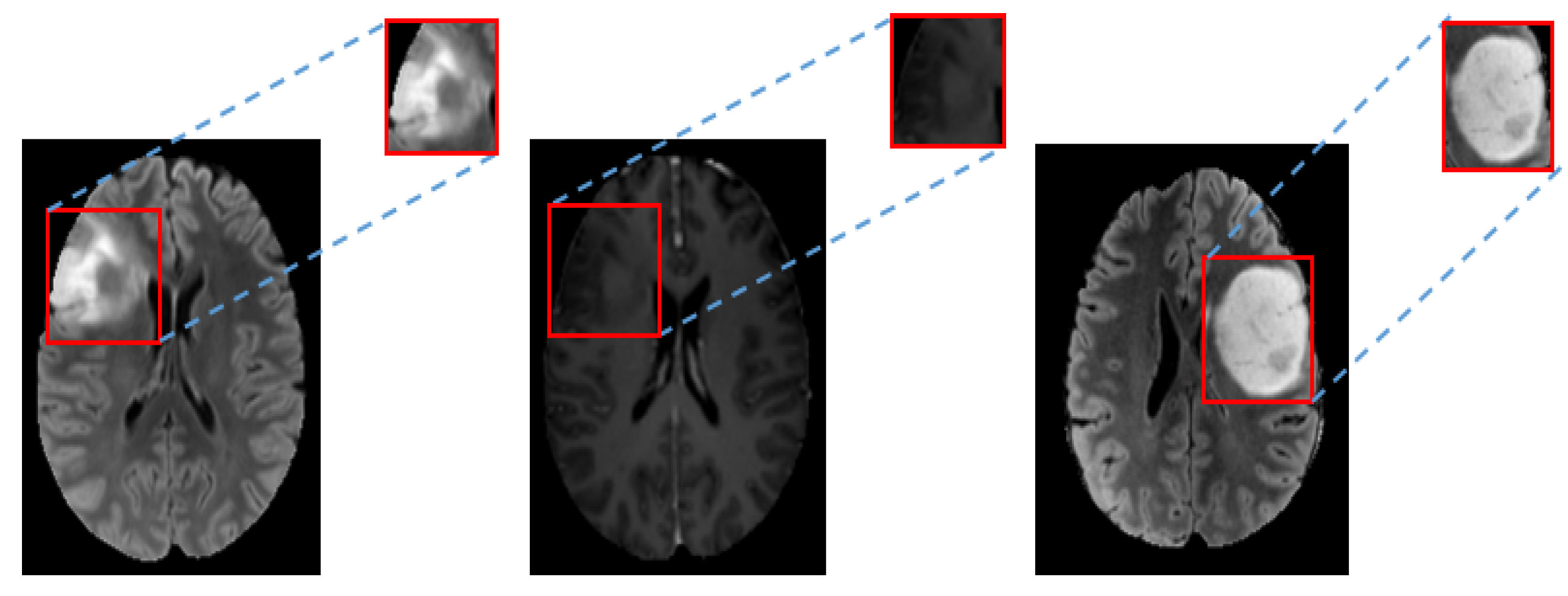
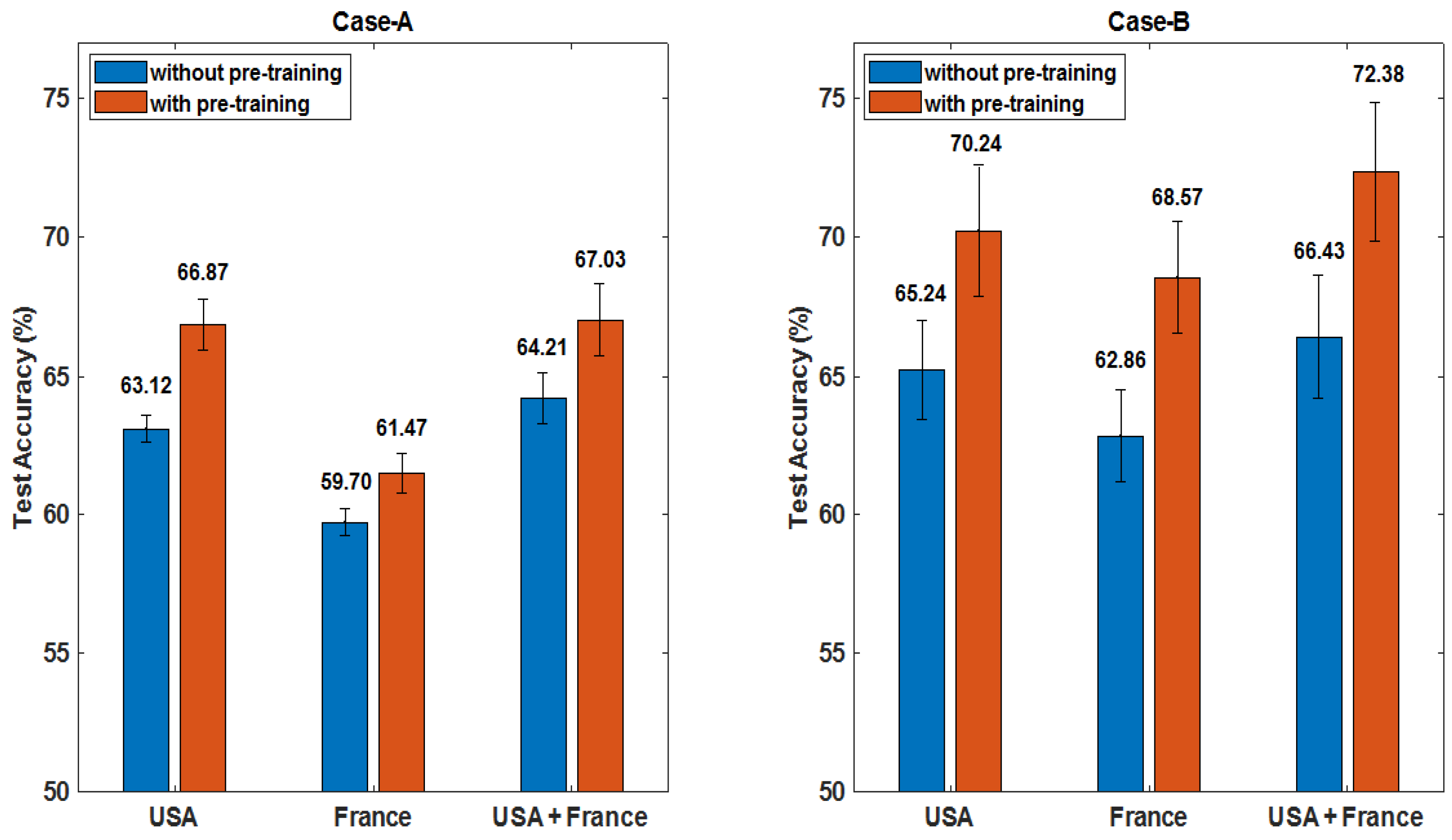
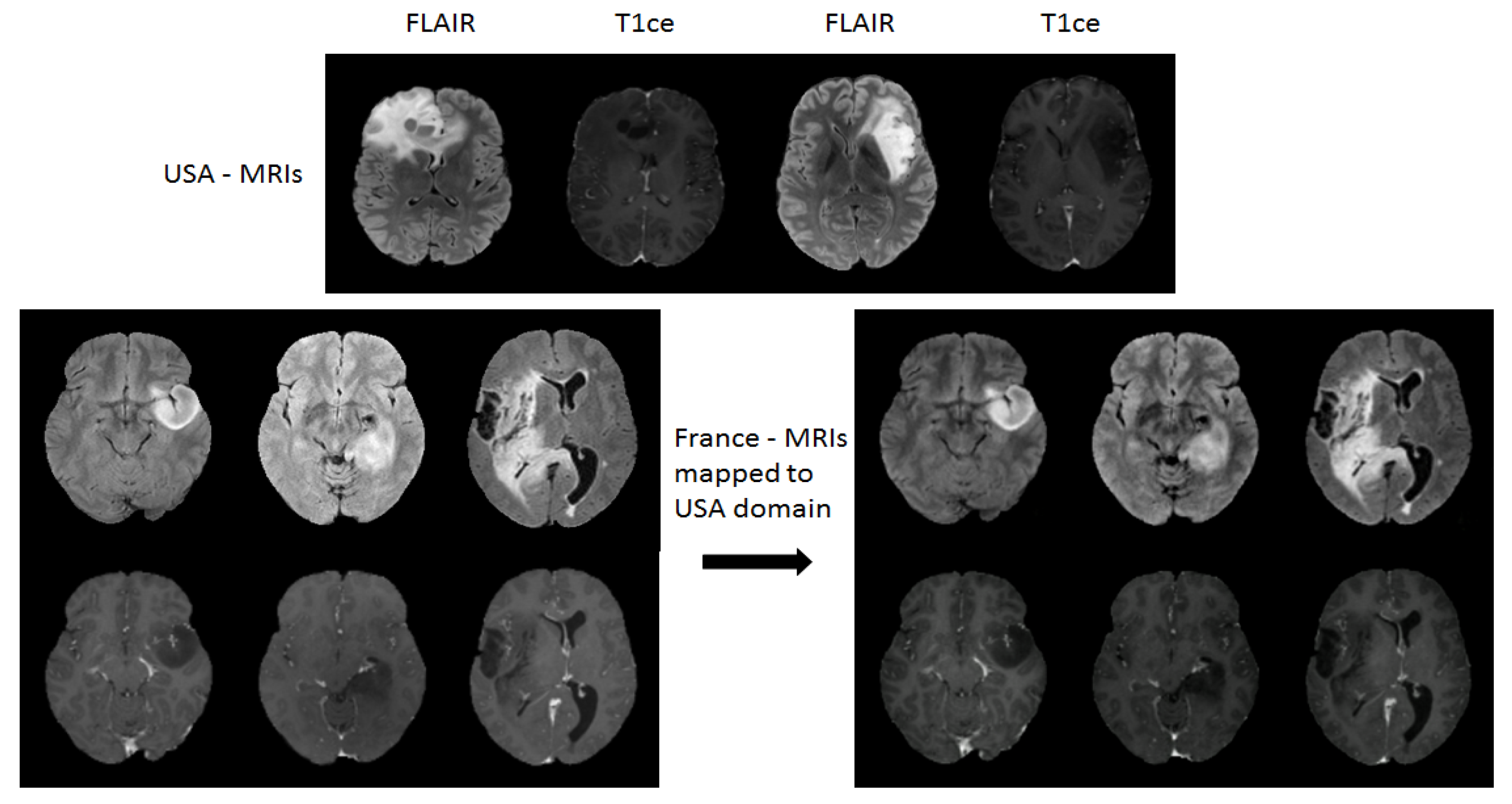
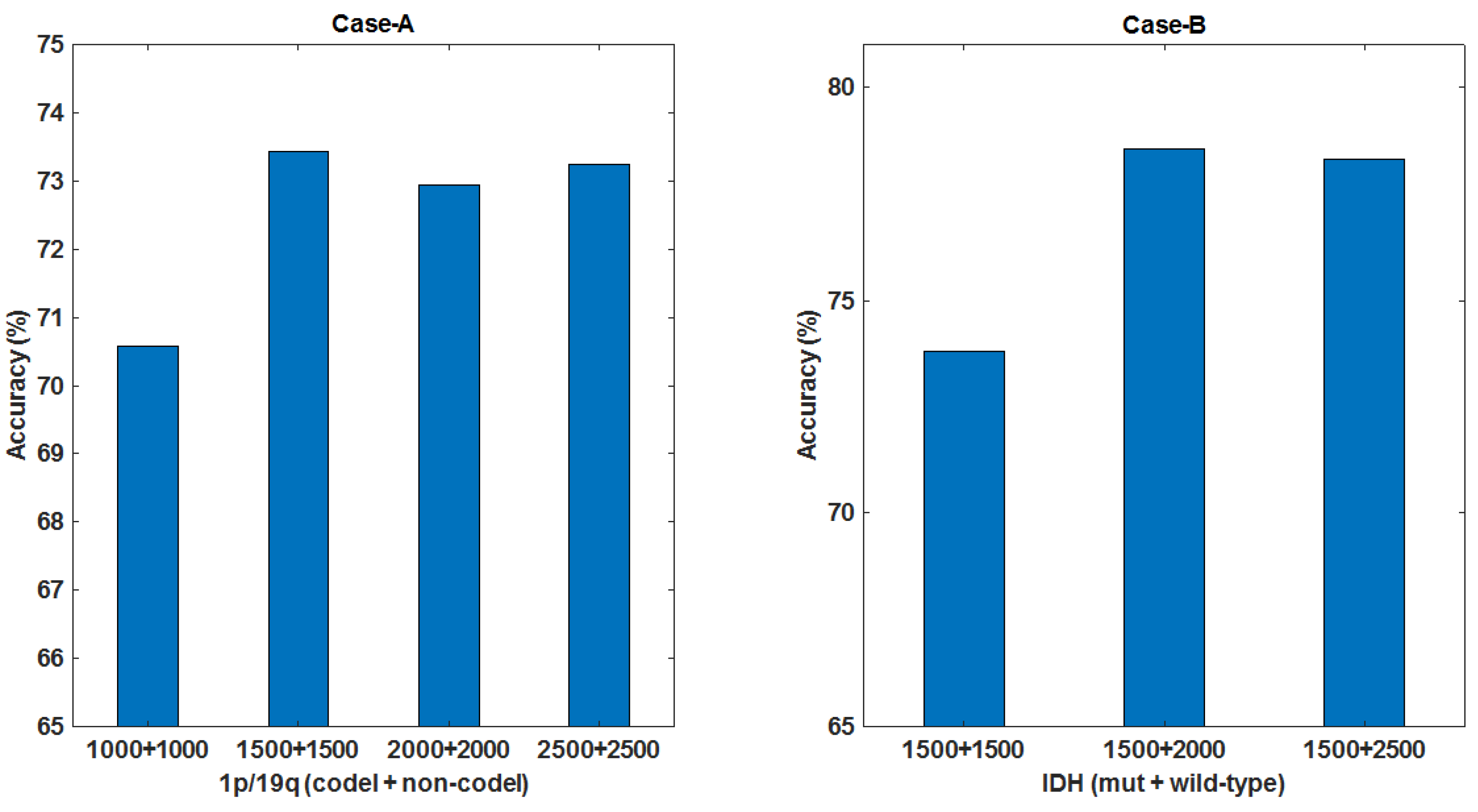
We propose a novel approach based on unpaired-CycleGAN to overcome the scanner dependent domain mismatches while preserving the subtitle molecular-biomarker information of MRI data. The basic idea is to overcome the problem of LGG MRI data scarcity and make the small raw clinical data usable from multiple institutions for improved performance of subtype glioma classification, which consists of: (a) using unpaired-CycleGAN to map source domain MRIs (FLAIR, T1ce) to target domain MRIs. (b) The combined MRI data are still small in size because of (i) still less number of subjects, (ii) poor resolution