3.1.1. Dataset Introduction and Experiment Description
The data used in this paper for experimental validation were provided by Case Western Reserve University (CWRU), Cleveland, Ohio, USA. As shown in
Figure 6, the test stand consists of an electronic motor, a torque transducer, a dynamometer, and control electronics. Single point faults were introduced to the test bearings using electro-discharge machining. Faults were set on the rolling elements, the outer races, and the inner races, and each fault bearing was installed in the test ring, which was run at a constant speed for motor loads of 0, 746, 1492, and 2238W, with motor speeds corresponding to 1797, 1772, 1750, and 1730 rpm. A more detailed introduction can be found on the CWRU Bearing Data website [
39].
In this experiment, sample data were collected at 12 kHz, and detailed information is listed in
Table 1. A motor load of 746W with corresponding motor speeds of 1772 rpm was selected. Datasets, including a normal condition (N), an outer race fault (ORF), a ball fault (BF), and an inter race fault (IRF), with fault diameters of 0.18, 0.36, and 0.54 mm. and a fault depth of 0.3mm, were selected. We chose 150 samples for each defect diameter with the same fault type, in which 100 samples at a motor load of 746W were used for training, and the remaining 50 samples were used for testing. Therefore, each fault type included 450 samples; 300 samples and 150 samples of which were respectively used as training and testing samples. Detailed information on the bearing datasets is provided in
Table 2.
3.1.2. Spectral Characteristic Analysis and IMFs Screening
