1. Introduction
How exactly speech perception works is still a mystery. It is widely assumed that multiple acoustic cues are needed for the perception of segments (consonants and vowels) and suprasegmentals (tone, intonation, etc.), and a major goal of research is to find out which cues are relevant for the recognition of these units [
1,
2]. For example, formants may provide primary cues for signaling different vowel categories, VOT is useful for distinguishing between voiced and voiceless plosives [
3], pitch contour and pitch height are useful for differentiating lexical tones [
4,
5], etc. During speech perception, those cues are detected and then combined to identify specific contrastive phonetic units such as consonants, vowels, or tones [
6]. This assumed mechanism, therefore, consists of two phases: feature detection, and phonetic recognition. No research so far, however, has demonstrated how exactly such a two-phase process can achieve the recognition of phonetic units in the perception of continuous speech. At the same time, another possibility about speech perception has rarely been theoretically contemplated, namely, a mechanism in which raw acoustic signals are processed to directly recognize phonetic units, without the extraction of intermediate featural representations. It may be difficult to test this hypothesis with existing accounts, however, because conventional behavioral and neural studies can only allow us to explore what acoustic cues are important for perception, but not how the whole perception process may work. What is needed is a way to explore the operation of speech perception by simulating it as a step-by-step procedural process, starting from acoustic signals as input, and ending with identified phonetic categories as output. This can be done through computational modeling that implements each proposed perception model as a phonetic recognition system. The present study is an attempt to apply this paradigm by making a computational comparison of direct phonetic perception to various two-phase perception models. In order to avoid the pitfall, often seen in computational modeling, of allowing multiple hidden layers that do not correspond to specific aspects of theoretical models of perception, here we try to construct computational models with transparent components that correspond explicitly to specific aspects of the related theoretical models.
1.1. Feature-to-Percept Theories
1.1.1. Distinctive Feature Theories
A major source of the feature-based view of speech perception is the classic theory of distinctive features [
7]. The theory was proposed as an attempt to economize the representation of speech sounds beyond segmental phonemes [
8,
9]. In a pursuit to identify the most rudimentary phonetic entities, an even smaller set of featural contrasts than phonemes, aka distinctive features, was proposed [
10]. Jakobson et al. [
7] proposed a system with only 12 pairs of features, each making a binary contrast based predominantly on acoustic properties. An alternative system was proposed by Chomsky and Halle [
11] with a much larger set of binary features (around 40) that are predominantly based on articulatory properties. Some phonological theories have even claimed that distinctive features are the true minimal constituents of language [
12,
13]. Most relevant for the current discussion, it is often assumed that the detection of the discrete features [
14,
15], be it binary or multivalued [
1], is the key to speech perception [
16,
17]. This is seen in both the auditory theories and motor theories of speech perception, two competing lines of theories that have been dominating this area of research, as will be outlined next.
1.1.2. Auditory Theories
Auditory theories as a group assume that perceptual cues of phonetic contrasts are directly present in the acoustic signals of speech [
17,
18,
19,
20]. These theories assume that it is the distinctive acoustic properties that listeners are primarily sensitive to, and that speech perception is achieved by either capturing these properties [
21] or extracting distinctive features [
22]. These theories are often presented in opposition to motor theory, to be discussed next, in that they assume no intermediate gestural representations between acoustic cues and perceived categories. They recognize a role of distinctive features, and assume a need for extracting them in perception [
17]. This need is elaborated in the Quantal Theory [
23,
24,
25,
26] based on the observation that auditory properties are not linearly related to continuous changes of articulation, but show some stable plateau-like regions in the spectrum. The plateaus are argued to form the basis of universal distinctive features. In addition, it is further proposed that there are enhancing features to augment the distinctive features [
15,
18,
26,
27,
28].
1.1.3. Motor Theories
The motor theory [
29,
30,
31], in contrast, assumes that the peripheral auditory processing phase of speech perception is followed by an articulatory recognition phase, in which articulatory gestures such as tongue backing, lip rounding, and jaw raising are identified. The motor theory is mainly motivated by the observation of the lack of one-to-one relations between acoustic patterns and speech sounds [
32,
33]. It is argued that invariance must lie in the articulatory gestures that generate the highly variable acoustic patterns. Therefore, gestures would serve as intermediate features that can match the auditory signals on the one hand, and the perceived phonemic or lexical units on the other hand.
Counter evidence to the motor theory comes from findings that speech perception can be achieved without speech motor ability in infants [
34], non-human animals [
35], and people suffering from aphasia [
36,
37,
38]. However, there is also increasing evidence that perceiving speech involves neural activity of the motor system [
39,
40], and the motor regions are recruited during listening [
41,
42,
43,
44]. A range of brain studies using methods like TMS also showed evidence for the motor theory [
45,
46,
47].
However, perceptual involvement of the motor system is not direct evidence for gesture recognition as the necessary prerequisite to phonetic recognition. For one thing, it is not clear whether motor activations occur before or after the recognition of the perceived categories. For another thing, there is increasing evidence that motor area activation mostly occurs only under adverse auditory conditions [
45,
48,
49], which means that motor involvement may not be obligatory for normal perception tasks.
An issue that has rarely been pointed out by critics of motor theory is that gestures are actually not likely to be as invariant as the theory assumes. While a consonantal gesture could be in most cases moving toward a constricted vocal tract configuration, a vowel gesture could be either a closing or opening movement, depending on the openness of the preceding segment. In this respect, a greater degree of articulatory invariance is more likely found in the underlying phonetic targets in terms of vocal tract and/or laryngeal configuration rather than the target approximation movements [
50,
51,
52].
