

Applying Deep Learning on a Few EEG Electrodes during Resting State Reveals Depressive States: A Data Driven Study

Abstract
:1. Introduction
- Higuchi’s fractal dimension (Higuchi) is an approximate value for the box-counting dimension used on fractal analysis to graph a real-valued time series that has been used for more than 20 years in neurophysiological domains [14].
- Spectral entropy (SpectEnt) describes the complexity of a system based on applying the standard formula for entropy to the power spectral density of EEG data. It quantifies the irregularity of EEG data [15].
- Singular value decomposition entropy (SVDEnt) characterizes the information content or regularity of a signal depending on the number of vectors attributed to the process [16].
- Sample entropy (SampEnt) is a modification of approximate entropy, used for assessing the complexity of physiological time series signals [17].
- Detrended fluctuation analysis (DFA) is a stochastic process, chaos theory, and time-series analysis. DFA is a method for determining the statistical self-affinity of a signal. It is useful for analyzing time series that appear to be long memory processes [18].
- Permutation entropy (PermEnt) gives a quantification measure of the complexity of a dynamic system by capturing the order relations between values of a time series and extracting a probability distribution of the ordinal patterns [19].
- Logistic regression (LR): a baseline dichotomic classifier from machine learning (ML).
- Support vector machine (SVM): a robust ML algorithm that maps training examples to points in space (vectors), searching to maximize the distance between categories.
- Multi-layer perceptron (MLP): one of the simplest deep learning (DL) models used in supervised learning, consisting of fully connected layers.
- Convolutional neural network (CNN): another DL algorithm mainly used in image data analysis due to its biological visual architecture similarity.
- Long short-term memory (LSTM): a DL algorithm mainly used in sequential data analysis like natural language processing or time-series analysis.
- CNN + GRU (CNNGRU): a DL algorithm suggested by Liu et al. [11] that combines a CNN as a feature extractor plus a gated recurrent unit (GRU), an improvement of LSTM.
2. Materials and Methods
2.1. Participants
2.2. Procedure
2.2.1. First Step: Selecting the Time-Window Span and Key Electrodes
EEG-Resting State
Preprocesing
Time-Window Span Analysis
Key Electrodes Identification
2.2.2. Second Step: Exploring Features and Classifiers
Features Extraction and Selection
- COMB0: PermEnt
- COMB1: PermEnt + SampEnt
- COMB2: PermEnt + SampEnt + SVDEnt
- COMB3: PermEnt + SampEnt + SVDEnt + DFA
- COMB4: PermEnt + SampEnt + SVDEnt + DFA + SpectEnt
- COMB5: PermEnt + SampEnt + SVDEnt + DFA + SpectEnt + Higuchi
Testing Different Classifiers
2.2.3. Third Step: Tuning, Training, and Validating with the Experimental Data
Tuning and Training the Selected Model
