
Supervised Learning Algorithm Based on Spike Train Inner Product for Deep Spiking Neural Networks

Abstract
:1. Introduction
2. Related Works
2.1. Learning Algorithms Based on Network Conversion
2.2. Learning Algorithms Based on Synaptic Plasticity
2.3. Learning Algorithms Based on Gradient Descent
3. Definition of STIP and Error Function
3.1. Kernel Function and STIP Representation
3.2. Spike Train Relationship and Error Function
4. DSNN Supervised Learning Algorithms
4.1. Backpropagation Learning Rule Based on STIP
4.2. Feedback Alignment Learning Rule Based on STIP
4.3. Broadcast Alignment Learning Rule Based on STIP
5. Experimental Results and Discussion
5.1. Deep Learning Framework and Parameter Settings
- Spike train encoding of grey-scale images. The first step is to flatten the two-dimensional matrix of image data into a one-dimensional vector with 784 pixels, and normalize elements of the vector to [0,1]. Then, 784 spike trains are generated from the pixel vector of the sample image using the Poisson encoding method [44]. Subsequently, these spike trains are inputted into the input layer of DSNN.
- DSNN simulation. The clock-driven strategy is applied to simulate the DSNN with multiple hidden layers, and the spike trains fired by neurons are used for synaptic weight learning and sample classification.
- Decoding and sample classification. According to the number of categories of MNIST problems, the output layer of the network contains 10 neurons, and the spike trains of output neurons are used for decoding and classification. Similar to the calculation method of Softmax, the category is divided according to the similarity between the spike trains of output neurons and the target spike trains.
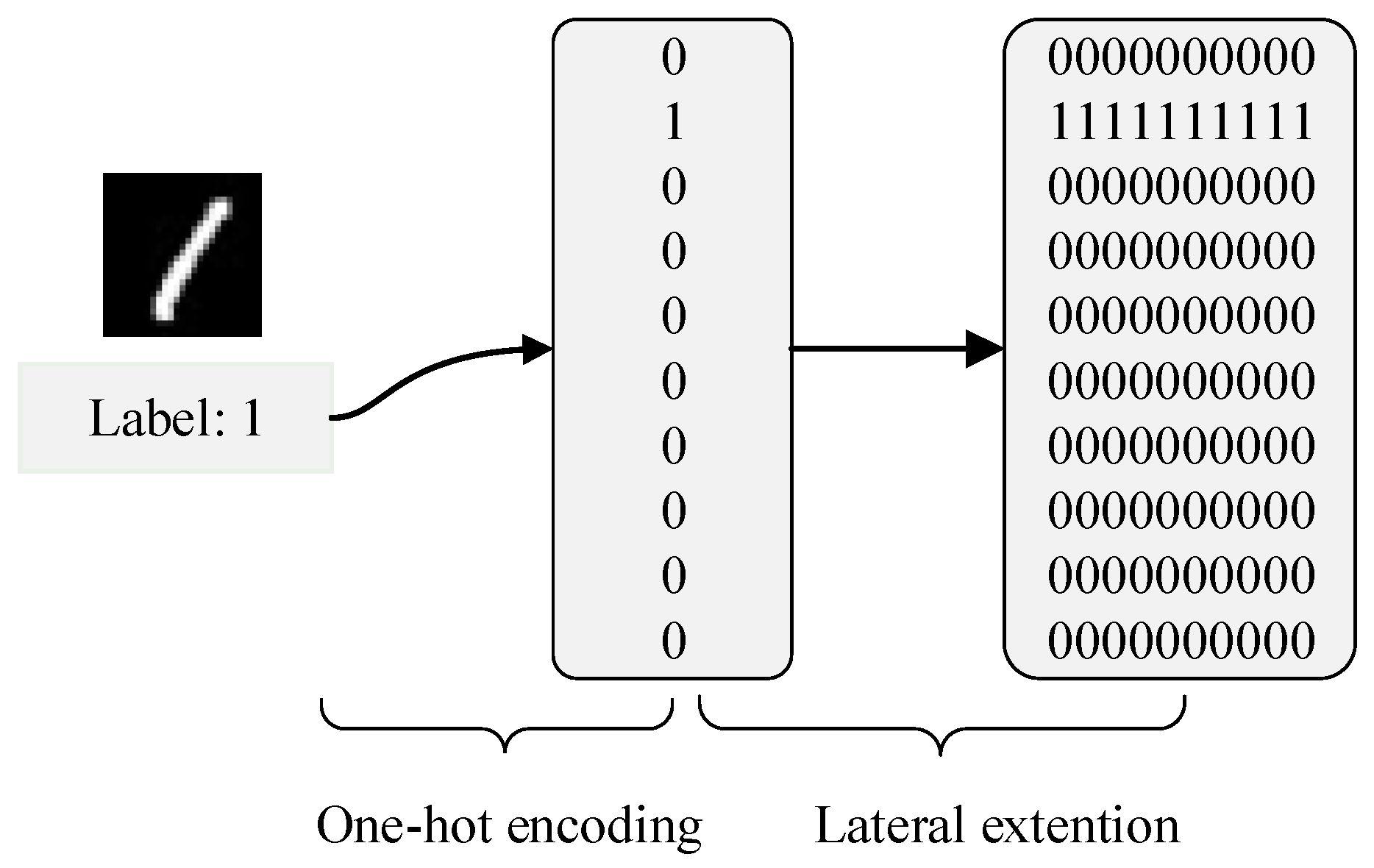
- Target spike train generation based on labels. The DSNN takes spike trains as the carrier of information processing and propagation, so labels from 0 to 9 need to be encoded into corresponding target spike trains, which are important information for sample classification and error signal calculation.
- Error backpropagation and deep learning. According to the actual spike trains of the output layer neurons, combined with the target spike trains, the error of DSNN is calculated. Based on the different feedback pathways of error signal backpropagation, the proposed deep learning algorithm, such as BP-STIP, FA-STIP or BA-STIP, is applied to adjust the synaptic weights of the network.
