An FCM–GABPN Ensemble Approach for Material Feeding Prediction of Printed Circuit Board Template


Abstract
:Featured Application
Abstract
1. Introduction
2. Variables and Sample
3. Methodology
3.1. Data Preparation and Template Classification with FCM
- (1)
- The cluster membership value, (the coefficient giving the degree of being in the jth cluster), are initialized randomly and establish an initial clustering result.
- (2)
- (Iterations) obtain the centers of each cluster as , , , , , where is the jth variable of the selected 17 attributes of sample i, and is the centroid of cluster c.
- (3)
- Re-measure the distance of each PCB template to the centroid of every cluster, and then recalculate the corresponding membership value.
- (4)
- Stop if the number of iterations is larger than a set value. Otherwise, return to Step (2).
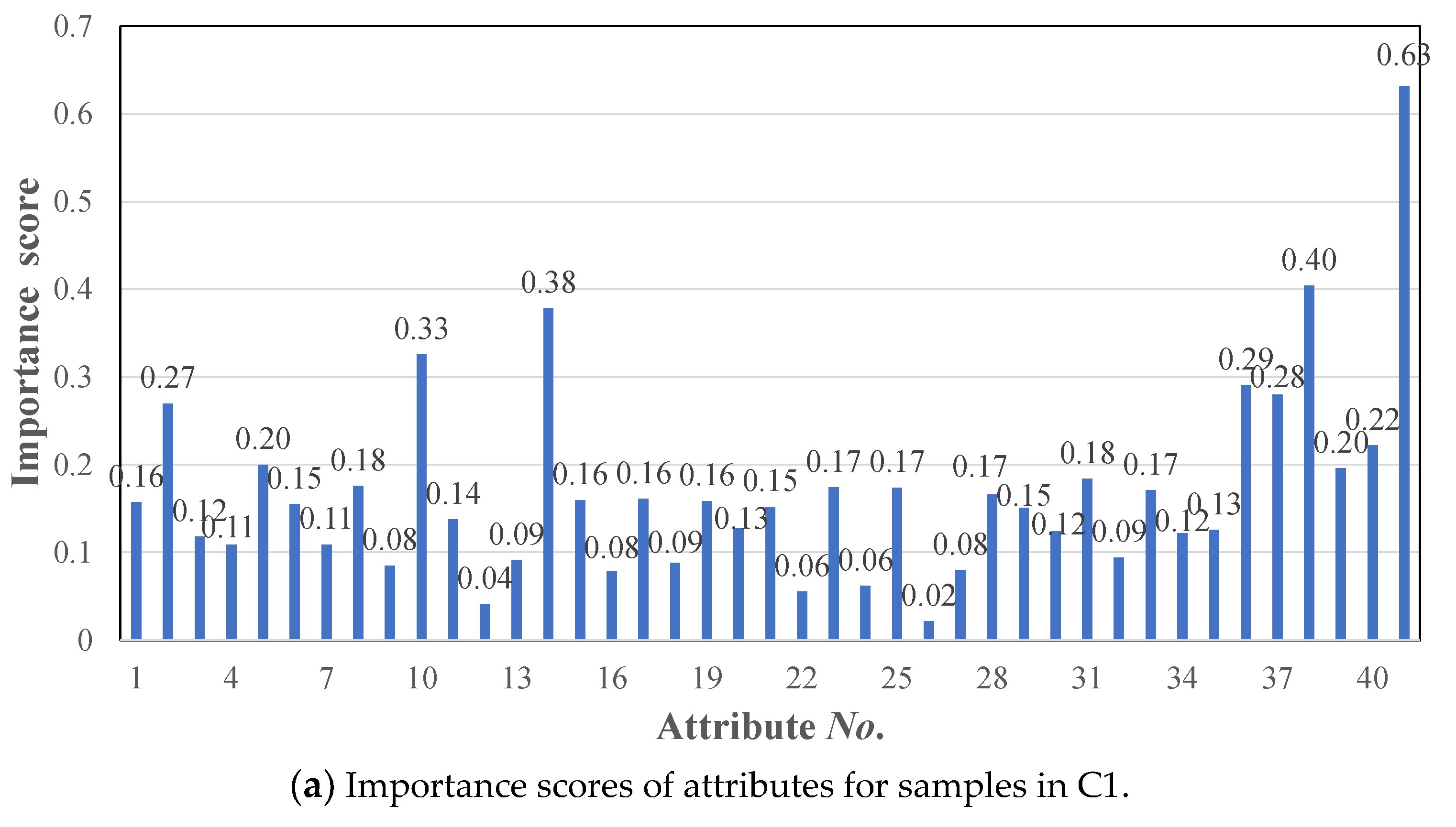
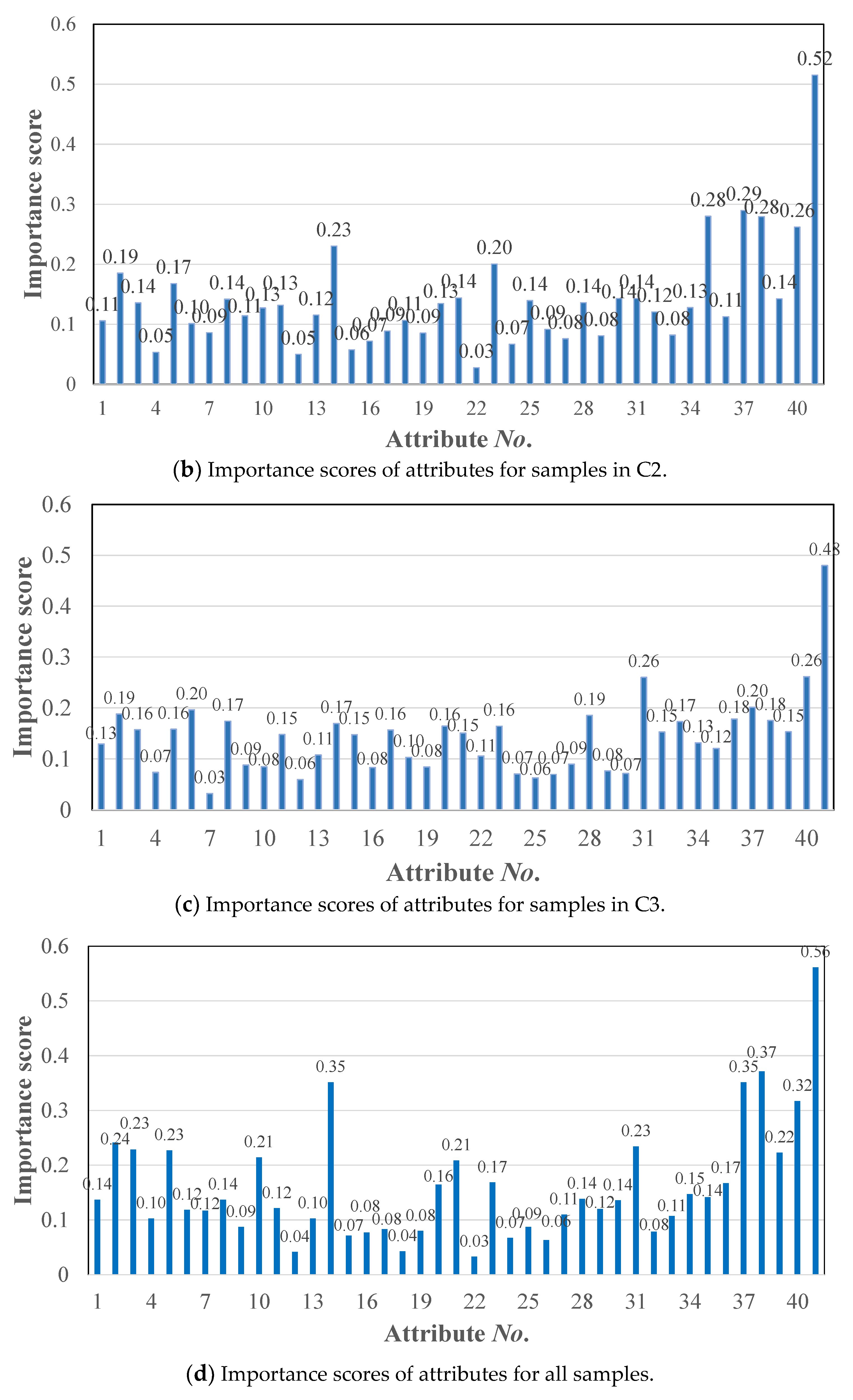
3.2. Attributes Selection for Each BPN Prediction Model
3.3. GABPN-Based Scrap Rate Prediction for Each Category
- (1)
- Input: the 0–1 normalized data of the selected attributes for each category.
