
Different Approximation Methods for Calculation of Integrated Information Coefficient in the Brain during Instrumental Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Behavioral Experiment
2.2. Applied Approximation Methods for Calculation
2.3. Calculation of for Time-Series Spike Data
2.4. Statistical Analysis
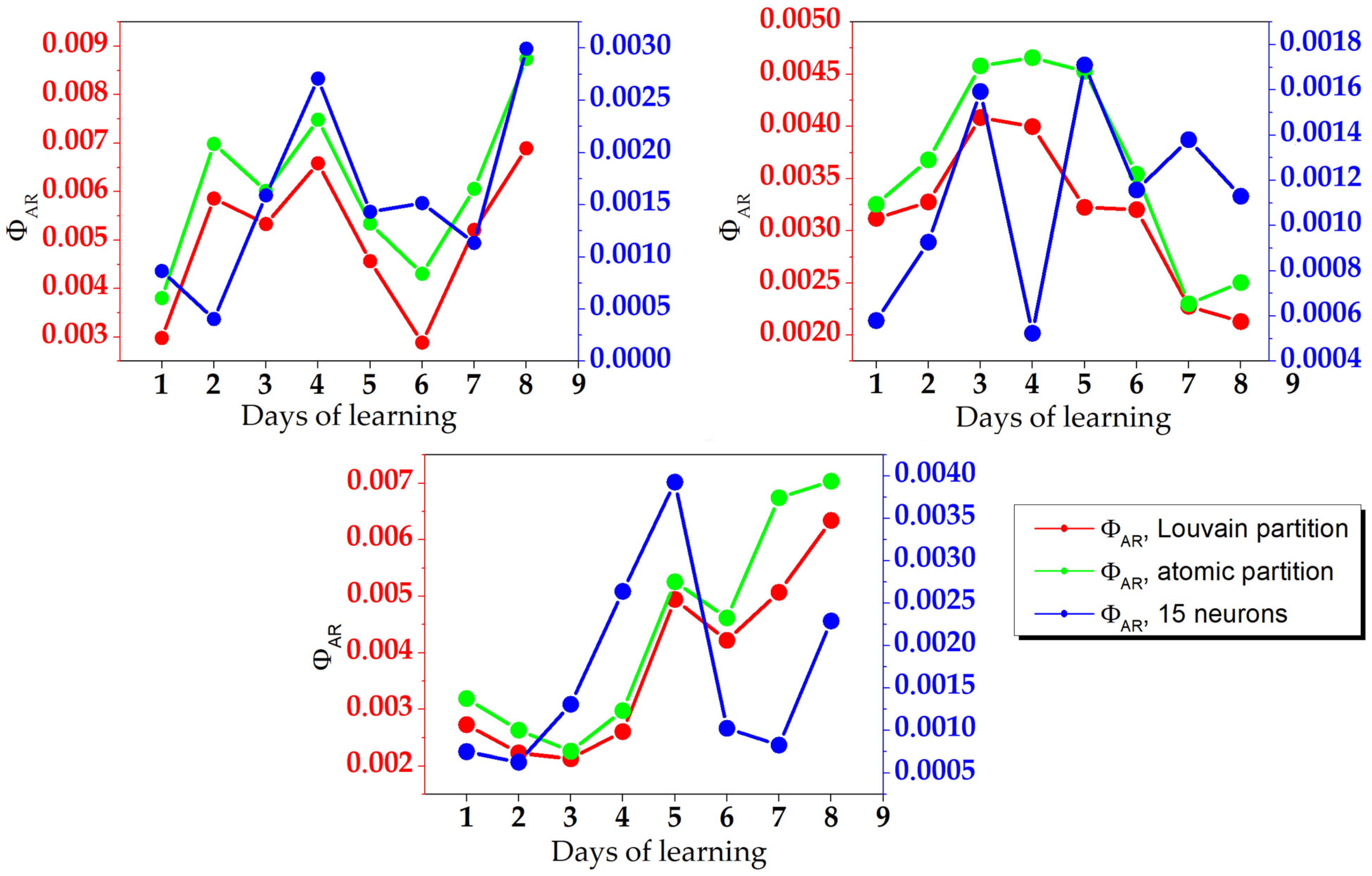
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tononi, G.; Edelman, G.M.; Sporns, O. Complexity and coherency: Integrating information in the brain. Trends Cogn. Sci. 1998, 2, 474–484. [Google Scholar] [CrossRef]
- Tononi, G. An information integration theory of consciousness. BMC Neurosci. 2004, 5, 42. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Balduzzi, D.; Tononi, G. Integrated information in discrete dynamical systems: Motivation and theoretical framework. PLoS Comput. Biol. 2008, 4, e1000091. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tononi, G. The integrated information theory of consciousness: An updated account. Arch. Ital. Biol. 2012, 150, 56–90. [Google Scholar]
- Sarasso, S.; Boly, M.; Napolitani, M.; Gosseries, O.; Charland-Verville, V.; Casarotto, S.; Rosanova, M.; Casali, A.G.; Brichant, J.-F.; Boveroux, P.; et al. Consciousness and complexity during unresponsiveness induced by propofol, xenon, and ketamine. Curr. Biol. 2015, 25, 3099–3105. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Casali, A.G.; Gosseries, O.; Rosanova, M.; Boly, M.; Sarasso, S.; Casali, K.R.; Casarotto, S.; Bruno, M.-A.; Laureys, S.; Tononi, G.; et al. A theoretically based index of consciousness independent of sensory processing and behavior. Sci. Transl. Med. 2013, 5, ra105–ra198. [Google Scholar] [CrossRef] [PubMed]
- Lee, U.; Kim, S.; Noh, G.J.; Choi, B.M.; Mashour, G.A. Propofol induction reduces the capacity for neural information integration: Implications for the mechanism of consciousness and general anesthesia. Nat. Preced. 2008, 1. [Google Scholar] [CrossRef] [Green Version]
- Leung, A.; Cohen, D.; Van Swinderen, B.; Tsuchiya, N. Integrated information structure collapses with anesthetic loss of conscious arousal in Drosophila melanogaster. PLoS Comput. Biol. 2021, 17, e1008722. [Google Scholar] [CrossRef] [PubMed]
- Tagliazucchi, E. The signatures of conscious access and its phenomenology are consistent with large-scale brain communication at criticality. Conscious Cogn. 2017, 55, 136–147. [Google Scholar] [CrossRef] [Green Version]
