1. Introduction
Nowadays, many people lead a sedentary life due to the facilities that the increasingly pervasive technologies offer.
Unfortunately, it is recognized that insufficient physical activity is one of the 10 leading risk factors for global mortality: people with poor physical activity are subjected to a risk of all-cause mortality that is 20% to 30% higher then people performing at least 150 min of moderate intensity physical activity per week [
1]. Another important global phenomenon currently affecting our society is population aging: the decline or even decrease of the natural population growth rates due to a rise in life expectancy [
2] and to a long-term downtrend in fertility (expecially in Europe [
3]). Falls are a major health risk that impacts the quality of life of elderly people. Indeed, among elderly people, accidental falls occur frequently: 30% of the over 65 population falls at least once per year; the proportion increases rapidly with age [
4]. Moreover, fallers who are not able to get up are more likely require hospitalization or, even worse, die [
5].
Thus, research on techniques able to recognize activities of daily living (ADLs), also known as human activities (HA), and to detect falls is very active in recent years: the recognition of ADLs may allow to infer the amount of physical activity that a subject perform daily, while a prompt detection of falls may help in reducing the consequence (even fatal) that a fall may cause mostly in elderly people.
ADLs recognition and fall detection techniques usually accomplish their task by analizing samples from sensors, which can be physically deployed in the ambient surroundings (ambient sensors, e.g., cameras, vibration sensors, and microphones) or worn by people (wearable sensors, e.g., accelerometers, gyroscopes, and barometers) [
6]. To train and evaluate their techniques, researchers usually build their own dataset of samples and rarely make it publicly available [
7,
8,
9]. This practice makes difficult to compare in an objective way the several newly proposed techniques and implementations due to a lack of a common source of data [
9,
10,
11]. Cameras (ambient sensors) and inertial sensors (wearable devices) are the mainly used sensors to record public publicly datasets containing kinematic data of human subjects. HumanEva [
12] , CMU Mocap [
13] , and those reported in the survey by Chaquet et al. [
14] , are examples of datasets including samples from cameras, while the works by Wang et al. [
15] and Urtasum et al. [
16] are some examples of methods for learning dynamical models of human motion from camera data. Only very recently, Janidarmian et al. combined 14 publicly available datasets focusing on acceleration patterns in order to conduct an analysis on feature representations and classification techniques for human activity recognition [
17]. Unfortunately, they do not make the resulting dataset available for downloading.
The few publicly available datasets can been primary divided into three main sets: acquired by ambient sensors, acquired by wearable devices, and a combination of the two. Recently, a lot of attention has been paid to wearable sensors because they are less intrusive, work outdoors, and often cheaper than the ambient ones. This is confirmed by the increasing number of techniques that are based on wearable sensors (see for example the survey by Luque et al. related to fall detection techniques relying on data from smartphones [
18]).
Wearable sensors are divided in two main groups: ad-hoc wearable devices (e.g., SHIMMER sensor nodes), and smartphones (e.g., Android). Concerning fall detection, several studies concluded that, in order to be used, fall detection devices must not stigmatize people nor disturb their daily life [
19,
20,
21]. Unfortunately, devices such as ad-hoc wearable devices and ambient sensors are not well accepted by elderly people because mostly of their intrusiveness. On the contrary, smartphones are good candidate devices for hosting fall detection systems: they are are widespread and daily used by a very large number of person, included elderly people. This, on the one hand, reduces costs, and on the other, eliminates the problem of having to learn how to use a new device. Moreover, studies demonstrated that samples from smartphones sensors (e.g., accelerometer and gyroscope) are accurate enough to be used in clinical domain, such as ADLs recognition [
22]. This is also confirmed by the amount of publications that rely on the use of smartphones as acquisition devices for fall detection systems [
18,
23] and ADLs recognition.