- (2)
- Architecture: Single hidden layer (number of nodes in the input layer + number of nodes in the output layer)/2 is one of the commonly used ways to determine the suitable number of neurons in the hidden layer. Therefore, the number of nodes in hidden layer is depended on the number of selected attributes in this study. In order to achieve better prediction accuracy (a large number of the hidden-layer nodes are theoretically conducive to improve the predicting accuracy) and to keep the consistency, the number of neurons in the hidden layer of each BPN was set to 12 for each category in the proposed approach, considering the number of selected attributes (up to 23 selected attributes for the samples that will be discussed in Section 4).
- (3)
- Output: normalized scrap rate forecast of the template.
- (4)
- Learning rule: Delta rule (the adjustment of weight and bias is proportional to the negative gradient of the error during the backward-propagation procedure).
- (5)
- Propagation function: sigmoid activation function, .
- (6)
- Learning rate: 0.05.
- (7)
- Number of iterations: 25,000.
- (1)
- Encoding and decoding: The individual chromosome in the population was encoded as in which (selected i attributes as input and the number of neurons in the hidden layer is 12) represents the weights between nodes in input layer and hidden layer; represents the weights between the nodes in hidden layer and output layer; is the bias vector of nodes in the hidden layer; and is the bias of output node. The decoding is to assign corresponding weights and bias to each node based on the BPN structure, and then conduct the forward propagation to compute the output of each BPN.
- (2)
- Population initialization: Each individual chromosome in the population was initialized randomly with its elements between −3 and 3, based on the encoding principle.
- (3)
- Fitness evaluation: The sum of absolute error between reversely normalized scrap rate forecast and actual scrap rate was taken as the fitness for each individual. The smaller the fitness is, the more accurate prediction result it can obtain. Thereafter, the minimization objective function, which the problem seeks to optimize, is the same as the fitness function.
- (4)
- Reproduction, crossover and mutation operation:
- (5)
- Number of iterations: 100.
3.4. Nonlinear Aggregation with Another BPN and Transformation
- (1)
- Input: 2K parameters consisted of the predicted results of each component GABPNs for the template and the membership values of the template belonging to each category.
- (2)
- Architecture: Single hidden layer and the number of nodes in the hidden layer were set to the same as that in the input layer, 2K.
- (3)
- Output: normalized scrap rate forecast of the template.
- (4)
- Learning rule: Delta rule.
- (5)
- Propagation function: sigmoid activation function.
- (6)
- Learning rate: 0.05.
- (7)
- Number of iterations: 10000.
3.5. Performance Indicators
4. Experimental Results and Discussions
5. Conclusions
- (1)
- The accuracy of the proposed approach was better than those of the other approaches by achieving a 95.91%, 83.03%, and 89.57% reduction in MSE, MAE, and MAPE, respectively, over the comparison basis—manual feeding. Meanwhile, the FCM–GABPN’s performance was superior to that of the other methods in the reduction of simulated surplus and/or supplemental feeding in most of the cases, by achieving a 70.16% reduction in Surpr_Pd and a 31.03% reduction in Supfr Pd over manual feeding.
