
Instrument Detection and Descriptive Gesture Segmentation on a Robotic Surgical Maneuvers Dataset

 , , ,
, , ,
Abstract
:1. Introduction
- This work completes the ROSMA dataset with surgical tool detection and gesture annotations, resulting in 2 new datasets: ROSMAG40, which contains 40 videos labeled with the instruments’ gestures, and ROSMAT24, which provides bounding box annotations of the instruments’ tip for 24 videos of the original ROSMA dataset.
- Unlike previous work, annotations are performed on the right tool and on the left tool independently.
- Annotations for gesture recognition have been evaluated using a recurrent neural network based on a bi-directional long short-term memory layer, using an experimental setup-up with four cross-validation schemes.
- Annotations for surgical tool detection have been evaluated with a YOLOV4 network using two experimental setups.
2. Materials and Methods
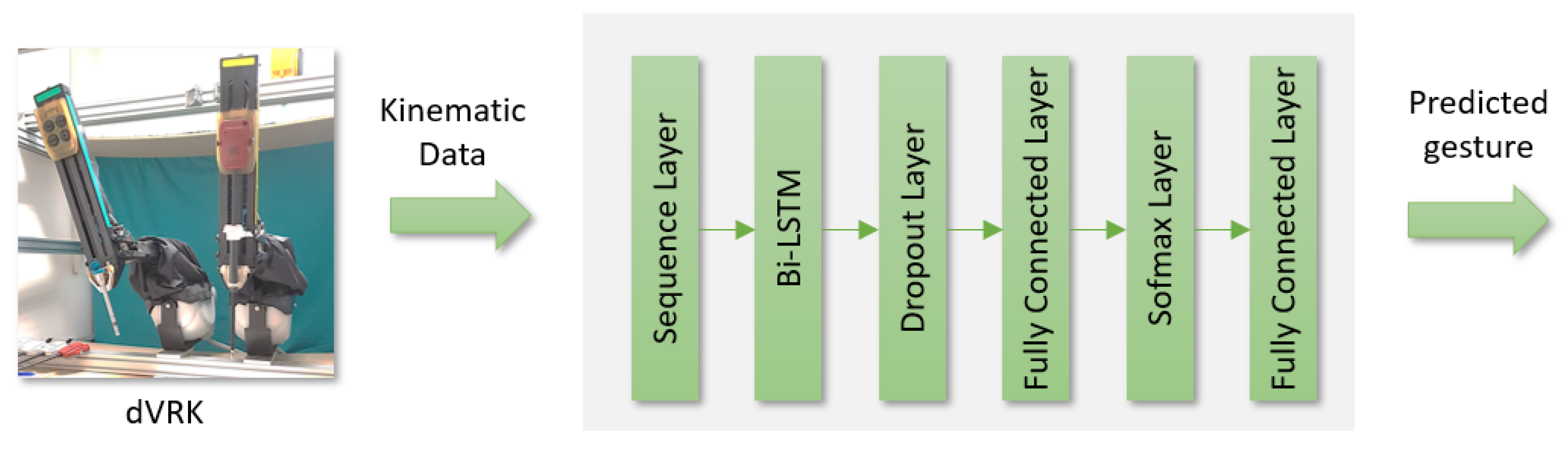
2.1. System Description
2.2. Robotics Surgical Maneuvers Dataset (ROSMA)
2.3. Gesture Annotations
2.3.1. ROSMAG40 Annotations
- FGDlabels: this folder contains text files with the FGD annotations. Each row, which corresponds with a video frame, contains two items: the gesture label for PSM1 and the gesture label for PSM2.
- MDlabels: this folder contains text files with the MD annotations with the same structure as FGDlabels files.
- Kinematics: this folder contains text files with the 34 kinematic features. The first row of these files contains the name of the kinematic feature corresponding with each column.
- Video: this folder contains the video files in mp4 format for the 40 trials of the tasks.
2.3.2. Maneuver Descriptor (MD) Gestures
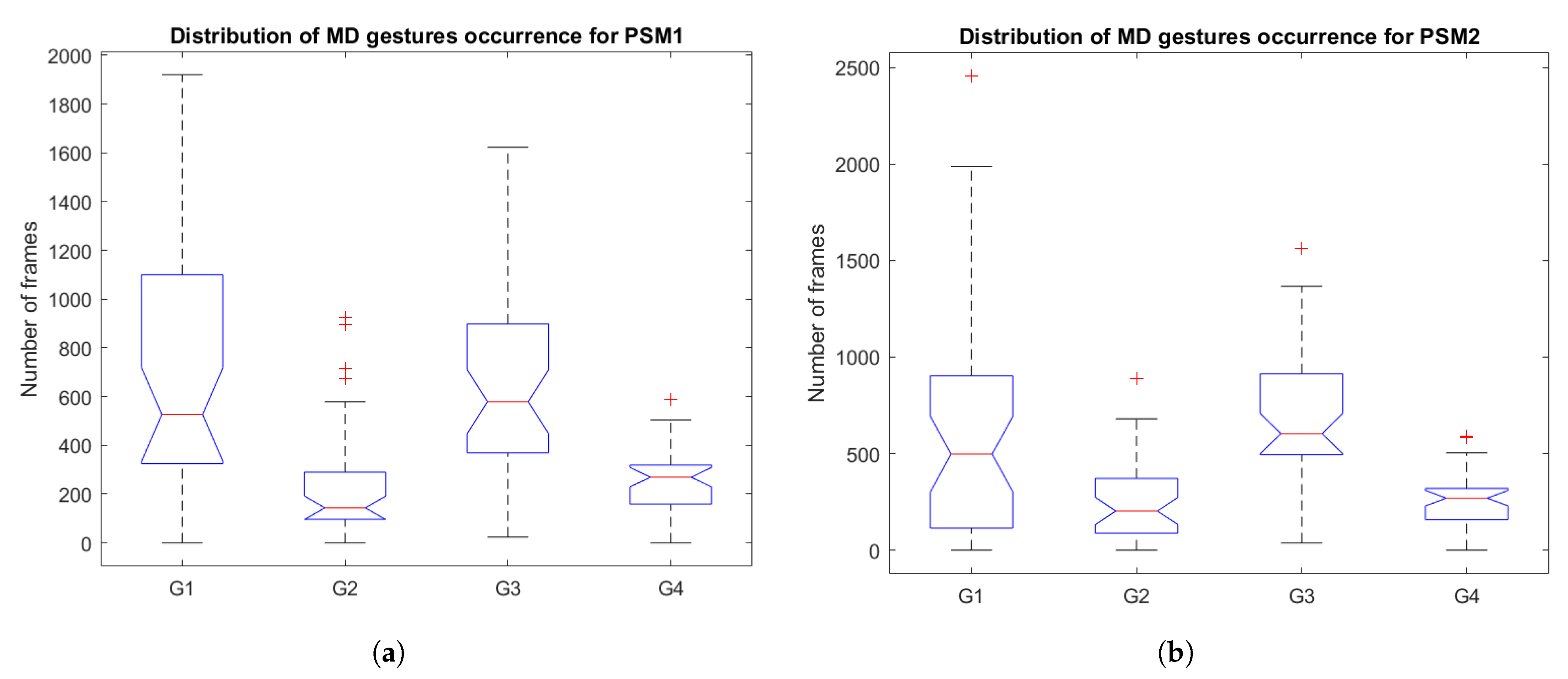
- Idle (G1): the instrument is in a resting position.