5.2. Learning Process Analysis of the Algorithms
5.3. Comparison and Analysis of Different Kernel Functions
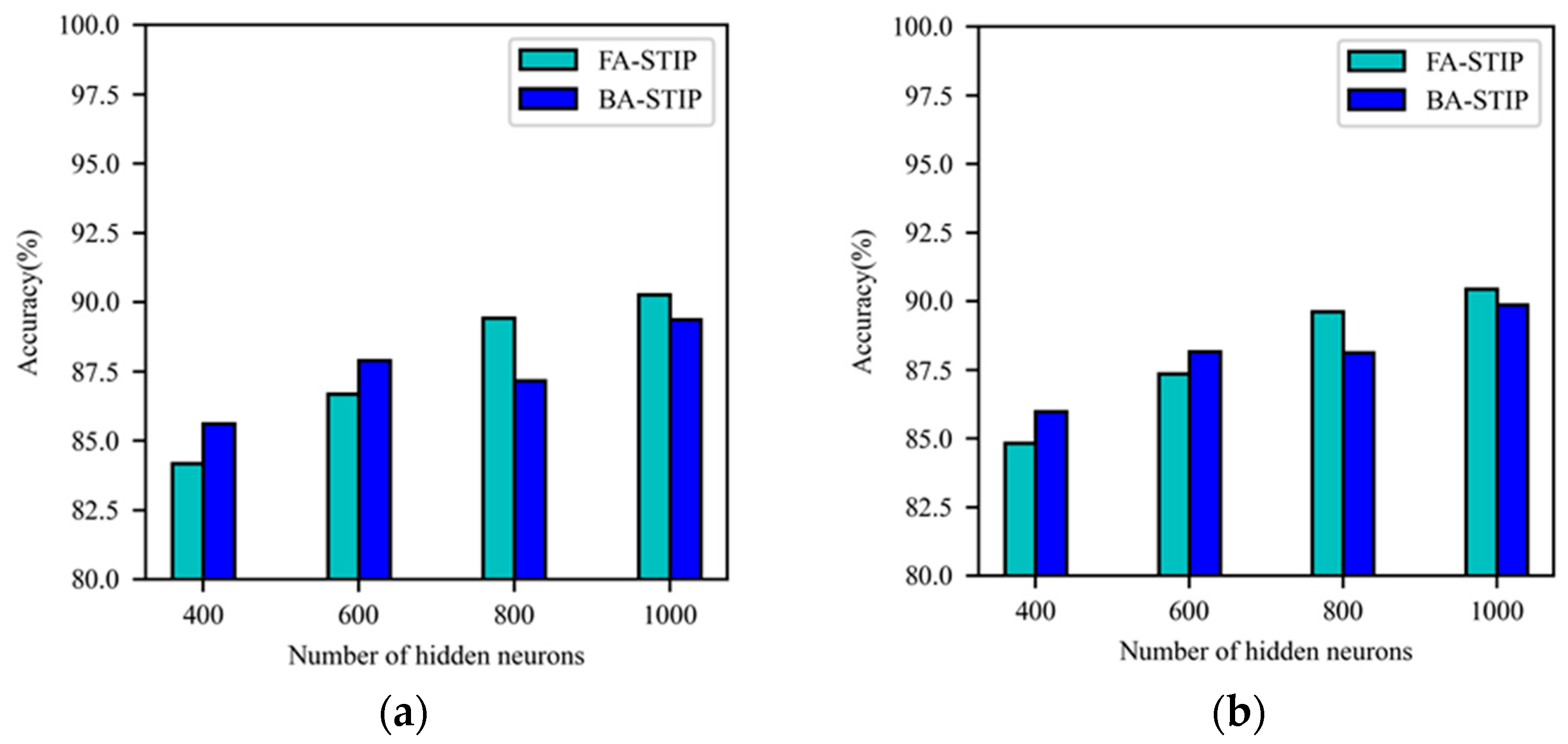
5.4. Comparison of Different Deep Learning Algorithms
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Basheer, I.A.; Hajmeer, M. Artificial neural networks: Fundamentals, computing, design, and application. J. Microbiol. Methods 2000, 43, 3–31. [Google Scholar] [CrossRef] [PubMed]
- Jiao, L.C.; Yang, S.Y.; Liu, F.; Wang, S.G.; Feng, Z.X. Seventy years beyond neural networks: Retrospect and prospect. Chin. J. Comput. 2016, 39, 1697–1716. [Google Scholar]
- Ghosh-Dastidar, S.; Adeli, H. Spiking neural networks. Int. J. Neural. Syst. 2009, 19, 295–308. [Google Scholar] [CrossRef] [Green Version]
- Kreiman, G. Neural coding: Computational and biophysical perspectives. Phys. Life Rev. 2004, 1, 71–102. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Ali, R.; Hardie, R.C.; Narayanan, B.N.; Kebede, T.M. IMNets: Deep Learning Using an Incremental Modular Network Synthesis Approach for Medical Imaging Applications. Appl. Sci. 2022, 12, 5500. [Google Scholar] [CrossRef]
- Ali, R.; Li, H.; Dillman, J.R.; Altaye, M.; Wang, H.; Parikh, N.A.; He, L. A self-training deep neural network for early prediction of cognitive deficits in very preterm infants using brain functional connectome data. Pediatr. Radiol. 2022, 52, 2227–2240. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zaidi, B.F.; Selouani, S.A.; Boudraa, M.; Yakoub, M.S. Deep neural network architectures for dysarthric speech analysis and recognition. Neural Comput. Appl. 2021, 33, 9089–9108. [Google Scholar] [CrossRef]
- Pfeiffer, M.; Pfeil, T. Deep Learning with Spiking Neurons: Opportunities and Challenges. Front. Neurosci. 2018, 12, 774. [Google Scholar] [CrossRef] [Green Version]
- Mirsadeghi, M.; Shalchian, M.; Kheradpisheh, S.R.; Masquelier, T. STiDi-BP: Spike time displacement based error backpropagation in multilayer spiking neural networks. Neurocomputing 2021, 427, 131–140. [Google Scholar] [CrossRef]
