

Investigating Students’ Pre-University Admission Requirements and Their Correlation with Academic Performance for Medical Students: An Educational Data Mining Approach

Abstract
:1. Introduction
- Assess the efficacy of weightages given to HSP, GAT and SAT using regression and optimization techniques.
- Compare the performance of selected data mining techniques to predict student performance based on existing admission criteria.
- Recommend revised weightages for admission criteria based upon comparative analysis of data mining techniques using existing weightages and optimized weightages to predict student performance.
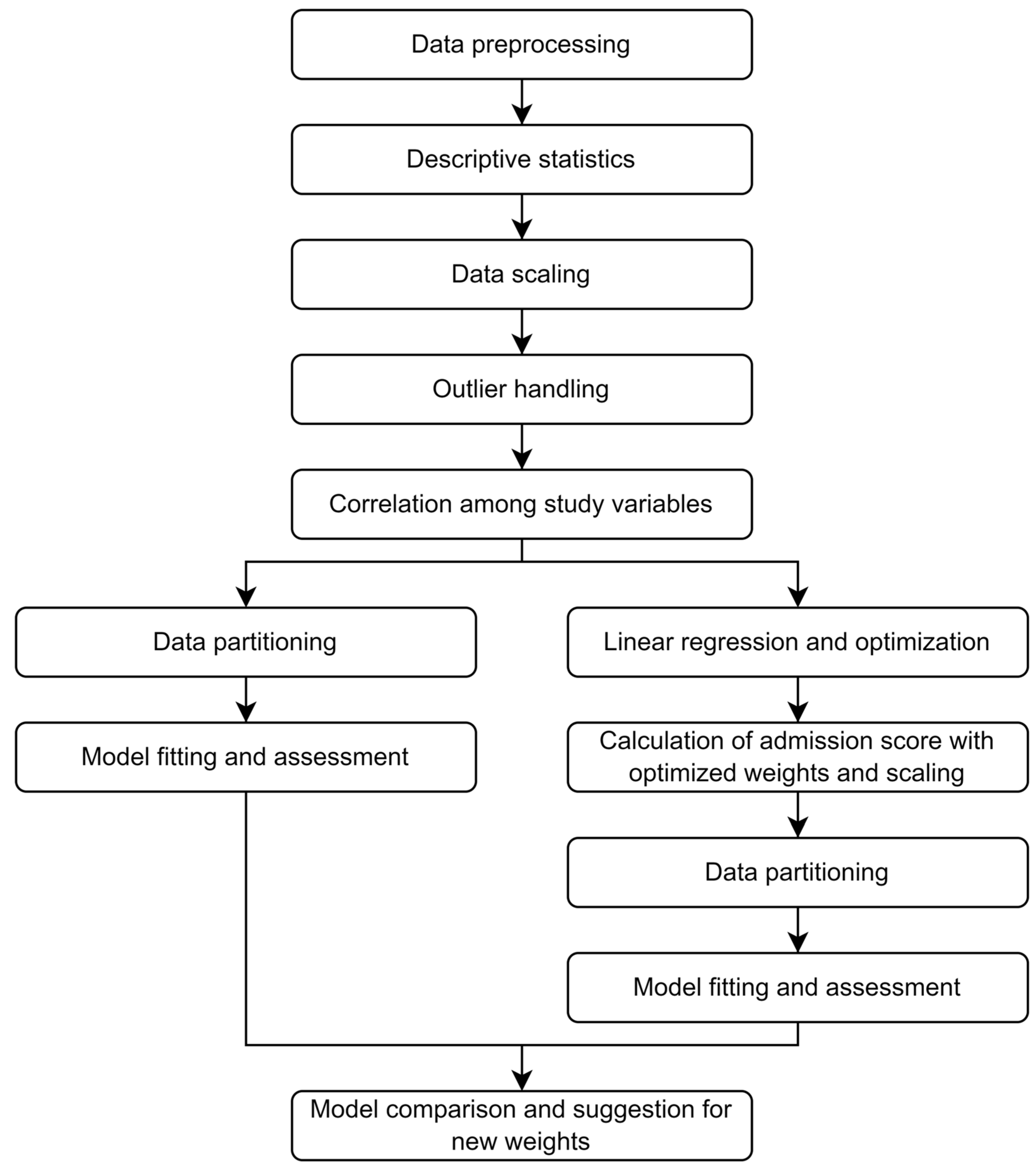
2. Materials and Methods
2.1. Data Pre-Processing and Descriptive Statistics
2.2. Data Scaling and Outlier Handling
2.3. Correlation Analysis
2.4. Linear Regression and Optimization, and Admission Score Optimized
2.5. Data Partitioning
2.6. Model Fitting and Assessment
2.7. Model Comparisons
- True positive (TP): the number of cases correctly predicted as positive,
- False positive (FP): the number of cases incorrectly predicted as positive,
- True negative (TN): the number of cases correctly predicted as negative and
- False negative (FN): the number of cases incorrectly predicted as negative.
