1. Introduction
The recent boom in the development of Internet technology has caused a similar boom in hacker attack methods which is being constantly updated. Industry, as well as government, now face more serious threats to information security. The threat to information from advanced persistent threat (APT) is much greater than that from independent hackers and poses an enormous challenge to network information security systems [
1,
2]. Among the important characteristics of APT is that it is advanced and intrusion is at a very high level. It also has strong shielding ability and the attack path is often indiscernible and this makes it more difficult for traditional methods to detect and put up a defense. It is also persistent, the attack is continuous and of long duration, this also makes it difficult for single, point based, detection techniques to handle. Although APT’s carrier exists in big data, it brings a series of difficulties to APT detection and protection, but it can also use big data to test and respond to APT. If there is comprehensive information data at all levels and stages, and any interactive behavior is detected, different data can be used to find different stages for APT analysis. APT is a major attack model that goes on for a long time, involves a large amount of data traffic, and is multi-faceted. This mode of attack presents major hurdles to which traditional single-point feature matching detection can hardly put up serious and effective resistance.
In 2013, Mandiant, now part of the FireEye US Information Network Security group, classified an APT attack as being cyclic and having five stages. The first is an initial invasion, mainly using email as the medium. The second stage is the establishment of a foothold, and malicious programs are used to take hold of the target system. The third stage involves gaining administrator privileges and cracking the password to obtain control and user authority. An internal investigation and parallel diffusion comprise the fourth stage where the main task is a search for other nearby servers and the acquisition of internal related information. The final stage is continuous monitoring and control of the server, and the theft and export of data [
3]. The APT attack threat is getting more serious, its evolution speed is beyond imagination, while its form has become more diversified. The techniques APT has adopted for different targets and objects have also changed. The common methods now used for APT attacks are watering hole, spear phishing, and SQL injection attacks, and some others [
4,
5].
The detection schemes for APT attacks include sandbox detection, network anomaly detection, and full traffic detection. However, the existing APT attack detection methods have lower accuracy and require a large number of labeled samples. Heba et al. evaluated the NSL-KDD dataset and proposed an anomaly intrusion detection system based on SVM, where PCA is applied for feature selection. They examined the effectiveness of the intrusion detection system by conducting several experiments on the NSL-KDD dataset [
6]. Liu et al. proposed a deep intrusion-based network intrusion detection model (DBN-SVDD) [
7]. This method uses DBN (deep belief net) for structural dimensionality reduction to improve detection efficiency and it uses SVDD (support vector data description) to identify and detect data sets. The experimental results of the NSL-KDD dataset using various algorithms show that the detection rate of the method can reach 93.71%. There is no need to mark a large number of samples, it can process high-dimensional data, detection of an APT attack is effective and there is no need for supervision.
The frequency of automatic attacks on networks has increased enormously as has the speed and variety of malware employed. The provision of effective analysis processing on big data networks is very important. Incidentally, the processing capacity of the attack data almost always exceeds the capabilities of personal computers. Providers use many different network intrusion detection system (NIDS) devices [
8] that are available on the market. Most use the sniffer method to give real-time packet monitoring on the network and compare suspicious packets with others used in previous attacks. When a suspected intrusion is found, these defense systems can launch an immediate warning. There is so far no indication of which algorithm, of the many, used by any hardware device gives the best rate of APT data detection. Currently, there are three common types of APT attack detection: sandbox, abnormal network, and full-flow detection. All have shortcomings and low accuracy and require a large number of labeled samples. Most focus on one stage of the APT attack, and such single detection methods cannot monitor the life cycle of an APT attack at every stage. It is necessary to study the attack data and establish an integrated security detection architecture for the APT that can deal with the complexities of the attack. APT security detection architecture uses stratified thinking to cover all the stages of an APT attack, including preparation, intrusion, infiltration, and harvest stages. It is an in-depth detection system that covers multiple information sources and network protocols. The attackers may be lucky enough to bypass one of the detection stages, but it is very difficult to avoid detection completely.
In the new era of big data, the huge volume of data now spread around the entire globe has brought with it new security challenges far greater than encountered ever before. There is a corresponding and parallel relationship between the space of reality, or real space and data space. Any activity, interaction, and behavior, especially as news, in real space has a corresponding relationship in data space. Information about the vast numbers of worldwide enterprises and their data, about billions of individuals and even objects, cloud computing and the Internet of Things are all carriers that generate big data. There is no doubt about the existence of big data, but it has also become the main carrier of cyber-attacks.
