Adaptive Network Based Fuzzy Inference System with Meta-Heuristic Optimizations for International Roughness Index Prediction


 ,
,  , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Case Study and Database
2.2. Methods Used
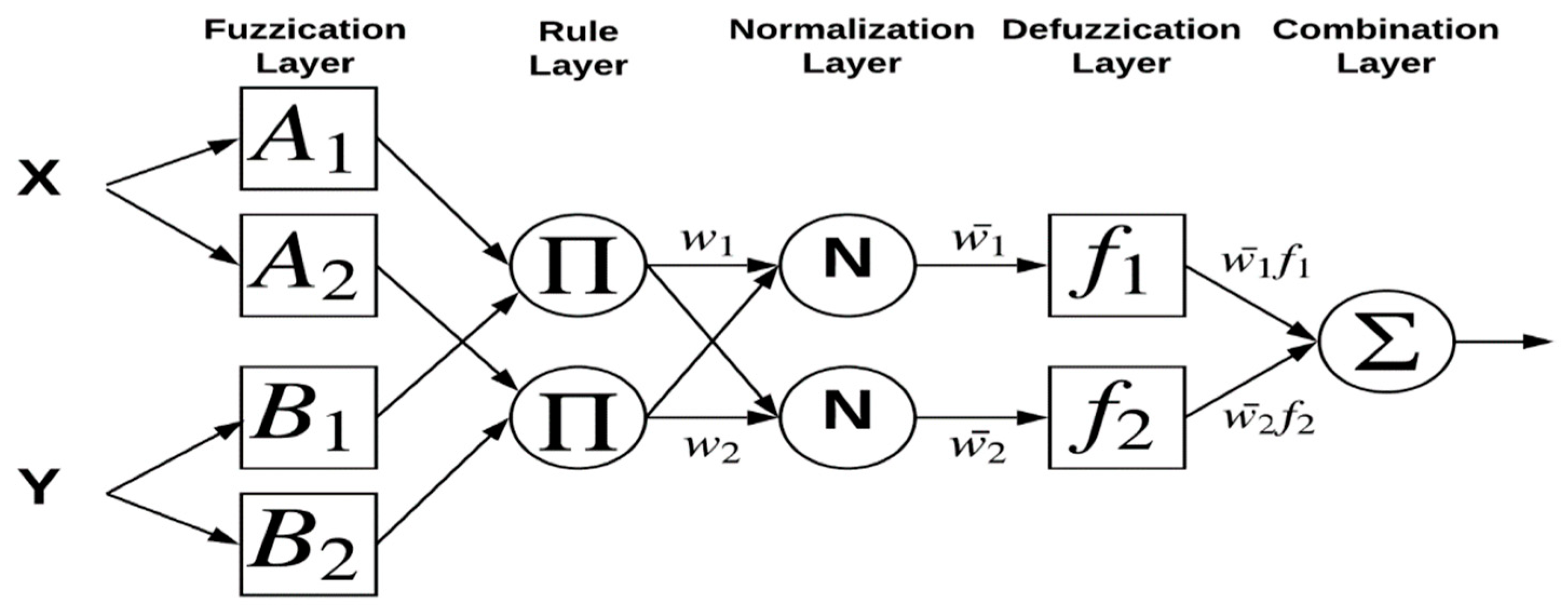
2.2.1. Adaptive Neural Fuzzy Inference System (ANFIS)
2.2.2. Particle Swarm Optimization (PSO)
2.2.3. Genetic Algorithm (GA)
- Step 1:
- Population Initiation: Generated randomly a population of n individuals (where n is the solution to the problem).
- Step 2:
- Estimated the adaptation value of each individual.
- Step 3:
- Stop Condition: Checked the condition to terminate the algorithm.
- Step 4:
- Selection: Selected two parents from the old population according to their adaptation.
- Step 5:
- Cross exchange: With a selected probability, there was a new one which was created by the crossing exchange of two parents.
- Step 6:
- Mutation: With a selected mutation probability, the new individual was mutated.
- Step 7:
