Inductive Design Exploration Method with Active Learning for Complex Design Problems

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Inductive Design Exploration Method with Active Learning
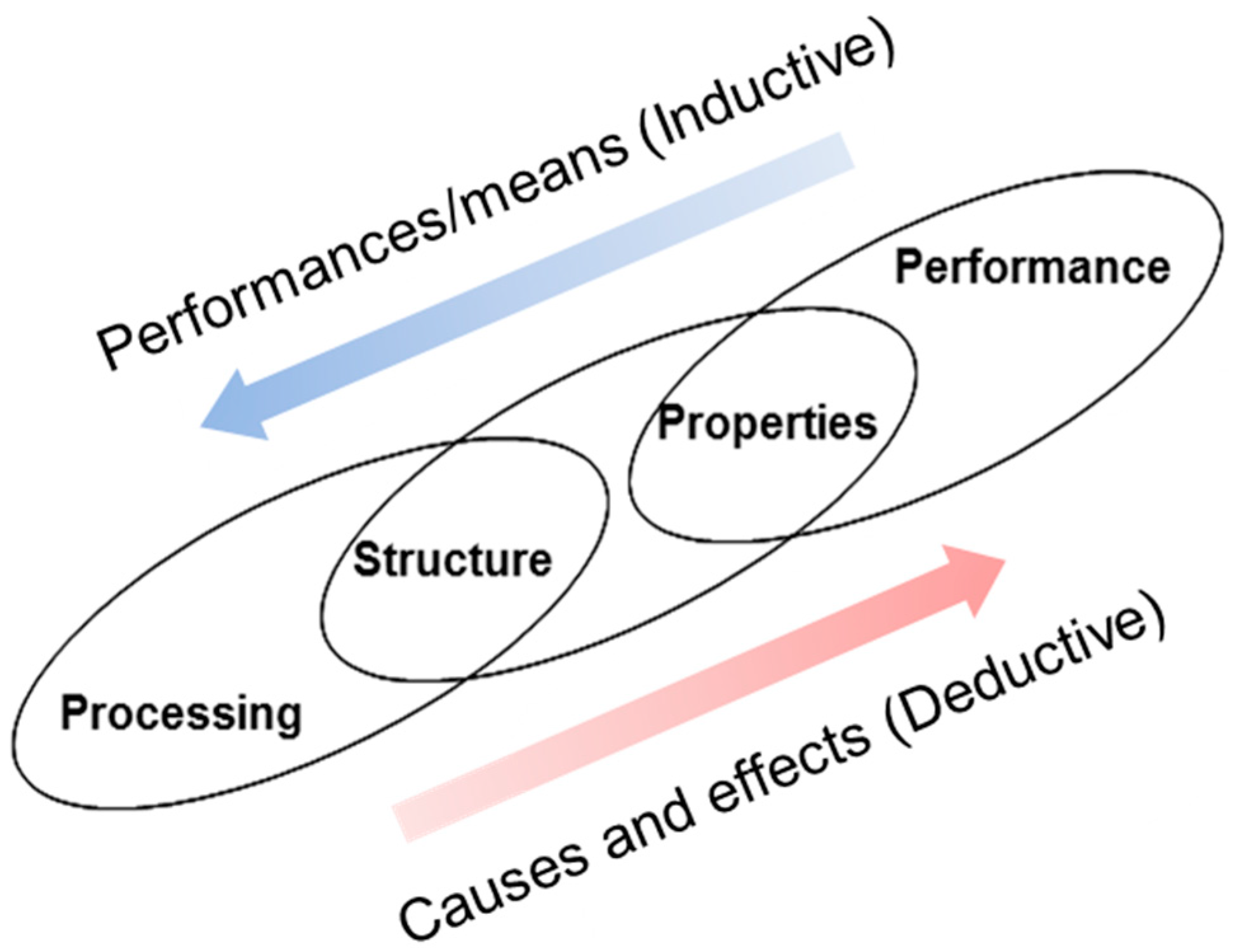
2.1. Limitation of Traditional IDEM
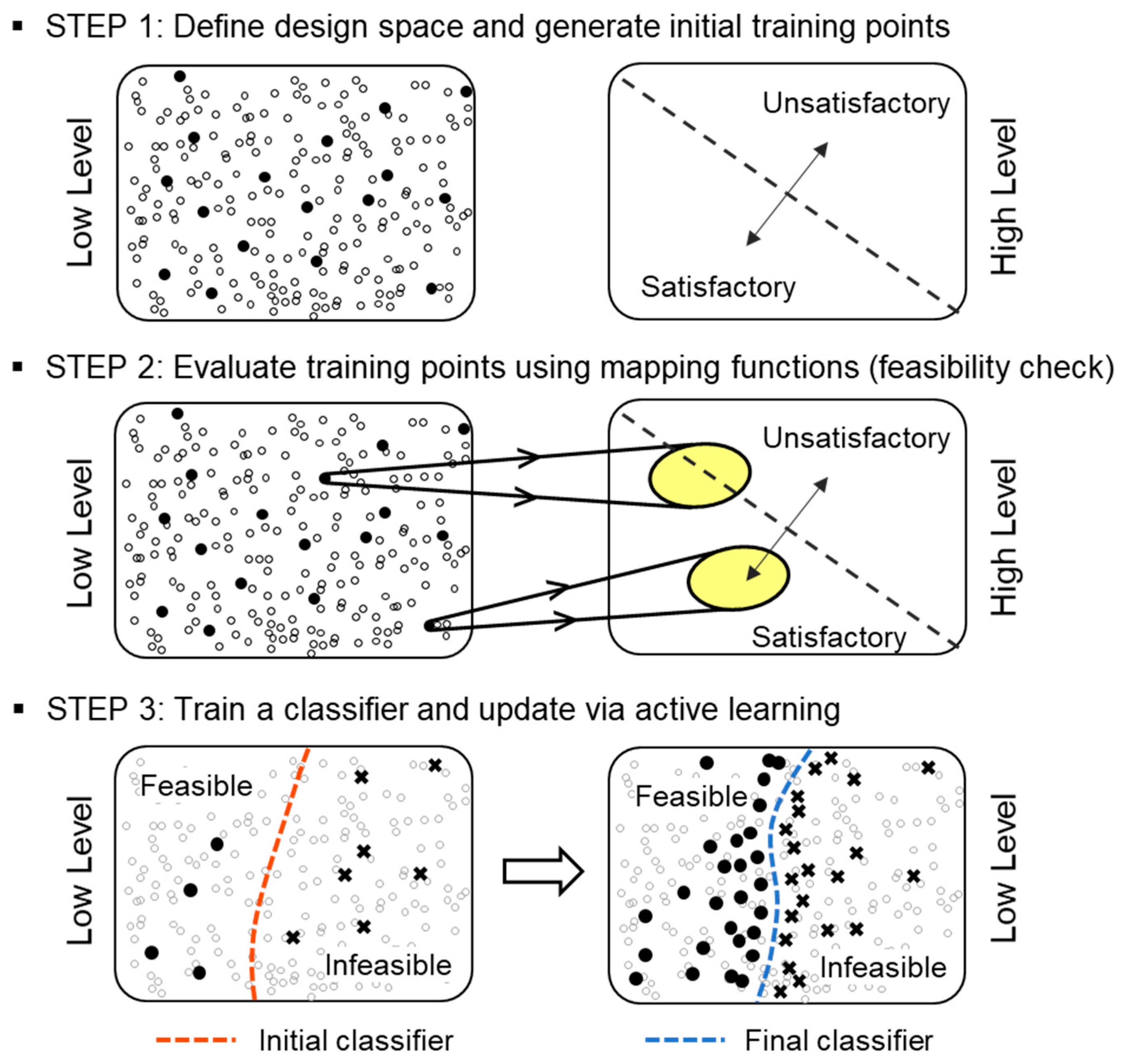
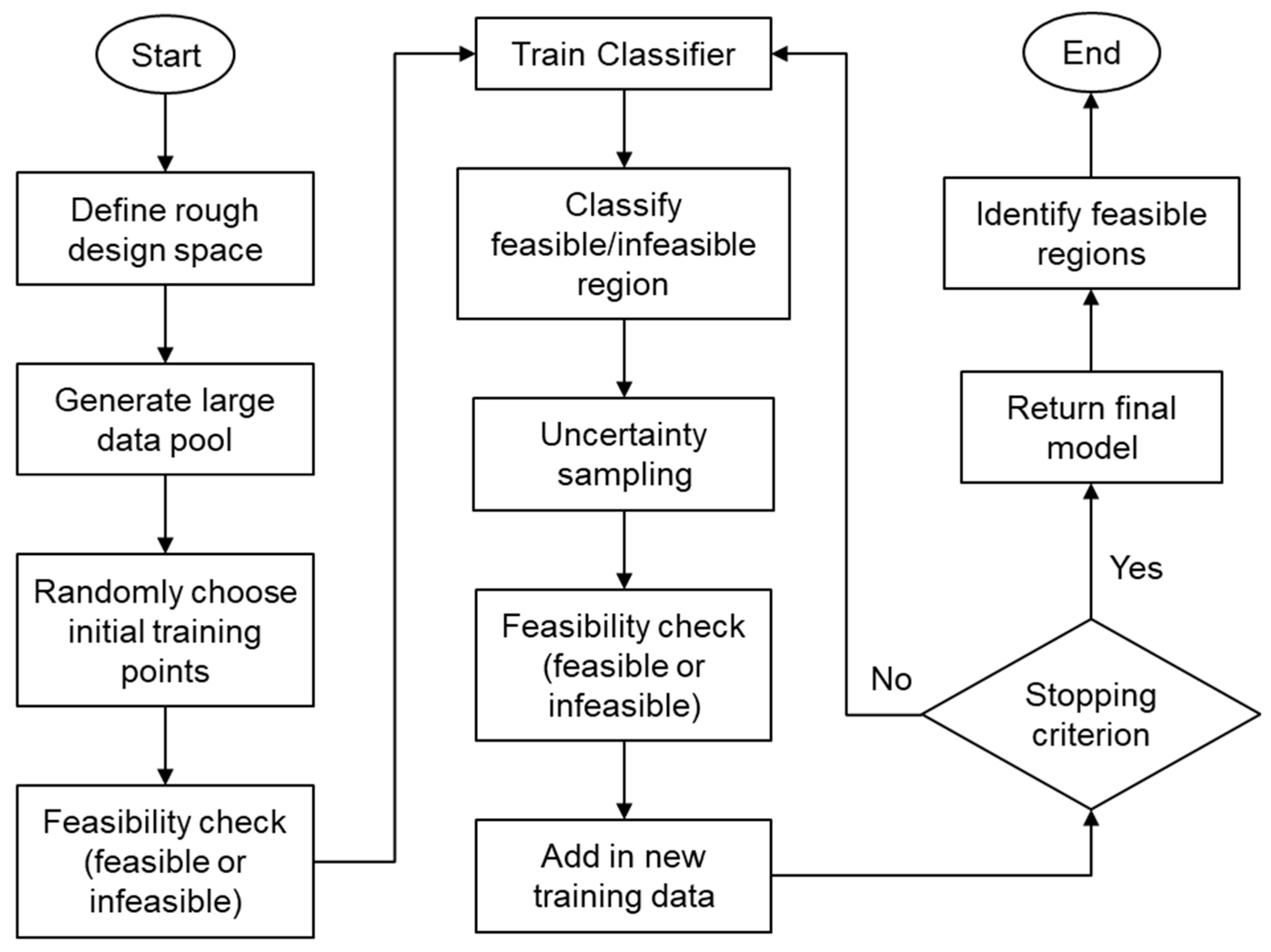
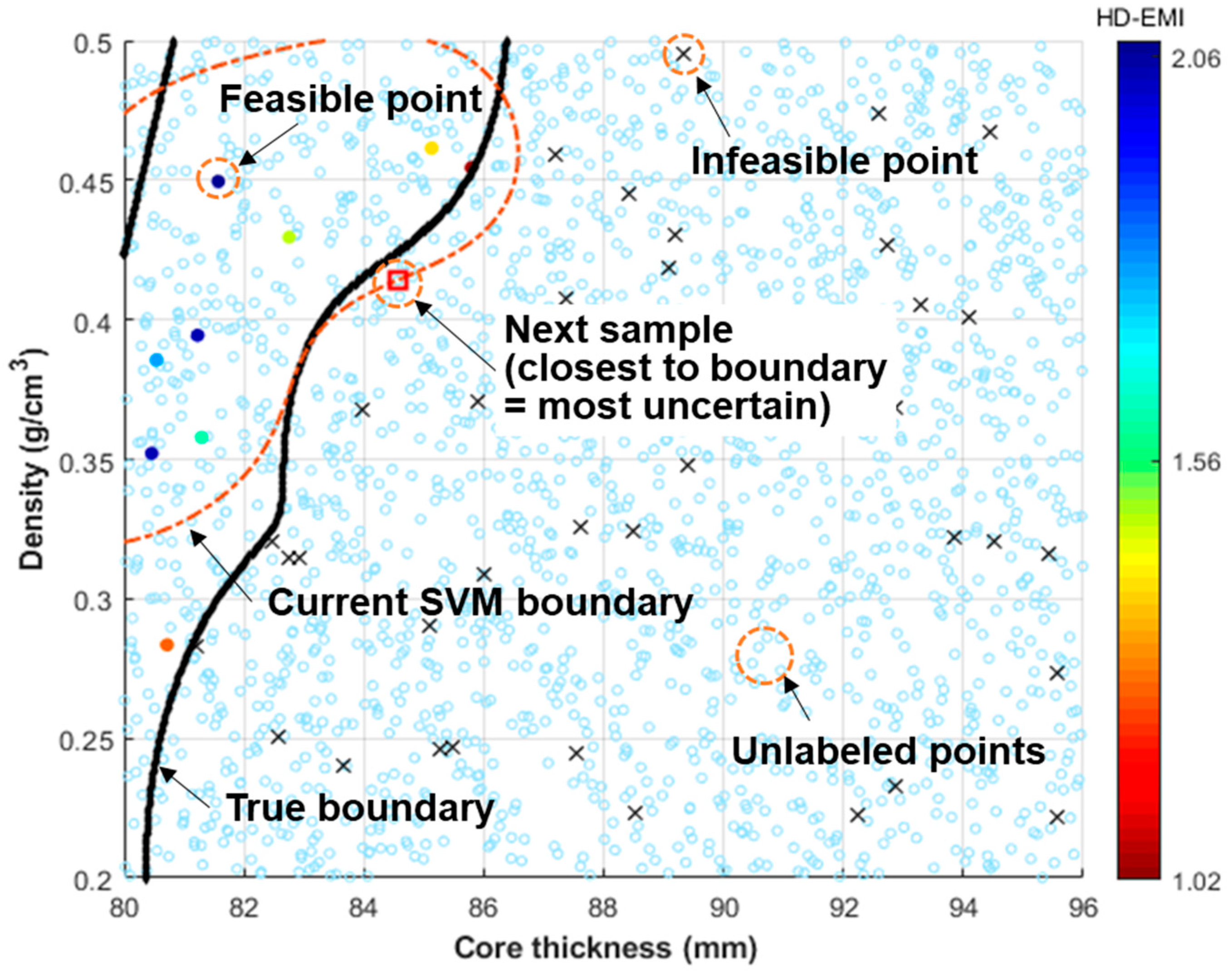
2.2. IDEM with Active Learning
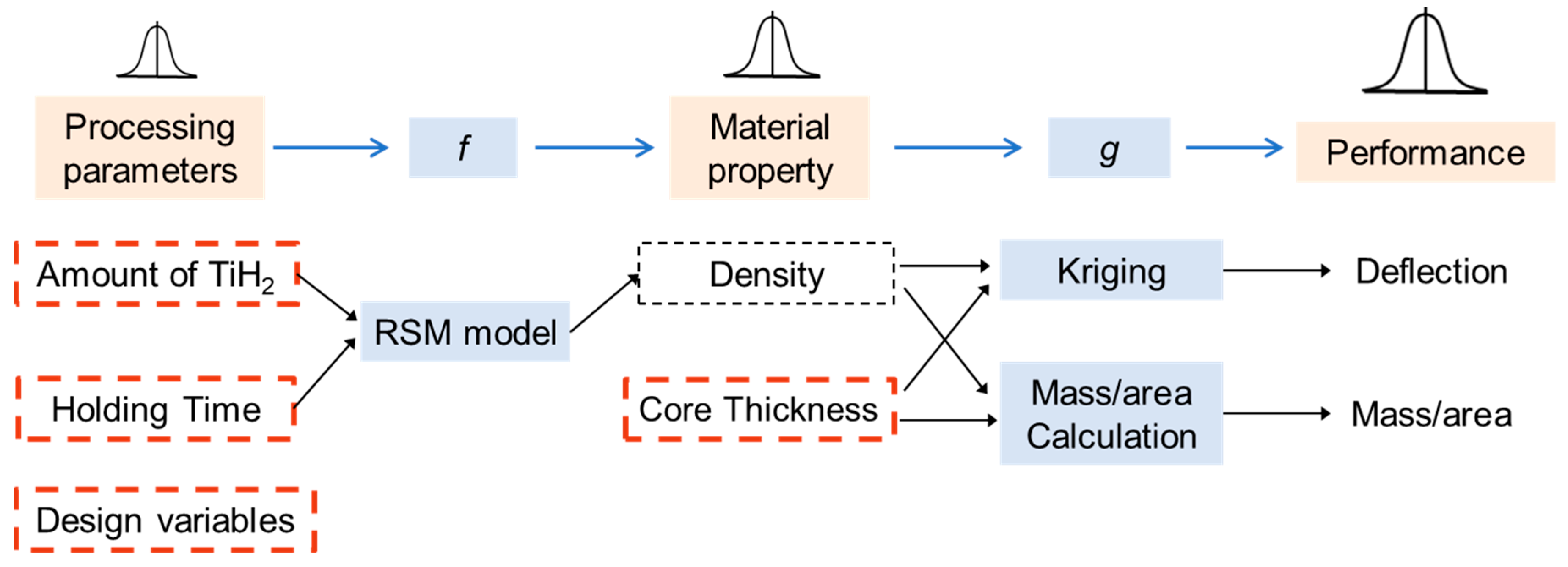
3. Demonstration Problem: Design of Aluminum Foam-Cored Sandwich Panel
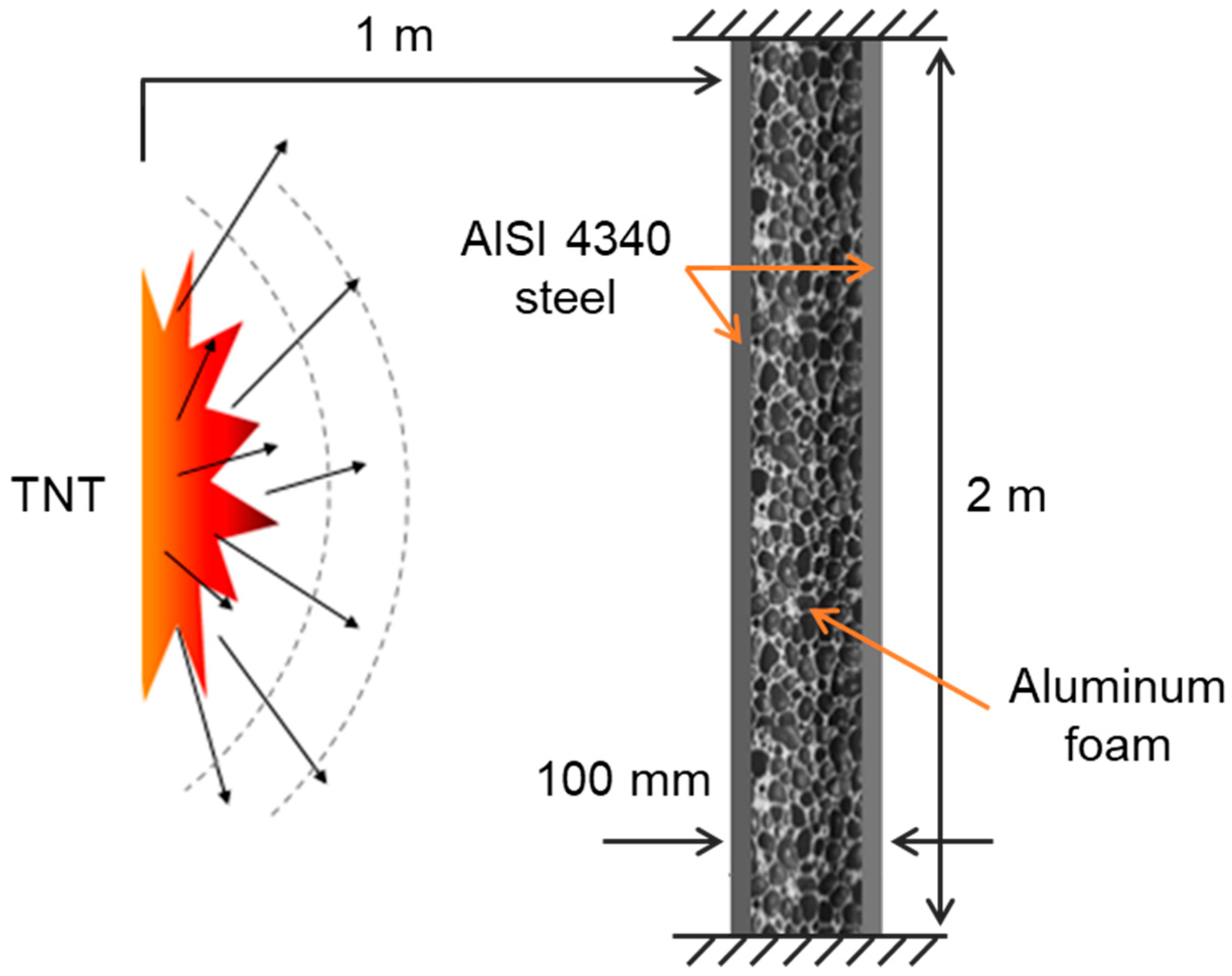
3.1. Problem Formulation
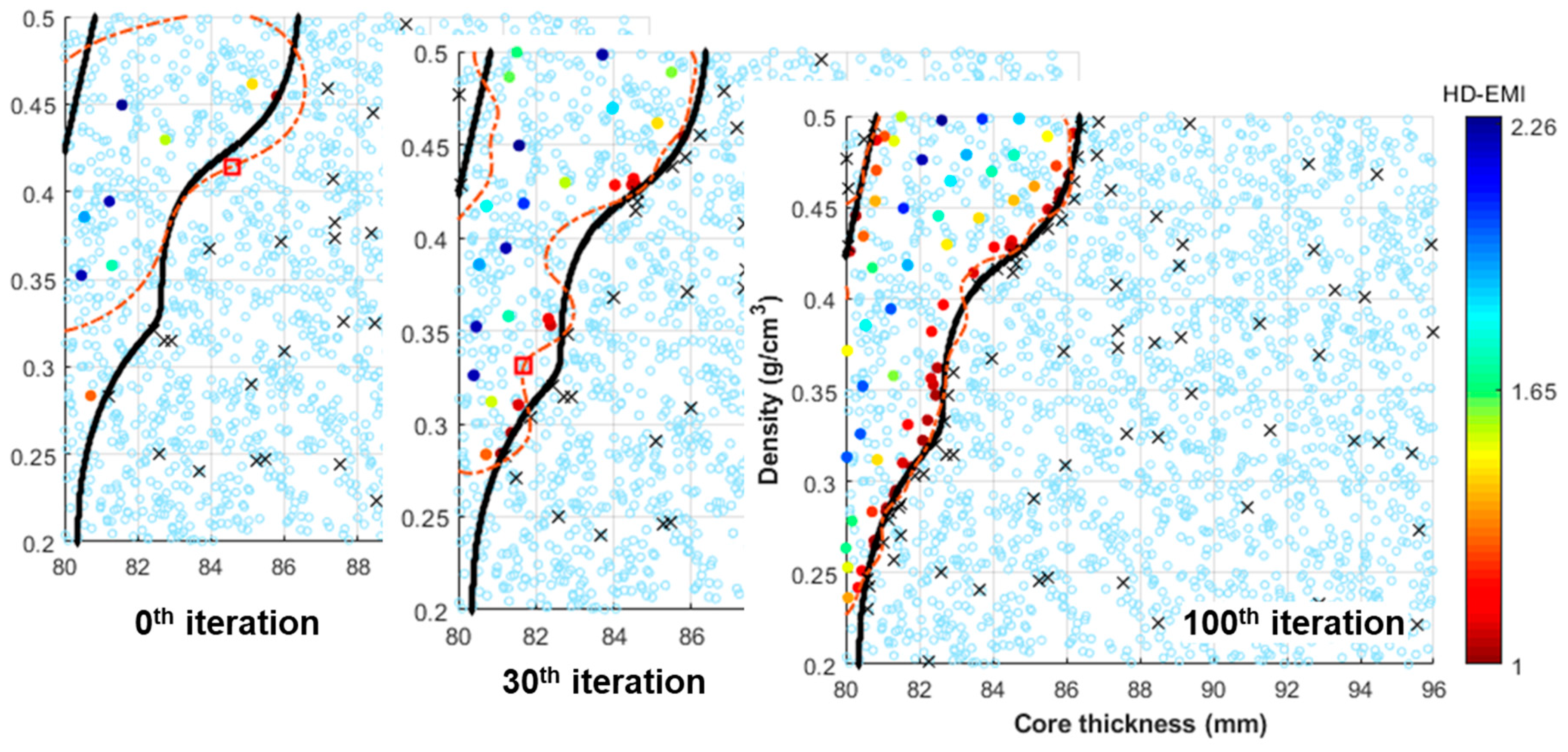
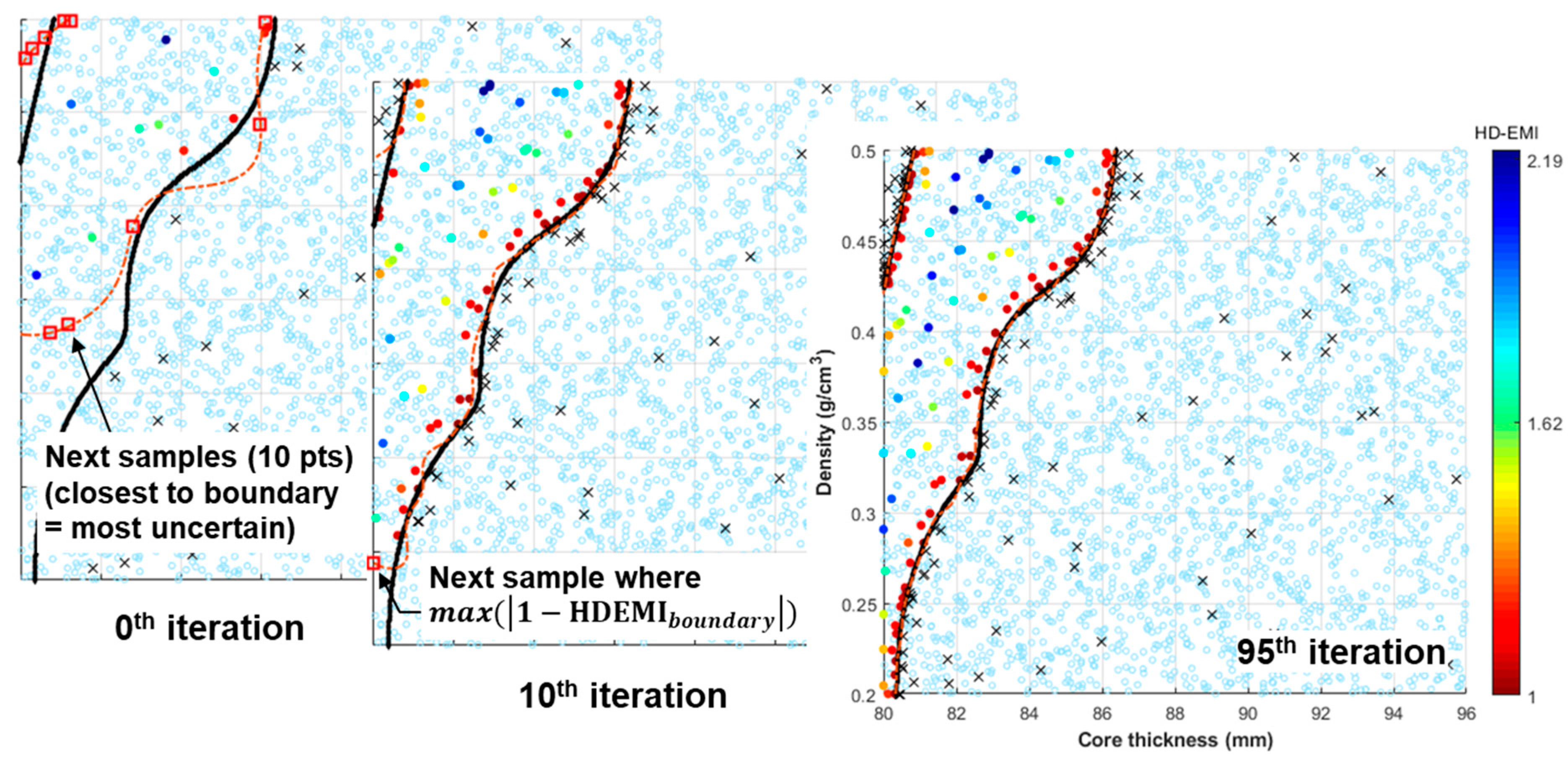
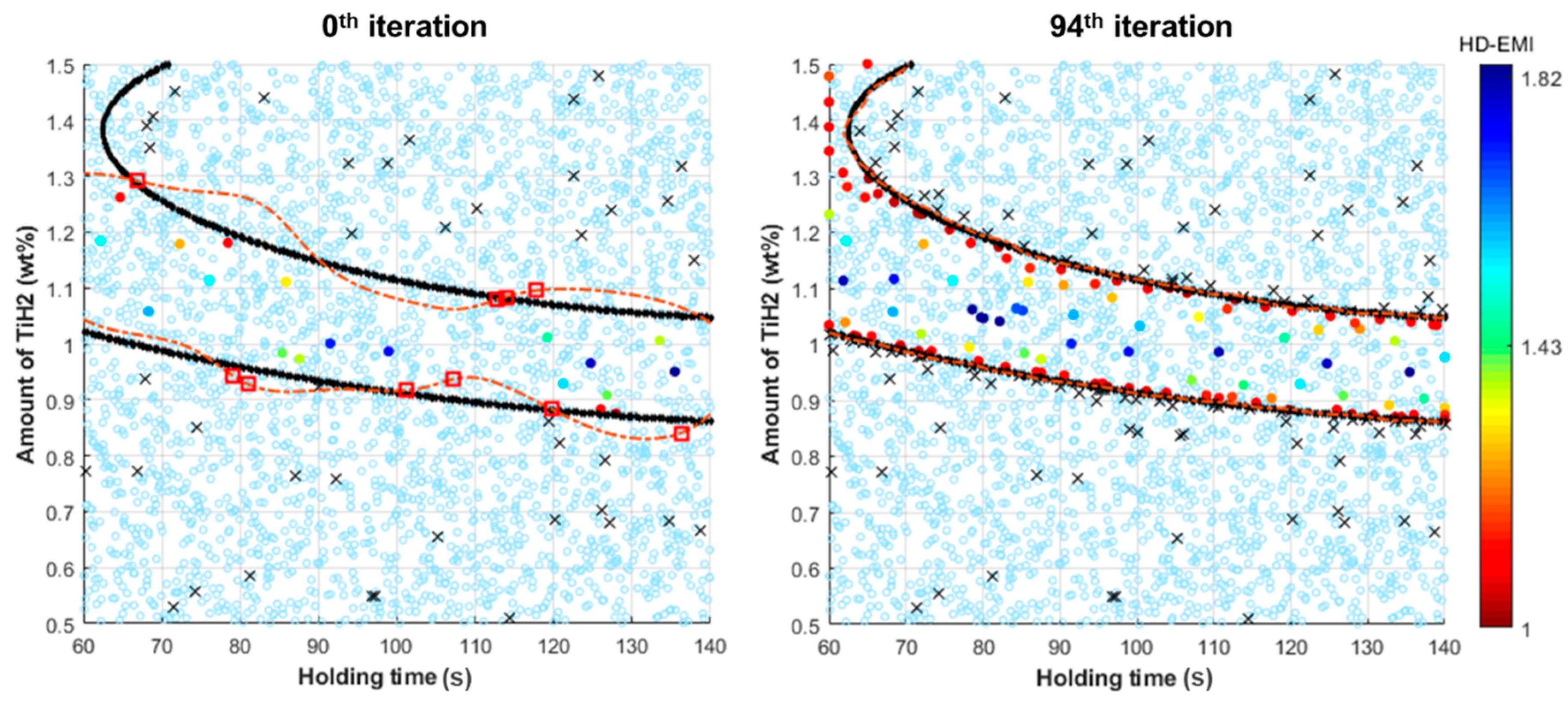
3.2. IDEM with Active Learning for Sandwich Panel Problem
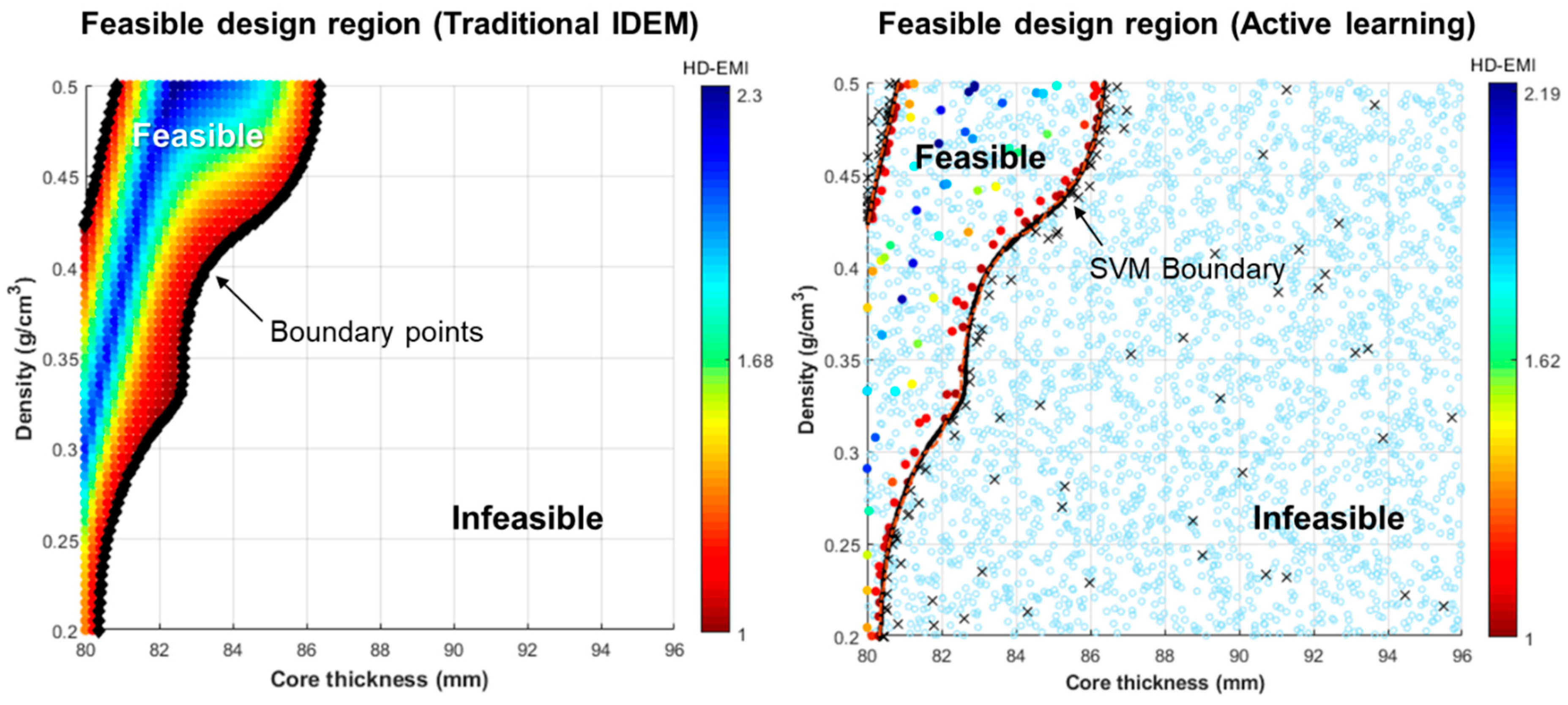