- Edlund, J.A.; Chaumont, N.; Hintze, A.; Koch, C.; Tononi, G.; Adami, C. Integrated information increases with fitness in the evolution of animats. PLoS Comput. Biol. 2011, 7, e1002236. [Google Scholar] [CrossRef] [Green Version]
- Engel, D.; Malone, T.W. Integrated information as a metric for group interaction. PLoS ONE 2018, 13, e0205335. [Google Scholar] [CrossRef] [PubMed]
- Niizato, T.; Sakamoto, K.; Mototake, Y.I.; Murakami, H.; Tomaru, T.; Hoshika, T.; Fukushima, T. Finding continuity and discontinuity in fish schools via integrated information theory. PLoS ONE 2020, 15, e0229573. [Google Scholar] [CrossRef] [PubMed]
- Fischer, D.; Mostaghim, S.; Albantakis, L. How cognitive and environmental constraints influence the reliability of simulated animats in groups. PLoS ONE 2020, 15, e0228879. [Google Scholar] [CrossRef] [PubMed]
- Popiel, N.J.; Khajehabdollahi, S.; Abeyasinghe, P.M.; Riganello, F.; Nichols, E.S.; Owen, A.M.; Soddu, A. The emergence of integrated information, complexity, and ‘consciousness’ at criticality. Entropy 2020, 22, 339. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mediano, P.A.; Rosas, F.E.; Farah, J.C.; Shanahan, M.; Bor, D.; Barrett, A.B. Integrated information as a common signature of dynamical and information-processing complexity. Chaos 2022, 32, 013115. [Google Scholar] [CrossRef] [PubMed]
- Fujii, K.; Kanazawa, H.; Kuniyoshi, Y. Spike Timing Dependent Plasticity Enhances Integrated Information at the EEG Level: A Large-scale Brain Simulation Experiment. In Proceedings of the 2019 Joint IEEE 9th International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Oslo, Norway, 19–22 August 2019. [Google Scholar]
- Isler, J.R.; Stark, R.I.; Grieve, P.G.; Welch, M.G.; Myers, M.M. Integrated information in the EEG of preterm infants increases with family nurture intervention, age, and conscious state. PLoS ONE 2018, 13, e0206237. [Google Scholar] [CrossRef] [PubMed]
- Rota, G.C. The number of partitions of a set. Am. Math. Mon. 1964, 71, 498–504. [Google Scholar] [CrossRef]
- Barrett, A.B.; Seth, A.K. Practical measures of integrated information for time-series data. PLoS Comput. Biol. 2011, 7, e1001052. [Google Scholar] [CrossRef] [Green Version]
- Graham, R.L.; Knuth, D.E.; Patashnik, O. Concrete Mathematics, 2nd ed.; Addison-Wesley: Boston, MA USA, 1994; pp. 257–267. [Google Scholar]