Many experiments have been carried out using the KDD 99 database [
9], which has been the most commonly used in past studies. This data is based on a database established by DARPA in 1999. DARPA collected the data of three weeks of normal data flow and two weeks of an anomaly attack. This work was done at the Lincoln Labs of the Massachusetts Institute of Technology (MIT) and there are 494,021 records in the database data training set, and 311,029 records in the test set. There are a total of 41 features and 5 types of large tags (normal, dos, r2l, u2l, probe) [
10,
11]. The inherent flaws in the KDD 99 data set have been revealed by various statistical analyses, where many studies found flaws that affect the precision of the intrusion detection system (IDS) modeling. Tavallaee et al. [
11] questioned the KDD 99 data, and further modified the data sample. He introduced the NSL-KDD database, which is more discriminative and allows better intrusion detection.
The NSL-KDD data set was used in this study. It is suitable for the study and evaluation of network intrusion detection systems [
11]. Its predecessor was an improved version of KDD 99 [
9], which had redundant data removed, and overcame the classifier recurring records problem that tended to affect learning performance. In addition, the ratio of normal to anomalous data is properly selected, the test and training data volumes are more reasonable, and it is generally more suitable for the accurate evaluation of different machine learning techniques. Big data has become the foundation of science and clarification, structuration, standardization, dimensionality reduction, and visualization. Dimensionality reduction algorithms map the original multidimensional data to low- dimensional data and describe the main features of the original with less data. Common methods currently used can be linear or non-linear. The most frequently used non-linear dimensionality reduction methods are locally linear embedding (LLE) and local tangent space alignment (LTSA) [
12]. However, the computational complexity of non-linearity is high, and in this study, it was necessary to process rapidly, even immediately, and so linear dimensionality reduction was used. The focus of this study was on the exploration of linear principal component analysis (PCA) [
13] as the main axis. The three important characteristics of PCA are: (1) it is the best linear scheme, in terms of mean square error, for the compression and reconstruction of a set of high-dimensional vectors into lower-dimensional vectors; (2) it can directly calculate model parameters from data, such as sample covariance; (3) compression and decompression are simple processes for the execution of model parameters. In line with a method proposed by Revathi et al. [
14], the NSL-KDD data set was used for network intrusion detection. The data set has 41 attributes, some of which may not be necessary and others unrelated. When the data set is very large dimensional problems may arise. To reduce the dimensions, we used PCA, a dimensional and multivariate analysis technique primarily used for data compression, image processing, pattern recognition, and time series prediction [
15,
16].
APT attack detection technology has also been combined with data mining techniques [
17,
18]. The aim being to carry out data integration and classification using frequently encountered pattern sets and association rules to detect and gain early warning of an APT attack. Classification is divided into categories that have been established using the test data. During the data mining process, attack detection technology becomes a classification issue that determines the category and feature sets. Each audit record is classified as one of two types: normal behavior or attack behavior. In APT attack detection, correlation analysis can be used to find the relationship between the various kinds of attack behavior. This correlation is used to classify the data and for the detection of attacks. The most influential classification algorithms used in data mining are the Iterative Dichotomizer 3 (ID3), C4.5 [
19,
20], the native Bayes classifier, based on the posterior attitude that uses the Bayes theorem and the backpropagation of the Bayesian and neural networks. If prediction accuracy, calculation speed, robustness, and interpretability are used to evaluate the classification algorithms, it is found that each different method has advantages and disadvantages. No method has so far been found that is superior to the others for all data. They are selected according to the type of data and the application field.
In this study the (NSL-KDD) data set provided by knowledge discovery and data mining (KDD) CUP [
11] was used. Although the NSL-KDD dataset data is old, its network communication protocol and attack behavior patterns remain unchanged. The dimension was reduced using PCA to enhance the efficiency of detection. The relevant classification method was then used for the data set experiments and to establish models for the training data (using the training algorithm) to analyze and classify the APT attack packets. The test data were loaded using the training model to obtain the performance indicator. The model was then used to establish the APT attack detection system. Detection and defense covered all stages of the APT attack to achieve the best result.
