Memory-Enhanced Dynamic Multi-Objective Evolutionary Algorithm Based on Lp Decomposition


Abstract
:1. Introduction
2. Related works
2.1. Problem Description and Basic Definitions
- Type I: where POS(t) changes while POF(t) remains invariant.
- Type II: where both POS(t) and POF(t) change.
- Type III: where POF(t) changes while POS(t) remains invariant.
- Type IV: where both POS(t) and POF(t) remain invariant.
2.2. Decomposition Methods
- Weighted Sum (WS) approach
- Tchebycheff (TCH) approach
- Penalty-based boundary intersection (PBI) approach
2.3. Memory-Enhanced Algorithm for Environmental Change
2.3.1. DEMO Algorithm with Short-Term Memory
- (1)
- The immune clonal coevolutionary algorithm for dynamic multi-objective optimization (QICCA) algorithm is a short-term memory approach [7].
- (2)
- DNSGA-II algorithm with short-term memory and diversity [23]
2.3.2. DEMO Algorithm with Medium-Term Memory
- (1)
- When should put the individuals deposited into the memory pool in the population?
- (2)
- How many individuals should be stored in the memory pool, and which individuals should be replaced to make room for the memory pool to accommodate new individuals?
- (3)
- Which individuals are retrieved from the memory pool and reinserted into the population?
3. Memory-Enhanced Dynamic Multi-Objective Evolutionary Algorithm Based on Decomposition
3.1. Decomposition Used in dMOEA/D-
3.2. Environmental Change Detection Operator
3.3. Subproblem-Based Bunchy Memory (SBM) Method to Respond to Environmental Change
| Algorithm 1: SBM method |
|
3.4. Detailed Description of dMOEA/D- and Its Time Complexity Analysis
| Algorithm 2: The overall framework of dMOEA/D- |
|
- (1)
- Detection and response steps: the time complexity of the detection operation is , K is the number of individuals used in Formula (7), and the time complexity of responding environment change (i.e., calling SBM) is . Because , the time complexity of this step is .
- (2)
- The evolutionary optimization step of subproblems: because N subproblems are involved, and the neighborhood size of each subproblem is T, the time complexity of this step is , where m is the number of objectives.
4. Experiments
4.1. Test Problems
4.2. Performance Metric
4.3. Setting of Experimental Parameters
4.4. Experimental Results and Analysis
- (1)
- Compare dMOEA/D- with dMOEA/D-WS, dMOEA/D-TCH, and dMOEA/D-PBI
- (2)
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Qu, B. Evolutionary Algorithms for Solving Multi-Modal and Multi-Objective Optimization Problems. Ph.D. Thesis, Nanyang Technological University, Singapore, 2011. [Google Scholar]
- Sindhya, K.; Miettinen, K.; Deb, K. A Hybrid Framework for Evolutionary Multi-Objective Optimization. IEEE Trans. Evolut. Comput. 2013, 17, 495–511. [Google Scholar] [CrossRef]
