Image Super-Resolution Algorithm Based on Dual-Channel Convolutional Neural Networks



Abstract
:1. Introduction
2. Related Works
2.1. The SCRNN Model
2.2. Image Super-Resolution Algorithm Based on Dual-Channel Convolutional Neural Networks
3. Dual-Channel Convolutional Neural Networks
3.1. The Improved Ideas
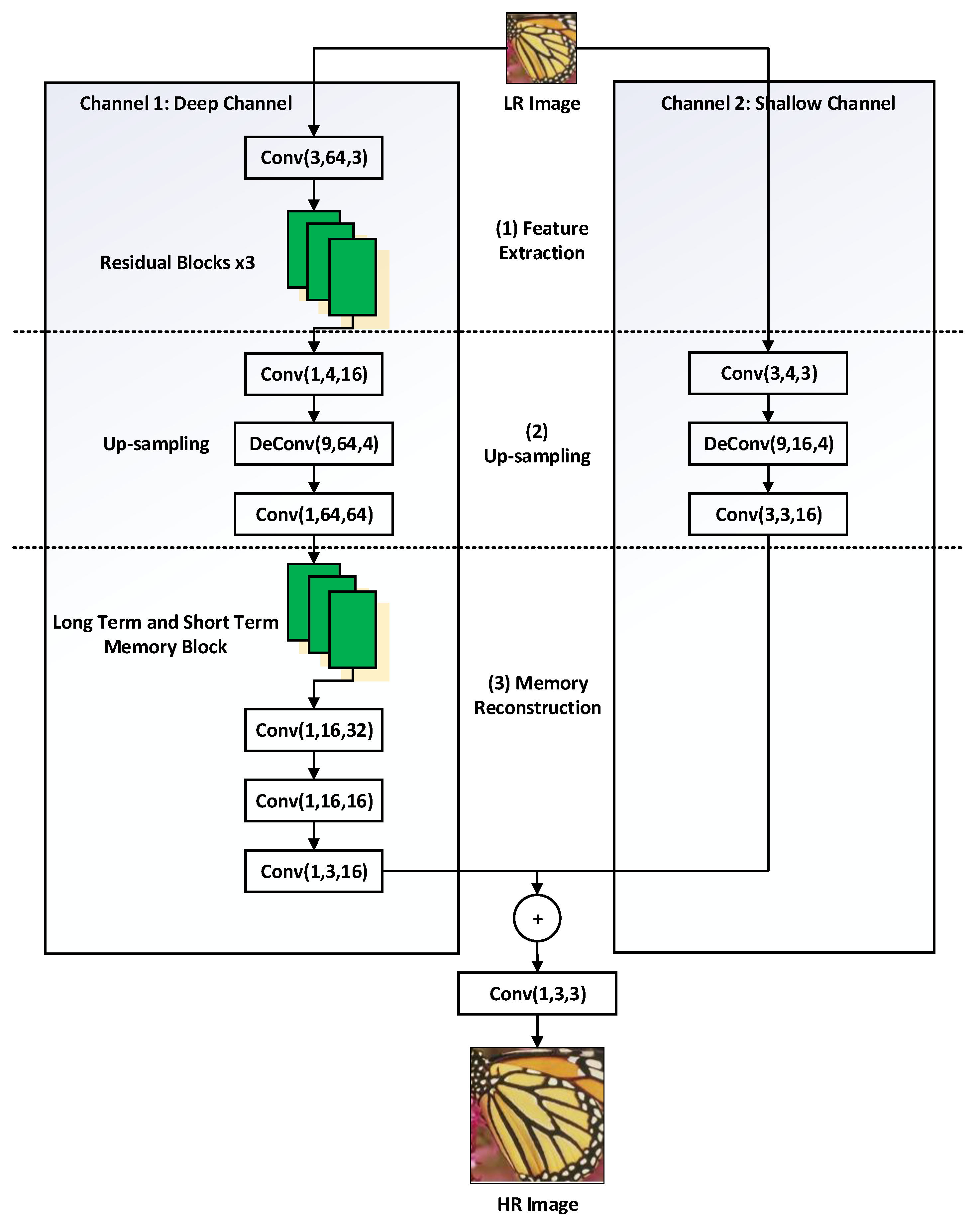
3.2. The Network Structure of DCCNN
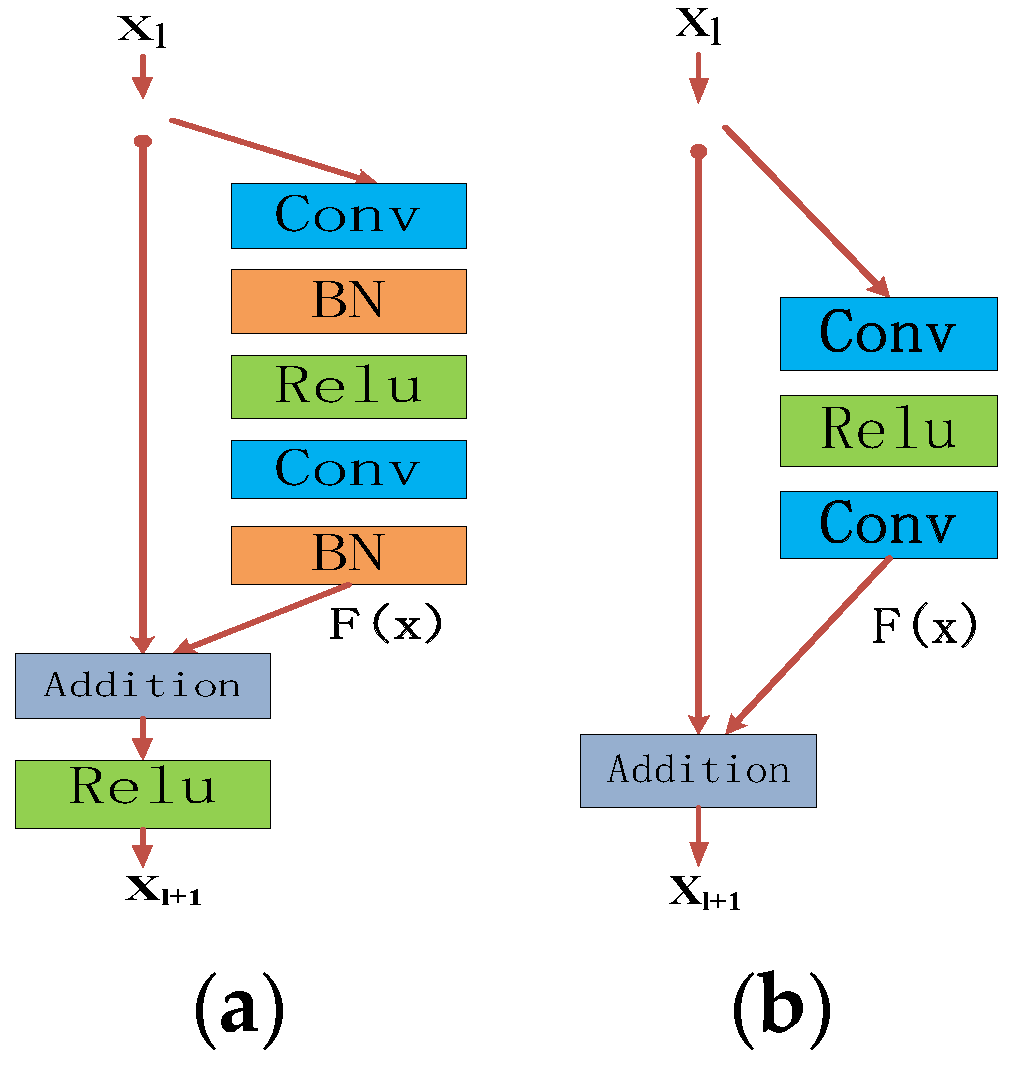
3.3. Residual Blocks and Long-Term and Short-Term Memory Block
3.4. Loss Function and Evaluation Standard
4. Experimental Results and Analysis
4.1. Parameter Settings
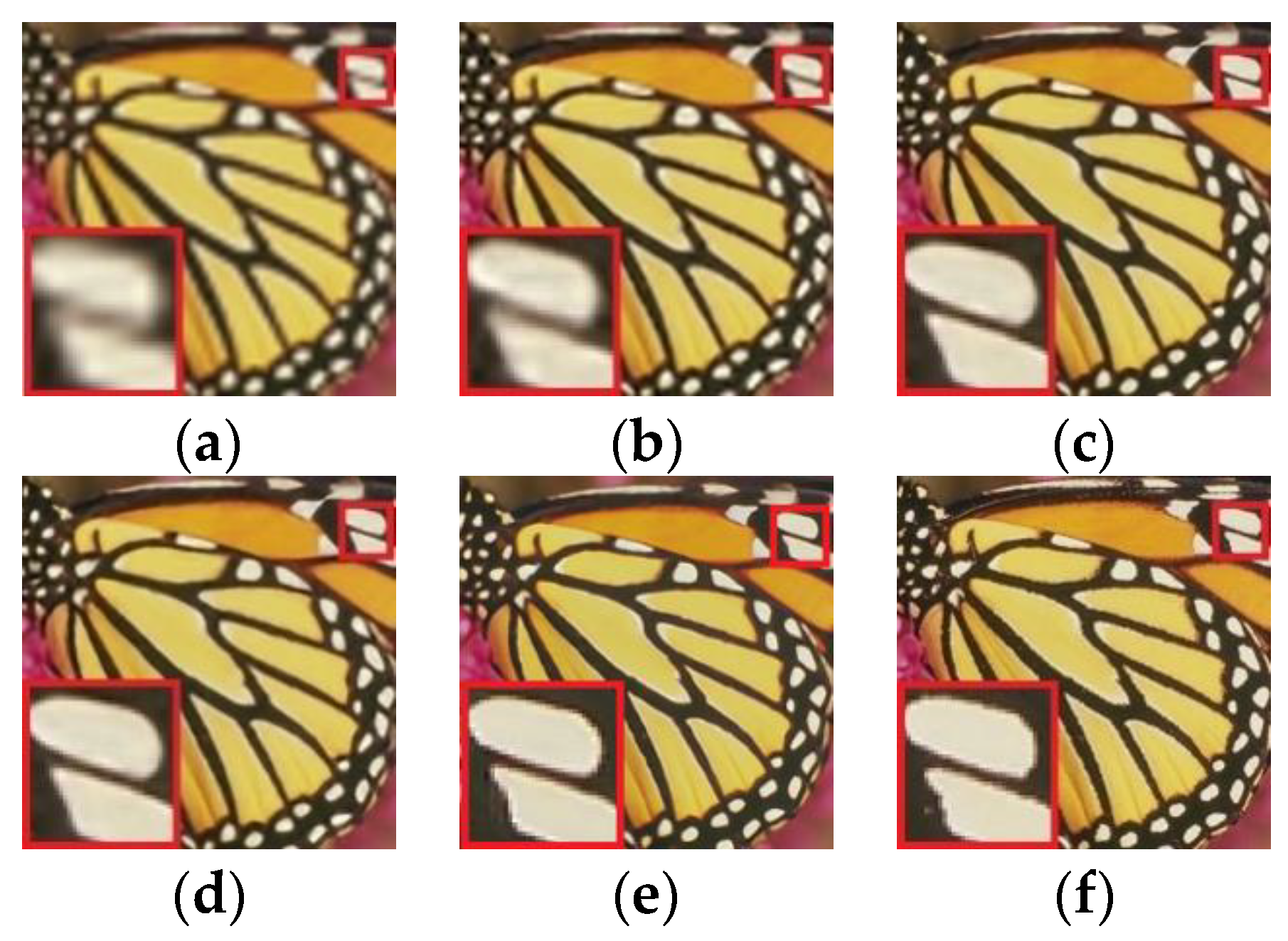
4.2. Experimental Results and Comparative Analysis
4.3. Efficiency Comparison
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gunturk, B.K.; Batur, A.U.; Altunbasak, Y.; Hayes, M.H.; Mersereau, R.M. Eigenface-Domain Super-Resolution for Face Recognition. IEEE Trans. Image Process. 2003, 12, 597–606. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Fan, R.; Lei, G.Q.; Yue, G.H.; Hou, C.P. A Two-Channel Convolutional Neural Network for Image Super-Resolution. Neurocomputing 2018, 275, 267–277. [Google Scholar] [CrossRef]
- Zhang, L.P.; Zhang, H.Y.; Shen, H.F.; Li, P.X. A Super-Resolution Reconstruction Algorithm for Surveillance Images. Signal Process. 2010, 90, 848–859. [Google Scholar] [CrossRef]
- Shi, W.Z.; Caballero, J.; Ledig, C.; Zhuang, X.H.; Bai, W.J.; Bhatia, K.K.; Marvao, A.M.M.D.; Dawes, T.; O’Regan, D.P.; Rueckert, D. Cardiac Image Super-Resolution with Global Correspondence using Multi-Atlas Patchmatch. In Proceedings of the 2013 Medical image computing and computer-assisted intervention: MICCAI, Nagoya, Japan, 22–26 September 2013; pp. 9–16. [Google Scholar]
- Chen, Y.T.; Wang, J.; Xia, R.L.; Zhang, Q.; Cao, Z.H.; Yang, K. The Visual Object Tracking Algorithm Research Based on Adaptive Combination Kernel. J. Ambient Intell. Humaniz. Comput. 2019, 1–19. [Google Scholar] [CrossRef]