- (2)
- The material feeding prediction of PCB template problem considering category fuzziness of samples and the diverse samples with different influence factors is different from the existing production quality prediction and optimization problem, to the best of our knowledge. The novelty of the proposed FCM–GABPN is that we fuzzily clustered samples into different categories with FCM and specified a membership threshold to adopt samples for each category. Meanwhile, component GABPN prediction model for each category was established with separately selected input attributes and GA optimized initial parameter. Furthermore, an aggregator BPN was employed to aggregate the predicted results of each GABPN by considering the membership values of each template.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Marque, A.C.; Cabrera, J.M.; Malfatti, C.F. Printed circuit boards: A review on the perspective of sustainability. J. Environ. Manag. 2013, 31, 298–306. [Google Scholar] [CrossRef] [PubMed]
- Lv, S.P.; Zheng, B.B.; Kim, H.; Yue, Q.S. Data mining for material feeding optimization of printed circuit board template production. J. Electr. Comput. Eng. 2018, 2018, 1852938. [Google Scholar] [CrossRef]
- Lv, S.P.; Kim, H.; Zheng, B.B.; Jin, H. A review of data mining with big data towards its applications in the electronics industry. Appl. Sci. 2018, 8, 582. [Google Scholar] [CrossRef]
- Lee, H.; Kim, C.O.; Ko, H.H.; Kim, M.Y. Yield prediction through the event sequence analysis of the die attach process. IEEE Trans. Semicond. Manuf. 2015, 28, 563–570. [Google Scholar] [CrossRef]
- Tsai, T. Development of a soldering quality classifier system using a hybrid data mining approach. Expert Syst. Appl. 2012, 39, 5727–5738. [Google Scholar] [CrossRef]
- Stoyanov, S.; Bailey, C.; Tourloukis, G. Similarity approach for reducing qualification tests of electronic components. Microelectron. Reliab. 2016, 67, 111–119. [Google Scholar] [CrossRef]
- Khader, N.; Yoon, S.W.; Li, D.B. Stencil printing optimization using a hybrid of support vector regression and mixed-integer linear programming. Procedia Manuf. 2017, 11, 1809–1817. [Google Scholar] [CrossRef]
- Tsai, T.; Liukkonen, M. Robust parameter design for the micro-BGA stencil printing process using a fuzzy logic-based Taguchi method. Appl. Soft. Comput. 2016, 48, 124–136. [Google Scholar] [CrossRef]
- Kwak, D.; Kim, K. A data mining approach considering missing values for the optimization of semiconductor-manufacturing processes. Expert Syst. Appl. 2012, 39, 2590–2596. [Google Scholar] [CrossRef]
- Tsai, T. Thermal parameters optimization of a reflow soldering profile in printed circuit board assembly, A comparative study. Appl. Soft. Comput. 2012, 12, 2601–2613. [Google Scholar] [CrossRef]
- Chan, K.Y.; Kwong, C.K.; Tsim, Y.C. Modelling and optimization of fluid dispensing for electronic packaging using neural fuzzy networks and genetic algorithms. Eng. Appl. Artif. Intell. 2010, 23, 18–26. [Google Scholar] [CrossRef] [Green Version]
- Liukkonen, M.; Havia, E.; Leinonenb, H.; Hiltunena, Y. Quality-oriented optimization of wave soldering process by using self-organizing maps. Appl. Soft. Comput. 2011, 11, 214–220. [Google Scholar] [CrossRef]
- Liukkonen, M.; Hiltunen, T.; Havia, E.; Leinonen, H.; Hiltunen, Y. Modeling of soldering quality by using artificial neural networks. IEEE Trans. Electron. Packag. Manuf. 2009, 32, 89–96. [Google Scholar] [CrossRef]
- Srimani, P.K.; Prathiba, V. Adaptive data mining approach for PCB defect detection and classification. Indian J. Sci. Technol. 2016, 9, 1–9. [Google Scholar] [CrossRef]