of 3D MRI at sagittal and coronal views, (iii) large class imbalance in IDH genotype. Therefore, deep convolutional GAN (DCGAN) is used to augment synthetic MRIs across different modalities to enlarge the training data. The fake generated MRIs cover more tumor statistics that offer more robustness to its distribution although they look similar to real MRIs visually [
22]. (c) Extracting high-level glioma features through applying 2-streams of convolutional autoencoders (CAEs) from multi-modality MRIs (T1ce, FLAIR) that is followed by information fusion with 2-stage training strategy. The augmented MRIs are used for pre-training to capture the glioma features while the real MRIs are used for refined training.
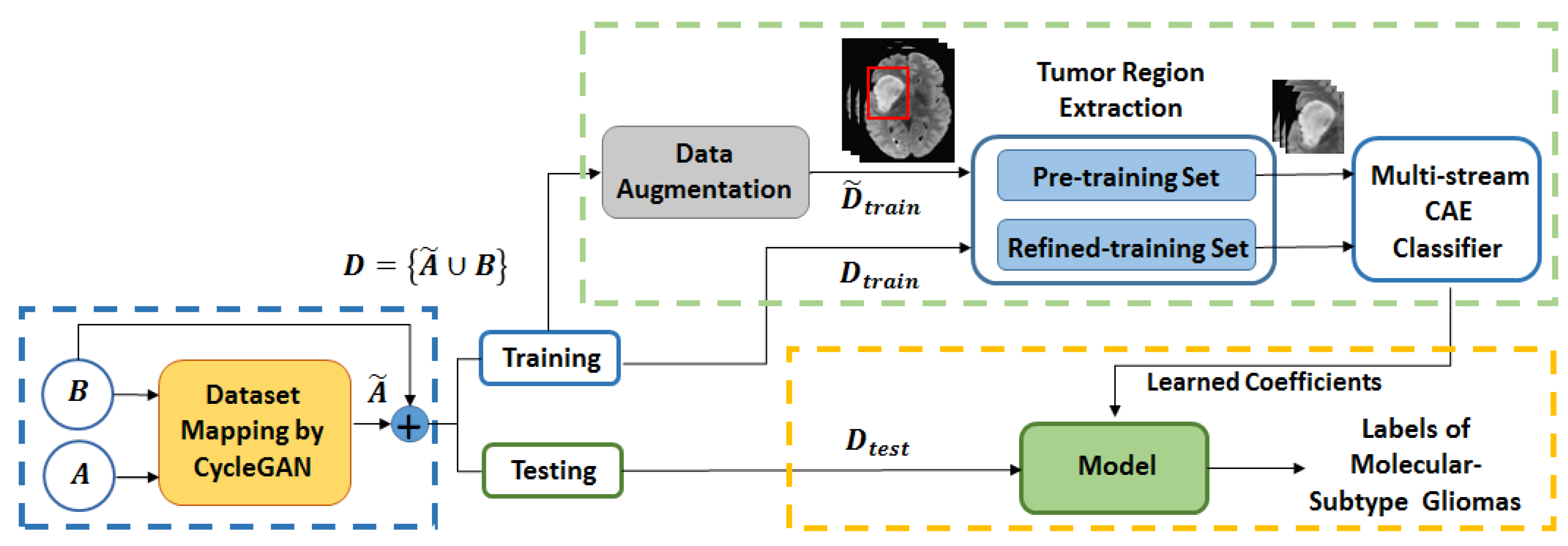