- Chen, Y.T.; Xiong, J.; Xu, W.H.; Zuo, J.W. A Novel Online Incremental and Decremental Learning Algorithm Based on Variable Support Vector Machine. Clust. Comput. 2018, 1–11. [Google Scholar] [CrossRef]
- Zhang, J.M.; Jin, X.K.; Sun, J.; Wang, J.; Sangaiah, A.K. Spatial and Semantic Convolutional Features for Robust Visual Object Tracking. Multimed. Tools Appl. 2018, 1–21. [Google Scholar] [CrossRef]
- Wang, J.; Gao, Y.; Liu, W.; Wu, W.B.; Lim, S.J. An Asynchronous Clustering and Mobile Data Gathering Schema based on Timer Mechanism in Wireless Sensor Networks. Comput. Mater. Contin. 2019, 58, 711–725. [Google Scholar] [CrossRef]
- Timofte, R.; De Smet, V.; Van Gool, L. Anchored Neighborhood Regression for Fast Example-Based Super-Resolution. In Proceedings of the 2013 IEEE International Conference Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1920–1927. [Google Scholar]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted Anchored Neighborhood Regression for Fast Super-Resolution. In Proceedings of the 2014 Asian Conference Computer Vision, Singapore, Singapore, 1–5 November 2014; pp. 111–126. [Google Scholar]
- Yang, J.C.; Wright, J.; Huang, T.S.; Ma, Y. Image Super-Resolution as Sparse Representation of Raw Image Patches. In Proceedings of the 2008 IEEE Conference Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image Super-Resolution Via Sparse Representation. IEEE Trans. Image Process. 2010, 19, 2861–2870. [Google Scholar] [CrossRef]
- Wang, J.; Gao, Y.; Liu, W.; Sangaiah, A.K.; Kim, H.J. An Intelligent Data Gathering Schema with Data Fusion Supported for Mobile Sink in WSNs. Int. J. Distrib. Sens. Netw. 2019, 15. [Google Scholar] [CrossRef]
