.; Li, X.; Duan, H.; Su, Y.; Zhang, X.; Guan, X. Medical image fusion based on convolutional neural networks and non-subsampled contourlet transform. Expert Syst. Appl. 2021, 171, 114574. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Lahoud, F.; Süsstrunk, S. Zero-learning fast medical image fusion. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Deng, X.; Liu, E.; Li, S.; Duan, Y.; Xu, M. Interpretable Multi-Modal Image Registration Network Based on Disentangled Convolutional Sparse Coding. IEEE Trans. Image Process. 2023, 32, 1078–1091. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Yang, B.; Wang, Y.; Tian, J.; Yin, L.; Zheng, W. 2D/3D Multimode Medical Image Registration Based on Normalized Cross-Correlation. Appl. Sci. 2022, 12, 2828. [Google Scholar] [CrossRef]
- Hussain, A.; Khunteta, A. Semantic segmentation of brain tumor from MRI images and SVM classification using GLCM features. In Proceedings of the 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 15–17 July 2020; pp. 38–43. [Google Scholar] [CrossRef]
- Jia, Z.; Chen, D. Brain tumor identification and classification of MRI images using deep learning techniques. IEEE Access 2020. [Google Scholar] [CrossRef]
- Lepcha, D.C.; Goyal, B.; Dogra, A.; Wang, S.H.; Chohan, J.S. Medical image enhancement strategy based on morphologically processing of residuals using a special kernel. Expert Syst. 2022, e13207. [Google Scholar] [CrossRef]
- Zhou, J.; Yang, X.; Zhang, L.; Shao, S.; Bian, G. Multisignal VGG19 network with transposed convolution for rotating machinery fault diagnosis based on deep transfer learning. Shock Vib. 2020, 2020, 8863388. [Google Scholar] [CrossRef]
- Jha, D.; Riegler, M.A.; Johansen, D.; Halvorsen, P.; Johansen, H.D. Doubleu-net: A deep convolutional neural network for medical image segmentation. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; pp. 558–564. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, H.; Lu, X.; Lu, Y. DenseUNet: Improved image classification method using standard convolution and dense transposed convolution. Knowl.-Based Syst. 2022, 254, 109658. [Google Scholar] [CrossRef]
- Machida, K.; Nambu, I.; Wada, Y. Transposed Convolution as Alternative Preprocessor for Brain-Computer Interface Using Electroencephalogram. Appl. Sci. 2023, 13, 3578. [Google Scholar] [CrossRef]
- Lu, Y.; Qiu, Y.; Gao, Q.; Sun, D. Infrared and visible image fusion based on tight frame learning via VGG19 network. Digit. Signal Process. 2022, 131, 103745. [Google Scholar] [CrossRef]
- Amini, N.; Mostaar, A. Deep learning approach for fusion of magnetic resonance imaging-positron emission tomography image based on extract image features using pretrained network (VGG19). J. Med. Signals Sens. 2022, 12, 25. [Google Scholar] [CrossRef] [PubMed]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Metrics | |||
