
A Vulnerability Scanning Method for Web Services in Embedded Firmware


Abstract
:1. Introduction
- We offer data flow tracing based on front end–back end associations, introducing a novel method of pinpointing boundary binaries and external data entry points.
- We provide rule parsing based on abstract syntax tree (AST) nodes derived from decompiled code, utilizing these AST nodes to filter hazardous functions.
- We designed coarse-grained taint propagation rules to facilitate data flow tracking from external data entry points to hazardous functions.
- We designed and implemented a prototype system, WFinder, and evaluated it using 10 real-world firmware samples. This evaluation revealed 13 unknown bugs, 8 of which were assigned CNVD numbers.
2. Related Work
2.1. Dynamic Analysis-Based Approaches
2.2. Static Analysis-Based Approaches
3. Background and Motivation
3.1. Motivating Example
3.2. Challenges and Methods
4. Design
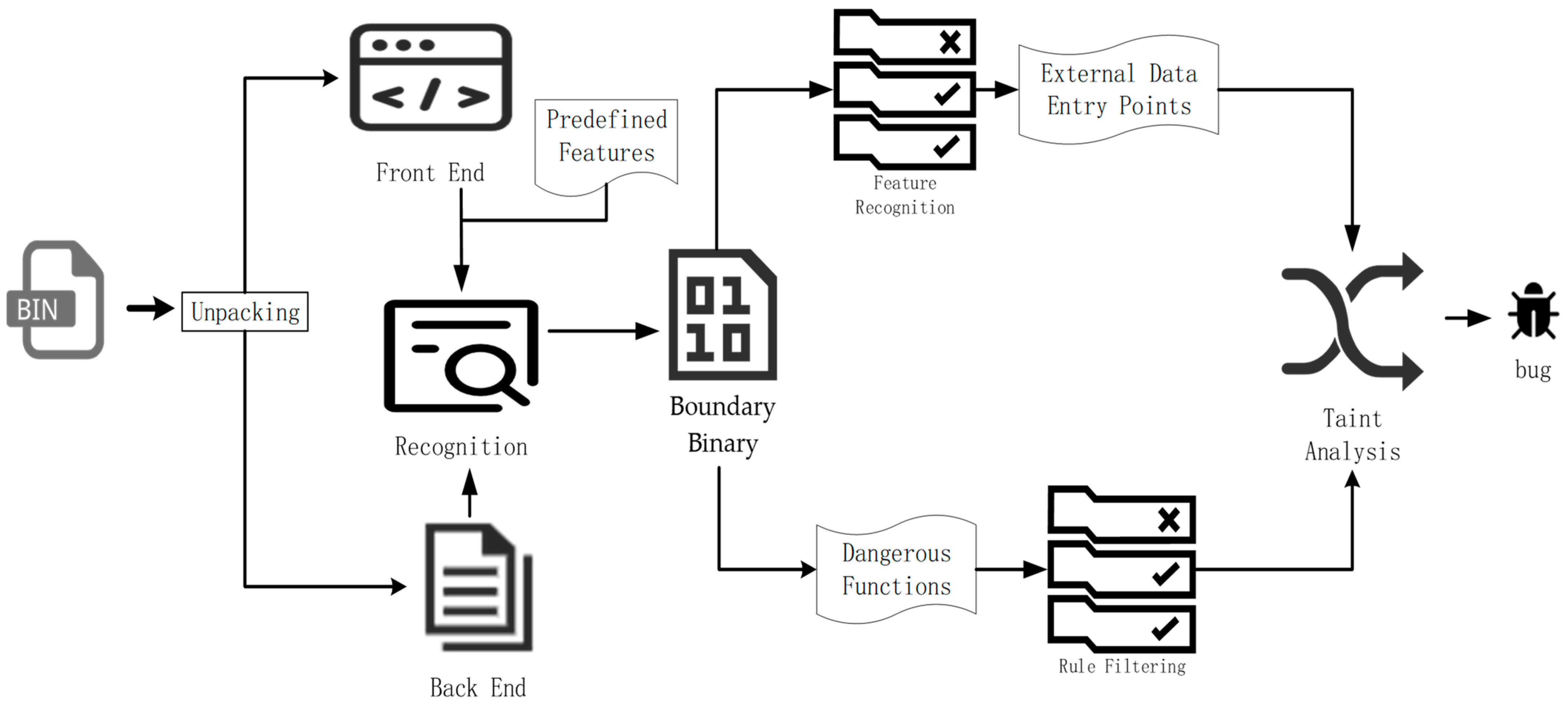
4.1. Overview
4.2. Boundary Binary Recognition
4.2.1. Keywords of Feature 1 and Feature 2
4.2.2. Keywords of Feature 3
4.3. Identification of External Data Entry Points
- High-frequency characteristics: Functions that introduce external data are invoked repeatedly throughout various sections of the program. These functions typically reference keywords shared between the front end and back end, matching corresponding data from external input sources. Due to their reference to a range of keywords, these functions experience extensive utilization within the program. Therefore, we consider functions with a higher frequency of referenced parameter keywords candidate functions.