- Shen, G.; Zhao, D.; Zeng, Y. Backpropagation with biologically plausible spatio-temporal adjustment for training deep spiking neural networks. arXiv 2021, arXiv:2110.088582021. [Google Scholar] [CrossRef]
- Kolen, J.F.; Pollack, J.B. Backpropagation without weight transport. In Proceedings of the 1994 IEEE International Conference on Neural Networks, Orlando, FL, USA, 27 June–2 July 1994; pp. 1375–1380. [Google Scholar]
- Lillicrap, T.P.; Cownden, D.; Tweed, D.B.; Akerman, C.J. Random synaptic feedback weights support error backpropagation for deep learning. Nat. Commun. 2016, 7, 13276. [Google Scholar] [CrossRef]
- Nøkland, A. Direct feedback alignment provides learning in deep neural networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 1045–1053. [Google Scholar]
- Crafton, B.; Parihar, A.; Gebhardt, E.; Raychowdhury, A. Direct Feedback Alignment with Sparse Connections for Local Learning. Front. Neurosci. 2019, 13, 525. [Google Scholar] [CrossRef]
- Paiva, A.; Park, I.M.; Príncipe, J.C. A Reproducing Kernel Hilbert Space Framework for Spike Train Signal Processing. Neural Comput. 2009, 21, 424–449. [Google Scholar] [CrossRef]
- Park, I.M.; Seth, S.; Paiva, A.R.; Li, L.; Principe, J.C. Kernel Methods on Spike Train Space for Neuroscience: A Tutorial. IEEE Signal Process. Mag. 2013, 30, 149–160. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Lin, X.; Dang, X. Supervised learning in spiking neural networks: A review of algorithms and evaluations. Neural Netw. 2020, 125, 258–280. [Google Scholar] [CrossRef]
- Lin, X.; Zhang, M.; Wang, X. Supervised Learning Algorithm for Multilayer Spiking Neural Networks with Long-Term Memory Spike Response Model. Comput. Intell. Neurosci. 2021, 2021, 1–16. [Google Scholar] [CrossRef]
- Tavanaei, A.; Ghodrati, M.; Kheradpisheh, S.R.; Masquelier, T.; Maida, A. Deep learning in spiking neural networks. Neural Netw. 2019, 111, 47–63. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Lian, S.; Zhang, Y.; Cui, X.; Yan, R.; Tang, H. Towards lossless ANN-SNN conversion under ultra-low latency with dual-phase optimization. arXiv 2022, arXiv:2205.07473. [Google Scholar]
- Diehl, P.U.; Neil, D.; Binas, J.; Cook, M.; Liu, S.C.; Pfeiffer, M. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In Proceedings of the 2015 International Joint Conference on Neural Networks, Killarney, Ireland, 12–16 July 2015; pp. 1–8. [Google Scholar]
