1. Introduction
The design and operation of haulage systems are very important in mining sites. This is because mining costs may vary significantly according to the design and operation methods [
1]. Various simulation techniques have been used for haulage systems in mines [
2,
3,
4,
5,
6,
7,
8]. In the case of a mine truck haulage system, simulations may be used to predict productivity indices, such as the mine production and equipment utilization, according to system operating conditions, including the task time, amount of equipment, dispatch interval, and time consumed per unit task [
9,
10]. In this manner, it is possible to select optimal equipment combinations [
11,
12,
13,
14], establish equipment dispatch plans [
10,
15,
16,
17,
18], and identify optimal haulage routes [
19,
20,
21,
22].
The numerous simulation techniques that have been developed thus far are based on algorithms that consider the sequential tasks performed by trucks. However, algorithm-based simulation techniques have certain problems. Mines are dynamic systems and hence unexpected events often occur, such as failure of mining equipment and crusher capacity overflow. Accurate simulations require humans to design and develop haulage system logic, taking into account all events that may occur in a mining environment. In addition, it is necessary to modify existing algorithms to consider a new loading point or haulage road changes and several algorithms should be adapted to simulate real-time dispatching truck haulage systems.
To address these problems, technologies such as sensor networks, mobile devices, the Internet of things, and cloud computing have been introduced into mining sites, and researchers have been studying simulation techniques using big data collected on-site rather than algorithms based on prior knowledge [
23]. Moreover, deep learning has been attracting attention as a technology that efficiently analyzes big data according to its purpose [
24,
25]. Deep learning is an artificial intelligence technology that learns object characteristics hierarchically, without human interference, and improves the prediction performance by means of error evaluation [
26]. Deep learning was developed based on the deep neural network (DNN), which is a supervised machine-learning technique [
27]. DNNs imitate the neurons (nodes) and synapses that connect the neurons within the human brain. They have a multilayer perceptron structure in which an input layer, output layer, and one or more hidden layers are connected hierarchically [
28,
29,
30]. The nodes of each layer are connected to all nodes on the next layer, and the output values are determined through a feed-forward network [
31].
Various deep learning models based on the DNN have been developed by numerous researchers [
32]. Convolutional neural networks (CNNs) are used to learn two-dimensional pixel data, such as images and videos [
33]. A CNN is composed of a convolutional layer, pooling layer, and fully connected layer. It calculates the sum of weights between the training data and filter (or kernel) to extract detailed characteristics from images [
34]. A recurrent neural network (RNN) is a model suitable for learning time series data that change sequentially over time [
35]. It is mainly used to save the input elements of the previous time stage in the neural network and to predict the value of the next time stage [
36]. Furthermore, auto-encoders are models that continuously perform encoding and decoding tasks to analyze the characteristics of input values [
37,
38]. Deep belief networks are stochastic models that learn the stochastic distribution of input data in the form of stacks of restricted Boltzmann machines, in which the visible and hidden layers are connected bidirectionally [
39,
40].
In recent years, researchers have published reports on the use of deep learning in the mining industry. Deep learning technology has been applied in the exploration stage to detect anomalies [
41,
42,
43], analyze deposit potential [
44,
45,
46,
47], and classify downhole exploration data [
48]. Furthermore, Sayadi et al. [
49] used deep learning to classify ore and waste in a three-dimensional ore body model and to analyze the optimal pit limit. Deep learning models have also been developed to detect micro-seismic events [
50], evaluate the road roof status [
51], and quickly recognize mine water inrush to prevent underground safety incidents in the production stage [
52]. Moreover, deep learning has been used to develop a truck fuel consumption prediction system [
53], coal cutting pattern recognition system [
54], automatic iron ore quality control system [
55], and zinc ore recovery prediction system [
56]. However, at present, no studies exist on methods for using deep learning to predict major production index values by learning the characteristics of truck haulage systems from the big data of underground mining sites.
