Fusing Appearance and Prior Cues for Road Detection


Abstract
:
1. Introduction
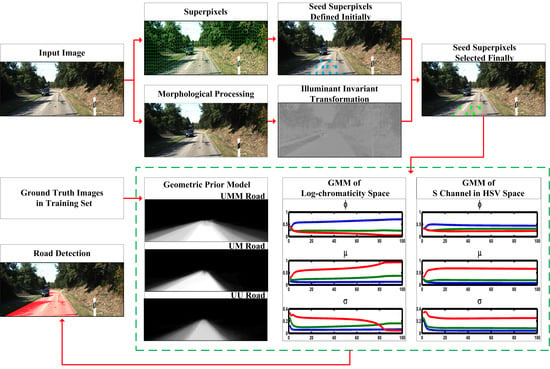
2. Proposed Algorithm
2.1. Preprocessing of the Input Image
2.1.1. Superpixels
2.1.2. Lane Markings Removal by Morphological Processing
2.1.3. Illuminant Invariant Transformation
2.2. Estimate of Appearance Model
2.2.1. Seed Superpixels Selection
2.2.2. Gaussian Mixture Model
2.3. Construction of the Geometric Prior Model
2.4. Fusion of Appearance and Prior Cues
3. Experimental Results and Discussion
3.1. Dataset and Platform of the Experiment
3.2. Experimental Results
3.2.1. Evaluation of Variant Combinations of Color Channels
3.2.2. Optimization of the Threshold
3.2.3. Qualitative Evaluation
3.2.4. Quantitative Evaluation
3.3. Discussion
4. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hillel, A.B.; Lerner, R.; Dan, L.; Raz, G. Recent progress in road and lane detection: a survey. Mach. Vis. Appl. 2014, 25, 727–745. [Google Scholar] [CrossRef]
- Janai, J.; Güney, F.; Behl, A.; Geiger, A. Computer Vision for Autonomous Vehicles: Problems, Datasets and State-of-the-Art. arXiv, 2017; arXiv:1704.05519. [Google Scholar]
- Yasrab, R.; Gu, N.; Zhang, X. An Encoder-Decoder Based Convolution Neural Network (CNN) for Future Advanced Driver Assistance System (ADAS). Appl. Sci. 2017, 7, 312. [Google Scholar] [CrossRef]
- Chacra, D.A.; Zelek, J. Road Segmentation in Street View Images Using Texture Information. In Proceedings of the Computer & Robot Vision, Victoria, BC, Canada, 1–3 June 2016. [Google Scholar]
- Zhou, S.; Gong, J.; Xiong, G.; Chen, H.; Iagnemma, K. Road detection using support vector machine based on online learning and evaluation. In Proceedings of the Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010. [Google Scholar]
- Xiao, L.; Dai, B.; Liu, D.; Zhao, D.; Wu, T. Monocular road detection using structured random forest. Int. J. Adv. Robot. Syst. 2016, 13, 101. [Google Scholar] [CrossRef]
- Alvarez, J.M.; Gevers, T.; Lecun, Y.; Lopez, A.M. Road Scene Segmentation from a Single Image. Proc. Eur. Conf. Comput. Vis. 2012. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 39, 640–651. [Google Scholar]
- Gao, J.; Qi, W.; Yuan, Y. Embedding structured contour and location prior in siamesed fully convolutional networks for road detection. Proc. IEEE Int. Conf. Robot. Autom. 2018, 19, 230–241. [Google Scholar]
- Zhe, C.; Chen, Z. RBNet: A Deep Neural Network for Unified Road and Road Boundary Detection. Proc. Int. Conf. Neural Inf. Process. 2017. [Google Scholar] [CrossRef]
- Oliveira, G.L.; Burgard, W.; Brox, T. Efficient deep models for monocular road segmentation. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4885–4891. [Google Scholar]
- Mendes, C.C.T.; Frémont, V.; Wolf, D.F. Exploiting fully convolutional neural networks for fast road detection. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–20 May 2016; pp. 3174–3179. [Google Scholar]
- Teichmann, M.; Weber, M.; Zoellner, M.; Cipolla, R.; Urtasun, R. MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks; Springer: Cham, Switzerland, 2013. [Google Scholar]
- Kong, H.; Audibert, J.Y.; Ponce, J. Vanishing point detection for road detection. Comput. Vis. Pattern Recog. 2013, 2009, 96–103. [Google Scholar]