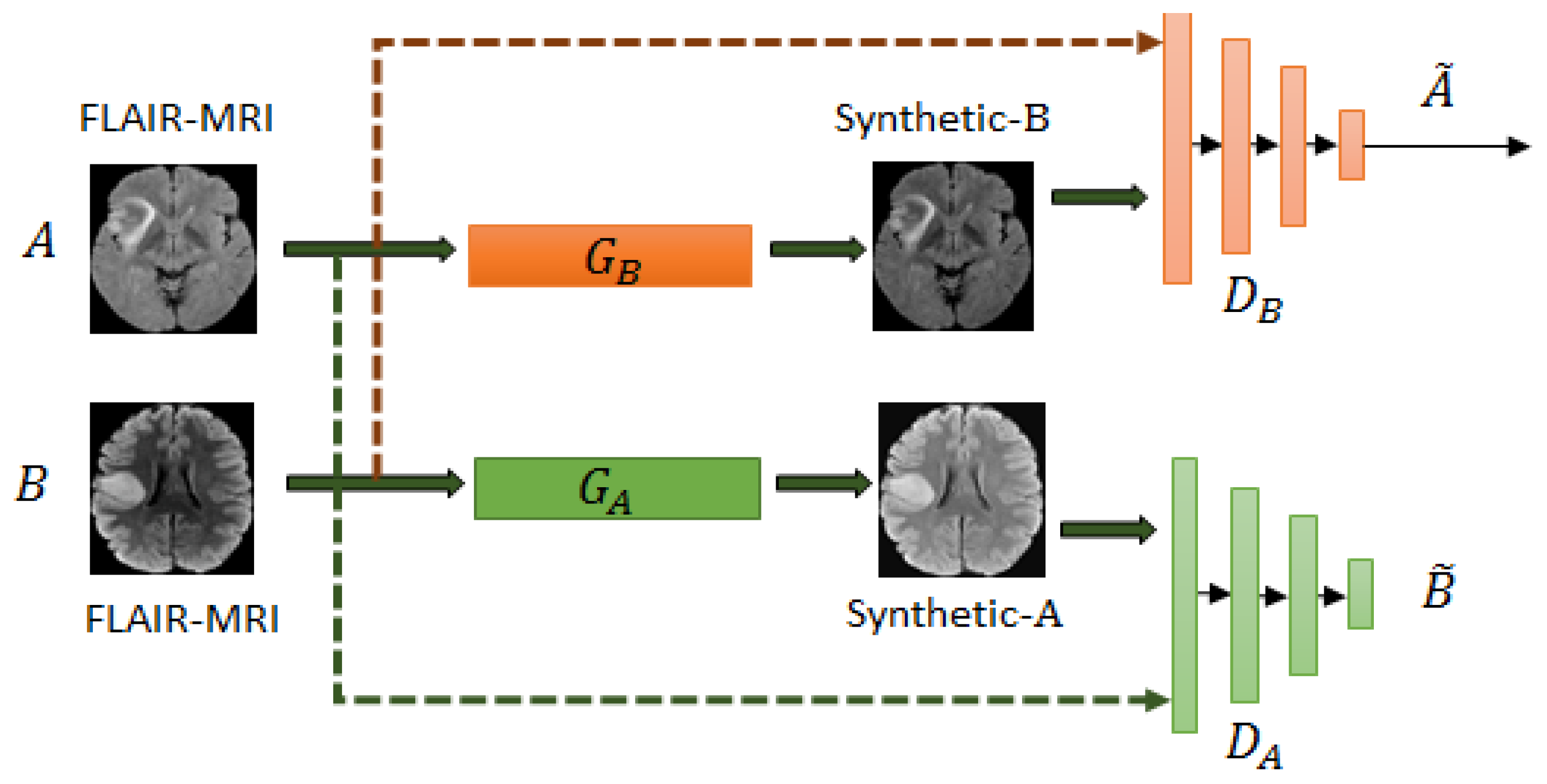
Figure 1 shows the block diagram of the proposed scheme for LGG-subtype glioma prediction based on clinical MRI data from two hospitals. Input 2D images from multi-modality MRIs (T1-contrast enhanced (T1ce), FLAIR) are fed into CycleGAN for mapping from source domain
A to target domain
B to generate mapped 2D images
for each modality. These mapped data are added to the target domain to obtain total data
D. To further enlarge the size of training data
for each modality, image augmentation is done by employing deep convolution GAN (DCGAN) [
35]. As the datasets have no tumor masks, the tumor regions are extracted by fixing a tight rectangular bounding box around ROI of images. These images with only tumor regions are used in a two step training strategy by 2-streams of convolutional autoencoder (CAE) [
34]. During pre-training, phase features are learned from augmented images
(T1ce-MRI and FLAIR-MRI). In refined training stage, features are fine tuned from
MRIs in two streams which are further followed by feature fusion and two fully connected layers for prediction. Once the model is trained (green dashed box in
Figure 1), the prediction is made on test data
(yellow dashed box). In the remaining of this section, we shall give further details to explain the block from the blue dashed box (CycleGAN for domain mapping in
Section 2.1) and the green dashed box (data augmentation in
Section 2.2 and multi-stream CAE classifier in
Section 2.3) from
Figure 1 with their corresponding architectures.