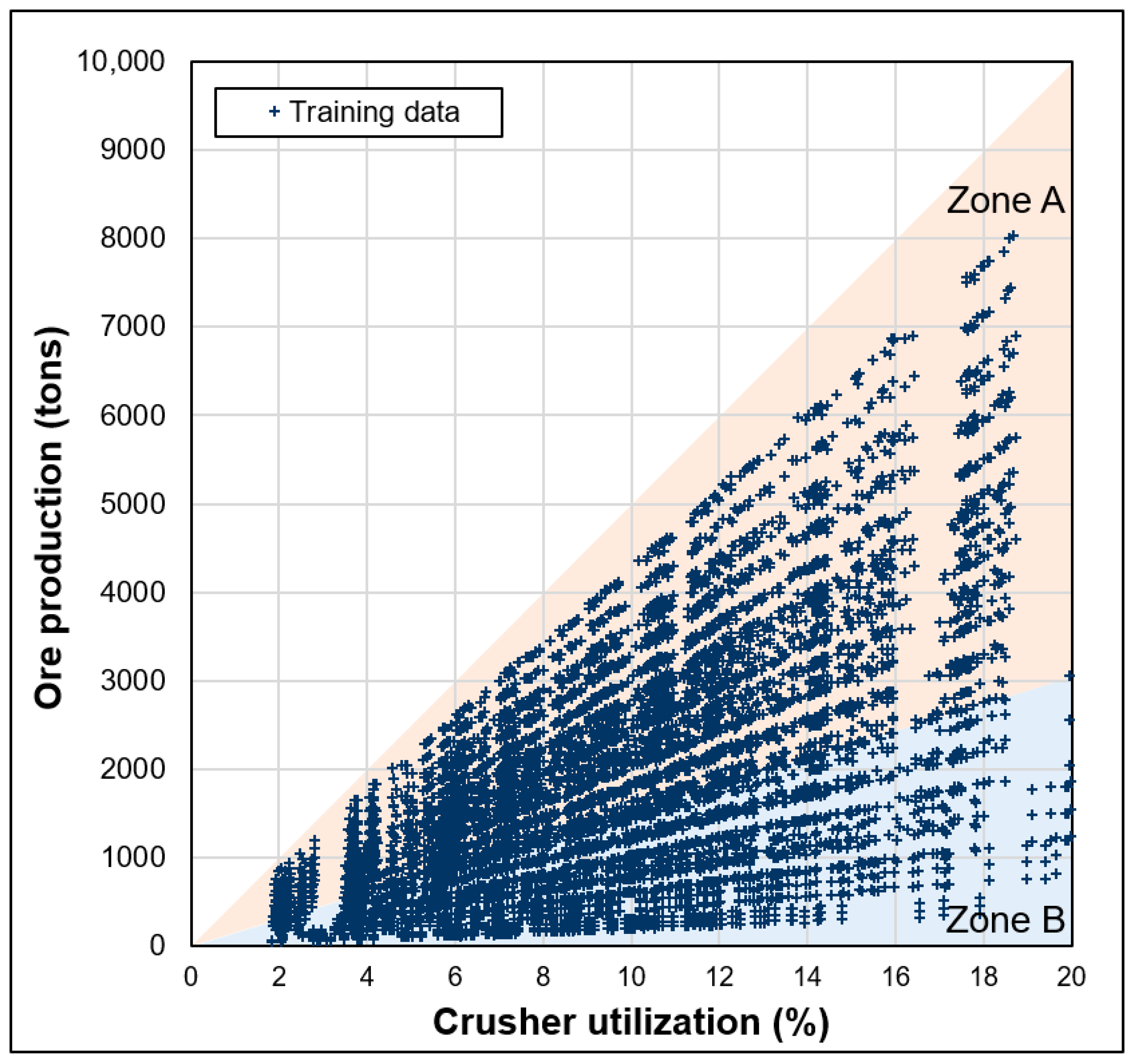
The aim of this study is to present a new method that uses a DNN model to predict the ore production and crusher utilization of an underground mine truck haulage system. An underground limestone mine equipped with an information & communications technology (ICT)-based mine safety management system was selected as the study area. Big data collected for 1 month in October 2018 were processed to create the DNN model training data. The numbers of hidden layers and hidden layer nodes of the DNN model were set to various values, and the coefficient of determination and mean absolute percentage error (MAPE) of the training and test data were analyzed to select the optimal DNN model. The completely trained DNN model was used to predict the ore production and crusher utilization for 10 days, starting on 1 November 2018, and the results were compared with the values observed on site.