- Functions introducing request body parameters may utilize C standard library functions such as websGetVar, getenv, and nvram_get. Initially, we examine whether the candidate functions utilize C standard library functions; if so, we classify them as functions that import external data. If standard library functions are not used, we review the names of candidate functions, prioritizing those named with keywords related to WEB input for subsequent examination, such as Web, http, get, var, and similar terms.
- Functions for importing external data typically resemble the strcmp function or obtain the address index of values corresponding to keywords from external inputs by invoking functions similar to strcmp (we collectively refer to these as strcmp-like functions). Therefore, we assess whether the candidate functions are strcmp-like, prioritizing those marked for examination. Simultaneously, we evaluate whether these functions’ parameters or return values contain pointers that store values. We identify functions characterized by strcmp-like features and with parameters or return values that retain values as functions for importing external data.
4.4. Hazardous Function Filtering
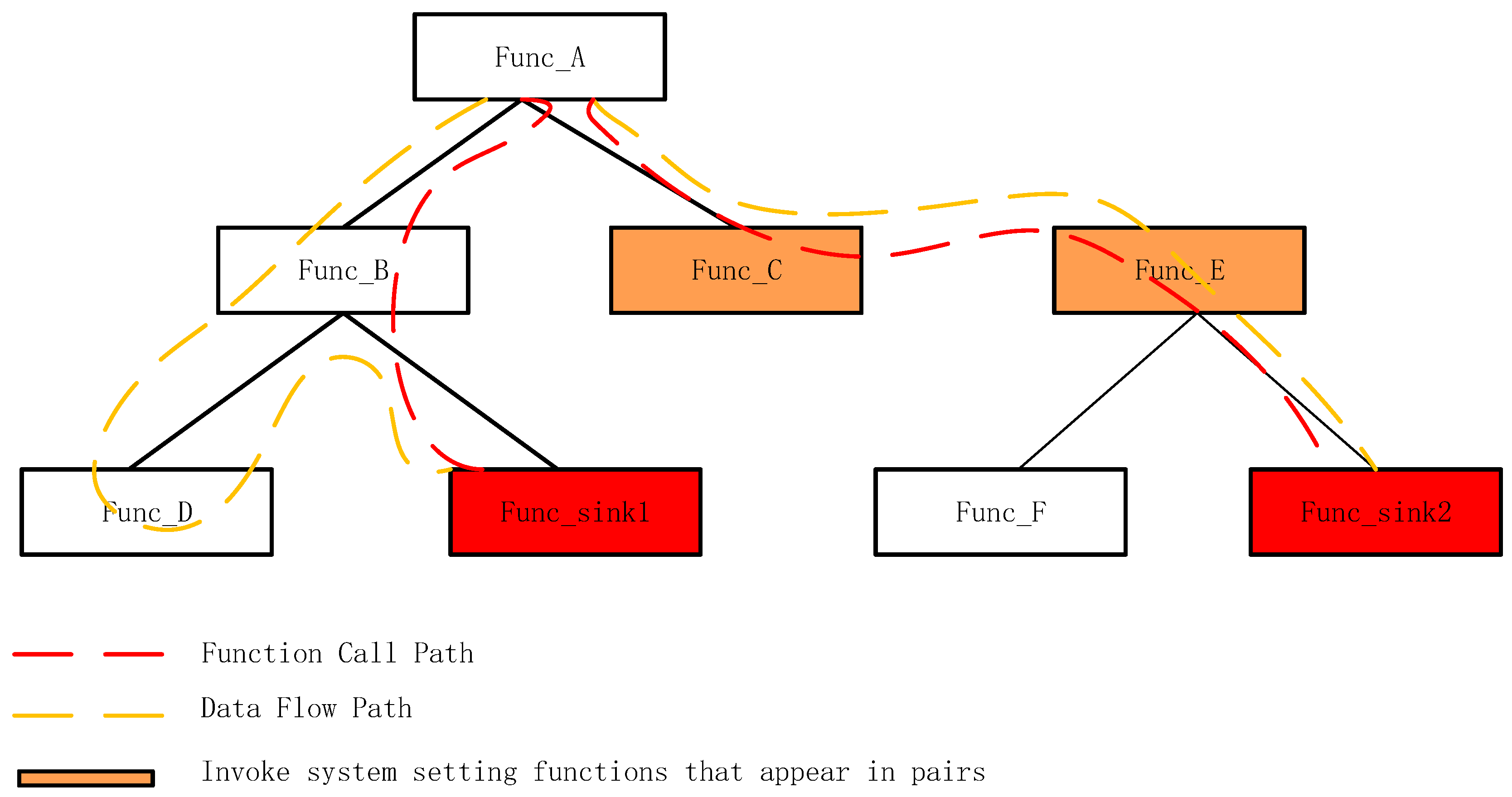
4.5. Vulnerability Path Exploration
| Algorithm 1: Taint Specifications. |
| 1. Function Taint(Ins,Taint_Map) 2. if IS_FUNCALL then 3. func ← GETFUNADDR(Ins) 4. (retv,params) ← GERPARAMS(Ins) 5. taint_set ← HAS_TAINT(params) 6. if taint_set = NULL then return 7. end if 8. if IS_CALLNOTEFUNC(func) then 9. STEPINTO(func,Taint_Map,taint_set) 10. else if IS_SINKFUNC(func) then 11. alert() 12. else then 13. if IS_POINTER(retv) && IS_USED(retv) then 14. T(retv) 15. else 16. T(params,retv) 17. end if 18. end if 19. else 20. TAINT_RULE(Ins,Taint_Map) 21. end if 22. end function |
5. Evaluation
5.1. Experiment Setup
5.2. Real-World Vulnerabilities
5.3. Inferring External Data Entry Points
5.4. Sensitive Path Reduction Analysis
5.5. Efficacy of Taint Analysis
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- GSMA. June 2020. Available online: https://www.gsma.com/ (accessed on 1 June 2020).
- Boofuzz. 2018. Available online: https://github.com/jtpereyda/boofuzz (accessed on 16 April 2018).
- Chen, J.; Diao, W.; Zhao, Q.; Zuo, C.; Lin, Z.; Wang, X.; Lau, W.C.; Sun, M.; Yang, R.; Zhang, K. IoTFuzzer: Discovering Memory Corruptions in IoT Through App-based Fuzzing. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Feng, X.; Sun, R.; Zhu, X.; Xue, M.; Wen, S.; Liu, D.; Nepal, S.; Xiang, Y. Snipuzz: Black-box fuzzing of iot firmware via message snippet inference. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 15–19 November 2021; pp. 337–350. [Google Scholar]
