A New Cost Function Combining Deep Neural Networks (DNNs) and l2,1-Norm with Extraction of Robust Facial and Superpixels Features in Age Estimation

Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Deep Learning
2.2. l2,1-Norm
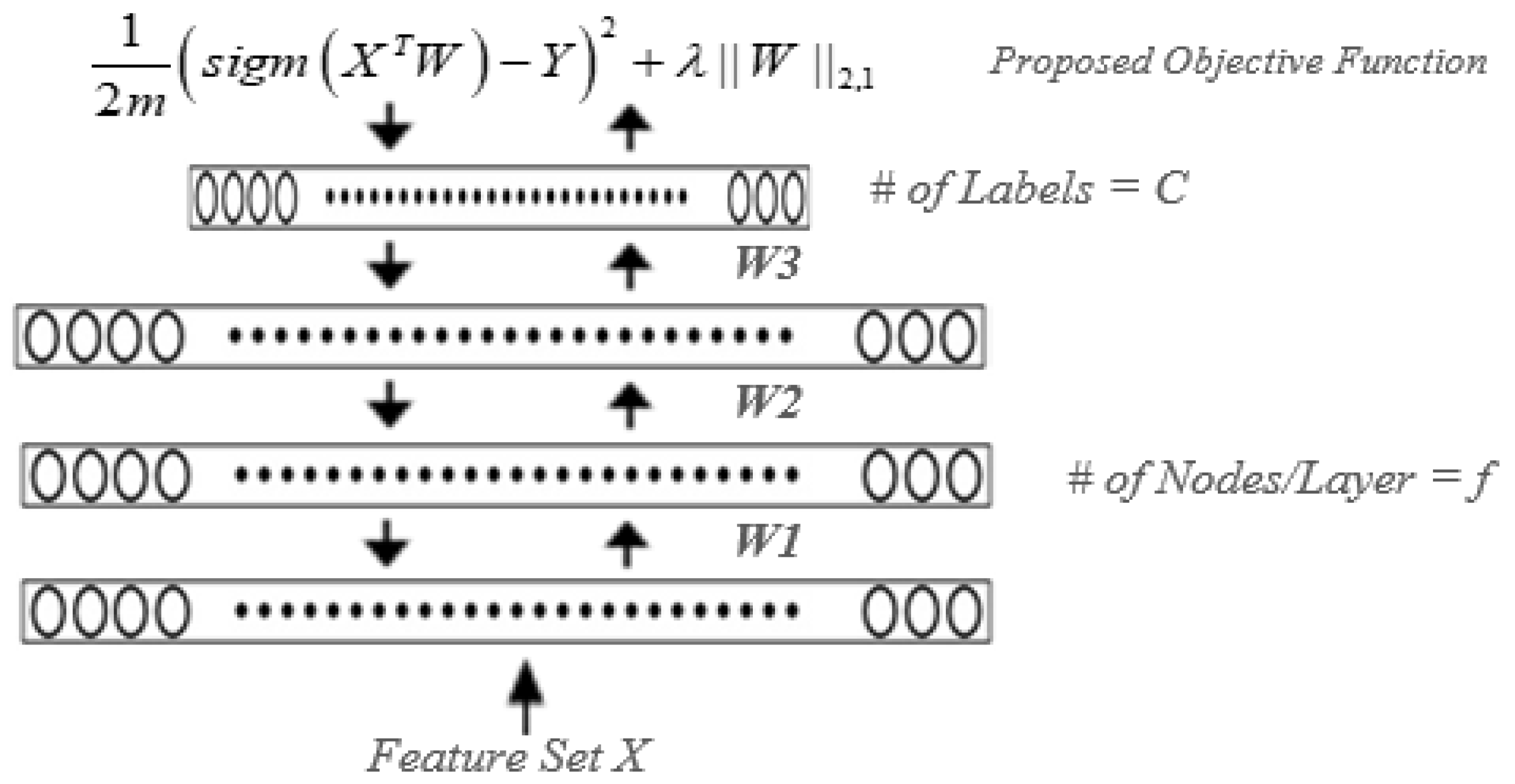
2.3. Proposed Model: DNNs and l2,1-Norm Regularization Framework for Robust Features Selection
2.3.1. The Architecture
2.3.2. Learning
2.4. Feature Sets
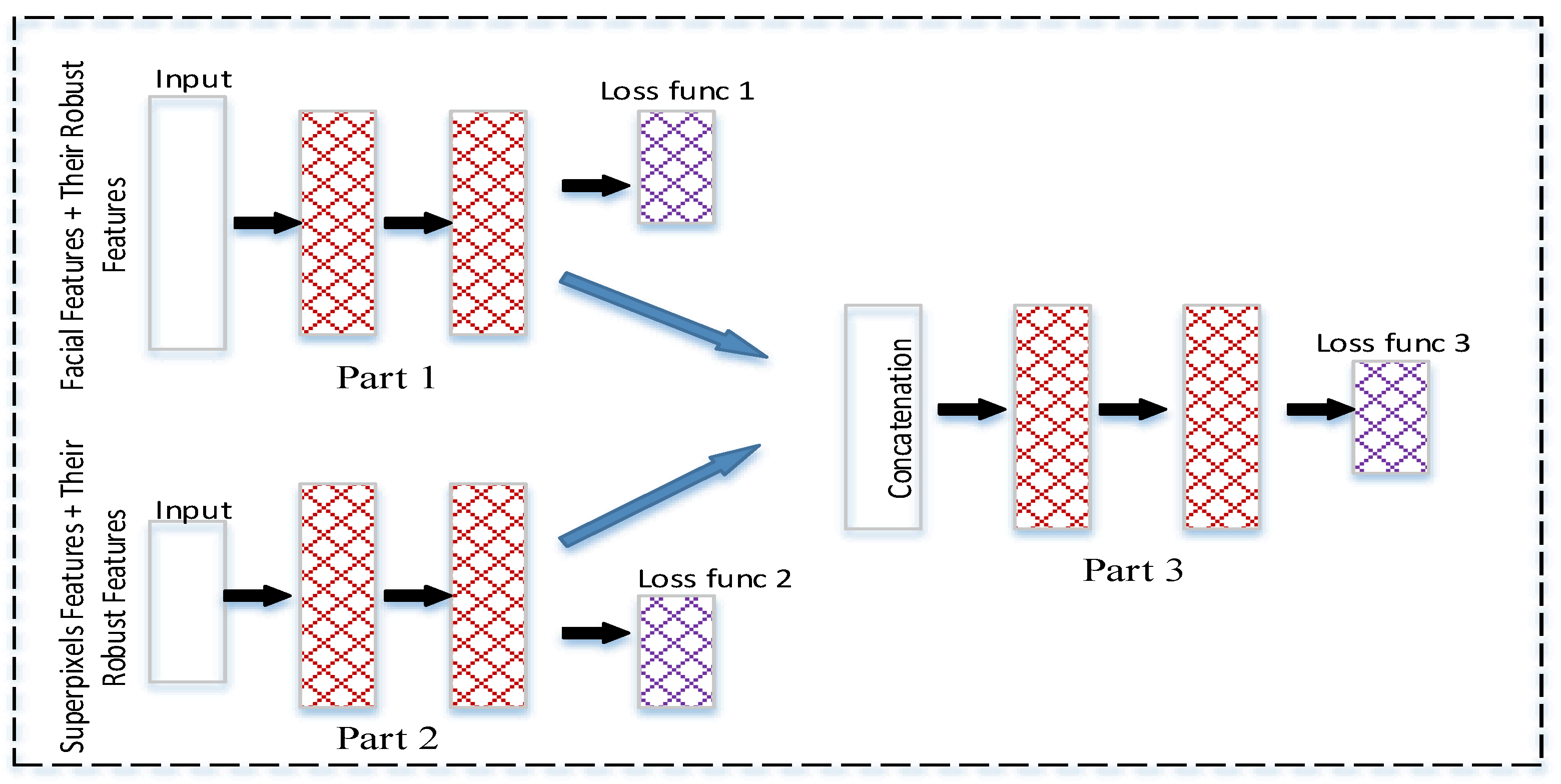
2.5. Jointly Fine-Tuning of Two DNNs
2.5.1. By Amplified Features (JFN-A)
- Step 1:
- Three loss functions are used to train the three networks. All three loss functions are the softmax cross entropy function, as in (11).Li is the loss function of the network i, yj is the jth value of the label, and is the jth output value of the network i.
- Step 2:
- The first and second parts of the model are trained by using first batch of their corresponding features. Then, the outputs of the last hidden layer of both networks are element-wise summed to form the input of the third part, as in Equation (12).x3,j is the input of the third part, l1,j and l2,j are the outputs of the last hidden layer of the first and second parts, and Relu is the rectified activation function.