- Precision (G2): this gesture is characterized by actions that require an accurate motion of the tool, such as picking or placing objects.
- Displacement (G3): this gesture is characterized by motions that do not require high accuracy, i.e., displacement of the tools either to carry an object or to position the tip in a particular area of the scenario.
- Collaboration (G4): both instruments are collaborating on the same task. For pea on a peg, collaboration occurs when the dominant tool needs support, usually to release peas held together by static friction, so it is an intermittent and unpredictable action. For post and sleeve, collaboration is a mandatory step between picking and placing an object, in which the sleeve is passed from one tool to another.
- Pea on a peg is mostly performed with the dominant tool, which follows the flow of picking a pea and placing it on top of a peg. The other tool mainly carries out collaborative actions to provide support for releasing peas from the tool. Thus, the dominant tool gestures follow mostly the following flow: displacement (G3)-precision (G2)-displacement (G3)-precision (G2), with short interruptions for collaboration (G4). While the other tool is mainly in an idle (G1) position, with some interruptions for collaboration (G4). This workflow is shown in Figure 6, which represents the sequential distribution of the gestures along a complete trial of the task.
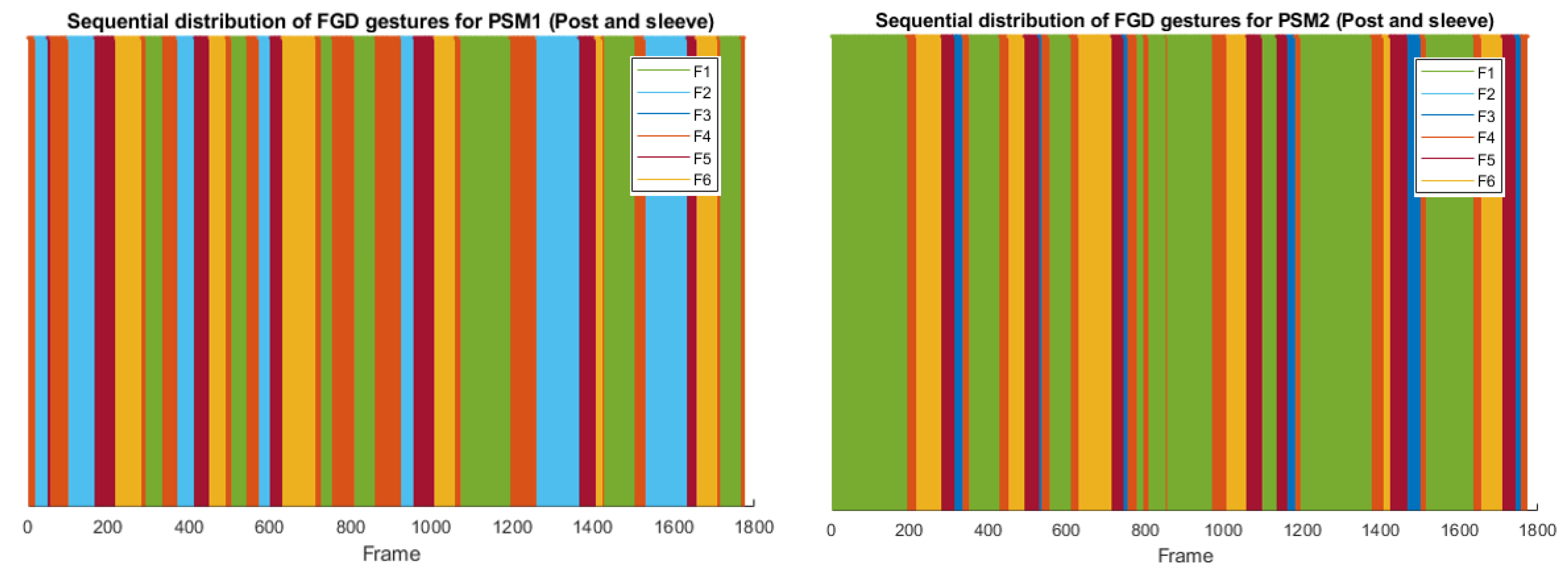
- Post and sleeve tasks follow a more sequential workflow between the tools: one tool picks a sleeve and transfers it to the other tool, which places it over a peg on the opposite side of the board. Thus, the workflow is more similar for both tools, as can be seen in Figure 7.
2.3.3. Fine-Grain Descriptor (FGD) Gestures
- Idle (F1): this is the same gesture as for MD gestures described in the previous section (G1).
- Picking (F2): the instrument is picking an object, either a pea on the pea on a peg task or a colored sleeve on the post and sleeve task. This gesture is a particularity of G2 of MD descriptors.
- Placing (F3): the instrument is placing an object, either a pea on top of a peg or a sleeve over a peg. This gesture is also a particularity of G2.
- Free motion (F4): the instrument is moving without carrying anything at the tip. This gesture corresponds with actions of approaching the objective to pick, and it is a particularity of G3 of MD descriptors.
- Load motion (F5): the instrument moves while holding an object. This gesture corresponds with actions of approaching the objective to a place, and, therefore, it is also a particularity of G3.
- Collaboration (F6): equivalent to gesture G4 of maneuver descriptors.
- The workflow of pea on a peg task for FGD gesture is mainly as follows: free motion (F4)-picking (F2)-load motion (F5)-placing (F3), with short interruptions for collaboration (F6). The other tool is mostly in an idle (F1) position, with some interruptions for collaboration (F6).
- As we stated previously, post and sleeve tasks follow a more sequential workflow between the tools. In the trial represented in Figure 11, PSM1 was the dominant tool, so the comparison between the gesture sequential distribution for PSM1 and PSM2 reflects that picking is a more time-consuming task than placing.
2.4. Instruments Annotations (ROSMAT24)
- Labels: this folder contains the text files with the bounding boxes for the tip of PSM1 and PSM2. Each row, which corresponds with a video frame, has the following eight items:where BX, BY, BW, and BH are the coordinates of the bounding boxes x1 (left), y1 (top), width and height, respectively, and the Subindexes 1 and 2 refer to PSM1 and PSM2, respectively.
- Video: this folder contains the video files in mp4 format.