- Ma, X.; Zeng, Q.; Chi, H.; Luo, L. No More Companion Apps Hacking but One Dongle: Hub-Based Blackbox Fuzzing of IoT Firmware. In Proceedings of the 21st Annual International Conference on Mobile Systems, Applications and Service, Helsinki, Finland, 18–22 June 2023; pp. 205–218. [Google Scholar]
- Chen, D.D.; Woo, M.; Brumley, D.; Brumley, D. Towards automated dynamic analysis for linux-based embedded firmware. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 21–24 February 2016; Volume 1, pp. 1.1–8.1. [Google Scholar]
- Kim, M.; Kim, D.; Kim, E.; Kim, S.; Jang, Y.; Kim, Y. Firmae: Towards large-scale emulation of iot firmware for dynamic analysis. In Proceedings of the Annual Computer Security Applications Conference, Austin, TX, USA, 7–11 December 2020; pp. 733–745. [Google Scholar]
- Zheng, Y.; Davanian, A.; Yin, H.; Song, C.; Zhu, H.; Sun, L. FIRM-AFL: High-Throughput Greybox Fuzzing of IoT Firmware via Augmented Process Emulation. In Proceedings of the USENIX Security Symposium, Santa Clara, CA, USA, 14–16 August 2019; pp. 1099–1114. [Google Scholar]
- Cheng, K.; Li, Q.; Wang, L.; Chen, Q.; Zheng, Y.; Sun, L.; Liang, Z. DTaint: Detecting the taint-style vulnerability in embedded device firmware. In Proceedings of the 2018 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Luxembourg, 25–28 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 430–441. [Google Scholar]
- Zhu, L.; Fu, X.; Yao, Y.; Zhang, Y.; Wang, H. FIoT: Detecting the memory corruption in lightweight IoT device firmware. In Proceedings of the 2019 18th IEEE International Conference On Trust, Security and Privacy In Computing And Communications/13th IEEE International Conference On Big Data Science And Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 248–255. [Google Scholar]
- Redini, N.; Machiry, A.; Wang, R.; Spensky, C.; Continella, A.; Shoshitaishvili, Y.; Kruegel, C.; Vigna, G. Karonte: Detecting insecure multi-binary interactions in embedded firmware. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1544–1561. [Google Scholar]
- Chen, L.; Wang, Y.; Cai, Q.; Zhan, Y.; Hu, H.; Linghu, J.; Hou, Q.; Zhang, C.; Duan, H.; Xue, Z. Sharing more and checking less: Leveraging common input keywords to detect bugs in embedded systems. In Proceedings of the 30th USENIX Security Symposium, Virtual Event, 11–13 August 2021; pp. 303–319. [Google Scholar]
- Liu, L.; Pan, Z.; Li, Y.; Li, Z. A static localization method for firmware vulnerabilities based on front-end and back-end correlation analysis. Inf. Netw. Secur. 2022, 22, 44–54. [Google Scholar]