Section 3 describes the experimental setup, obtained results and comparison with the existing methods. Finally, in
Section 4 conclusions are drawn from discussion.
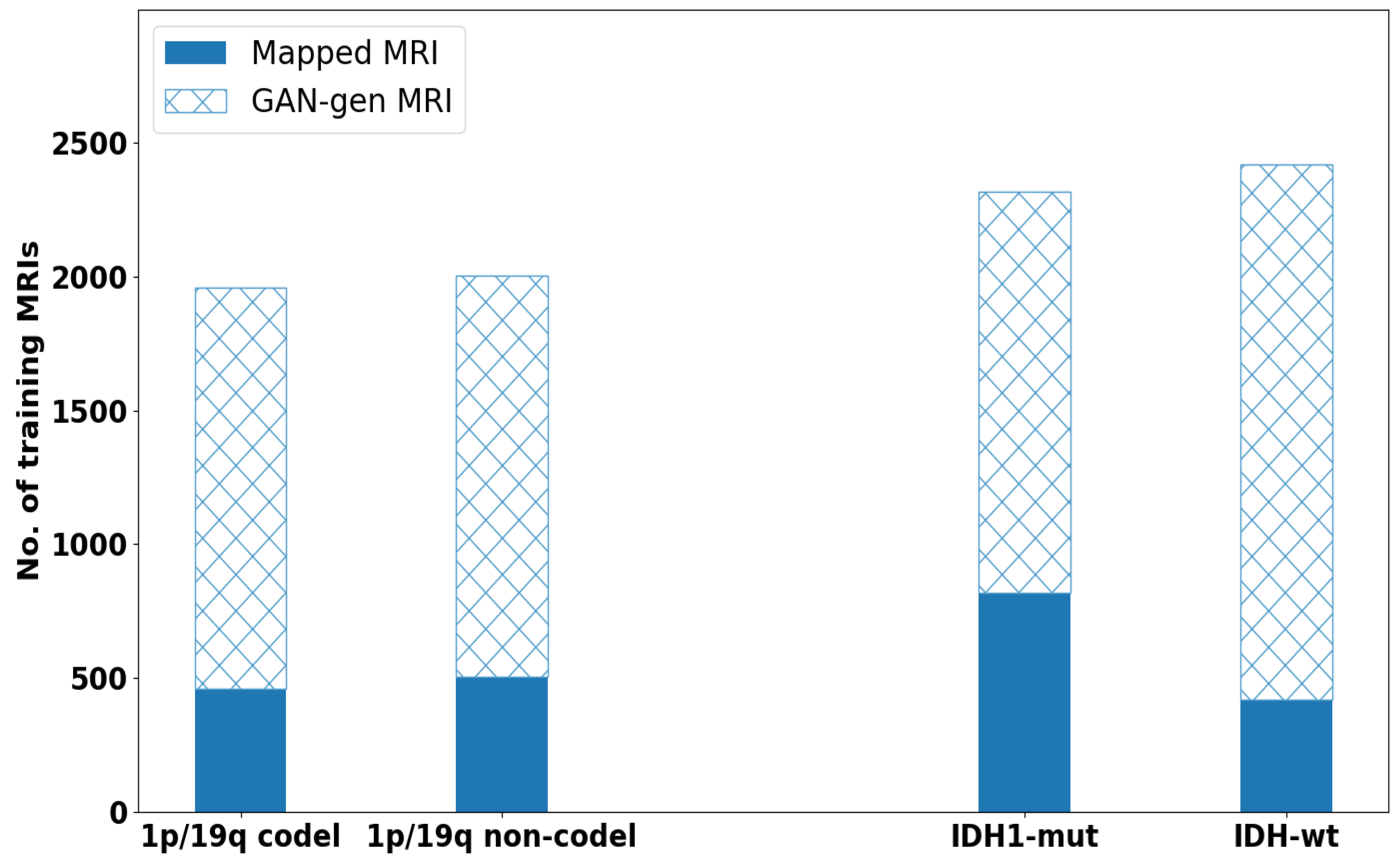
2.2. Data Augmentation by Deep Convolutional GAN
This part explains the data augmentation block in the pipeline from
Figure 1 to generate augmented synthetic data
. In medical imaging, insufficient training dataset is partially resolved by slicing the 3D-MRIs to 2D slices with the maximum number covering tumor regions. Usually if data has enough resolution in all directional views, 2D slices are extracted from all directions of 3D volume (e.g., axial, coronal and sagittal). However, this strategy helps to some extent to increase diversity in training set and prevents the model from over-fitting. Since, the size of the datasets
A and
B are quite small which is still not sufficient to train a good predictive model. In this regard, we have used deep convolutional GAN (DCGAN) [
35] for enlarging the training data size by generating augmented images for both modalities T1ce-MRIs and FLAIR-MRIs. Although the CycleGAN generated data are also considered as synthetic but because it preserves the anatomy of brain image from molecular level of tumor to the whole brain image unlike DCGAN, we call it here as mapped data. While the augmented distribution of data from DCGAN presents some differences, for instance; size of tumor, tumor location and introduce other structural differences. A detail description of the architecture is given in
