
Strategic Processing of Gender Stereotypes in Sentence Comprehension: An ERP Study


Abstract
:1. Introduction
2. Methods
2.1. Participants
2.2. Materials and Normative Measures
2.3. Procedure
2.4. EEG Recording and ERP Data Analysis
3. Results
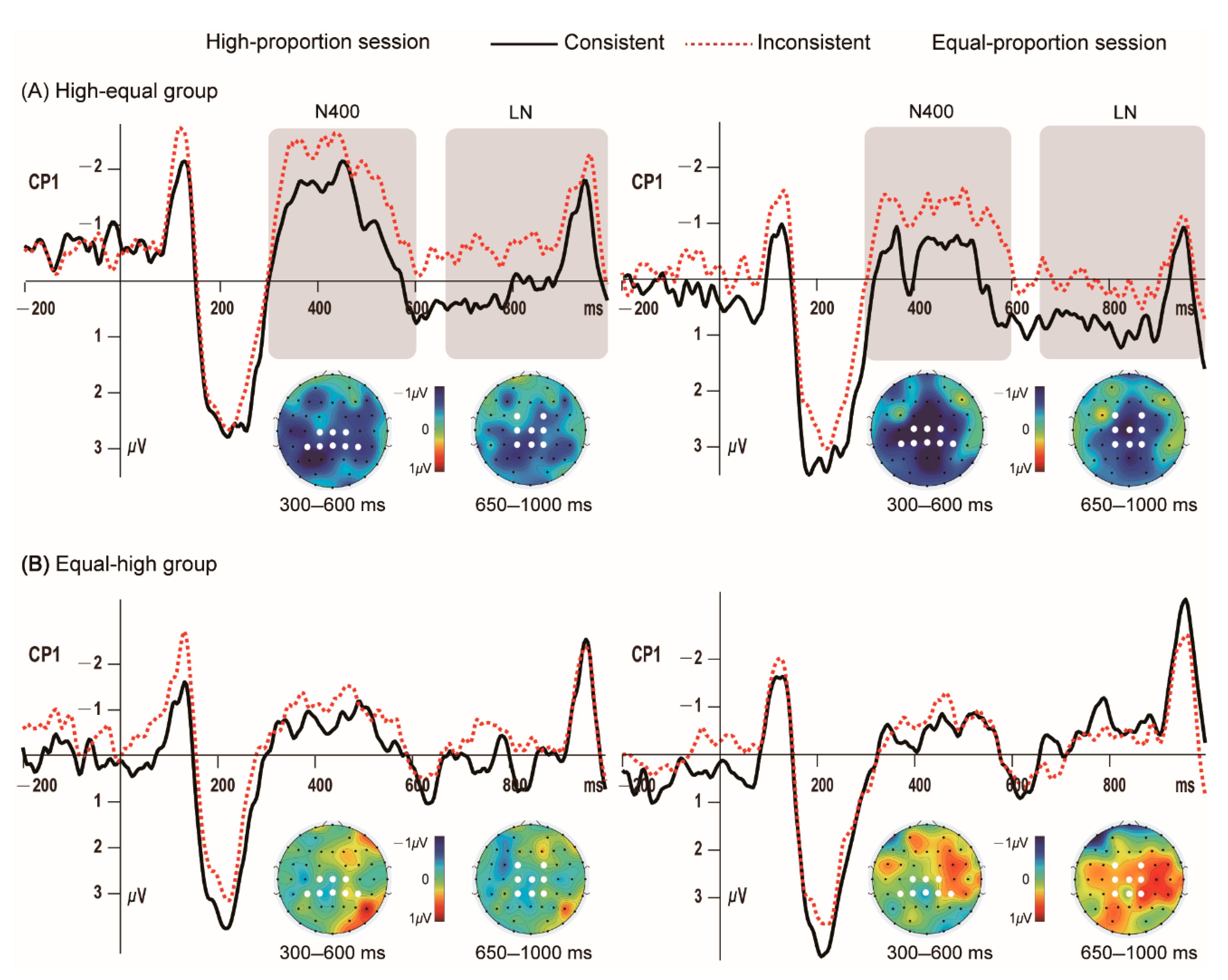
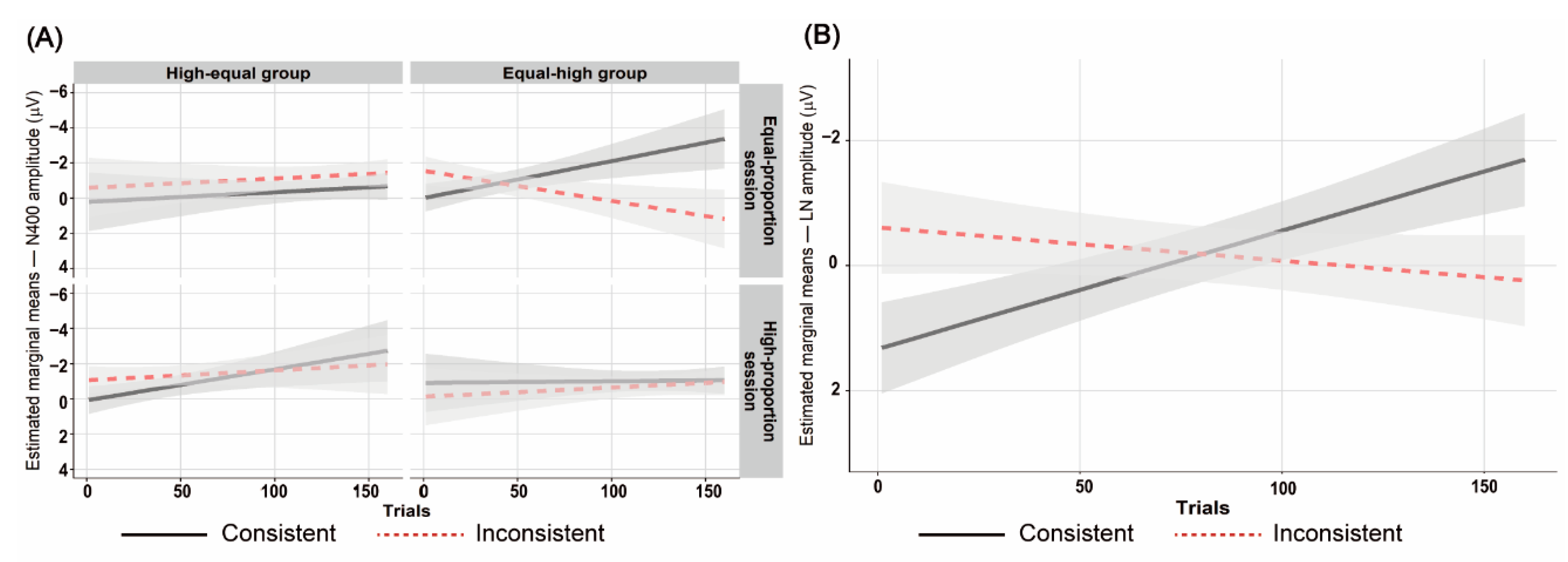
3.1. The 300–600 ms Time Window
3.2. The 650–1000 ms Time Window
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Carreiras, M. The use of stereotypical gender information in constructing a mental model: Evidence from English and Spanish. Q. J. Exp. Psychol. 1996, 49, 639–663. [Google Scholar] [CrossRef]
- Kreiner, H.; Sturt, P.; Garrod, S. Processing definitional and stereotypical gender in reference resolution: Evidence from eye-movements. J. Mem. Lang. 2008, 58, 239–261. [Google Scholar] [CrossRef]
- Kreiner, H.; Mohr, S.; Kessler, K.; Garrod, S. Can context affect gender processing? ERP differences between definitional and stereotypical gender. In Brain Talk: Discourse with and in the Brain: Papers from the First Birgit Rausing Language Program Conference in Linguistics, Lund, June 2008 (Birgit Rausing Language Program Conference Series in Linguistics; Volume 1); Alter, K., Horne, M., Lindgren, M., Roll, M., von Koss Torkildsen, J., Eds.; Media-Tryck: Lund, Sweden, 2009; pp. 107–119. [Google Scholar]
- Reynolds, D.J.; Garnham, A.; Oakhill, J. Evidence of immediate activation of gender information from a social role name. Q. J. Exp. Psychol. 2006, 59, 886–903. [Google Scholar] [CrossRef]
- Duffy, S.A.; Keir, J.A. Violating stereotypes: Eye movements and comprehension processes when text conflicts with world knowledge. Mem. Cognit. 2004, 32, 551–559. [Google Scholar] [CrossRef] [Green Version]
- Molinaro, N.; Su, J.J.; Carreiras, M. Stereotypes override grammar: Social knowledge in sentence comprehension. Brain Lang. 2016, 155, 36–43. [Google Scholar] [CrossRef] [PubMed]
- Proverbio, A.M.; Orlandi, A.; Bianchi, E. Electrophysiological markers of prejudice related to sexual gender. Neuroscience 2017, 358, 1–12. [Google Scholar] [CrossRef]