3. Classifier
3.1. Support Vector Machine
SVM technology was devised for handling data in space. A hyperplane in the space is found which separates the data into two different groups. Suppose we have a bunch of points and the rendezvous point is expressed as (5)
An attempt is made to find a straight line that allows all the points to fall on the side, and all the to fall on the side. Therefore, it is possible to distinguish to which side a point belongs by the sign (+ or −) of . This spatial plane is called the separating hyperplane, and the greatest distance from the margin is called the optimal separating hyperplane (OSH). Solving OSH is equivalent to finding the support hyperplane with the farthest distance.
The support hyperplane is defined as in (6)
The margin between the two separating hyperplanes is naturally double
. Where the margin = 2d = 2/‖
w‖, the smaller the ‖
w‖, the larger the margin. Knowing that the distance between the support hyperplane and the optimal separating hyperplane is within ±1, so the constraint conditions are written as in Equations (7) and (8)
The Lagrange multiplier is then used for transformation to a quadratic Equation (8) and to find
,
, and
that allows
L to be a minimum, as in Equation (8)
To solve the minimum value
, find the partial differential of
and
respectively to get (9)
However, the solution for nonlinear data is to project the data to a space of higher dimension or a feature space. The mapping of
x to the feature space through
φ, is shown in (10)
However, the mapping function
φ is very complicated and it is not easy to obtain the value, but its inner product type may become very simple. Take the radial based function (RBF) as an example. Although RBF is a complex function, it can be changed to an inner product and simplified as shown in (11)
The function obtained by the mapping function from the inner product is the SVM kernel.
3.2. Naive Bayes
Naive Bayes predicts the results of classification according to the Bayesian theorem. It is mainly used to calculate the data of unknown categories and the probability of its belonging to a category. Bayesian classification attains minimum error by the analysis of probability statistics, using known category attribute probability values and their pre-probability values, to calculate the probability of a new case in each category. The probability of each category is compared and the case will be classified as the category with the greatest probability. Assume that event
is in
category data collection sample space, an observe quantity
is then given which has an
features parameter. According to the Bayesian theorem, the classification
belongs to the observe quantity
, and the error probability of classification can be expected to be minimized. The following Equation (12) can be obtained from the Bayesian theorem.
In Equation (12),
is the pre-probability, and represents the probability of the
category.
is a constant,
is the probability of observe quantity
and appears in the
category.
is the post-probability and reference used to judge the
category, to which the observe quantity
belongs, the judgment Equation is (13)
To judge to which category a certain feature
belongs, it is only necessary to estimate the similarity rate between category
and category
, where the similarity rate
is given by Equation (14)
If , then is biased towards category ; on the other hand, if , is more biased towards category .
3.3. Decision Tree
The decision tree algorithm classifies data to achieve the purpose of detection. The decision tree is formed from the training set data. If the tree cannot offer a correct classification of all the objects, then some exceptions are selected and added to the training set. This is repeated until a correct decision set has been formed. J48 is a decision tree C4.5 algorithm developed for the generation of decision trees as an extension of the ID3 algorithm previously developed by Quinlan [
17,
18]. The decision tree generated by the C4.5 algorithm can be used for classification purposes. Information gain is an attribute selection method of information theory, the formal definition is,
and is the information before testing and after the training set has been classified.
is the information after testing, which represents the information in each subset after the training set has been tested by the attribute A
k. Its Equation (15) is shown below
In the equation, is the finite set of examples, a set of attributes. The decision tree generated by Equation (15) is gradually trimmed to form a complete decision tree, and further trimmed to give easy-to-understand rules. The advantage of using the C4.5 algorithm is that it can be pruned during the tree construction process. Discretization processing of the continuous attributes allows the processing of incomplete data. The generated classification rules are easy to understand, and have high accuracy. The disadvantage is that the data set needs to be scanned and sorted many times during the process of building the tree. This inefficiency increases computer calculation time. The J48 algorithm has two important parameters, C and M. C is the confidence level used to define the confidence intervals. The value of the confidence factor is based on the trimmed parameter after the decision tree has been established. The smaller the value, the more the tree has been trimmed. The M parameter is the smallest sample number in two of the most popular branches.