For these reasons we concentrate our attention on smartphones as acquisition devices both for ADL recognition and fall detection. Thus, we searched the publicly available datasets acquired with smartphones in order to identify their strengths and weaknesses so as to outline an effective method for carrying out a new acquisition campaign. We searched the most common repository (IEEE, ACM Digital Library , Google, and Google Scholar) by using in our query the terms ADL dataset and Fall dataset in combination with the following words smartphone, acceleration, accelerometer, inertial, IMU (Inertial Measurement Unit), sensor, and wearable. We selected the first 100 results for each query. Removing duplicate entries, we obtained less then 200 different references. Then we manually examined the title, the abstract, and the introduction to eliminate references unrelated to ADL recognition and fall detection, and references that were based on ambient sensors such as camera, microphones, or RFID (Radio Frequency Identification) tags. We then read carefully the remaining references and discarded those that do not make publicly available the dataset used in the experimentation. Finally, we added the relevant references that we missed with our searches but were cited in the papers we selected. At the end of the process, we individuated 13 datasets with data from smartphones and 19 with data from wearable ad-hoc sensors. We then included only those datasets that have been recorded starting from 2012 (We considered the year in which the dataset has been made available. This year does not necessarily coincide with the year in which the related article has been published) mostly because the oldest dataset including samples from smartphones is dated 2012. This choice makes the datasets homogeneous with respect to the sensors technologies related to acquisition sensors which rapidly evolves year by year.
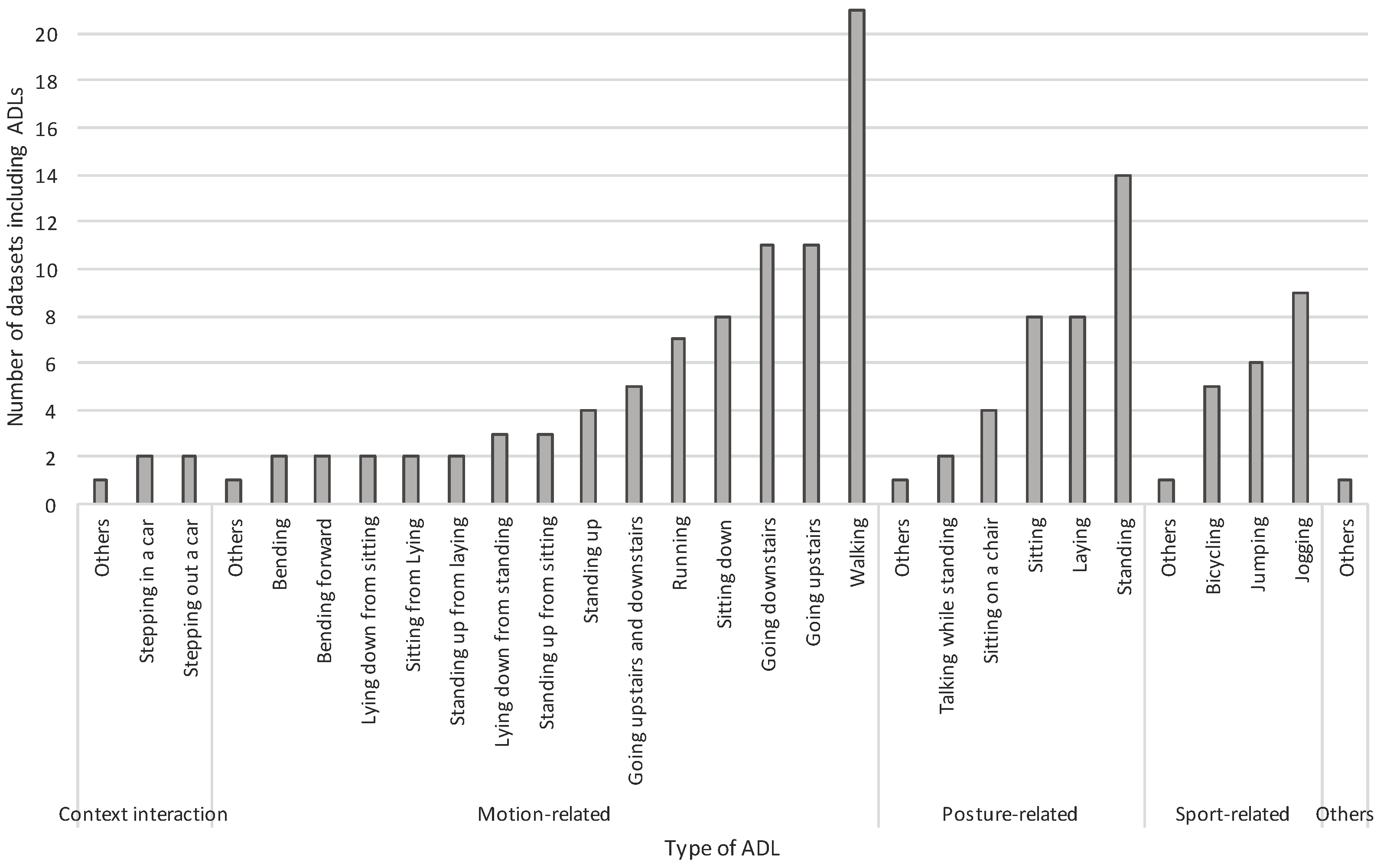
At the end of the process, we individuated 13 datasets with data from smartphones and 13 with data from wearable ad-hoc sensors. In the following, we will detail some relevant characteristics of the 13 datasets from smartphones since our aim was to build a new dataset containing acceleration patters from smartphone able to complement the existing ones. As it will presented in
Section 2, the datasets from ad-hoc wearable devices have be examined with the aim of identifying the most common ADLs and falls.