- Proverbio, A.M.; Alberio, A.; De Benedetto, F. Neural correlates of automatic beliefs about gender stereotypes: Males are more prejudicial. Brain Lang. 2018, 186, 8–16. [Google Scholar] [CrossRef] [PubMed]
- Osterhout, L.; Bersick, M.; McLaughlin, J. Brain potentials reflect violations of gender stereotypes. Mem. Cognit. 1997, 25, 273–285. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wicha, N.Y.; Moreno, E.M.; Kutas, M. Anticipating words and their gender: An event-related brain potential study of semantic integration, gender expectancy, and gender agreement in Spanish sentence reading. J. Cogn. Neurosci. 2004, 16, 1272–1288. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Banaji, M.R.; Hardin, C.D. Automatic stereotypes. Psychol. Sci. 1996, 7, 136–142. [Google Scholar] [CrossRef]
- Oakhill, J.; Garnham, A.; Reynolds, D. Immediate activation of stereotypical gender information. Mem. Cognit. 2005, 33, 972–983. [Google Scholar] [CrossRef] [PubMed]
- Pesciarelli, F.; Scorolli, C.; Cacciari, C. Neural correlates of the implicit processing of grammatical and stereotypical gender violations: A masked and unmasked priming study. Biol. Psychol. 2019, 146, 107714. [Google Scholar] [CrossRef]
- Siyanova-Chanturia, A.; Pesciarelli, F.; Cacciari, C. The electrophysiological underpinnings of processing gender stereotypes in language. PLoS ONE 2012, 7, e48712. [Google Scholar] [CrossRef] [Green Version]
- Irmen, L.; Holt, D.V.; Weisbrod, M. Effects of role typicality on processing person information in German: Evidence from an ERP study. Brain Res. 2010, 1353, 133–144. [Google Scholar] [CrossRef] [PubMed]
- Qiu, L.; Swaab, T.Y.; Chen, H.C.; Wang, S. The role of gender information in pronoun resolution: Evidence from Chinese. PLoS ONE 2012, 7, e36156. [Google Scholar] [CrossRef] [Green Version]
- Garnham, A.; Oakhill, J.; Reynolds, D. Are inferences from stereotyped role names to characters’ gender made elaboratively? Mem. Cognit. 2002, 30, 439–446. [Google Scholar] [CrossRef] [PubMed]
- Brothers, T.; Swaab, T.Y.; Traxler, M.J. Goals and strategies influence lexical prediction during sentence comprehension. J. Mem. Lang. 2017, 93, 203–216. [Google Scholar] [CrossRef] [Green Version]