- Chen, Y.T.; Xia, R.L.; Wang, Z.; Zhang, J.M.; Yang, K.; Cao, Z.H. The Visual Saliency Detection Algorithm Research Based on Hierarchical Principle Component Analysis Method. Multimedia Tools Appl. 2019, 78. [Google Scholar] [CrossRef]
- Yang, Y.; Lin, Z.; Cohen, S. Fast image super-resolution based on in-place example regression. In Proceedings of the 2013 IEEE Conference on Computer Vision Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1059–1066. [Google Scholar]
- Zhou, S.R.; Ke, M.L.; Luo, P. Multi-Camera Transfer GAN for Person Re-Identification. J. Visual Commun. Image Represent. 2019, 59, 393–400. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 2012 International Conference Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.M.; Tang, X.O. Image Super-Resolution using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–303. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.M.; Tang, X.O. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the 2014 International European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Wang, Y.F.; Wang, L.J.; Wang, H.Y.; Li, P.H. End-to-End Image Super-Resolution via Deep and Shallow Convolutional Networks. IEEE Access 2019, 7, 31959–31970. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Yang, J.X.; Zhao, Y.Q.; Chan, J.C.W.; Yi, C. Hyperspectral Image Classification using Two-Channel Deep Convolutional Neural Network. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016; pp. 5079–5082. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Ke, R.M.; Li, W.; Cui, Z.Y.; Wang, Y.H. Two-Stream Multi-Channel Convolutional Neural Network (TM-CNN) for Multi-Lane Traffic Speed Prediction Considering Traffic Volume Impact. Available online: https://arxiv.org/abs/1903.01678 (accessed on 4 June 2019).