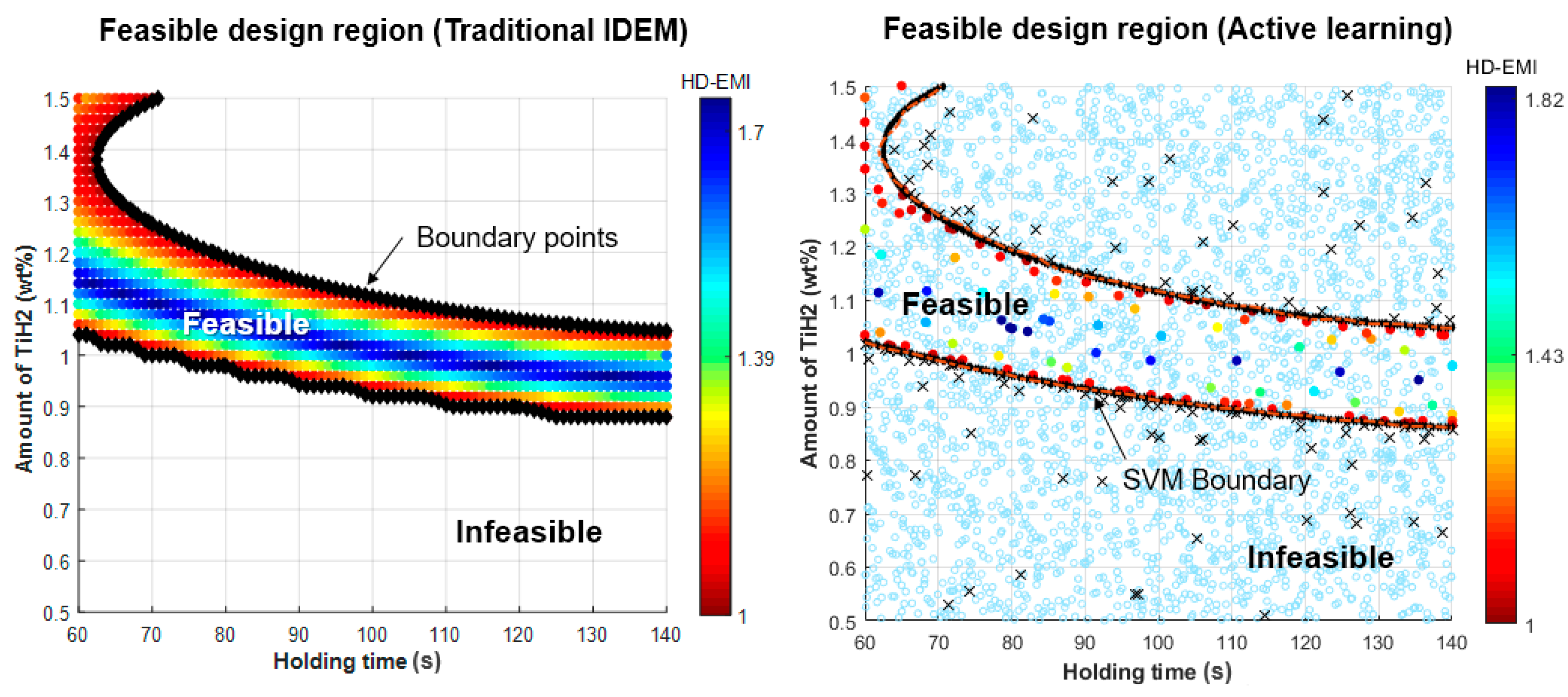
3.3. Comparison of Results with Traditional IDEM
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Olson, G.B. Computational design of hierarchically structured materials. Science 1997, 277, 1237–1242. [Google Scholar] [CrossRef]
- Shahan, D.W.; Seepersad, C.C. Bayesian network classifiers for set-based collaborative design. J. Mech. Des. 2012, 134, 071001. [Google Scholar] [CrossRef]
- Matthews, J.; Klatt, T.; Seepersad, C.C.; Haberman, M.; Shahan, D. Hierarchical Design of Composite Materials with Negative Stiffness Inclusions Using a Bayesian Network Classifier. In Proceedings of the ASME 2013 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Portland, OR, USA, 4–7 August 2013; p. V03AT03A055. [Google Scholar]