- Delaney-Busch, N.; Morgan, E.; Lau, E.; Kuperberg, G.R. Neural evidence for Bayesian trial-by-trial adaptation on the N400 during semantic priming. Cognition 2019, 187, 10–20. [Google Scholar] [CrossRef]
- Hahne, A.; Friederici, A.D. Electrophysiological evidence for two steps in syntactic analysis: Early automatic and late controlled processes. J. Cogn. Neurosci. 1999, 11, 194–205. [Google Scholar] [CrossRef]
- Lau, E.F.; Holcomb, P.J.; Kuperberg, G.R. Dissociating N400 effects of prediction from association in single-word contexts. J. Cogn. Neurosci. 2013, 25, 484–502. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Chen, X.; Su, Q.; Liu, S.; Huang, J. Adapt retrieval rules and inhibit already-existing world knowledge: Adjustment of world knowledge’s activation level in auditory sentence comprehension. Lang. Cogn. 2019, 11, 645–668. [Google Scholar] [CrossRef]
- Ness, T.; Meltzer-Asscher, A. Rational adaptation in lexical prediction: The influence of prediction strength. Front. Psychol. 2021, 12, 622873. [Google Scholar] [CrossRef] [PubMed]
- Nieuwland, M.S. How ‘rational’ is semantic prediction? A critique and re-analysis of. Cognition 2021, 215, 104848. [Google Scholar] [CrossRef]
- Nieuwland, M.S. Commentary: Rational adaptation in lexical prediction: The influence of prediction strength. Front. Psychol. 2021, 12, 735849. [Google Scholar] [CrossRef] [PubMed]
- Yano, M.; Suwazono, S.; Arao, H.; Yasunaga, D.; Oishi, H. Selective adaptation in sentence comprehension: Evidence from event-related brain potentials. Q. J. Exp. Psychol. 2021, 74, 645–668. [Google Scholar] [CrossRef]
- Zhang, W.; Chow, W.Y.; Liang, B.; Wang, S. Robust effects of predictability across experimental contexts: Evidence from event-related potentials. Neuropsychologia 2019, 134, 107229. [Google Scholar] [CrossRef]
- Du, Y.; Zhang, Y. Discourse context immediately overrides gender stereotypes during discourse reading: Evidence from ERPs. Brain Sci. 2023, 13, 387. [Google Scholar] [CrossRef]
- Hagoort, P. Interplay between syntax and semantics during sentence comprehension: Erp effects of combining syntactic and semantic violations. J. Cogn. Neurosci. 2003, 15, 883–899. [Google Scholar] [CrossRef] [Green Version]
