
Lie Recognition with Multi-Modal Spatial–Temporal State Transition Patterns Based on Hybrid Convolutional Neural Network–Bidirectional Long Short-Term Memory
 , and
, and
Abstract
:1. Introduction
- (1)
- This study designs a state transition pattern vector based on STSTP to model the involuntary cognitive cues of the hand, body, and eye-blinking motion of a lying or truth-telling person.
- (2)
- This study presents lie recognition with multi-modal STSTP based on hybrid ResNet-152 and BLSTM.
- (3)
- The proposed approach controls redundant features and improves computational efficiency.
- (4)
- The performance evaluation indicates the superiority of the proposed approach when compared to classical algorithms.
- (5)
- This study computes facial involuntary actions using the EAR formulation, while complete body motion is computed using optical information to distinguish between involuntary lying and truthful cognitive indices.
- (6)
- This work demonstrates empirical evidence of an improved police investigation/court trial process with an automatic system, compared to a single and manual lie recognition system.
2. Literature Review
2.1. Eye Blinking Approach
2.2. Multi-Modal Cue Approaches
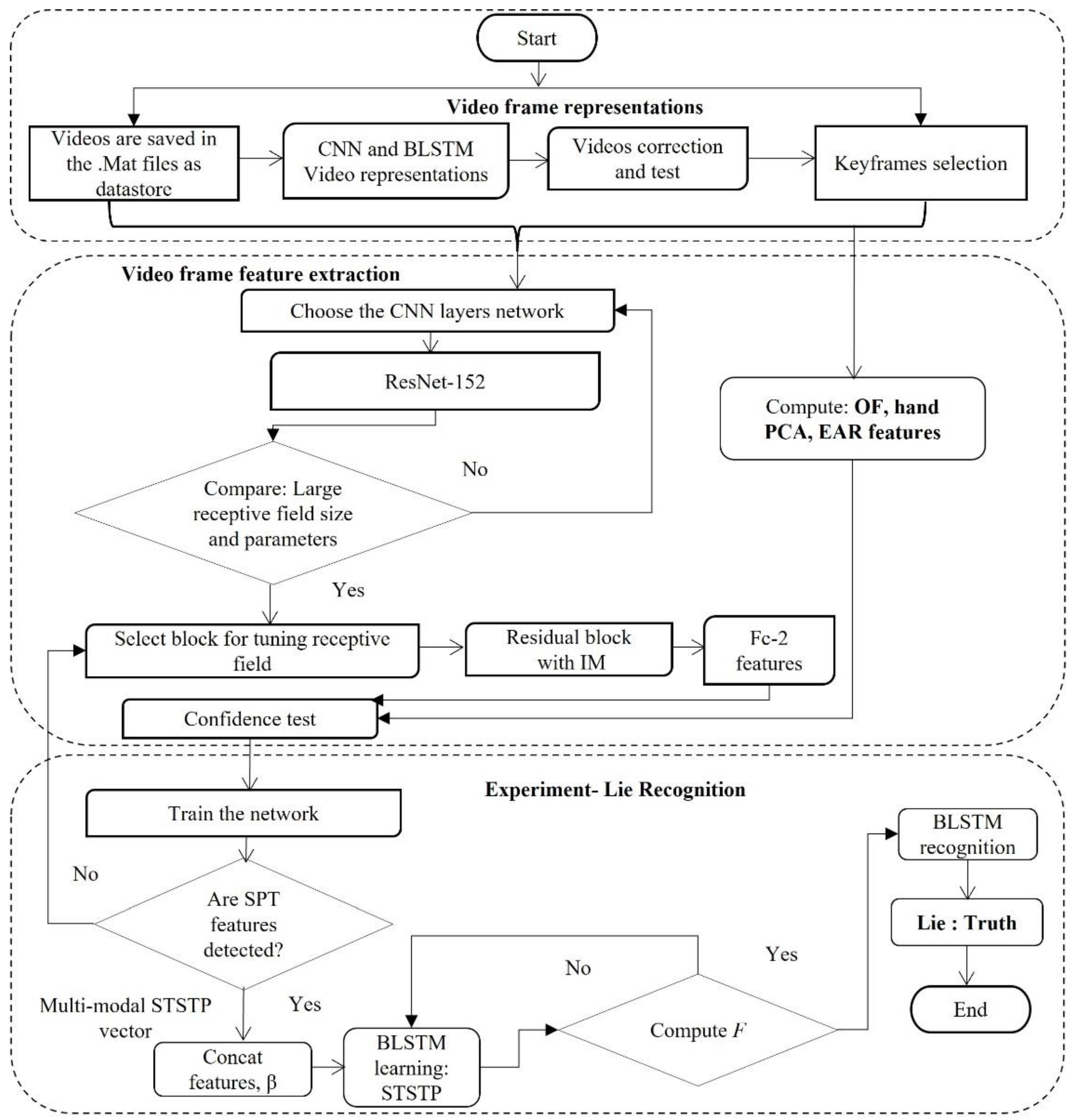
3. The Proposed Conceptual Framework
3.1. Video Frame Representation from the Proposed Method
3.1.1. Convolutional Neural Network-Based Video Representation
3.1.2. Bidirectional Long Short-Term Memory-Based Video Representation
3.1.3. Scheme to Control the Network Saturation
| Algorithm 1: Guided-learning algorithm |
