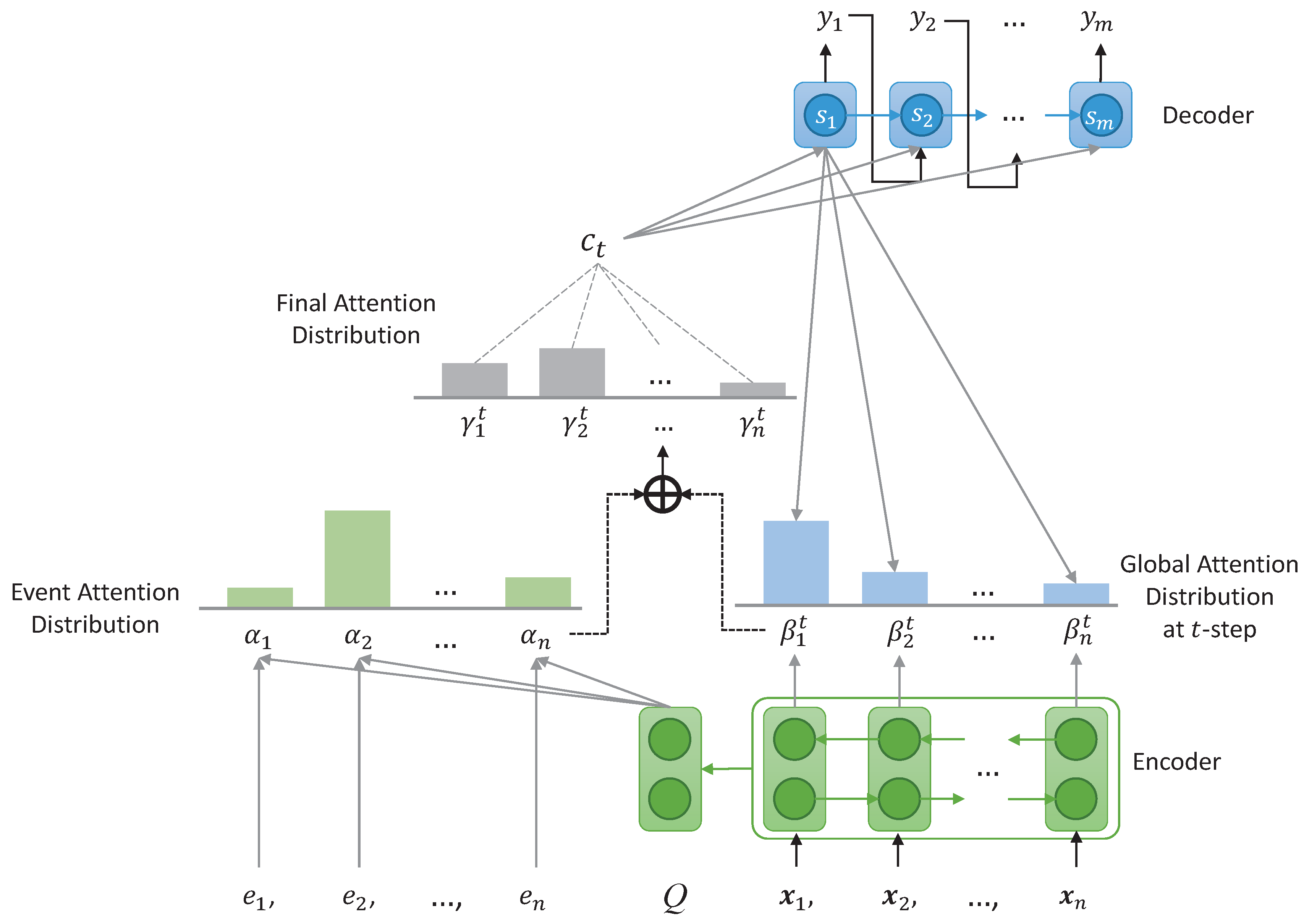
5.1. Experimental Setting
The proposed model is evaluated with three kinds of datasets: MSR dataset [
21] (see
Supplementary Materials), Filippova dataset [
9] (see
Supplementary Materials), and Korean sentence compression dataset. The simple statistics on each dataset is given in
Table 2. The MSR dataset proposed by Toutanova et al. is used for abstractive sentence compression. It consists of a newswires, business letters, journals, and technical documents from the Open American National Corpus, and the compressed sentences are created manually. In this dataset, the numbers of training, validation, and test examples are 21,145, 1908, and 3370 pairs, respectively. The average length of source sentences is 193.2, while that of target sentences is 133.6. Filippova dataset [
9] is used for deletion-based sentence compression. This dataset is automatically produced from Google News using the method proposed by Filippova et al [
6]. The total number of sentence pairs is 10,000, and target sentences have 13.7 fewer words than source sentences on average. The last Korean sentence compression dataset is designed for testing morphologically complex languages. This dataset contains 3117 source sentences from Korean news articles, and the sentences are split to 8:1:1 for training, validation, and test sets, respectively. Its target sentences are created by a native speaker and their length is short on average by 6.01 words when compared to the source sentences.