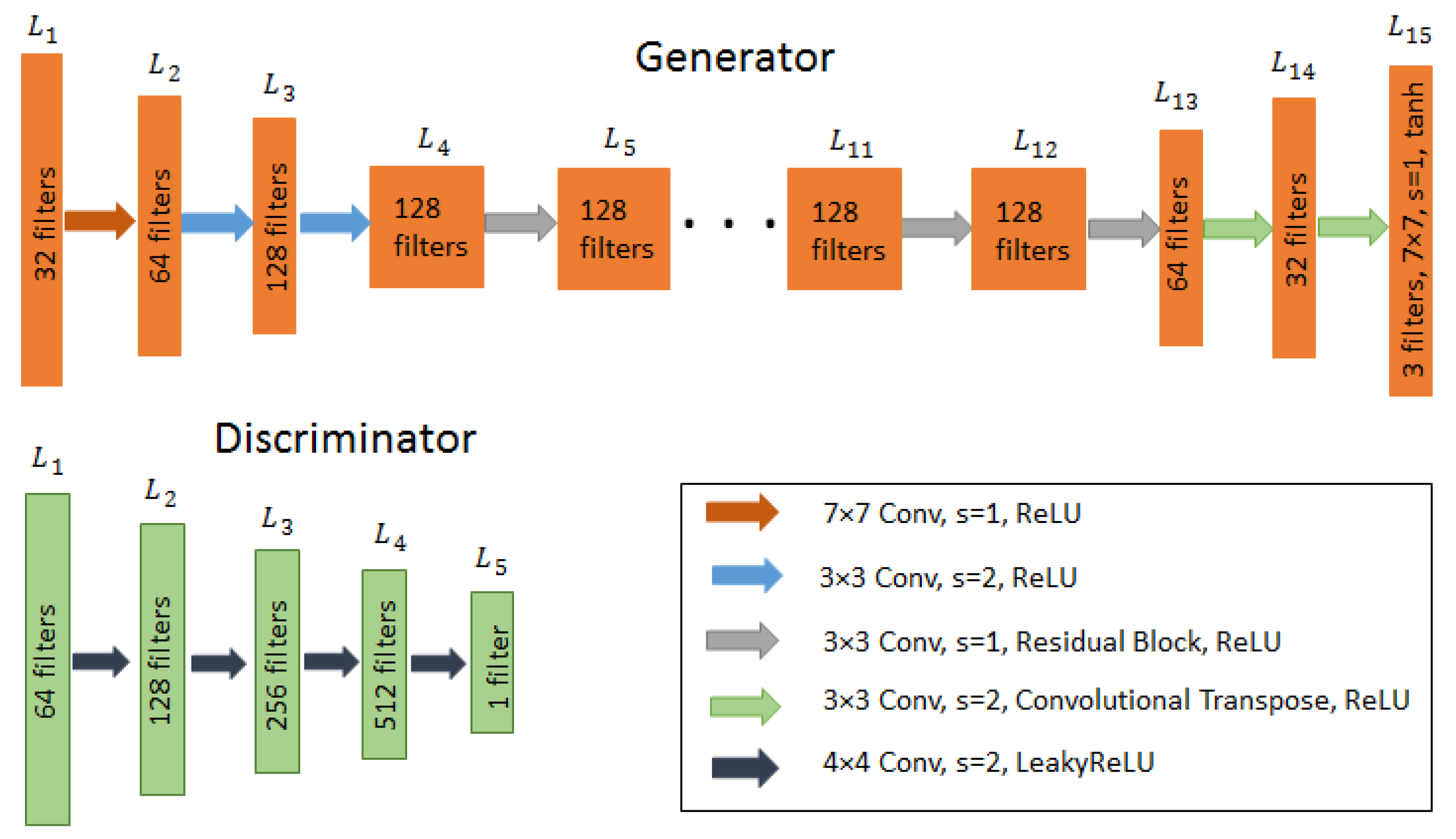
Table 1.
Unlike CycleGAN from
Section 2.1 which accepts input as an image, here, the generator
G learns a mapping from an input vector
z (typically from a uniform distribution
) and maps to an image
y in the target domain
. While discriminator
D learns to distinguish between the true images
y and the fake images
. While training, both
G and
D learn simultaneously where
G aims to generate images with high probability to achieve the goal
and look more real. Conversely,
D learns aiming to discriminate the fake and true images. This is obtained by optimizing the given adversarial loss function in Equation (
5):
where
G tries to minimize the loss function
for images with
y≁
and
D tries to maximize
for images with
y∼
simultaneously. The aim is that
G learns to produce more realistic augmented images that
D might not differentiate from the real ones. For each MRI-modality, DCGAN is trained separately to synthesize the augmented images from the corresponding modality. A vector of 100 random samples drawn from a uniform distribution is given to the generator network as input to generate the augmented MR images and the discriminator compares the original and augmented images to output a decision: real or fake?