- Step 3:
- Feedforwarding, error calculation, and backpropagation are performed on the third part.
- Step 4:
- The steps from 1 to 3 are repeated for the rest of the training batches.
- Step 5:
- After the training is complete, the softmax output of the third part, , is obtained as the final decision, as in Equation (13).
2.5.2. By the Softmax and the Sigmoid (JFN-SS)
2.6. Database
3. Results
3.1. Robust Feature Selection Method
3.2. Jointly Fine-Tuning Robust Feature Sets
4. Discussion
- -
- The availability of large databases is essential to perform efficient age classification from facial images. It is especially important when the model utilizes deep and very deep NNs. Otherwise, the model is liable to overfitting problem. Database should contain sufficient examples of reflecting real environment challenges, such as pose, illumination, resolution, and other real conditions. In the case of relatively small databases, transferable learning could be used to compensate the limited facial images. For example, pre-trained models, which were trained over large databases for different yet related tasks, could be used and customized.
- -
- Extracting distinctive feature set(s) is also a very important step. Distinctive features allow for the classifier to differentiate between different age groups efficiently. Finding such feature sets is not an easy task and it needs a thorough investigation and study.
- -
- Choosing a classifier to utilize and customize for the age classification task from facial images plays a major role in reaching a satisfactory and competitive classification accuracies.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predict | 0–2 | 4–6 | 8–13 | 15–20 | 25–32 | 38–43 | 48–53 | 60– | |
|---|---|---|---|---|---|---|---|---|---|
| Actual | |||||||||
| 0–2 | 82.19 | 15.73 | 0.21 | 0.00 | 1.86 | 0.00 | 0.00 | 0.00 | |
| 4–6 | 13.51 | 69.12 | 12.98 | 1.23 | 2.81 | 0.18 | 0.00 | 0.18 | |
| 8–13 | 0.59 | 5.88 | 39.71 | 5.59 | 44.12 | 3.82 | 0.00 | 0.29 | |
| 15–20 | 0.44 | 0.88 | 15.42 | 12.78 | 65.64 | 3.96 | 0.00 | 0.88 | |
| 25–32 | 0.19 | 0.38 | 5.49 | 1.52 | 76.42 | 11.65 | 0.76 | 3.60 | |
| 38–43 | 0.59 | 0.39 | 1.97 | 0.59 | 62.73 | 19.53 | 3.55 | 10.65 | |
| 48–53 | 0.83 | 0.41 | 3.73 | 2.49 | 52.70 | 23.24 | 6.64 | 9.96 | |
| 60– | 0.00 | 0.39 | 1.17 | 0.00 | 29.97 | 27.24 | 2.72 | 38.52 | |
| Predict | 0–2 | 4–6 | 8–13 | 15–20 | 25–32 | 38–43 | 48–53 | 60– | |
|---|---|---|---|---|---|---|---|---|---|
| Actual | |||||||||
| 0–2 | 78.14 | 17.35 | 2.24 | 0.32 | 1.41 | 0 | 0 | 0.54 | |
| 4–6 | 28.27 | 52.37 | 9.42 | 4.64 | 2.92 | 1.16 | 0.64 | 0.58 | |
| 8–13 | 2.31 | 7.67 | 36.46 | 8.54 | 38.12 | 5.03 | 0 | 1.87 | |
| 15–20 | 0 | 4.99 | 14.08 | 20.28 | 53.24 | 3.92 | 1.85 | 1.64 | |
| 25–32 | 1.88 | 2.43 | 6.04 | 7.93 | 67.61 | 9.51 | 1.23 | 3.37 | |
| 38–43 | 1.63 | 2.66 | 3.49 | 6.7 | 55.44 | 17.77 | 5.08 | 7.23 | |
| 48–53 | 0 | 3.96 | 5.65 | 3.72 | 44.29 | 11.89 | 17.38 | 13.11 | |
| 60– | 0.07 | 2.07 | 3.69 | 7.81 | 20.83 | 5.46 | 2.92 | 57.15 | |
References
- Fu, Y.; Guo, G.; Huang, T.S. Age synthesis and estimation via faces: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1955–1976. [Google Scholar] [PubMed]
- Barer, B.M. Men and women aging differently. Int. J. Aging Hum. Dev. 1994, 38, 29–40. [Google Scholar] [CrossRef] [PubMed]
- Sveikata, K.; Balciuniene, I.; Tutkuviene, J. Factors influencing face aging. Literature review. Stomatologija Baltic Dent. Maxillofacial J. 2011, 13, 113–115. [Google Scholar]
- Ramanathan, N.; Chellappa, R. Face verification across age progression. IEEE Trans. Image Process. 2006, 15, 3349–3361. [Google Scholar] [CrossRef] [PubMed]
