A Method to Detect Type 1 Diabetes Based on Physical Activity Measurements Using a Mobile Device


Abstract
:Featured Application
Abstract
1. Introduction
2. Background
2.1. Available Methods of Assessing Physical Activity
2.2. Pedometers and Accelerometers in Physical Activity Measuring
2.3. ActiGraph Activity Monitor
2.4. Methods to Compare New and Traditional Accelerometer Data
3. Materials and Methods
3.1. Data Source
- General and BMI parameters:
- Age
- Sex
- Weight
- Height
- Physical activity parameters (per week):
- Step count
- Sedentary activity minutes
- Light activity minutes
- Moderate activity minutes
- Vigorous activity minutes
- Type 1 diabetes presence (binary parameter)
3.2. Classification Methods
3.2.1. Support Vector Machine
3.2.2. Probabilistic Neural Network
3.2.3. Multilayer Perceptron
3.2.4. Group Method of Data Handling
3.2.5. Gene Expression Programming
3.2.6. Linear Regression
3.2.7. Radial Basis Function Network
3.2.8. Logistic Regression
3.2.9. Decision Tree
3.2.10. Random Forests
3.3. Validation Methods
3.3.1. Accuracy
3.3.2. Sensitivity
3.3.3. Specificity
3.3.4. Precision
3.3.5. AUC
3.3.6. Goodness Index
- optimum, when G ≤ 0.25,
- good, when 0.25 < G < 0.70,
- random, if G = 0.70,
- bad, if G > 0.70 [40].
3.4. Other Data Analysis Methods
3.4.1. Clustering Method
- Data assignment: each data point is assigned to its nearest centroid, based on the squared Euclidean distance. If is the collection of centroids in set C, then each data point x is assigned to a cluster based on:where is the standard Euclidean distance. is the set of data point assignments for each cluster centroid.
- Centroid update: centroids are recomputed by taking the mean of all data points assigned to that centroid’s cluster.
3.4.2. Feature Selection Methods
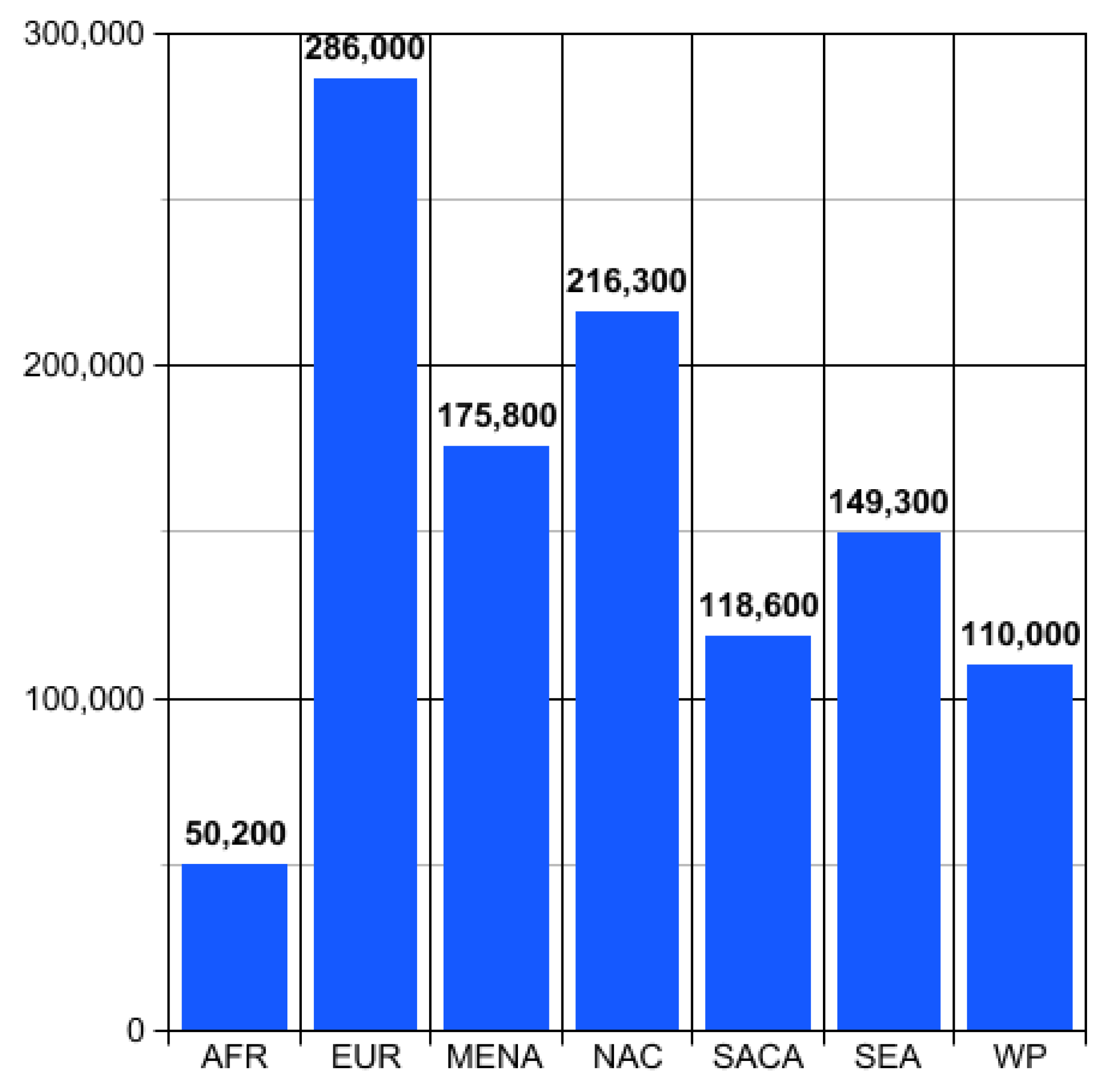
4. Results
4.1. Data Analysis Results
4.2. Classification Result
4.3. Clustering Result
5. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ADA | American Diabetes Association |
| AUC | Area under the receiver operating characteristic curve |
| BMI | Body mass index |
| DT | Decision tree |
| EE | energy expenditure |
| FN | False negative |
| FP | False positive |
| FR | Feature ranking |
| G | Goodness index |
| GEP | Gene expression programming |
| GMDH | Group method of data handling |
| LPA | light physical activity |
| MLP | Multilayer perceptron |
| MPA | moderate physical activity |
| PNN | Probabilistic neural network |
| RBF | Radial basis function |
| RF | Random forest |
| SVM | Support vector machine |
| TN | True negative |
| TP | Truth positive |
| WHO | World Health Organization |
| VPA | vigorous physical activity |
References
- American Diabetes Association. Diagnosis and classification of diabetes mellitus. Diabetes Care 2009, 33 (Suppl. 1), 62–67. [Google Scholar]
- Tatoń, J.; Czech, A.; Bernas, M. Edukacja terapeutyczna, samokontrola glikemii i psychologia cukrzycy. Terapeutyczny styl życia. In Diabetologia Kliniczna; Tatoń, J., Czech, A., Bernas, M., Eds.; PZWL: Warsaw, Poland, 2008; pp. 339–429. [Google Scholar]
- World Health Organization. Global Strategy on Diet, Physical Activity and Health; WHO Library Cataloguing-in-Publication Data; World Health Organization: Geneva, Switzerland, 2004; pp. 1–18. [Google Scholar]
- Iannotti, R.J.; Kalman, M.; Inchley, J.; Tynjälä, J.; Bucksch, J.; The HBSC Physical Activity Focus Group. Social determinants of health and well-being among young people. In Health Behaviour in School-Aged Children (HBSC) Study: International Report from the 2009/2010 Survey; Currie, C., Ed.; WHO Regional Office for Europe: Copenhagen, Denmark, 2012; pp. 129–132. [Google Scholar]
- Faigenbaum, A. Physical Activity in Children and Adolescents. ACSM Bull. 2015. Available online: https://www.acsm.org/ (accessed on 16 October 2018).