2.5. Evaluation Method
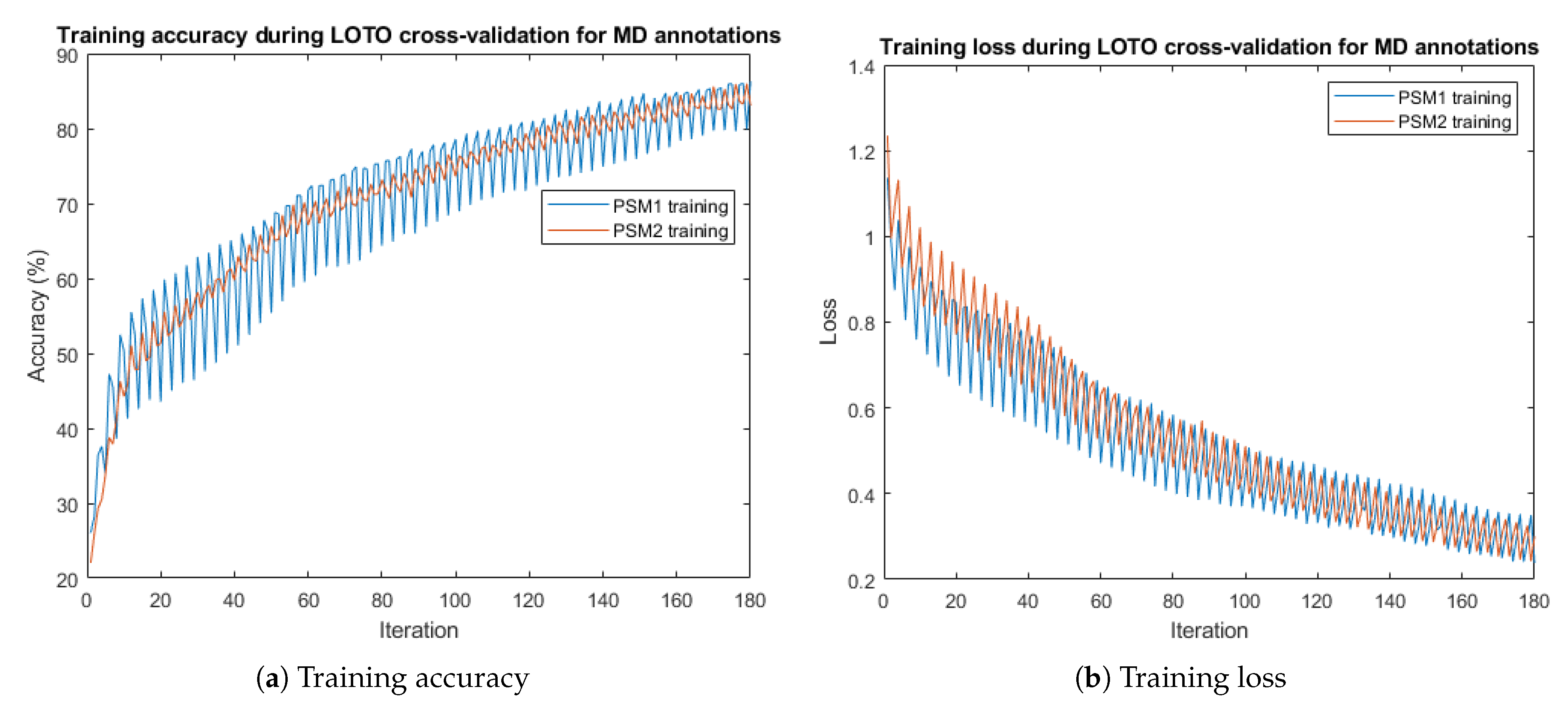
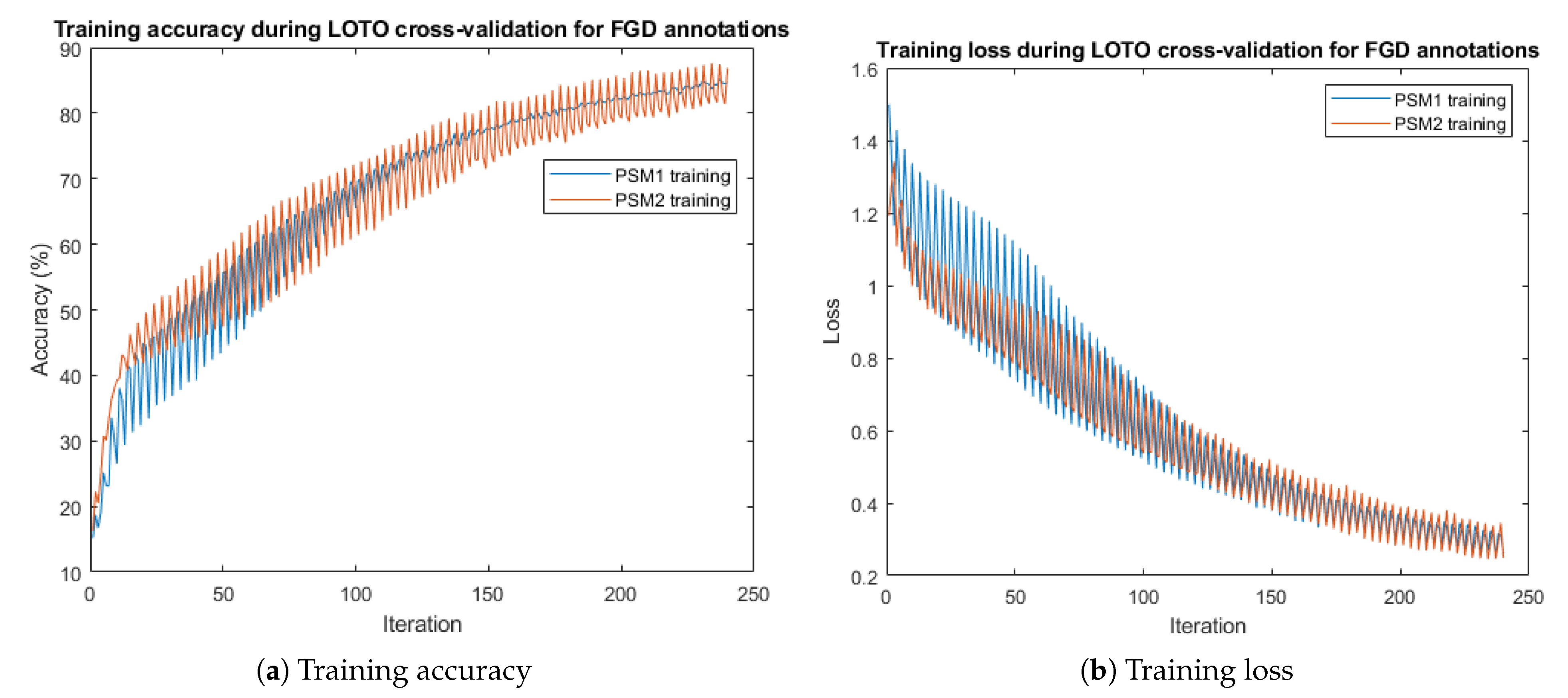
2.5.1. Gesture Segmentation
- Leave-one-user-out (LOUO): in the LOUO setup, we created five folds, each one consisting of data from one of the five users. This setup can be used to evaluate the robustness of the model when a subject is not seen by the model.