3.4. Multilayer Perceptron
Multilayer perceptron (MLP) is a back-propagation neural network with high learning accuracy and fast recall. It can handle complex sample discrimination and highly nonlinear function synthesis problems where the output values can be suspended values. It is a popular neural network that has a wide range of applications that include: sample identification, bifurcation problems, function simulation, prediction, system control, noise filtering, data compression, etc.
MLP is a back-propagating supervised learning algorithm, through , m is the dimension at input and is the dimension at output. By inputting the feature and the target value Y, this algorithm can classify the data using nonlinear approximation or perform regression. MLP can have many nonlinear layers inserted between the input and output layers.
The stochastic gradient descent (SGD) method is used in MLP training. SGD uses the gradient of the loss function, relative to the parameter that needs to be adaptive for updating, see Equation (16), where
is the learning rate in the control parameter space search step, and Loss is the loss function used by the network.
If a training sample set
is given, where
with
, then the MLP learning function of one hidden layer and one hidden neuron is shown as in Equation (17)
In Equation (17),
and
, is the model parameter.
and
the weights of the input and hidden layers respectively, and
and
are the deviations added to the hidden and the output layers.
is the activate function, set here as the hyperbolic tangent (tanh), the equation is shown as (18)
For binary classification,
can have an output value between 0 and 1 through the logic function
. With the threshold set to 0.5, the output sample will be greater than or equal to 0.5 in the positive category, and the rest will be negative. If there are more than two categories,
will be a vector of size n and will be a softmax function rather than a logical one.
represents the
ith element input to softmax, which corresponds to the
ith category, and K is the number of categories. The result is a probability vector that contains sample
for each category. The output category is the one with the highest probability, the mathematical Equation (19) is
As for the regression method, the output remains
, so the output start function is an identical function. MLP uses a different loss function, depending on the type of problem. The loss function of the classification has cross entropy, and in the binary case, its loss function is shown in Equation (20)
Starting with the initial random weight, the multilayer perceptron (MLP) reduces the loss function to the greatest extent by repeatedly updating these weights. After the loss has been calculated, it is passed back to propagate from the output layer to the previous layer, and each weight parameter is provided with an updated value to reduce error in the loss function.
In the gradient descent, the update of the weight can be expressed as Equation (21)