| 1: start 2: set in Equation (1) {create matrix} 3: set in Equation (1) {STSTP sequence} 4: set {output} 5: set {Initialization} 6: Evaluate Equation (6) {selection} 7: for each do 8: repeat 9: if then 10: Evaluate Equation (5) 11: else 12: go to STEP 1 13: until Equation (14) converge 14. return 15: end |
3.2. Video Frame Feature Extraction
3.2.1. Frame Extraction Strategy
3.2.2. Optical Features of Real-Life Court Videos
3.2.3. Hand Features
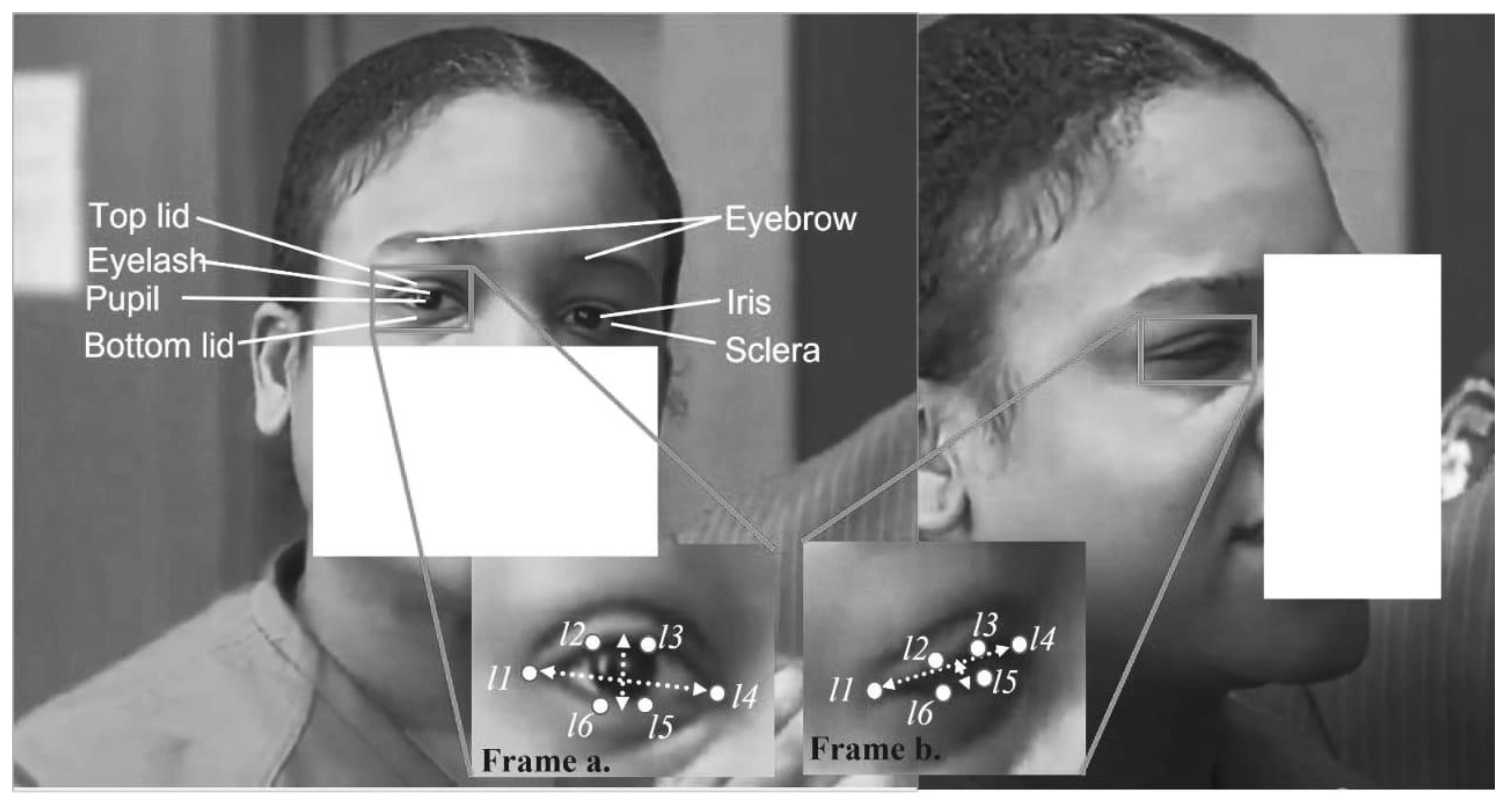
3.2.4. Eye Aspect Ratio Features
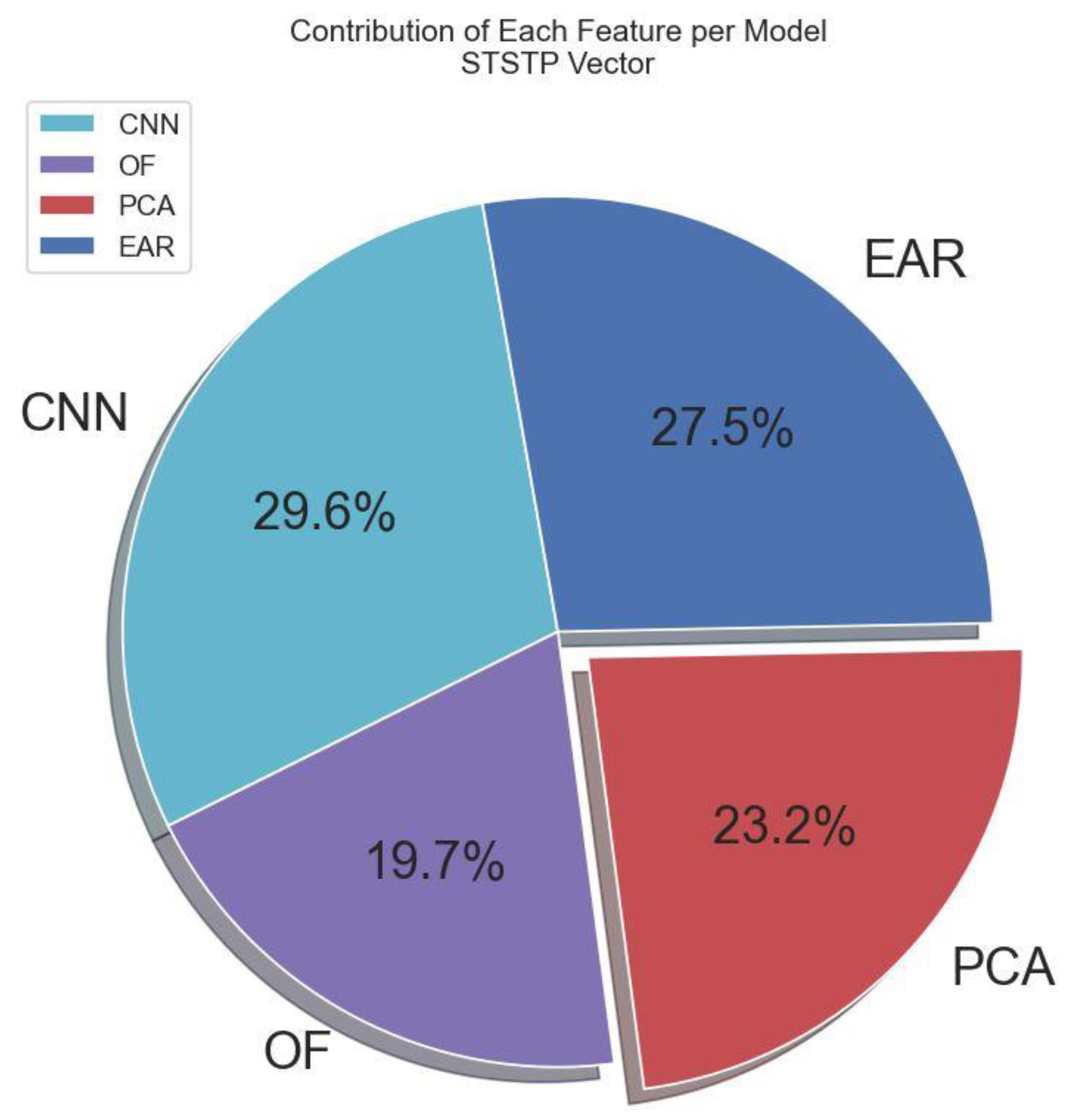
3.3. Multi-Modal Spatial–Temporal State Transition Pattern Feature Vector
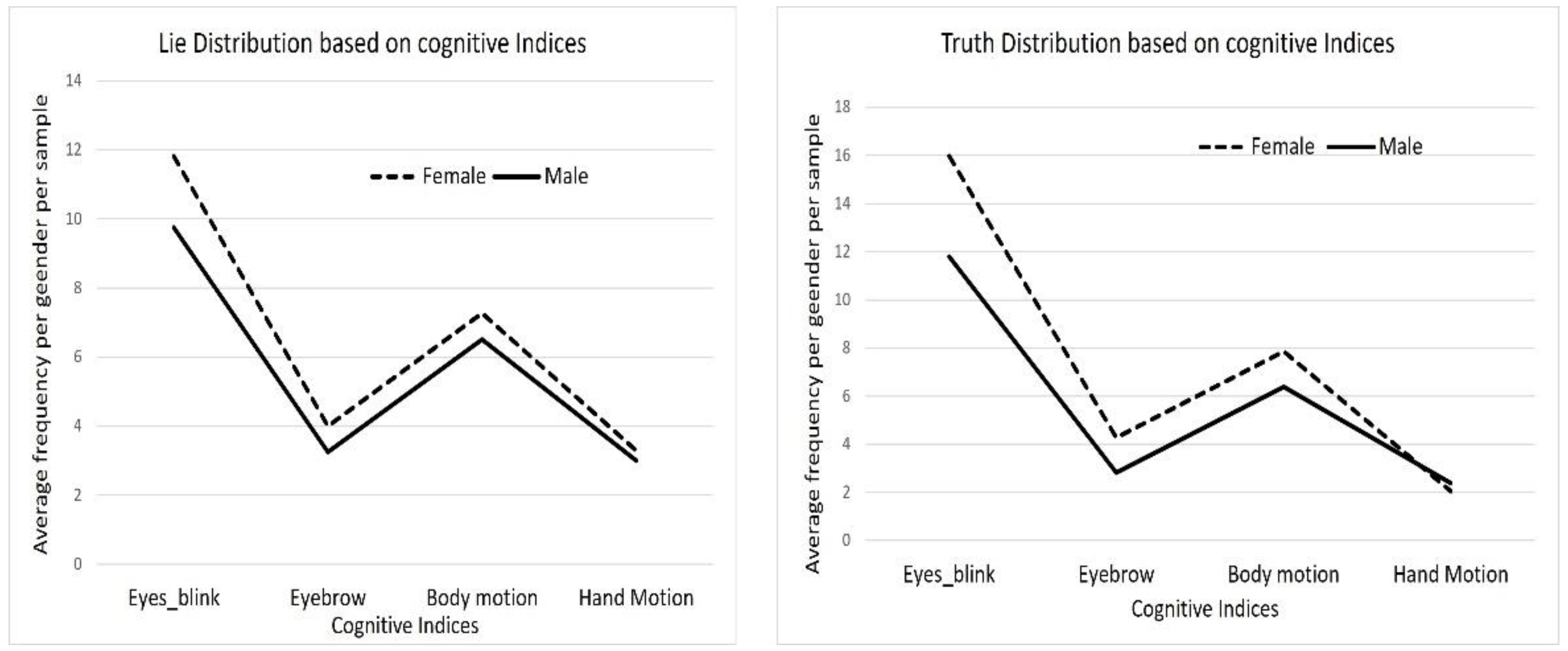
3.4. Qualitative Analysis of Real-Life Court Trial Videos
4. Experiment
4.1. Data Study
4.2. Confidence Test
4.3. Recognition of Spatial–Temporal State Transition PatternTransition
4.4. Selection of Network Parameters
4.5. Performance Evaluation Metrics
4.5.1. Eye Aspect Ratio Detection Error
4.5.2. Coefficient of Determination
4.5.3. Accuracy
5. Results and Analysis
5.1. Comparison between the ResNet-BLSTM and State-of-the-Art Methods
5.2. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| STSTP | Spatial–temporal state transition patterns |
| BLSTM | Bidirectional long short-term memory |
| CV | Computer vision |
| DL | Deep learning |
| ML | Machine learning |
| RGB | Red, green, and blue |
| CNN | Convolutional neural network |
| SVM | Support vector machine |
| LUT | Look-up table |
| EAR | Eye aspect ratio |
| ResNet | Residual network |
| PCA | Principal component analysis |
| OF | Optical flow |
| FC | Fully connected layer. |
| POI | Point of interest |
| CHT | Circular Hough transform |