- Select the result: If the stop condition was satisfied, the algorithm terminated and chose the best solution in the current population.
2.2.4. Firefly Algorithm (FA)
- (1)
- The fireflies were unisex so that a firefly was attracted to all other fireflies regardless of their sex.
- (2)
- Attractiveness of a firefly was proportional to its brightness. The firefly moved randomly as there was no brighter firefly nearby.
- (3)
- Brightness of a firefly was determined by the value of its objective function.
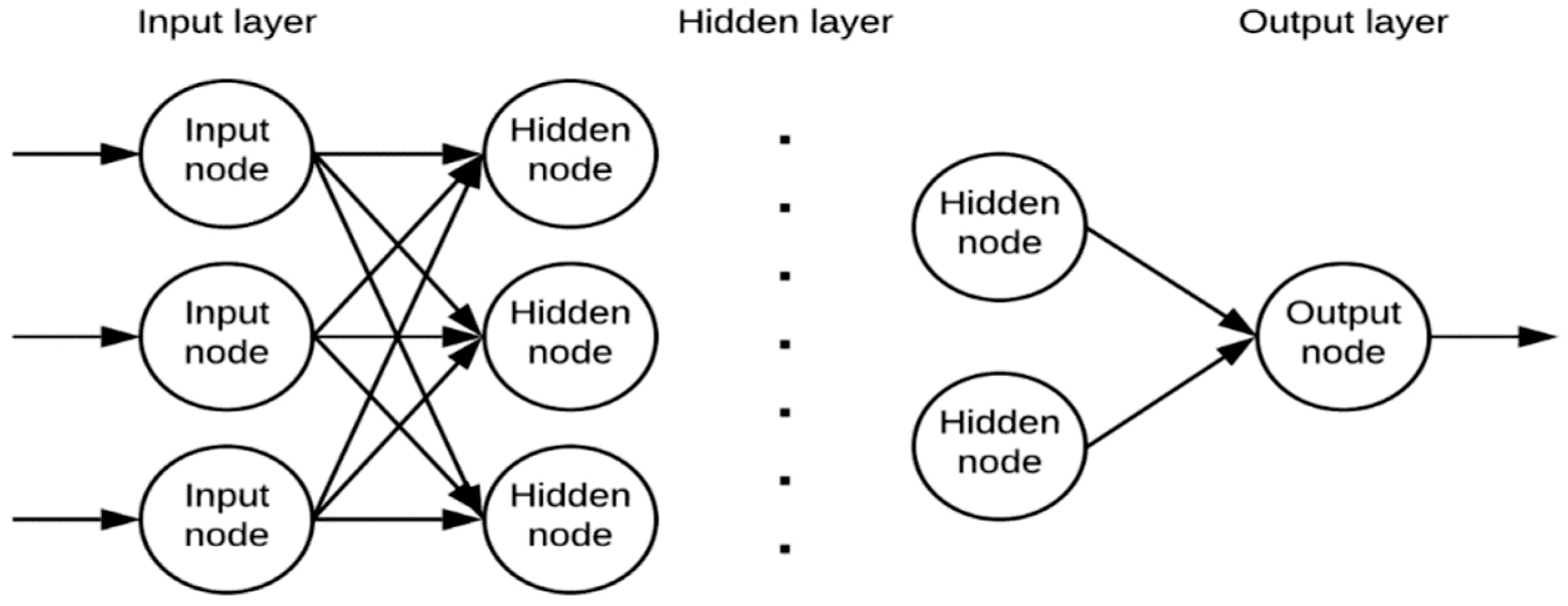
2.2.5. Artificial Neural Network (ANN)
2.2.6. Accuracy Validation
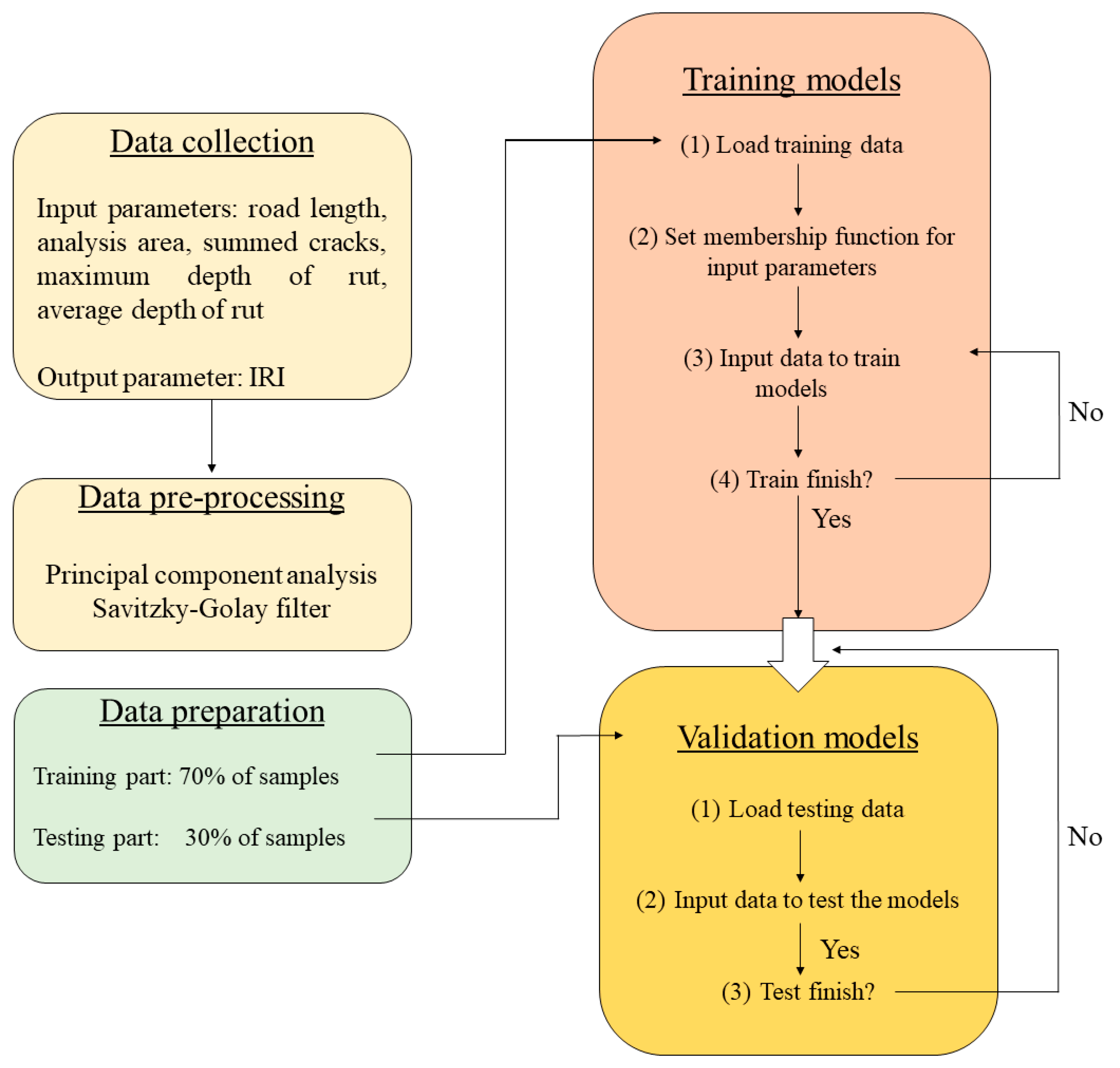
2.3. Methodology Framework
- (i)
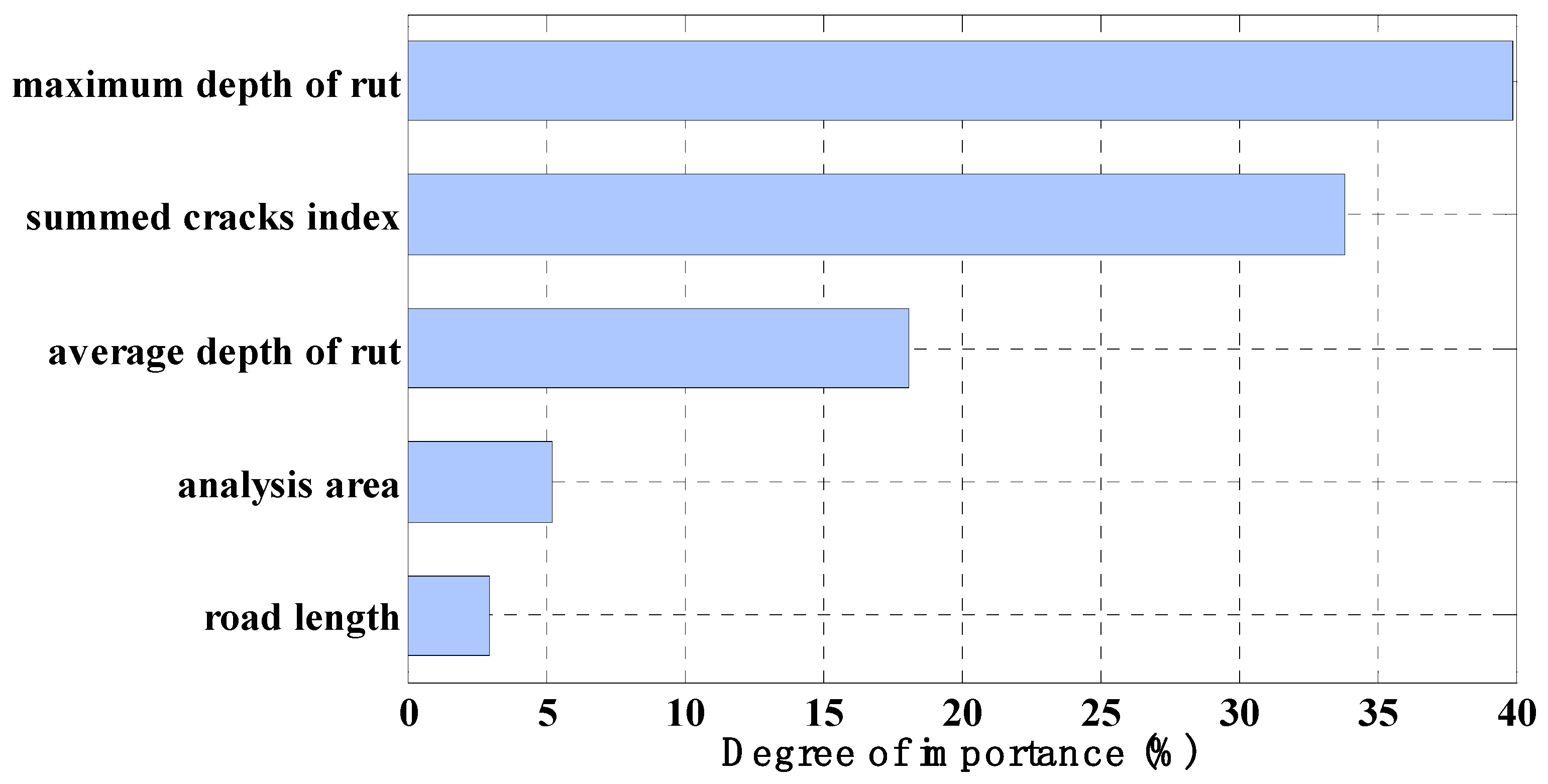
- Data collection: in this step, the data generated from laboratory experiments were collected and summarized into two groups whereas the first groups contains all input parameters such as: road length, analysis area, summed cracks, maximum depth of rut, average depth of rut and the second one encloses the output parameter (IRI).