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision Pattern Recognition, Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.M.; Xu, C.Y. MemNet: A Persistent Memory Network for Image Restoration. In Proceedings of the 2017 IEEE International Conference Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4549–4557. [Google Scholar]
- Asvija, B.; Eswari, R.; Bijoy, M.B. Security in Hardware Assisted Virtualization for Cloud Computing—State of the Art Issues and Challenges. Comput. Netw. 2019, 151, 68–92. [Google Scholar] [CrossRef]
- Zhou, S.W.; He, Y.; Xiang, S.Z.; Li, K.Q.; Liu, Y.H. Region-Based Compressive Networked Storage with Lazy Encoding. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 1390–1402. [Google Scholar] [CrossRef]
- Min, X.; Ma, K.; Gu, K.; Zhai, G.; Wang, Z.; Lin, W. Unified Blind Quality Assessment of Compressed Natural, Graphic, and Screen Content Images. IEEE Trans. Image Process. 2017, 26, 5462–5474. [Google Scholar] [CrossRef] [PubMed]
- Gu, K.; Zhai, G.T.; Yang, X.K.; Zhang, W.J. Using Free Energy Principle for Blind Image Quality Assessment. IEEE Trans. Multimed. 2015, 17, 50–63. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE International Conference on Computer Vision Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 2010 International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Sun, J.; Xu, Z.B.; Shum, H.Y. Image Super-Resolution using Gradient Profile Prior. In Proceedings of the 2008 IEEE International Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008. [Google Scholar] [CrossRef]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep Multi-Scale Convolutional Neural Network for Dynamic Scene Deblurring. In Proceedings of the 2016 IEEE Conference on Computer Vision Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 257–265. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the 2014 European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Goodfellow, I.; Pouget-Adadie, J.; Mirza, M.; Xu, B.; Farley, D.W.