- Farina, M.; Deb, K.; Amato, P. Dynamic multiobjective optimization problems: Test cases, approximations, and applications. IEEE Trans. Evolut. Comput. 2004, 8, 425–442. [Google Scholar] [CrossRef]
- Wu, Y.; Jin, Y.; Liu, X. A directed search strategy for evolutionary dynamic multiobjective optimization. Soft Comput. 2015, 19, 3221–3235. [Google Scholar] [CrossRef]
- Jin, Y.; Branke, J. Evolutionary optimization in uncertain environments-a survey. IEEE Trans. Evolut. Comput. 2005, 9, 303–317. [Google Scholar] [CrossRef]
- Liu, C.; Wang, Y. Dynamic Multi-objective Optimization Evolutionary Algorithm. Nat. Sci. J. Hainan Univ. 2010, 4, 456–459. [Google Scholar]
- Shang, R.; Jiao, L.; Ren, Y.; Li, L.; Wang, L. Quantum immune clonal coevolutionary algorithm for dynamic multiobjective optimization. Nat. Comput. Int. J. 2014, 13, 421–445. [Google Scholar] [CrossRef]
- Zhang, Z. Multiobjective Optimization Immune Algorithm In Dynamic Environments And Its Application To Greenhouse Control. Appl. Soft Comput. 2008, 8, 959–971. [Google Scholar] [CrossRef]
- Li, X.; Branke, J.; Kirley, M. On performance metrics and particle swarm methods for dynamic multiobjective optimization problems. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC 2007), Singapore, 25–28 September 2007; pp. 576–583. [Google Scholar]
- Li, Y.; Zhan, Z.H.; Lin, S.; Zhang, J.; Luo, X. Competitive and cooperative particle swarm optimization with information sharing mechanism for global optimization problems. Inf. Sci. 2015, 293, 370–382. [Google Scholar] [CrossRef]
- Zheng, X.W.; Lu, D.J.; Wang, X.G.; Liu, H. A cooperative coevolutionary biogeography-based optimizer. Appl. Intell. 2015, 43, 95–111. [Google Scholar] [CrossRef]
- Goh, C.K.; Tan, K.C. A Competitive-Cooperative Coevolutionary Paradigm for Dynamic Multiobjective Optimization. IEEE Trans. Evolut. Comput. 2009, 13, 103–127. [Google Scholar]
- Jiang, S.; Yang, S. A Steady-state and Generational Evolutionary Algorithm for Dynamic Multiobjective Optimization. IEEE Trans. Evolut. Comput. 2017, 21, 65–82. [Google Scholar] [CrossRef]
- Wang, Y.; Li, B. Multi-strategy ensemble evolutionary algorithm for dynamic multi-objective optimization. Memet. Comput. 2010, 2, 3–24. [Google Scholar] [CrossRef]
- Chen, J.H.; Cheng, C.W. Multi-objective evolutionary optimization of dynamic service facility location problems. In Proceedings of the 2011 IEEE Southeastcon, Nashville, TN, USA, 17–20 March 2011; pp. 333–338. [Google Scholar]
- Deb, K.; Udaya, B.R.N.; Karthik, S. Dynamic Multi-objective Optimization and Decision-Making Using Modified NSGA-II: A Case Study on Hydro-thermal Power Scheduling. In Proceedings of the International Conference on Evolutionary Multi-Criterion Optimization, Matsushima, Japan, 5–8 March 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 803–817. [Google Scholar]