Before processing, the raw signal was analyzed preliminarily. The rotating frequency of the shaft is 29.5Hz. According to the bearing parameters and the shaft rotating frequency, the fault characteristic frequencies of each part can be calculated [
40]. The characteristic frequencies of IRF, ORF and BF are
Hz,
Hz and
, respectively. The time domain signals of four different conditions and their spectra figures are shown in
Figure 7. It can be seen the main frequency components of normal condition are concentrated within 2000 Hz, and main characteristic frequencies are 87.89 Hz, 1066 Hz and 2104 Hz, which are 3, 36 and 71 times of the frequency conversion respectively. The main frequency components of ORF are concentrated, and 2449 Hz, 2602 Hz, 2707 Hz, 2871 Hz and 3357 Hz are the main frequency components, and only 2449 Hz is the frequency doubling of the shaft rotating frequency and its characteristic frequency. The main frequency components are also concentrated in BF spectrum, 3217 Hz and 3480 Hz are the frequency doubling of the rotating frequency and its characteristic frequency. The main frequency components of IRF are multiple and scattered, and only 2742 Hz and 3539 Hz are the frequency doubling of the rotating frequency and its characteristic frequency. From the above spectrum analysis, it can be seen that only a few of the main frequency components in each state are frequency conversion and frequency doubling of their fault characteristic frequencies, and there are many interference frequencies.
The signal samples were initially preprocessed with EEMD.