Table 1 shows the publicly available datasets recorded by means of smartphones and their characteristics.
Table 1 also includes the dataset we realized in the last row, in order to ease the comparison.
The total number of datasets decreases to 11 because MobiAct and UCI HAPT are updated versions of MobiFall and UCI HAR respectively. Thus, in the following we will refer to 11 datasets overall, discarding MobiFall and UCI HAR.
The 11 datasets have been recorded in the period 2012 to 2016 (column Year). Only 5 datasets out of 11 contain both falls (column Falls) and ADLs (column ADLs).
The average number of subjects for dataset is 18 (column Nr. of subjects). The datasets that specify the gender of the subjects (which are MobiAct, RealWorld (HAR), Shoaib PA, Shoaib SA, tFall, and UMA Fall) contain in mean 6 women and 13 men (columns Gender-Female and Gender-Male respectively).
DMPSBFD, UCI UIWADS, and WISDM do not specify the age of the subjects (column Age). In the remaining 8 datasets, subjects are aged between 21 and 43 on average with a standard deviation of 4 and 11 respectively.
Finally, only Gravity, MobiAct, RealWorld (HAR), tFall, and UMA Fall datasets provide detailed information about the height and the weight of the subjects (columns Height and Weight respectively).
The detailed information reported in
Table 1 have been collected from the web site hosting the dataset, the readme files of each dataset, and the related papers. It is remarkable to notice that in many cases such information get lost in the downloaded dataset. Grey cells in
Table 1 indicate that samples are stored so that they can be filtered according to the information contained in the cell.
For instance, in all the datasets, with the exception of tFall, it is possible to select subsets of samples according to the specific ADL (column ADLs). For example, it is possible to select all the samples that have been labeled walking. tFall is an exception because the samples are simply labeled as generic ADL, thus not specifying which specific kind of ADL are.
Concerning falls (column Falls), all the datasets have organized samples maintaining the information related to the specific type of fall they are related to (e.g., forward).
As specified in column Nr. of subjects, the samples are linked to the subjects that performed the related activities and, where provided, falls. This means that in all the datasets (with the exception of Shoaib PA) it is possible to select samples related to a specific subject. However, this information is unhelpful if there is no information on the physical characteristics of the subject. Looking at the double column Gender, only MobiAct, RealWorld (HAR), Shoaib PA, Shoaib SA, and UMA Fall maintain information related to the gender of the subject. Finally, it is surprising that only Gravity, MobiAct, RealWorld (HAR), and UMA Fall allow to select samples according to age, height, and/or weight of the subjects (columns Age, Height, and Weight).
In view of this analysis, only MobiAct, RealWorld (HAR), and UMA Fall allow us to select samples according to several dimensions, such as the age, the gender, the weight of the subjects, or the type of ADL. MobiAct and UMA Fall allow us to select samples also according to the type of fall. Unfortunately, the other datasets are not suitable in some experimental evaluations. For example, the evaluation of the effects of personalization in classification techniques [
35] taking into account the physical characteristics of the subjects, that is, operating leave-one-subject-out cross-validation [
36].
To further contribute to the worldwide collection of accelerometer patterns, in this paper we present a new dataset of smartphone accelerometer samples, named UniMiB SHAR (University of Milano Bicocca Smartphone-based Human Activity Recognition). The dataset was created with the aim of providing the scientific community with a new dataset of acceleration patterns captured by smartphones to be used as a common benchmark for the objective evaluation of both ADLs recognition and fall detection techniques.