For the experiments below, the dimension of word embeddings is set as 256, and that of all hidden layers is set as 512. LSTM [
33] is used for the function
f in Equation (
3) and the hyperbolic tangent is used for the function
g in Equations (
5) and (
6). The proposed network is trained with batch size 64 and learning rate 0.001, and is optimized with an Adam optimizer [
38]. The value of
in Equation (
7) is 0.6 which is estimated using MSR validation set. BLEU [
23], ROUGE [
22], and compression ratio (CR) [
24] are used as evaluation metrics, where
CR is computed as
and
u is the number of sentences in a test set. Since the test set consists of pairs of a source sentence and its target sentence, the golden compression ratio can be computed from the test set. The golden compression ratio on MSR dataset is 68.60%, while those on Filippova dataset and Korean dataset are 42.62% and 47.52%, respectively. Two baselines are adopted for comparing the proposed model with existing models. One baseline is the standard sequence-to-sequence model proposed by Cho et al. [
16], and the other is the pointer generator [
19] in which the copy technique is applied to the sequence-to-sequence model.
5.2. Experimental Results
Table 3 shows the sentence compression performance on MSR dataset. In this table, ‘seq-to-seq’ and ‘PG’ denote the sequence-to-sequence model and the pointer generator, respectively. The model of Yu et al. is based on the sequence-to-sequence with a deletion decoder and a copy-generator decoder [
15]. Unlike the proposed model, it first conducts the deletion of a source sentence using the deletion decoder and then either generates words or copies the source sentence through the copy-generator decoder. According to the table, the use of event attention improves its base model. That is, ‘seq-to-seq + Event’ shows higher performance than ‘seq-to-seq’ in ROUGE metrics, and ‘PG + Event’ outperforms ‘PG’ in all metrics. In particular, ‘PG + Event’ achieves the best performance. On the other hand, the performance of Yu’s model is lower than ‘PG + Event’, even if it is also based on the copy mechanism. This is because the errors by the deletion decoder are easy to propagate to the copy-generation decoder in Yu’s model.
The compression ratios denoted as CR are also given in this table to see how much a method compresses source sentences. The value within parentheses denotes the difference between the compression ratio of a method and the golden ratio. As a result, the smaller the absolute value of the difference is, the better a method compresses source sentences. The golden compression ratio on MSR dataset is 68.60%, and the difference between it and the compression of ratio of ‘PG + Event’ is smallest as −0.63. This result implies that the proposed model is an effective compressor as well as a good writer.
Table 4 shows the results of sentence compression on Filippova dataset. When the event attention is applied to a baseline model, the performance of the baseline model improves. That is, ‘seq-to-seq + Event’ is better than ‘seq-to-seq’ and ‘PG + Event’ outperforms ‘PG’ for all evaluation metrics. The proposed model works effectively even with the dataset for deletion-based compression. However, in compression ratio, the proposed model is only slightly worse than ‘PG’. The golden compression ratio of Filippova dataset is 42.62%, but the compression ratio of ‘PG’ is 42.45% while that of ‘PG + Event’ is 41.70%. The main reason ‘PG’ is better than ‘PG + Event’ in compression ratio is that this dataset is designed for deletion-based compression.
To verify that the proposed model works for morphologically complex languages, we conducted sentence compression on Korean dataset.