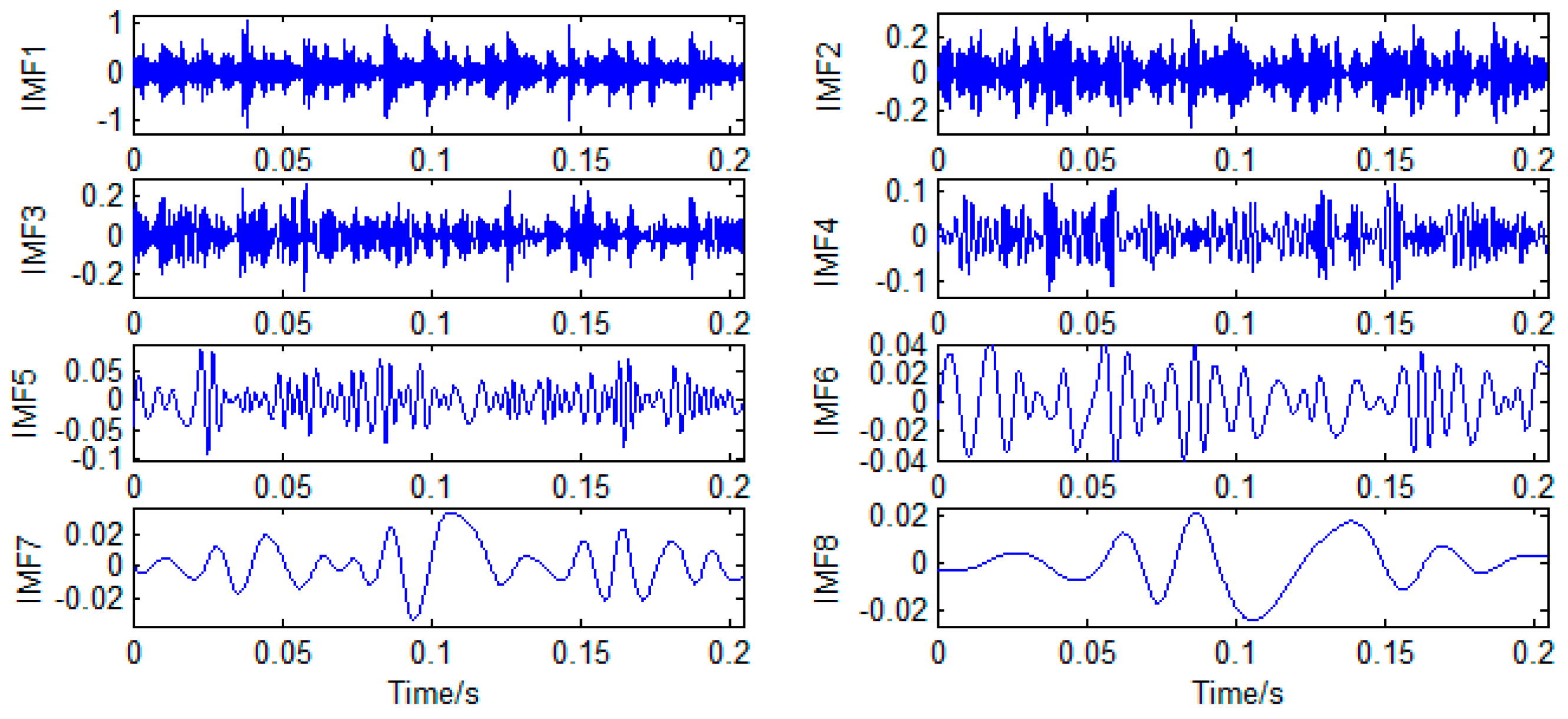
Figure 8 shows IMFs of a BF signal sample. As can be deduced from the IMF waveform, the first five-order IMFs contain sufficient frequency components, and IMF6–IMF8 may be low-frequency false components. As shown in
Figure 9, (a) is spectrogram of a BF sample, and (b) are the spectrogram of its eight-order IMFs. It can be seen that IMF1 to IMF5 contain the main characteristic frequency components of the raw signal from high frequency to low frequency, respectively. IMF5 is followed by low-frequency false components. So the first five-order IMFs were selected for the subsequent feature extraction.
3.1.3. Scale Factor Selection and Feature Extraction Analysis
In the PE feature extraction process, as described in
Section 2.3,
was selected as 5, and
was set as 1. Moreover, the range of scale factor
also plays an important role in feature extraction performance. The maximum scale factor 20 is selected for analysis, and the MPE curves of four types of samples are obtained as shown in
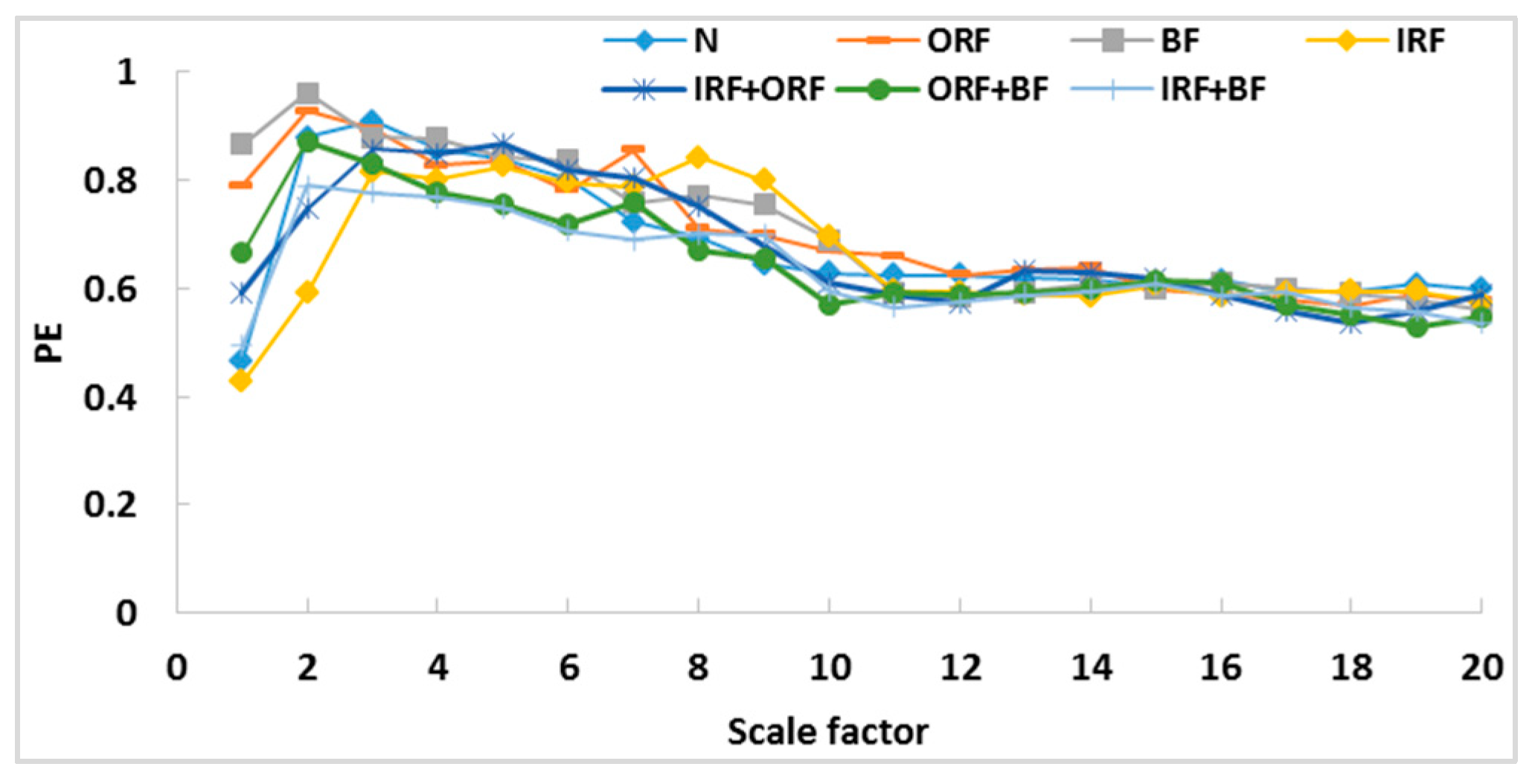
Figure 10. It can be seen that the MPE values increase first and then decrease with the increase of scale factor. At the same time, when scale factor is greater than 10, the trend of the MPE curves of different types tend to converge, which indicates that the complexity of different vibration signals tends to decrease at the same rate. This means that when the scale factor is greater than 10, it has little significance for PE to describe the complexity of the signal. As such, the scale factor was selected as 10.
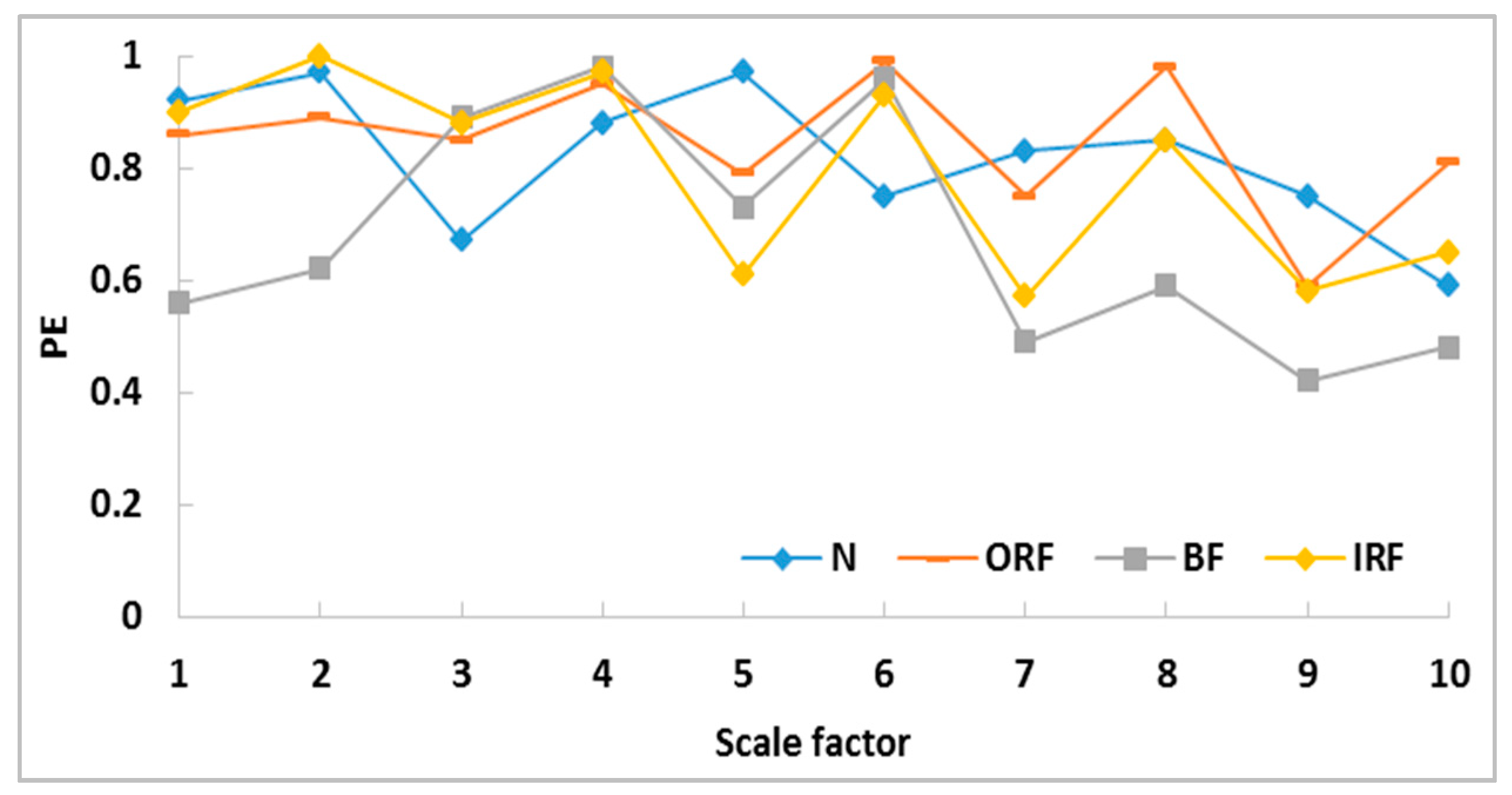
