A Method for Singular Points Detection Based on Faster-RCNN


Abstract
:1. Introduction
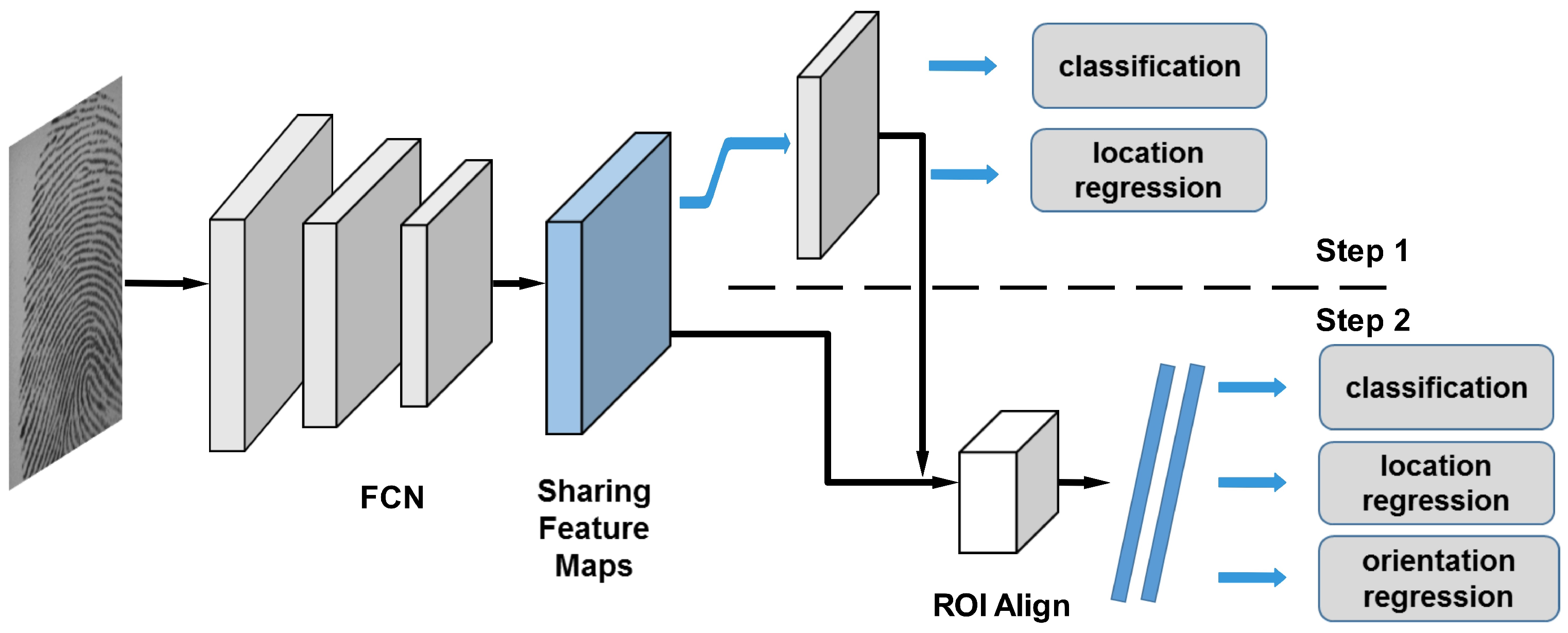
2. Proposed Method
2.1. Generating Proposals
2.2. Fine Single Point Extractor
2.3. Loss Definition and Training
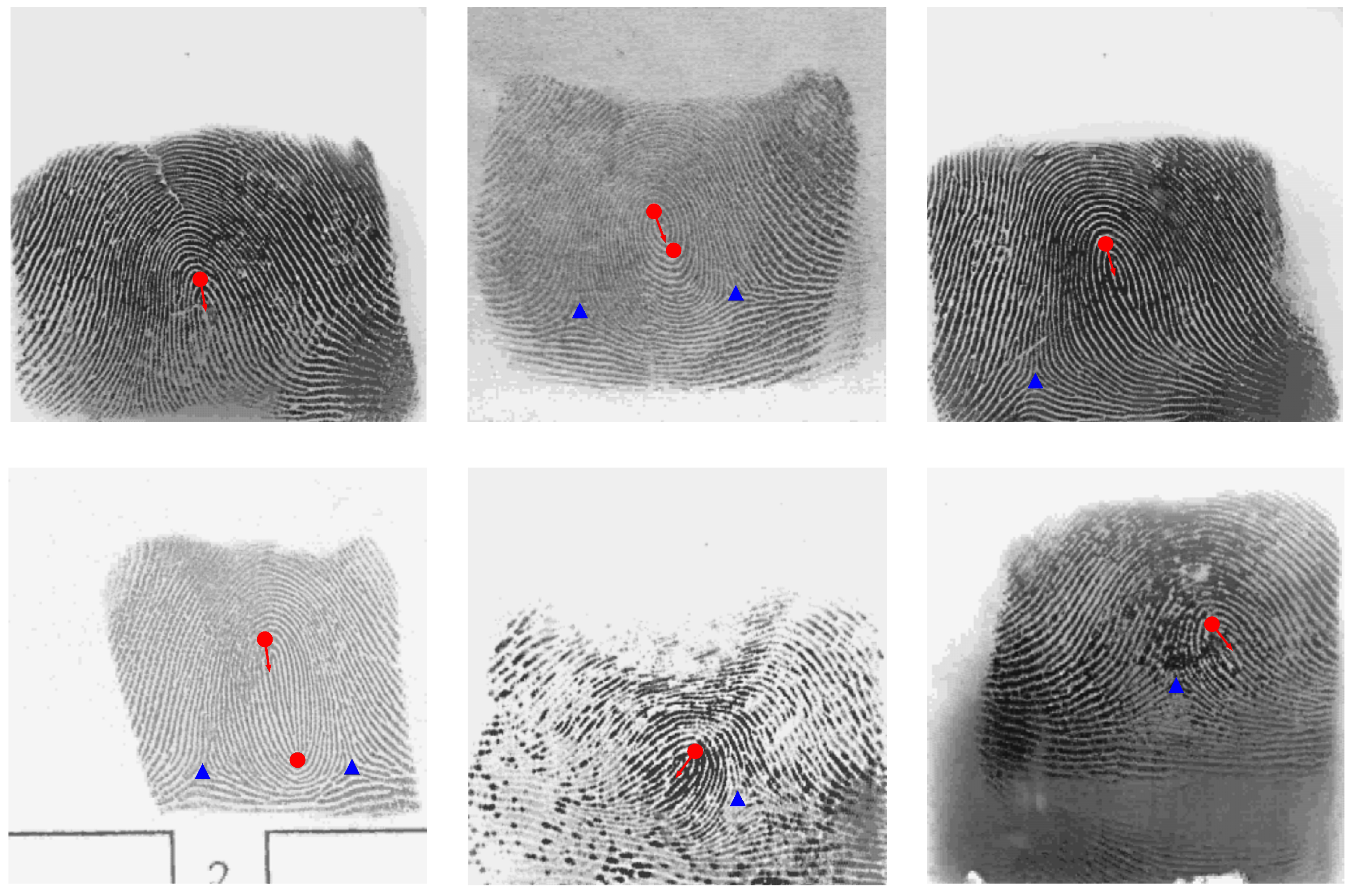
3. Experimental Results
3.1. Experimental Setup
3.2. Singular Points Detection Performance
4. Conclusions and Future Lines
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Maltoni, D.; Maio, D.; Jain, A.K.; Prabhakar, S. Handbook of Fingerprint Recognition; Springer: New York, NY, USA, 2009. [Google Scholar]
- Guo, J.; Liu, Y.; Chang, J.; Lee, J. Fingerprint classification based on decision tree from singular points and orientation field. Expert Syst. Appl. 2014, 41, 752–764. [Google Scholar] [CrossRef]
- Jiang, X.; Yau, W. Fingerprint minutiae matching based on the local and global structures. In Proceedings of the IEEE International Conference on Pattern Recognition (ICPR), Barcelona, Spain, 3–7 September 2000; pp. 1038–1041. [Google Scholar]
- Kumar, R.; Chandra, P.; Hanmandlu, M. A robust fingerprint matching system using orientation features. J. Inf. Process. Syst. 2016, 12, 83–89. [Google Scholar]
- Kawagoe, M.; Tojo, A. Fingerprint pattern classification. Pattern Recognit. 1984, 17, 295–303. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, F.; Gu, J. A novel algorithm for detecting singular points from fingerprint images. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2009, 31, 1239–1250. [Google Scholar] [CrossRef] [PubMed]
- Fan, L.; Wang, S.; Wang, H.; Guo, T. Singular points detection based on zero-pole model in fingerprint images. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2008, 30, 929–940. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep learning face representation by joint identification-verification. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 1988–1996. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 212–220. [Google Scholar]