- Matthews, J.; Klatt, T.; Seepersad, C.C.; Haberman, M.; Shahan, D. Bayesian Network Classifiers and Design Flexibility Metrics for Set-Based, Multiscale Design With Materials Design Applications. In Proceedings of the ASME 2014 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Buffalo, NY, USA, 17–20 August 2014; p. V02BT03A008. [Google Scholar]
- Matthews, J.; Klatt, T.; Morris, C.; Seepersad, C.C.; Haberman, M.; Shahan, D. Hierarchical design of negative stiffness metamaterials using a bayesian network classifier. J. Mech. Des. 2016, 138, 041404. [Google Scholar] [CrossRef]
- Choi, H.-J.; Allen, J.K.; Rosen, D.; McDowell, D.L.; Mistree, F. An inductive design exploration method for the integrated design of multi-scale materials and products. In Proceedings of the ASME 2005 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Long Beach, CA, USA, 24–28 September 2005; pp. 859–870. [Google Scholar]
- Choi, H.-J.; McDowell, D.L.; Allen, J.K.; Mistree, F. An inductive design exploration method for hierarchical systems design under uncertainty. Eng. Optimiz. 2008, 40, 287–307. [Google Scholar] [CrossRef]
- Choi, H.-J.; McDowell, D.; Allen, J.; Rosen, D.; Mistree, F. An inductive design exploration method for robust multiscale materials design. J. Mech. Des. 2008, 130, 31402. [Google Scholar] [CrossRef]
- Jang, S.; Park, Y.; Choi, H.-J. Integrated design of aluminum foam processing parameters and sandwich panels under uncertainty. Proc. Inst. Mech. Eng. Part C J. Eng. Mech. Eng. Sci. 2015, 229, 2387–2401. [Google Scholar] [CrossRef]
- Jang, S.; Goh, C.H.; Choi, H.-J. Multiphase design exploration method for lightweight structural design: Example of vehicle mounted antenna-supporting structure. Int. J. Precis. Eng. Manuf.-Green Technol. 2015, 2, 281–287. [Google Scholar] [CrossRef] [Green Version]