- Kheradpisheh, S.R.; Mirsadeghi, M.; Masquelier, T. Spiking neural networks trained via proxy. arXiv 2021, arXiv:2109.13208. [Google Scholar] [CrossRef]
- Rueckauer, B.; Lungu, I.-A.; Hu, Y.; Pfeiffer, M.; Liu, S.-C. Conversion of Continuous-Valued Deep Networks to Efficient Event-Driven Networks for Image Classification. Front. Neurosci. 2017, 11, 682. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, Z.; Zhu, W.; Yu, S.; Liu, L.; Wu, N. Deterministic conversion rule for CNNs to efficient spiking convolutional neural networks. Sci. China Inf. Sci. 2020, 63, 122402. [Google Scholar] [CrossRef] [Green Version]
- O’Connor, P.; Neil, D.; Liu, S.-C.; Delbruck, T.; Pfeiffer, M. Real-time classification and sensor fusion with a spiking deep belief network. Front. Neurosci. 2013, 7, 178. [Google Scholar] [CrossRef] [Green Version]
- Caporale, N.; Dan, Y. Spike Timing–Dependent Plasticity: A Hebbian Learning Rule. Annu. Rev. Neurosci. 2008, 31, 25–46. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.; Srinivasan, G.; Panda, P.; Roy, K. Deep Spiking Convolutional Neural Network Trained with Unsupervised Spike-Timing-Dependent Plasticity. IEEE Trans. Cogn. Dev. Syst. 2019, 11, 384–394. [Google Scholar] [CrossRef]
- Lee, C.; Panda, P.; Srinivasan, G.; Roy, K. Training Deep Spiking Convolutional Neural Networks with STDP-Based Unsupervised Pre-training Followed by Supervised Fine-Tuning. Front. Neurosci. 2018, 12, 435. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Mesnard, T.; Fischer, A.; Zhang, S.; Wu, Y. STDP-Compatible Approximation of Backpropagation in an Energy-Based Model. Neural Comput. 2017, 29, 555–577. [Google Scholar] [CrossRef]
- Tavanaei, A.; Maida, A. BP-STDP: Approximating backpropagation using spike timing dependent plasticity. Neurocomputing 2019, 330, 39–47. [Google Scholar] [CrossRef] [Green Version]
- Liu, D.; Bellotto, N.; Yue, S. Deep Spiking Neural Network for Video-Based Disguise Face Recognition Based on Dynamic Facial Movements. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1843–1855. [Google Scholar] [CrossRef]
- O’Connor, P.; Welling, M. Deep spiking networks. arXiv 2016, arXiv:602.08323. [Google Scholar]