- Cheng, K.; Fang, D.; Qin, C.; Wang, H.; Zheng, Y.; Yu, N. Automatic inference of taint sources to discover vulnerabilities in soho router firmware. In Proceedings of the IFIP International Conference on ICT Systems Security and Privacy Protection, Oslo, Norway, 22–24 June 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 83–99. [Google Scholar]
- Wang, D.; Zhang, X.; Chen, T.; Li, J. Discovering vulnerabilities in COTS IoT devices through blackbox fuzzing web management interface. Secur. Commun. Netw. 2019, 2019, 1–19. [Google Scholar] [CrossRef]
- Kampourakis, V.; Chatzoglou, E.; Kambourakis, G.; Dolmes, A.; Zaroliagis, C. Wpaxfuzz: Sniffing out vulnerabilities in wi-fi implementations. Cryptography 2022, 6, 53. [Google Scholar] [CrossRef]
- Chatzoglou, E.; Kambourakis, G.; Kolias, C. Your wap is at risk: A vulnerability analysis on wireless access point web-based management interfaces. Secur. Commun. Netw. 2022, 2022, 1833062. [Google Scholar] [CrossRef]
- Chatzoglou, E.; Kampourakis, V.; Kambourakis, G. Bl0ck: Paralyzing 802.11 connections through Block Ack frames. arXiv 2023, arXiv:2302.05899. [Google Scholar]
- Chatzoglou, E.; Kambourakis, G.; Kolias, C. How is your Wi-Fi connection today? DoS attacks on WPA3-SAE. J. Inf. Secur. Appl. 2022, 64, 103058. [Google Scholar] [CrossRef]
- Srivastava, P.; Peng, H.; Li, J.; Okhravi, H.; Shrobe, H.; Payer, M. Firmfuzz: Automated iot firmware introspection and analysis. In Proceedings of the 2nd International ACM Workshop on Security and Privacy for the Internet-of-Things, New York, NY, USA, 15 November 2019; pp. 15–21. [Google Scholar]
- Bellard, F. QEMU, a fast and portable dynamic translator. In Proceedings of the USENIX Annual Technical Conference, FREENIX Track, Anaheim, CA, USA, 10–15 April 2005; Volume 41, p. 46. [Google Scholar]
- Chen, L.; Cai, Q.; Ma, Z.; Wang, Y.; Hu, H.; Shen, M.; Liu, Y.; Guo, S.; Duan, H.; Jiang, K.; et al. SFuzz: Slice-based Fuzzing for Real-Time Operating Systems. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 7–11 November 2022; pp. 485–498. [Google Scholar]
- Yu, B.; Wang, P.; Yue, T.; Tang, Y. Poster: Fuzzing iot firmware via multi-stage message generation. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2525–2527. [Google Scholar]
- Shoshitaishvili, Y.; Wang, R.; Salls, C.; Stephens, N.; Polino, M.; Dutcher, A.; Grosen, J.; Feng, S.; Hauser, C.; Kruegel, C.; et al. Sok: (state of) the art of war: Offensive techniques in binary analysis. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 138–157. [Google Scholar]
- Binwalk. 2015. Available online: https://github.com/ReFirmLabs/binwalk (accessed on 1 February 2024).