2. Study Area
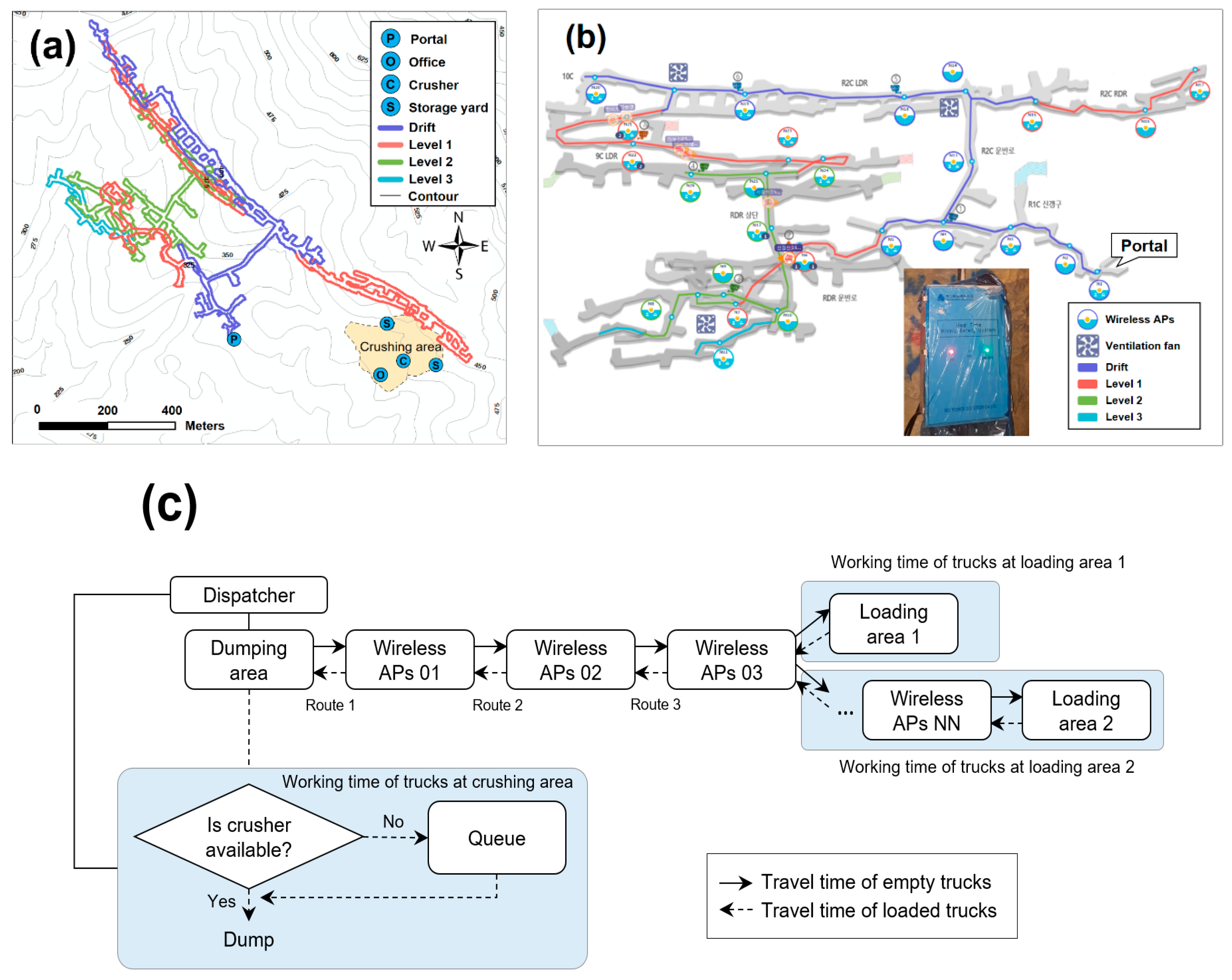
The Baekkwang Mineral Products Yeongcheon underground mine (37°4′14″, 128°18′48″), located in Danyang-gun, Chungcheongbuk-do, South Korea, was selected as the study area. This mine produces 1.2 million tons of limestone annually. The produced limestone is sorted according to its quality and shipped for use in steel, chemicals, and construction materials. The mine interior consists of drifts and three levels, while the exterior includes offices, a crusher, and two storage yards (see
Figure 1a).