3. Results
3.1. Descriptive Statistics
3.2. Correlations
3.3. Linear Regression and Optimization
3.4. Model Fitting
3.5. Model Comparisons
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Patterson, F.; Knight, A.; Dowell, J.; Nicholson, S.; Cousans, F.; Cleland, J. How effective are selection methods in medical education? A systematic review. Med. Educ. 2016, 50, 36–60. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferguson, E. Factors associated with success in medical school: Systematic review of the literature. BMJ 2002, 324, 952–957. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al-Sulaiman, A.A. Saudi medical education: Challenges in the new millennium. J. Fam. Community Med. 2000, 7, 15. [Google Scholar]
- Al-Rukban, M.O.; Munshi, F.M.; Abdulghani, H.M.; Al-Hoqail, I. The ability of the pre-admission criteria to predict performance in a Saudi medical school. Saudi Med. J. 2010, 31, 560–564. [Google Scholar]
- Albishri, J.A.; Aly, S.M.; Alnemary, Y. Admission criteria to Saudi medical schools. Which is the best predictor for successful achievement? Saudi Med. J. 2012, 33, 1222–1226. [Google Scholar]
- Murshid, K.R. The predictive value of individual admission criteria on academic performance in a Saudi medical college. J. Taibah Univ. Med. Sci. 2013, 8, 18–23. [Google Scholar] [CrossRef] [Green Version]
- Alhadlaq, A.M.; Alshammari, O.F.; Alsager, S.M.; Neel, K.A.F.; Mohamed, A.G. Ability of Admissions Criteria to Predict Early Academic Performance Among Students of Health Science Colleges at King Saud University, Saudi Arabia. J. Dent. Educ. 2015, 79, 665–670. [Google Scholar] [CrossRef]
- Althewini, A.; Alkushi, A. Predictive validity of Saudi admission criteria for freshmen students’ English performance: Experience of king Saud Bin Abdulaziz university for Health sciences. J. Lang. Teach. Res. 2020, 11, 108–114. [Google Scholar] [CrossRef]
- Alhurishi, S.A.; Aljuraiban, G.S.; Alshaikh, F.A.; Almutairi, M.M.; Almutairi, K.M. Predictors of students’ academic achievements in allied health professions at King Saud University: A retrospective cohort study. BMC Med. Educ. 2021, 21, 1–7. [Google Scholar] [CrossRef]
- Althewini, A.; Al Baz, N. Prediction of Admission Tests for Medical Students’ Academic Performance. Adv. Med. Educ. Pract. 2022, 13, 1287–1292. [Google Scholar] [CrossRef]
- Alamoudi, A.A.; Fallatah, H.I.; Eldakhakhny, B.M.; Kamel, F.O.; AlShawwa, L.A.; Elsamanoudy, A.Z. Relationship between admission criteria and academic performance in basic science courses in health science colleges in KAU. BMC Med. Educ. 2021, 21, 1–8. [Google Scholar] [CrossRef]
- Dabaliz, A.-A.; Kaadan, S.; Dabbagh, M.M.; Barakat, A.; Shareef, M.A.; Al-Tannir, M.; Obeidat, A.; Mohamed, A. Predictive validity of pre-admission assessments on medical student performance. Int. J. Med. Educ. 2017, 8, 408. [Google Scholar] [CrossRef] [Green Version]
- Jawhar, S.S.; Al Makoshi, M.; Alhawsawi, S.; Alkushi, A. Validating English Language Entrance Test at a Saudi University for Health Sciences. Arab World Engl. J. Vol. 2021, 12, 49–71. [Google Scholar] [CrossRef]
- Al-Qahtani, M.F.; Alanzi, T.M. Comparisons of the predictive values of admission criteria for academic achievement among undergraduate students of health and non-health science professions: A longitudinal cohort study. Psychol. Res. Behav. Manag. 2018, 12, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Romero, C.; Ventura, S. Educational data mining: A survey from 1995 to 2005. Expert Syst. Appl. 2007, 33, 135–146. [Google Scholar] [CrossRef]