The dataset has been designed keeping in mind on one side the limitations of the actual publicly available datasets, and on the other the characteristics of MobiAct, RealWorld (HAR), and UMA Fall, so to create a new dataset that juxtaposes and complements MobiAct, RealWorld (HAR), and UMA Fall with respect to the data that is missing. Thus, such a dataset would have to contain a large number of subjects (more than the 18 on average), with a large number of women (to compensate MobiAct, RealWorld (HAR), and UMA Fall), with subjects over the age of 55 (to extend the range of UMA Fall (We do not consider RealWorld (HAR) since it contains ADLs only. Indeed, it is most difficult to recruit elderly subjects performing falls), with different physical characteristics (to maintain heterogeneity), performing a wide number of both ADLs and falls (to be suitable in several contexts). Moreover, the dataset would have to contain all the information required to select subjects or ADLs and falls according to different criteria, such as for example, all the female whose height is in the range 160–168 cm, all the men whose weight is in the range 80–110 Kg, all the walking activities of the subjects whose age is in the range 45–60 years.
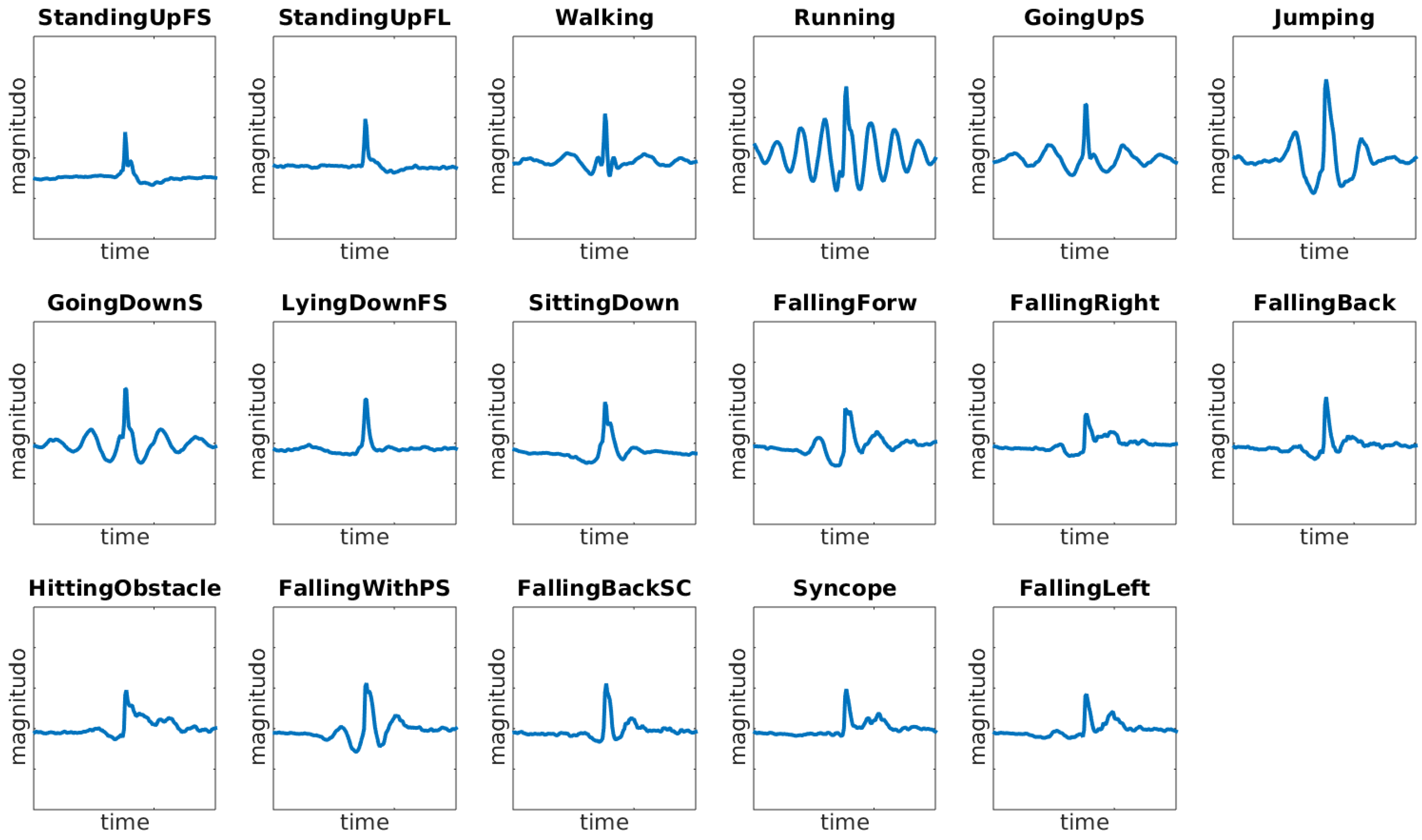
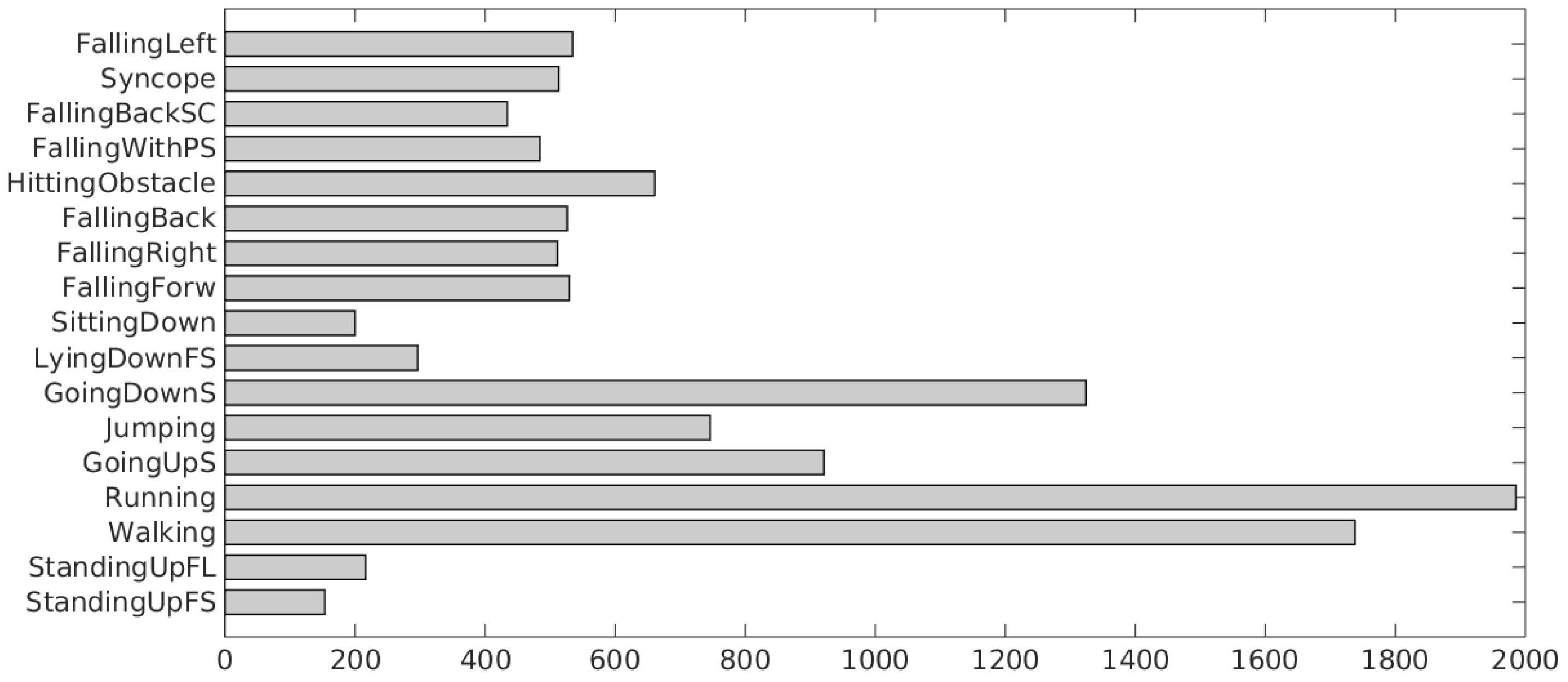
To fulfil those requirements, we built a dataset including 9 different types of ADLs and 8 different types of falls. The dataset contains a total of 11,771 samples describing both activities of daily living (7579) and falls (4192) performed by 30 subjects, mostly females (24), of ages ranging from 18 to 60 years. Each sample is a vector of 151 accelerometer values for each axis. Each accelerometer entry in the dataset maintains the information about the subject that generated it. Moreover, each accelerometer entry has been labeled by specifying the type of ADL (e.g., walking, sitting, or standing) or the type of fall (e.g., forward, syncope, or backward).