- Christensen, R.H.B. Ordinal—Regression Models for Ordinal Data (Version 2019.12-10). 2019. Available online: https://CRAN.Rproject.org/package=ordinal (accessed on 30 October 2020).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: http://www.r-project.org/ (accessed on 15 October 2020).
- Schad, D.J.; Vasishth, S.; Hohenstein, S.; Kliegl, R. How to capitalize on a priori contrasts in linear (mixed) models: A tutorial. J. Mem. Lang. 2020, 110, 104038. [Google Scholar] [CrossRef]
- Barr, D.J.; Levy, R.; Scheepers, C.; Tily, H.J. Random effects structure for confirmatory hypothesis testing: Keep it maximal. J. Mem. Lang. 2013, 68, 255–278. [Google Scholar] [CrossRef] [Green Version]
- Osterhout, L.; McLaughlin, J.; Kim, A.; Greenwald, R.; Inoue, K. Sentences in the brain: Event related potentials as real time reflections of sentence comprehension and language learning. In The On-Line Study of Sentence Comprehension: Eye Tracking. ERP and Beyond; Carreiras, M., Clifton, J., Eds.; Psychology Press: New York, NY, USA, 2004; pp. 271–308. [Google Scholar]
- Steinhauer, K.; Drury, J.E. On the early left-anterior negativity (elan) in syntax studies. Brain Lang. 2012, 120, 135–162. [Google Scholar] [CrossRef] [PubMed]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [Green Version]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Brockhoff, P.B.; Christensen, R.H.B. lmerTest package: Tests in linear mixed effects models. J. Stat. Softw. 2017, 82, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Alday, P.M. How much baseline correction do we need in ERP research? Extended GLM model can replace baseline correction while lifting its limits. Psychophysiology 2019, 56, e13451. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Matuschek, H.; Kliegl, R.; Vasishth, S.; Baayen, H.; Bates, D. Balancing Type I error and power in linear mixed models. J. Mem. Lang. 2017, 94, 305–315. [Google Scholar] [CrossRef]
- Fox, J.; Weisberg, S. An R Companion to Applied Regression, 3rd ed.; Sage: London, UK, 1999; ISBN 978-1-5443-3647-3. Available online: https://socialsciences.mcmaster.ca/jfox/Books/Companion/ (accessed on 20 October 2020).