|---|---|---|---|---|
| SSIM | PSNR | MSE | E | |
| VGG19 | ||||
| MRI (CN) | 0.680 | 35.43 | 0.15 | 2.850 |
| MRI (AD) | 0.802 | 35.93 | 0.12 | 4.510 |
| MRI (MCI) | 0.664 | 34.31 | 0.20 | 2.750 |
| PET (CN) | 0.669 | 34.18 | 0.28 | 2.830 |
| PET (AD) | 0.815 | 36.01 | 0.10 | 4.602 |
| PET (MCI) | 0.660 | 34.02 | 0.28 | 2.822 |
| VGG16 | ||||
| MRI (CN) | 0.670 | 33.90 | 0.30 | 2.840 |
| MRI (AD) | 0.790 | 35.10 | 0.29 | 3.540 |
| MRI (MCI) | 0.600 | 32.90 | 0.40 | 2.620 |
| PET (CN) | 0.650 | 33.80 | 0.30 | 2.630 |
| PET (AD) | 0.602 | 33.40 | 0.35 | 2.605 |
| PET (MCI) | 0.602 | 32.90 | 0.40 | 2.605 |
| VGG11 | ||||
| MRI (CN) | 0.560 | 33.50 | 0.40 | 1.548 |
| MRI (AD) | 0.580 | 33.90 | 0.30 | 1.552 |
| MRI (MCI) | 0.580 | 33.90 | 0.30 | 1.552 |
| PET (CN) | 0.650 | 33.85 | 0.30 | 1.540 |
| PET (AD) | 0.604 | 33.40 | 0.45 | 1.460 |
| PET (MCI) | 0.570 | 33.90 | 0.40 | 1.550 |
| Metrics | Without Transposition Layer | With Transposition Layer | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| W1 | W2 | W3 | W4 | W5 | W1 | W2 | W3 | W4 | W5 | |
| MRI (CN) | ||||||||||
| SIMM | 0.585 | 0.560 | 0.560 | 0.558 | 0.558 | 0.680 | 0.660 | 0.660 | 0.645 | 0.640 |
| PSNR | 29.280 | 29.200 | 29.200 | 29.180 | 29.180 | 35.430 | 35.400 | 35.400 | 35.300 | 35.280 |
| MSE | 0.350 | 0.320 | 0.320 | 0.310 | 0.310 | 0.150 | 0.190 | 0.190 | 0.210 | 0.210 |
| E | 1.950 | 1.900 | 1.900 | 1.890 | 1.890 | 2.850 | 2.760 | 2.760 | 2.680 | 2.650 |
| APT (s) | 0.006 | 0.006 | 0.007 | 0.007 | 0.008 | 0.007 | 0.008 | 0.008 | 0.008 | 0.009 |
| MRI (AD) | ||||||||||
| SIMM | 0.702 | 0.690 | 0.680 | 0.678 | 0.678 | 0.802 | 0.0701 | 0.690 | 0.690 | 0.689 |
| PSNR | 35.850 | 35.800 | 35.700 | 35.700 | 35.700 | 36.930 | 35.930 | 35.800 | 35.800 | 35.800 |
| MSE | 0.180 | 0.180 | 0.170 | 0.170 | 0.170 | 0.120 | 0.130 | 0.180 | 0.180 | 0.180 |
| E | 4.025 | 3.290 | 3.172 | 3.164 | 3.164 | 4.510 | 4.005 | 3.290 | 3.290 | 3.180 |
| APT (s) | 0.006 | 0.007 | 0.007 | 0.008 | 0.008 | 0.007 | 0.008 | 0.008 | 0.009 | 0.010 |
| MRI (MCI) | ||||||||||
| SIMM | 0.560 | 0.560 | 0.540 | 0.540 | 0.538 | 0.664 | 0.654 | 0.652 | 0.650 | 0.650 |
| PSNR | 29.200 | 29.200 | 29.010 | 29.010 | 29.010 | 34.310 | 34.280 | 34.280 | 34.280 | 34.280 |
| MSE | 0.380 | 0.400 | 0.400 | 0.400 | 0.400 | 0.200 | 0.220 | 0.220 | 0.220 | 0.220 |
| E | 1.900 | 1.900 | 1.700 | 1.700 | 1.690 | 2.750 | 2.740 | 2.740 | 2.740 | 2.740 |
| APT (s) | 0.006 | 0.007 | 0.007 | 0.008 | 0.008 | 0.007 | 0.008 | 0.008 | 0.009 | 0.010 |
| PET (CN) | ||||||||||