- International Diabetes Federation. IDF Diabetes Atlas. Eighth Edition 2017; International Diabetes Federation: Brussels, Belgium, 2017; Volume 8, pp. 1–150. [Google Scholar]
- Pettitt, D.J.; Talton, J.; Dabelea, D.; Divers, J.; Imperatore, G.; Lawrence, J.M.; Liese, A.D.; Linder, B.; Mayer-Davis, E.J.; Pihoker, C.; et al. Prevalence of Diabetes in U.S. Youth in 2009: The SEARCH for Diabetes in Youth Study. Diabetes Care 2014, 37, 402–408. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Czenczek-Lewandowska, E. Level of Physical Activity in Children and Adolescents with type 1 Diabetes, Relative to the Insulin Therapy Applied. Ph.D. Thesis, University of Rzeszów, Rzeszów, Poland, 2017; pp. 1–165. [Google Scholar]
- Czenczek-Lewandowska, E.; Grzegorczyk, J.; Mazur, A. Physical activity in children and adolescents with type 1 diabetes and contem-porary methods of its assessment. Pediatr. Endocrinol. Diabetes Metab. 2018, 24, 179–184. [Google Scholar] [CrossRef] [PubMed]
- Allen, N.; Gupta, A. Current Diabetes Technology: Striving for the Artificial Pancreas. Diagnostics 2019, 9, 31. [Google Scholar] [CrossRef] [PubMed]
- Strath, S.J.; Kaminsky, L.A.; Ainsworth, B.E.; Ekelund, U.; Freedson, P.S.; Gary, R.A.; Richardson, C.R.; Smith, D.T.; Swartz, A.M. Guide to the Assessment of Physical Activity: Clinical and Research Applications A Scientific Statement From the American Heart Association. Circulation 2013, 128, 2259–2279. [Google Scholar] [CrossRef]
- Katch, V.L.; McArdle, W.D.; Katch, F.I. Energy expenditure during rest and physical activity. In Essentials of Exercise Physiology, 4th ed.; McArdle, W.D., Katch, F.I., Katch, V.L., Eds.; Lippincott Williams & Wilkins: Baltimore, MD, USA, 2011; pp. 237–262. [Google Scholar]
- Sylvia, L.G.; Bernstein, E.E.; Hubbard, J.L. Practical Guide to Measuring Physical Activity. J. Acad. Nutr. Diet. 2014, 114, 199–208. [Google Scholar] [CrossRef]
- Hills, A.P.; Mokhtar, N.; Byrne, N.M. Assessment of Physical Activity and Energy Expenditure: An Overview of Objective Measures. Front. Nutr. 2014, 1, 1–14. [Google Scholar] [CrossRef]
- Tanaka, C.; Hikihara, Y.; Ando, T.; Oshima, Y.; Usui, C.; Ohgi, Y.; Kaneda, K.; Tanaka, S. Prediction of Physical Activity Intensity with Accelerometry in Young Children. Int. J. Environ. Res. Public Health 2019, 16, 931. [Google Scholar] [CrossRef]
- Van Hees, V.T.; Pias, M.; Taherian, S.; Ekelund, U.; Brage, S. A method to compare new and traditional accelerometry data in physical activity monitoring. In Proceedings of the 2010 IEEE International Symposium on “A World of Wireless, Mobile and Multimedia Networks”, Montrreal, QC, Canada, 14–17 June 2010; pp. 1–6. [Google Scholar]
- Vijay, R.; Watts, A.; Watts, V. Daily Physical Activity Patterns During the Early Stage of Alzheimer’s Disease. J. Alzheimer’s Dis. 2016, 55, 659–667. [Google Scholar]
- Bonato, P.; Sherrill, D.M.; Standaert, D.G.; Salles, S.S.; Akay, M. Data mining techniques to detect motor fluctuations in Parkinson’s disease. Conf. Proc. IEEE Eng. Med. Biol. Soc. 2004, 7, 4766–4769. [Google Scholar] [PubMed]
- Ahmadi, M.; O’Neil, M.; Fragala-Pinkham, M.; Lennon, N.; Trost, S. Machine learning algorithms for activity recognition in ambulant children and adolescents with cerebral palsy. J. Neuroeng. Rehabil. 2018, 15, 105. [Google Scholar] [CrossRef] [PubMed]
- Quante, M.; Cespedes Feliciano, E.M.; Rifas-Shiman, S.L.; Mariani, S.; Kaplan, E.R.; Rueschman, M.; Oken, E.; Taveras, E.M.; Redline, S. Association of Daily Rest-Activity Patterns With Adiposity and Cardiometabolic Risk Measures in Teens. J. Adolesc. Health 2019. [Google Scholar] [CrossRef] [PubMed]
- Kanna, K.R.; Sugumaran, V.; Vijayaram, T.R.; Karthikeyan, C.P. Activities of Daily Life (ADL) Recognition using Wrist-worn Accelerometer. Int. J. Eng. Technol. (IJET) 2016, 8, 1406–1413. [Google Scholar]
- Welk, G.J. Use of accelerometry-based activity monitors to assess physical activity. In Physical Activity Assessments for Health-Related Research; Welk, G.J., Ed.; Human Kinetics Publishers: Champaign, IL, USA, 2002; pp. 125–142. [Google Scholar]