- Hui, K.; Jean-Yves, A.; Jean, P. General road detection from a single image. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2010, 19, 2211–2220. [Google Scholar]
- Helala, M.A.; Pu, K.Q.; Qureshi, F.Z. Road Boundary Detection in Challenging Scenarios. In Proceedings of the IEEE Ninth International Conference on Advanced Video & Signal-based Surveillance, Taipei, Taiwan, 18–21 September 2019. [Google Scholar]
- Nan, Z.; Wei, P.; Xu, L.; Zheng, N. Efficient Lane Boundary Detection with Spatial-Temporal Knowledge Filtering. Sensors 2016, 16, 1276. [Google Scholar] [CrossRef] [PubMed]
- Geng, Z.; Zheng, N.; Chao, C.; Yan, Y.; Yuan, Z. An efficient road detection method in noisy urban environment. In Proceedings of the Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009. [Google Scholar]
- Broggi, A.; Bertè, S. Vision-Based Road Detection in Automotive Systems: A Real-Time Expectation-Driven Approach. J. Artif. Intell. Res. 1995, 3, 325–348. [Google Scholar] [CrossRef]
- He, Y.; Wang, H.; Zhang, B. Color-based road detection in urban traffic scenes. IEEE Trans. Intell. Transp. Syst. 2004, 5, 309–318. [Google Scholar] [CrossRef]
- Tan, C.; Hong, T.; Chang, T.; Shneier, M. Color model-based real-time learning for road following. In Proceedings of the IEEE Intelligent Transportation Systems Conference, Toronto, ON, Canada, 17–20 September 2006. [Google Scholar]
- Zhang, H.; Hernandez, D.; Su, Z.; Su, B. A Low Cost Vision-Based Road-Following System for Mobile Robots. Appl. Sci. 2018, 8, 1635. [Google Scholar] [CrossRef]
- Wang, B.; Fremont, V.; Rodriguez, S.A. Color-based road detection and its evaluation on the KITTI road benchmark. In Proceedings of the Intelligent Vehicles Symposium, Dearborn, MI, USA, 3–5 October 2000. [Google Scholar]
- Alvarez, J.M.Á.; Lopez, A.M. Road Detection Based on Illuminant Invariance. IEEE Trans. Intell. Transp. Syst. 2011, 12, 184–193. [Google Scholar] [CrossRef]
- Scharwachter, T.; Franke, U. Low-level fusion of color, texture and depth for robust road scene understanding. In Proceedings of the Intelligent Vehicles Symposium, Seoul, Korea, 29 June–1 July 2015. [Google Scholar]
- Vitor, G.B.; Lima, D.A.; Victorino, A.C.; Ferreira, J.V. A 2D/3D Vision Based Approach Applied to Road Detection in Urban Environments. In Proceedings of the Intelligent Vehicles Symposium, Gold Coast, Australia, 23–26 June 2013. [Google Scholar]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR-Camera Fusion for Road Detection Using Fully Convolutional Neural Networks. Robot. Auton. Syst. 2018, 111, 125–131. [Google Scholar] [CrossRef]
- Liang, C.; Jian, Y.; Hui, K. Lidar-histogram for fast road and obstacle detection. In Proceedings of the IEEE International Conference on Robotics & Automation, Singapore, 29 May–3 June 2017. [Google Scholar]
- Laddha, A.; Kocamaz, M.K.; Navarro-Serment, L.E.; Hebert, M. Map-supervised road detection. In Proceedings of the Intelligent Vehicles Symposium, Gothenburg, Sweden, 19–22 June 2016. [Google Scholar]
- Zhao, W.; Zhang, H.; Yan, Y.; Fu, Y.; Wang, H. A Semantic Segmentation Algorithm Using FCN with Combination of BSLIC. Appl. Sci. 2018, 8, 500. [Google Scholar] [CrossRef]