2.3. Review of Multi-Stream Convolutional Autoencoder and Feature Fusion
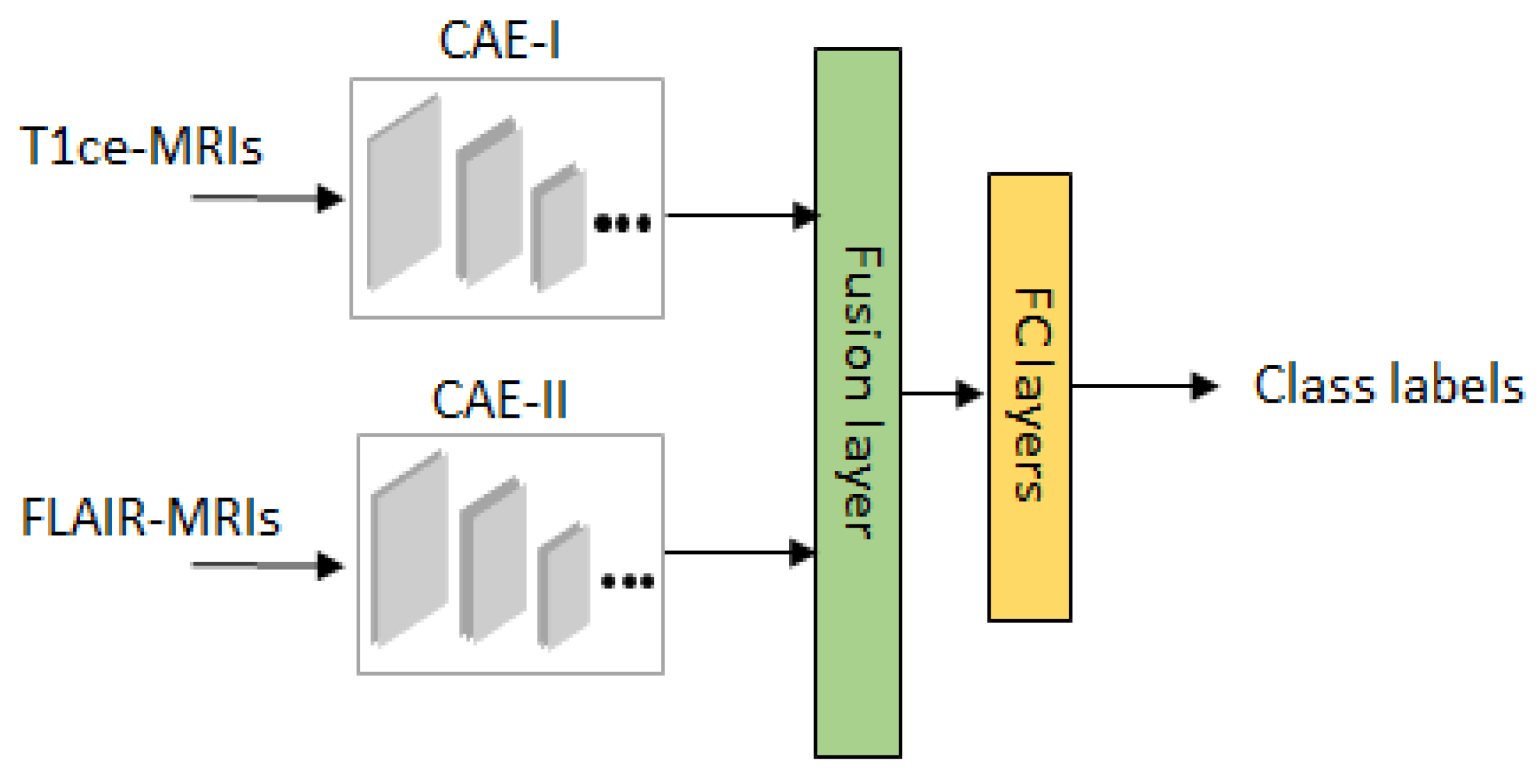
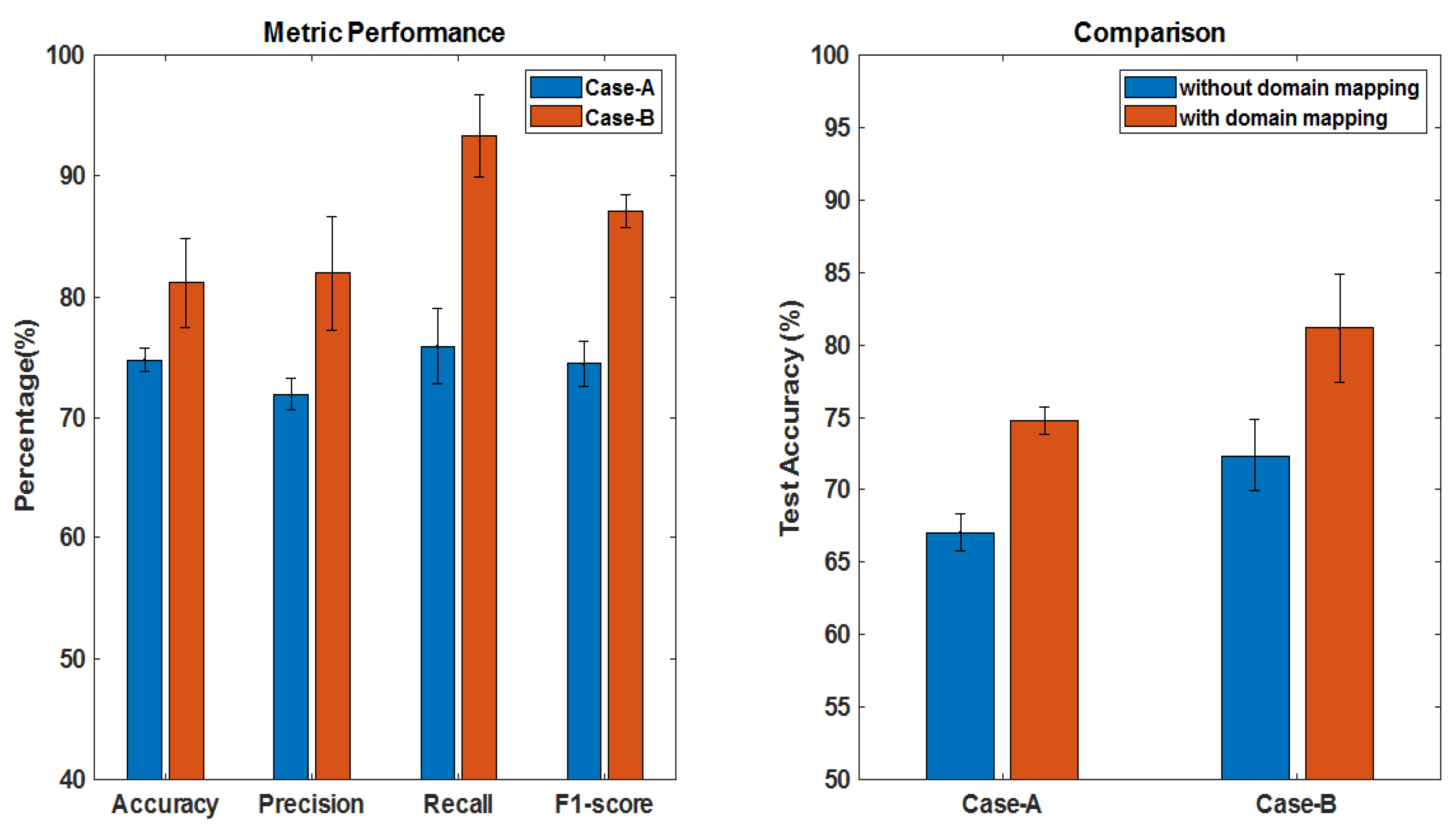
For the sake of convenience to the readers, a brief overview of the classifier is given in
Figure 4. After overcoming the possible mismatches between the two domains
A and
B, we have obtained data
D in total. Moreover, both the datasets are available without the tumor masks so to allow the network to focus on learning the tumor characteristics, we have fixed a rectangular tight bounding box on the ROI (region of interest) of each image. This step is further proceeded with a two-stage training strategy based on our previous work on Multistream Convolutional Auoteoncder [
25] as a classifier. By doing so, a noticeable performance is obtained from our empirical test results. A detailed architecture of one stream of classifier is described in
Table 2. For the 2 modalities of MRIs, we train 2 convolutional autoencoders denoted as CAE-I and CAE-II. In each CAE, the encoder part consists of 6 convolutional layers for extracting high dimensional feature maps followed by the decoder with 5 convolutional layers for reconstruction. Since, this overcomplete representation gives the CAE possibility to learn the identity function. To prevent over representation, max-pooling is used to enforce the learning of plausible features.