- Jadhav, S.P.; Rothschild, G.; Roumis, D.K.; Frank, L.M. Coordinated excitation and inhibition of prefrontal ensembles during awake hippocampal sharp-wave ripple events. Neuron 2016, 90, 113–127. [Google Scholar] [CrossRef] [Green Version]
- Tang, W.; Shin, J.D.; Frank, L.M.; Jadhav, S.P. Hippocampal-prefrontal reactivation during learning is stronger in awake compared with sleep states. J. Neurosci. 2017, 37, 11789–11805. [Google Scholar] [CrossRef]
- Jadhav, S.P.; Frank, L. Simultaneous Extracellular Recordings from Hippocampal Area CA1 and Medial Prefrontal Cortex from Rats Performing a W-Track Alternation Task. CRCNS.org. 2020. Available online: https://crcns.org/data-sets/hc (accessed on 23 February 2022). [CrossRef]
- Li, Y.; Liu, Y.; Li, J.; Qin, W.; Li, K.; Yu, C.; Jiang, T. Brain anatomical network and intelligence. PLoS Comput. Biol. 2009, 5, e1000395. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, H.J.; Friston, K. Structural and functional brain networks: From connections to cognition. Science 2013, 342, 1238411. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hong, G.; Lieber, C.M. Novel electrode technologies for neural recordings. Nat. Rev. Neurosci. 2019, 20, 330–345. [Google Scholar] [CrossRef] [PubMed]
- Steinmetz, N.A.; Aydin, C.; Lebedeva, A.; Okun, M.; Pachitariu, M.; Bauza, M.; Beau, M.; Bhagat, J.; Bohm, C.; Broux, M.; et al. Neuropixels 2.0: A miniaturized high-density probe for stable, long-term brain recordings. Science 2021, 372, eabf4588. [Google Scholar] [CrossRef] [PubMed]
- Kitazono, J.; Kanai, R.; Oizumi, M. Efficient Algorithms for Searching the Minimum Information Partition in Integrated Information Theory. Entropy 2018, 20, 173. [Google Scholar] [CrossRef] [Green Version]
- Mediano, P.A.; Seth, A.K.; Barrett, A.B. Measuring integrated information: Comparison of candidate measures in theory and simulation. Entropy 2019, 21, 17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Toker, D.; Sommer, F.T. Information integration in large brain networks. PLoS Comput. Biol. 2019, 15, e1006807. [Google Scholar] [CrossRef] [Green Version]
- Sporns, O. Network attributes for segregation and integration in the human brain. Curr. Opin. Neurobiol. 2013, 23, 162–171. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech-Theory E 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Advances in Neural Information Processing Systems: Proceedings of the 2001 Conference, British Columbia, Canada, 3–8 December 2001; MIT Press: Cambridge, MA, USA.