- Sim, H.; Choi, D.; Kim, C.C. A data mining approach to the causal analysis of product faults in multi-stage PCB manufacturing. Int. J. Precis. Eng. Manuf. 2014, 15, 1563–1573. [Google Scholar] [CrossRef]
- Nagorny, K.; Lima-Monteiro, P.; Barata, J.; Colombo, A.W. Big data analysis in smart manufacturing: A Review. Int. J. Commun. Netw. Syst. Sci. 2017, 10, 31–58. [Google Scholar] [CrossRef]
- Cheng, Y.; Chen, K.; Sun, H.M.; Zhang, Y.P.; Tao, F. Data and knowledge mining with big data towards smart production. J. Ind. Inform. Integr. 2018, 9, 1–13. [Google Scholar] [CrossRef]
- Hashem, S.T.; Ebadati, E.O.M.; Kaur, H. A hybrid conceptual cost estimating model using ANN and GA for power plant projects. Neural Comput. Appl. 2017, 2017, 1–12. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, S.; Tang, Y.; Qiu, Z.P. Optimization of impulse water turbine based on GA-BP neural network arithmetic. J. Mech. Sci. Technol. 2019, 33, 241–253. [Google Scholar] [CrossRef]
- Jiang, S.; Wang, L. Efficient feature selection based on correlation measure between continuous and discrete features. Inf. Proc. Lett. 2016, 116, 203–215. [Google Scholar] [CrossRef]
- Reshef, D.N.; Reshef, Y.A.; Finucane, H.K.; Grossman, S.R.; McVean, V.; Turnbaugh, P.J.; Lander, E.S.; Mitzenmacher, M.; Sabeti, P.C. Detecting novel associations in large data sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef] [PubMed]
- Gregorutti, B.; Michel, B.; Saint-Pierre, P. Correlation and variable importance in random forests. Stat. Comput. 2017, 27, 659–678. [Google Scholar] [CrossRef]
- Hess, A.S.; Hess, J.R. Linear regression and correlation. Transfusion 2017, 57, 9–11. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Tian, Y.; Bai, L.; Xiahou, J.B.; Hancock, E. High-order covariate interacted lasso for feature selection. Pattern Recognit. Lett. 2017, 87, 139–146. [Google Scholar] [CrossRef]
- Ohishi, M.; Yanagihara, H.; Fujikoshi, Y. A fast algorithm for optimizing ridge parameters in a generalized ridge regression by minimizing a model selection criterion. J. Stat. Plan. Inference 2019. [Google Scholar] [CrossRef]
- Ao, Y.; Li, H.Q.; Zhu, L.P.; Ali, S.; Yang, Z.G. The linear random forest algorithm and its advantages in machine learning assisted logging regression modeling. J. Pet. Sci. Eng. 2019, 174, 776–789. [Google Scholar] [CrossRef]
- Tang, J.; Yu, S.W.; Liu, F.; Chen, X.Q. A hierarchical prediction model for lane-changes based on combination of fuzzy C-means and adaptive neural network. Expert Syst. Appl. 2019, 130, 265–275. [Google Scholar] [CrossRef]
- Rezaee, M.J.; Jozmaleki, M.; Valipour, M. Integrating dynamic fuzzy C-means, data envelopment analysis and artificial neural network to online prediction performance of companies in stock exchange. Phys. A Stat. Mech. Its Appl. 2018, 489, 78–93. [Google Scholar] [CrossRef]
- Fathabadi, H. Power distribution network reconfiguration for power loss minimization using novel dynamic fuzzy c-means (dFCM) clustering based ANN approach. Int. J. Electr. Power 2016, 78, 96–107. [Google Scholar] [CrossRef]
- Jia, W.; Zhao, D.; Zheng, Y.; Hou, S.J. A novel optimized GA–Elman neural network algorithm. Neural Comput. Appl. 2019, 31, 449–459. [Google Scholar] [CrossRef]
- Chen, T. Incorporating fuzzy c-means and a back-propagation network ensemble to job completion time prediction in a semiconductor fabrication factory. Fuzzy Sets Syst. 2007, 158, 2153–2168. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. A review of feature selection methods on synthetic data. Knowl. Inf. Syst. 2013, 34, 483–519. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Variable Name | Symbol | Description | Value Range |