- Leave-one-supertrial-out (LOSO): a supertrial is defined as in Gao et al. [8] as the set of trials from all subjects for a given surgical task. Thus, we created two folds, each comprising data from one of the two tasks. This setup can be used to evaluate the robustness of the method for a new task.
- Leave-one-psm-out (LOPO): as half of the trials of the dataset are performed with PSM1 as the dominant tool while the other half are performed with PSM2 as the dominant tool, we have created two folds, one for trials of each dominant tool. This setup can be used to evaluate the robustness of the model when tasks are not performed following a predefined order.
- Leave-one-trial-out (LOTO): a trial is defined as the performance by one subject of one instance of a specific task. For this cross-validation scheme, we have considered the following test data partitions:
- -
- Test data 1: test data include two trials per user as follows: one of each task, and performed with a different PSM as dominant. Thus, we have left out 10 trials: 2 per user, 5 from each task, and 5 with one PSM as dominant. This setup allows us to train the model with the widest variety possible.
- -
- Test data 2: this test folder includes 10 trials of pea on a peg task, 2 trials per user with different PSM as dominant. This setup allows evaluating the robustness of the method when the network has significantly more observations of one task.
- -
- Test data 3: the same philosophy of test data 2, but leaving for testing just post and sleeve data for testing.
- -
- Test data 4: this test folder includes 10 trials performed with PSM1 as the dominant tool, and 2 trials per user and task. This setup allows evaluating the robustness of the method when the network has significantly more observations with a particular workflow of the task performance.
- -
- Test data 5: the same philosophy of test data 4, but leaving for testing just performance with PSM2 as the dominant tool.
2.5.2. Instrument Detection
- Leave-One-Supertrial-Out (LOSO): for this setup, we only used images of videos performing pea on a peg for training the network, and then we incorporated images of videos performing post and leave for testing. This setup can be used to evaluate the robustness of the method for different experimental scenarios.
- Leave-One-Trial-Out (LOTO): for this setup, we used images of videos performing pea on a peg and post and sleeve for training and testing the network.
3. Results
3.1. Results for Gesture Segmentation
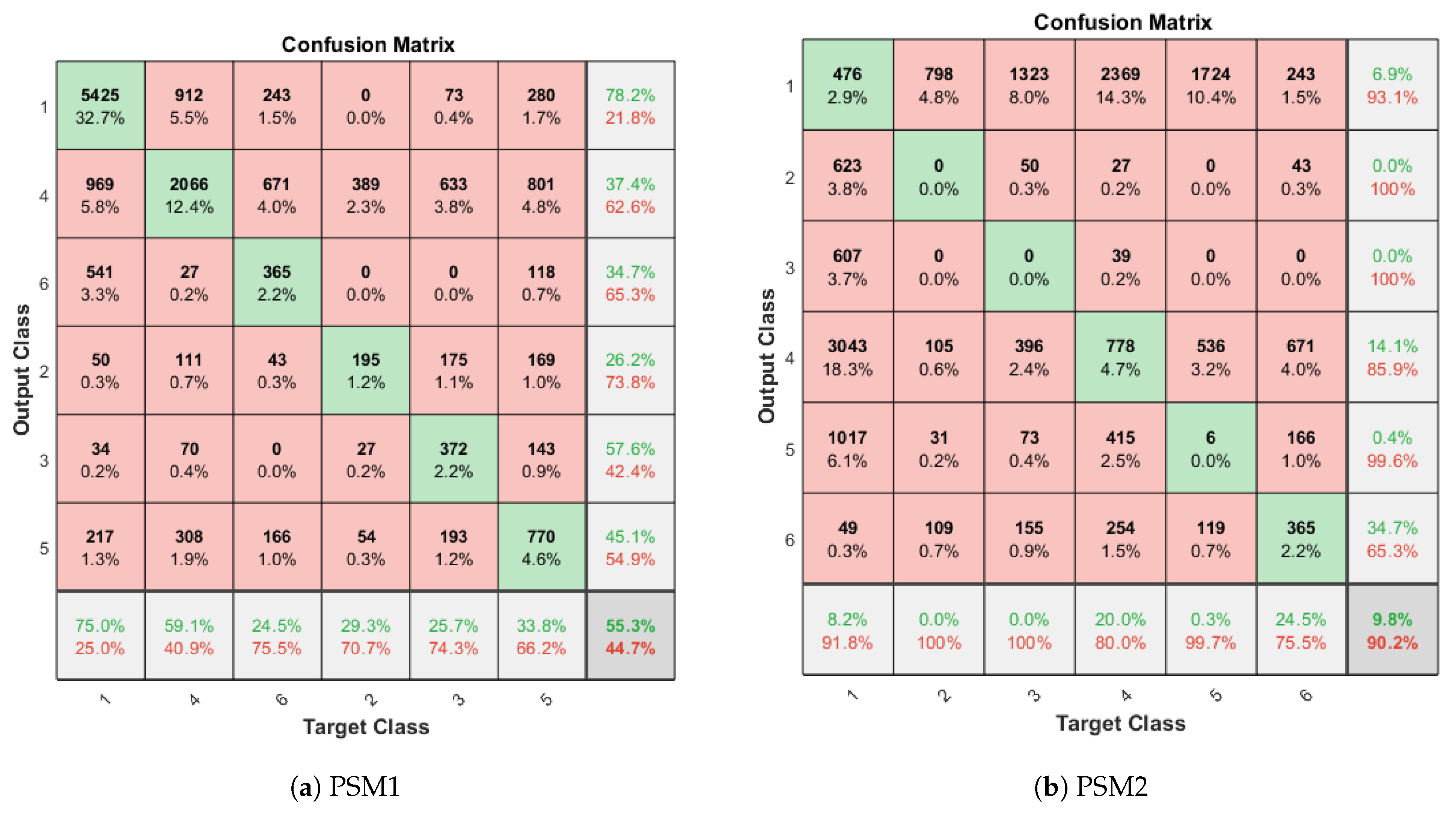
3.2. Results for Instruments Detection
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ROSMA | Robotics Surgical Maneuvers |
| dVRK | da Vinci Research Kit |
| MD | Maneuver Descriptor |
| FGD | Fine-Grained Descriptor |
| RNN | Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| Bi-LSTM | Bidirectional Long-short Term Memory |
| MT | Master Tool Manipulator |
| PSM | Patient-sided Manipulator |
| YOLO | You Only Look Once |
Appendix A
- Testgestures_peaonapeg.mp4: this video shows the annotated labels for a trial of the pea on a peg task using the FGD annotations. Gesture of PSM1 is displayed in green on the left side of the image, and gesture of PSM2 is displayed in blue on the right side of the image. The purpose of this video is to provide the reader with a better understanding of the meaning of the gestures.
- Testgestures_postandsleeve.mp4: this video shows the performance of the gesture recognition network for a trial of the post and sleeve task using the MD annotations. The predicted gesture of PSM1 is displayed in green on the left side of the image, and the predicted gesture of PSM2 is displayed in blue on the right side of the image. The purpose of this video is to demonstrate the performance of the network.