| SIMM | 0.578 | 0.570 | 0.570 | 0.570 | 0.563 | 0.699 | 0.680 | 0.680 | 0.679 | 0.679 |
| PSNR | 29.250 | 29.230 | 29.230 | 29.23 | 29.200 | 35.180 | 34.120 | 34.120 | 34.090 | 34.090 |
| MSE | 0.350 | 0.360 | 0.360 | 0.360 | 0.400 | 0.280 | 0.300 | 0.300 | 0.320 | 0.320 |
| E | 1.998 | 1.908 | 1.908 | 1.908 | 1.899 | 2.830 | 2.730 | 2.730 | 2.690 | 2.690 |
| APT (s) | 0.006 | 0.006 | 0.007 | 0.007 | 0.008 | 0.007 | 0.008 | 0.008 | 0.009 | 0.010 |
| PET (AD) | ||||||||||
| SIMM | 0.540 | 0.538 | 0.530 | 0.530 | 0.530 | 0.815 | 0.661 | 0.658 | 0.658 | 0.650 |
| PSNR | 29.010 | 29.010 | 28.990 | 28.990 | 28.990 | 36.990 | 35.610 | 35.500 | 35.500 | 35.480 |
| MSE | 0.400 | 0.400 | 0.420 | 0.420 | 0.420 | 0.100 | 0.120 | 0.120 | 0.120 | 0.130 |
| E | 1.700 | 1.652 | 1.650 | 1.650 | 1.650 | 4.602 | 2.745 | 2.748 | 2.748 | 2.740 |
| APT (s) | 0.006 | 0.007 | 0.007 | 0.008 | 0.008 | 0.007 | 0.008 | 0.008 | 0.009 | 0.010 |
| PET (MCI) | ||||||||||
| SIMM | 0.537 | 0.520 | 0.520 | 0.520 | 0.513 | 0.660 | 0.650 | 0.652 | 0.652 | 0.650 |
| PSNR | 29.010 | 28.900 | 28.990 | 28.990 | 28.800 | 34.280 | 34.290 | 34.080 | 34.080 | 34.020 |
| MSE | 0.430 | 0.450 | 0.450 | 0.450 | 0.450 | 0.48 | 0.280 | 0.280 | 0.300 | 0.300 |
| E | 1.655 | 1.640 | 1.640 | 1.640 | 1.638 | 2.822 | 2.801 | 2.810 | 2.810 | 2.798 |
| APT (s) | 0.006 | 0.007 | 0.007 | 0.008 | 0.008 | 0.007 | 0.008 | 0.008 | 0.009 | 0.009 |
| Proposed Model | Time | Hardware |
|---|---|---|
| With transposition convolution | 0.003 | GPU |
| Without transposition convolution (not optimized) | 0.006 | GPU |
| Reference | Method | SIMM | PSNR | MSE | E |
|---|---|---|---|---|---|
| [12] | DWT with transfer learning | 0.779 | - | - | - |
| [27] | PCNN with parameter adaptive | 0.7184 | - | - | 4.496 |
| [28] | NSST coupled with PCNN | - | - | - | 4.754 |
| [12] | NSCT | - | - | - | 2.174 |
| Proposed Model | Pareto optimized VGG19 with transposed layer | 0.802 | 36.93 | 0.12 | 4.510 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Odusami, M.; Maskeliūnas, R.; Damaševičius, R. Pareto Optimized Adaptive Learning with Transposed Convolution for Image Fusion Alzheimer’s Disease Classification. Brain Sci. 2023, 13, 1045. https://doi.org/10.3390/brainsci13071045
Odusami M, Maskeliūnas R, Damaševičius R. Pareto Optimized Adaptive Learning with Transposed Convolution for Image Fusion Alzheimer’s Disease Classification. Brain Sciences. 2023; 13(7):1045. https://doi.org/10.3390/brainsci13071045
Chicago/Turabian StyleOdusami, Modupe, Rytis Maskeliūnas, and Robertas Damaševičius. 2023. "Pareto Optimized Adaptive Learning with Transposed Convolution for Image Fusion Alzheimer’s Disease Classification" Brain Sciences 13, no. 7: 1045. https://doi.org/10.3390/brainsci13071045