- Interactive Disassembler Professional. Available online: https://hex-rays.com/ida-pro/ (accessed on 1 February 2024).
- VulFi. 2021. Available online: https://github.com/Accenture/VulFi (accessed on 1 February 2024).
- Tenda. Available online: https://www.tenda.com.cn/ (accessed on 14 July 2022).
- D-Link. Available online: http://www.dlink.com.cn/ (accessed on 6 August 2015).
- Netgear. Available online: https://www.netgear.com/ (accessed on 27 May 2016).
- ToToLink. Available online: https://www.totolink.cn/ (accessed on 28 February 2023).
- Vivotek. Available online: https://www.vivotek.com/ (accessed on 24 July 2019).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HTML tags | <html>, <head>, <title>, <meta>, <link>, <style>, <script>, <body> |
| HTTP Header | Accept, Accept-Charset, Accept-Encoding, Accept-Language, Accept-Ranges, Age, Authorization, Cache-Control, Connection, Keep-Alive, Content-Encoding, Content-Language, Content-Length, Content-Range, Content-Type, Etag, Expired, Host, If-Match, If-None-Match, If-Modified-Since, If-Unmodified-Since, If-Range, Last-Modified, Location, Pramga, Proxy-Authenticate, Proxy-Authorization, Range, Referer, Server, User-Agent, Transfer-Encoding, Vary, Via |
| Vulnerability Types | Function Types | Rules |
|---|---|---|
| Buffer Overflow | Strncpy-like Functions | not param[1].is_constant() and not param[1].used_in_call_after([‘strlen’]) and (not param[2].is_constant() or param[2].is_morethan(256) ) |
| Sprintf-like Functions | any([(not param[i+1].used_in_call_before([‘strlen’]) and not param[i+1].is_constant()) for i in range(len(param[1].string_value().split(‘%’))) if param[1].string_value().split(‘%’)[i].startswith(‘s’)] | |
| Command Injection | System-like Functions | not param[0].is_constant() |
| Formatted String | Print-like Functions | not param[0].is_constant() |
| Vendor | Device Series | Architecture | SizeP | SizeUP |
|---|---|---|---|---|
| Tenda | AX1803 | ARM | 41.7 MB | 102.7 MB |
| AX1806 | ARM | 46.8 MB | 114.5 MB | |
| G1/G3 | ARM | 10.4 MB | 62.5 MB | |
| D-Link | DIR823G | MIPS | 6.2 MB | 31.8 MB |
| DIR816 | MIPS | 3.9 MB | 20.5 MB | |
| ToToLink | X2000R | MIPS | 12.5 MB | 72.9 MB |
| A3002R | MIPS | 6.9 MB | 37.5 MB | |
| Netgear | R7000 | ARM | 32.3 MB | 192.9 MB |
| R7000P | ARM | 41.7 MB | 227.2 MB | |
| vivotek | CC8160 | ARM | 36.4 MB | 51.7 MB |
| Device Series | Total | Bug IDs |
|---|---|---|
| AX1803 | 8 | CNVD-2022-89238, CNVD-2022-89237, CNVD-2022-89236, CNVD-2023-03805, CNVD-2023-03806, CNVD-2023-03807, CNVD-2023-03809, CNVD-2023-00833 |
| X2000R | 2 | unassigned |
| AX1806 | 3 | unassigned |