- Crouter, S.E.; Horton, M.; Bassett, D.R. Validity of ActiGraph Child-Specific Equations during Various Physical Activities. Med. Sci. Sports Exerc. 2013, 45, 1403–1409. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hekler, E.B.; Buman, M.P.; Grieco, L.; Rosenberger, M.; Winter, S.J.; Haskell, W.; King, A.C. Validation of Physical Activity Tracking via Android Smartphones Compared to ActiGraph Accelerometer: Laboratory-Based and Free-Living Validation Studies. JMIR MHealth UHealth 2015, 3, e36. [Google Scholar] [CrossRef] [PubMed]
- Migueles, J.H.; Cadenas-Sanchez, C.; Ekelund, U.; Delisle Nyström, C.; Mora-Gonzalez, J.; Löf, M.; Labayen, I.; Ruiz, J.R.; Ortega, F.B. Accelerometer Data Collection and Processing Criteria to Assess Physical Activity and Other Outcomes: A Systematic Review and Practical Considerations. Sports Med. 2017, 47, 1821–1845. [Google Scholar] [CrossRef] [PubMed]
- Jacob, E. Classification and Categorization: A Difference that Makes a Difference. Libr. Trends 2004, 52, 515–540. [Google Scholar]
- Huang, S.; Cai, N.; Pacheco, P.P.; Narrandes, S.; Wang, Y.; Xu, W. Applications of Support Vector Machine(SVM) Learning in Cancer Genomics. Cancer Genom. Proteom. 2018, 15, 41–51. [Google Scholar]
- Taborri, J.; Palermo, E.; Rossi, S. Automatic Detection of Faults in Race Walking: A Comparative Analysis of Machine-Learning Algorithms Fed with Inertial Sensor Data. Sensors 2019, 19, 1461. [Google Scholar] [CrossRef]
- Sun, Q.; Lin, F.; Yan, W.; Wang, F.; Chen, S.; Zhong, L. Estimation of the Hydrophobicity of a Composite Insulator Based on an Improved Probabilistic Neural Network. Energies 2018, 11, 2459. [Google Scholar] [CrossRef]
- Nazzal, J.M.; El-Emary, I.M.; Najim, S.A. Multilayer Perceptron Neural Network (MLPs) For Analyzing the Properties of Jordan Oil Shale. World Appl. Sci. J. 2008, 5, 546–552. [Google Scholar]
- Li, R.Y.M.; Fong, S.; Chong, W.S. Forecasting the REITs and stock indices: Group Method of Data Handling Neural Network approach. Pac. Rim Prop. Res. J. 2017, 23, 1–38. [Google Scholar] [CrossRef]
- Ferreira, C. The Basic Gene Expression Algorithm. In Gene Expression Programming: Mathematical Modeling by an Artificial Intelligence; Springer: Berlin, Germany, 2006; pp. 55–120. [Google Scholar]
- Godfrey, K. Simple Linear Regression in Medical Research. N. Engl. J. Med. 1985, 313, 1629–1636. [Google Scholar] [CrossRef] [PubMed]
- Acosta, F.M.A. Radial basis function and related models: An overview. Signal Process. 1995, 45, 37–58. [Google Scholar] [CrossRef]
- Peng, C.Y.J.; Lee, K.L.; Ingersoll, G.M. An Introduction to Logistic Regression Analysis and Reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Tree-Based Methods. In An Introduction to Statistical Learning with Applications in R; Springer: New York, NY, USA, 2017; pp. 303–336. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Brisimi, T.; Xu, T.; Wang, T.; Dai, W.; Adams, W.; Paschalidis, I. Predicting Chronic Disease Hospitalizations from Electronic Health Records: An Interpretable Classification Approach. Proc. IEEE 2018, 106, 690–707. [Google Scholar] [CrossRef]
- Taborri, J.; Scalona, E.; Palermo, E.; Rossi, S.; Cappa, P. Validation of Inter-Subject Training for Hidden Markov Models Applied to Gait Phase Detection in Children with Cerebral Palsy. Sensors 2015, 15, 24514–24529. [Google Scholar] [CrossRef] [Green Version]
- Wilkin, G.A.; Huang, X. K-Means Clustering Algorithms: Implementation and Comparison. In Second International Multi-Symposiums on Computer and Computational Sciences (IMSCCS 2007); IEEE: Lowa City, IA, USA, 2007. [Google Scholar]
- Cilia, N.; De Stefano, C.; Fontanella, F.; Raimondo, S.; di Freca, A.S. An Experimental Comparison of Feature-Selection and Classification Methods for Microarray Datasets. Information 2019, 10, 109. [Google Scholar] [CrossRef]
- Rodgers, J.L.; Nicewander, W.A. Thirteen Ways to Look at the Correlation Coefficient. Am. Stat. 1988, 42, 59–66. [Google Scholar] [CrossRef]
- Robert, C. An entropy concentration theorem: Applications in artificial intelligence and descriptive statistics. J. Appl. Probab. 1990, 27, 303–313. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Sherrod, P. DTREG Predictive Modeling Software. 2003. Available online: www.dtreg.com (accessed on 12 February 2019).