- (ii)
- Data pre-processing: in this step, PCA and the Savitzky–Golay filter were used to reduce the dimensions data and reduce extreme values in the distribution of data.
- (iii)
- Data preparation: in this study, the holdout validation method was used for training and validating the models as it is a popular and effective method for generating the datasets for training and testing the models [24,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61], and thus the collected data were divided into two parts. The first part included 70% data which was used to train the models, whereas the second part contained 30%, the remaining data and this was used to validate the models as the ratio 70/30 for dividing the training and testing dataset was a common ratio used in applying the ML models [29,62,63,64,65,66,67,68,69,70,71].
- (iv)
- Training the models: the models were created using a 70% training dataset. PSOANFIS was created by combining PSO and ANFIS, GANFIS was created by combining GA and ANFIS, FAANFIS was created by combining FA and ANFIS. Out of these, PSO, GA, FA were used to optimize the consequence, antecedent parameters for giving the best ANFIS. An artificial neural network (ANN) was created using sigmoid algorithm.
- (v)
- Validation the models: after optimization of consequence, antecedent parameters, as well as training models, validation of the models were carried out using testing dataset via two methods namely RMSE and R.
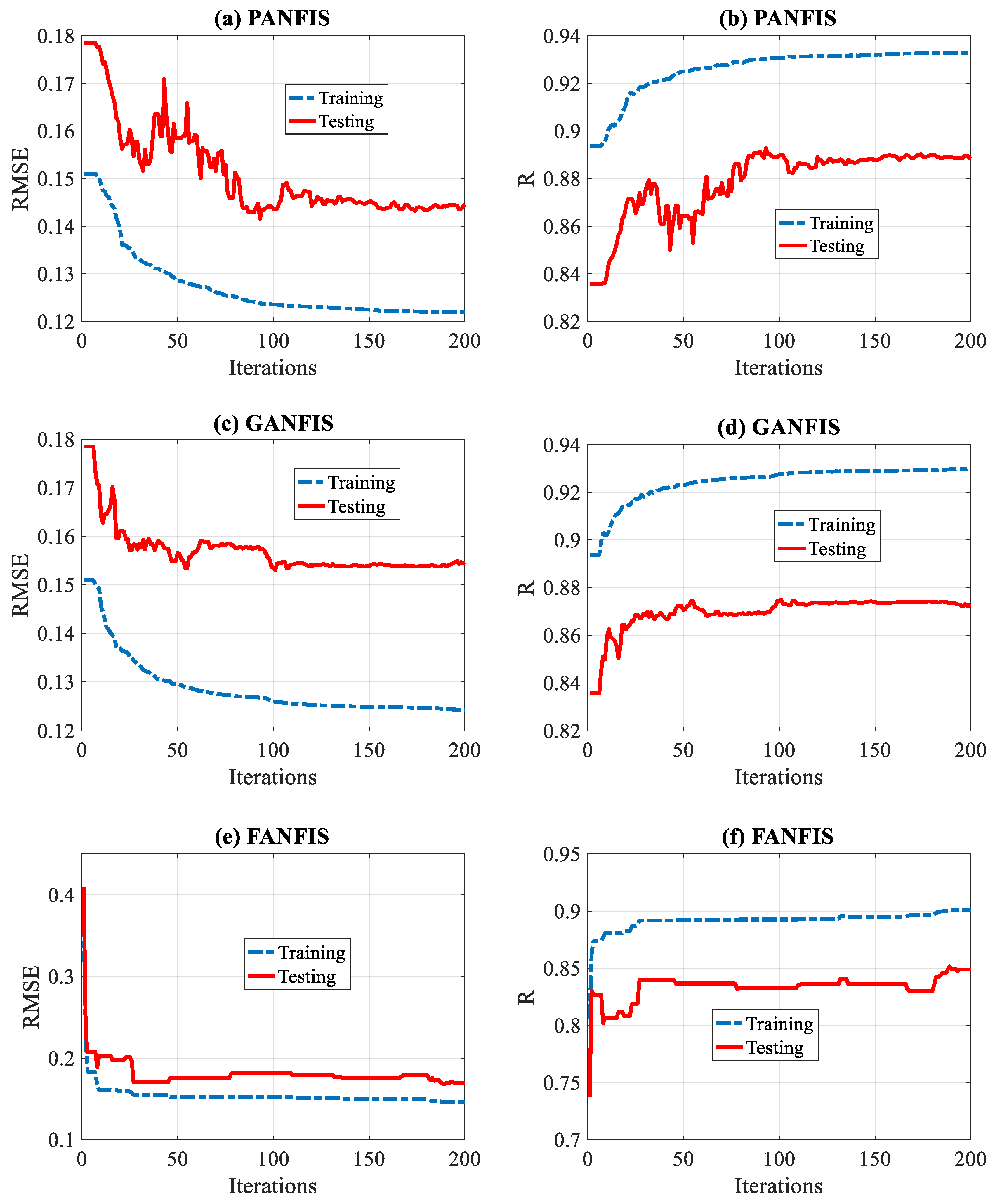
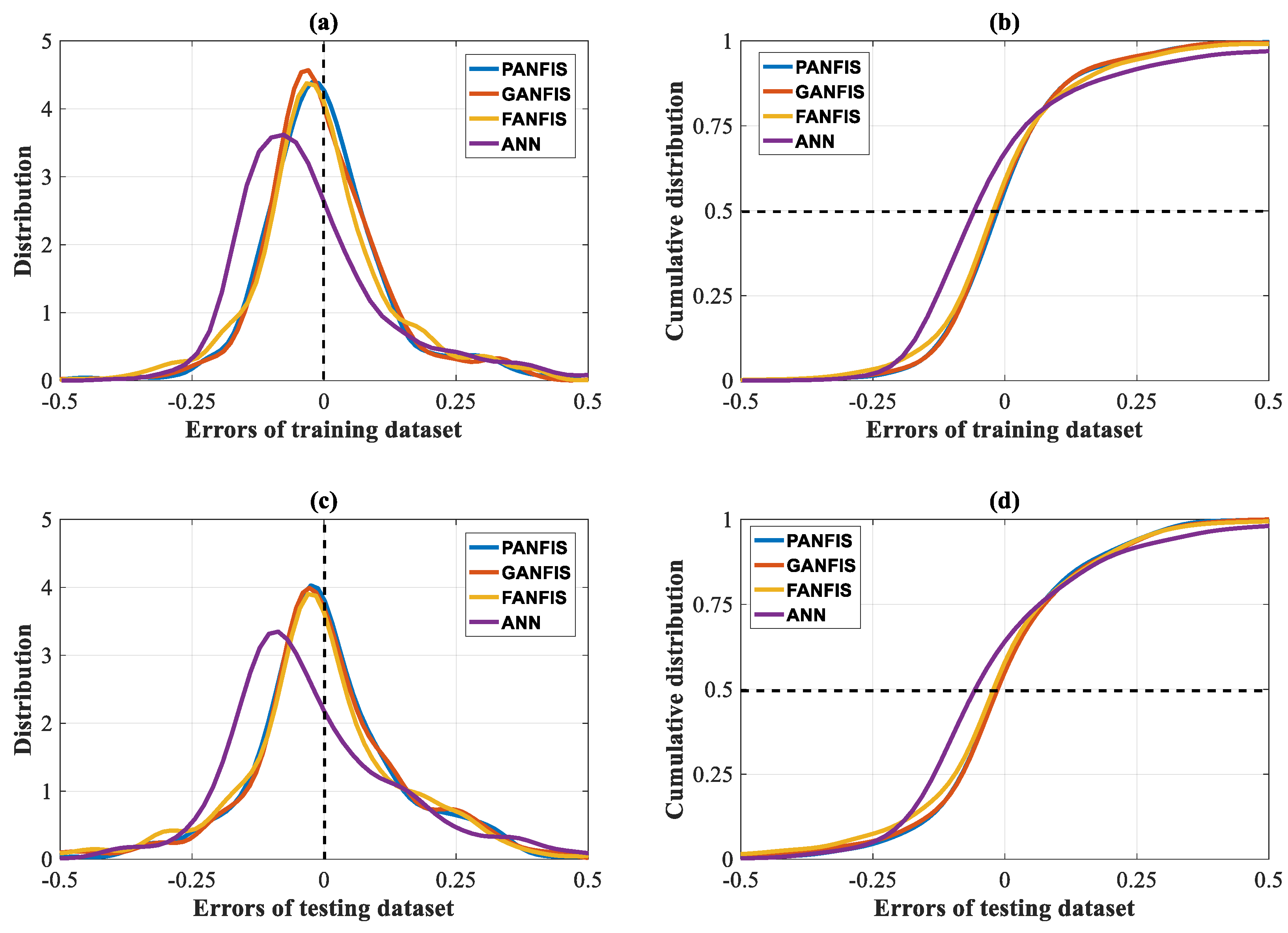
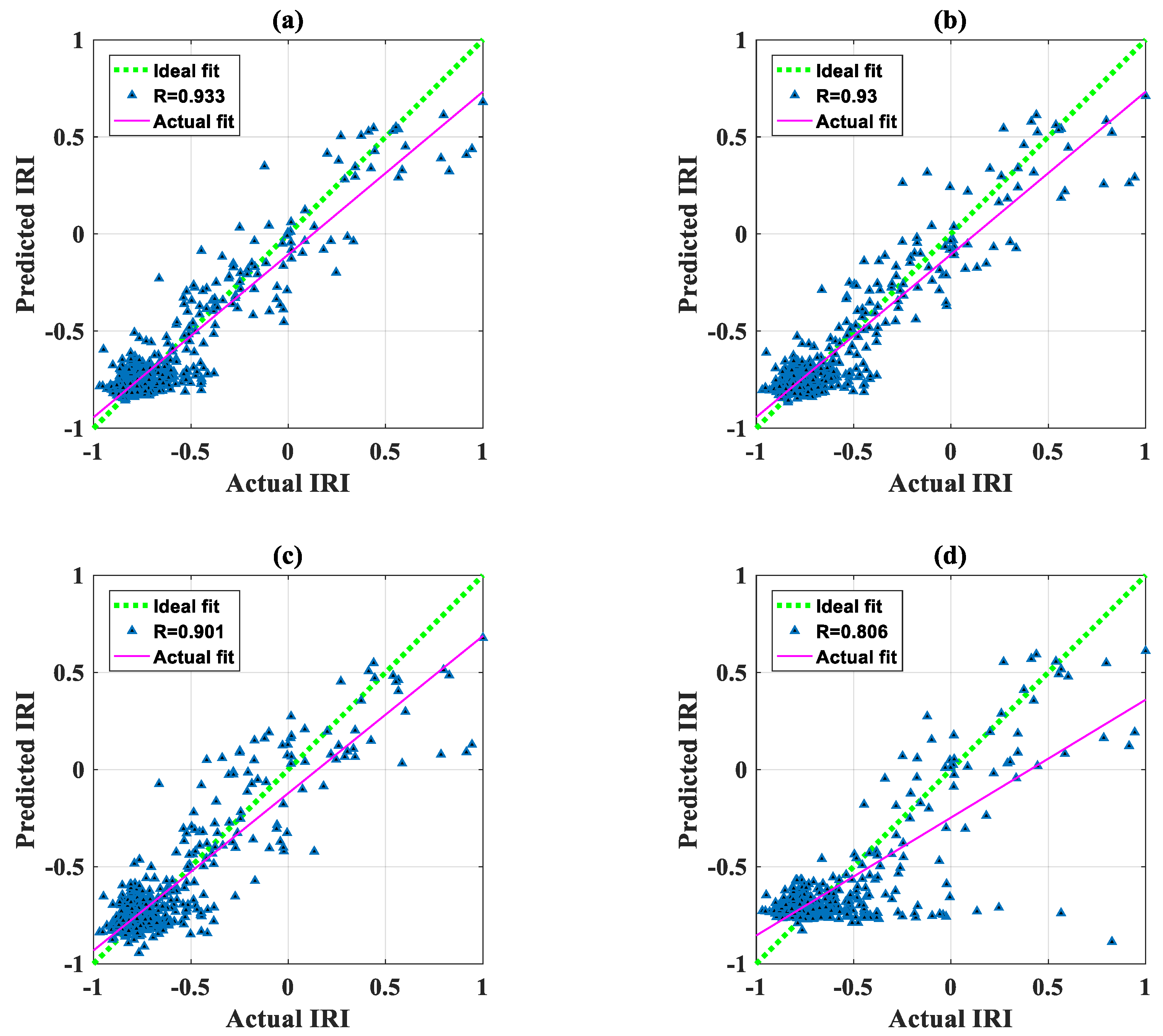
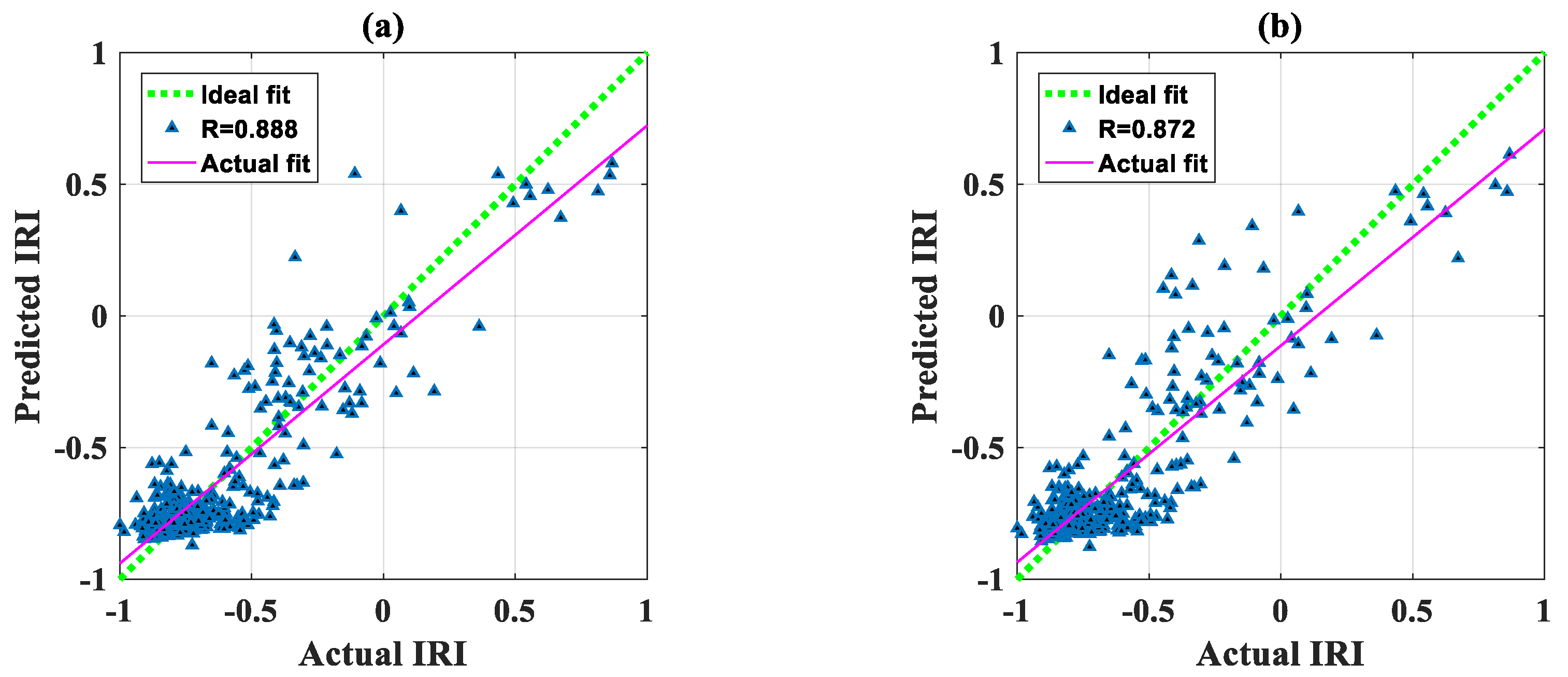
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Arhin, S.A.; Williams, L.N.; Ribbiso, A.; Anderson, M.F. Predicting pavement condition index using international roughness index in a dense urban area. J. Civ. Eng. Res. 2015, 5, 10–17. [Google Scholar]
- Li, J.; Zhang, Z.; Wang, W. International roughness index and a new solution for its calculation. J. Transp. Eng. Part B Pavements 2018, 144, 06018002. [Google Scholar] [CrossRef]
- Hossain, M.; Gopisetti, L.; Miah, M. International Roughness Index Prediction of Flexible Pavements Using Neural Networks. J. Transp. Eng. Part B Pavements 2018, 145, 04018058. [Google Scholar] [CrossRef]
- Ziari, H.; Sobhani, J.; Ayoubinejad, J.; Hartmann, T. Prediction of IRI in short and long terms for flexible pavements: ANN and GMDH methods. Int. J. Pavement Eng. 2016, 17, 776–788. [Google Scholar] [CrossRef]
- Khalifeh, V.; Golroo, A.; Ovaici, K. Application of an Inexpensive Sensor in Calculating the International Roughness Index. J. Comput. Civ. Eng. 2018, 32, 04018022. [Google Scholar] [CrossRef]
- Chen, C.-T.; Hung, C.-T.; Chou, C.-C.; Chiang, Z.; Lin, J.-D. The predicted model of international roughness index for drainage asphalt pavement. In Proceedings of the International Conference on Intelligent Computing, Shanghai, China, 15–18 September 2008; pp. 937–945. [Google Scholar]
- Lin, J.-D.; Yau, J.-T.; Hsiao, L.-H. Correlation analysis between international roughness index (IRI) and pavement distress by neural network. In Proceedings of the 82th Annual Meeting of the Transportation Research Board, Washington, DC, USA, 12–16 January 2003; pp. 12–16. [Google Scholar]
- Yousefzadeh, M.; Azadi, S.; Soltani, A. Road profile estimation using neural network algorithm. J. Mech. Sci. Technol. 2010, 24, 743–754. [Google Scholar] [CrossRef]
- Mactutis, J.A.; Alavi, S.H.; Ott, W.C. Investigation of relationship between roughness and pavement surface distress based on WesTrack project. Transp. Res. Rec. 2000, 1699, 107–113. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Press, W.H.; Teukolsky, S.A. Savitzky-Golay smoothing filters. Comput. Phys. 1990, 4, 669–672. [Google Scholar] [CrossRef]