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 2014 Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Timofte, R.; Agustsson, E.; Gool, L.V.; Yang, M.H.; Zhang, L.; Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M.; et al. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the 2017 IEEE Conference on Computer Vision Pattern Recognition, Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1110–1121. [Google Scholar] [CrossRef]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-Complexity Single-Image Super-Resolution Based on Nonnegative Neighbor Embedding. In Proceedings of the 2012 British Machine Vision Conference, Northumbria University, Newcastle, UK, 3–6 September 2018; pp. 135.1–135.10. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On Single Image Scale-up using Sparse-Representations. In Proceedings of the 2010 International Conference Curves and Surfaces, Avignon, France, 24–30 June 2010; pp. 711–730. [Google Scholar]
- Choi, S.Y.; Dowan, C. Unmanned Aerial Vehicles using Machine Learning for Autonomous Flight; State-of-The-Art. Adv. Rob. 2019, 33, 265–277. [Google Scholar] [CrossRef]
- Gao, G.W.; Zhu, D.; Yang, M.; Lu, H.M.; Yang, W.K.; Gao, H. Face Image Super-Resolution with Pose via Nuclear Norm Regularized Structural Orthogonal Procrustes Regression. Neural Comput. Appl. 2018, 1–11. [Google Scholar] [CrossRef]
- Chen, Y.T.; Wang, J.; Chen, X.; Zhu, M.W.; Yang, K.; Wang, Z.; Xia, R.L. Single-Image Super-Resolution Algorithm Based on Structural Self-Similarity and Deformation Block Features. IEEE Access 2019, 7, 58791–58801. [Google Scholar] [CrossRef]
- Hong, P.L.; Zhang, G.Q. A Review of Super-Resolution Imaging through Optical High-Order Interference. Appl. Sci. 2019, 9, 1166. [Google Scholar] [CrossRef]
- Pan, C.; Lu, M.Y.; Xu, B.; Gao, H.L. An Improved CNN Model for Within-Project Software Defect Prediction. Appl. Sci. 2019, 8, 2138. [Google Scholar] [CrossRef]