- Kern, P.C.; Priddy, M.W.; Ellis, B.D.; McDowell, D.L. pyDEM: A generalized implementation of the inductive design exploration method. Mater. Des. 2017, 134, 293–300. [Google Scholar] [CrossRef]
- Ellis, B.D.; McDowell, D.L. Application-Specific Computational Materials Design via Multiscale Modeling and the Inductive Design Exploration Method (IDEM). Integr. Mater. Manuf. Innov. 2017, 6, 9–35. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey; Computer Sciences Technical Report 1648; University of Wisconsin-Madison: Madison, WI, USA, 2009. [Google Scholar]
- Sassano, M. An empirical study of active learning with support vector machines for Japanese word segmentation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 505–512. [Google Scholar]
- Tong, S.; Chang, E. Support vector machine active learning for image retrieval. In Proceedings of the 9th ACM international conference on Multimedia, Ottawa, QC, Canada, 30 September–5 October 2001; pp. 107–118. [Google Scholar]
- Tong, S.; Koller, D. Support vector machine active learning with applications to text classification. J. Mach. Learn. Res. 2001, 2, 45–66. [Google Scholar]
- Warmuth, M.K.; Liao, J.; Rätsch, G.; Mathieson, M.; Putta, S.; Lemmen, C. Active Learning with Support Vector Machines in the Drug Discovery Process. J. Chem. Inf. Comput. Sci. 2003, 43, 667–673. [Google Scholar] [CrossRef] [PubMed]
- Baumeister, J.; Banhart, J.; Weber, M. Aluminium foams for transport industry. Mater. Des. 1997, 18, 217–220. [Google Scholar] [CrossRef]
- Schwingel, D.; Seeliger, H.-W.; Vecchionacci, C.; Alwes, D.; Dittrich, J. Aluminium foam sandwich structures for space applications. Acta Astronaut. 2007, 61, 326–330. [Google Scholar] [CrossRef]