- Zhu, X.; Xiong, Y.; Dai, J.; Yuan, L.; Wei, Y. Deep feature flow for video recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2349–2358. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Izadpanahkakhk, M.; Razavi, S.M.; Taghipour-Gorjikolaie, M.; Zahiri, S.H.; Uncini, A. Deep Region of Interest and Feature Extraction Models for Palmprint Verification Using Convolutional Neural Networks Transfer Learning. Appl. Sci. 2018, 8, 1210. [Google Scholar] [CrossRef]
- Wang, R.; Han, C.; Guo, T. A novel fingerprint classification method based on deep learning. In Proceedings of the IEEE International Conference on Pattern Recognition (ICPR), Cancún, Mexico, 4–8 December 2016; pp. 931–936. [Google Scholar]
- Qin, J.; Tang, S.; Han, C.; Guo, T. Partial fingerprint matching via phase-only correlation and deep convolutional neural network. In Proceedings of the International Conference on Neural Information Processing (ICONIP), Guangzhou, China, 14–18 November 2017; pp. 602–611. [Google Scholar]
- Labati, R.D.; Genovese, A.; Muñoz, E.; Piuri, V.; Scotti, F. A novel pore extraction method for heterogeneous fingerprint images using Convolutional Neural Networks. Pattern Recognit. Lett. 2017. [Google Scholar] [CrossRef]
- Qin, J.; Han, C.; Bai, C.; Guo, T. Multi-scaling detection of singular points based on fully convolutional networks in fingerprint images. In Proceedings of the Chinese Conference on Biometric Recognition (CCBR), Shenzhen, China, 28–29 October 2017; pp. 221–230. [Google Scholar]
- Long, J.; Shelha, E. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv, 2015; arXiv:1511.07289. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Maio, D.; Maltoni, D.; Cappelli, R.; Wayman, J.L.; Jain, A.K. FVC2002: Second fingerprint verification competition. In Proceedings of the IEEE International Conference on Pattern Recognition (ICPR), Quebec City, QC, Canada, 11–15 August 2002; pp. 811–814. [Google Scholar]