Figure 11 shows the MPE of the raw vibration signals in the four health conditions. The PE of the vibration signals with different health conditions has similar fluctuation intervals, and the intensity of fluctuation is also similar. Simultaneously, there are overlaps and intersections in the PE fluctuation range.
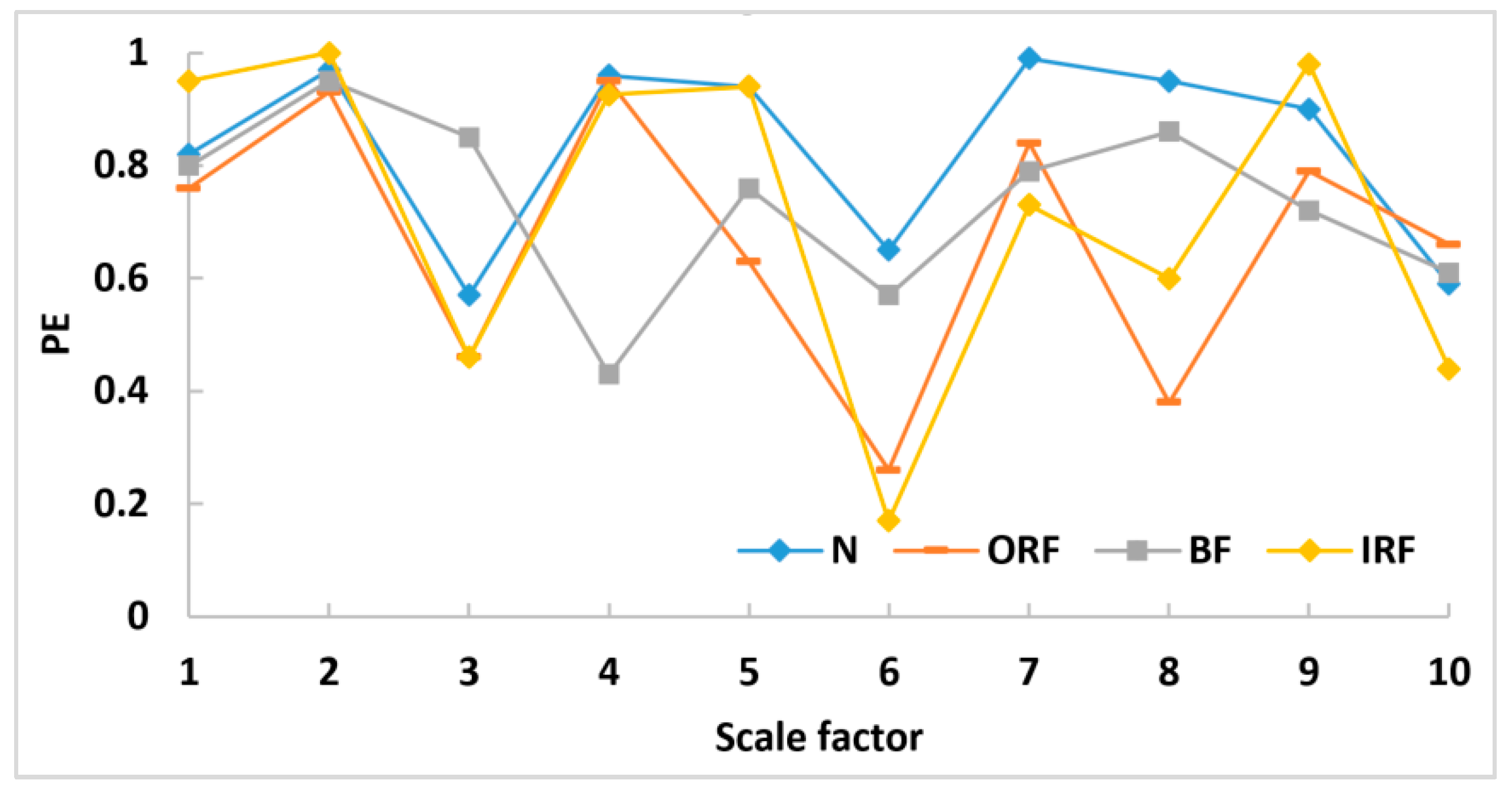
Figure 12 and
Figure 13 show the MPE of IMF1 and IMF3 for the four health conditions, respectively. The fluctuation intensity in IMF1 and IMF3 both vary greatly compared with that shown in
Figure 11, and the MPE of IMF3 varies more than that of IMF1. In other words, the MPE features of IMF3 are more separable than those of IMF1 and those of the raw signal. However, the fluctuation intervals of PE still overlap. Therefore, it is not easy to directly distinguish faults with MPE parameters.
As the raw signal contains a great deal of useful information, the MPE of the raw signal was considered and fused with the IMF permutation entropy to enrich the information of the extracted feature vector. According to the training samples (N, ORF, BF, and IRF), the MPE of the selected IMFs and the raw signals were extracted. The MPE of the raw signal was recorded as MPE
i, which is a 10-dimensional vector. The MPE of the first five-order IMFs was recorded as MPE
j. Therefore, the final feature vector
is obtained as follows:
The dimension of the feature vector is 60. Through the above feature extraction method, the obtained feature vector considers the correlation of the IMFs and the raw signals themselves. It also takes advantage of MPE to characterize weak fault signals, which is beneficial in terms of establishing more abundant and comprehensive feature extraction. According to the above method, the feature vectors of all experimental samples were extracted. The MPE feature vector was then used as for input in the SSDAE network for training and testing.
3.1.4. Validation Results
As mentioned in
Section 2.4.2., the proposed SSDAE contains two hidden layers. The neuron numbers of the first and second hidden layers were set to 100 and 60, respectively. The number of output layer neurons was four, which was determined by the number of bearing health conditions. The activation function was sigmoid, and the learning rates of the two hidden layers and the softmax layer were 0.1, 0.1, and 0.2, respectively. The sparsity parameter was 0.15, and the corruption level was 0.3. The detailed parameters of the SSDAE are listed in
Table 3.
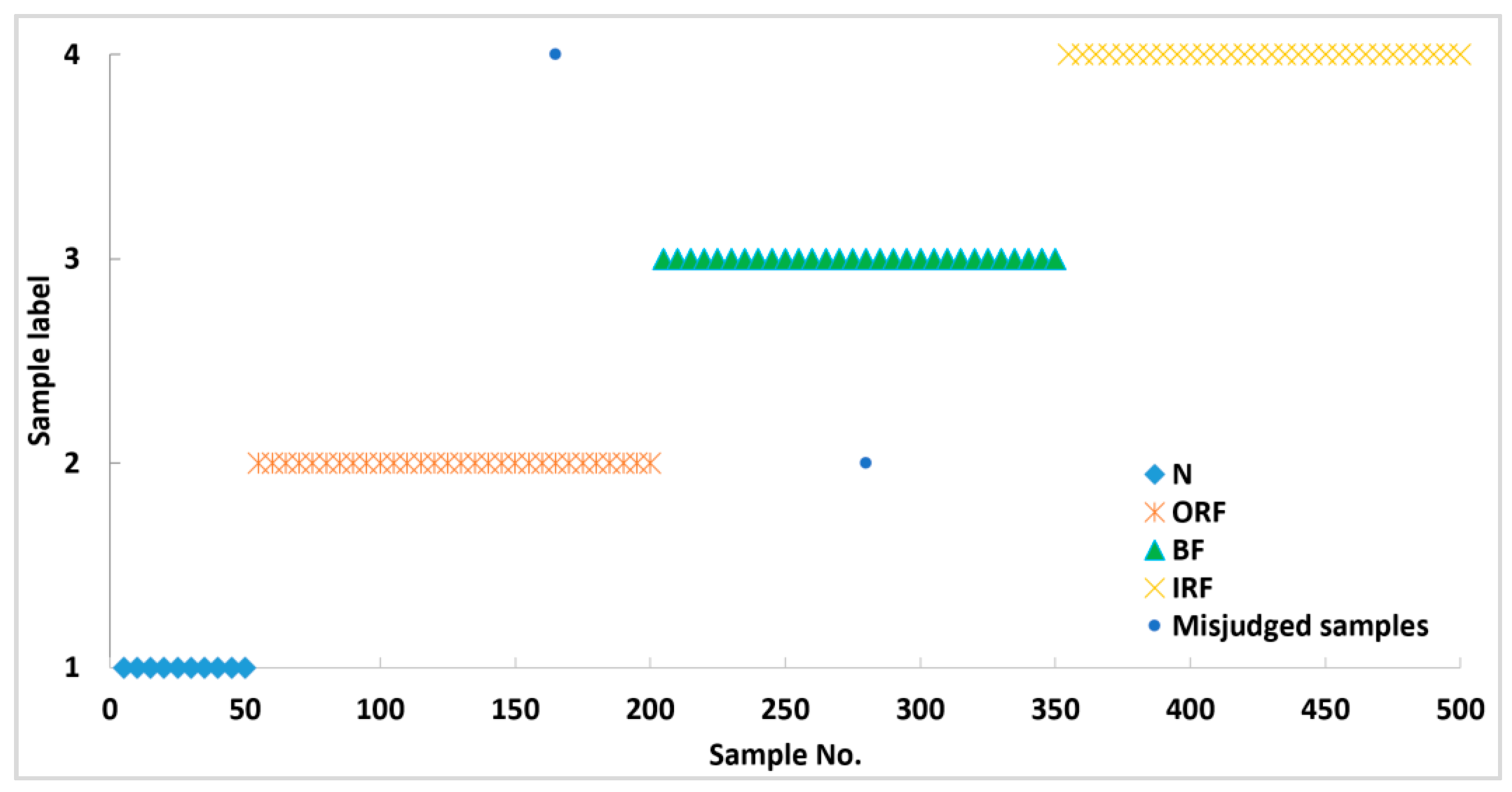
The extracted feature vector was divided into training and testing data. The former was used to train the constructed network, and the latter was used to validate the performance of the diagnosis model. Four tests were carried out, with an average classification accuracy of 99.55%. One of the test classification results is shown in
Figure 14. According to the classification result, 498 out of 500 test samples were identified accurately. All samples of N and IRF were identified accurately, and only two samples were misjudged: one BF sample was misjudged as an ORF, and one ORF sample was misjudged as an IRF. The classification accuracy rate was 99.6% (498/500 = 99.6%). The experimental result shows that the proposed method based on MPE and the SSDAE can effectively detect bearing faults, and the recognition and analysis effect in different working conditions is ideal.