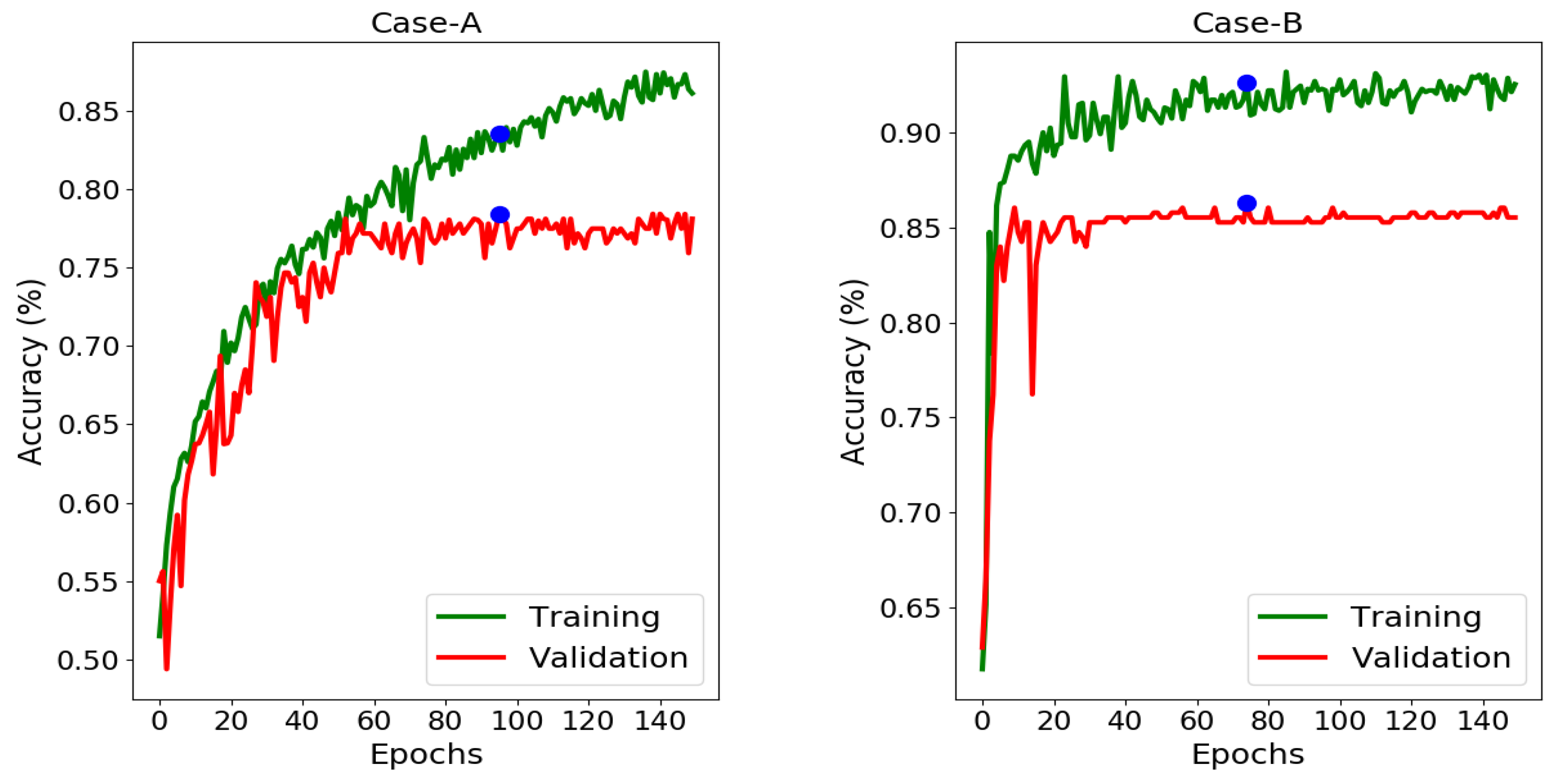
We use two stage training strategy for our classifier network. In pre-training stage, both streams are unsupervisedly trained on GAN augmented data
with the corresponding MRI modalities. The aim of this training phase is allowing the encoders learn generic features from augmented data
. In refine training stage, features learned by encoder layers from 2 streams are proceeded further by feature fusion for prediction where it has access to the data
and the class labels. For the refinement of fused features and compact representation, aggregation and bilinear layers are used on fusion layers [
37]. Let
and
denote the features from the last encoder layers of size
, where
h is the height,
w is the width and
c shows the number of channels. The aggregated feature vector is obtained by element-wise multiplication as
and hence the spatial relationship of features from both streams are maintained. The bilinear feature layer captures the interaction of features with each other at spatial locations by computing
, where
is the final refinement map. Finally, fully connected layers are introduced each with 256 number of neurons with random initialization and dropout regularization. Then, a softmax layer is added that determines the class labels. This way of two stage training has been seen effective in learning generic features and fast convergence.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}