- Hutzschenreuter, A.K.; Bosman, P.A.N.; Han, L.P. Evolutionary Multiobjective Optimization for Dynamic Hospital Resource Management. In Proceedings of the International Conference on Evolutionary Multi-Criterion Optimization, Nantes, France, 7–10 April 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 320–334. [Google Scholar]
- Li, J.Q.; Sang, H.Y.; Han, Y.Y.; Wang, C.G.; Gao, K.Z. Efficient multi-objective optimization algorithm for hybrid flow shop scheduling problems with setup energy consumptions. J. Clean. Prod. 2018, 181, 584–598. [Google Scholar] [CrossRef]
- Barlow, G.J.; Smith, S.F. A Memory Enhanced Evolutionary Algorithm for Dynamic Scheduling Problems. In Workshops on Applications of Evolutionary Computation; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; Volume 4974, pp. 606–615. [Google Scholar]
- Yang, S.; Yao, X. Population-Based Incremental Learning with Associative Memory for Dynamic Environments. IEEE Trans. Evolut. Comput. 2008, 12, 542–561. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T.A.M.T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evolut. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Koo, W.T.; Chi, K.G.; Tan, K.C. A predictive gradient strategy for multiobjective evolutionary algorithms in a fast changing environment. Memet. Comput. 2010, 2, 87–110. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evolut. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef] [Green Version]
- Coello, C.A.C.; Lamont, G.B.; Van Veldhuizen, D.A. Evolutionary Algorithms For Solving Multi-Objective Problems; Springer: New York, NY, USA, 2007. [Google Scholar]
- Miettinen, K. Nonlinear Multiobjective Optimization; Kluwer Academic Publishers: Boston, MA, USA, 1999. [Google Scholar]
- Bai, J.; Liu, H. Multi-objective artificial bee algorithm based on decomposition by PBI method. Appl. Intell. 2016, 45, 976–991. [Google Scholar] [CrossRef]
- Branke, J. Memory enhanced evolutionary algorithms for changing optimization problems. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99, Washington, DC, USA, 6–9 July 1999; Volume 3, pp. 1875–1882. [Google Scholar]
- Das, S.; Suganthan, P.N. Differential Evolution: A Survey of the State-of-the-Art. IEEE Trans. Evolut. Comput. 2011, 15, 4–13. [Google Scholar] [CrossRef]
- Tan, Y.Y.; Jiao, Y.C.; Li, H.; Wang, X.K. A modification to MOEA/D-DE for multiobjective optimization problems with complicated Pareto sets. Inf. Sci. 2012, 213, 14–38. [Google Scholar] [CrossRef]
- Min, L. Memory Enhanced Dynamic Multi-Objective Evolutionary Algorithm Based on Decomposition. J. Softw. 2013, 24, 1571–1588. [Google Scholar]
- Liu, R.; Niu, X.; Fan, J. An orthogonal predictive model-based dynamic multi-objective optimization algorithm. Soft Comput. 2015, 19, 3083–3107. [Google Scholar] [CrossRef]