- Levi, G.; Hassner, T. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 34–42. [Google Scholar]
- Hong, L.; Jain, A.K.; Pankanti, S. Can multibiometrics improve performance? In Proceedings of the AutoID ’99, Summit, NJ, USA, 28–29 October 1999; pp. 59–64. [Google Scholar]
- Jain, A.K.; Dass, S.C.; Nandakumar, K. Soft biometric traits for personal recognition systems. In Biometric Authentication; Springer: Berlin/Heidelberg, Germany, 2004; pp. 731–738. [Google Scholar]
- Brin, S.; Page, L. Reprint of: The anatomy of a large-scale hypertextual web search engine. Comput. Netw. 2012, 56, 3825–3833. [Google Scholar] [CrossRef]
- Linden, G.; Smith, B.; York, J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Qawaqneh, Z.; Mallouh, A.A.; Barkana, B.D. Age and gender classification from speech and face images by jointly fine-tuned deep neural networks. Expert Syst. Appl. 2017, 85, 76–86. [Google Scholar] [CrossRef]
- Kwon, Y.H.; Lobo, N.D. Age classification from facial images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 21–23 June 1994; pp. 762–767. [Google Scholar]
- Farkas, L.G. Anthropometry of the Head and Face; Raven Press: New York, NY, USA, 1994. [Google Scholar]
- Ramanathan, N.; Chellappa, R. Modeling age progression in young faces. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006; pp. 387–394. [Google Scholar]
- Cootes, T.F.; Edwards, G.J.; Taylor, C.J. Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 681–685. [Google Scholar] [CrossRef] [Green Version]
- Lanitis, A.; Taylor, C.J.; Cootes, T.F. Modeling the process of ageing in face images. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 131–136. [Google Scholar]
- Lanitis, A.; Taylor, C.J.; Cootes, T.F. Toward automatic simulation of aging effects on face images. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 442–455. [Google Scholar] [CrossRef]
- Luu, K.; Ricanek, K.; Bui, T.D.; Suen, C.Y. Age estimation using active appearance models and support vector machine regression. In Proceedings of the IEEE 3rd International Conference on Biometrics: Theory, Applications, and Systems, Los Angeles, CA, USA, 22–25 October 2009; pp. 1–5. [Google Scholar]
- Luu, K.; Seshadri, K.; Savvides, M.; Bui, T.D.; Suen, C.Y. Contourlet appearance model for facial age estimation. In Proceedings of the International Joint Conference on Biometrics, Washington, DC, USA, 11–13 October 2011; pp. 1–8. [Google Scholar]
- Geng, X.; Zhou, Z.-H.; Zhang, Y.; Li, G.; Dai, H. Learning from facial aging patterns for automatic age estimation. In Proceedings of the 14th ACM International Conference on Multimedia, Santa Barbara, CA, USA, 23–27 October 2006; pp. 307–316. [Google Scholar]
- Geng, X.; Zhou, Z.-H.; Smith-Miles, K. Automatic age estimation based on facial aging patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2234–2240. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Xu, Y.; Huang, T.S. Estimating human age by manifold analysis of face pictures and regression on aging features. In Proceedings of the IEEE International Conference on Multimedia and Expo, Beijing, China, 2–5 July 2007; pp. 1383–1386. [Google Scholar]
- Fu, Y.; Huang, T.S. Human age estimation with regression on discriminative aging manifold. IEEE Trans. Multimed. 2008, 10, 578–584. [Google Scholar] [CrossRef]
- Scherbaum, K.; Sunkel, M.; Seidel, H.P.; Blanz, V. Prediction of Individual Non-Linear Aging Trajectories of Faces. In Proceedings of the Computer Graphics Forum, Oxford, UK, 12 October 2007; pp. 285–294. [Google Scholar]
- Guo, G.; Fu, Y.; Dyer, C.R.; Huang, T.S. Image-based human age estimation by manifold learning and locally adjusted robust regression. IEEE Trans. Image Process. 2008, 17, 1178–1188. [Google Scholar] [PubMed]