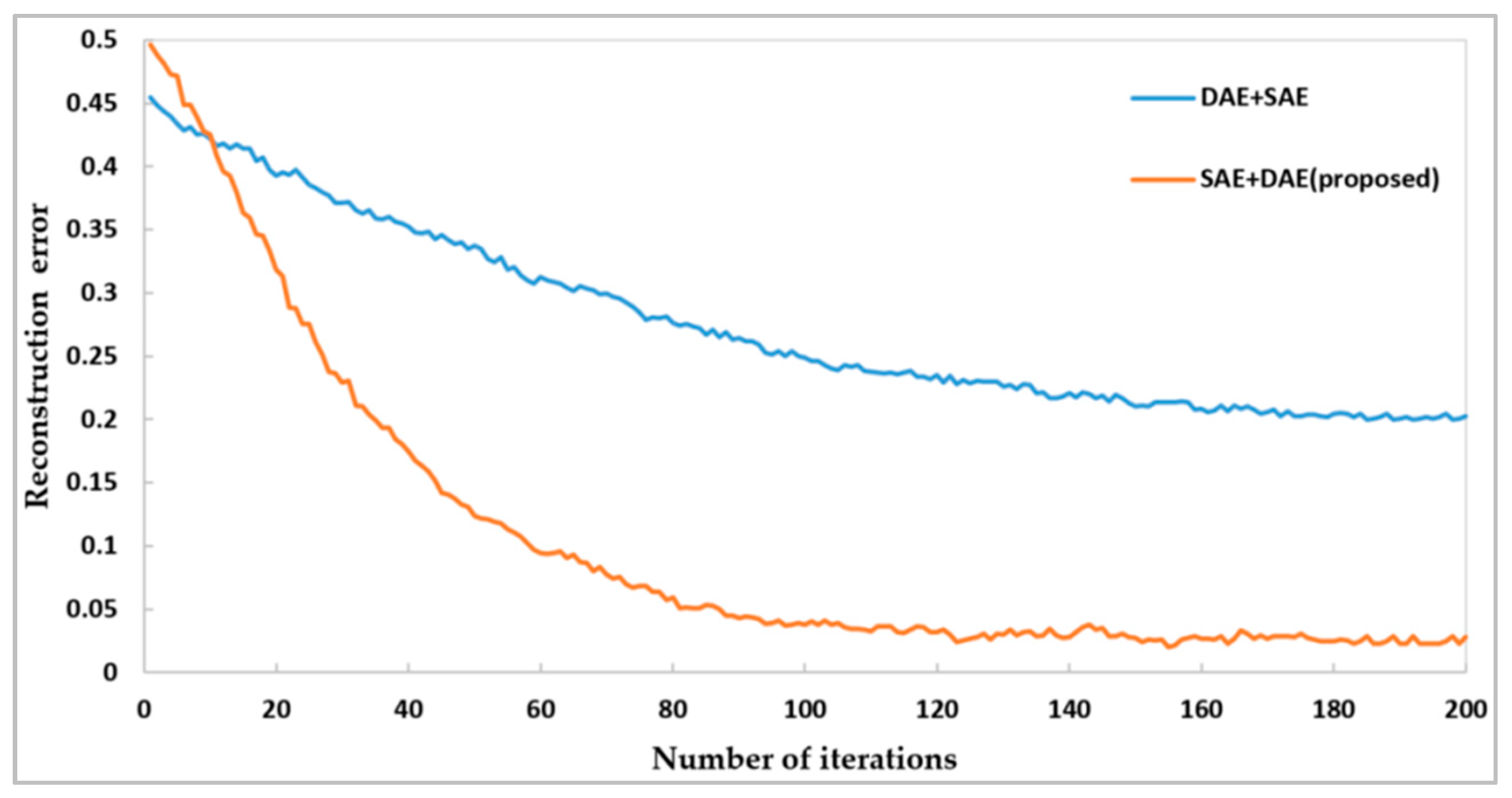
To further validate the superiority of the proposed SSDAE model structure, a comparative experiment of a different stack order, Scheme 1 (SAE + DAE), with Scheme 2 (DAE + SAE) was conducted. According to the training process of the SSDAE model, the experimental results of the two schemes were compared in the same experimental condition.
Figure 15 shows that the reconstruction error of both schemes decreases as iterations increase. In Scheme 1, the reconstruction error is less than 0.05 after 100 iterations, and with the increase in iterations, the reconstruction error is stable at about 0.025. In Scheme 2, the reconstruction error is less than 0.25 after 100 iterations. With the increase in iterations, the reconstruction error decreases slowly. As the number of iterations reaches 200, the reconstruction error is still as high as 0.2. However, at the beginning of training, the reconstruction error of Scheme 1 is slightly larger than that of Scheme 2. With the increase in iterations, the reconstruction error of Scheme 1 decreases rapidly and is less than that of Scheme 2. Therefore, (the proposed) Scheme 1 is superior to Scheme 2 in terms of the real reconstruction error. One possible reason for this result is that when human visual systems process information, its mechanism is similar to sparse coding. That is, a single neuron only responds strongly to certain