The study area is equipped with an ICT-based mine safety management system. In such a system, a wireless network environment is created within the underground mine to track the movement of the equipment and workers in real time and to monitor the work environment to prevent casualties. In the study area, 37 wireless access points (APs) were installed in the pit and 3 were installed in the exterior crushing area to create a wireless communication network (see
Figure 1b). Wireless APs recognize the tags attached to the equipment and workers, and monitor the work environment in the pit, transmitting the collected information to a server in real time. The web server accumulates real-time data, including whether the equipment and workers have entered the pit, the work times, and data regarding the pit environment (for example, the temperature, humidity, and hazardous gas concentrations). Therefore, the mine safety management system creates big data, which records the mining work on a web server. Further details on the study area mine safety management system and big data can be found in Baek and Choi [
23].
In the mine, 25-ton dump trucks travel back and forth between the interior and exterior, hauling ore and waste (see
Figure 1c). The production manager considers the average quality of the ore that will be delivered that day, determines the positions and number of production work areas, and notifies the truck drivers of their destinations. The trucks that are provided with their destinations enter through the underground mine entrance and travel to the loading areas via Wireless APs 01, 02, and 03. After a loader has loaded a truck with ore, the truck exits the mine again, travels to the crushing area, and determines whether or not it can unload the ore in a hopper. If there are no trucks waiting to unload, the ore is immediately unloaded in the hopper. If there are trucks waiting, each truck waits for a fixed time. Trucks that have completed unloading enter the mine again to perform further haulage work.
6. Conclusions