- Hayashi, J.; Yasumoto, M.; Ito, H.; Niwa, Y.; Koshimizu, H. Age and gender estimation from facial image processing. In Proceedings of the 41st SICE Annual Conference, Osaka, Japan, 5–7 August 2002; pp. 13–18. [Google Scholar]
- Hayashi, J.; Yasumoto, M.; Ito, H.; Koshimizu, H. Method for estimating and modeling age and gender using facial image processing. In Proceedings of the Seventh International Conference on Virtual Systems and Multimedia, Berkeley, CA, USA, 25–27 October 2001; pp. 439–448. [Google Scholar]
- Gunay, A.; Nabiyev, V.V. Automatic age classification with LBP. In Proceedings of the 23rd International Symposium on Computer and Information Sciences (ISCIS), Istanbul, Turkey, 27–29 October 2008; pp. 1–4. [Google Scholar]
- Gao, F.; Ai, H. Face age classification on consumer images with gabor feature and fuzzy LDA method. In Proceedings of the International Conference on Biometrics, Alghero, Italy, 2–5 June 2009; pp. 132–141. [Google Scholar]
- Yan, S.; Liu, M.; Huang, T.S. Extracting age information from local spatially flexible patches. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 30 March–4 April 2008; pp. 737–740. [Google Scholar]
- Yan, S.; Zhou, X.; Liu, M.; Hasegawa-Johnson, M.; Huang, T.S. Regression from patch-kernel. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Mu, G.; Guo, G.; Fu, Y.; Huang, T.S. Human age estimation using bio-inspired features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–24 June 2009; pp. 112–119. [Google Scholar]
- Shan, C. Learning local features for age estimation on real-life faces. In Proceedings of the 1st ACM International Workshop on Multimodal Pervasive Video Analysis, Firenze, Italy, 25–29 October 2010; pp. 23–28. [Google Scholar]
- Lu, J.; Liong, V.E.; Zhou, J. Cost-sensitive local binary feature learning for facial age estimation. IEEE Trans. Image Process. 2015, 24, 5356–5368. [Google Scholar] [CrossRef] [PubMed]
- Ranjan, R.; Zhou, S.; Chen, J.C.; Kumar, A.; Alavi, A.; Patel, V.M. Unconstrained age estimation with deep convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 109–117. [Google Scholar]
- Chen, J.-C.; Kumar, A.; Ranjan, R.; Patel, V.M.; Alavi, A.; Chellappa, R. A cascaded convolutional neural network for age estimation of unconstrained faces. In Proceedings of the IEEE 8th International Conference on Biometrics Theory, Applications and Systems (BTAS), Angeles, CA, USA, 22–25 October 2016; pp. 1–8. [Google Scholar]
- Yang, H.-F.; Lin, B.-Y.; Chang, K.-Y.; Chen, C.-S. Automatic Age Estimation from Face Images via Deep Ranking. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; p. 55. [Google Scholar]
- Yi, D.; Lei, Z.; Li, S.Z. Age estimation by multi-scale convolutional network. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 144–158. [Google Scholar]
- Liu, X.; Li, S.; Kan, M.; Zhang, J.; Wu, S.; Liu, W.; Han, H.; Shan, S.; Chen, X. Agenet: Deeply learned regressor and classifier for robust apparent age estimation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 258–266. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-R.; Jaitly, N. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, X.; Tang, X. Deep learning face representation from predicting 10,000 classes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1891–1898. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; p. 6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems Conference, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Lake Tahoe, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 431–3440. [Google Scholar]