information. Most of the neurons in the hidden layer are suppressed, and input data are represented by sparse components. Therefore, the ability of the SAE to extract representative features is better than that of the DAE. The DAE model itself can erase the noise in the training data because the noise data is close to the test data, which can reduce the generation gap between the training and test data. Thus, in Scheme 1, the SAE is first used to extract a better feature description of the input, and the DAE is then used to enhance the robustness of feature extraction and reduce the generation gap between the training set and the testing set. Therefore, the reconstruction error of Scheme 1 was smaller. Thus, Scheme 1 would help improve the classification accuracy.
Figure 16 shows that the time required of the two schemes decreases with the increase in iterations. Each iteration time of Scheme 1 (SAE + DAE) and Scheme 2 (DAE + SAE) tends to stabilize after about 120 iterations and 80 iterations, respectively, mainly because the network has been fully trained. However, regardless of the number of iterations, Scheme 1 takes less time than Scheme 2, and each iteration time is stable at about 1s and 5s, respectively. The possible reason for this finding is that, in our experiment, the input of the SSDAE is a high-dimensional vector, and the proposed Scheme 1 starts training the SAE first, which ensures that the dimension reduction is implemented at the beginning of network training. Therefore, the network could be trained quickly from the low-dimensional vector, so each iteration time is reduced.