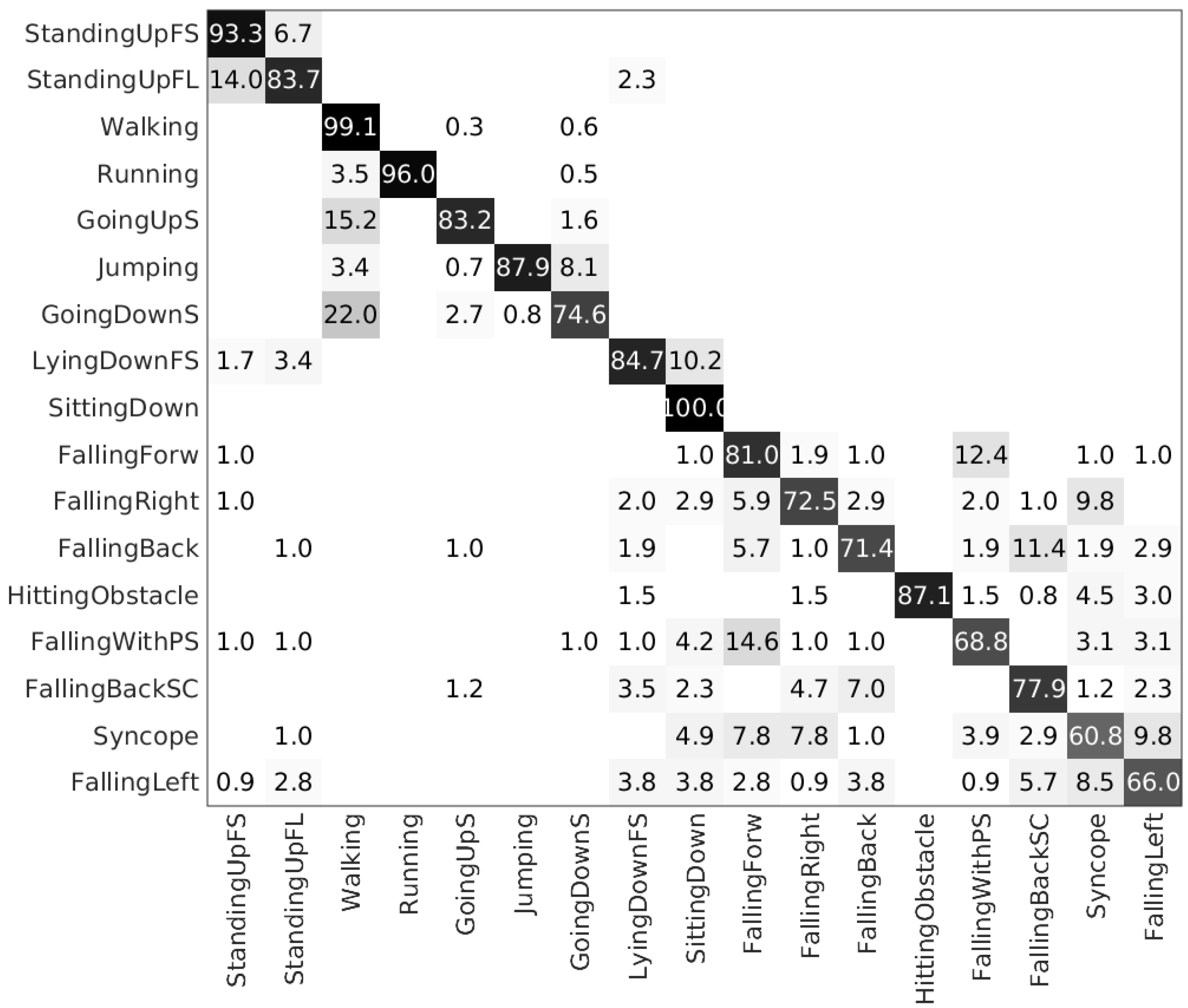
We benchmarked the dataset by performing several experiments. We evaluated four classifiers: k-Nearest Neighbour (k-NN), Support Vector Machines (SVM), Artificial Neural Networks (ANN), and Random Forest (RF). Raw data and magnitudo have been considered as feature vectors. Finally, for each classification we performed a 5-fold cross validation and a leave-one-subject-out evaluation. Results show how much the proposed dataset is challenging with respect to a set of classification tasks.
The article is organized as follows.
Section 2 describes the method used to build the datasets.
Section 3 presents the dataset evaluation and
Section 4 discusses the results of the evaluation. Finally,
Section 5 provides final remarks.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}