In this study, a DNN-based deep learning model was trained for predicting the ore production and crusher utilization of a truck haulage system in an underground mine. An underground limestone mine was selected as the study area, and the DNN model input nodes were configured to reflect the truck haulage system of the study area. The DNN model was trained by setting various hidden layer configurations, and the coefficient of determination and MAPE for the training and test data were calculated to evaluate the model prediction accuracy. The DNN model was trained considering the haulage work operating conditions in the study area, and it was used to predict the ore production and crusher utilization over 10 days, starting on 1 November 2018. The predicted results were compared with the actual observed results.
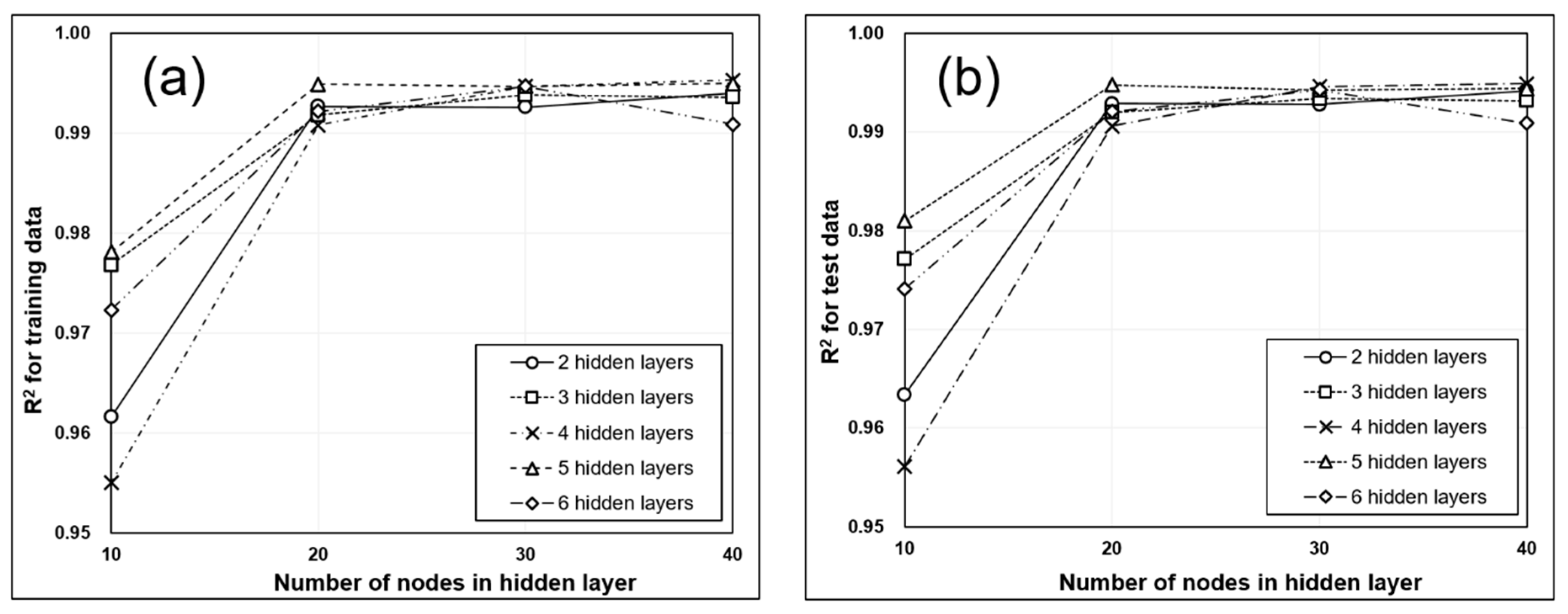
The prediction accuracy for the ore production was the highest when the number of hidden layers of the DNN model was set to four and the number of hidden layer nodes was set to 40. In this case, the coefficient of determination for the test data was approximately 0.99, while the MAPE was approximately 2.80%. The prediction accuracy for the crusher utilization was the highest when the number of hidden layers of the DNN model was set to four and the number of hidden layer nodes was set to 40. In this case, the coefficient of determination for the test data was approximately 0.99, while the MAPE was approximately 2.49%. The predicted ore production and crusher utilization for the 9 days of haulage work excluding 7 November tended to match the observed values. On 7 November, the trucks used a haulage path longer than that normally used to haul ore, and as a result, the predicted and observed values did not match. The RMSE of the ore prediction for the 9 days excluding 7 November was approximately 6.92 tons, while that for the crusher utilization was approximately 0.04%.
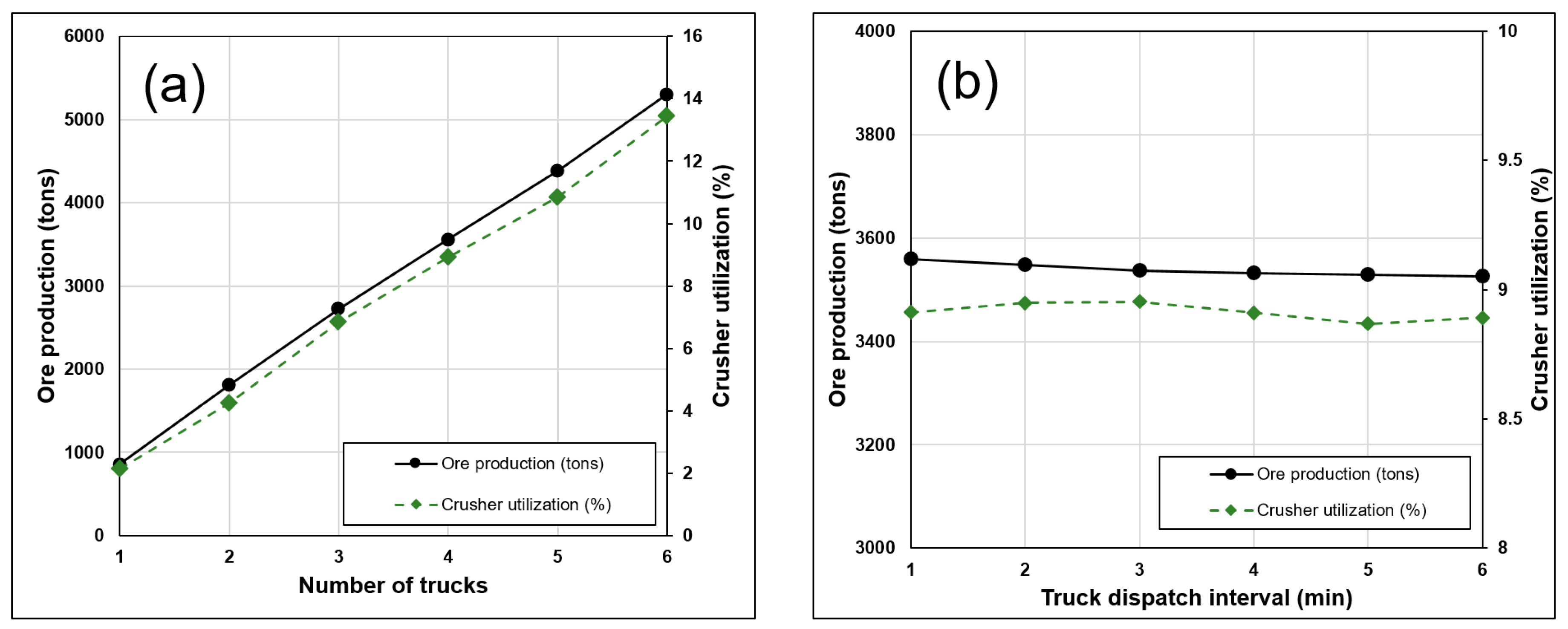
The DNN model input nodes were set considering the operating conditions of the ore haulage work performed on 5 November 2018. The number of trucks and truck dispatch interval were set to various values, and the changes in the ore production and crusher utilization were predicted. The results demonstrated that a daily ore production target of 3000 tons can be satisfied if the number of ore haulage trucks is set to four and the truck dispatch interval is set to 1 to 2 min. It was confirmed that the DNN model-based ore production and crusher utilization prediction methods presented in this study can be used for short-term or long-term mine haulage system design and prediction.