- Argyriou, A.; Evgeniou, T.; Pontil, M. Multi-task feature learning. In Proceedings of the Neural Information Processing Systems Conference, Vancouver, BC, Canada, 3–6 December 2007; pp. 41–48. [Google Scholar]
- Obozinski, G.; Taskar, B. Multi-task feature selection. In Proceedings of the 23rd International Conference on Machine Learning (ICML), Pittsburgh, PA, USA, 25–26 June 2006. [Google Scholar]
- Wang, L.; Zhu, J.; Zou, H. Hybrid huberized support vector machines for microarray classification. In Proceedings of the 24th International Conference on Machine Learning (ICML), Corvalis, OR, USA, 20–24 June 2007; pp. 983–990. [Google Scholar]
- Nie, F.; Huang, H.; Cai, X.; Ding, C. Efficient and robust feature selection via joint L21-norms minimization. In Proceedings of the Neural Information Processing Systems (NIPS) Conference, Vancouver, BC, Canada, 6–9 December 2010; pp. 1813–1821. [Google Scholar]
- Ding, C.; Zhou, D.; He, X.; Zha, H. R 1-PCA: Rotational invariant L 1-norm principal component analysis for robust subspace factorization. In Proceedings of the 23rd International Conference on Machine Learning (ICML), Pittsburgh, PA, USA, 25–29 June 2006; pp. 281–288. [Google Scholar]
- Gu, Q.; Li, Z.; Han, J. Joint feature selection and subspace learning. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Barcelona, Spain, 16–22 July 2011; pp. 1294–1299. [Google Scholar]
- He, R.; Tan, T.N.; Wang, L.; Zheng, W. L21 regularized correntropy for robust feature selection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2504–2511. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G. Deep convolutional neural fields for depth estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5162–5170. [Google Scholar]
- Eidinger, E.; Enbar, R.; Hassner, T. Age and gender estimation of unfiltered faces. IEEE Trans. Inf. Forensic Secur. 2014, 9, 2170–2179. [Google Scholar] [CrossRef]
- Hebda, B.; Kryjak, T. A compact deep convolutional neural network architecture for video based age and gender estimation. In Proceedings of the IEEE Federated Conference in Computer Science and Information Systems (FedCSIS), Gdańsk, Poland, 11–14 September 2016; pp. 787–790. [Google Scholar]
- Zhu, L.; Wang, K.; Lin, L.; Zhang, L. Learning a lightweight deep convolutional network for joint age and gender recognition. In Proceedings of the IEEE 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3282–3287. [Google Scholar]
- Rothe, R.; Timofte, R.; van Gool, L. Deep expectation of real and apparent age from a single image without facial landmarks. Int. J. Comput. Vis. 2018, 126–144. [Google Scholar] [CrossRef]
- Iqbal, M.T.B.; Shoyaib, M.; Ryu, B.; Abdullah-Al-Wadud, M.; Chae, O. Directional Age-Primitive Pattern (DAPP) for Human Age Group Recognition and Age Estimation. IEEE Trans. Inf. Forensic Secur. 2017, 12, 2505–2517. [Google Scholar] [CrossRef]
- Liu, H.; Lu, J.; Feng, J.; Zhou, J. Label-Sensiti00000ve Deep Metric Learning for Facial Age Estimation. IEEE Trans. Inf. Forensic Secur. 2018, 13, 292–305. [Google Scholar] [CrossRef]
- Duan, M.; Li, K.; Yang, C.; Li, K. A hybrid deep learning CNN–ELM for age and gender classification. Neurocomputing 2018, 275, 448–461. [Google Scholar] [CrossRef]
- Rodríguez, P.; Cucurull, G.; Gonfaus, J.M.; Roca, F.X.; Gonzàlez, J. Age and gender recognition in the wild with deep attention. Pattern Recognit. 2017, 72, 563–571. [Google Scholar] [CrossRef]








| Age Groups | 0–2 | 4–6 | 8–13 | 15–20 | 25–32 | 38–43 | 48–53 | 60– | Accuracy | 1-Off Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Feature Sets | |||||||||||
| Facial | 88.41 | 60.18 | 39.12 | 43.61 | 67.14 | 43.79 | 14.52 | 57.20 | 57.45 | 94.32 | |
| Robust-Facial | 82.19 | 69.12 | 39.71 | 12.78 | 76.42 | 19.53 | 6.64 | 38.52 | 53.25 | 81.18 | |