Table 5 shows the result on Korean sentence compression. Overall, the proposed model outperforms all baselines. That is, ‘PG + Event’ shows the best performance for all metrics. One thing to note is that the performance difference between ‘PG + Event’ and ‘seq-to-seq + Event’ is large. This is because Korean dataset is relatively small, but its vocabulary size is large. Under this circumstance, the copy mechanism is much helpful in solving the out-of-vocabulary problem. In compression ratio, both ‘PG’ and ‘PG + Event’ are relatively closer to the golden compression ratio of Korean dataset. Please note that the overall performance of the proposed model for this dataset is lower than those for other datasets. This is because it is difficult to generate good Korean sentences with a small dataset since Korean is a morphologically complex language. However, even for this dataset, the proposed model outperforms its competitors.
Table 6 presents some examples of compressed sentences by ‘PG’ and ‘PG + Event’. Sentence 1 and 2 in this table are from MSR dataset, while Sentence 3 comes from Filippova dataset. Bold words indicate event words in all source sentences. The important phrases of Sentence 1 are ‘
80% of youth will report increased supervised time in safe environments’ and ‘
80% of participants will report increased conflict resolution skills’, and the phrases contain the event word ‘
report increased’. The compressed sentence by ‘PG’ is “
Anticipated outcomes from the spring survey include supervised increased conflict % of participants will report increased conflict resolution.” which misses the important information such as ‘
supervised time in safe environments’ and thus delivers distorted meaning from the source sentence. On the other hand, the compressed sentence by the proposed ‘PG + Event’ delivers more precise meaning than that by ‘PG’, since it contains ‘
80% of youth will report in safe environments’ and ‘
they will report increased conflict resolution skills.’
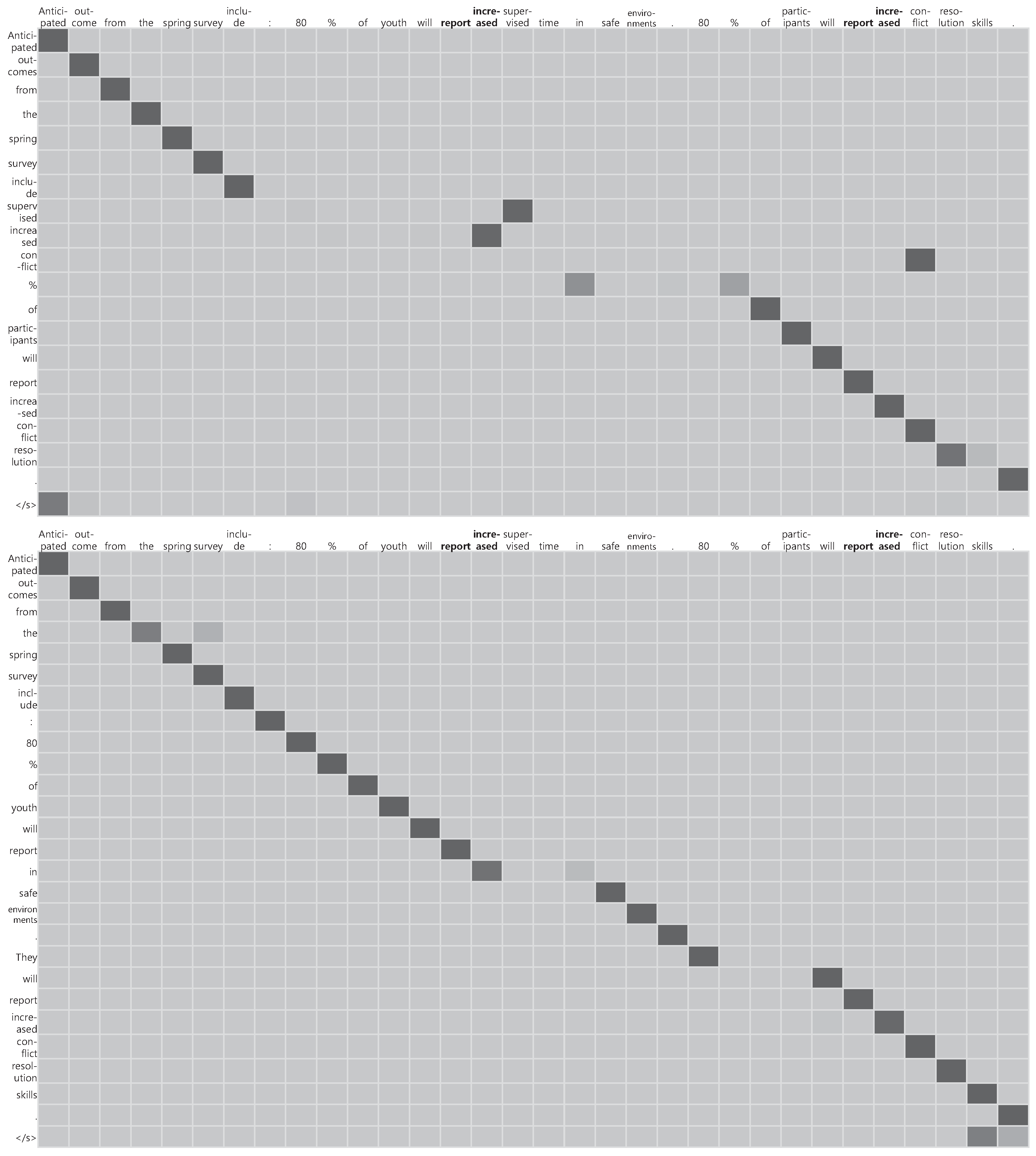
To verify the attention weights when decoding, the weights for Sentence 1 are shown in