1.2. Feature-to-Percept vs. Direct Phonetic Perception
As mentioned above, what originally motivated the motor theory, which has also permeated much of the debate between the motor and auditory theories is the apparent and pervasive variability in the speech signal. This is an issue fundamental for any theory of speech perception, namely, how is it possible that speech perception can successfully recover the phonetic categories intended by the speaker despite the variability? Note that, however, the question can be asked in a different way. That is, despite the variability, is there still enough within-category consistency in the acoustic signal that makes speech perception effective? If the answer is yes, the next question would be, what is the best way to capture the within-category consistency?
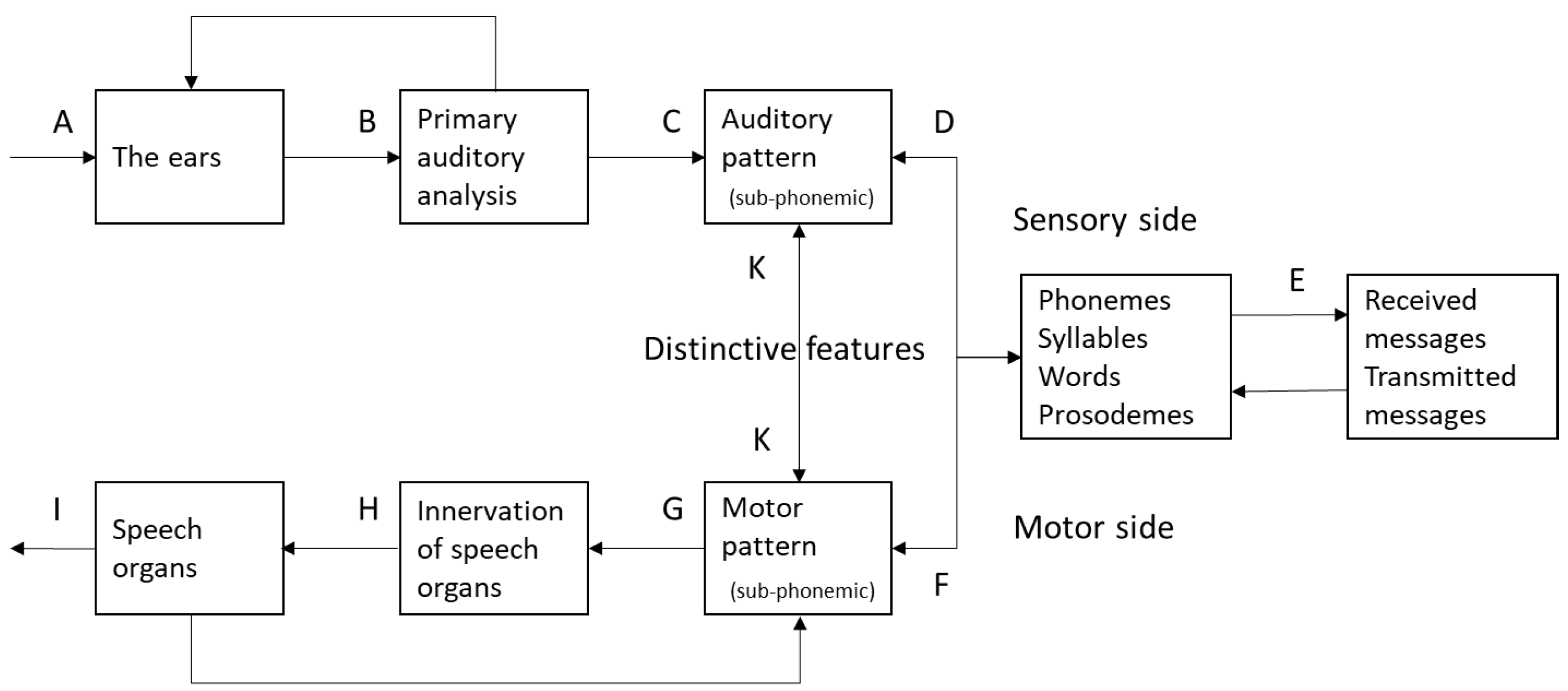
The answer by all the theories reviewed above would be that a feature-based two-phase process is the best way to capture the within-category consistency. They differ from each other only in terms of whether the extracted features are primarily auditory or articulatory, or a mixture of both as in the case of distinctive features. This commonality is nicely illustrated in
Figure 1 from Fant [
53]. Here, after being received by the ear, and having gone through the primary auditory analysis, the acoustic signals of speech are first turned into featural patterns that are either auditory (intervals CD) or motor (interval GF). Either way, they are both sub-phonemic and featural, and need to be further processed to identify the categorical phonemes, syllables, words, etc.
A key to this two-phase concept is the assumption that for each specific phonetic element only certain aspects of the speech signal are the most relevant, and what needs to be theoretically determined is whether the critical aspects are auditory or motor in nature. This implies that the non-critical properties (i.e., those beyond even the enhancing features) are redundant and are therefore not taken into account in perception. Even though there is also recognition that certain minor cues can be useful [
54], it is generally felt that the minor cues are not nearly as important. There is little discussion, however, as to how the perception system can learn what cues to focus on and what cues to ignore.