| SGDM | Stochastic gradient decent with momentum |
| ReLU | Rectified linear unit. |
| IVC | Involuntary cognitive cues |
References
- Avola, D.; Cinque, L.; Maria, D.; Alessio, F.; Foresti, G. LieToMe: Preliminary study on hand gestures for deception detection via Fisher-LSTM. Pattern Recognit. Lett. 2020, 138, 455–461. [Google Scholar] [CrossRef]
- Al-jarrah, O.; Halawan, A. Recognition of gestures in Arabic sign language using neuro-fuzzy systems. Artif. Intell. 2001, 133, 117–138. [Google Scholar] [CrossRef] [Green Version]
- Abdullahi, S.B.; Khunpanuk, C.; Bature, Z.A.; Chroma, H.; Pakkaranang, N.; Abubakar, A.B.; Ibrahm, A.H. Biometric Information Recognition Using Artificial Intelligence Algorithms: A Performance Comparison. IEEE Access 2022, 10, 49167–49183. [Google Scholar] [CrossRef]
- Avola, D.; Cascio, M.; Cinque, L.; Fagioli, A.; Foresti, G. LieToMe: An Ensemble Approach for Deception Detection from Facial Cues. Int. J. Neural Syst. 2021, 31, 2050068. [Google Scholar] [CrossRef] [PubMed]
- Sen, U.; Perez, V.; Yanikoglu, B.; Abouelenien, M.; Burzo, M.; Mihalcea, R. Multimodal deception detection using real-life trial data. IEEE Trans. Affect. Comput. 2022, 2022, 2050068. [Google Scholar] [CrossRef]
- Ding, M.; Zhao, A.; Lu, Z.; Xiang, T.; Wen, J. Face-focused cross-stream network for deception detection in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Abdullahi, S.B.; Chamnongthai, K. American sign language words recognition using spatio-temporal prosodic and angle features: A sequential learning approach. IEEE Access 2022, 10, 15911–15923. [Google Scholar] [CrossRef]