- Lenth, R.V.; Buerkner, P.; Herve, M.; Jung, M.; Love, J.; Miguez, F.; Riebl, H.; Singmann, H. Emmeans: Estimated Marginal Means, Aka Least-Squares Means (Version 1.5.1). 2020. Available online: https://github.com/rvlenth/emmeans (accessed on 16 October 2020).
- Fine, A.B.; Jaeger, T.F. The role of verb repetition in cumulative structural priming in comprehension. J. Exp. Psychol. Learn. Mem. Cogn. 2016, 42, 1362–1376. [Google Scholar] [CrossRef]
- Fine, A.B.; Jaeger, T.F.; Farmer, T.A.; Qian, T. Rapid expectation adaptation during syntactic comprehension. PLoS ONE 2013, 8, e77661. [Google Scholar] [CrossRef] [Green Version]
- Yan, S.; Jaeger, T.F. Expectation adaptation during natural reading. Lang. Cogn. Neurosci. 2020, 35, 1394–1422. [Google Scholar] [CrossRef]
- MacGregor-Fors, I.; Payton, M.E. Contrasting diversity values: Statistical inferences based on overlapping confidence intervals. PLoS ONE 2013, 8, e56794. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.; Li, Y.; Zhou, X. Even a rich man can afford that expensive house: ERP responses to construction-based pragmatic constraints during sentence comprehension. Neuropsychologia 2013, 51, 1857–1866. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Li, Y.; Zhou, X. Is it over-respectful or disrespectful? Differential patterns of brain activity in perceiving pragmatic violation of social status information during utterance comprehension. Neuropsychologia 2013, 51, 2210–2223. [Google Scholar] [CrossRef] [PubMed]
- Politzer-Ahles, S.; Fiorentino, R.; Jiang, X.; Zhou, X. Distinct neural correlates for pragmatic and semantic meaning processing: An event-related potential investigation of scalar implicature processing using picture-sentence verification. Brain Res. 2013, 1490, 134–152. [Google Scholar] [CrossRef] [Green Version]
- Stoops, A.; Luke, S.G.; Christianson, K. Animacy information outweighs morphological cues in Russian. Lang. Cogn. Neurosci. 2014, 29, 584–604. [Google Scholar] [CrossRef]
- Ferreira, F.; Ferraro, B.V. Good enough representations in language comprehension. Curr. Dir. Psychol. Sci. 2002, 11, 11–15. [Google Scholar] [CrossRef]
- Christianson, K. When language comprehension goes wrong for the right reasons: Good-enough, underspecified, or shallow language processing. Q. J. Exp. Psychol. 2016, 69, 817–828. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Consistency | Example Sentences | Number of Trials (for Each Order) | ||
|---|---|---|---|---|
| High-Proportion Sessions | Equal-Proportion Sessions | |||
| Critical | Consistent | 老李的/女儿/是/一名/护士,/经常/值/夜班。 | 40 | 40 |
| Li’s/daughter/is/a/nurse,/often/works/night shifts. Li’s daughter is a nurse and often works night shifts. | ||||
