Methane Detection Based on Improved Chicken Algorithm Optimization Support Vector Machine


Abstract
:
1. Introduction
2. Methodology
2.1. SVM
2.2. Chicken Swarm Optimization Algorithm (CSO)
2.3. Improved Chicken Swarm Optimization (ICSO)
2.4. ICSO Optimized SVM Model
- (1)
- Parameter setting.The population size pop: namely, the number of chickens (roosters, hens, and chicks).The maximum number of iterations M: the chickens finish their forage after repeating their search procedure M times.Reconstruction coefficient G: the role assignment of chickens and the subgroup divisions will be done every G times.The numbers of roosters is denoted as RP, hens are HP, mother hens are MP, and chicks are CP.The values of the learning factors are denoted as C3 and C4.The penalty factor C and the kernel parameter g are set within a range.
- (2)
- Calculate the best fitness of the individuals, and find the optimum position according to the value of their fitness. Initialize the personal best position p best and the global best position g best. Initialize the current iteration number t = 1.
- (3)
- If t% G = 1, rank the fitness of chickens and sort chickens according to their fitness values in descending order. Select the chickens with the best fitness values as roosters. Those chickens with the worst fitness values are chicks, and the other chickens are hens. The chickens are divided into subgroups, the number of subgroups equals to the number of roosters. The hens and chicks are randomly assigned. The hens are assigned randomly as the chicks’ mothers, and chicks are in the same subgroup as their mothers.
- (4)
- Update the position of each chicken with Equations (14), (16), and (20), and recalculate the fitness values of the chickens. Update the value of p best and g best.
- (5)
- Repeat steps (3) and (4) until the iteration stop condition is reached, and output the optimum value.
3. Performance Evaluation Criterion
4. Introduction of Datasets
5. Results and Analysis
5.1. Parameter Setting and Analysis
5.2. Prediction Results
6. Conclusions
- (1)
- The mean squared error was adopted as the fitness function of the models. The experimental results show that the ICSO algorithm more easily finds a global optimum, and can converge more stably than the other three algorithms. The results also show that the ICSO algorithm has satisfactory convergence, and that it is effective for the improvement of the CSO algorithm.
- (2)
- The samples were randomly selected from the whole dataset. The train–test procedure was repeated five times with four models. Compared with the other three optimization algorithms, the prediction values and predicted average relative error percentage of the ICSO-SVM model are obviously superior.
- (3)
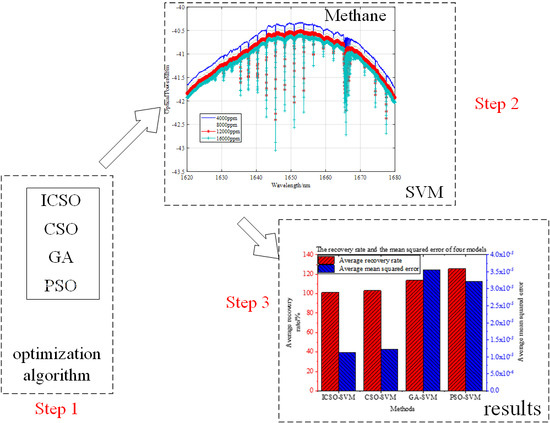
- From the 50 train–test repeats experiment, we can see that the recovery rate of ICSO-SVM model shows better stability than other three models. The average recovery rates of ICSO-SVM, CSO-SVM, GA-SVM, and PSO-SVM were 101.23, 103.15, 113.58, and 125.61, respectively. The average mean squared errors of the four models were 1.12 × 10−5, 1.23 × 10−5, 3.56 × 10−5, and 3.22 × 10−5, respectively. These experimental results verify the feasibility and validity of ICSO-SVM for predicting the concentration of methane.