- ToolsDetection_peaonapeg.mp4: this video shows the performance of the instruments detection network for a trial of the pea on a peg task. The predicted bounding boxes for PSM1 and PSM2 are shown in green and blue, respectively, with a label on the top displaying the predicted accuracy.
- ToolsDetection_postandsleeve.mp4: performance of the instruments detection network for a trial of the post and sleeve task. The predicted bounding boxes for PSM1 and PSM2 are shown in green and blue, respectively, with a label on the top displaying the predicted accuracy.
Appendix B




References
- Vedula, S.S.; Hager, G.D. Surgical data science: The new knowledge domain. Innov. Surg. Sci. 2020, 2, 109–121. [Google Scholar] [CrossRef]
- Pérez-del Pulgar, C.J.; Smisek, J.; Rivas-Blanco, I.; Schiele, A.; Muñoz, V.F. Using Gaussian Mixture Models for Gesture Recognition During Haptically Guided Telemanipulation. Electronics 2019, 8, 772. [Google Scholar] [CrossRef]
- Ahmidi, N.; Tao, L.; Sefati, S.; Gao, Y.; Lea, C.; Haro, B.B.; Zappella, L.; Khudanpur, S.; Vidal, R.; Hager, G.D. A Dataset and Benchmarks for Segmentation and Recognition of Gestures in Robotic Surgery. IEEE Trans. Biomed. Eng. 2017, 64, 2025–2041. [Google Scholar] [CrossRef] [PubMed]
- Setti, F.; Oleari, E.; Leporini, A.; Trojaniello, D.; Sanna, A.; Capitanio, U.; Montorsi, F.; Salonia, A.; Muradore, R. A Multirobots Teleoperated Platform for Artificial Intelligence Training Data Collection in Minimally Invasive Surgery. In Proceedings of the 2019 International Symposium on Medical Robotics, ISMR 2019, Atlanta, GA, USA, 3–5 April 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Rivas-Blanco, I.; Perez-Del-Pulgar, C.J.; Garcia-Morales, I.; Munoz, V.F.; Rivas-Blanco, I. A Review on Deep Learning in Minimally Invasive Surgery. IEEE Access 2021, 9, 48658–48678. [Google Scholar] [CrossRef]
- Attanasio, A.; Scaglioni, B.; Leonetti, M.; Frangi, A.F.; Cross, W.; Biyani, C.S.; Valdastri, P. Autonomous Tissue Retraction in Robotic Assisted Minimally Invasive Surgery—A Feasibility Study. IEEE Robot. Autom. Lett. 2020, 5, 6528–6535. [Google Scholar] [CrossRef]
- Sarikaya, D.; Corso, J.J.; Guru, K.A. Detection and Localization of Robotic Tools in Robot-Assisted Surgery Videos Using Deep Neural Networks for Region Proposal and Detection. IEEE Trans. Med. Imaging 2017, 36, 1542–1549. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Vedula, S.S.; Reiley, C.E.; Ahmidi, N.; Varadarajan, B.; Lin, H.C.; Tao, L.; Zappella, L.; Béjar, B.; Yuh, D.D.; et al. JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS): A Surgical Activity Dataset for Human Motion Modeling. In Proceedings of the MICCAIWorkshop: Modeling and Monitoring of Computer Assisted Interventions (M2CAI), Boston, MA, USA, 14–18 September 2014; pp. 1–10. [Google Scholar]
- Colleoni, E.; Edwards, P.; Stoyanov, D. Synthetic and Real Inputs for Tool Segmentation in Robotic Surgery. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention-MICCAI 2020, Lima, Peru, 4–8 October 2020; pp. 700–710. [Google Scholar] [CrossRef]
- Wang, S.; Raju, A.; Huang, J. Deep learning based multi-label classification for surgical tool presence detection in laparoscopic videos. In Proceedings of the International Symposium on Biomedical Imaging, Melbourne, VIC, Australia, 18–21 April 2017; pp. 620–623. [Google Scholar] [CrossRef]
- Mishra, K.; Sathish, R.; Sheet, D. Learning Latent Temporal Connectionism of Deep Residual Visual Abstractions for Identifying Surgical Tools in Laparoscopy Procedures. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, IEEE Computer Society, Honolulu, HI, USA, 21–26 July 2017; pp. 2233–2240. [Google Scholar] [CrossRef]
- Islam, M.; Atputharuban, D.A.; Ramesh, R.; Ren, H. Real-time instrument segmentation in robotic surgery using auxiliary supervised deep adversarial learning. IEEE Robot. Autom. Lett. 2019, 4, 2188–2195. [Google Scholar] [CrossRef]
- Kurmann, T.; Marquez Neila, P.; Du, X.; Fua, P.; Stoyanov, D.; Wolf, S.; Sznitman, R. Simultaneous recognition and pose estimation of instruments in minimally invasive surgery. In Lecture Notes in Computer Science, Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10434 LNCS, pp. 505–513. [Google Scholar] [CrossRef]
- Chen, Z.; Zhao, Z.; Cheng, X. Surgical instruments tracking based on deep learning with lines detection and spatio-temporal context. In Proceedings of the 2017 Chinese Automation Congress, CAC 2017, Jinan, China, 20–22 October 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 2711–2714. [Google Scholar] [CrossRef]
- Al Hajj, H.; Lamard, M.; Conze, P.H.; Cochener, B.; Quellec, G. Monitoring tool usage in surgery videos using boosted convolutional and recurrent neural networks. Med. Image Anal. 2018, 47, 203–218. [Google Scholar] [CrossRef] [PubMed]
- Nazir, A.; Cheema, M.N.; Sheng, B.; Li, P.; Li, H.; Yang, P.; Jung, Y.; Qin, J.; Feng, D.D. SPST-CNN: Spatial pyramid based searching and tagging of liver’s intraoperative live views via CNN for minimal invasive surgery. J. Biomed. Inform. 2020, 106, 103430. [Google Scholar] [CrossRef]