- Faskowitz, J.; Yan, X.; Zuo, X.N.; Sporns, O. Weighted stochastic block models of the human connectome across the life span. Sci. Rep. 2018, 8, 12997. [Google Scholar] [CrossRef] [Green Version]
- Strong, S.P.; Koberle, R.; Van Steveninck, R.R.D.R.; Bialek, W. Entropy and information in neural spike trains. Phys. Rev. Lett. 1980, 80, 197. [Google Scholar] [CrossRef]
- GenLouvain/GenLouvain: A Generalized Louvain Method for Community Detection Implemented in MATLAB. Available online: https://github.com/GenLouvain/GenLouvain (accessed on 23 February 2022).
- O’Keefe, J.; Dostrovsky, J. The hippocampus as a spatial map: Preliminary evidence from unit activity in the freely-moving rat. Brain Res. 1971, 34, 171–175. [Google Scholar] [CrossRef]
- VanRullen, R. Perceptual cycles. Trends Cogn. Sci. 2016, 20, 723–735. [Google Scholar] [CrossRef] [PubMed]
- Fiebelkorn, I.C.; Pinsk, M.A.; Kastner, S. A dynamic interplay within the frontoparietal network underlies rhythmic spatial attention. Neuron 2018, 99, 842–853. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Helfrich, R.F.; Fiebelkorn, I.C.; Szczepanski, S.M.; Lin, J.J.; Parvizi, J.; Knight, R.T.; Kastner, S. Neural mechanisms of sustained attention are rhythmic. Neuron 2018, 99, 854–865. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 15 Neurons | Louvain Partition | Atomic Partition | |
|---|---|---|---|
| Animal 1 | 14 bins (0.42 s) | 15 bins (0.45 s) | 15 bins (0.45 s) |
| Animal 2 | 16 bins (0.48 s) | 17 bins (0.56 s) | 13 bins (0.39 s) |
| Animal 3 | 13 bins (0.39 s) | 12 bins (0.36 s) | 12 bins (0.36 s) |
| 15 Neurons | Louvain Partition | Atomic Partition | |
|---|---|---|---|
| Animal 1 | r = 0.4796 p < 0.0001 ** | r = 0.5364 p < 0.0001 ** | r = 0.5911 p < 0.0001 ** |
| Animal 2 | r = 0.3229 p = 0.0008 * | r = −0.2274 p = 0.0213 ns | r = −0.1293 p = 0.3987 ns |
| Animal 3 | r = 0.3096 p = 0.0014 * | r = 0.5726 p < 0.0001 ** | r = 0.6544 p < 0.0001 ** |
| Louvain Partition | Atomic Partition | |
|---|---|---|
| Animal 1 | r = 0.6767 p < 0.0001 ** | r = 0.6645 p < 0.0001 ** |
| Animal 2 | r = 0.4557 p < 0.0001 ** | r = 0.3952 p < 0.0001 ** |
| Animal 3 | r = 0.6060 p < 0.0001 ** | r = 0.6544 p < 0.0001 ** |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nazhestkin, I.; Svarnik, O. Different Approximation Methods for Calculation of Integrated Information Coefficient in the Brain during Instrumental Learning. Brain Sci. 2022, 12, 596. https://doi.org/10.3390/brainsci12050596
Nazhestkin I, Svarnik O. Different Approximation Methods for Calculation of Integrated Information Coefficient in the Brain during Instrumental Learning. Brain Sciences. 2022; 12(5):596. https://doi.org/10.3390/brainsci12050596
Chicago/Turabian StyleNazhestkin, Ivan, and Olga Svarnik. 2022. "Different Approximation Methods for Calculation of Integrated Information Coefficient in the Brain during Instrumental Learning" Brain Sciences 12, no. 5: 596. https://doi.org/10.3390/brainsci12050596