Figure 2. The figure shows the source sentence in the horizontal axis and the generated sentence in the vertical axis. The darker the color of each word cell is, the heavier the attention weight of the word is. The upper figure shows the compressed sentence by ‘PG’ and the bottom one is by ‘PG + Event’. The bold tokens are those recognized as event words. In the attention by ‘PG’, after the word ‘
include’, attention should have given to ‘
youth’ and ‘
increased supervised time’ or ‘
in the safe environments’, but is given to a wrong word ‘
conflict’. As a result, ‘PG’ generates ‘
participants will report increased conflict resolution’. In the bottom figure, the attention weights by‘PG + Event’ are relatively ideal. The model is attentive to all event words, and the words are generated in the compressed sentence. In addition, globally important phrases such as ‘
youth’, ‘
safe environments’, and ‘
conflict resolution skills’ get attentive, and then the compressed sentence is generated semantically correctly. Since the proposed model is designed to consider both event words and global information, it can generate an effective compressed sentence.
Sentence 2 also shows the superiority of the proposed model. The important phrases of the source sentence is ‘
support is needed to maintain and expand’ and ‘
help the American Cancer Society continue’. As a compressed sentence, ‘PG’ generates ‘
nature much to maintain these comprehensive programs. The American Cancer Society’s vital work’ which is wrong semantically and grammatically. On the other hand, the compressed sentence by‘PG + Event’ is ‘
Support the American Cancer Society continue its vital work and help to maintain.’ This sentence contains the event word ‘
support’ and delivers the meaning of source sentence correctly. Lastly, Sentence 3 is sampled from Filippova dataset and is shorter than other examples. The key information of the source sentence is ‘
report that their glass door shattered.’ ‘PG + Event’ generates ‘
reporting their glass door shattered’ in which salient words such as ‘
report’ and ‘
shatter’ are involved. As a result, one can find out ‘
glass door shatters’ from the compressed sentence, but not from the compressed sentence by ‘PG’. The sentence by ‘PG’ is grammatically incomplete and the fact related to ‘
homeowners reporting’ is not found.