Some key parameters considerably influence classification accuracy or time consumption, such as the number of hidden layer neurons, the sparsity parameter, and the corruption level. Therefore, to analyze the impacts of different parameters on the diagnosis result, experiments for each parameter with different values are carried out for comparison.
The number of hidden layer neurons is important for the feature learning and classification accuracy of the SSDAE.
Figure 17 shows the relationship between the number of neurons in two hidden layers with classification accuracy and time consumption. Considering dimension reduction, the number of neurons in the second hidden layer was set to be less than that in the first hidden layer, but equal or a little more than half of that in the first layer.
Figure 17 shows that the classification accuracy improves gradually as the number of neurons increases. Notably, when the number of neurons in the first layer is more than 100, the classification accuracy tends to be stable, but time consumption increases linearly. Therefore, to ensure both high classification accuracy and quicker calculation speed, the number of neurons in the two hidden layers was selected as 100 and 60, respectively.
A proper sparsity parameter not only improves the feature learning ability of the network but also improves the computing efficiency. The sparsity parameter is usually a small value that is no greater than 0.5. So, the performance with sparsity parameters varying from 0.05 to 0.5 was studied in our experiments. The experimental results are shown in
Figure 18.
Figure 18 shows that with the increase in sparse parameter values, the classification accuracy increases gradually and then decreases gradually. When the sparsity value is greater than 0.25, the diagnosis accuracy obviously decreases. Therefore, the best diagnosis performance is obtained when the sparsity parameter is 0.15.
An excessive corruption level value may excessively remove useful information, and too small a value will affect the filtering of redundant information, thus affecting the diagnosis accuracy. The effect on classification accuracy of different corruption level values is shown in
Figure 19. With the increase in the corruption level value, the classification accuracy increases gradually, and then decreases gradually. When the corruption level value is greater than 0.2 and less than 0.35, stable high classification accuracy rates are observed. When the corruption level value is greater than 0.35, the classification accuracy obviously decreases. Therefore, the best diagnosis performance is obtained when the corruption level is 0.3.
In order to know the layer-by-layer feature extraction effect of the SSDAE, the dimension reduction technology of t-SNE (t-distributed stochastic neighbor embedding) is used to reduce the dimension of each layer feature of a test set to 2 dimensions and visualize it [
41]. The visualization results are shown in
Figure 20. It can be seen that in the scatter plot of input data, the four states of samples are basically mixed together, and the degree of sample aggregation is poor. For each hidden layer, the features of each category are aggregated once. After the second hidden layer, each type has been basically separated. This shows that the feature distribution is greatly improved by SSDAE layer by layer feature extraction, and the ability of feature expression and distinction is stronger, thus ensuring the effective realization of subsequent state recognition and classification.
Commonly used classification models, such as the traditional stacked AE, SVM, and back-propagation neural network (BPNN), were used to validate and compare the effectiveness of the proposed SSDAE. The stacked AE has the same structure as the SSDAE. The input, hidden, and output dimensions of the BPNN were 200, 100, and 4, respectively, and sigmoid was used as an activation function. The SVM used the Gaussian kernel function. As shown in
Table 4, the four methods used the same signal preprocessing (EEMD) and feature extraction (MPE) models in addition to the classification models mentioned above.
The classification results of each health condition and the total classification accuracy are shown in
Table 4. The results demonstrate that the proposed method achieved the highest classification accuracy (99.6%), and the classification accuracy of each condition was also higher than the others. By comparing the first two shallow architecture methods with the last two deep learning methods, we found that, in the case of the same signal processing and feature extraction methods, methods based on the SSDAE or the stacked AE have higher classification accuracy than SVM and BPNN. This shows that deep learning method has a stronger ability in terms of feature learning and abstraction than shallow intelligent diagnosis method, especially in the case of a large number of samples with high-dimension and multi-classification issues. In addition, the SSDAE-based method achieved a higher accuracy than the stacked AE-based method, which proves that the proposed SSDAE outperforms the traditional stacked AE in extracting more representative features.
To further verify the effectiveness of the proposed feature extraction method, wavelet packet-empirical mode decomposition (WP-EMD) [
42], variational mode decomposition and permutation entropy (VMD-PE) [
43], and improved empirical mode decomposition energy entropy (EMDEE) [
44] were considered for comparison. The features extracted by the above methods were input into the SSDAE for classification, and the classification accuracies are shown in
Table 5. The proposed method achieved the highest total classification accuracy and performed better in most health conditions. Through the comparison, we observed that the feature extraction methods based on PE have higher classification accuracy than the EMD-based methods. This shows that MPE could effectively characterize and extract the volatility characteristics of different signals and mine the representative features for further diagnosis.


































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}