|---|---|---|---|---|
| Overall characteristics | ||||
| 1 | PCB thickness (mil) | Pt | Thickness of the ordered PCB | 0.3–8 |
| 2 | Layer number | Ln | Number of copper layer. | 4–20 |
| 3 | Rogers material | Ro | Whether substrate material is Rogers. | 0/1 |
| 4 | Plating frequency | Plfr | Number of plating operation. | 0–4 |
| 5 | Number of operations | Noo | Number of operations to produce the order. | 16–71 |
| 6 | Number of Prepreg | NPP | Number of Prepreg for lamination | 1–50 |
| 7 | Scrap units in a set | Sus | Allowed maximum scrap units in a set. | 0–8 |
| 8 | Photoelectric board | Photb | Whether the order is the specified board. | 0/1 |
| 9 | High frequency board | Highfb | ||
| 10 | Test board | Semictb | ||
| 11 | Negative film plating | Nflp | Whether the order takes negative film plating. | |
| 12 | Tinning copper | Tinc | Whether the order has tinning copper. | |
| 13 | IPCIII standard | IPCIII | Whether the order takes IPCIII or Huawei standard. | |
| 14 | Huawei standard | Huawei | ||
| Feature of internal/outer layer line | ||||
| 15 | Minimum line width in internal layer (mil) | Mwil | Minimum line width or space in core boards | 3–100 |
| 16 | Minimum line space in internal layer(mil) | Mlsil | 1–137.66 | |
| 17 | Minimum line width in outer layer(mil) | Mwol | Minimum line width or space in outer layer | 1–157.5 |
| 18 | Minimum line space in outer layer (mil) | Mlsol | 1.2–290 | |
| 19 | Average residual rate | Arcr | Average residual rate of copper layer | 0.15%–94.75% |
| Feature and operation information of hole | ||||
| 20 | Solder resist plug hole | Srph | Whether the order has the specified hole related operation. | 0/1 |
| 21 | Plug hole with resin | Phwr | ||
| 22 | Second drilling | Secd | ||
| 23 | Back drilling | Bcdr | ||
| Operation information of character/solder mask | ||||
| 24 | Character print | Chaprt | Whether the order has the specified character/solder mask related operation. | 0/1 |
| 25 | White oil solder mask | White | ||
| 26 | Blue oil solder mask | Blue | ||
| 27 | Black oil solder mask | Black | ||
| Surface finishing operation options | ||||
| 28 | Hot-air solder leveling | Hasl | Whether the order takes the specified surface finishing operation. | 0/1 |
| 29 | Lead-free hot air solder leveling | Lfhasl | ||
| 30 | Entek | Osp | ||
| 31 | Cu/Ni/Au pattern plating | Cnapp | ||
| 32 | Gold finger plating | Gfig | ||
| 33 | Gold plating | Godp | ||
| 34 | Soft Ni/Au plating | Snap | ||
| 35 | Immersion Ag/Sn/Au | Iasa | ||
| Statistic items | ||||
| 36 | Delivery unit in a panel | Duap | Number of delivery unit in a panel | 1–262 |
| 37 | Supplemental feeding frequency | Supff | Material feeding frequency minus 1 | 0–14 |
| 38 | Required quantity | Reqq | Demand quantity of delivery unit minus delivery unit in inventory for the same order No. | 1–3000 |
| 39 | Required panel | Reqp | Reqq/Duap rounded up to the nearest integer | 1–225 |
| 40 | Feeding quantity | Fedq | Feeding number of delivery unit | 2–6296 |
| 41 | Least feeding panel | Lfp | Reqq/(1-scrap rate) rounded up to the nearest integer | 1–245 |
| 42 | Feeding panel | Fedp | Number of feeding panel | 1–308 |
| 43 | Scrap quantity | Scraq | Scrap number of delivery unit | 0–712 |
| 44 | Qualified quantity | Qualq | Qualified number of delivery unit | 1–6226 |
| 45 | Surplus quantity | Surpq | Qualq–Fedq | 0–3226 |
| 46 | Delivery unit area(m2) | Dunita | Area of a delivery unit | 0.001–0.393 |
| 47 | Required area(m2) | Reqa | Reqq × Dunita | 0.001–25.74 |
| 48 | Feeding area(m2) | Feda | Fedq × Dunita | 0.011–42.63 |