- Baker, R.S.J.D.; Yacef, K. The state of educational data mining in 2009: A review and future visions. J. Educ. Data Min. 2009, 1, 3–17. [Google Scholar]
- Romero, C.; Ventura, S. Educational data mining and learning analytics: An updated survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1355. [Google Scholar] [CrossRef]
- Algarni, A. Data mining in education. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 456–461. [Google Scholar]
- Vandamme, J.-P.; Meskens, N.; Superby, J.-F. Predicting academic performance by data mining methods. Educ. Econ. 2007, 15, 405. [Google Scholar] [CrossRef]
- Bresfelean, V.P.; Bresfelean, M.; Ghisoiu, N.; Comes, C.-A. Determining students’ academic failure profile founded on data mining methods. In Proceedings of the ITI 2008-30th international conference on information technology interfaces, Cavtat, Croatia, 23–26 June 2008; pp. 317–322. [Google Scholar]
- Lampropoulos, G. Educational Data Mining and Learning Analytics in the 21st Century. In Encyclopedia of Data Science and Machine Learning; IGI Global: Hershey, PA, USA, 2023; pp. 1642–1651. [Google Scholar]
- Ordoñez-Avila, R.; Reyes, N.S.; Meza, J.; Ventura, S. Data mining techniques for predicting teacher evaluation in higher education. A SYSTEMATIC literature review. Heliyon 2023, 9, e13939. [Google Scholar] [CrossRef]
- Mohsin, M.F.M.; Hibadullah, C.F.; Norwawi, N.M.; Abd Wahab, M.H. Mining the student programming performance using rough set. In Proceedings of the 2010 IEEE International Conference on Intelligent Systems and Knowledge Engineering, Hangzhou, China, 15–16 November 2010; pp. 478–483. [Google Scholar]
- Zaiane, O.R. Building a recommender agent for e-learning systems. In Proceedings of the International Conference on Computers in Education, Washington, DC, USA, 3–6 December 2002; pp. 55–59. [Google Scholar]
- Balaji, P.; Alelyani, S.; Qahmash, A.; Mohana, M. Contributions of Machine Learning Models towards Student Academic Performance Prediction: A Systematic Review. Appl. Sci. 2021, 11, 10007. [Google Scholar] [CrossRef]
- Baker, R.S.J.d. Data Mining. In International Encyclopedia of Education, 3rd ed.; Peterson, P., Baker, E., McGaw, B., Eds.; Elsevier: Oxford, UK, 2010; pp. 112–118. ISBN 978-0-08-044894-7. [Google Scholar]
- Wongvorachan, T.; He, S.; Bulut, O. A Comparison of Undersampling, Oversampling, and SMOTE Methods for Dealing with Imbalanced Classification in Educational Data Mining. Information 2023, 14, 54. [Google Scholar] [CrossRef]
- Abdelmagid, A.S.; Qahmash, A.I.M. Utilizing the Educational Data Mining Techniques" Orange Technology" for Detecting Patterns and Predicting Academic Performance of University Students. Inf. Sci. Lett. 2023, 12, 1415–1431. [Google Scholar]
- Zaffar, M.; Hashmani, M.A.; Savita, K.S. Performance analysis of feature selection algorithm for educational data mining. In Proceedings of the 2017 IEEE Conference on Big Data and Analytics (ICBDA), Beijing, China, 10–12 March 2017; pp. 7–12. [Google Scholar]
- Mengash, H.A. Using data mining techniques to predict student performance to support decision making in university admission systems. IEEE Access 2020, 8, 55462–55470. [Google Scholar] [CrossRef]
- Statistics. Available online: https://www.kku.edu.sa/en/statistics (accessed on 25 May 2022).