An alternative possibility, as explored in the present study, is that raw acoustic signals of connected speech, after an initial segmentation into syllable sized chunks, can be processed as a whole to directly recognize the relevant phonetic elements, such as consonants, vowels, and tones. This process does not consist of a phase in which auditory or articulatory features are explicitly identified and then used as input to the recognition of the units at the phonemic level. There are a number of reasons why such a direct perception of phonetic categories may be effective. First, given that speakers differ extensively in terms of static articulatory configurations such as vocal tract length, articulator size, and length and thickness of the vocal folds, greater commonality could be in the dynamics of the articulatory trajectories, which is constrained by physical laws. The dynamic nature of continuous speech [
55,
56,
57,
58] means that it is intrinsically difficult to find the optimal time points at which discrete features can be extracted from the continuous articulatory or acoustic trajectories. Second, there is evidence that continuous articulatory (and the resulting acoustic) movements are divided into syllable-sized unidirectional target approximation movements [
59,
60,
61] or gestures [
62]. This suggests that processing syllable-sized acoustic signals could be an effective perceptual strategy to capture the full details of all the relevant information about contrastive phonetic units such as consonants, vowels, and tones. Finally, a seemingly trivial but in fact critical reason is that, if detailed acoustic signals are all available to the auditory system, should perception throw away any part of the signal that is potentially helpful? The answer to this question would be no, according to the data processing theorem, also known as data processing inequality [
63]. This is an information theoretic concept that states that the information content of a signal cannot be increased via data processing:
where X, Y and Z form a Markov Chain (a stochastic process consisting of a sequence of events, where the probability of each event depends on the state of the previous event). X is the input, Z is the processed output, and Y is the only path to convert X to Z. What this says is that whenever data is processed, some information is lost. In the best-case scenario, the equality could still largely hold when some information is lost but no processing can increase the amount of original information. In general, the more data processing, the greater the information loss. An extraction of intermediate features before phonetic recognition, therefore, would necessarily involve more processing than direct recognition of phonetic categories from raw acoustic signals.
There have already been some theories that favor relative direct or holistic speech perception. Direct realism [
64], for example, argues that speech perception involves direct recognition of articulatory gestures, without the intermediatory of explicit representation of auditory features. However, because gestures are also sub-phonemic (
Figure 1), an extra step is still needed to convert them to syllables and words. The exemplar theories [
65,
66,
67] also postulate that in both production and perception, information about particular instances (episodic information) as a whole is stored. Categorization of an input is accomplished by comparison with all remembered instances of each category. It is suggested that people use already-encountered memories to determine categorization, rather than creating an additional abstract summary of representations. In exemplar models of phonology, phonological structures, including syllables, segments and even sub-segmental features emerge from the phonetic properties of words or larger units [
67,
68,
69], which implies that units larger than phonemes are processed as a whole. The exemplar theories, however, have not been highly specific on how exactly such recognition is achieved.
In fact, there is a general lack of step-by-step procedural account of any of the theoretical frameworks on speech perception that starts from the processing of continuous acoustic signals. Auditory theories have presented no demonstration of how exactly continuous acoustic signals are converted into auditory cues in the first phase of perception, and how these representations are translated into consonants, vowels, and tones. Motor theory has suggested that gestures can be detected from acoustic signals through analysis by synthesis [
31], but this has not yet been tested in perception studies, and has remained only as a theoretical conjecture. What is needed is to go beyond purely theoretical discussion of what is logically plausible, and start to test computationally what may actually work. For this purpose, it is worth noting that computational speech recognition has been going on for decades, in research and development in speech technology. As a matter of fact, automatic speech recognition (ASR) has been one of the most successful areas in speech technologies [
70,
71]. Zhang et al. [
72], for example, reported word-error-rates (WERs) as low as 1.4%/2.6%.
The state of the art in speech recognition, however, does not use intermediate feature extraction as a core technology. Instead, units like diphones or triphones are directly recognized from continuous acoustic signals [
73,
74,
75,
76,
77]. There have been some attempts to make use of features in automatic speech recognition. For example, the landmark-based approach tries to extract distinctive features from around acoustic landmarks such as the onset or offset of consonant closure, which can then be used to make choices between candidate segments to be recognized [
14,
78,
79,
80]. In most cases, however, systems using landmarks or distinctive features are knowledge-based, and the detected features are used as one kind of feature added on top of other linguistic features and acoustic features to facilitate the recognition of phonemes [
81,
82]. In this kind of process, there is no test of the effectiveness of distinctive features relative to other features. Some other automatic speech recognition systems use acoustic properties around the landmarks, but without converting them to any featural representations [
83,
84,
85,
86]. What is more, those recognition systems still use phoneme as the basic unit, which implies that phoneme is the basic functional speech unit, and units under phonemes do not have to be categorical. There have also been systems that make some use of articulatory features. However, there is no system that we know of that performs phonetic recognition entirely based on articulatory gestures extracted from acoustic signals.
Feature-to-percept, therefore, is questionable as a general strategy of speech perception, especially given the possibility of direct phonetic perception as an alternative. There has not yet been any direct comparisons of the two strategies, however. In light of the data processing theorem in Equation (1), both strategies would involve data processing that may lead to information loss. In addition, a strategy that can generate better perceptual accuracy could be computationally too costly. Therefore, in this study, a set of modelling experiments are conducted to compare the two perceptual strategies, measured in terms of recognition accuracy and computational cost. As the very first such effort, the object of recognition is Mandarin tones, because they involve fewer acoustic dimensions than consonants and vowels, as explained next.
1.3. Tone Recognition: A Test Case
In languages like Mandarin, Yoruba, and Thai, words are distinguished from each other not only by consonants and vowels, but also by pitch patterns known as tones. Tone in these languages therefore serves a contrastive function like consonants and vowels. Syllables with the same CV structure can represent different words when the pitch profiles in the syllable vary. Although tonal contrasts are sometimes also accompanied by differences in consonants, vowels and voice quality, pitch patterns provide both sufficient and dominant cues for the identification of tones [
59,
87].