2.2.4. Fourth Step: Validating the Models with External Data
3. Results
3.1. First Step: Exploring the Time-Window Span and Key Electrodes
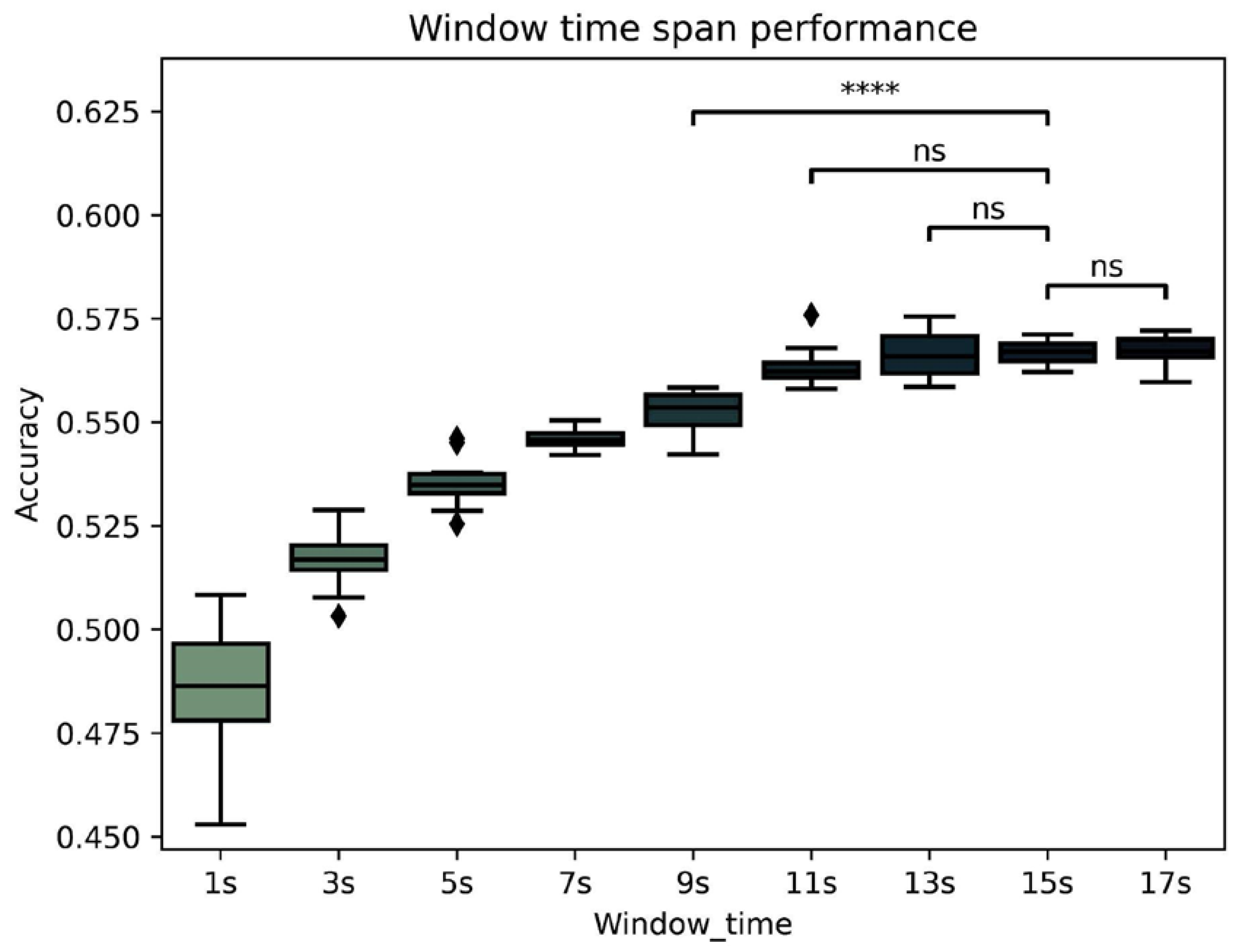
3.1.1. Time-Window Span Analysis
- 15 s vs. 17 s: t-test independent samples, t (49) = −0.206, p = 0.838
- 13 s vs. 15 s: t-test independent samples, t (49) = −0.211, p = 0.834
- 11 s vs. 15 s: t-test independent samples, t (49) = −1.695, p = 0.107
- 9 s vs. 15 s: t-test independent samples, t (49) = −7.152, p < 0.0001
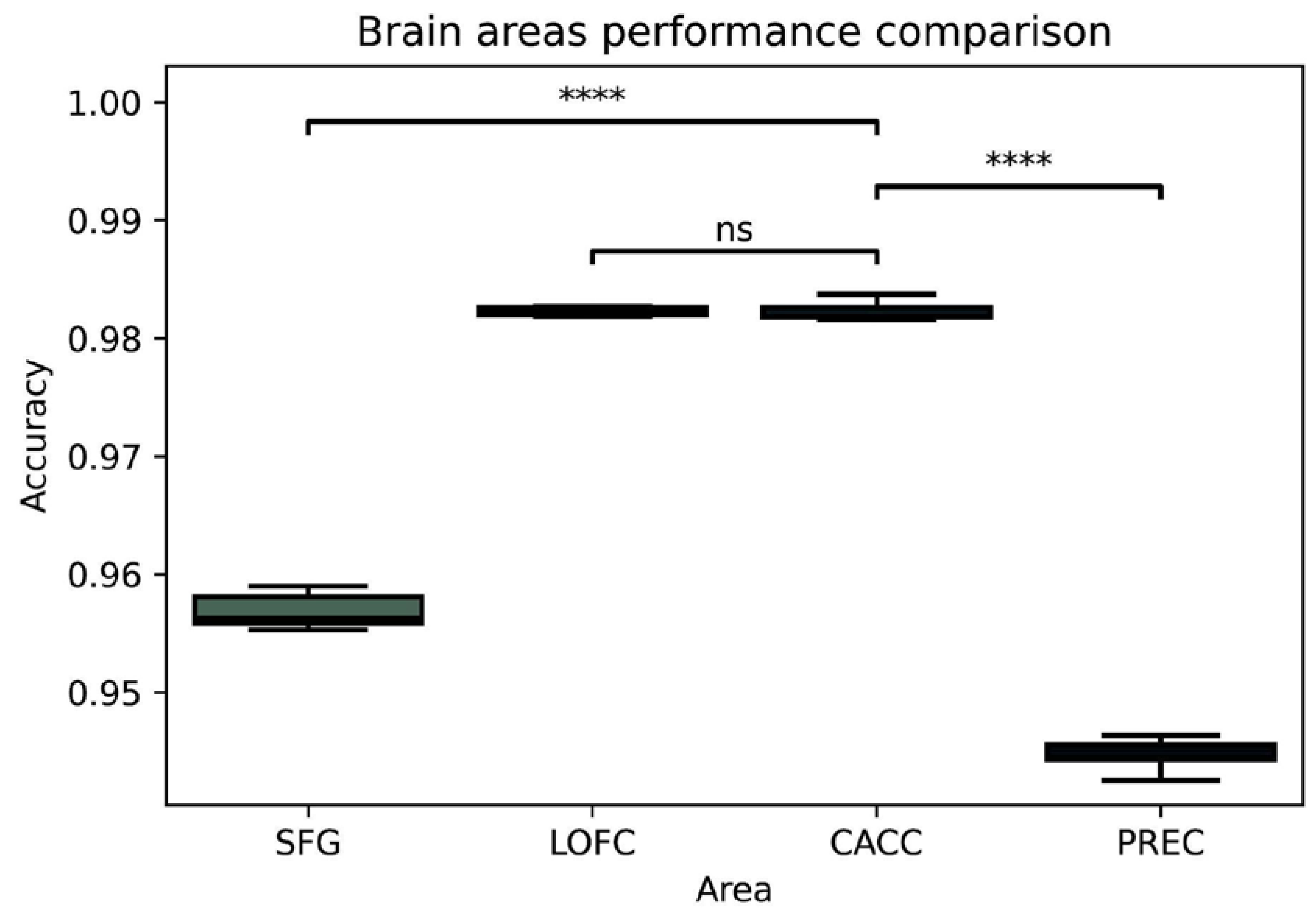
3.1.2. Identifying Key Electrodes
3.2. Second Step: Exploring Features and Classifiers
3.2.1. Features Extraction and Selection
- COMB0: Permutation entropy (PerEnt)
- COMB1: PerEnt + sampling entropy (SampEnt)
- COMB2: PerEnt + SampEnt + single-value decomposition entropy (SVDEnt)
- COMB3: PerEnt + SampEnt + SVDEnt + detrended fluctuation analysis (DFA)
- COMB4: PerEnt + SampEnt + SVDEnt + DFA + spectral entropy (SpectEnt)
- COMB5: PerEnt + SampEnt + SVDEnt + DFA + SpectEnt + Higuchi’s fractal dimension (Higuchi)
3.2.2. Testing and Comparing Different Classifiers
3.3. Third Step: Tuning, Training, and Validating with the Experimental Data
3.4. Fourth Step: Validating the Model with External Data
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders; American Psychiatric Association: Washington, DC, USA, 2013. [Google Scholar]
- World Health Organization. Mental Health. Available online: https://www.who.int/health-topics/mental-health (accessed on 26 October 2022).