- Fu, Y.; Robu, M.R.; Koo, B.; Schneider, C.; van Laarhoven, S.; Stoyanov, D.; Davidson, B.; Clarkson, M.J.; Hu, Y. More unlabelled data or label more data? A study on semi-supervised laparoscopic image segmentation. In Lecture Notes in Computer Science, Proceedings of the Domain Adaptation and Representation Transfer and Medical Image Learning with Less Labels and Imperfect Data: First MICCAI Workshop, DART 2019, and First International Workshop, MIL3ID 2019, Shenzhen, Held in Conjunction with MICCAI 2019, Shenzhen, China, 13 and 17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11795 LNCS, pp. 173–180. [Google Scholar] [CrossRef]
- Petscharnig, S.; Schöffmann, K. Deep learning for shot classification in gynecologic surgery videos. In Lecture Notes in Computer Science, Proceedings of the MultiMedia Modeling: 23rd International Conference, MMM 2017, Reykjavik, Iceland, 4–6 January 2017; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10132 LNCS, pp. 702–713. [Google Scholar] [CrossRef]
- Twinanda, A.P.; Shehata, S.; Mutter, D.; Marescaux, J.; De Mathelin, M.; Padoy, N. EndoNet: A Deep Architecture for Recognition Tasks on Laparoscopic Videos. IEEE Trans. Med. Imaging 2017, 36, 86–97. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Jin, Y.; Dou, Q.; Heng, P.A. Automatic Gesture Recognition in Robot-assisted Surgery with Reinforcement Learning and Tree Search. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), IE63, Paris, France, 31 May–31 August 2020; pp. 8440–8446. [Google Scholar] [CrossRef]
- Qin, Y.; Pedram, S.A.; Feyzabadi, S.; Allan, M.; McLeod, A.J.; Burdick, J.W.; Azizian, M. Temporal Segmentation of Surgical Sub-tasks through Deep Learning with Multiple Data Sources. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Institute of Electrical and Electronics Engineers (IEEE), Paris, France, 31 May–31 August 2020; pp. 371–377. [Google Scholar] [CrossRef]
- Funke, I.; Bodenstedt, S.; Oehme, F.; von Bechtolsheim, F.; Weitz, J.; Speidel, S. Using 3D Convolutional Neural Networks to Learn Spatiotemporal Features for Automatic Surgical Gesture Recognition in Video. In Lecture Notes in Computer Science, Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11768 LNCS, pp. 467–475. [Google Scholar] [CrossRef]
- Luongo, F.; Hakim, R.; Nguyen, J.H.; Anandkumar, A.; Hung, A.J. Deep learning-based computer vision to recognize and classify suturing gestures in robot-assisted surgery. Surgery 2020, 169, 1240–1244. [Google Scholar] [CrossRef] [PubMed]
- Murali, A.; Garg, A.; Krishnan, S.; Pokorny, F.T.; Abbeel, P.; Darrell, T.; Goldberg, K. TSC-DL: Unsupervised trajectory segmentation of multi-modal surgical demonstrations with Deep Learning. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; Volume 2016, pp. 4150–4157. [Google Scholar] [CrossRef]
- Zhao, H.; Xie, J.; Shao, Z.; Qu, Y.; Guan, Y.; Tan, J. A fast unsupervised approach for multi-modality surgical trajectory segmentation. IEEE Access 2018, 6, 56411–56422. [Google Scholar] [CrossRef]
- Shao, Z.; Zhao, H.; Xie, J.; Qu, Y.; Guan, Y.; Tan, J. Unsupervised Trajectory Segmentation and Promoting of Multi-Modal Surgical Demonstrations. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 777–782. [Google Scholar] [CrossRef]
- Marban, A.; Srinivasan, V.; Samek, W.; Fernández, J.; Casals, A. Estimating Position & Velocity in 3D Space from Monocular Video Sequences Using a Deep Neural Network. In Proceedings of the Proceedings-2017 IEEE International Conference on Computer VisionWorkshops, ICCVW 2017, Venice, Italy, 22–29 October 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; Volume 2018, pp. 1460–1469. [Google Scholar] [CrossRef]
- Rivas-Blanco, I.; Del-Pulgar, C.J.; Mariani, A.; Tortora, G.; Reina, A.J. A surgical dataset from the da Vinci Research Kit for task automation and recognition. In Proceedings of the International Conference on Electrical, Computer, Communications and Mechatronics Engineering, ICECCME 2023, Tenerife, Canary Islands, Spain, 19–21 July 2023. [Google Scholar] [CrossRef]
- Kazanzides, P.; Chen, Z.; Deguet, A.; Fischer, G.S.; Taylor, R.H.; Dimaio, S.P. An Open-Source Research Kit for the da Vinci R Surgical System. In Proceedings of the IEEE International Conference on Robotics & Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 6434–6439. [Google Scholar]
- Chen, Z.; Deguet, A.; Taylor, R.H.; Kazanzides, P. Software architecture of the da vinci research kit. In Proceedings of the 2017 1st IEEE International Conference on Robotic Computing, IRC 2017, Taichung, Taiwan, 10–12 April 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 180–187. [Google Scholar] [CrossRef]
- Fontanelli, G.A.; Ficuciello, F.; Villani, L.; Siciliano, B. Modelling and identification of the da Vinci Research Kit robotic arms. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; Volume 2017, pp. 1464–1469. [Google Scholar] [CrossRef]
- Hardon, S.F.; Horeman, T.; Bonjer, H.J.; Meijerink, W.J. Force-based learning curve tracking in fundamental laparoscopic skills training. Surg. Endosc. 2018, 32, 3609–3621. [Google Scholar] [CrossRef] [PubMed]
- Rivas-Blanco, I.; Pérez-del Pulgar, C.; Mariani, A.; Tortora, G. Training dataset from the Da Vinci Research Kit. 2020. Available online: https://zenodo.org/records/3932964 (accessed on 26 February 2024).
- ROSMAG40: A Subset of ROSMA Dataset with Gesture Annotations. Available online: https://zenodo.org/records/10719748 (accessed on 26 February 2024).
- ROSMAT24: A Subset of ROSMA Dataset with Instruments Detection Annotations. Available online: https://zenodo.org/records/10719714 (accessed on 26 February 2024).