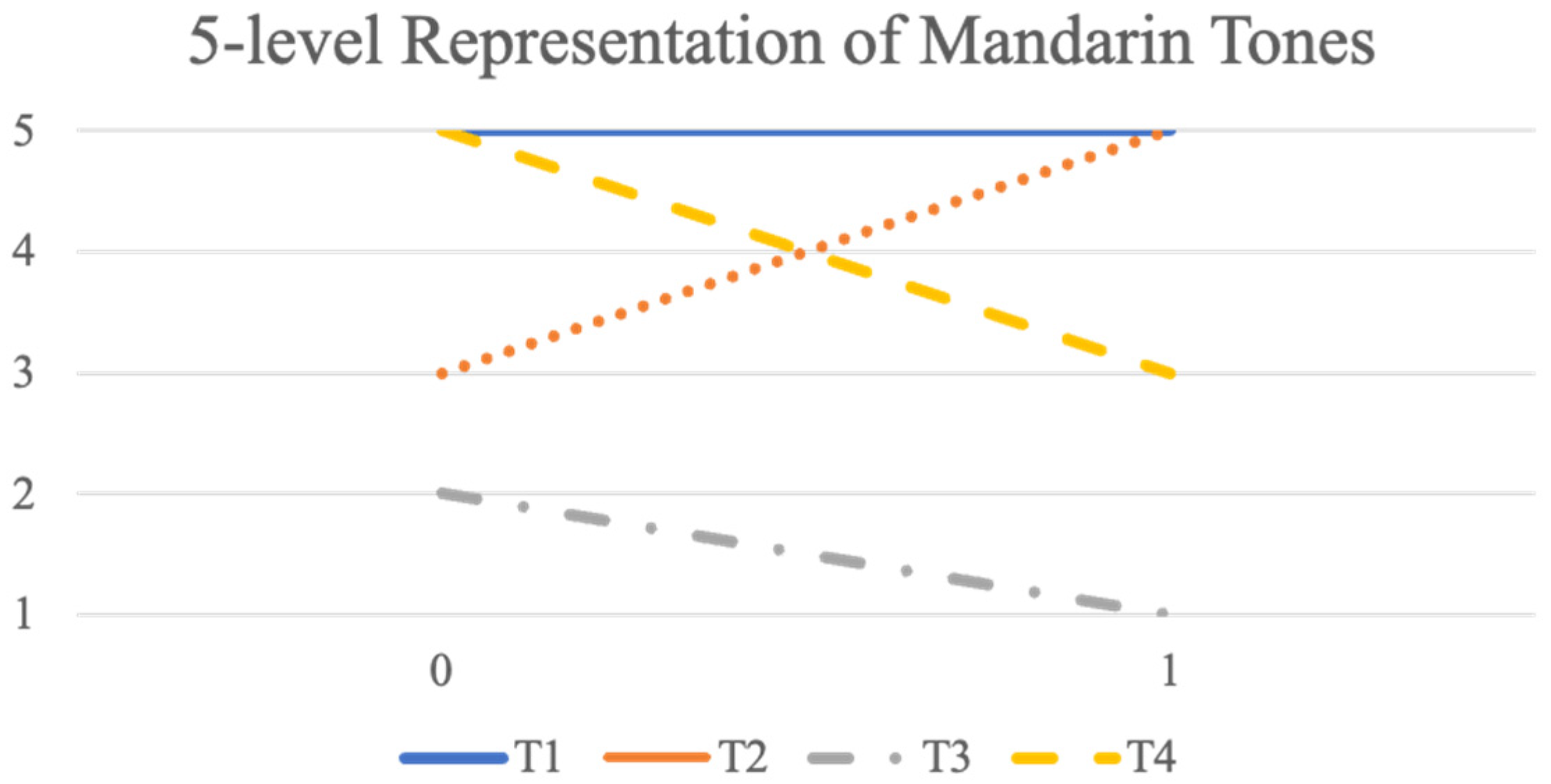
How to define tonal contrasts is a long-standing issue for tone language studies. In general, efforts have predominantly focused on establishing the best featural representation of tones, starting from Wang’s [
88] binary tone features in the style of distinctive features of Jakobson et al. [
7]. Later development has moved away from simple binary features. For East Asian languages, a broadly accepted practice is to use a five-level system [
89] which assumes that five discrete levels are sufficient to distinguish all the tones of many languages. Also different from the classical feature theory, the five-level system represents pitch changes over time by denoting each tone with two temporal points. The four tones of Mandarin, for example, can be represented as 55—tone 1, 35—Tone 2, 214—Tone 3, and 51—Tone 4, where a greater number indicates a higher pitch. Two points per tone is also widely used for African tone languages [
90,
91,
92], although for those languages usually only up to three pitch levels, High, Mid, Low, are used. Morén and Zsiga [
93] and Zsiga and Nitisaroj [
94] even claimed that for Thai, only one target point per tone is needed for connected speech. There has also been a long-standing debate over whether pitch level alone is sufficient to represent all tones, or slope and contour specifications are also needed as part of the representation [
4,
5]. There are also alternative schemes that try to represent tone contours, such as the T value method, LZ value method [
95,
96,
97], etc., but they also focus on abstracting the pitch contours into several discrete levels.
Under the feature-to-percept assumption, the two-point + five-level tone representation would mean that, to perceive a tone, listeners need to first determine if the pitch level is any of the five levels at each of the two temporal locations, so as to derive at a representation in the form of, e.g., 55, 35, 21 or 51. Those representations would then lead to the recognition of the tones. In such a recognition process, the key is to first detect discrete pitch levels at specific temporal locations before tone recognition. A conceivable difficulty with such tone feature detection is the well-known extensive amount of contextual variability. For example, due to inertia, much of the pitch contours of a tone varies heavily with the preceding tone, and it is only near the end of the syllable that the underlying tonal targets are best approached [
98,
99]. This would make tone level detection hard, at least for the first of the two temporal locations.