| Facial + Robust-Facial | 86.96 | 65.96 | 45.88 | 35.24 | 78.98 | 41.22 | 15.35 | 83.66 | 63.22 | 94.38 | |
| Superpixels Features | 86.34 | 58.82 | 34.18 | 15.01 | 80.78 | 11.05 | 10.88 | 53.31 | 53.62 | 81.40 | |
| Robust-Superpixels | 78.14 | 52.37 | 36.46 | 20.28 | 67.61 | 17.77 | 17.38 | 57.15 | 49.95 | 78.89 | |
| Superpixels + Robust-Superpixels | 87.56 | 56.82 | 43.57 | 31.05 | 78.31 | 24.81 | 29.70 | 60.96 | 58.31 | 86.17 | |
| Age Groups | 0–2 | 4–6 | 8–13 | 15–20 | 25–32 | 38–43 | 48–53 | 60– | Accuracy | 1-Off Acc | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Features | |||||||||||
| (1) Superpixels Features concatenated with their robust features | 87.56 | 56.82 | 43.57 | 31.05 | 78.31 | 24.81 | 29.70 | 60.96 | 58.31 | 86.17 | |
| (2) Facial Features concatenated with their robust features | 86.96 | 65.96 | 45.88 | 35.24 | 78.98 | 41.22 | 15.35 | 83.66 | 63.22 | 94.38 | |
| (1) + (2) as input for JFN-A | 88.5 | 63.44 | 49.84 | 37.97 | 82.55 | 43.29 | 27.92 | 81.61 | 65.55 | 94.86 | |
| (1) + (2) as input for JFN-SS | 88.72 | 68.58 | 48.23 | 34.86 | 82.56 | 35.89 | 28.46 | 83.67 | 65.20 | 91.39 | |
| Method | Exact Accuracy | 1-Off Accuracy | |
|---|---|---|---|
| [5] | Shallow CNNs Using Single Crop | 49.5 | 84.6 |
| Shallow CNNs Using Over-Sample | 50.7 | 84.7 | |
| [10] | DNN1 with Facial Features | 57.45 | 94.32 |
| DNN2 with Superpixels Features | 53.62 | 81.40 | |
| Facial and Superpixels as input for JFN-SS | 62.37 | 94.46 | |
| [35] | Cascaded Convolutional Neural Network | 52.88 | 88.45 |
| [57] | LBP | 41.4 | 78.2 |
| LBP + FPLBP | 44.5 | 80.7 | |
| LBP + FPLBP + Dropout 0.5 | 44.5 | 80.6 | |
| LBP + FPLBP + Dropout 0.8 | 45.1 | 79.5 | |
| [58] | Compact DCNN architecture as base for video learning | 42.0 | - |
| [59] | Employ light weight DCNN for a multitask learning scheme (age + gender), best model single-6-conv | 49.7 | - |
| [60] | DCNNs based on VGG-16 architecture + softmax expected function for refinement | 55.6 | 89.7 |
| [61] | Subject-Exclusive DAPP | 54.9 | - |
| Subject-Inclusive DAPP | 62.2 | - | |
| [62] | LSDML: w/o data augmentation | 56 | - |
| LSDML: random cropping + horizontal flipping | 56.9 | - | |
| M-LSDML: w/o data augmentation + 3 DB | 58.2 | - | |
| M- LSDML: random cropping + horizontal flipping + 3 DB | 60.2 | - | |
| [63] | Proposed CNN-ELM + Dropout 0.5 | 51.4 | - |
| Proposed CNN-ELM + Dropout 0.7 | 52.3 | - | |
| [64] | VGG-16-Faces + Attention Network | 61.8 | 95.1 |
| This work | Facial and Superpixels as input for JFN-A | 63.78 | 93.70 |
| (1) Superpixels Features Concatenated with Their Robust Features | 58.31 | 86.17 | |
| (2) Facial Features Concatenated with Their Robust Features | 63.22 | 94.38 | |
| (1) + (2) as input for JFN-A | 65.55 | 94.86 | |
| (1) + (2) as input for JFN-SS | 65.20 | 91.39 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abu Mallouh, A.; Qawaqneh, Z.; Barkana, B.D. A New Cost Function Combining Deep Neural Networks (DNNs) and l2,1-Norm with Extraction of Robust Facial and Superpixels Features in Age Estimation. Appl. Sci. 2018, 8, 1943. https://doi.org/10.3390/app8101943
Abu Mallouh A, Qawaqneh Z, Barkana BD. A New Cost Function Combining Deep Neural Networks (DNNs) and l2,1-Norm with Extraction of Robust Facial and Superpixels Features in Age Estimation. Applied Sciences. 2018; 8(10):1943. https://doi.org/10.3390/app8101943
Chicago/Turabian StyleAbu Mallouh, Arafat, Zakariya Qawaqneh, and Buket D. Barkana. 2018. "A New Cost Function Combining Deep Neural Networks (DNNs) and l2,1-Norm with Extraction of Robust Facial and Superpixels Features in Age Estimation" Applied Sciences 8, no. 10: 1943. https://doi.org/10.3390/app8101943