- Sola, M.C. Parallel Processing for Dynamic Multi-Objective Optimization. Ph.D. Thesis, University of Granada, Granada, Spain, 2010. [Google Scholar]
- Zitzler, E.; Thiele, L.; Laumanns, M.; Fonseca, C.M.; Da Fonseca, V.G. Performance assessment of multiobjective optimizers: An analysis and review. IEEE Trans. Evolut. Comput. 2003, 7, 117–132. [Google Scholar] [CrossRef]
- Veldhuizen, D.A.V.; Lamont, G.B. Evolutionary Computation and Convergence to a Pareto Front. In Proceedings of the Late Breaking Papers at the Genetic Programming 1998 Conference, Madison, WI, USA, 22–25 July 1998; pp. 221–228. [Google Scholar]
- Veldhuizen, D.A.V.; Lamont, G.B. Multiobjective evolutionary algorithm test suites. In Proceedings of the 1999 ACM Symposium on Applied Computing, San Antonio, TX, USA, 28 February–2 March 1999; pp. 351–357. [Google Scholar]
- Okimoto, T.; Schwind, N.; Clement, M. Lp-Norm based algorithm for multi-objective distributed constraint optimization. In Proceedings of the 2014 International Conference on Autonomous Agents and Multi-Agent Systems, Paris, France, 5–9 May 2014; Volume 18, pp. 1427–1428. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
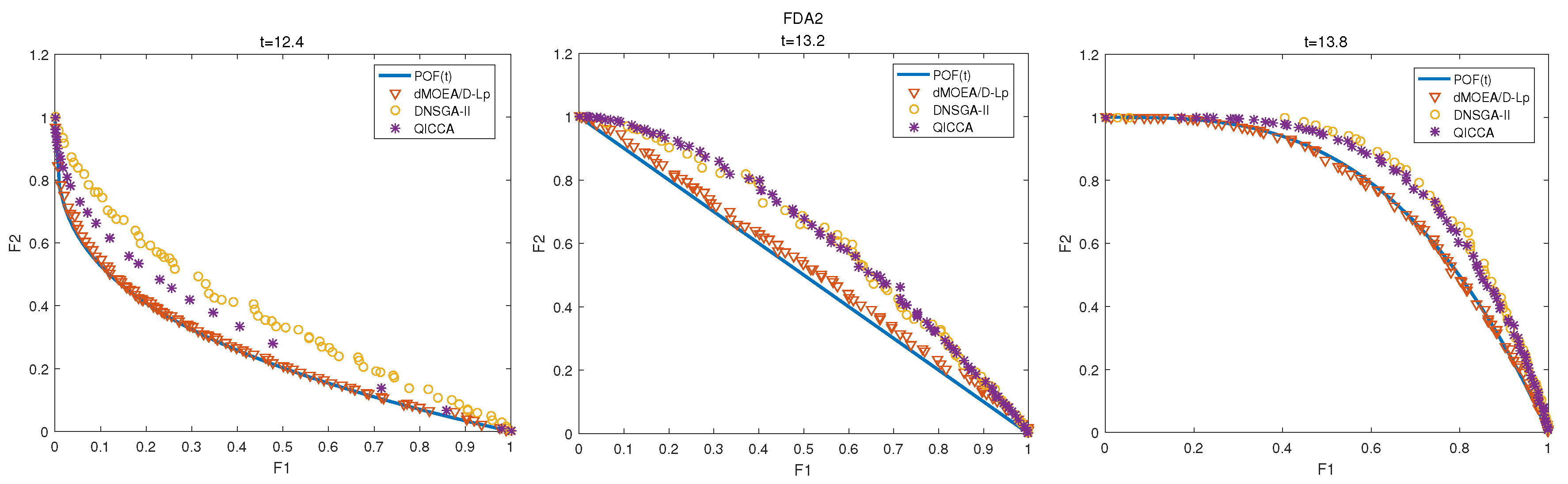{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
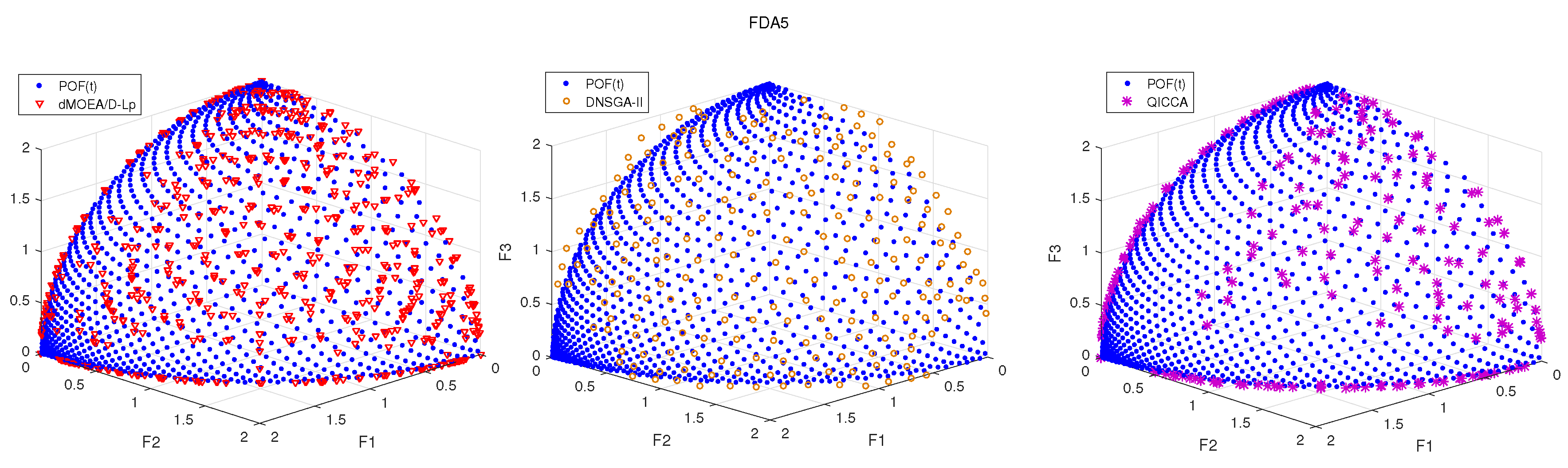{kind=link}
| Problems | Objective Functions | Variable Bounds | n |
|---|---|---|---|
| FDA1 | 20 | ||
| FDA2 | 20 | ||
| FDA3 | 30 | ||
| FDA4 | 12 | ||
| FDA5 | 12 |
| Parameter | Value |
|---|---|
| Population size (N) | Two objectives: N = 100; Three objectives: N = 300 |
| Crossover probability | 0.9 |
| Mutation probability | |
| Frequency of change () | 5, 10, 15, 20, 25, 35 |
| Severity of change () | 5, 10 |
| Problem | (,) | Statistic | rGD(t) | ||||
|---|---|---|---|---|---|---|---|
| FDA1(2) | (25,5) | Min Mean Std | (6.03 × 10) (9.81 × 10) (2.55 × 10) | (8.30 × 10) (1.07 × 10) (8.98 × 10) | (8.30 × 10) (1.07 × 10) (8.98 × 10) | (1.98 × 10) (2.02 × 10) (8.11 × 10) | (6.75 × 10) (1.06 × 10) (2.41 × 10) |
| FDA2(2) | (15,5) | Min Mean Std | (1.11 × 10) (1.83 × 10) (7.47 × 10) | (9.33 × 10) (1.56 × 10) (5.30 × 10) | (9.33 × 10) (1.56 × 10) (5.30 × 10) | (2.10 × 10) (2.91 × 10) (4.20 × 10) | (6.33 × 10) (7.34 × 10) (5.04 × 10) |
| FDA3(2) | (35,5) | Min Mean Std | (4.13 × 10) (4.60 × 10) (1.84 × 10) | (6.94 × 10) (3.33 × 10) (1.34 × 10) | (6.94 × 10) (3.33 × 10) (1.34 × 10) | (5.01 × 10) (6.23 × 10) (8.71 × 10) | (4.79 × 10) (5.16 × 10) (2.73 × 10) |
| FDA4(3) | (25,5) | Min Mean Std | (2.02 × 10) (4.64 × 10) (2.64 × 10) | (8.31 × 10) (8.36 × 10) (2.71 × 10) | (8.31 × 10) (8.36 × 10) (2.71 × 10) | (8.91 × 10) (1.03 × 10) (6.38 × 10) | (1.30 × 10) (1.35 × 10) (2.51 × 10) |