An alternative to the feature-to-tone scheme, based on the direct phonetic perception hypothesis, is to process continuous
f0 contour of each tone-carrying syllable as a whole without derivation of intermediate featural representations. The plausibility of holistic tone processing can be seen in the success of tone recognition in speech technology. The state-of-the-art automatic tone recognition can be as accurate as 94.5% on continuous speech [
100], with no extraction of intermediate tonal features. In fact, the current trend is to process as many sources of raw acoustics as possible, including many non-
f0 dimensions in complex models [
100,
101]. This suggests that maximization of signal processing rather than isolation of distinctive cues may be the key to tone recognition.
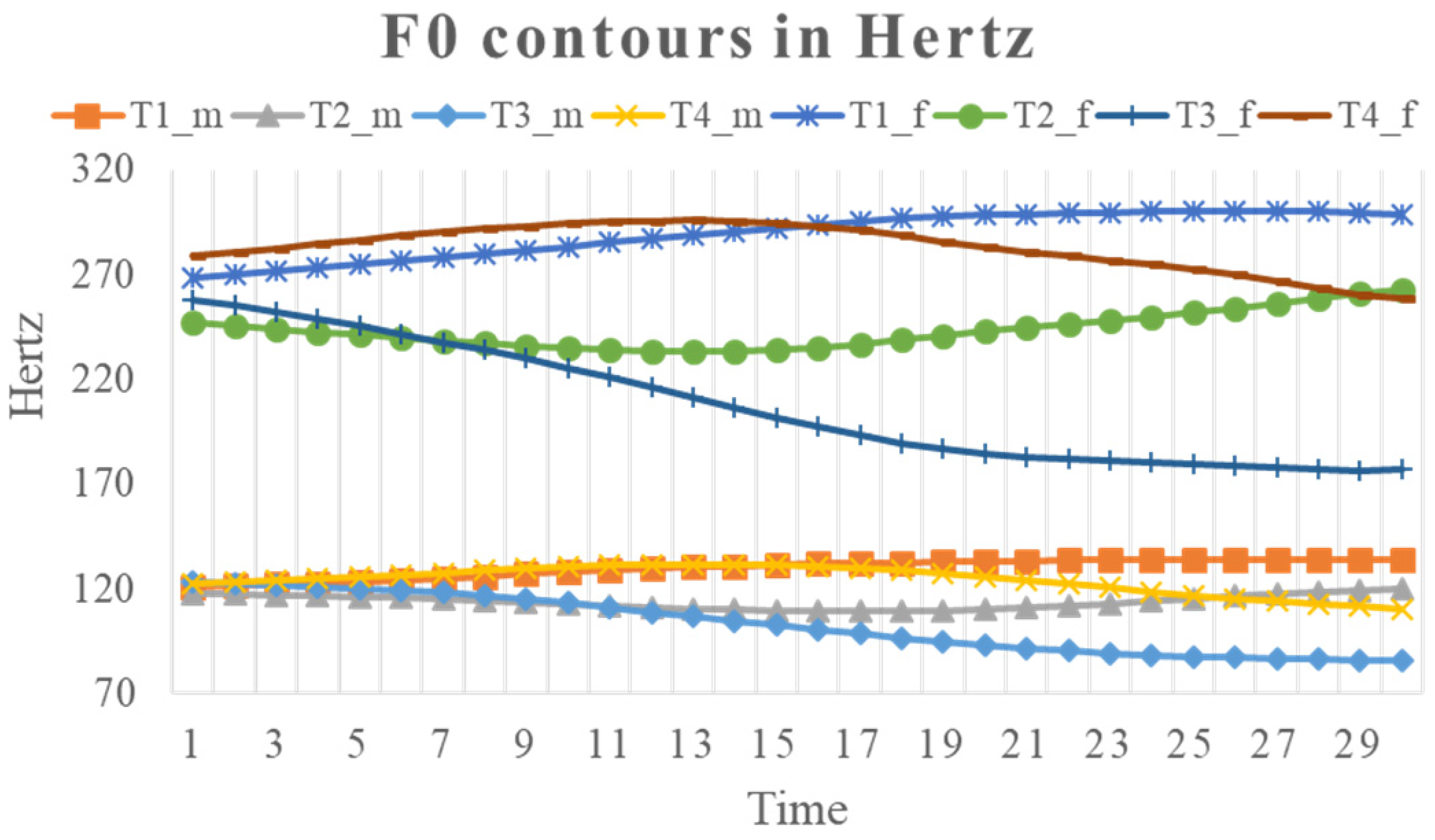
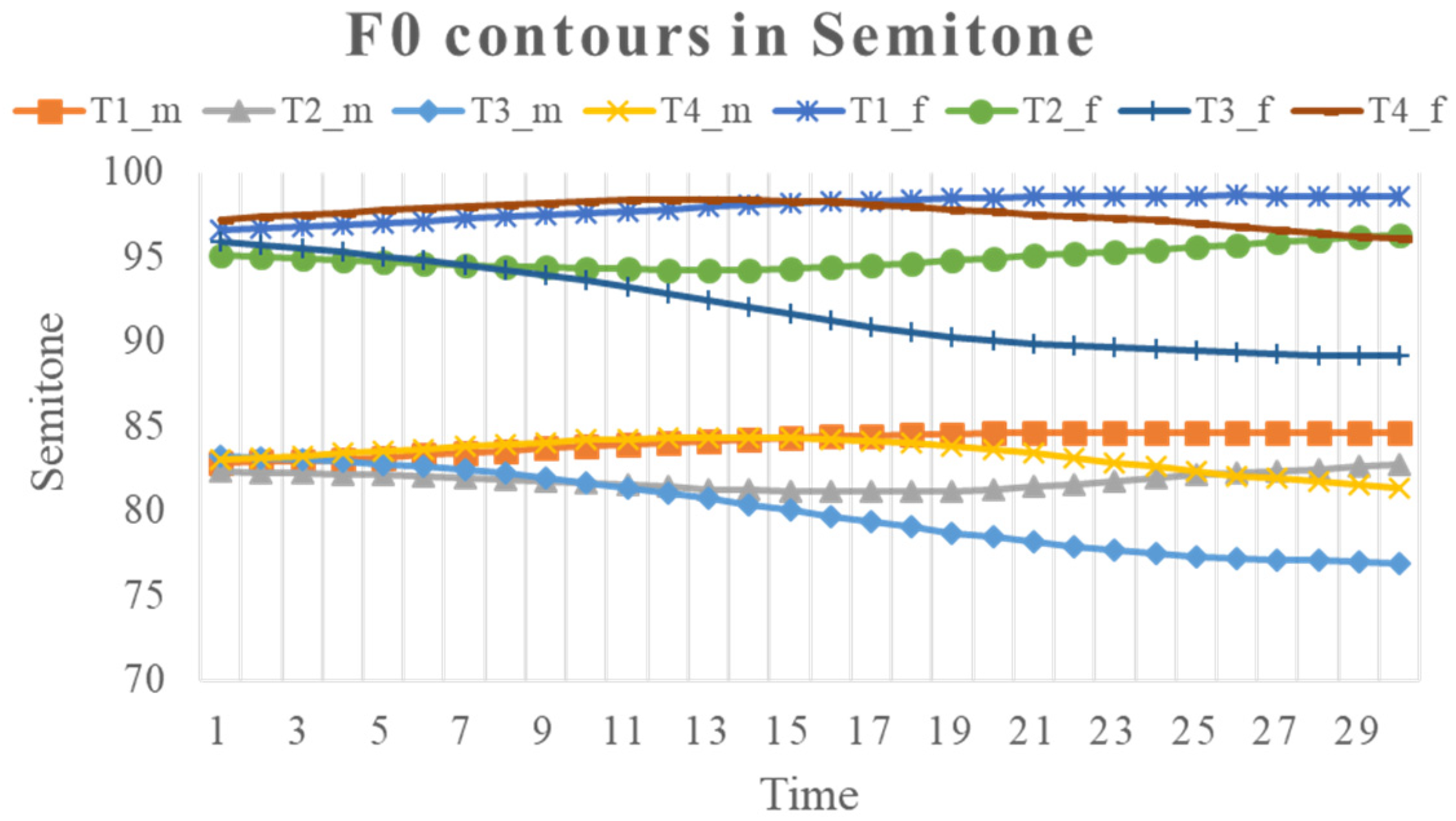
Tone recognition would therefore serve as a test case for comparing direct and two-phase perception. But the speech-technology-oriented approach of using as many acoustic properties as possible makes it hard to isolate the key differences between the two approaches. Given that f0 alone is sufficient to convey most tonal contrasts in perception as mentioned above, in this study we will use a computational tone recognition task that processes raw f0 contours in connected Mandarin speech, with the aim to test if the perception of phonetic categories is more likely a two-phase feature-to-percept process or a single-phase direct acoustic decoding process. We will apply two machine learning algorithms to process Mandarin tones from syllable-sized f0 contours extracted from a connected speech corpus in ways that parallel different tone perception hypotheses, including direct perception, pitch level extraction, pitch profile features, and underlying articulatory targets.
4. Discussion
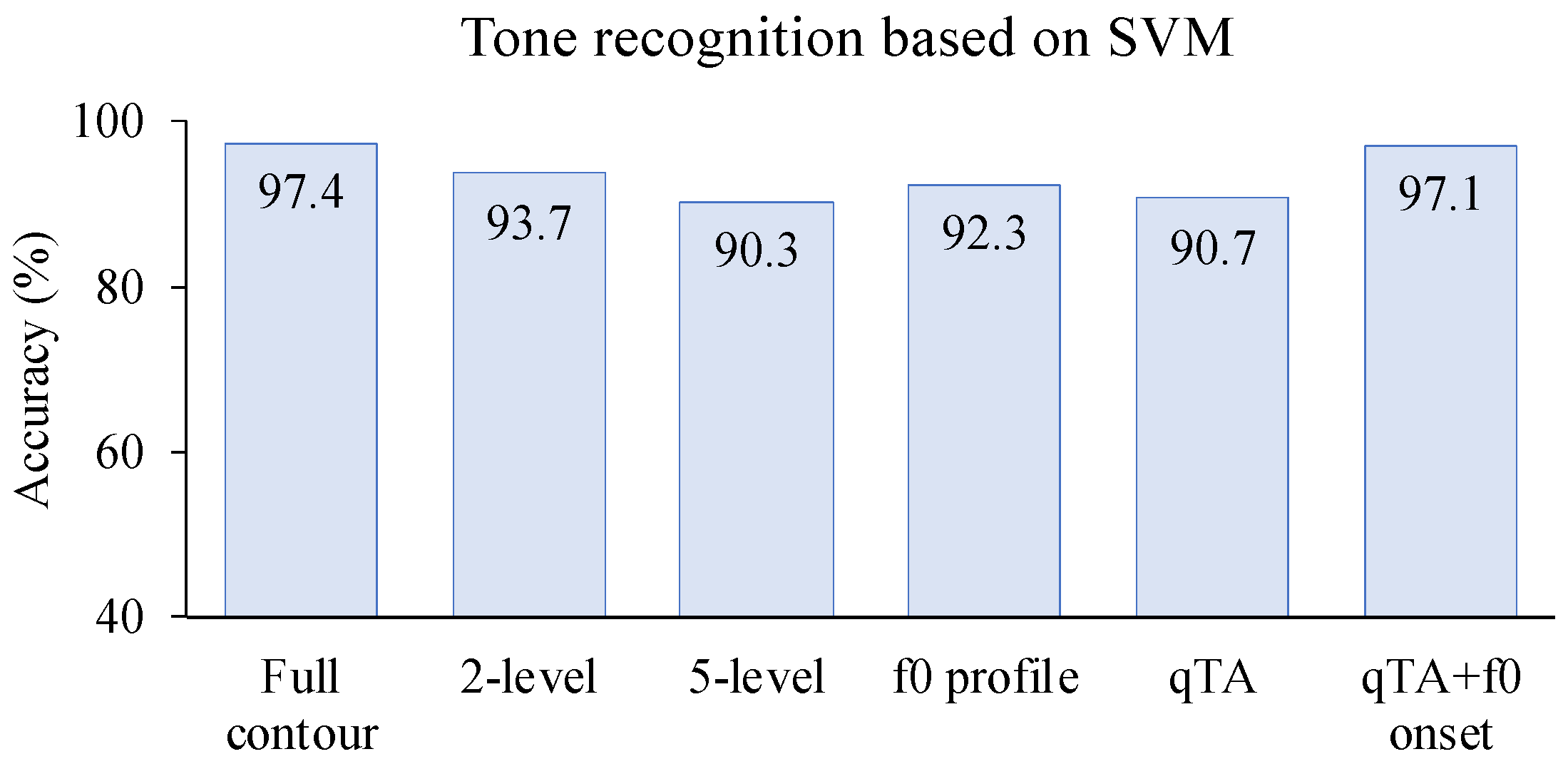
In the five experiments, we tested whether direct phonetic perception or feature-to-percept is a more likely mechanism of speech perception. All the tests were done by applying the SVM and/or SOM model with either full
f0 contours or various extracted
f0 features as the training and testing data. Except for qTA (due to model-internal setting), all the models were tested with