- Harrell, F.E. Regression Modeling Strategies: With Applications to Linear Models, Logistic Regression, and Survival Analysis; Springer: Berlin/Heidelberg, Germany, 2001; Volume 608. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Osborne, J. Improving your data transformations: Applying the Box-Cox transformation. Pract. Assess. Res. Eval. 2010, 15, 12. [Google Scholar]
- Yeo, I.-K.; Johnson, R.A. A new family of power transformations to improve normality or symmetry. Biometrika 2000, 87, 954–959. [Google Scholar] [CrossRef]
- Vinutha, H.P.; Poornima, B.; Sagar, B.M. Detection of Outliers Using Interquartile Range Technique from Intrusion Dataset. In Information and Decision Sciences. Advances in Intelligent Systems and Computing; Satapathy, S., Tavares, J., Bhateja, V., Mohanty, J., Eds.; Springer: Singapore, 2018; Volume 701, pp. 511–518. [Google Scholar]
- Dash, C.S.K.; Behera, A.K.; Dehuri, S.; Ghosh, A. An outliers detection and elimination framework in classification task of data mining. Decis. Anal. J. 2023, 6, 100164. [Google Scholar] [CrossRef]
- Walfish, S. A review of statistical outlier methods. Pharm. Technol. 2006, 30, 82. [Google Scholar]