| FDA5(3) | (25,5) | Min Mean Std | (8.43 × 10) (1.02 × 10) (8.43 × 10) | (8.32 × 10) (1.26 × 10) (2.37 × 10) | (8.32 × 10) (1.26 × 10) (2.37 × 10) | (1.01 × 10) (1.69 × 10) (1.86 × 10) | (5.01 × 10) (5.69 × 10) (3.05 × 10) |
| Problem | (,) | Statistic | rGD(t) Metrics | |||
|---|---|---|---|---|---|---|
| dMOEA/D- | dMOEA/D-TCH | dMOEA/D-WS | dMOEA/D-PBI | |||
| FDA1(2) | (10, 10) | Min Mean Std | (6.69 × 10) (1.05 × 10) (2.39 × 10) | (5.76 × 10) (1.12 × 10) (3.20 × 10) | (1.94 × 10) (2.05 × 10) (1.27 × 10) | (8.01 × 10) (1.16 × 10) (5.13 × 10) |
| (25,10) | Min Mean Std | (6.75 × 10) (7.27 × 10) (2.03 × 10) | (7.33 × 10) (1.96 × 10) (2.32 × 10) | (1.99 × 10) (2.01 × 10) (3.49 × 10) | (8.01 × 10) (8.74 × 10) (2.11 × 10) | |
| (25,5) | Min Mean Std | (6.75 × 10) (1.06 × 10) (2.41 × 10) | (6.03 × 10) (9.81 × 10) (2.55 × 10) | (1.98 × 10) (2.02 × 10) (8.11 × 10) | (8.85 × 10) (9.13 × 10) (2.32 × 10) | |
| FDA2(2) | (5,10) | Min Mean Std | (2.25 × 10) (3.32 × 10) (5.78 × 10) | (1.79 × 10) (2.75 × 10) (6.91 × 10) | (1.05 × 10) (2.44 × 10) (6.01 × 10) | (2.33 × 10) (1.13 × 10) (5.25 × 10) |
| (15,10) | Min Mean Std | (1.21 × 10) (1.30 × 10) (5.71 × 10) | (3.49 × 10) (7.33 × 10) (5.69 × 10) | (1.77 × 10) (2.74 × 10) (6.92 × 10) | (2.33 × 10) (1.13 × 10) (5.25 × 10) | |
| (15,5) | Min Mean Std | (6.33 × 10) (7.34 × 10) (5.04 × 10) | (1.11 × 10) (1.83 × 10) (7.47 × 10) | (2.10 × 10) (2.91 × 10) (4.20 × 10) | (1.00 × 10) (1.77 × 10) (7.14 × 10) | |
| FDA3(2) | (25,10) | Min Mean Std | (1.00 × 10) (1.03 × 10) (2.05 × 10) | (2.64 × 10) (4.03 × 10) (2.38 × 10) | (5.74 × 10) (6.56 × 10) (2.10 × 10) | (1.51 × 10) (5.15 × 10) (2.54 × 10) |
| (35,10) | Min Mean Std | (4.04 × 10) (6.05 × 10) (2.73 × 10) | (6.06 × 10) (7.56 × 10) (2.05 × 10) | (6.13 × 10) (7.23 × 10) (1.34 × 10) | (2.17 × 10) (6.06 × 10) (2.31 × 10) | |
| (35,5) | Min Mean Std | (4.79 × 10) (5.16 × 10) (2.73 × 10) | (4.13 × 10) (4.60 × 10) (1.84 × 10) | (5.01 × 10) (6.23 × 10) (8.71 × 10) | (1.35 × 10) (5.33 × 10) (2.08 × 10) | |
| FDA4(3) | (20,10) | Min Mean Std | (1.29 × 10) (2.43 × 10) (5.67 × 10) | (7.01 × 10) (8.00 × 10) (2.34 × 10) | (1.96 × 10) (2.74 × 10) (6.97 × 10) | (4.05 × 10) (4.14 × 10) (1.13 × 10) |
| (25,10) | Min Mean Std | (1.26 × 10) (1.40 × 10) (3.36 × 10) | (7.01 × 10) (8.00 × 10) (2.34 × 10) | (1.00 × 10) (2.98 × 10) (6.30 × 10) | (1.01 × 10) (3.87 × 10) (3.20 × 10) | |
| (25,5) | Min Mean Std | (1.30 × 10) (1.35 × 10) (2.51 × 10) | (2.02 × 10) (4.64 × 10) (2.64 × 10) | (8.91 × 10) (1.03 × 10) (6.38 × 10) | (1.14 × 10) (2.32 × 10) (1.03 × 10) | |
| FDA5(3) | (20,10) | Min Mean Std | (8.22 × 10) (9.05 × 10) (8.43 × 10) | (7.37 × 10) (9.06 × 10) (2.76 × 10) | (6.03 × 10) (8.96 × 10) (1.09 × 10) | (7.79 × 10) (9.16 × 10) (1.75 × 10) |