- Bhaskaran, N.; Nwogu, I.; Frank, M.G.; Govindaraju, V. Lie to me: Deceit detection via online behavioral learning. In Proceedings of the 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG), Santa Barbara, CA, USA, 21–23 March 2011; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar]
- Jeffry, G.; Jenkins, J.L.; Burgoon, J.K.; Judee, K.; Nunamaker, J.F. Deception is in the eye of the communicator: Investigating pupil diameter variations in automated deception detection interviews. In Proceedings of the 2015 IEEE International Conference on Intelligence and Security Informatics (ISI), Baltimore, MD, USA, 27–29 May 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Thakar, M.K.; Kaur, P.; Sharma, T. Validation studies on gender determination from fingerprints with special emphasis on ridge characteristics. Egypt. J. Forensic Sci. 2022, 8, 20. [Google Scholar] [CrossRef] [Green Version]
- Meservy, T.O.; Jensen, M.L.; Kruse, J.; Burgoon, J.K.; Nunamaker, J.F.; Twitchell, D.P.; Tsechpenakis, G.; Metaxas, D.N. Deception detection through automatic, unobtrusive analysis of nonverbal behavior. IEEE Intell. Syst. 2005, 20, 36–43. [Google Scholar] [CrossRef]
- Pérez-Rosas, V.; Abouelenien, M.; Mihalcea, R.; Burzo, M. Deception detection using real-life trial data. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, DC, USA, 9–13 November 2015; ACM: New York, NY, USA, 2015. [Google Scholar]
- Abouelenien, M.; Pérez-Rosas, V.; Mihalcea, R.; Burzo, M. Detecting deceptive behavior via integration of discriminative features from multiple modalities. IEEE Trans. Inf. Forensics Secur. 2017, 5, 1042–1055. [Google Scholar] [CrossRef]