- Le, L.M.; Ly, H.-B.; Pham, B.T.; Le, V.M.; Pham, T.A.; Nguyen, D.-H.; Tran, X.-T.; Le, T.-T. Hybrid Artificial Intelligence Approaches for Predicting Buckling Damage of Steel Columns under Axial Compression. Materials 2019, 12, 1670. [Google Scholar] [CrossRef]
- Ly, H.-B.; Le, L.M.; Duong, H.T.; Nguyen, T.C.; Pham, T.A.; Le, T.-T.; Le, V.M.; Nguyen-Ngoc, L.; Pham, B.T. Hybrid Artificial Intelligence Approaches for Predicting Critical Buckling Load of Structural Members under Compression Considering the Influence of Initial Geometric Imperfections. Appl. Sci. 2019, 9, 2258. [Google Scholar] [CrossRef]
- Termeh, S.V.R.; Khosravi, K.; Sartaj, M.; Keesstra, S.D.; Tsai, F.T.-C.; Dijksma, R.; Pham, B.T. Optimization of an adaptive neuro-fuzzy inference system for groundwater potential mapping. Hydrogeol. J. 2019, 27, 2511–2534. [Google Scholar] [CrossRef]
- Manogaran, G.; Varatharajan, R.; Priyan, M. Hybrid recommendation system for heart disease diagnosis based on multiple kernel learning with adaptive neuro-fuzzy inference system. Multimed. Tools Appl. 2018, 77, 4379–4399. [Google Scholar] [CrossRef]
- Marini, F.; Walczak, B. Particle swarm optimization (PSO). A tutorial. Chemom. Intell. Lab. Syst. 2015, 149, 153–165. [Google Scholar] [CrossRef]
- Eberhart, R.; Kennedy, J. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019; pp. 1942–1948. [Google Scholar]
- Du, K.-L.; Swamy, M. Particle swarm optimization. In Search and Optimization by Metaheuristics; Springer: Basel, Switzerland, 2016; pp. 153–173. [Google Scholar]
- Chatterjee, S.; Sarkar, S.; Hore, S.; Dey, N.; Ashour, A.S.; Balas, V.E. Particle swarm optimization trained neural network for structural failure prediction of multistoried RC buildings. Neural Comput. Appl. 2017, 28, 2005–2016. [Google Scholar] [CrossRef]
- Juang, C.-F. A hybrid of genetic algorithm and particle swarm optimization for recurrent network design. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 2004, 34, 997–1006. [Google Scholar] [CrossRef]
- Gai, K.; Qiu, M.; Zhao, H. Cost-aware multimedia data allocation for heterogeneous memory using genetic algorithm in cloud computing. IEEE Trans. Cloud Comput. 2016. [Google Scholar] [CrossRef]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, UK, 1998. [Google Scholar]
- Yang, X. Firefly Algorithm, Nature Inspired Metaheuristic Algorithms, 2010; Luniver Press: Frome, UK, 2010. [Google Scholar]
- Bayat, M.; Ghorbanpour, M.; Zare, R.; Jaafari, A.; Pham, B.T. Application of artificial neural networks for predicting tree survival and mortality in the Hyrcanian forest of Iran. Comput. Electron. Agric. 2019, 164, 104929. [Google Scholar] [CrossRef]
- Hassoun, M.H. Fundamentals of Artificial Neural Networks; MIT Press: Cambridge, UK, 1995. [Google Scholar]
- Basheer, I.A.; Hajmeer, M. Artificial neural networks: Fundamentals, computing, design, and application. J. Microbiol. Methods 2000, 43, 3–31. [Google Scholar] [CrossRef]
- Apostolopoulou, M.; Armaghani, D.J.; Bakolas, A.; Douvika, M.G.; Moropoulou, A.; Asteris, P.G. Compressive strength of natural hydraulic lime mortars using soft computing techniques. Procedia Struct. Integr. 2019, 17, 914–923. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Hatzigeorgiou, G.D.; Karamani, C.; Skentou, A.; Zoumpoulaki, I.; Asteris, P.G. Soft computing-based techniques for concrete beams shear strength. Procedia Struct. Integr. 2019, 17, 924–933. [Google Scholar] [CrossRef]
- Khozani, Z.S.; Khosravi, K.; Pham, B.T.; Kløve, B.; Mohtar, W.; Melini, W.H.; Yaseen, Z.M. Determination of compound channel apparent shear stress: Application of novel data mining models. J. Hydroinform. 2019, 21, 798–811. [Google Scholar] [CrossRef]