- Joshi, V.M.; Ghongade, R.B.; Joshi, A.M.; Kulkarni, R.V. Deep BiLSTM neural network model for emotion detection using cross-dataset approach. Biomed. Signal Process. Control 2022, 73, 103407. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Q.; Sun, G.; Gu, L.; Liu, Z. Object detection of surgical instruments based on Yolov4. In Proceedings of the 2021 6th IEEE International Conference on Advanced Robotics and Mechatronics, ICARM 2021, Chongqing, China, 3–5 July 2021. [Google Scholar] [CrossRef]
- Jais, I.K.M.; Ismail, A.R.; Nisa, S.Q. Adam Optimization Algorithm for Wide and Deep Neural Network. Knowl. Eng. Data Sci. 2019, 2. [Google Scholar] [CrossRef]
- Itzkovich, D.; Sharon, Y.; Jarc, A.; Refaely, Y.; Nisky, I. Using augmentation to improve the robustness to rotation of deep learning segmentation in robotic-assisted surgical data. In Proceedings of the IEEE International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; Volume 2019, pp. 5068–5075. [Google Scholar] [CrossRef]
- Zhao, Z.; Cai, T.; Chang, F.; Cheng, X. Real-time surgical instrument detection in robot-assisted surgery using a convolutional neural network cascade. Healthc. Technol. Lett. 2019, 6, 275–279. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kinematic Variable | Component | No. Features |
|---|---|---|
| Cartesian position (x, y, z) | PSM1 | 3 |
| PSM2 | 3 | |
| MTML | 3 | |
| MTMR | 3 | |
| Orientation (x, y, z, w) | PSM1 | 4 |
| PSM2 | 4 | |
| MTML | 4 | |
| MTMR | 4 | |
| Linear velocity (x, y, z) | PSM1 | 3 |
| PSM2 | 3 | |
| MTML | 3 | |
| MTMR | 3 | |
| Angular velocity (x, y, z) | PSM1 | 3 |
| PSM2 | 3 | |
| MTML | 3 | |
| MTMR | 3 | |
| Wrench force (x, y, z) | PSM1 | 3 |
| PSM2 | 3 | |
| MTML | 3 | |
| MTMR | 3 | |
| Wrench torque (x, y, z) | PSM1 | 3 |
| PSM2 | 3 | |
| MTML | 3 | |
| MTMR | 3 | |
| Joint position | PSM1 | 7 |
| PSM2 | 7 | |
| MTML | 6 | |
| MTMR | 6 | |
| Joint velocity | PSM1 | 7 |
| PSM2 | 7 | |
| MTML | 6 | |
| MTMR | 6 | |
| Joint effort | PSM1 | 7 |
| PSM2 | 7 | |
| MTML | 6 | |
| MTMR | 6 |
| Post and Sleeve | Pea on a Peg | |
|---|---|---|
| Goal | To move the colored sleeves from side-to-side of the board. | To put the beads on the 14 pegs of the board. |
| Starting position | The board is placed with the peg rows in a vertical position (from left to right: 4-2-2-4). The six sleeves are positioned over the six pegs on one of the sides of the board. | All beads are on the cup. |
| Procedure | The subject has to take a sleeve with one hand, pass it to the other hand, and place it over a peg on the opposite side of the board. If a sleeve is dropped, it is considered a penalty and it cannot be taken back. | The subject has to take the beads one by one out of the cup and place them on top of the pegs. For the trials performed with the right hand, the beads are placed on the right side of the board, and vice versa. If a bead is dropped, it is considered a penalty and it cannot be taken back. |
| Repetitions | Six trials: three from right to left, and other three from left to right. | Six trials: three placing the beads on the pegs of the right side of the board, and the other three on the left side. |
| User ID | Task | Dominant Tool | Annotated Videos |
|---|---|---|---|
| X01 | Pea on a Peg | PSM1 | 2 |
| PSM2 | 2 | ||
| Post and sleeve | PSM1 | 2 | |
| PSM2 | 2 | ||
| X02 | Pea on a Peg | PSM1 | 2 |
| PSM2 | 2 | ||
| Post and sleeve | PSM1 | 2 | |
| PSM2 | 2 | ||
| X06 | Pea on a Peg | PSM1 | 2 |
| PSM2 | 2 | ||
| Post and sleeve | PSM1 | 2 | |
| PSM2 | 2 | ||
| X07 | Pea on a Peg | PSM1 | 2 |
| PSM2 | 2 | ||
| Post and sleeve | PSM1 | 2 | |
| PSM2 | 2 | ||
| X08 | Pea on a Peg | PSM1 | 2 |
| PSM2 | 2 | ||
| Post and sleeve | PSM1 | 2 | |
| PSM2 | 2 |
| Gesture ID | Gesture Label | Gesture Description | No. Frames PSM1 | No. Frames PSM2 |
|---|---|---|---|---|
| G1 | Idle | The instrument is in a resting position | 28,395 (38.98%) | 2583 (35.46%) |
| G2 | Precision | The instrument is performing an action that requires an accurate motion of the tip. | 9062 (12.43%) | 9630 (13.1%) |
| G3 | Displacement | The instrument is moving with or without an object on the tip | 24,871 (34.14%) | 26,865 (36.42%) |
| G4 | Collaboration | Both instruments are collaborating on the same task. | 10,515 (14.53%) | 10,515 (14.53%) |
| MD Gestures | FGD Gestures | Description |
|---|---|---|
| Idle (G1) | Idle (F1) | Resting position |
| Precision (G2) | Picking (F2) | Picking an object |
| Placing (F3) | Placing an object | |