| (25,10) | Min Mean Std | (7.83 × 10) (8.86 × 10) (9.75 × 10) | (8.21 × 10) (8.35 × 10) (1.07 × 10) | (8.43 × 10) (8.65 × 10) (1.09 × 10) | (8.03 × 10) (8.43 × 10) (1.10 × 10) | |
| (25,5) | Min Mean Std | (5.01 × 10) (5.69 × 10) (3.05 × 10) | (8.43 × 10) (1.02 × 10) (8.43 × 10) | (1.01 × 10) (1.69 × 10) (1.86 × 10) | (8.01 × 10) (1.05 × 10) (6.09 × 10) | |
| Problem | (,) | Statistic | GD(t) Metrics | |||
|---|---|---|---|---|---|---|
| dMOEA/D- | dMOEA/D-TCH | dMOEA/D-WS | dMOEA/D-PBI | |||
| FDA1(2) | (10,10) | Min Mean Std | (5.55 × 10) (9.14 × 10) (4.79 × 10) | (5.96 × 10) (6.45 × 10) (4.45 × 10) | (7.74 × 10) (9.61 × 10) (1.77 × 10) | (9.72 × 10) (1.01 × 10) (6.49 × 10) |
| (25,10) | Min Mean Std | (4.18 × 10) (1.26 × 10) (5.18 × 10) | (4.92 × 10) (1.62 × 10) (6.00 × 10) | (1.20 × 10) (1.66 × 10) (1.49 × 10) | (6.71 × 10) (3.00 × 10) (1.24 × 10) | |
| (25,5) | Min Mean Std | (5.97 × 10) (9.13 × 10) (4.79 × 10) | (6.26 × 10) (2.26 × 10) (1.29 × 10) | (1.12 × 10) (3.35 × 10) (6.37 × 10) | (7.64 × 10) (4.12 × 10) (1.86 × 10) | |
| FDA2(2) | (5,10) | Min Mean Std | (7.89 × 10) (5.10 × 10) (4.92 × 10) | (1.20 × 10) (3.31 × 10) (2.54 × 10) | (3.16 × 10) (1.55 × 10) (1.26 × 10) | (8.04 × 10) (5.79 × 10) (3.43 × 10) |
| (15,10) | Min Mean Std | (6.16 × 10) (2.43 × 10) (4.92 × 10) | (6.70 × 10) (2.46 × 10) (1.22 × 10) | (1.02 × 10) (1.32 × 10) (1.31 × 10) | (6.49 × 10) (2.57 × 10) (1.54 × 10) | |
| (15,5) | Min Mean Std | (7.56 × 10) (4.75 × 10) (2.53 × 10) | (5.99 × 10) (1.91 × 10) (1.40 × 10) | (6.02 × 10) (7.66 × 10) (1.28 × 10) | (6.60 × 10) (1.98 × 10) (1.36 × 10) | |
| FDA3(2) | (25,10) | Min Mean Std | (1.00 × 10) (3.48 × 10) (3.91 × 10) | (8.07 × 10) (4.92 × 10) (7.34 × 10) | (1.00 × 10) (2.20 × 10) (1.08 × 10) | (3.37 × 10) (3.71 × 10) (4.17 × 10) |
| (35,10) | Min Mean Std | (1.02 × 10) (3.15 × 10) (3.48 × 10) | (7.56 × 10) (2.16 × 10) (1.06 × 10) | (5.90 × 10) (6.89 × 10) (5.35 × 10) | (3.23 × 10) (3.36 × 10) (3.87 × 10) | |
| (35,5) | Min Mean Std | (1.06 × 10) (3.64 × 10) (3.39 × 10) | (9.18 × 10) (3.90 × 10) (3.89 × 10) | (1.11 × 10) (6.67 × 10) (5.53 × 10) | (7.72 × 10) (3.63 × 10) (3.48 × 10) | |
| FDA4(3) | (20,10) | Min Mean Std | (2.13 × 10) (2.16 × 10) (1.68 × 10) | (2.52 × 10) (2.56 × 10) (8.54 × 10) | (3.24 × 10) (4.64 × 10) (2.48 × 10) | (2.31 × 10) (2.56 × 10) (2.04 × 10) |
| (25,10) | Min Mean Std | (2.51 × 10) (2.55 × 10) (1.48 × 10) | (1.52 × 10) (2.59 × 10) (3.08 × 10) | (3.22 × 10) (5.18 × 10) (2.53 × 10) | (2.31 × 10) (2.34 × 10) (1.64 × 10) | |
| (25,5) | Min Mean Std | (1.12 × 10) (1.47 × 10) (6.04 × 10) | (2.53 × 10) (2.56 × 10) (1.07 × 10) | (3.21 × 10) (5.33 × 10) (3.62 × 10) | (2.31 × 10) (2.34 × 10) (1.64 × 10) | |
| FDA5(3) | (20,10) | Min Mean Std | (2.69 × 10) (4.26 × 10) (8.35 × 10) | (2.20 × 10) (3.99 × 10) (1.16 × 10) | (3.23 × 10) (7.14 × 10) (3.11 × 10) | (5.76 × 10) (3.25 × 10) (7.09 × 10) |