- James, S.L.; Abate, D.; Abate, K.H.; Abay, S.M.; Abbafati, C.; Abbasi, N.; GBD 2017 Disease and Injury Incidence and Prevalence Collaborators. Global, Regional, and National Incidence, Prevalence, and Years Lived with Disability for 354 Diseases and Injuries for 195 Countries and Territories, 1990–2017: A Systematic Analysis for the Global Burden of Disease Study 2017. Lancet 2018. Available online: https://linkinghub.elsevier.com/retrieve/pii/S0140673618322797 (accessed on 16 March 2022).
- Merino, Y.; Adams, L.; Hall, W.J. Implicit Bias and Mental Health Professionals: Priorities and Directions for Research. Psychiatr. Serv. 2018, 69, 723–725. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Snowden, L.R. Bias in Mental Health Assessment and Intervention: Theory and Evidence. Am. J. Public Health 2003, 93, 239–243. [Google Scholar] [CrossRef] [PubMed]
- de Aguiar Neto, F.S.; Rosa, J.L.G. Depression biomarkers using non-invasive EEG: A review. Neurosci. Biobehav. Rev. 2019, 105, 83–93. [Google Scholar] [CrossRef] [PubMed]
- Craik, A.; He, Y.; Contreras-Vidal, J.L. Deep learning for electroencephalogram (EEG) classification tasks: A review. J. Neural Eng. 2019, 16, 031001. [Google Scholar] [CrossRef] [PubMed]
- Čukić, M.; López, V.; Pavón, J. Classification of Depression through Resting-State Electroencephalogram as a Novel Practice in Psychiatry: Review. J. Med. Internet Res. 2020, 22, e19548. [Google Scholar] [CrossRef]
- Abd-Alrazaq, A.A.; Alajlani, M.; Alalwan, A.A.; Bewick, B.M.; Gardner, P.; Househ, M. An overview of the features of chatbots in mental health: A scoping review. Int. J. Med Inform. 2019, 132, 103978. [Google Scholar] [CrossRef]
- Vaidyam, A.N.; Wisniewski, H.; Halamka, J.D.; Kashavan, M.S.; Torous, J.B. Chatbots and Conversational Agents in Mental Health: A Review of the Psychiatric Landscape. Can. J. Psychiatry 2019, 64, 456–464. [Google Scholar] [CrossRef]
- Liu, W.; Jia, K.; Wang, Z.; Ma, Z. A Depression Prediction Algorithm Based on Spatiotemporal Feature of EEG Signal. Brain Sci. 2022, 12, 630. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, Z.; Liu, W.; An, Z.; Huang, F. A Depression Diagnosis Method Based on the Hybrid Neural Network and Attention Mechanism. Brain Sci. 2022, 12, 834. [Google Scholar] [CrossRef]
- Giacometti, P.; Perdue, K.L.; Diamond, S.G. Algorithm to find high density EEG scalp coordinates and analysis of their correspondence to structural and functional regions of the brain. J. Neurosci. Methods 2014, 229, 84–96. [Google Scholar] [CrossRef]
- Kesić, S.; Spasić, S.Z. Application of Higuchi’s fractal dimension from basic to clinical neurophysiology: A review. Comput. Methods Programs Biomed. 2016, 133, 55–70. [Google Scholar] [CrossRef] [PubMed]
- Inouye, T.; Shinosaki, K.; Sakamoto, H.; Toi, S.; Ukai, S.; Iyama, A.; Katsuda, Y.; Hirano, M. Quantification of EEG irregularity by use of the entropy of the power spectrum. Electroencephalogr. Clin. Neurophysiol. 1991, 79, 204–210. [Google Scholar] [CrossRef]
- Jelinek, H.F.; Donnan, L.; Khandoker, A.H. Singular Value Decomposition Entropy As a Measure of Ankle Dynamics Efficacy in a Y-Balance Test Following Supportive Lower Limb Taping. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; Volume 2019, pp. 2439–2442. Available online: https://ieeexplore.ieee.org/document/8856655/ (accessed on 26 October 2022).