- Pham, B.T.; Nguyen, M.D.; Van Dao, D.; Prakash, I.; Ly, H.-B.; Le, T.-T.; Ho, L.S.; Nguyen, K.T.; Ngo, T.Q.; Hoang, V. Development of artificial intelligence models for the prediction of Compression Coefficient of soil: An application of Monte Carlo sensitivity analysis. Sci. Total Environ. 2019, 679, 172–184. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Asteris, P.G.; Jahed Armaghani, D.; Gordan, B.; Pham, B.T.J.A.S. Assessing dynamic conditions of the retaining wall: developing two hybrid intelligent models. Appl. Sci. 2019, 9, 1042. [Google Scholar] [CrossRef]
- Nguyen, H.-L.; Le, T.-H.; Pham, C.-T.; Le, T.-T.; Ho, L.S.; Le, V.M.; Pham, B.T.; Ly, H.-B. Development of Hybrid Artificial Intelligence Approaches and a Support Vector Machine Algorithm for Predicting the Marshall Parameters of Stone Matrix Asphalt. Appl. Sci. 2019, 9, 3172. [Google Scholar] [CrossRef]
- Ly, H.-B.; Desceliers, C.; Le, L.M.; Le, T.-T.; Pham, B.T.; Nguyen-Ngoc, L.; Doan, V.T.; Le, M. Quantification of Uncertainties on the Critical Buckling Load of Columns under Axial Compression with Uncertain Random Materials. Materials 2019, 12, 1828. [Google Scholar] [CrossRef]
- Nakagawa, S.; Johnson, P.C.; Schielzeth, H. The coefficient of determination R2 and intra-class correlation coefficient from generalized linear mixed-effects models revisited and expanded. J. R. Soc. Interface 2017, 14. [Google Scholar] [CrossRef]
- Ly, H.-B.; Monteiro, E.; Le, T.-T.; Le, V.M.; Dal, M.; Regnier, G.; Pham, B.T. Prediction and sensitivity analysis of bubble dissolution time in 3D selective laser sintering using ensemble decision trees. Materials 2019, 12, 1544. [Google Scholar] [CrossRef]
- Dao, D.V.; Ly, H.-B.; Trinh, S.H.; Le, T.-T.; Pham, B.T. Artificial intelligence approaches for prediction of compressive strength of geopolymer concrete. Materials 2019, 12, 983. [Google Scholar] [CrossRef]
- Dao, D.V.; Trinh, S.H.; Ly, H.-B.; Pham, B.T. Prediction of compressive strength of geopolymer concrete using entirely steel slag aggregates: Novel hybrid artificial intelligence approaches. Appl. Sci. 2019, 9, 1113. [Google Scholar] [CrossRef]
- Nagelkerke, N.J. A note on a general definition of the coefficient of determination. Biometrika 1991, 78, 691–692. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Asteris, P.G.; Kolovos, K.G. Self-compacting concrete strength prediction using surrogate models. Neural Comput. Appl. 2019, 31, 409–424. [Google Scholar] [CrossRef]
- Sarir, P.; Chen, J.; Asteris, P.G.; Armaghani, D.J.; Tahir, M. Developing GEP tree-based, neuro-swarm, and whale optimization models for evaluation of bearing capacity of concrete-filled steel tube columns. Eng. Comput. 2019, 1–19. [Google Scholar] [CrossRef]
- Bui, D.T.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Omidavr, E.; Pham, B.T.; Asl, D.T.; Khaledian, H.; Pradhan, B.; Panahi, M. A Novel Ensemble Artificial Intelligence Approach for Gully Erosion Mapping in a Semi-Arid Watershed (Iran). Sensors 2019, 19, 2444. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar]
- Pham, B.T.; Nguyen, M.D.; Ly, H.-B.; Pham, T.A.; Hoang, V.; Van Le, H.; Le, T.-T.; Nguyen, H.Q.; Bui, G.L. Development of Artificial Neural Networks for Prediction of Compression Coefficient of Soft Soil. In CIGOS 2019, Innovation for Sustainable Infrastructure; Springer: Singapore, 2020; pp. 1167–1172. [Google Scholar]
- Le, T.-T.; Pham, B.T.; Ly, H.-B.; Shirzadi, A.; Le, L.M. Development of 48-hour Precipitation Forecasting Model using Nonlinear Autoregressive Neural Network. In CIGOS 2019, Innovation for Sustainable Infrastructure; Springer: Singapore, 2020; pp. 1191–1196. [Google Scholar]
- Thanh, T.T.M.; Ly, H.-B.; Pham, B.T. A Possibility of AI Application on Mode-choice Prediction of Transport Users in Hanoi. In CIGOS 2019, Innovation for Sustainable Infrastructure; Springer: Singapore, 2020; pp. 1179–1184. [Google Scholar]