In Equation (21), is the iteration step and the learning rate is a value greater than zero. The algorithm stops when the preset maximum number of iterations has been reached, or when the improvement of loss is below a certain small number.
4. Results and Discussion
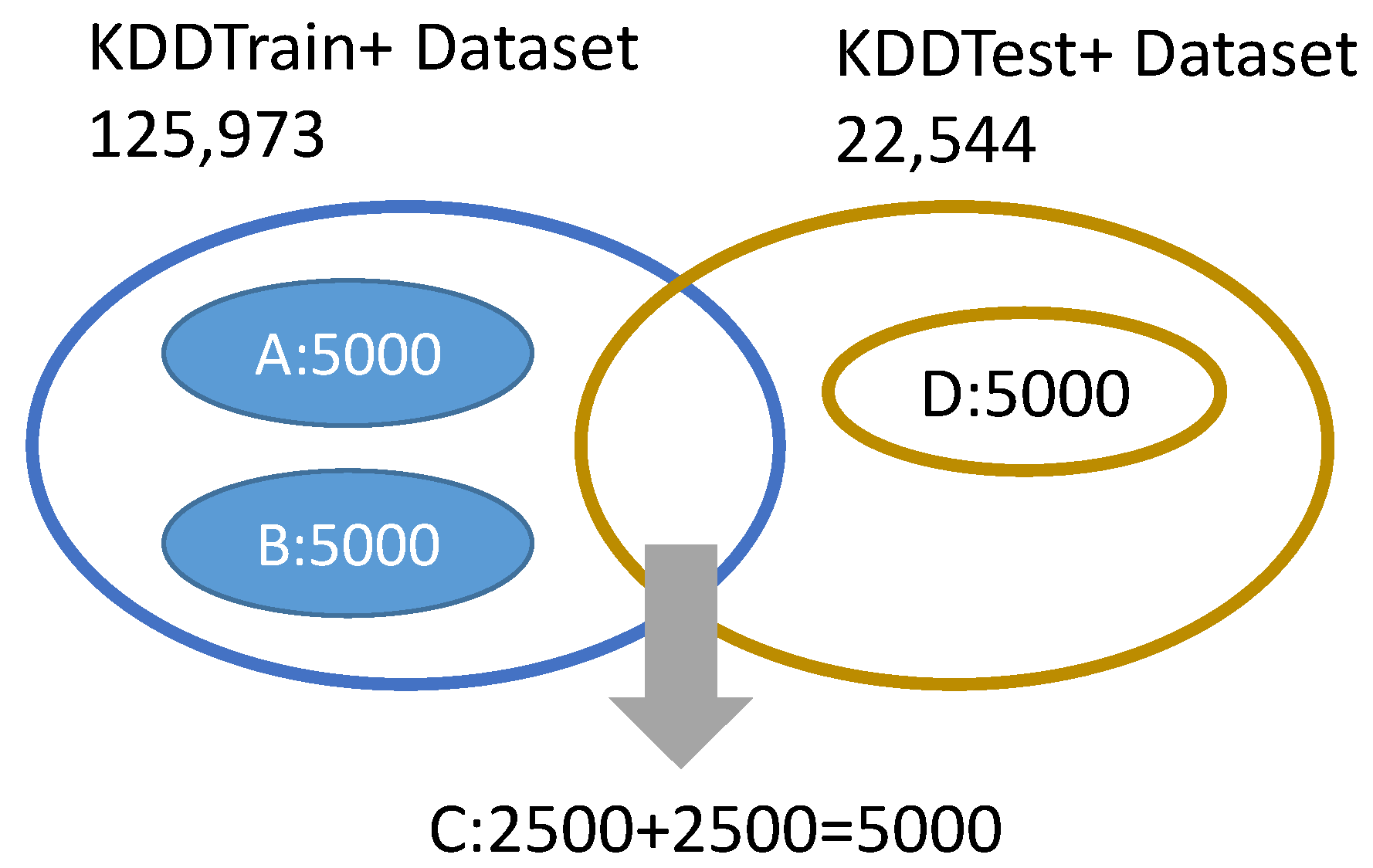
The NSL-KDD data set was used in this study and had the basic host feature content which included time and traffic. The training data set contained 22 different attacks. To simulate an actual situation, new attacks would appear. The test data set contained 17 attack types that had not appeared in the training dataset. The KDDTest+ and KDDTrain+ datasets, which have 22,544 and 125,973 network data records respectively, were used. The WEKA-ReSample tool was used for the sampling of four sub-datasets A, B, C, and D from the original (KDDTest+ and KDDTrain+) respectively, for use as experimental data set samples, as shown in
Figure 1.
Each NSL-KDD network data record has 38 digital type attribute features, as well as three character type attribute features including protocol type, service, and flag. Furthermore, the protocol type has 3 features, service has 70 features, and flag has 11 features. It was therefore necessary to map and transform the character type features in the original record to digital feature attributes. The WEKA-Nominal to binary encoding method was used to encode the character features, turning each original data record into a 122-dimensional eigenvector. Since the data had significantly different resolutions and ranges, the range of value captured was not uniform. Therefore, standardization or mean removal and variance scaling was needed for each eigenvector. After the transformation, each dimension had a mean of 0, also called the Z-score normalization. Calculation involved subtraction of the mean (M) from feature (X) and division by the standard deviation (S) (calculation equation: Z = (X − M)/S), so the attribute data was scaled within a range of [0, 1]. After standardization of the training data set, the same procedure was used to standardize the test data set.
The Weka tool was used to load the sampled experimental data set (sub-data sets A, B, C, and D, each having 5000 records, and the random sampling reflected, as far as possible, the various information expected during the analysis) for data preprocessing, and PCA was used to reduce the number of features to 94. Four kinds of classification algorithms: SVM, naive Bayes, decision tree (J48), and MLP were used in the experimental tests. Data that had not been dimensionally reduced, and data which had been reduced, were both used. In the accuracy experiment for each group, data was compared in three different combinations. Data set A was used to train each group, data set B was used to test the first group, data set C was used for the second group, and data set D was used for the third group.