- Zhao, W.; Fu, Y.; Wei, X.; Wang, H. An Improved Image Semantic Segmentation Method Based on Superpixels and Conditional Random Fields. Appl. Sci. 2018, 8, 837. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gonzalez, R.C.; Wintz, P. Digital Image Processing; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2007. [Google Scholar]
- Alvarez, J.M.; Gevers, T.; Lopez, A.M. Evaluating Color Representations for On-Line Road Detection. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Fritsch, J.; Kuhnl, T.; Geiger, A. A new performance measure and evaluation benchmark for road detection algorithms. In Proceedings of the International IEEE Conference on Intelligent Transportation Systems, The Hague, The Netherlands, 6–9 October 2013. [Google Scholar]
- Ren, C.Y.; Prisacariu, V.A.; Reid, I.D. gSLICr: SLIC superpixels at over 250 Hz. arXiv, 2015; arXiv:1509.04232. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PRE (%) | REC (%) | MaxF (%) | FPR (%) | FNR (%) |
|---|---|---|---|---|---|
| SRF [6] | 89.35 | 92.23 | 90.77 | 12.08 | 7.77 |
| CN [7] | 82.85 | 89.86 | 86.21 | 20.45 | 10.14 |
| FCN–LC [12] | 94.05 | 94.13 | 94.09 | 6.55 | 5.87 |
| BM [24] | 83.43 | 96.30 | 89.41 | 21.02 | 3.70 |
| ANN [27] | 69.95 | 96.05 | 80.95 | 45.35 | 3.95 |
| LidarHisto [29] | 95.39 | 91.34 | 93.32 | 4.85 | 8.66 |
| Our method | 93.46 | 95.33 | 94.39 | 1.76 | 4.67 |
| Method | PRE (%) | REC (%) | MaxF (%) | FPR (%) | FNR (%) |
|---|---|---|---|---|---|
| SRF [6] | 75.53 | 77.35 | 76.43 | 11.42 | 22.65 |
| CN [7] | 69.18 | 78.83 | 73.69 | 16.00 | 21.17 |
| FCN–LC [12] | 89.35 | 89.37 | 89.36 | 4.85 | 10.63 |
| BM [24] | 69.53 | 91.19 | 78.90 | 18.21 | 8.81 |
| ANN [27] | 50.21 | 83.91 | 62.83 | 37.91 | 16.09 |
| LidarHisto [29] | 91.28 | 88.49 | 89.87 | 3.85 | 11.51 |
| Our method | 89.93 | 93.46 | 91.66 | 2.79 | 6.54 |
| Method | PRE (%) | REC (%) | MaxF (%) | FPR (%) | FNR (%) |
|---|---|---|---|---|---|
| SRF [6] | 71.47 | 81.31 | 76.07 | 10.57 | 18.69 |
| CN [7] | 71.96 | 72.54 | 72.25 | 9.21 | 27.46 |
| FCN–LC [12] | 86.65 | 85.89 | 86.27 | 4.31 | 14.11 |
| BM [24] | 70.87 | 87.80 | 78.43 | 11.76 | 12.20 |
| ANN [27] | 39.28 | 86.69 | 54.07 | 43.67 | 13.31 |
| LidarHisto [29] | 90.71 | 82.75 | 86.55 | 2.76 | 17.25 |
| Our method | 91.66 | 89.93 | 90.79 | 2.55 | 10.07 |
| Method | PRE (%) | REC (%) | MaxF (%) | FPR (%) | FNR (%) |
|---|---|---|---|---|---|
| SRF [6] | 80.60 | 84.36 | 82.44 | 11.18 | 15.64 |
| CN [7] | 76.64 | 81.55 | 79.02 | 13.69 | 18.45 |
| FCN–LC [12] | 90.87 | 90.72 | 90.79 | 5.02 | 9.28 |
| BM [24] | 75.90 | 92.72 | 83.47 | 16.22 | 7.28 |
| ANN [27] | 54.19 | 90.17 | 67.70 | 41.98 | 9.83 |
| LidarHisto [29] | 93.06 | 88.41 | 90.67 | 3.63 | 11.59 |
| Our method | 92.04 | 92.98 | 92.51 | 2.46 | 7.02 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, F.; He, X.; Wei, Z.; Zhang, L.; He, J.; Mu, Z.; Lv, Y. Fusing Appearance and Prior Cues for Road Detection. Appl. Sci. 2019, 9, 996. https://doi.org/10.3390/app9050996
Ren F, He X, Wei Z, Zhang L, He J, Mu Z, Lv Y. Fusing Appearance and Prior Cues for Road Detection. Applied Sciences. 2019; 9(5):996. https://doi.org/10.3390/app9050996
Chicago/Turabian StyleRen, Fenglei, Xin He, Zhonghui Wei, Lei Zhang, Jiawei He, Zhiya Mu, and You Lv. 2019. "Fusing Appearance and Prior Cues for Road Detection" Applied Sciences 9, no. 5: 996. https://doi.org/10.3390/app9050996