- Khosravi, K.; Daggupati, P.; Alami, M.T.; Awadh, S.M.; Ghareb, M.I.; Panahi, M.; Pham, B.T.; Rezaie, F.; Qi, C.; Yaseen, Z.M. Meteorological data mining and hybrid data-intelligence models for reference evaporation simulation: A case study in Iraq. Comput. Electron. Agric. 2019, 167, 105041. [Google Scholar] [CrossRef]
- Pham, B.T.; Jaafari, A.; Prakash, I.; Singh, S.K.; Quoc, N.K.; Bui, D.T. Hybrid computational intelligence models for groundwater potential mapping. Catena 2019, 182, 104101. [Google Scholar] [CrossRef]
- Phong, T.V.; Phan, T.T.; Prakash, I.; Singh, S.K.; Shirzadi, A.; Chapi, K.; Ly, H.-B.; Ho, L.S.; Quoc, N.K.; Pham, B.T. Landslide susceptibility modeling using different artificial intelligence methods: A case study at Muong Lay district, Vietnam. Geocarto Int. 2019. [Google Scholar] [CrossRef]
- Nguyen, M.D.; Pham, B.T.; Tuyen, T.T.; Yen, H.; Phan, H.; Prakash, I.; Vu, T.T.; Chapi, K.; Shirzadi, A.; Shahabi, H. Development of an Artificial Intelligence Approach for Prediction of Consolidation Coefficient of Soft Soil: A Sensitivity Analysis. Open Constr. Build. Technol. J. 2019, 13, 178–188. [Google Scholar] [CrossRef]
- Chang, K.-T.; Merghadi, A.; Yunus, A.P.; Pham, B.T.; Dou, J. Evaluating scale effects of topographic variables in landslide susceptibility models using GIS-based machine learning techniques. Sci. Rep. 2019, 9, 12296. [Google Scholar] [CrossRef] [PubMed]
- Nohani, E.; Moharrami, M.; Sharafi, S.; Khosravi, K.; Pradhan, B.; Pham, B.T.; Lee, S.; M Melesse, A. Landslide susceptibility mapping using different GIS-based bivariate models. Water 2019, 11, 1402. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Jaafari, A.; Bui, D.T. Spatial prediction of rainfall-induced landslides using aggregating one-dependence estimators classifier. J. Indian Soc. Remote Sens. 2018, 46, 1457–1470. [Google Scholar] [CrossRef]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Pham, B.T.; Bin Ahmad, B.; Tien Bui, D. A novel hybrid approach of bayesian logistic regression and its ensembles for landslide susceptibility assessment. Geocarto Int. 2018, 34, 1427–1457. [Google Scholar] [CrossRef]
- Pham, B.T. A novel classifier based on composite hyper-cubes on iterated random projections for assessment of landslide susceptibility. J. Geol. Soc. India 2018, 91, 355–362. [Google Scholar] [CrossRef]
- Jaafari, A.; Zenner, E.K.; Pham, B.T. Wildfire spatial pattern analysis in the Zagros Mountains, Iran: A comparative study of decision tree based classifiers. Ecol. Inform. 2018, 43, 200–211. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I. Spatial prediction of rainfall induced shallow landslides using adaptive-network-based fuzzy inference system and particle swarm optimization: A case study at the Uttarakhand Area, India. In Proceedings of the International Conference on Geo-Spatial Technologies and Earth Resources, Hanoi, Vietnam, 5–6 October 2017; pp. 224–238. [Google Scholar]
- Pham, B.T.; Prakash, I. A Novel Hybrid Intelligent Approach of Random Subspace Ensemble and Reduced Error Pruning Trees for Landslide Susceptibility Modeling: A Case Study at Mu Cang Chai District, Yen Bai Province, Viet Nam. In Proceedings of the International Conference on Geo-Spatial Technologies and Earth Resources, Hanoi, Vietnam, 5–6 October 2017; pp. 255–269. [Google Scholar]
- Pham, B.T.; Nguyen, V.-T.; Ngo, V.-L.; Trinh, P.T.; Ngo, H.T.T.; Bui, D.T. A novel hybrid model of rotation forest based functional trees for landslide susceptibility mapping: A case study at Kon Tum Province, Vietnam. In Proceedings of the International Conference on Geo-Spatial Technologies and Earth Resources, Hanoi, Vietnam, 5–6 October 2017; pp. 186–201. [Google Scholar]
- Khosravi, K.; Sartaj, M.; Tsai, F.T.-C.; Singh, V.P.; Kazakis, N.; Melesse, A.M.; Prakash, I.; Bui, D.T.; Pham, B.T. A comparison study of DRASTIC methods with various objective methods for groundwater vulnerability assessment. Sci. Total Environ. 2018, 642, 1032–1049. [Google Scholar] [CrossRef]