- Karimi, H.; Tang, J.; Li, Y. Toward end-to-end deception detection in videos. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Wu, Z.; Singh, B.; Davis, L.; Subrahmanian, V. Deception detection in videos. In Proceedings of the AAAI conference on artificial intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI: Washington, DC, USA, 2018. [Google Scholar]
- Rill-García, R.; Jair, E.H.; Villasenor-Pineda, L.; Reyes-Meza, V. High-level features for multimodal deception detection in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Krishnamurthy, G.; Majumder, N.; Poria, S.; Cambria, E. A deep learning approach for multimodal deception detection. arXiv 2018, arXiv:1803.00344. [Google Scholar]
- Abdullahi, S.B.; Ibrahim, A.H.; Abubakar, A.B.; Kambheera, A. Optimizing Hammerstein-Wiener Model for Forecasting Confirmed Cases of COVID-19. IAENG Int. J. Appl. Math. 2022, 52, 101–115. [Google Scholar]
- Abdullahi, S.B.; Muangchoo, K. Semantic parsing for automatic retail food image recognition. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 53, 7808–7816. [Google Scholar]
- Lu, S.; Tsechpenakis, G.; Metaxas, D.N.; Jensen, M.L.; Kruse, J. Blob analysis of the head and hands: A method for deception detection. In Proceedings of the 38th Annual Hawaii International Conference on System Sciences, Big Island, HI, USA, 3–6 January 2005; IEEE: Piscataway, NJ, USA, 2005. [Google Scholar]
- Abdullahi, S.B.; Chamnongthai, K. American sign language words recognition of skeletal videos using processed video driven multi-stacked deep LSTM. Sensors 2022, 22, 1406. [Google Scholar] [CrossRef] [PubMed]