4.1. SVM Classifier Results
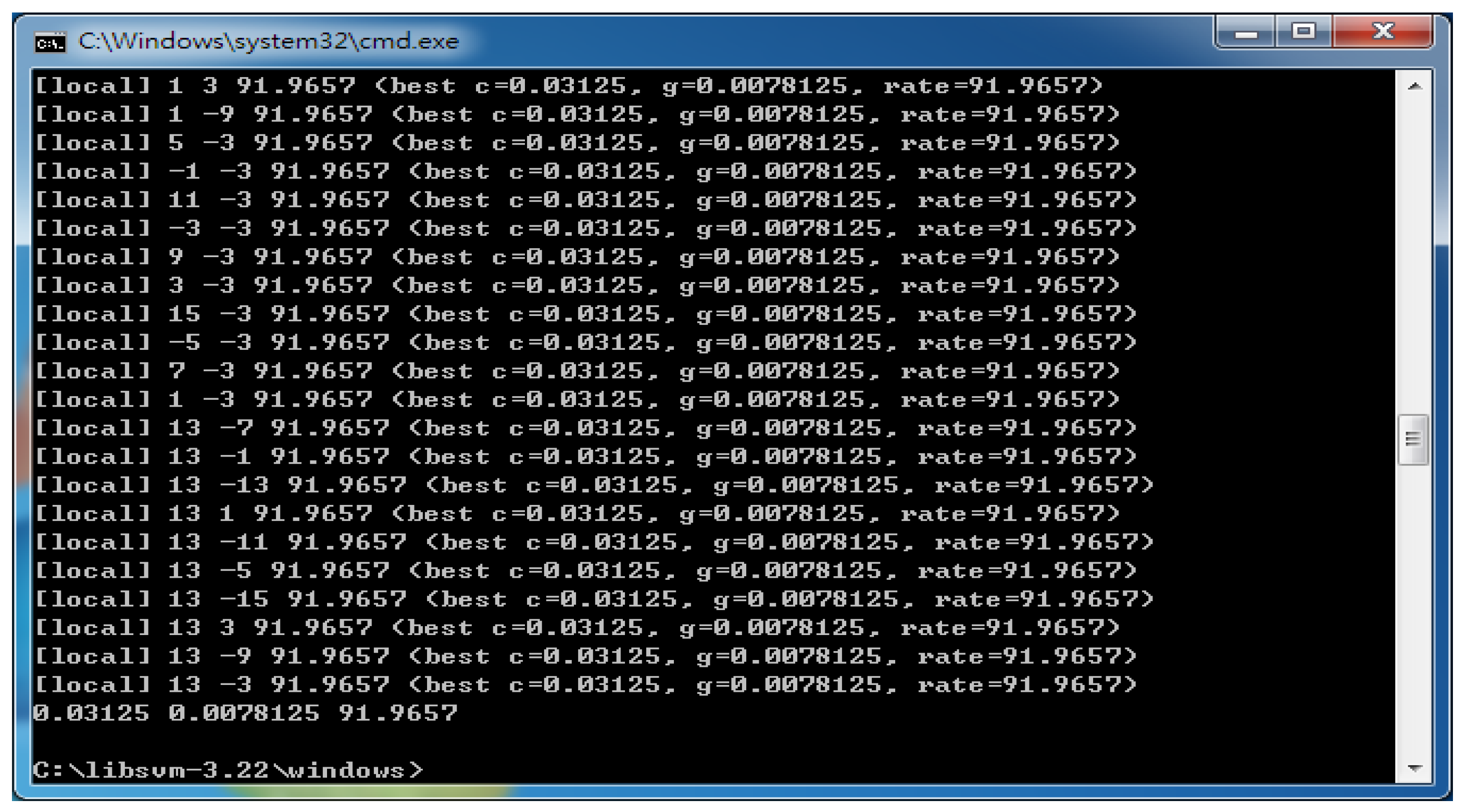
The SVM model has two very important parameters, C and gamma. Where C is the penalty factor, which is the tolerance for error. The higher the value of c, the less the tolerance and over-fitting is easy. The smaller the value of C, the easier it is to fit. If C is too big or too small, the generalization ability will suffer and become worse. Gamma is a parameter that comes with the function after selection of the RBF function as the kernel. It implicitly determines the distribution of data after mapping to a new feature space. The larger the gamma value, the smaller the support vector, the smaller the gamma, the larger the support vector. The number of support vectors affects the speed of training and prediction. In the process, we experimented with the parameters c and g settings, and used the parameter check program grid.py to find the best parameters c and g. After the program is executed, the last set of parameters is 0.03125, 0.0078125, and 91.9657 (
Figure 2), where c = 0.03125, g = 0.0078125, the parameters c and g are brought into the SVM classifier respectively, the correct rate of training and test results are 92.2396% and 67.7032% respectively. After several parameter adjustment experiments, it was decided to use c = 1.0 and g = 0.0 as the best parameter values to verify with the other three classifiers in the paper.