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zorick, T.; Mandelkern, M.A. Multifractal Detrended Fluctuation Analysis of Human EEG: Preliminary Investigation and Comparison with the Wavelet Transform Modulus Maxima Technique. PLoS ONE 2013, 8, e68360. [Google Scholar] [CrossRef]
- Henry, M.; Judge, G. Permutation Entropy and Information Recovery in Nonlinear Dynamic Economic Time Series. Econometrics 2019, 7, 10. [Google Scholar] [CrossRef] [Green Version]
- Beck, A.T.; Steer, R.A.; Brown, G. Beck Depression Inventory–II [Internet]; American Psychological Association: San Antonio, TX, USA, 2011; Available online: http://doi.apa.org/getdoi.cfm?doi=10.1037/t00742-000 (accessed on 26 October 2022).
- Oldfield, R.C. The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia 1971, 9, 97–113. [Google Scholar] [CrossRef]
- Gramfort, A. MEG and EEG data analysis with MNE-Python. Front. Neurosci. 2013, 7, 267. Available online: http://journal.frontiersin.org/article/10.3389/fnins.2013.00267/abstract (accessed on 26 October 2022). [CrossRef] [Green Version]
- Kumaravel, V.P.; Kartsch, V.; Benatti, S.; Vallortigara, G.; Farella, E.; Buiatti, M. Efficient Artifact Removal from Low-Density Wearable EEG using Artifacts Subspace Reconstruction. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Guadalajara, Mexico, 31 October–4 November 2021; IEEE: Guadalajara, Mexico, 2021; pp. 333–336. Available online: https://ieeexplore.ieee.org/document/9629771/ (accessed on 26 October 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Nothman, G.; et al. Scikit-Learn: Machine learning in Python. arXiv 2018, arXiv:1201.0490. Available online: http://arxiv.org/abs/1201.0490 (accessed on 26 October 2022).
- Vallat, R.; Walker, M.P. An open-source, high-performance tool for automated sleep staging. eLife 2021, 10, e70092. [Google Scholar] [CrossRef]
- Keras-Team. Keras-Team/Keras: Deep Learning for Humans. GitHub 2022. Available online: https://github.com/keras-team/keras (accessed on 26 October 2022).
- Cavanagh, J.F.; Napolitano, A.; Wu, C.; Mueen, A. The Patient Repository for EEG Data + Computational Tools (PRED+CT). Front. Neuroinform. 2017, 11, 67. [Google Scholar] [CrossRef] [Green Version]
- Fraschini, M.; Demuru, M.; Crobe, A.; Marrosu, F.; Stam, C.J.; Hillebrand, A. The effect of epoch length on estimated EEG functional connectivity and brain network organisation. J. Neural Eng. 2016, 13, 036015. [Google Scholar] [CrossRef] [PubMed]
- Peng, X.; Wu, X.; Gong, R.; Yang, R.; Wang, X.; Zhu, W.; Lin, P. Sub-regional anterior cingulate cortex functional connectivity revealed default network subsystem dysfunction in patients with major depressive disorder. Psychol. Med. 2020, 51, 1687–1695. [Google Scholar] [CrossRef] [PubMed]
- Toenders, Y.J.; Schmaal, L.; Nawijn, L.; Han, L.K.; Binnewies, J.; van der Wee, N.J.; van Tol, M.-J.; Veltman, D.J.; Milaneschi, Y.; Lamers, F.; et al. The association between clinical and biological characteristics of depression and structural brain alterations. J. Affect. Disord. 2022, 312, 268–274. [Google Scholar] [CrossRef] [PubMed]