| Inconsistent | 老李的/儿子/是/一名/护士,/经常/值/夜班。 | 40 | 40 | |
| Li’s/son/is/a/nurse,/often/works/night shifts. Li’s son is a nurse and often works night shifts. | ||||
| Filler | Consistent | 小张的/爸爸/是/一位/企业家,/在当地/颇有/声望。 | 120 | 60 |
| Zhang’s/father/is/an/entrepreneur,/locally/is well-known. Zhang’s father is an entrepreneur who is well-known locally. | ||||
| Inconsistent | 老宋的/堂妹/曾是/一名/采煤工,/年轻时/吃了/不少苦。 | 0 | 60 | |
| Song’s/cousin [female]/was/a/coal miner,/when she was young/suffered a lot. Song’s cousin [female] was a coal miner and suffered a lot when she was young. | ||||
| N400 | LN | |||||
|---|---|---|---|---|---|---|
| Order | Proportion | Consistency | M | SE | M | SE |
| high–equal | high | consistent | −0.64 | 0.41 | 0.44 | 0.38 |
| inconsistent | −1.28 | 0.41 | −0.20 | 0.37 | ||
| equal | consistent | −0.46 | 0.42 | 0.63 | 0.40 | |
| inconsistent | −1.23 | 0.44 | −0.20 | 0.43 | ||
| equal–high | high | consistent | −1.02 | 0.41 | −0.14 | 0.37 |
| inconsistent | −0.76 | 0.41 | −0.10 | 0.37 | ||
| equal | consistent | −0.88 | 0.42 | −0.80 | 0.40 | |
| inconsistent | −0.84 | 0.44 | −0.59 | 0.43 | ||
| β | SE | 95% CI | t | χ2 | p (>χ2) | |
|---|---|---|---|---|---|---|
| intercept | 0.00 | 0.03 | [–0.06, 0.06] | −0.11 | ||
| consistency | 0.02 | 0.01 | [0.00, 0.04] | 1.72 | 2.25 | 0.134 |
| proportion | 0.00 | 0.01 | [–0.03, 0.02] | −0.37 | 0.55 | 0.457 |
| order | 0.00 | 0.03 | [–0.06, 0.06] | −0.05 | 0.02 | 0.884 |
| cloze | 0.00 | 0.02 | [–0.03, 0.03] | −0.17 | 0.67 | 0.413 |
| consistency:proportion | −0.01 | 0.01 | [–0.02, 0.01] | −0.54 | 0.05 | 0.816 |
| consistency:order | 0.03 | 0.01 | [0.01, 0.04] | 2.71 | 8.29 | 0.004 |
| proportion:order | 0.00 | 0.01 | [–0.02, 0.02] | −0.24 | 0.12 | 0.729 |
| consistency:cloze | 0.01 | 0.02 | [–0.02, 0.04] | 0.71 | 0.004 | 0.947 |
| proportion:cloze | 0.02 | 0.02 | [–0.01, 0.05] | 1.10 | 0.21 | 0.645 |
| order:cloze | 0.00 | 0.02 | [–0.03, 0.03] | 0.08 | 0.84 | 0.358 |
| consistency:proportion:order | 0.00 | 0.01 | [–0.02, 0.02] | 0.14 | 0.07 | 0.793 |
| consistency:proportion:cloze | −0.02 | 0.02 | [–0.05, 0.01] | −1.08 | 0.82 | 0.365 |
| consistency:order:cloze | −0.02 | 0.02 | [–0.05, 0.01] | −1.09 | 3.92 | 0.048 |
| proportion:order:cloze | 0.00 | 0.02 | [–0.03, 0.03] | −0.08 | 0.22 | 0.636 |
| consistency:proportion:order:cloze | −0.01 | 0.02 | [–0.03, 0.02] | −0.34 | 0.06 | 0.808 |
| β | SE | 95% CI | t | χ2 | p (>χ2) | |
|---|---|---|---|---|---|---|
| intercept | −0.01 | 0.03 | [–0.08, 0.06] | −0.29 | ||
| consistency | −0.02 | 0.02 | [–0.05, 0.02] | −0.82 | 2.17 | 0.141 |
| proportion | −0.02 | 0.02 | [–0.06, 0.02] | −0.96 | 1.31 | 0.252 |