f0 in both Hz and semitone scales. The performance of the models was assessed in terms of tone recognition rate. In all the experiments the recognition was consistently better for the SVM model than for the SOM model, and better with the semitone scale than the Hz scale. To make a fair comparison of the all the models, a summary of the best performances in all five experiments based on SVM in semitones is shown
Figure 5. As can be seen, the highest recognition rate, 97.4%, was achieved in the full
f0 contour condition in Experiment 1. With pitch level features extracted in Experiments 2–3, recognition rates of 93.7% and 90.3% were achieved for the two-level and five-level conditions, respectively. These are fairly good, but are well below the top recognition rate in Experiment 1. Experiment 4 tested two mathematical (parabola and broken-line) representations of
f0 profiles, which, unlike the discrete pitch level features in Experiments 2–3, have continuous values. The highest recognition rate of 92.3% was achieved for the combination of slope and curve. This is very close to the best recognition rate of 93.7% with the two-level condition in Experiment 2. Another continuous parametric representation tested in Experiment 5, namely, qTA parameters based on [
59], achieved a very high recognition rate of 97.1% when initial
f0 was included as a fourth parameter, which is almost as high as the benchmark of 97.4% in Experiment 1. Without the initial
f0, however, the recognition rate was only 90.7%. It is worth noting, however, that the initial
f0 is actually included in the full
f0 contour in Experiment 1, as it is just the first
f0 point in an
f0 contour.
The fairly high tone recognition rates from the best performances in all the five experiments are rather remarkable, given that the
f0 contours used were extracted from fluent speech [
51] in multiple tonal contexts and two different syllable positions, yet no contextual or positional information was provided during either training or testing, contrary to the common practice of including tonal context as an input feature in speech technology [
101,
115,
116]. This means that, despite the extensive variability, tones produced in contexts by multiple speakers of both genders are still sufficiently distinct to allow a pattern recognition model (SVM) to accurately identify the tonal categories based on syllable-sized