Author Contributions
Funding
Conflicts of Interest
References
- Apte, J.S.; Marshall, J.D.; Cohen, A.J.; Brauer, M. Addressing global mortality from ambient PM2.5. Environ. Sci. Technol. 2015, 49, 8057–8066. [Google Scholar] [CrossRef] [PubMed]
- Di, Q.; Kloog, I.; Koutrakis, P.; Lyapustin, A.; Wang, Y.; Schwartz, J. Assessing PM2.5 exposures with high spatiotemporal resolution across the continental United States. Environ. Sci. Technol. 2016, 50, 4712–4721. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Zhu, Z. Research and application of a novel hybrid air quality early-warning system: A case study in China. Sci. Total Environ. 2018, 626, 1421–1438. [Google Scholar] [CrossRef]
- Liu, K.; Wang, L.; Tan, T.; Wang, G.; Zhang, W.; Chen, W.; Gao, X. Highly Sensitive Detection of Methane by Near-infrared Laser Absorption Spectroscopy Using A Compact Dense-pattern Multipass Cell. Sens. Actuators B-Chem. 2015, 220, 1000–1005. [Google Scholar] [CrossRef]
- Cao, Y.; Sanchez, N.P.; Jiang, W.; Griffin, R.J.; Xie, F.; Hughes, L.C.; Zah, C.-E.; Tittel, F.K. Simultaneous Atmospheric Nitrous Oxide, Methane and Water Vapor Detection with A Single Continuous Wave Quantum Cascade Laser. Opt. Express 2015, 23, 2121–2132. [Google Scholar] [CrossRef]
- Tan, W.; Yu, H.; Huang, C. Discrepant responses of methane emissions to additions with different organic compound classes of rice straw in paddy soil. Sci. Total Environ. 2018, 630, 141–145. [Google Scholar] [CrossRef]
- Zhou, G. Research prospect on impact of climate change on agricultural production in China. Meteorol. Environ. Sci. 2015, 38, 80–94. [Google Scholar]
- Contribution of Working Group I to the 5th Assessment Report of the Intergovernmental Panel on Climate Change. The Physical Science Basis; IPCC: Geneva, Switzerland, 2013. [Google Scholar]
- Shemshad, J.; Aminossadati, S.M.; Kizil, M.S. A review of developments in near infrared methane detection based on tunable diode laser. Sens. Actuators B Chem. 2012, 171, 77–92. [Google Scholar] [CrossRef]
- Ma, Y.; Lewicki, R.; Razeghi, M.; Tittel, F.K. QEPAS based ppb-level detection of CO and N2O using a high power CW DFB-QCL. Opt. Express 2013, 21, 1008–1019. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Ma, Y.; Tong, Y.; Yu, X.; Tittel, F.K. Ultra-high sensitive light-induced thermoelastic spectroscopy sensor with a high Q-factor quartz tuning fork and a multipass cell. Opt. Lett. 2019, 44, 1904–1907. [Google Scholar] [CrossRef] [PubMed]
- Hao, Z.; Zhao, H.; Zhang, C.; Wang, H.; Jiang, Y.; Yi, Z. Estimating winter wheat area based on an SVM and the variable fuzzy set method. Remote Sens. Lett. 2019, 10, 343–352. [Google Scholar] [CrossRef]
- Haobin, P.E.N.G.; Guohua, C.H.E.N.; Xiaoxuan, C.H.E.N.; Zhimin, L.U.; Shunchun, Y.A.O. Hybrid classification of coal and biomass by laser-induced breakdown spectroscopy combined with K-means and SVM. Plasma Sci. Technol. 2019, 21, 034008. [Google Scholar] [CrossRef]
- Tao, Z.; Huiling, L.; Wenwen, W.; Xia, Y. GA-SVM based feature selection and parameter optimization in hospitalization expense modeling. Appl. Soft Comput. J. 2019, 75, 323–332. [Google Scholar] [CrossRef]
- Wang, X.; Guan, S.; Hua, L.; Wang, B.; He, X. Classification of spot-welded joint strength using ultrasonic signal time-frequency features and PSO-SVM method. Ultrasonics 2019, 91, 161–169. [Google Scholar] [CrossRef]
- Wang, Y.; Meng, X.; Zhu, L. Cell Group Recognition Method Based on Adaptive Mutation PSO-SVM. Cells 2018, 7, 135. [Google Scholar] [CrossRef]
- Liu, T.; Liu, S.; Heng, J.; Gao, Y. A New Hybrid Approach for Wind Speed Forecasting Applying Support Vector Machine with Ensemble Empirical Mode Decomposition and Cuckoo Search Algorithm. Appl. Sci. 2018, 8, 1754. [Google Scholar] [CrossRef]
- He, Z.; Xia, K.; Niu, W.; Aslam, N.; Hou, J. Semi supervised SVM Based on Cuckoo Search Algorithm and Its Application. Mathe. Probl. Eng. 2018, 2018, 8243764. [Google Scholar]