| (25,10) | Min Mean Std | (2.68 × 10) (4.23 × 10) (8.30 × 10) | (1.96 × 10) (3.62 × 10) (7.29 × 10) | (3.42 × 10) (6.38 × 10) (2.28 × 10) | (2.56 × 10) (3.83 × 10) (1.81 × 10) | |
| (25,5) | Min Mean Std | (2.86 × 10) (4.21 × 10) (7.85 × 10) | (2.22 × 10) (4.19 × 10) (8.84 × 10) | (3.26 × 10) (9.34 × 10) (5.04 × 10) | (2.82 × 10) (3.89 × 10) (8.11 × 10) | |
| Problem | (,) | Statistic | rGD(t) Metrics | ||
|---|---|---|---|---|---|
| dMOEA/D- | DNSGA-II | QICCA | |||
| FDA1(2) | (10,10) | Min Mean Std | (6.69 × 10) (1.05 × 10) (2.39 × 10) | (1.115 × 10) (1.21 × 10) (3.11 × 10) | (1.05 × 10) (1.08 × 10) (2.45 × 10) |
| (25,10) | Min Mean Std | (6.75 × 10) (7.27 × 10) (2.03 × 10) | (1.07 × 10) (1.08 × 10) (5.48 × 10) | (1.05 × 10) (1.06 × 10) (4.43 × 10) | |
| (25,5) | Min Mean Std | (6.75 × 10) (1.06 × 10) (2.41 × 10) | (1.06 × 10) (1.09 × 10) (1.36 × 10) | (1.06 × 10) (1.07 × 10) (7.44 × 10) | |
| FDA2(2) | (5,10) | Min Mean Std | (2.25 × 10) (3.32 × 10) (5.78 × 10) | (1.50 × 10) (3.65 × 10) (7.53 × 10) | (1.07 × 10) (3.32 × 10) (7.11 × 10) |
| (15,10) | Min Mean Std | (1.21 × 10) (1.30 × 10) (5.71 × 10) | (1.34 × 10) (4.30 × 10) (5.95 × 10) | (1.47 × 10) (3.95 × 10) (6.36 × 10) | |
| (15,5) | Min Mean Std | (6.33 × 10) (7.34 × 10) (5.04 × 10) | (1.88 × 10) (3.75 × 10) (6.33 × 10) | (1.40 × 10) (3.63 × 10) (6.95 × 10) | |
| FDA3(2) | (25,10) | Min Mean Std | (1.00 × 10) (1.03 × 10) (2.05 × 10) | (1.17 × 10) (6.36 × 10) (2.61 × 10) | (1.40 × 10) (6.40 × 10) (2.63 × 10) |
| (35,10) | Min Mean Std | (4.04 × 10) (6.05 × 10) (2.73 × 10) | (6.30 × 10) (6.35 × 10) (2.67 × 10) | (6.35 × 10) (6.38 × 10) (2.68 × 10) | |
| (35,5) | Min Mean Std | (4.79 × 10) (5.16 × 10) (2.73 × 10) | (6.06 × 10) (6.10 × 10) (2.70 × 10) | (6.09 × 10) (6.11 × 10) (2.52 × 10) | |
| FDA4(3) | (20,10) | Min Mean Std | (2.43 × 10) (1.29 × 10) (5.67 × 10) | (1.39 × 10) (1.40 × 10) (5.19 × 10) | (1.41 × 10) (1.77 × 10) (3.13 × 10) |
| (25,10) | Min Mean Std | (1.26 × 10) (1.40 × 10) (3.36 × 10) | (1.27 × 10) (1.42 × 10) (4.38 × 10) | (1.38 × 10) (1.45 × 10) (3.83 × 10) | |
| (25,5) | Min Mean Std | (1.30 × 10) (1.35 × 10) (2.51 × 10) | (1.32 × 10) (1.38 × 10) (3.08 × 10) | (2.02 × 10) (2.29 × 10) (5.98 × 10) | |
| FDA5(3) | (20,10) | Min Mean Std | (8.22 × 10) (9.05 × 10) (8.43 × 10) | (7.31 × 10) (9.73 × 10) (3.16 × 10) | (8.03 × 10) (9.13 × 10) (4.86 × 10) |
| (25,10) | Min Mean Std | (8.43 × 10) (9.16 × 10) (1.07 × 10) | (6.36 × 10) (8.65 × 10) (1.55 × 10) | (7.91 × 10) (8.43 × 10) (1.10 × 10) | |
| (25,5) | Min Mean Std | (5.01 × 10) (5.69 × 10) (3.05 × 10) | (8.00 × 10) (1.06 × 10) (5.43 × 10) | (9.38 × 10) (1.05 × 10) (6.09 × 10) | |
| Problem | (,) | Statistic | GD(t) Metrics | ||
|---|---|---|---|---|---|
| dMOEA/D- | DNSGA-II | QICCA | |||