| Displacement (G3) | Free Motion (F4) | Moving without an object |
| Load Motion (F5) | Moving with an object | |
| Collaboration (G4) | Collaboration (F6) | Instrument collaborating |
| Gesture ID | Gesture Label | Gesture Description | Number of Frames PSM1 | Number of Frames PSM2 |
|---|---|---|---|---|
| F1 | Idle | The instrument is in a resting position | 28,395 (38.98%) | 25,830 (35.46%) |
| F2 | Picking | The instrument is picking an object. | 3499 (4.8%) | 4287 (5.8%) |
| F3 | Placing | The instrument is placing an object on a peg. | 5563 (7.63%) | 5343 (7.3%) |
| F4 | Free motion | The instrument is moving without carrying anything at the tool tip. | 15,813 (21.71%) | 16,019 (21.99%) |
| F5 | Load motion | The instrument moves while holding an object. | 9058 (12.43%) | 10,846 (14.43%) |
| F6 | Collaboration | Both instruments are collaborating on the same task. | 10,515 (14.53%) | 10,515 (14.53%) |
| Video | No. Frames | Video | No. Frames |
|---|---|---|---|
| X01 Pea on a Peg 01 | 1856 | X03 Pea on a Peg 01 | 1909 |
| X01 Pea on a Peg 02 | 1532 | X03 Pea on a Peg 02 | 1691 |
| X01 Pea on a Peg 03 | 1748 | X03 Pea on a Peg 03 | 1899 |
| X01 Pea on a Peg 04 | 1407 | X03 Pea on a Peg 04 | 2631 |
| X01 Pea on a Peg 05 | 1778 | X03 Pea on a Peg 05 | 1587 |
| X01 Pea on a Peg 06 | 2040 | X03 Pea on a Peg 06 | 2303 |
| X02 Pea on a Peg 01 | 2250 | X04 Pea on a Peg 01 | 2892 |
| X02 Pea on a Peg 02 | 2151 | X04 Pea on a Peg 02 | 1858 |
| X02 Pea on a Peg 03 | 1733 | X04 Pea on a Peg 03 | 2905 |
| X02 Pea on a Peg 04 | 2640 | X04 Pea on a Peg 04 | 2265 |
| X02 Pea on a Peg 05 | 1615 | X01 Post and Sleeve 01 | 1911 |
| X02 Pea on a Peg 06 | 2328 | X11 Post and Sleeve 04 | 1990 |
| Kinematic Variable | PSM | No. Features |
|---|---|---|
| Tool orientation (x, y, z, w) | PSM1 | 4 |
| PSM2 | 4 | |
| Linear velocity (x, y, z) | PSM1 | 3 |
| PSM2 | 3 | |
| Angular velocity (x, y, z) | PSM1 | 3 |
| PSM2 | 3 | |
| Wrench force (x, y, z) | PSM1 | 3 |
| PSM2 | 3 | |
| Wrench torque (x, y, z) | PSM1 | 3 |
| PSM2 | 3 | |
| Distance between tools | - | 1 |
| Angle between tools | - | 1 |
| Total number of input features | - | 34 |
| User Left Out Id | PSM1 mAP (MD) | PSM2 mAP (MD) | PSM1 mAP (FGD) | PSM2 mAP (FGD) |
|---|---|---|---|---|
| X1 | 48.9% | 39% | 46.26% | 23.36% |
| X2 | 58.8% | 64.9% | 48.16% | 51.39% |
| X3 | 50.4% | 64.2% | 39.71% | 51.24% |
| X4 | 63.0% | 61.2% | 54.05% | 49.08% |
| X5 | 54.6% | 53.6% | 52.34% | 52.7% |
| Mean | 55.14% | 56.58 | 48.01% | 45.55% |
| Supertrial Left Out | PSM1 mAP (MD) | PSM2 mAP (MD) | PSM1 mAP (FGD) | PSM2 mAP (FGD) |
|---|---|---|---|---|
| Pea on a peg | 56.15% | 56% | 46.36% | 46.67% |
| Post and sleeve | 52.2% | 51.9% | 39.06% | 43.38% |
| Dominant PSM | PSM1 mAP (MD) | PSM2 mAP (MD) | PSM1 mAP (FGD) | PSM2 mAP (FGD) |
|---|---|---|---|---|
| PSM1 | 56.53% | 67% | 24.11% | 37.33% |
| PSM2 | 65.7% | 67.5% | 52.47% | 54.68% |
| Dominant PSM | PSM1 mAP (MD) | PSM2 mAP (MD) | PSM1 mAP (FGD) | PSM2 mAP (FGD) |
|---|---|---|---|---|
| Test data 1 | 64.65% | 77.35% | 56.46% | 58.99% |
| Test data 2 | 63.8% | 62.8% | 30.43% | 70.58% |
| Test data 3 | 53.26% | 55.58% | 53.26% | 61.6% |
| Test data 4 | 48.72% | 60.62% | 58.3% | 55.58% |
| Test data 5 | 60.51% | 66.84% | 71.39% | 46.67% |
| Architecture | Test Data | PSM1 mAP | PSM2 mAP |
|---|---|---|---|
| CSPDarknet53 | Post and sleeve | 70.92% | 84.66% |
| YOLOv4-tiny | Post and sleeve | 83.64% | 73.45% |
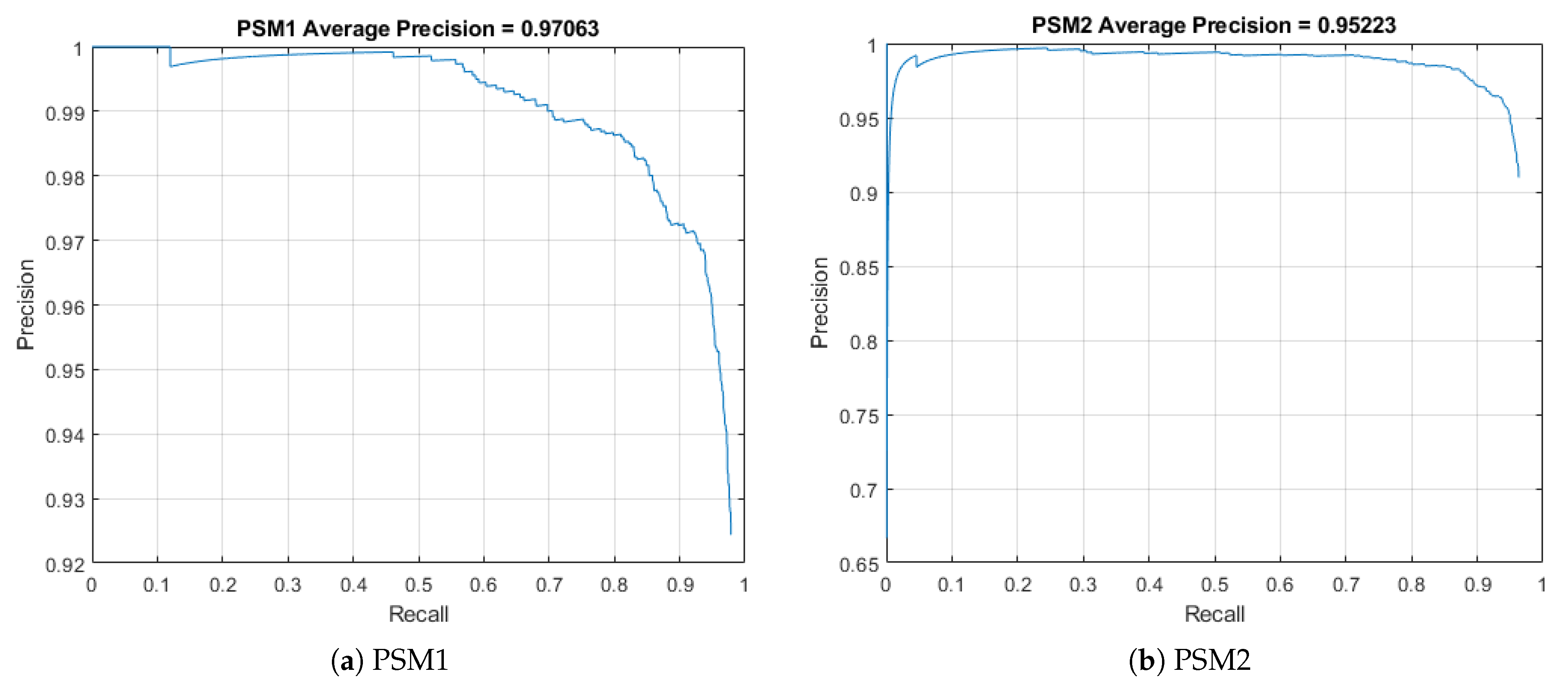
| Architecture | Left Tool mAP | Right Tool mAP | Detection Time |
|---|---|---|---|
| CSPDarknet53 | 97.06% | 95.22% | 0.0335 s (30 fps) |
| YOLOv4-tiny | 93.63% | 95.8% | 0.02 s (50 fps) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rivas-Blanco, I.; López-Casado, C.; Herrera-López, J.M.; Cabrera-Villa, J.; Pérez-del-Pulgar, C.J. Instrument Detection and Descriptive Gesture Segmentation on a Robotic Surgical Maneuvers Dataset. Appl. Sci. 2024, 14, 3701. https://doi.org/10.3390/app14093701
Rivas-Blanco I, López-Casado C, Herrera-López JM, Cabrera-Villa J, Pérez-del-Pulgar CJ. Instrument Detection and Descriptive Gesture Segmentation on a Robotic Surgical Maneuvers Dataset. Applied Sciences. 2024; 14(9):3701. https://doi.org/10.3390/app14093701
Chicago/Turabian StyleRivas-Blanco, Irene, Carmen López-Casado, Juan M. Herrera-López, José Cabrera-Villa, and Carlos J. Pérez-del-Pulgar. 2024. "Instrument Detection and Descriptive Gesture Segmentation on a Robotic Surgical Maneuvers Dataset" Applied Sciences 14, no. 9: 3701. https://doi.org/10.3390/app14093701