- Dai, S.; Niu, D.; Han, Y. Forecasting of Power Grid Investment in China Based on Support Vector Machine Optimized by Differential Evolution Algorithm and Grey Wolf Optimization Algorithm. Appl. Sci. 2018, 8, 636. [Google Scholar] [CrossRef]
- Meng, X.; Liu, Y.; Gao, X.; Zhang, H. A New Bio-Inspired Algorithm: Chicken Swarm Optimization; Advances in Swarm Intelligence; Springer: Berlin, Germany, 2014; pp. 86–94. [Google Scholar]
- Wu, D.; Kong, F.; Gao, W.; Shen, Y.; Ji, Z. Improved Chicken Swarm Optimization. In Proceedings of the 5th Annual IEEE International Conference on Cyber Technology in Automation, Shenyang, China, 8–12 June 2015. [Google Scholar]
- Wu, Z.; Yu, D.; Kang, X. Application of improved chicken swarm optimization for MPPT in photovoltaic system. Optim. Control Appl. Meth. 2018, 39, 1029–1042. [Google Scholar] [CrossRef]
- Liang, J.; Wang, L.; Ma, M.; Zhang, J. A fast SAR image segmentation method based on improved chicken swarm optimization algorithm. Multimed. Tools Appl. 2018, 77, 31787–31805. [Google Scholar] [CrossRef]
- VAPNIK, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Cherkassky, V. The Nature of Statistical Learning Theory. IEEE Trans. Neural Netw. 1997, 8, 1564. [Google Scholar] [CrossRef] [PubMed]
- Smola, A.J.; Scholkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Standard Concentration of Methane/ppm | Detectable Concentration/ppm | Average Concentrations/ppm | Relative Error | ||
|---|---|---|---|---|---|
| 1 | 2 | 3 | |||
| 2000 | 2100 | 2010 | 2150 | 2090 | 0.0450 |
| 4000 | 3900 | 4070 | 3870 | 3970 | −0.0075 |
| 6000 | 6110 | 6030 | 5900 | 6010 | 0.0017 |
| 8000 | 8060 | 8270 | 8100 | 8140 | 0.0175 |
| 10,000 | 10,110 | 9770 | 9960 | 9950 | −0.0050 |
| 12,000 | 12,120 | 11,970 | 12,010 | 12,030 | 0.0025 |
| 14,000 | 14,240 | 14,170 | 14,050 | 14,150 | 0.0107 |
| 16,000 | 16,300 | 16,110 | 16,250 | 16,220 | 0.0138 |
| 18,000 | 17,950 | 17,870 | 18,130 | 17,980 | −0.0011 |
| 20,000 | 19,860 | 19,930 | 20,020 | 19,940 | −0.0030 |
| The Algorithms | Parameters |
|---|---|
| GA 1 | C ∈ [0.1, 1000], g ∈ [0.001, 100] |
| PSO 2 | C1 = 1.5, C2 = 1.7, w = 0.7, C ∈ [0.1, 1000], g ∈ [0.001, 100] |
| CSO 3 | RP = 0.15 * pop, HP = 0.7 * pop, MP = 0.5 * HP, CP = pop − RP − HP − MP, G = 10, C ∈ [0.1, 1000], g ∈ [0.001, 100] |
| ICSO 4 | RP = 0.15 * pop, HP = 0.7 * pop, MP = 0.5 * HP, CP = pop − RP − HP − MP, G = 10, C ∈ [0.1, 1000], g ∈ [0.001, 100] |
| Samples Number | Ture Value/ppm | ICSO-SVM/ppm | CSO-SVM/ppm | GA-SVM/ppm | PSO-SVM/ppm |
|---|---|---|---|---|---|
| 1 | 2000 | 2300 | 2300 | 2600 | 2800 |
| 2 | 7000 | 6900 | 7200 | 7400 | 7700 |
| 3 | 11,000 | 11,300 | 11,500 | 11,800 | 11,800 |
| 4 | 14,000 | 14,100 | 14,200 | 13,700 | 13,600 |
| 5 | 19,000 | 18,800 | 18,900 | 18,600 | 18,700 |
| 6 | 26,000 | 26,200 | 26,200 | 26,400 | 26,700 |
| 7 | 31,000 | 31,200 | 31,300 | 30,700 | 30,700 |
| 8 | 38,000 | 37,900 | 37,900 | 38,300 | 38,200 |
| Models | ICSO-SVM | CSO-SVM | GA-SVM | PSO-SVM |
|---|---|---|---|---|
| Average recovery rate/% | 101.23 | 103.15 | 113.58 | 125.61 |
| Average mean squared error | 1.12 × 10−5 | 1.23 × 10−5 | 3.56 × 10−5 | 3.22 × 10−5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Wang, S.; Kong, D.; Liu, S. Methane Detection Based on Improved Chicken Algorithm Optimization Support Vector Machine. Appl. Sci. 2019, 9, 1761. https://doi.org/10.3390/app9091761
Wang Z, Wang S, Kong D, Liu S. Methane Detection Based on Improved Chicken Algorithm Optimization Support Vector Machine. Applied Sciences. 2019; 9(9):1761. https://doi.org/10.3390/app9091761
Chicago/Turabian StyleWang, Zhifang, Shutao Wang, Deming Kong, and Shiyu Liu. 2019. "Methane Detection Based on Improved Chicken Algorithm Optimization Support Vector Machine" Applied Sciences 9, no. 9: 1761. https://doi.org/10.3390/app9091761