- Van Rossum, G.; Drake, F.L. The Python Language Reference Manual; Network Theory Ltd.: Godalming, UK, 2011. [Google Scholar]
- Gnambs, T. A Brief Note on the Standard Error of the Pearson Correlation. 2022. Available online: https://psyarxiv.com/uts98 (accessed on 5 March 2023).
- Tan, P.-N.; Steinbach, M.; Kumar, V. Introduction to Data Mining; Pearson Education India: Bengaluru, India, 2016. [Google Scholar]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond accuracy, F-score and ROC: A family of discriminant measures for performance evaluation. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Hobart, Australia, 4–8 December 2006; pp. 1015–1021. [Google Scholar]
- Shahiri, A.M.; Husain, W.; Rashid, N.A. A review on predicting student’s performance using data mining techniques. Procedia Comput. Sci. 2015, 72, 414–422. [Google Scholar] [CrossRef] [Green Version]
- Kaur, P.; Singh, M.; Josan, G.S. Classification and prediction based data mining algorithms to predict slow learners in education sector. Procedia Comput. Sci. 2015, 57, 500–508. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Mean ± SD 1 |
|---|---|
| High school percentage (HSP) | 99.23 ± 1.07 |
| General aptitude test (GAT) | 90.00 ± 4.72 |
| Standard achievement admission test (SAAT) | 89.44 ± 6.80 |
| Grade point average (GPA) | 4.09 ± 0.72 |
| Variables | Pearson Correlation Coefficient | p-Value | Standard Error |
|---|---|---|---|
| High school percentage (HSP) | 0.3779 | 0.00 | 0.0278 |
| General aptitude test (GAT) | 0.2814 | 0.00 | 0.0298 |
| Standard achievement admission test (SAAT) | 0.5144 | 0.00 | 0.0238 |
| Admission Score Current (ASC) | 0.5135 | 0.00 | 0.0238 |
| Admission Score Optimized (ASO) | 0.5269 | 0.00 | 0.0238 |
| Metrics | Accuracy | Precision | Recall | F1 Score | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Techniques | ASC 1 | ASO 2 | % imp 3 | ASC | ASO | % imp | ASC | ASO | % imp | ASC | ASO | % imp |
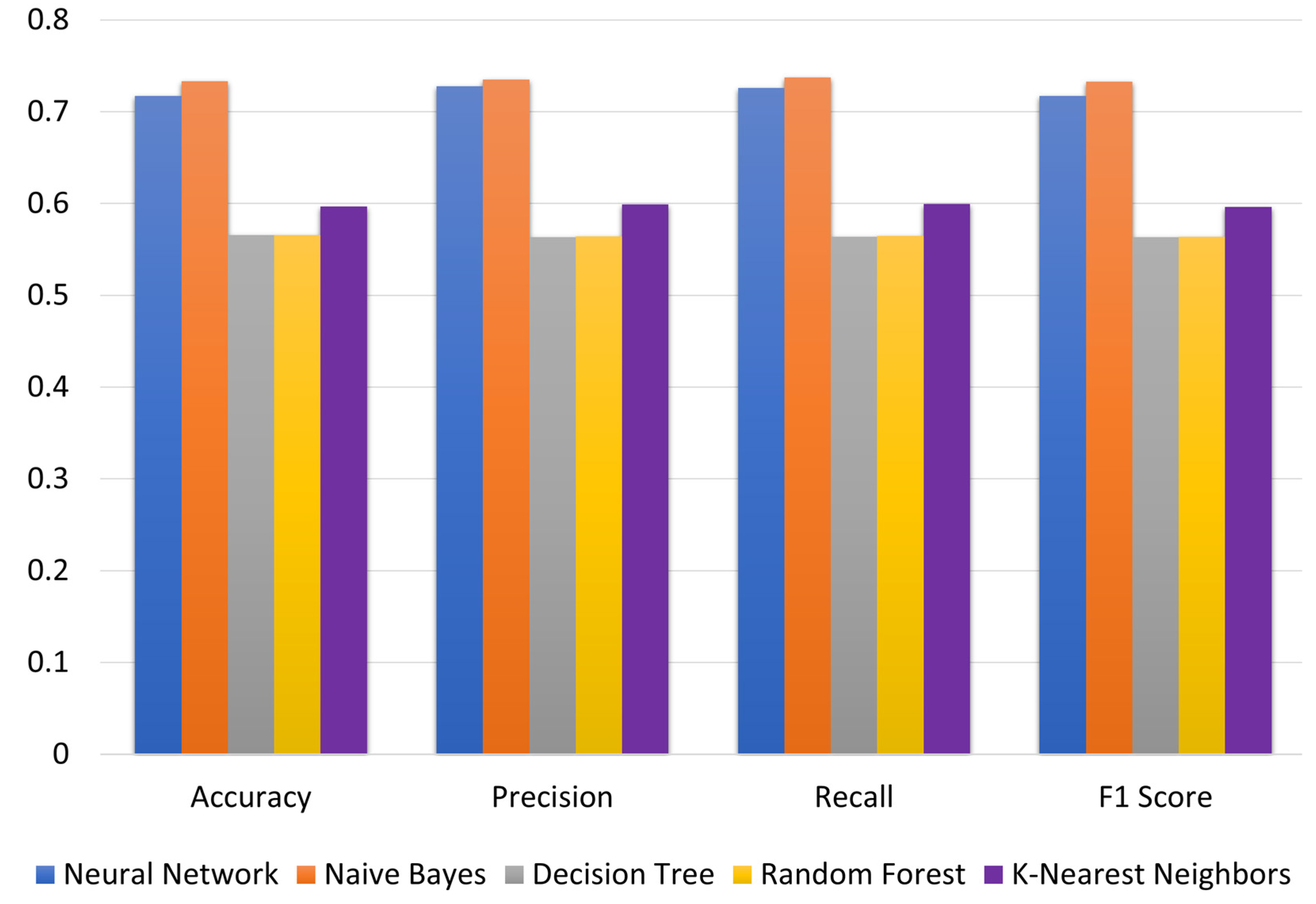
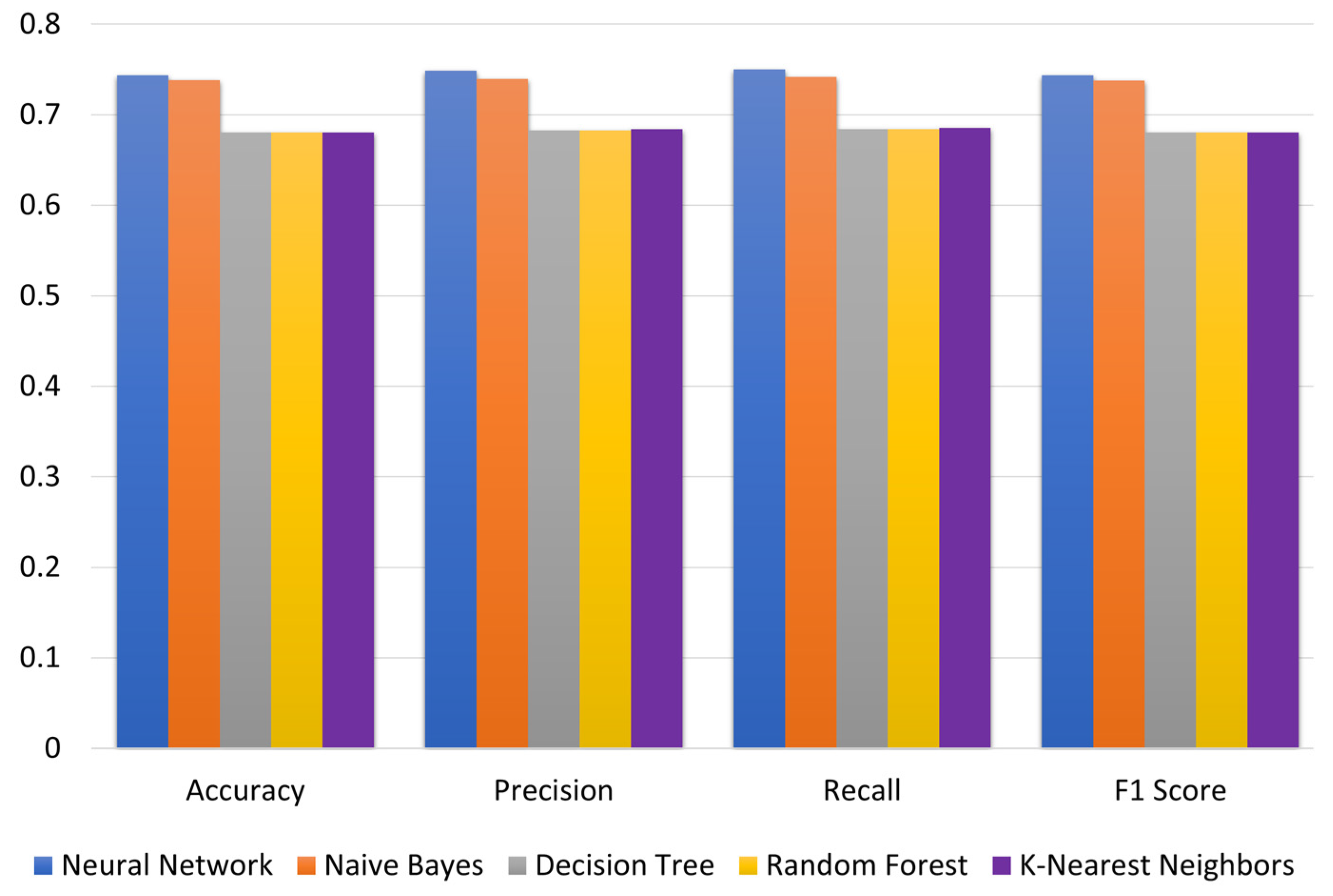
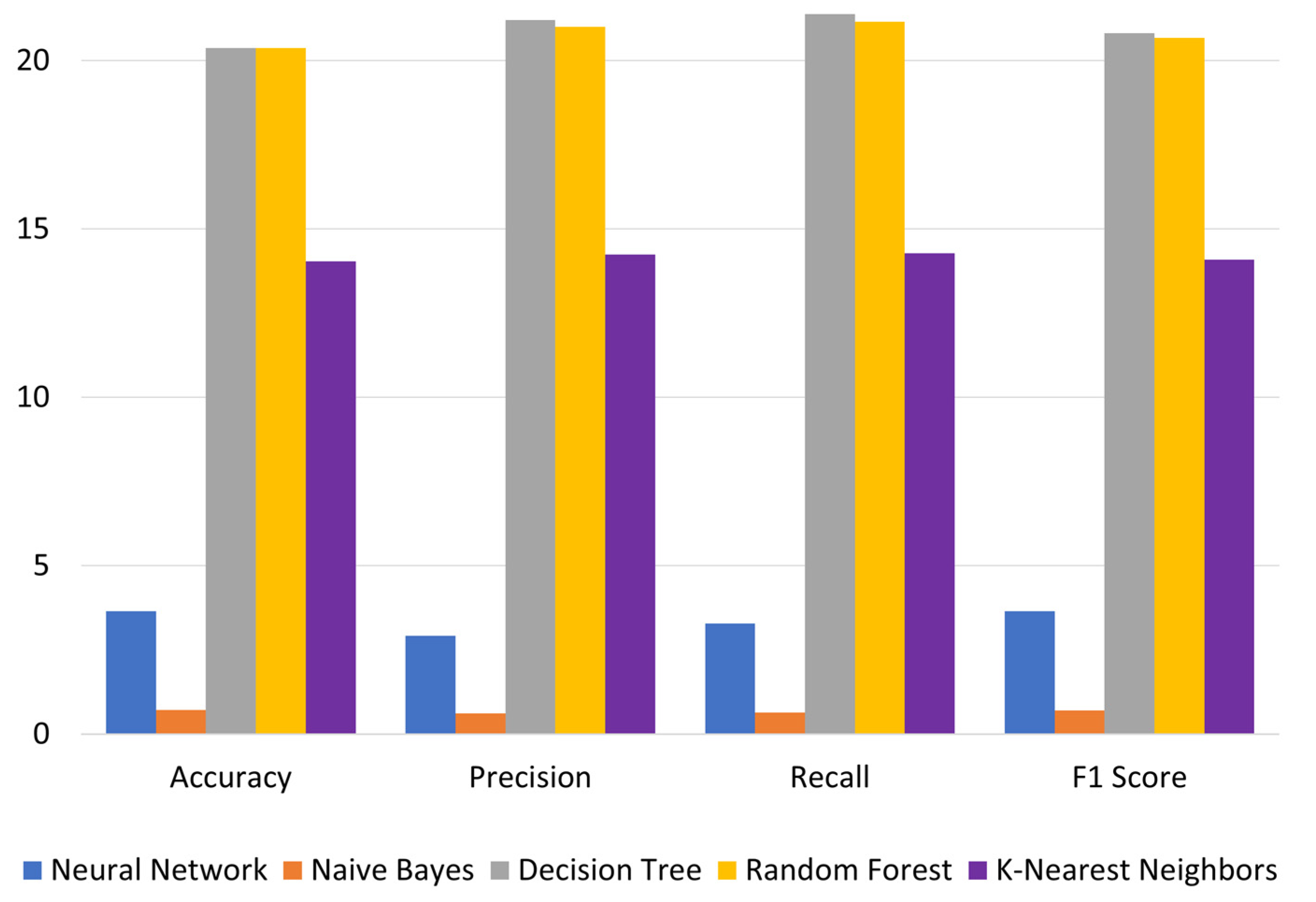
| Decision Tree | 0.565 | 0.681 | 20.4% | 0.563 | 0.683 | 21.2% | 0.564 | 0.684 | 21.4% | 0.563 | 0.680 | 20.8% |
| Neural Network | 0.717 | 0.743 | 3.6% | 0.728 | 0.749 | 2.9% | 0.726 | 0.750 | 3.3% | 0.717 | 0.743 | 3.7% |
| Random Forest | 0.565 | 0.681 | 20.4% | 0.564 | 0.683 | 21.0% | 0.565 | 0.684 | 21.2% | 0.564 | 0.680 | 20.7% |