| 49 | Scrap area(m2) | Scraa | Scraq × Dunita | 0–15.39 |
| 50 | Qualified area(m2) | Quala | Qualq × Dunita | 0.009–37.49 |
| 51 | Surplus area(m2) | Surpa | Surpq × Dunita | 0–25.45 |
| 52 | Supplemental feeding rate | Supfr | Supff in a certain period/number of orders × 100% | 18.83% |
| 53 | Scrap rate | Scrar | Scraa/Feda × 100% | 0%–68.48% |
| 54 | Qualified rate | Qualr | Quala/Feda × 100% | 31.52%–100% |
| 55 | Surplus rate | Surpr | Surpa/Reqa × 100% | 0%–554.22% |
| 56 | Historical qualified rate | Hquar | The Qualr for the same order No. in the past 2 years | 8.824%–100% |
| C1 | C2 | C3 | Unclassified | |
|---|---|---|---|---|
| 0 | 29,157 | 29,157 | 29,157 | 0 |
| 0.1 | 29,156 | 27,608 | 29,157 | 0 |
| 0.2 | 28,922 | 3434 | 28,815 | 0 |
| 0.3 | 29,157 | 2193 | 15,529 | 0 |
| 0.4 | 21,230 | 973 | 7037 | 1355 |
| 0.5 | 17,717 | 393 | 3097 | 7951 |
| 0.6 | 8455 | 184 | 446 | 20,072 |
| 0.7 | 408 | 18 | 8 | 28,723 |
| 0.8 | 0 | 0 | 0 | 29,157 |
| 0.9 | 0 | 0 | 0 | 29,157 |
| 1 | 0 | 0 | 0 | 29,157 |
| Training Samples | Testing Samples | |
|---|---|---|
| C1 | 14,153 | 8432 |
| C2 | 649 | 1679 |
| C3 | 4691 | 3701 |
| All | 19,448 | 9709 |
| No. | Attributes | C1 | C2 | C3 | All | No. | Attributes | C1 | C2 | C3 | All |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Pt | ▲ | 22 | Secd | |||||||
| 2 | Ln | ▲ | ▲ | ▲ | ▲ | 23 | Bcdr | ▲ | ▲ | ▲ | ▲ |
| 3 | Ro | ▲ | ▲ | 24 | Chaprt | ||||||
| 4 | Plfr | 25 | White | ▲ | |||||||
| 5 | Noo | ▲ | ▲ | ▲ | ▲ | 26 | Blue | ||||
| 6 | NPP | ▲ | ▲ | 27 | Black | ||||||
| 7 | Sus | 28 | Hasl | ▲ | ▲ | ||||||
| 8 | Photb | ▲ | ▲ | 29 | Lfhasl | ▲ | |||||
| 9 | Highfb | 30 | Osp | ||||||||
| 10 | Semictb | ▲ | ▲ | 31 | Cnapp | ▲ | ▲ | ▲ | |||
| 11 | Nflp | 32 | Gfig | ▲ | |||||||
| 12 | Tinc | 33 | Godp | ▲ | ▲ | ||||||
| 13 | IPCIII | 34 | Snap | ||||||||
| 14 | Huawei | ▲ | ▲ | ▲ | ▲ | 35 | Iasa | ▲ | |||
| 15 | Mwil | ▲ | 36 | Duap | ▲ | ▲ | ▲ | ||||
| 16 | Mlsil | 37 | Reqa | ▲ | ▲ | ▲ | ▲ | ||||
| 17 | Mwol | ▲ | ▲ | 38 | Reqq | ▲ | ▲ | ▲ | ▲ | ||
| 18 | Mlsol | 39 | Reqp | ▲ | ▲ | ▲ | |||||
| 19 | Arcr | ▲ | 40 | Hquar | ▲ | ▲ | ▲ | ▲ | |||
| 20 | Srph | ▲ | ▲ | 41 | Dunita | ▲ | ▲ | ▲ | ▲ | ||
| 21 | Phwr | ▲ | ▲ | ▲ |
| Approaches | MSE | MAE | MAPE | Surpr_Pd(%) | Supfr Pd(%) |
|---|---|---|---|---|---|
| Manual feeding | 22.862 | 1.467 | 29.161 | 28.49 | 18.53 |
| BPN | 2.143 (−90.63%) | 0.759 (−48.26%) | 17.962 (−38.40%) | 16.85 (−40.86%) | 13.02 (−29.74%) |
| MSC–ANN | 1.272 (−94.44%) | 0.396 (−73.01%) | 5.542 (−81.00%) | 12.25 (−57.00%) | 12.78 (−31.03%) |
| FCM–-GABPN-w/o aggregation | 1.031 (−95.49%) | 0.364 (−75.19%) | 4.537 (−84.44%) | 11.88 (−58.30%) | 11.34 (−38.81%) |
| FCM–BPN | 0.984 (−95.70%) | 0.305 (−79.21%) | 3.423 (−88.26%) | 9.05 (−68.23%) | 13.86 (−25.20%) |
| FCM–GABPN | 0.935 (−95.91%) | 0.249 (−83.03%) | 3.041 (−89.57%) | 8.50 (−70.16%) | 12.78 (−31.03%) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, S.; Xian, R.; Li, D.; Zheng, B.; Jin, H. An FCM–GABPN Ensemble Approach for Material Feeding Prediction of Printed Circuit Board Template. Appl. Sci. 2019, 9, 4455. https://doi.org/10.3390/app9204455
Lv S, Xian R, Li D, Zheng B, Jin H. An FCM–GABPN Ensemble Approach for Material Feeding Prediction of Printed Circuit Board Template. Applied Sciences. 2019; 9(20):4455. https://doi.org/10.3390/app9204455
Chicago/Turabian StyleLv, Shengping, Rongheng Xian, Denghui Li, Binbin Zheng, and Hong Jin. 2019. "An FCM–GABPN Ensemble Approach for Material Feeding Prediction of Printed Circuit Board Template" Applied Sciences 9, no. 20: 4455. https://doi.org/10.3390/app9204455