- Yin, C.Y.; Ding, S.L.; Wang, J. Mobile Marketing Recommendation method Based on User Location Feedback. Human-Centric Comput. Inf. Sci. 2019, 9, 1–17. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Reconstruction Multiple | Bicubic [5] | A+ [11] | SRCNN [18] | EEDS [20] | Proposed DCCNN |
|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| Set5 | ×2 | 33.64/0.9296 | 36.55/0.9543 | 36.67/0.9541 | 37.30/0.9578 | 37.43/0.9603 |
| ×3 | 30.38/0.8681 | 32.57/0.9089 | 32.76/0.9091 | 33.46/0.9190 | 33.59/0.9204 | |
| ×4 | 28.41/0.8106 | 30.29/0.8602 | 30.49/0.8627 | 31.15/0.8782 | 31.32/0.8842 | |
| Set14 | ×2 | 30.23/0.8687 | 32.29/0.9058 | 32.43/0.9062 | 32.82/0.9104 | 32.95/0.9115 |
| ×3 | 27.54/0.7743 | 29.14/0.8187 | 29.29/0.8208 | 29.61/0.8283 | 29.70/0.8307 | |
| ×4 | 26.01/0.7028 | 27.31/0.7492 | 27.48/0.7502 | 27.81/0.7625 | 28.13/0.7696 |
| Method | Feature Extraction/ms | Up-Sampling/ms | Reconstruction/ms | Shallow Channel/ms |
|---|---|---|---|---|
| EEDS | 38,015 | 4112 | 154,834 | 7265 |
| DCCNN | 19,151 | 24,895 | 70,500 | 5231 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Wang, J.; Chen, X.; Sangaiah, A.K.; Yang, K.; Cao, Z. Image Super-Resolution Algorithm Based on Dual-Channel Convolutional Neural Networks. Appl. Sci. 2019, 9, 2316. https://doi.org/10.3390/app9112316
Chen Y, Wang J, Chen X, Sangaiah AK, Yang K, Cao Z. Image Super-Resolution Algorithm Based on Dual-Channel Convolutional Neural Networks. Applied Sciences. 2019; 9(11):2316. https://doi.org/10.3390/app9112316
Chicago/Turabian StyleChen, Yuantao, Jin Wang, Xi Chen, Arun Kumar Sangaiah, Kai Yang, and Zhouhong Cao. 2019. "Image Super-Resolution Algorithm Based on Dual-Channel Convolutional Neural Networks" Applied Sciences 9, no. 11: 2316. https://doi.org/10.3390/app9112316