- Miraki, S.; Zanganeh, S.H.; Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Pham, B.T. Mapping groundwater potential using a novel hybrid intelligence approach. Water Resour. Manag. 2019, 33, 281–302. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Xu, Y.; Zhu, Z.; Chen, C.-W.; Sahana, M.; Khosravi, K.; Yang, Y.; Pham, B.T. Torrential rainfall-triggered shallow landslide characteristics and susceptibility assessment using ensemble data-driven models in the Dongjiang Reservoir Watershed, China. Nat. Hazards 2019, 97, 579–609. [Google Scholar] [CrossRef]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.-B.; Gróf, G.; Ho, H.L. A comparative assessment of flood susceptibility modeling using Multi-Criteria Decision-Making Analysis and Machine Learning Methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I. Evaluation and comparison of LogitBoost Ensemble, Fisher’s Linear Discriminant Analysis, logistic regression and support vector machines methods for landslide susceptibility mapping. Geocarto Int. 2019, 34, 316–333. [Google Scholar] [CrossRef]
- Nguyen, V.V.; Pham, B.T.; Vu, B.T.; Prakash, I.; Jha, S.; Shahabi, H.; Shirzadi, A.; Ba, D.N.; Kumar, R.; Chatterjee, J.M. Hybrid machine learning approaches for landslide susceptibility modeling. Forests 2019, 10, 157. [Google Scholar] [CrossRef]
- Pham, B.T.; Nguyen, M.D.; Bui, K.-T.T.; Prakash, I.; Chapi, K.; Bui, D.T. A novel artificial intelligence approach based on Multi-layer Perceptron Neural Network and Biogeography-based Optimization for predicting coefficient of consolidation of soil. Catena 2019, 173, 302–311. [Google Scholar] [CrossRef]
- Janizadeh, S.; Avand, M.; Jaafari, A.; Phong, T.V.; Bayat, M.; Ahmadisharaf, E.; Prakash, I.; Pham, B.T.; Lee, S. Prediction Success of Machine Learning Methods for Flash Flood Susceptibility Mapping in the Tafresh Watershed, Iran. Sustainability 2019, 11, 5426. [Google Scholar] [CrossRef]
- Pham, B.T.; Shirzadi, A.; Shahabi, H.; Omidvar, E.; Singh, S.K.; Sahana, M.; Asl, D.T.; Ahmad, B.B.; Quoc, N.K.; Lee, S. Landslide susceptibility assessment by novel hybrid machine learning algorithms. Sustainability 2019, 11, 4386. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Sahana, M.; Chen, C.-W.; Zhu, Z.; Wang, W.; Pham, B.T. Evaluating GIS-Based Multiple Statistical Models and Data Mining for Earthquake and Rainfall-Induced Landslide Susceptibility Using the LiDAR DEM. Remote Sens. 2019, 11, 638. [Google Scholar] [CrossRef]
- Jaafari, A.; Mafi-Gholami, D.; Thai Pham, B.; Tien Bui, D. Wildfire Probability Mapping: Bivariate vs. Multivariate Statistics. Remote Sens. 2019, 11, 618. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.-W.; Khosravi, K.; Yang, Y.; Pham, B.T. Assessment of advanced random forest and decision tree algorithms for modeling rainfall-induced landslide susceptibility in the Izu-Oshima Volcanic Island, Japan. Sci. Total Environ. 2019, 662, 332–346. [Google Scholar] [CrossRef]
- Al-Omari, B.; Darter, M. Effect of Pavement Deterioration Types on IRI and Rehabilitation; Transportation Research Record 1505; TRB: Washington, DC, USA, 1995. [Google Scholar]
- Park, K.; Thomas, N.E.; Wayne Lee, K.J.J.O.T.E. Applicability of the international roughness index as a predictor of asphalt pavement condition. J. Transp. Eng. 2007, 133, 706–709. [Google Scholar] [CrossRef]
- Mazari, M.; Rodriguez, D.D. Prediction of pavement roughness using a hybrid gene expression programming-neural network technique. J. Traffic Transp. Eng. 2016, 3, 448–455. [Google Scholar] [CrossRef] [Green Version]