- Lee, J.H.; Delbruck, T.; Pfeiffer, M. Training Deep Spiking Neural Networks Using Backpropagation. Front. Neurosci. 2016, 10, 508. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mostafa, H. Supervised Learning Based on Temporal Coding in Spiking Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3. [Google Scholar] [CrossRef] [PubMed]
- Neftci, E.O.; Mostafa, H.; Zenke, F. Surrogate Gradient Learning in Spiking Neural Networks: Bringing the Power of Gradient-Based Optimization to Spiking Neural Networks. IEEE Signal Process Mag. 2019, 36, 51–63. [Google Scholar] [CrossRef]
- Neftci, E.O.; Charles, A.; Somnath, P.; Georgios, D. Event-driven random back-propagation: Enabling neuromorphic deep learning machines. Front. Neurosci. 2017, 11, 324. [Google Scholar] [CrossRef] [Green Version]
- Samadi, A.; Lillicrap, T.P.; Tweed, D.B. Deep Learning with Dynamic Spiking Neurons and Fixed Feedback Weights. Neural Comput. 2017, 29, 578–602. [Google Scholar] [CrossRef]
- Shi, C.; Wang, T.; He, J.; Zhang, J.; Liu, L.; Wu, N. DeepTempo: A Hardware-Friendly Direct Feedback Alignment Multi-Layer Tempotron Learning Rule for Deep Spiking Neural Networks. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 1581–1585. [Google Scholar] [CrossRef]
- Lin, X.; Wang, X.; Hao, Z. Supervised learning in multilayer spiking neural networks with inner products of spike trains. Neurocomputing 2017, 237, 59–70. [Google Scholar] [CrossRef]
- Carnell, A.; Richardson, D. Linear algebra for times series of spikes. In Proceedings of the 13th European Symposium on Artificial Neural Networks, Evere, Burges, Belgium, 27–29 April 2005; pp. 363–368. [Google Scholar]
- Frémaux, N.; Wulfram, G. Neuromodulated spike-timing-dependent plasticity, and theory of three-factor learning rules. Front. Neural Circ. 2016, 9, 172. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Zeng, X.; Han, L.; Yang, J. A supervised multi-spike learning algorithm based on gradient descent for spiking neural networks. Neural Netw. 2013, 43, 99–113. [Google Scholar] [CrossRef] [PubMed]
- Lin, X.; Wang, X.; Dang, X. A new supervised learning algorithm for spiking neurons based on spike train kernels. Acta Electron. Sinica 2016, 44, 2877–2886. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Parameter | Value |
|---|---|---|
| Network | Number of input neurons | 784 |
| Number of output neurons | 10 | |