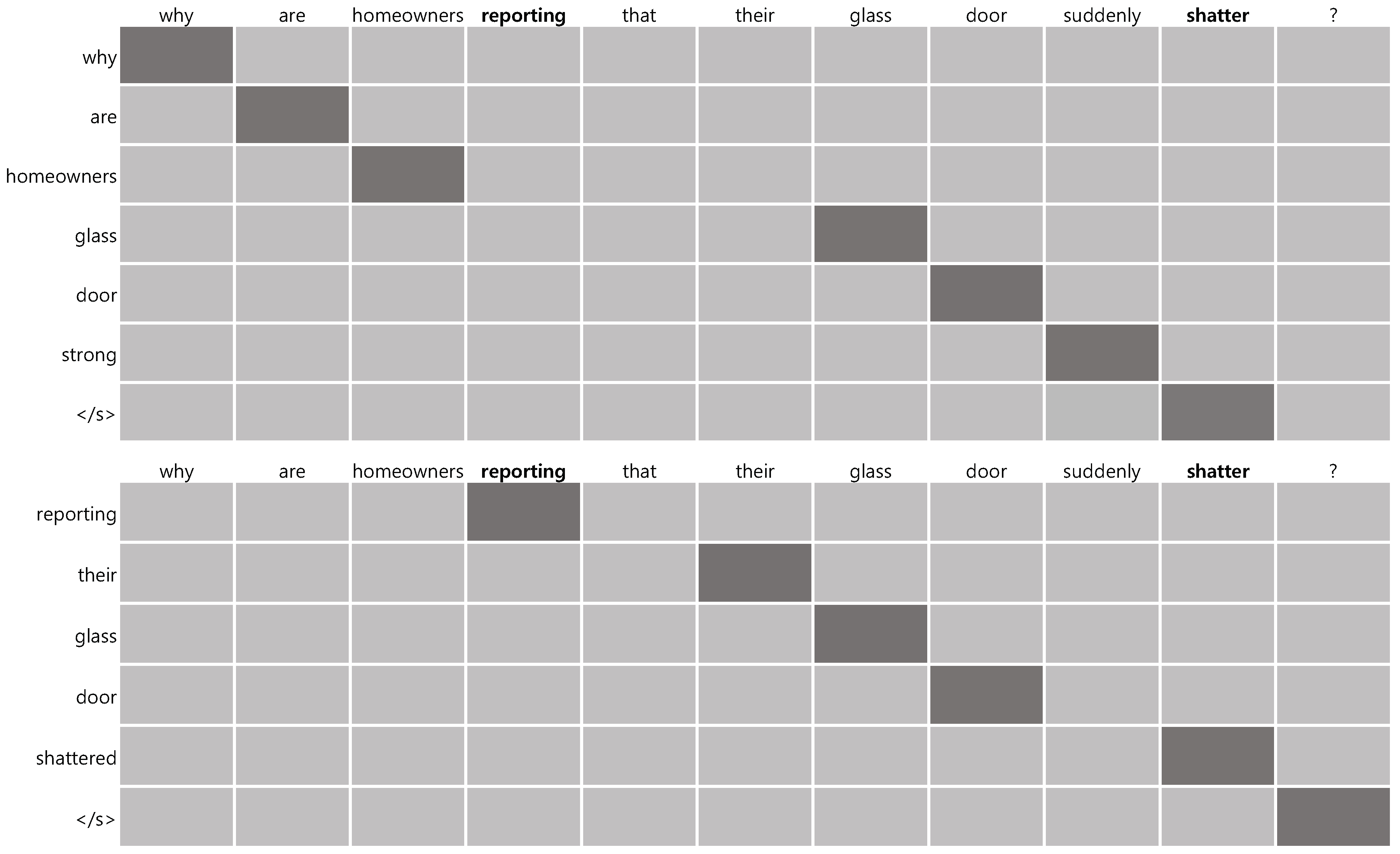
Figure 3 shows attention weights for the source sentence of Sentence 3. The top figure is the weights by ‘PG’ and the bottom is those by ‘PG + Event’. ‘PG’ does not regard ‘
reporting’ as a salient word, and thus it does not generate the word in the compressed sentence. In addition, even if ‘
shattered’ is attentive, it generates ‘
strong’ instead of it. On the other hand, ‘PG + Event’ pays attention to ‘
reporting’ and ‘
shatter’ as important information in terms of event. In addition, the globally salient phrase ‘
their glass door’ is also focused by ‘PG + Event’. As a result, ‘PG + Event’ is able to generate a compressed sentence which is semantically and grammatically correct. These examples show that it is effective for sentence compression to use event attention as well as global attention.






{kind=link}
{kind=link}
{kind=link}