- Prasad, J.R.; Kanuganti, S.; Bhanegaonkar, P.N.; Sarkar, A.K.; Arkatkar, S. Development of Relationship between Roughness (IRI) and Visible Surface Distresses: A Study on PMGSY Roads. Procedia Soc. Behav. Sci. 2013, 104, 322–331. [Google Scholar] [CrossRef] [Green Version]
- Chandra, S.; Sekhar, C.R.; Bharti, A.K.; Kangadurai, B. Relationship between Pavement Roughness and Distress Parameters for Indian Highways. J. Transp. Eng. 2013, 139, 467–475. [Google Scholar] [CrossRef]
- Sandra, A.K.; Sarkar, A.K. Development of a model for estimating International Roughness Index from pavement distresses. Int. J. Pavement Eng. 2013, 14, 715–724. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X1 | X2 | X3 | X4 | X5 | Y |
|---|---|---|---|---|---|
| 90 | 340.2 | 0 | 31 | 9 | 10.25 |
| 100 | 344 | 0 | 13 | 6 | 5.5 |
| 100 | 327 | 0 | 10 | 6 | 2.93 |
| 100 | 324 | 2.9 | 15 | 7 | 2.95 |
| 100 | 328 | 0 | 11 | 8 | 2.3 |
| … | … | … | … | … | … |
| … | … | … | … | … | … |
| … | … | … | … | … | … |
| 25 | 91.5 | 0 | 9 | 6 | 4.3 |
| 100 | 360 | 0 | 12 | 7 | 4.36 |
| 100 | 349 | 0 | 17 | 9 | 5.78 |
| 100 | 336 | 2 | 21 | 9 | 9.08 |
| 100 | 344 | 0 | 25 | 12 | 7.39 |
| Criteria | X1 | X2 | X3 | X4 | X5 | Y |
|---|---|---|---|---|---|---|
| Mean | 89.893 | 306.860 | 2.376 | 23.077 | 11.618 | 3.072 |
| Std | 26.776 | 92.131 | 7.937 | 13.685 | 3.289 | 1.904 |
| Min | 5 | 15.2 | 0 | 5 | 3 | 0.720 |
| 25% | 100 | 328 | 0 | 16 | 9 | 2.190 |
| 50% | 100 | 338 | 0 | 19 | 11 | 2.600 |
| 75% | 100 | 346 | 0 | 24 | 14 | 3.265 |
| Max | 100 | 380 | 100 | 119 | 33 | 37.520 |
| Dataset | Model | RMSE | R | Slope | Error Mean | Error StD |
|---|---|---|---|---|---|---|
| Training dataset | PSOANFIS | 0.122 | 0.933 | 0.838 | 0.004 | 0.122 |
| GANFIS | 0.124 | 0.930 | 0.838 | 0.003 | 0.124 | |
| FAANFIS | 0.146 | 0.901 | 0.809 | 0.002 | 0.146 | |
| Artificial neural networks (ANN) | 0.200 | 0.806 | 0.607 | 0.000 | 0.200 | |
| Testing dataset | PSOANFIS | 0.145 | 0.888 | 0.832 | 0.002 | 0.145 |
| GANFIS | 0.155 | 0.872 | 0.823 | 0.000 | 0.155 | |
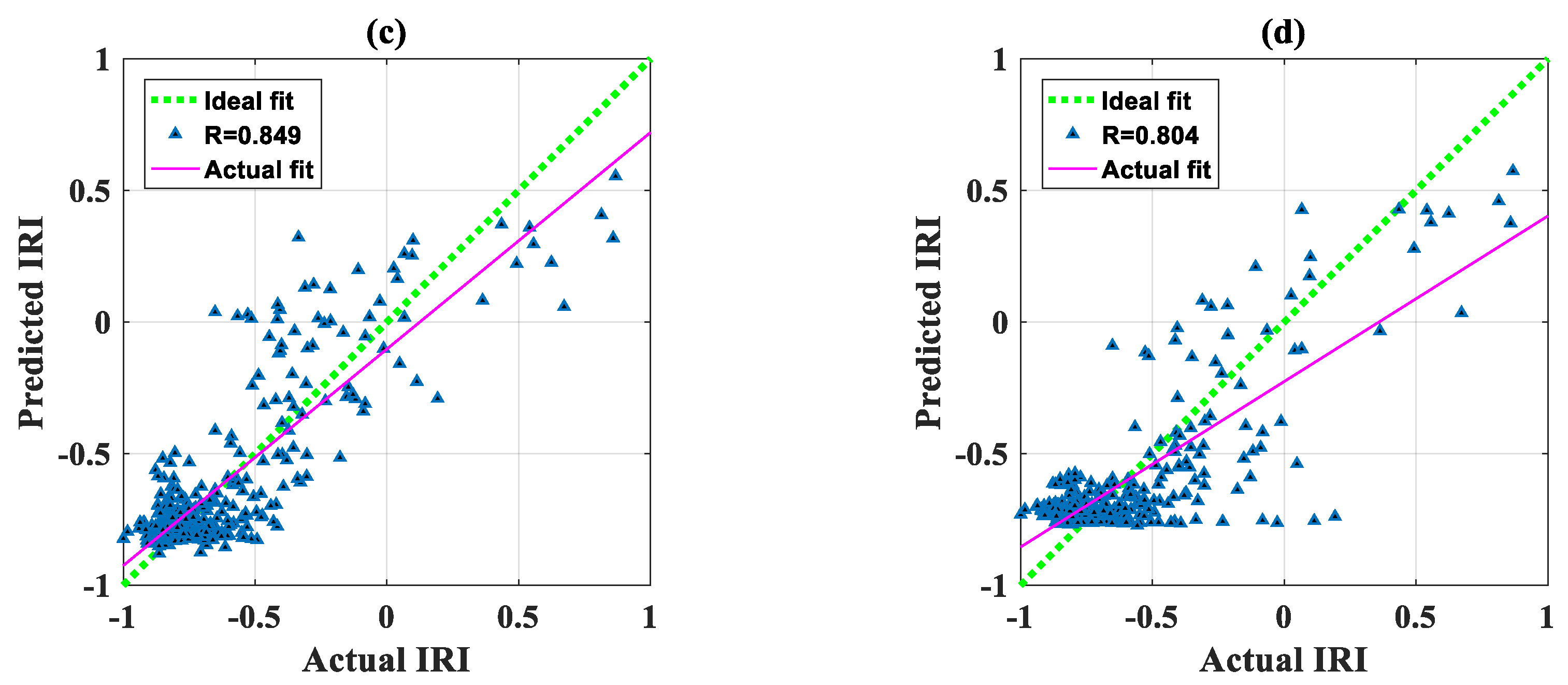
| FAANFIS | 0.170 | 0.849 | 0.823 | −0.010 | 0.170 | |
| ANN | 0.186 | 0.804 | 0.629 | −0.009 | 0.187 |
| No | Pair Samples | z-Value | p-Value | Significance |
|---|---|---|---|---|
| 1 | PSOANFIS vs. GANFIS | 7.163 | <0.0001 | Yes |
| 2 | PSOANFIS vs. FAANFIS | −2.793 | 0.0052 | Yes |
| 3 | PSOANFIS vs. ANN | −6.692 | <0.0001 | Yes |
| 4 | GANFIS vs. FAANFIS | −1.73 | 0.0836 | No |
| 5 | GANFIS vs. ANN | −6.859 | <0.0001 | Yes |
| 6 | FAANFIS vs. ANN | −6.135 | <0.0001 | Yes |
| No | Pair Samples | z-Value | p-Value | Significance |
|---|---|---|---|---|
| 1 | PSOANFIS vs. GANFIS | 6.35 | <0.0001 | Yes |
| 2 | PSOANFIS vs. FAANFIS | −3.997 | 0.0001 | Yes |
| 3 | PSOANFIS vs. ANN | −5.597 | <0.0001 | Yes |
| 4 | GANFIS vs. FAANFIS | −2.869 | 0.0041 | Yes |
| 5 | GANFIS vs. ANN | −5.897 | <0.0001 | Yes |
| 6 | FAANFIS vs. ANN | −4.2 | <0.0001 | Yes |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, H.-L.; Pham, B.T.; Son, L.H.; Thang, N.T.; Ly, H.-B.; Le, T.-T.; Ho, L.S.; Le, T.-H.; Tien Bui, D. Adaptive Network Based Fuzzy Inference System with Meta-Heuristic Optimizations for International Roughness Index Prediction. Appl. Sci. 2019, 9, 4715. https://doi.org/10.3390/app9214715
Nguyen H-L, Pham BT, Son LH, Thang NT, Ly H-B, Le T-T, Ho LS, Le T-H, Tien Bui D. Adaptive Network Based Fuzzy Inference System with Meta-Heuristic Optimizations for International Roughness Index Prediction. Applied Sciences. 2019; 9(21):4715. https://doi.org/10.3390/app9214715
Chicago/Turabian StyleNguyen, Hoang-Long, Binh Thai Pham, Le Hoang Son, Nguyen Trung Thang, Hai-Bang Ly, Tien-Thinh Le, Lanh Si Ho, Thanh-Hai Le, and Dieu Tien Bui. 2019. "Adaptive Network Based Fuzzy Inference System with Meta-Heuristic Optimizations for International Roughness Index Prediction" Applied Sciences 9, no. 21: 4715. https://doi.org/10.3390/app9214715