f0 contours alone. In other words, once implemented as trainable systems, most theory-motivated schemes may be able to perform phonetic recognition to some extent, though with varying levels of success. Thus, the acoustic variability that has prompted much of the early theoretical debates [
30,
117] does not seem to pose an impenetrable barrier. Instead, there seems to be plenty of consistency underneath the apparent variability for any recognition scheme to capture.
On the other hand, it is still the case that the tone recognition rates achieved by most of the feature extraction schemes in Experiments 2–5 were lower than that of the full
f0 contour baseline in Experiment 1. Only the qTA + initial
f0 scheme nearly matched the full
f0 contour performance. Therefore, for both the qTA + initial
f0 condition and the other feature extraction schemes, a further question is whether the extra processing required by the extraction of the intermediate features is cost-effective when compared to direct processing of full
f0 contours. One way to compare the cost-effectiveness of different tone recognition schemes is to calculate their time complexity [
118] in addition to their recognition rates. Time complexity is the amount of time needed to run an algorithm on a computer, as a function of the size of the input. It measures the time taken to execute each statement of the code in an algorithm and gives information about the variation in execution time when the number of operations changes in an algorithm. It is difficult to compute this function exactly, so it is commonly defined in terms of an asymptotic behaviour of the complexity. Time complexity is expressed with the big O notation,
, where
is the size of the input data and
is the order of the relation between
and the number of operations performed. Taking the SVM model as an example, the time complexity of the SVM model at testing phase is a function that involves a loop within a loop, which is
, where
is the number of dimensions of input data and
is the number of categories. When two models, A and B, are compared, if A is better than or equal to B in performance, and has a lower time complexity, A can be said to be a better model than B. If A and B differ clearly in performance, but has a lower time complexity, its performance needs to be balanced against time complexity when deciding which model is better.