| FDA1(2) | (10,10) | Min Mean Std | (5.55 × 10) (9.14 × 10) (4.79 × 10) | (6.91 × 10) (8.08 × 10) (7.00 × 10) | (5.76 × 10) (6.49 × 10) (6.08 × 10) |
| (25,10) | Min Mean Std | (4.18 × 10) (1.26 × 10) (5.18 × 10) | (1.81 × 10) (2.02 × 10) (6.42 × 10) | (1.93 × 10) (2.05 × 10) (1.37 × 10) | |
| (25,5) | Min Mean Std | (5.97 × 10) (9.13 × 10) (4.79 × 10) | (2.56 × 10) (2.97 × 10) (3.75 × 10) | (2.76 × 10) (2.92 × 10) (2.56 × 10) | |
| FDA2(2) | (5,10) | Min Mean Std | (7.89 × 10) (5.10 × 10) (4.92 × 10) | (1.52 × 10) (1.50 × 10) (2.33 × 10) | (5.10 × 10) (2.51 × 10) (2.97 × 10) |
| (15,10) | Min Mean Std | (6.16 × 10) (2.43 × 10) (4.92 × 10) | (8.80 × 10) (4.37 × 10) (3.82 × 10) | (9.11 × 10) (7.08 × 10) (5.44 × 10) | |
| (15,5) | Min Mean Std | (7.56 × 10) (4.75 × 10) (2.53 × 10) | (1.02 × 10) (7.55 × 10) (5.70 × 10) | (2.43 × 10) (1.80 × 10) (1.29 × 10) | |
| FDA3(2) | (25,10) | Min Mean Std | (1.00 × 10) (3.48 × 10) (3.91 × 10) | (8.07 × 10) (4.92 × 10) (7.34 × 10) | (1.00 × 10) (2.20 × 10) (1.08 × 10) |
| (35,10) | Min Mean Std | (1.02 × 10) (3.15 × 10) (3.48 × 10) | (3.02 × 10) (3.23 × 10) (3.50 × 10) | (3.40 × 10) (3.68 × 10) (4.32 × 10) | |
| (35,5) | Min Mean Std | (1.06 × 10) (3.64 × 10) (3.39 × 10) | (3.79 × 10) (3.92 × 10) (3.42 × 10) | (4.05 × 10) (4.27 × 10) (4.55 × 10) | |
| FDA4(3) | (20,10) | Min Mean Std | (2.13 × 10) (2.16 × 10) (1.68 × 10) | (3.57 × 10) (3.88 × 10) (2.03 × 10) | (2.54 × 10) (2.66 × 10) (1.83 × 10) |
| (25,10) | Min Mean Std | (2.51 × 10) (2.55 × 10) (1.48 × 10) | (2.56 × 10) (3.11 × 10) (1.75 × 10) | (2.43 × 10) (3.66 × 10) (2.02 × 10) | |
| (25,5) | Min Mean Std | (1.12 × 10) (1.47 × 10) (6.04 × 10) | (1.53 × 10) (1.67 × 10) (1.44 × 10) | (1.99 × 10) (2.47 × 10) (1.68 × 10) | |
| FDA5(3) | (20,10) | Min Mean Std | (2.69 × 10) (4.26 × 10) (8.35 × 10) | (2.20 × 10) (3.99 × 10) (1.16 × 10) | (3.23 × 10) (7.14 × 10) (3.11 × 10) |
| (25,10) | Min Mean Std | (2.68 × 10) (4.23 × 10) (8.30 × 10) | (3.44 × 10) (4.62 × 10) (8.53 × 10) | (3.67 × 10) (4.87 × 10) (8.28 × 10) | |
| (25,5) | Min Mean Std | (2.86 × 10) (4.21 × 10) (7.85 × 10) | (3.15 × 10) (4.36 × 10) (7.32 × 10) | (2.22 × 10) (3.38 × 10) (1.04 × 10) | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Tan, Y.; Zheng, W.; Li, S. Memory-Enhanced Dynamic Multi-Objective Evolutionary Algorithm Based on Lp Decomposition. Appl. Sci. 2018, 8, 1673. https://doi.org/10.3390/app8091673
Xu X, Tan Y, Zheng W, Li S. Memory-Enhanced Dynamic Multi-Objective Evolutionary Algorithm Based on Lp Decomposition. Applied Sciences. 2018; 8(9):1673. https://doi.org/10.3390/app8091673
Chicago/Turabian StyleXu, Xinxin, Yanyan Tan, Wei Zheng, and Shengtao Li. 2018. "Memory-Enhanced Dynamic Multi-Objective Evolutionary Algorithm Based on Lp Decomposition" Applied Sciences 8, no. 9: 1673. https://doi.org/10.3390/app8091673