| Number of hidden layers | 2 | |
| Weight initialization distribution | N(0,1) | |
| LIF neuron | Time constant of membrane potential | 5.0 ms |
| Threshold voltage of spike firing | 5.0 | |
| Reset voltage of membrane potential | 0.0 | |
| Algorithm | Random feedback path distribution | N(0,1) |
| Batch size | 64 | |
| Learning rate | 0.00008 | |
| Epochs | 150 |
| Kernel Function | Expression | Parameter |
|---|---|---|
| Gaussian | 40 | |
| Laplacian | 80 | |
| Inverse multiquadratic | 30 | |
| α-function | 5 |
| Algorithm | DSNN Structure | Neuron Model | Encoding Method | Accuracy (%) |
|---|---|---|---|---|
| ANN-to-SNN [23] | 784-1200-1200-10 | IF | frequency | 98.68 |
| ANN-to-SNN [25] | 784-32C-32C-P-64C-64C-P-512-10 | IF | frequency | 99.44 |
| ANN-to-SNN [26] | 784-12C-P-64C-P-10 | IF | frequency | 99.09 |
| SDBN [27] | 784-500-500-10 | LIF | temporal | 94.09 |
| Layer-wise STDP [29] | 784-16C-16C-P-10 | LIF | frequency | 91.10 |
| STDP-based Pretraining + BP [30] | 784-20C-P-50C-P-200-10 | LIF | frequency | 99.28 |
| BP-STDP [32] | 784-500-150-10 | IF | frequency | 97.20 |
| SNN-BP [35] | 784-500-500-10 | LIF | frequency | 98.70 |
| SNN-BP [36] | 784-400-400-10 | LIF | temporal | 96.92 |
| eRBP [38] | 784-500-500-10 | LIF | frequency | 97.64 |
| SNN-BA [39] | 784-630-370-10 | LIF | frequency | 97.05 |
| DeepTempo [40] | 784-400-400-10 | LIF | temporal | 95.10 |
| BP-STIP (Laplacian kernel) | 784-800-800-10 | LIF | temporal | 91.56 |
| FA-STIP (Gaussian kernel) | 784-1000-1000-10 | LIF | temporal | 94.73 |
| BA-STIP (α-kernel) | 784-400-400-10 | LIF | temporal | 95.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, X.; Zhang, Z.; Zheng, D. Supervised Learning Algorithm Based on Spike Train Inner Product for Deep Spiking Neural Networks. Brain Sci. 2023, 13, 168. https://doi.org/10.3390/brainsci13020168
Lin X, Zhang Z, Zheng D. Supervised Learning Algorithm Based on Spike Train Inner Product for Deep Spiking Neural Networks. Brain Sciences. 2023; 13(2):168. https://doi.org/10.3390/brainsci13020168
Chicago/Turabian StyleLin, Xianghong, Zhen Zhang, and Donghao Zheng. 2023. "Supervised Learning Algorithm Based on Spike Train Inner Product for Deep Spiking Neural Networks" Brain Sciences 13, no. 2: 168. https://doi.org/10.3390/brainsci13020168