- Abdullahi, S.B.; Chamnongthai, K. Hand pose aware multimodal isolated sign language recognition. Multimed. Tools Appl. 2021, 80, 127–163. [Google Scholar]
- Reddy, B.; Kim, Y.; Yun, S.; Seo, C.; Jang, J. Real-Time Eye Blink Detection using Facial Landmarks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Avola, D.; Cinque, L.; Foresti, G.L.; Pannone, D. Automatic deception detection in rgb videos using facial action units. In Proceedings of the 13th International Conference on Distributed Smart Cameras, Trento, Italy, 9–11 September 2019; ACM: New York, NY, USA, 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| V1 | V2 | V3 | |
|---|---|---|---|
| V1 | 0.99999 | ||
| V2 | 0.99772 | 0.9992 | |
| V3 | 0.99761 | 0.9974 | 0.99981 |
| Var1 | Var2 | Var3 | |
|---|---|---|---|
| Var1 | 0.99847 | ||
| Var2 | 0.99706 | 0.99465 | |
| Var3 | 0.98863 | 0.9344 | 0.9965 |
| Var1 | Var2 | Var3 | |
|---|---|---|---|
| V1 | 0.9858 | ||
| V2 | 0.95762 | 0.98768 | |
| V3 | 0.9838 | 0.99291 | 0.98635 |
| 0.8334 | |||
| 0.7641 | 0.8167 | ||
| 0.7739 | 0.7992 | 0.8049 |
| No. | Layers Name | Activation |
|---|---|---|
| 1 | Image input | 227 × 227 × 3 |
| 2 | Convolution 1 | 55 × 55 × 3 |
| 3 | ReLU 1 | 55 × 55 × 96 |
| 4 | Cross Normalization 1 | 55 × 55 × 96 |
| 5 | Max pooling 1 | 27 × 27 × 96 |
| 6 | Convolution 2 | 27 × 27 × 256 |
| 7 | ReLU 2 | 27 × 27 × 256 |
| 8 | Cross Normalization 2 | 27 × 27 × 256 |
| 9 | Max pooling 2 | 13 × 13 × 256 |
| 10 | Convolution 3 | 13 × 13 × 384 |
| 11 | ReLU 3 | 13 × 13 × 384 |
| 12 | Convolution 4 | 13 × 13 × 384 |
| 13 | ReLU 4 | 13 × 13 × 384 |