| Naïve Bayes | 0.733 | 0.738 | 0.7% | 0.735 | 0.740 | 0.6% | 0.737 | 0.742 | 0.6% | 0.733 | 0.738 | 0.7% |
| K-Nearest Neighbors | 0.597 | 0.681 | 14.0% | 0.599 | 0.684 | 14.2% | 0.600 | 0.685 | 14.3% | 0.596 | 0.680 | 14.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qahmash, A.; Ahmad, N.; Algarni, A. Investigating Students’ Pre-University Admission Requirements and Their Correlation with Academic Performance for Medical Students: An Educational Data Mining Approach. Brain Sci. 2023, 13, 456. https://doi.org/10.3390/brainsci13030456
Qahmash A, Ahmad N, Algarni A. Investigating Students’ Pre-University Admission Requirements and Their Correlation with Academic Performance for Medical Students: An Educational Data Mining Approach. Brain Sciences. 2023; 13(3):456. https://doi.org/10.3390/brainsci13030456
Chicago/Turabian StyleQahmash, Ayman, Naim Ahmad, and Abdulmohsen Algarni. 2023. "Investigating Students’ Pre-University Admission Requirements and Their Correlation with Academic Performance for Medical Students: An Educational Data Mining Approach" Brain Sciences 13, no. 3: 456. https://doi.org/10.3390/brainsci13030456