| order | −0.01 | 0.04 | [–0.08, 0.06] | −0.29 | 0.18 | 0.673 |
| cloze | 0.00 | 0.02 | [–0.03, 0.03] | −0.14 | 1.21 | 0.272 |
| trials | −0.03 | 0.02 | [–0.07, 0.01] | −1.50 | 2.23 | 0.135 |
| consistency:proportion | 0.01 | 0.02 | [–0.03, 0.04] | 0.39 | 0.52 | 0.472 |
| consistency:order | 0.04 | 0.02 | [0.01, 0.08] | 2.40 | 5.68 | 0.017 |
| proportion:order | −0.03 | 0.02 | [–0.07, 0.01] | −1.40 | 2.08 | 0.149 |
| consistency:cloze | 0.02 | 0.02 | [–0.02, 0.05] | 0.96 | 0.11 | 0.741 |
| consistency:trials | −0.03 | 0.02 | [–0.07, 0.00] | −1.70 | 2.63 | 0.105 |
| proportion:cloze | 0.02 | 0.02 | [–0.01, 0.05] | 1.20 | 0.24 | 0.623 |
| proportion:trials | −0.01 | 0.02 | [–0.05, 0.03] | −0.51 | 0.30 | 0.585 |
| order:cloze | 0.00 | 0.02 | [–0.03, 0.03] | 0.29 | 0.52 | 0.473 |
| order:trials | −0.02 | 0.02 | [–0.05, 0.02] | −0.90 | 0.81 | 0.369 |
| consistency:proportion:order | −0.03 | 0.02 | [–0.06, 0.01] | −1.40 | 1.68 | 0.194 |
| consistency:proportion:cloze | −0.02 | 0.02 | [–0.05, 0.01] | −1.20 | 1.16 | 0.282 |
| consistency:proportion:trials | 0.02 | 0.02 | [–0.01, 0.06] | 1.15 | 1.25 | 0.263 |
| consistency:order:cloze | −0.02 | 0.02 | [–0.05, 0.01] | −1.32 | 3.94 | 0.047 |
| consistency:order:trials | 0.02 | 0.02 | [–0.02, 0.05] | 0.81 | 0.96 | 0.327 |
| proportion:order:cloze | 0.00 | 0.02 | [–0.03, 0.03] | −0.17 | 0.06 | 0.804 |
| proportion:order:trials | −0.01 | 0.02 | [–0.04, 0.03] | −0.38 | 0.16 | 0.686 |
| consistency:proportion:order:cloze | 0.00 | 0.02 | [–0.03, 0.03] | 0.00 | 0.004 | 0.953 |
| consistency:proportion:order:trials | −0.04 | 0.02 | [–0.07, 0.00] | −2.03 | 4.27 | 0.039 |
| β | SE | 95% CI | t | χ2 | p (>χ2) | |
|---|---|---|---|---|---|---|
| intercept | −0.01 | 0.03 | [–0.06, 0.05] | −0.20 | ||
| consistency | 0.02 | 0.01 | [0.00, 0.04] | 1.68 | 1.34 | 0.247 |
| proportion | 0.01 | 0.01 | [–0.01, 0.04] | 1.23 | 0.41 | 0.525 |
| order | 0.03 | 0.03 | [–0.02, 0.09] | 1.27 | 0.93 | 0.336 |
| cloze | −0.04 | 0.02 | [–0.07, −0.01] | −2.36 | 1.85 | 0.173 |
| consistency:proportion | 0.00 | 0.01 | [–0.02, 0.02] | −0.05 | 0.27 | 0.606 |
| consistency:order | 0.03 | 0.01 | [0.00, 0.05] | 2.36 | 6.18 | 0.013 |
| proportion:order | −0.02 | 0.01 | [–0.04, 0.00] | −1.71 | 2.92 | 0.087 |
| consistency:cloze | 0.02 | 0.02 | [–0.01, 0.06] | 1.38 | 0.04 | 0.840 |
| proportion:cloze | 0.04 | 0.02 | [0.01, 0.07] | 2.30 | 1.91 | 0.167 |
| order:cloze | 0.00 | 0.02 | [–0.03, 0.03] | −0.04 | 1.63 | 0.201 |
| consistency:proportion:order | −0.01 | 0.01 | [–0.03, 0.02] | −0.48 | 0.23 | 0.633 |
| consistency:proportion:cloze | −0.03 | 0.02 | [–0.06, 0.01] | −1.61 | 1.19 | 0.276 |
| consistency:order:cloze | −0.02 | 0.02 | [–0.05, 0.02] | −0.95 | 1.43 | 0.232 |