| 14 | Convolution 5 | 13 × 13 × 256 |
| 15 | ReLU 5 | 13 × 13 × 256 |
| 16 | Max pooling 5 | 6 × 6 × 256 |
| 17 | Fully Connected (Fc6) | 1 × 1 × 4096 |
| 18 | ReLU | 1 × 1 × 4096 |
| 19 | Dropout | 1 × 1 × 4096 |
| 20 | Fully Connected (Fc7) | 1 × 1 × 4096 |
| 21 | ReLU | 1 × 1 × 4096 |
| 22 | Dropout | 1 × 1 × 4096 |
| 23 | Fully Connected (Fc8) | 1 × 1 × 1000 |
| 24 | Softmax | 1 × 1 × 1000 |
| 25 | Classification Output | 2 classes |
| Conv7-64 | |
| Maxpool | |
| Conv1-64S | |
| Conv3-64 | |
| Conv1-256 | |
| Conv1-128 | |
| Conv3-128 | |
| Conv1-512 | |
| Conv1-256 | |
| Conv3-256 | |
| Conv1-1024 | |
| Conv1-512 | |
| Conv3-512 | |
| Conv1-2048 | |
| Conv1-2 | |
| Global averaging pooling |
| Network | Parameters | Values |
|---|---|---|
| ResNet-152 | SGDM | 0.9 |
| Batch size | 128 | |
| Max. iteration | 500 | |
| No. of epochs | 250 | |
| Gaussian with S.D | 0.01 | |
| Learning rate | 0.01 | |
| Weight decay | 0.0005 | |
| Dropout | 0.7 | |
| Params | >60 M | |
| BLSTM | Input | 1 dim. |
| Hidden layer | 100 | |
| Output | Last | |
| Batch size | 32 | |
| FC | 2 | |
| Max epochs | 64 | |
| Dropout | 0.2 |
| Models | Feature Vector | Accuracy (%) |
|---|---|---|
| STSTP Model 1 | OF | 71.39 |
| STSTP Model 2 | Hand-PCA | 59.87 |
| STSTP Model 3 | EAR | 61.25 |
| STSTP [Model 1 + Model 2] | OF + Hand-PCA | 74.43 |
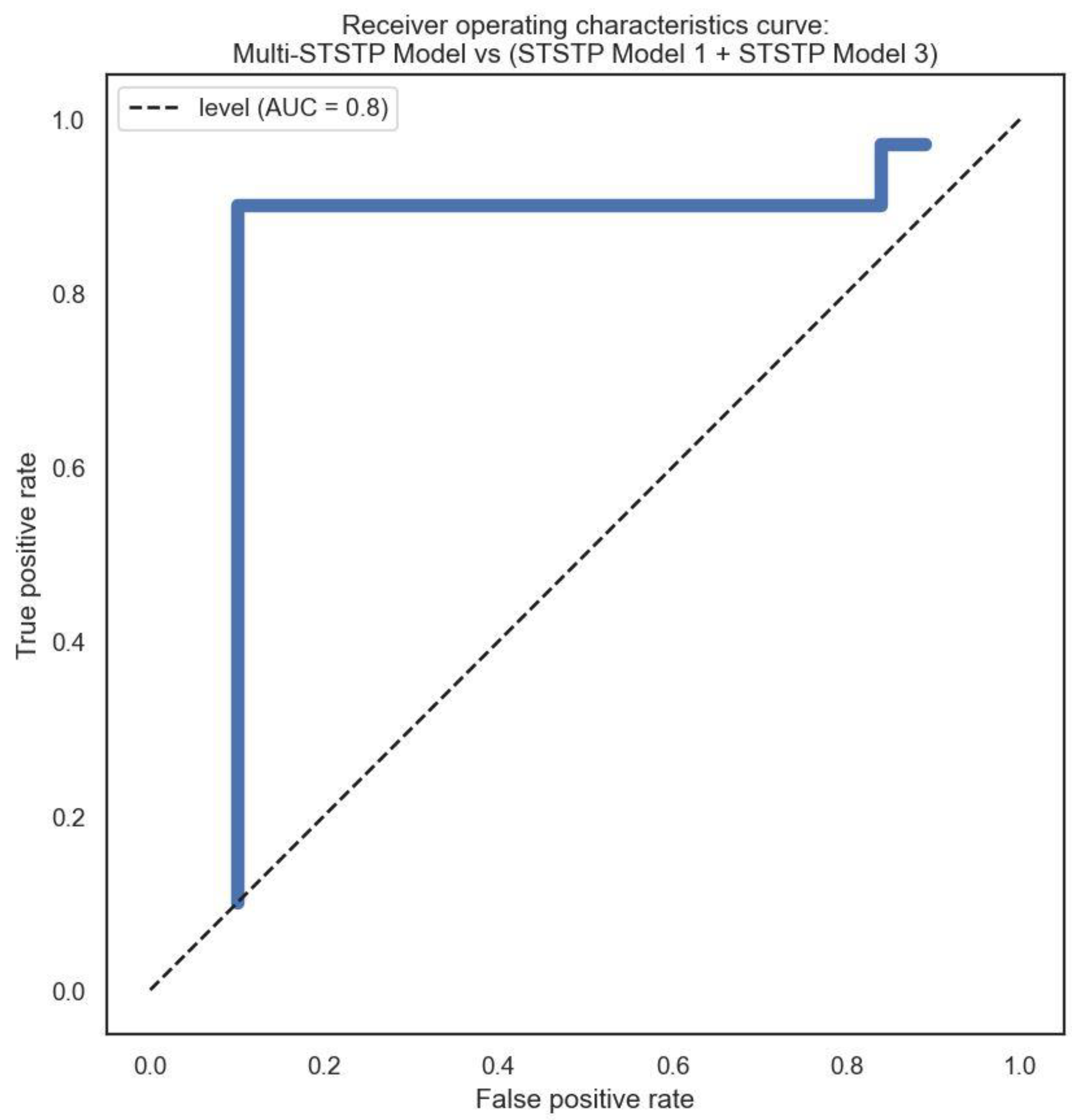
| STSTP [Model 1 + Model 3] | OF + EAR | 88.29 |
| STSTP [Model 2 + Model 3] | Hand-PCA + EAR | 77.38 |
| Multi-STSTP | OF + Hand-PCA + EAR | 96.56 |
| Methods | Hand Gesture | Facial Information | ||
|---|---|---|---|---|