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Michel, V.; Gramfort, A.; Varoquaux, G.; Eger, E.; Keribin, C.; Thirion, B. A supervised clustering approach for fMRI-based inference of brain states. Pattern Recognit. 2012, 45, 2041–2049. [Google Scholar] [CrossRef] [Green Version]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Proc. Int. Jt. Conf. Artif. Intell. 1995, 14, 1137–1143. [Google Scholar]
- Übeyli, E.D. Implementing automated diagnostic systems for breast cancer detection. Expert Syst. Appl. 2007, 33, 1054–1062. [Google Scholar] [CrossRef]
- Nahar, J.; Imam, T.; Tickle, K.S.; Chen, Y.P. Computational intelligence for heart disease diagnosis: A medical knowledge driven approach. Expert Syst. Appl. 2013, 40, 96–104. [Google Scholar] [CrossRef]
- Malik, S.; Khadgawat, R.; Anand, S.; Gupta, S. Non-invasive detection of fasting blood glucose level via electrochemical measurement of saliva. SpringerPlus 2016, 5, 701. [Google Scholar] [CrossRef]
- Tudor-Locke, C.; Craig, C.L.; Beets, M.W.; Belton, S.; Cardon, G.M.; Duncan, S.; Hatano, Y.; Lubans, D.R.; Olds, T.S.; Raustorp, A.; et al. How many steps/day are enough? for children and adolescents. Int. J. Behav. Nutr. Phys. Act. 2011, 8, 78. [Google Scholar] [CrossRef] [PubMed]
- Cerna, L.; Maresova, P. Patients’ attitudes to the use of modern technologies in the treatment of diabetes. Patient Prefer Adherence 2016, 10, 1869–1879. [Google Scholar] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Activity Label | Cut Point | |
|---|---|---|
| From | To | |
| Sedentary | 0 | 149 |
| Light | 150 | 499 |
| Moderate | 500 | 3999 |
| Vigorous | 4000 | 7599 |
| Very Vigorous | 7600 | ∞ |
| Feature Name | Score | |
|---|---|---|
| 1 | step count | 0.2362 |
| 2 | vigorous activity minutes | 0.0505 |
| 3 | moderate activity minutes | 0.0469 |
| 4 | sedentary activity minutes | 0.0408 |
| 5 | light activity minutes | 0.0127 |
| Feature Name | Score | |
|---|---|---|
| 1 | vigorous activity minutes | 0.1435 |
| 2 | moderate activity minutes | 0.1375 |
| 3 | step count | 0.084 |
| … | … | 0 |
| Algorithm Name | Acc(%) | Sen(%) | Spe(%) | Prec(%) | G | AUC |
|---|---|---|---|---|---|---|
| Decision Tree Forest | 86.09 | 87.83 | 84.35 | 84.87 | 0.1983 | - |
| PNN | 84.35 | 89.57 | 79.13 | 81.10 | 0.2333 | 0.926578 |
| SVM | 84.35 | 86.96 | 81.74 | 82.64 | 0.2244 | 0.909716 |
| Single tree | 83.48 | 86.09 | 80.87 | 81.82 | 0.2365 | - |
| GEP | 83.04 | 83.48 | 82.61 | 82.76 | 0.2399 | 0.830435 |
| Logistic regression | 82.61 | 84.35 | 80.87 | 81.51 | 0.2472 | 0.883478 |
| GMDH | 82.61 | 82.61 | 82.61 | 82.61 | 0.2460 | 0.905482 |
| RBF network | 82.17 | 85.22 | 79.13 | 80.33 | 0.2557 | 0.905331 |
| MLP | 81.30 | 86.09 | 76.52 | 78.57 | 0.2729 | 0.897921 |
| Linear regression | 80.87 | 85.22 | 76.52 | 78.40 | 0.2774 | 0.884008 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Czmil, A.; Czmil, S.; Mazur, D. A Method to Detect Type 1 Diabetes Based on Physical Activity Measurements Using a Mobile Device. Appl. Sci. 2019, 9, 2555. https://doi.org/10.3390/app9122555
Czmil A, Czmil S, Mazur D. A Method to Detect Type 1 Diabetes Based on Physical Activity Measurements Using a Mobile Device. Applied Sciences. 2019; 9(12):2555. https://doi.org/10.3390/app9122555
Chicago/Turabian StyleCzmil, Anna, Sylwester Czmil, and Damian Mazur. 2019. "A Method to Detect Type 1 Diabetes Based on Physical Activity Measurements Using a Mobile Device" Applied Sciences 9, no. 12: 2555. https://doi.org/10.3390/app9122555