| proportion:order:cloze | −0.01 | 0.02 | [–0.04, 0.02] | −0.61 | 0.45 | 0.504 |
| consistency:proportion:order:cloze | 0.01 | 0.02 | [–0.03, 0.04] | 0.37 | 0.51 | 0.473 |
| β | SE | 95% CI | t | χ2 | p (>χ2) | |
|---|---|---|---|---|---|---|
| intercept | −0.01 | 0.03 | [–0.08, 0.05] | −0.42 | ||
| consistency | 0.00 | 0.02 | [–0.04, 0.04] | −0.02 | 1.27 | 0.259 |
| proportion | 0.02 | 0.02 | [–0.02, 0.06] | 1.03 | 0.56 | 0.455 |
| order | 0.02 | 0.03 | [–0.04, 0.08] | 0.63 | 0.17 | 0.679 |
| cloze | −0.04 | 0.02 | [–0.07, 0.00] | −2.21 | 0.59 | 0.442 |
| trials | −0.04 | 0.02 | [–0.08, 0.00] | −1.80 | 3.09 | 0.079 |
| consistency:proportion | 0.01 | 0.02 | [–0.03, 0.05] | 0.32 | 0.62 | 0.431 |
| consistency:order | 0.02 | 0.02 | [–0.02, 0.06] | 1.07 | 1.19 | 0.275 |
| proportion:order | −0.05 | 0.02 | [–0.09, −0.01] | −2.43 | 5.68 | 0.017 |
| consistency:cloze | 0.03 | 0.02 | [–0.01, 0.06] | 1.67 | 0.36 | 0.551 |
| consistency:trials | −0.07 | 0.02 | [–0.11, −0.03] | −3.20 | 9.57 | 0.002 |
| proportion:cloze | 0.04 | 0.02 | [0.01, 0.08] | 2.46 | 2.52 | 0.112 |
| proportion:trials | −0.02 | 0.02 | [–0.06, 0.03] | −0.75 | 0.60 | 0.439 |
| order:cloze | 0.00 | 0.02 | [–0.03, 0.03] | 0.00 | 1.51 | 0.220 |
| order:trials | 0.01 | 0.02 | [–0.03, 0.05] | 0.45 | 0.18 | 0.675 |
| consistency:proportion:order | −0.06 | 0.02 | [–0.10, −0.02] | −2.95 | 8.72 | 0.003 |
| consistency:proportion:cloze | −0.03 | 0.02 | [–0.06, 0.01] | −1.64 | 1.33 | 0.248 |
| consistency:proportion:trials | 0.00 | 0.02 | [–0.04, 0.04] | −0.20 | 0.05 | 0.827 |
| consistency:order:cloze | −0.02 | 0.02 | [–0.05, 0.02] | −1.05 | 1.51 | 0.220 |
| consistency:order:trials | 0.01 | 0.02 | [–0.03, 0.05] | 0.43 | 0.27 | 0.603 |
| proportion:order:cloze | −0.01 | 0.02 | [–0.04, 0.02] | −0.59 | 0.28 | 0.595 |
| proportion:order:trials | −0.01 | 0.02 | [–0.05, 0.03] | −0.43 | 0.20 | 0.656 |
| consistency:proportion:order:cloze | 0.01 | 0.02 | [–0.03, 0.04] | 0.49 | 0.67 | 0.414 |
| consistency:proportion:order:trials | −0.02 | 0.02 | [0.06, 0.02] | −1.09 | 1.22 | 0.269 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, Y.; Zhang, Y. Strategic Processing of Gender Stereotypes in Sentence Comprehension: An ERP Study. Brain Sci. 2023, 13, 560. https://doi.org/10.3390/brainsci13040560
Du Y, Zhang Y. Strategic Processing of Gender Stereotypes in Sentence Comprehension: An ERP Study. Brain Sciences. 2023; 13(4):560. https://doi.org/10.3390/brainsci13040560
Chicago/Turabian StyleDu, Yanan, and Yaxu Zhang. 2023. "Strategic Processing of Gender Stereotypes in Sentence Comprehension: An ERP Study" Brain Sciences 13, no. 4: 560. https://doi.org/10.3390/brainsci13040560