- Watson, C.; Wilson, C. Nist Special Database 4; Fingerprint Database; National Institute of Standards and Technology: Gaithersburg, MD, USA, 1992; Volume 17, p. 77. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-scale machine learning on heterogeneous systems. arXiv, 2016; arXiv:1605.08695. [Google Scholar]
- Chikkerur, S.; Ratha, N. Impact of singular point detection on fingerprint matching performance. In Proceedings of the Fourth IEEE Workshop on Automatic Identification Advanced Technologies (AutoID’05), Buffalo, NY, USA, 17–18 October 2005; pp. 207–212. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Detection Rate (%) | False Alarm Rate (%) | |||
|---|---|---|---|---|---|
| Cores | Deltas | Cores | Deltas | ||
| Conventional Algorithms | Zhou et al. [6] | 95.78 | 96.98 | 2.27 | 9.97 |
| Fan et al. [7] | 95.64 | 96.95 | 1.88 | 10.84 | |
| Chikkerur et al. [27] | 95.89 | 92.75 | 6.93 | 8.16 | |
| Deep Learning | Qin et al. [17] | 95.39 | 98.26 | 1.03 | 4.10 |
| Ours | 96.03 | 98.33 | 0.92 | 3.88 | |
| Method | Detection Rate (%) | False Alarm Rate (%) | |||
|---|---|---|---|---|---|
| Cores | Deltas | Cores | Deltas | ||
| Conventional Algorithms | Zhou et al. [6] | 86.13 | 89.51 | 8.47 | 6.15 |
| Fan et al. [7] | 88.76 | 91.45 | 13.77 | 9.92 | |
| Chikkerur et al. [27] | 85.40 | 86.66 | 9.93 | 8.70 | |
| Deep Learning | Qin et al. [17] | 88.60 | 94.26 | 6.43 | 3.71 |
| Ours | 90.75 | 94.57 | 5.71 | 3.11 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhou, B.; Han, C.; Guo, T.; Qin, J. A Method for Singular Points Detection Based on Faster-RCNN. Appl. Sci. 2018, 8, 1853. https://doi.org/10.3390/app8101853
Liu Y, Zhou B, Han C, Guo T, Qin J. A Method for Singular Points Detection Based on Faster-RCNN. Applied Sciences. 2018; 8(10):1853. https://doi.org/10.3390/app8101853
Chicago/Turabian StyleLiu, Yonghong, Baicun Zhou, Congying Han, Tiande Guo, and Jin Qin. 2018. "A Method for Singular Points Detection Based on Faster-RCNN" Applied Sciences 8, no. 10: 1853. https://doi.org/10.3390/app8101853