Weka was used for pre-processing. Feature selection, dimension reduction to 94 features, and training and testing of the data set was done as before and according to the status of each data set. The kernel function (parameter setting: parameter gamma = 0.0, parameter C = 1.0) was applied including linear SVM, polynomial, RBF, and sigmoid for training and prediction, and the results are shown in
Table 2. It can be seen that the test of the first group had the best original data recognition. When used for recognition, the kernel of the RBF can reach 97.22%. The linear kernel recognition rate for the first group, after dimensionality reduction, can reach 96.68%. Although the SVM classifier showed no enhancement of recognition rate after dimension reduction, the calculation speed was substantially improved.
4.2. Naive Bayes Classifier Results
The results obtained with the Weka-naive Bayes classifier, using the default parameters are shown in
Table 3. The results indicate that, recognition of the data after dimension reduction was enhanced and the calculation speed also improved, achieving a 91.54% recognition rate and a calculation speed of 0.44 s.
4.3. J48 Classifier Results
The J48 algorithm has two important parameters: The first is C (the confidence factor) which is the level used to define the confidence interval. A lower C value will give a wider interval, meaning a more negative estimate, which will result in heavier pruning. The confidence factor value is the parameter basis for pruning after the decision tree has been established. The smaller the value, the more extensive the pruning. The second is the M parameter which is the minimum number of instances in the two most popular branches. The classifier displays the results in the text box next to the selection button, and shows (J48-C 0.05-M 2), (J48-C 0.25-M 2), (J48-C 0.4-M 2), (J48-C 0.05-M 50), (J 48-C 0.25-M 50), (J 48-C 0.4-M 50), (J 48-C 0.55-M 500), (J 48-C 0.25-M 500), (J 48-C 0.4-M 500) as the parameter settings. The results in
Table 4 show that the calculation speed tends to be fast, but the recognition rate is generally poor, and the data after dimension reduction (J48-C 0.05 to 0.4-M 500) had the best recognition rate, reaching 86.02%.
4.4. MLP Classification Test Results
The Weka-MLP tool was used to do the MLP classification test. The parameters were the number of hidden units (2 or 4), the ridge factor for quadratic penalty on weights (default 0.01), the tolerance parameter for delta values (default 1.0 × 10
−6), conjugate gradient descent was used (recommended for many attributes), the size of the thread pool (default 1), the number of threads to use (default 1), and random number seed (default 1). Tests were done for four combinations according to the parameters, the combinations were AA (approximate sigmoid and approximate absolute error), AS (approximate sigmoid and squared error), SA (soft plus and approximate absolute error), and SS (soft plus and squared error). The results in
Table 5 show that the highest recognition rate was 97.82%, and when number of hidden units was 4, and approximate sigmoid and squared error had also been selected, the calculation speed was 0.17 s.
4.5. Correlation of Recognition Rate between the Classification Methods and Reduction of Dimension
PCA was used for feature selection and to reduce the dimension of available attributes in the data set from 122 to 94. Classification was done by SKA, naive Bayes, J48, and the MLP algorithms through WEKA. Correlation of each kind of classification algorithm and dimension reduction was carried out, and
Table 6 shows the correct rate of classification detection for each data set and the parameter settings.
From the results, it can be clearly seen that the greater the amount of PCA dimension reduction, the faster the calculation speed. The reduction had no absolute correlation with the correct rate. When the classifier and parameter MLP-AS was N = 4, the same dimensionality reduction did not significantly improve the recognition rate. The MLP calculation speed was not improved either. However, its recognition rate was the highest among the classifiers, reaching 97.82%. The results of SVM-RBF are similar to those of MLP.





{kind=link}
{kind=link}