- Hultman, R.; Ulrich, K.; Sachs, B.D.; Blount, C.; Carlson, D.; Ndubuizu, N.; Bagot, R.C.; Parise, E.M.; Vu, M.-A.T.; Gallagher, N.; et al. Brain-wide Electrical Spatiotemporal Dynamics Encode Depression Vulnerability. Cell 2018, 173, 166–180.e14. [Google Scholar] [CrossRef] [Green Version]
- Siuly, S.; Kabir, E.; Wang, H.; Zhang, Y. Exploring Sampling in the Detection of Multicategory EEG Signals. Comput. Math. Methods Med. 2015, 2015, 576437. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, Y.; Fang, S.; Wang, J.; Wang, C.; Zhao, J.; Gai, Y. Continuous EEG detection of DCI and seizures following aSAH: A systematic review. Br. J. Neurosurg. 2019, 34, 543–548. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | Electrodes | Cross-Validation Score |
|---|---|---|
| Transverse temporal | TP8, T7, T8 | 0.660 (±0.01) |
| Banks superior temporal sulcus | P8, TP7, TP8 | 0.735 (±0.01) |
| Caudal anterior-cingulate | FC2, AFz, F2 | 0.987 (±0.0006) |
| Caudal middle frontal | FC6, FC3, FC4 | 0.791 (+/−0.003) |
| Isthmus-cingulate | PO8, PO7, Pz, POz | 0.807 (+/−0.01) |
| Lateral occipital | PO7, PO8, O1, O2 | 0.853 (±0.0007) |
| Lateral orbitofrontal | N2, F8, N1, F9, F10 | 0.987 (±0.0006) |
| Lingual gyrus | Iz, PO8, PO7, Oz | 0. 784 (±0.002) |
| Medial orbital frontal | Fp2, N2, Fpz | 0.928 (±0.001) |
| Paracentral lobule | C1, C2, Cpz, Cz | 0.931 (+/−0.001) |
| Pars opercularis | FC5, FC6, FT7, FT8 | 0.684 (±0.003) |
| Pars orbitalis | F8, AF7, F9, F10 | 0.918 (±0.001) |
| Pars triangularis | FT7, FT8, F5, F8, F7 | 0.685 (±0.004) |
| Pericalcarine | POz, O1, O2, Oz | 0.908 (±0.0005) |
| Postcentral gyrus | T8, C5, C4, C6, C3 | 0.610 (±0.002) |
| Posterior cingulate | Cz, C1, FC2, C2 | 0.881 (±0.001) |
| Precentral gyrus | C3, C2, C4, C1 | 0.821 (±0.001) |
| Precuneus | PO3, Pz, POz | 0.951 (±0.0009) |
| Rostral anterior cingulate | AF4, AFz, Fp2, Fpz | 0.853 (±0.001) |
| Rostral middle frontal gyrus | AF3, F5, AF8, F6 | 0.740 (±0.002) |
| Superior frontal gyrus | AF3, F5, AF8, F6 | 0.961 (±0.0004) |
| Superior parietal | POz, CP1, P2, P1 | 0.894 (±0.0007) |
| Superior temporal gyrus | TP8, FT9, T8, T7 | 0.660 (±0.001) |
| Supramarginal gyrus | C5, CP5, CP6 | 0.816 (±0.001) |
| Cuneus | PO3, PO4, Oz, POz | 0.919 (±0.0009) |
| Inferior parietal | P3, P4, P5, P6 | 0.842 (±0.002) |
| Model | Loss | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| LSTM | 0.0157 | 0.99489 | 0.99246 | 0.99715 | 0.99480 |
| CNNGRU | 0.0118 | 0.99628 | 0.99651 | 0.99588 | 0.99620 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jan, D.; de Vega, M.; López-Pigüi, J.; Padrón, I. Applying Deep Learning on a Few EEG Electrodes during Resting State Reveals Depressive States: A Data Driven Study. Brain Sci. 2022, 12, 1506. https://doi.org/10.3390/brainsci12111506
Jan D, de Vega M, López-Pigüi J, Padrón I. Applying Deep Learning on a Few EEG Electrodes during Resting State Reveals Depressive States: A Data Driven Study. Brain Sciences. 2022; 12(11):1506. https://doi.org/10.3390/brainsci12111506
Chicago/Turabian StyleJan, Damián, Manuel de Vega, Joana López-Pigüi, and Iván Padrón. 2022. "Applying Deep Learning on a Few EEG Electrodes during Resting State Reveals Depressive States: A Data Driven Study" Brain Sciences 12, no. 11: 1506. https://doi.org/10.3390/brainsci12111506