| AUC (%) | Accuracy (%) | AUC (%) | Accuracy (%) | |
| RF [12] | NA | 62.8 | NA | 76.03 |
| DT [12] | NA | 71.9 | NA | 59.5 |
| L-SVM [15] | NA | NA | 66.33 | NA |
| MLP [17] | 66.71 | 64.97 | 94.16 | 80.79 |
| Fisher-LSTM [1] | 91.14 | 90.96 | NA | NA |
| ResNet-152-BLSTM | 68.09 | 59.87 | 73.11 | 61.25 |
| Methods | AUC (%) | Accuracy (%) |
|---|---|---|
| RF [12] | NA | 75.2 |
| DT [12] | NA | 50.41 |
| L-SVM [15] | 90.65 | NA |
| LR [15] | 92.21 | NA |
| Hierarchical-BSSD [16] | 67.1 | NA |
| LSTM [16] | 66.5 | NA |
| RBF-SVM [25] | NA | 76.84 |
| Fisher-LSTM [1] | 91.14 | 90.96 |
| Stacked MLP [4] | 93.57 | 92.01 |
| NN [5] | 94 | 84.18 |
| ResNet-152-BLSTM | 97.58 | 96.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdullahi, S.B.; Bature, Z.A.; Gabralla, L.A.; Chiroma, H. Lie Recognition with Multi-Modal Spatial–Temporal State Transition Patterns Based on Hybrid Convolutional Neural Network–Bidirectional Long Short-Term Memory. Brain Sci. 2023, 13, 555. https://doi.org/10.3390/brainsci13040555
Abdullahi SB, Bature ZA, Gabralla LA, Chiroma H. Lie Recognition with Multi-Modal Spatial–Temporal State Transition Patterns Based on Hybrid Convolutional Neural Network–Bidirectional Long Short-Term Memory. Brain Sciences. 2023; 13(4):555. https://doi.org/10.3390/brainsci13040555
Chicago/Turabian StyleAbdullahi, Sunusi Bala, Zakariyya Abdullahi Bature, Lubna A. Gabralla, and Haruna Chiroma. 2023. "Lie Recognition with Multi-Modal Spatial–Temporal State Transition Patterns Based on Hybrid Convolutional Neural Network–Bidirectional Long Short-Term Memory" Brain Sciences 13, no. 4: 555. https://doi.org/10.3390/brainsci13040555