- Ashby, M.F.; Evans, A.G.; Fleck, N.A.; Gibson, L.J.; Hutchinson, J.W.; Wadley, H.N.G. Metal Foams: A Design Guide; Butterworth-Heinemann: Oxford, UK, 2000. [Google Scholar]
- Deshpande, V.S.; Fleck, N.A. High strain rate compressive behaviour of aluminium alloy foams. Int. J. Impact Eng. 2000, 24, 277–298. [Google Scholar] [CrossRef] [Green Version]
- Edwin Raj, R.; Daniel, B.S.S. Customization of closed-cell aluminum foam properties using design of experiments. Mater. Sci. Eng. A Struct. Mater. Prop. Microstruct. Process. 2011, 528, 2067–2075. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Zhu, J.; Wang, H.; Yao, T.; Tsou, B.K. Active learning with sampling by uncertainty and density for word sense disambiguation and text classification. In Proceedings of the 22nd International Conference on Computational Linguistics, Manchester, UK, 18–22 August 2008; pp. 1137–1144. [Google Scholar]












© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jang, S.; Choi, H.-J.; Choi, S.-K.; Oh, J.-S. Inductive Design Exploration Method with Active Learning for Complex Design Problems. Appl. Sci. 2018, 8, 2418. https://doi.org/10.3390/app8122418
Jang S, Choi H-J, Choi S-K, Oh J-S. Inductive Design Exploration Method with Active Learning for Complex Design Problems. Applied Sciences. 2018; 8(12):2418. https://doi.org/10.3390/app8122418
Chicago/Turabian StyleJang, Sungwoo, Hae-Jin Choi, Seung-Kyum Choi, and Jae-Sung Oh. 2018. "Inductive Design Exploration Method with Active Learning for Complex Design Problems" Applied Sciences 8, no. 12: 2418. https://doi.org/10.3390/app8122418