We trained the DNN models for ore production and crusher utilization prediction and tested them on the first 10 days of the following month. The DNN models predicted the target values accurately for 9 days; however, the models could not accurately predict the target value on the day the truck took a different path than usual. This may mean that the DNN models were successful because there was not a lot of variation between the routines of each day. The DNN models may only be memorizing the outputs given the inputs (over-fitting), which would make them very unreliable. To solve this problem, the models must be further trained such that the varying conditions of the mine can be taken into account. Alternatively, by training the model on a longer time span, all possible paths can be used as input parameters, and over-fitting can be avoided. Therefore, further studies are required in order to select a reasonable DNN model update cycle and determine the training data acquisition time span to consider various types of changing conditions in mines.
The results of the study confirmed that a DNN-based deep learning technique can learn sequential operations of a truck haulage system and analyze the correlation between truck haulage system operating conditions, ore production, and crusher utilization using big data acquired from the study area without human inference and algorithms based on prior knowledge. Moreover, it was found that trained DNN models can predict ore production and crusher utilization for 9 working days with low prediction errors. Thus, it would be possible to complement the limitations of existing algorithm-based simulation techniques.
In this study, a DNN model was selected from a variety of deep learning models and used to predict the ore production and crusher utilization. If time series data on ore production are collected to train an RNN model, the change patterns in the ore production over time can be analyzed, and the flow of future ore production changes can be predicted. Furthermore, if the costs of the ore production and haulage are considered and the mining rate of return is predicted, long-term operational mining plans can be established. Therefore, in the future, it will be necessary to perform additional studies on the use of various deep-learning models other than a DNN model to design and predict haulage systems.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}