Table 8 shows the time complexity of all the tone recognition schemes tested in Experiments 1–5.
As can be seen, most feature extraction schemes have greater time complexity than the baseline full
f0 contour scheme. The only feature extraction scheme with lower time complexity is the two-level condition. However, its tone recognition accuracy is 3.7% lower than the full
f0 contour condition, as shown in
Figure 5. Therefore, its reduced time complexity was not beneficial. In addition, as found in Chen and Xu [
119], the time complexity of full
f0 contour scheme does not need to be as high as in Experiment 1, because the temporal resolution of
f0 contours could be greatly reduced without lowering tone recognition accuracy. When the number of
f0 points were reduced to as few as 3, the tone recognition rate was still 95.7%, only a 1.7% drop from the 30-point condition. Therefore, compared to 3 points per contour, the two-level feature extraction would even lose its advantage in time complexity. Overall, therefore, there is no advantage in cost-effectiveness in any of the features extraction schemes over the full
f0 contour scheme.
Worth particular mentioning is the qTA scheme tested in Experiment 5, as it served as a test case for the motor theory of speech perception [
31]. The theory assumes that speech perception is a process of recovering articulatory gestures, and the recovery is done by listeners using their own articulatory system to perform analysis-by-synthesis. However, analysis-by-synthesis is a time-consuming process of testing numerous candidate model parameters until an optimal fit is found. As shown in
Table 8, the qTA scheme has the greatest time complexity of all the feature extraction schemes. Although its tone recognition accuracy was nearly as high as that of full
f0 contours benchmark when initial
f0 was included as the fourth parameter, one may have to wonder why speech perception would develop such an effortful strategy when direct processing of raw
f0 contours can already achieve top performance at a much lower computational cost.
An implication of the experiments in the present study is that listeners’ sensitivity to certain feature-like properties, such as
f0 slope [
5], height [
4] or alignment of turning point [
120,
121] does not necessarily mean that those properties are separately extracted during perception. Rather, the sensitivity patterns are what can be observed when various acoustic dimensions are independently manipulated under laboratory conditions. They do not necessarily tell us how speech perception operates. The step-by-step modelling simulations conducted in the current study demonstrate that there may be no need to focus on any specific features. Instead, the process of recognition training allows the perception system to learn how to make use of all the relevant phonetic properties, both major and minor, to achieve optimal phonetic recognition. The dynamic learning operation may in fact reflect how phonetic categories are developed in the first place. That is, speech production and perception probably form a reciprocal feedback loop that guarantees that articulation generates sufficiently distinct cues that perception can make use of during decoding. As a result, those articulatory gestures that can produce the greatest number of effective phonetic cues would tend to be retained in a language. At the same time, perceptual strategies would tend to be those that can make the fullest, and the most economical, use of all the available acoustic cues from detailed acoustic signals.
Finally, a few caveats and clarifications are in order. First, the tone recognition rates obtained in the present study may not directly reflect perception efficacy in real life. On the one hand, they could be too high because the
f0 contours tested here did not contain some of the known adverse effects like consonantal perturbation of
f0 [
122,
123], intonational confounds [
99,
124], etc. On the other hand, they could also be too low because not all tonal information is carried by
f0. Listeners are also known to make use of other cues such as duration, intensity, voice quality, etc. [
100,
101]. Second, there is a need to make a distinction between data transformation and feature extraction. Conversion of
f0 from Hz to semitones and from waveform to MFCC are examples of data transformation. Both have been shown to be beneficial [
125,
126], and are likely equivalent to certain signal processing performed by the human auditory system. They are therefore different from the feature extraction schemes tested in the present study. In addition, there is another kind of data processing that has been highly recommended [
106,
127], namely, speaker/data normalization schemes in the frequency dimension such as Z-score transformation (rather than in the temporal dimension). The justification is based on the need to handle variability within and especially across speakers. The difficulty from an operational perspective is that Z-score transformation is based on the total pitch range of multiple speakers in previously processed data. However, Z-score would be hard to compute when processing data from a new speaker, which happens frequently in real life. Furthermore, the present results have shown that, once an operational model is developed, explicit speaker normalization is not really needed, as the training process is already one of learning to handle variability, and the results showed that all models were capable of resolving this problem to various extends. Finally, the present findings do not suggest that a data representation of up to 30 points per syllable is necessary for tone recognition from continuous speech. As mentioned earlier, in a separate study [
119] we found that just three
f0 points (taken from the beginning, middle and end of a syllable) are enough for a model equivalent to the full contour model in Experiment 1 to achieve a tone recognition rate close to that of 30
f0 points, so long as the data points are in the original
f0 values rather than discretized pitch height bands. The study also found that discretization of continuous acoustic signal into categorical values (equivalent to reduction of frequency resolution), which is prototypical of featural representations, is the most likely to adversely affect tone recognition. In other words, a temporal resolution of up to 30 samples per syllable as tested in the present study is not always needed, and may in fact be excessive when time complexity is taken into consideration, whereas high precision of data representation, which is exactly the opposite of featural representation, may be the most important guarantee of effective speech perception.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}