| Device Series | Boundary Binary | SaTC | WFinder | ||||
|---|---|---|---|---|---|---|---|
| Alert | TP | Vulnerability | Alert | TP | Vulnerability | ||
| AX1803 | tdhttpd | 64 | 42 | 16 | 45 | 31 | 29 |
| AX1806 | tdhttpd | 61 | 45 | 19 | 51 | 29 | 25 |
| G1/G3 | httpd | 53 | 31 | 14 | 59 | 29 | 17 |
| DIR823G | goahead | 64 | 43 | 21 | 70 | 39 | 23 |
| DIR816 | goahead | 78 | 39 | 25 | 64 | 37 | 27 |
| X2000R | boa | 87 | 66 | 20 | 112 | 48 | 21 |
| A3002R | boa | 33 | 15 | 0 | 20 | 8 | 1 |
| R7000 | httpd | 96 | 78 | 32 | 121 | 64 | 41 |
| R7000P | httpd | 124 | 63 | 36 | 98 | 58 | 40 |
| CC8160 | httpd | 0 | 0 | 0 | 4 | 3 | 1 |
| Total | 660 | 422 | 183 | 644 | 346 | 225 | |
| Device Series | Device Series | SaTC | Wfinder | ||
|---|---|---|---|---|---|
| BB | BB | EDIF | CSF | ||
| Tenda | AX1803 | tdhttpd | tdhttpd | sub_4F4F4 | Getvalue Setvalue |
| AX1806 | tdhttpd | tdhttpd | sub_295C8 | Getvalue Setvalue | |
| G1/G3 | httpd | httpd | websGetVar | Getvalue Setvalue | |
| D-Link | DIR823G | boa | boa goahead | sub_40DF84 sub_41EA84 | apmib_set apmib_get |
| DIR816 | goahead | goahead | websGetVar | nvram_get nvram_set nvram_bufset nvram_bufget | |
| ToToLink | X2000R | boa | boa | sub_40F1F0 | |
| A3002R | boa | boa | sub_410510 | ||
| Netgear | R7000 | httpd | httpd | sub_19644 | acosNvramConfig_set acosNvramConfig_get |
| R7000P | httpd | httpd | sub_1A760 | acosNvramConfig_set acosNvramConfig_get | |
| vivotek | CC8160 | onvifd | httpd | sub_1A760 | |
| Series | Binary | SaTC | WFinder | ||||
|---|---|---|---|---|---|---|---|
| DF | IE | SP | FDF | IE | SP | ||
| AX1803 | tdhttpd | 649 | 2847 | 1324 | 457 | 345 | 257 |
| AX1806 | tdhttpd | 612 | 2721 | 977 | 429 | 367 | 276 |
| G1/G3 | httpd | 1268 | 4304 | 63,523 | 462 | 598 | 1236 |
| DIR823G | goahead | 254 | 670 | 672 | 208 | 48 | 143 |
| DIR816 | goahead | 316 | 427 | 1782 | 217 | 395 | 1322 |
| X2000R | boa | 909 | 1067 | 4,760,783 | 552 | 822 | 253,677 |
| A3002R | boa | 913 | 1171 | 3,524,763 | 505 | 785 | 245,343 |
| R7000 | httpd | 3813 | 5509 | 170,774 | 2907 | 1774 | 3566 |
| R7000P | httpd | 3615 | 5621 | 175,822 | 2758 | 1764 | 3687 |
| Vendor | AX1803 | AX1806 | G1/G3 | DIR823G | DIR816 | X2000R | A3002R | R7000 | R7000P | |
|---|---|---|---|---|---|---|---|---|---|---|
| WFinder | TP/Alert | 0.68 | 0.56 | 0.49 | 0.55 | 0.57 | 0.43 | 0.40 | 0.53 | 0.59 |
| Vulnerability/TP | 0.93 | 0.86 | 0.58 | 0.58 | 0.72 | 0.43 | 0.13 | 0.64 | 0.69 | |
| SaTC | TP/Alert | 0.66 | 0.73 | 0.58 | 0.67 | 0.5 | 0.76 | 0.45 | 0.81 | 0.50 |
| Vulnerability/TP | 0.38 | 0.42 | 0.45 | 0.48 | 0.64 | 0.30 | - | 0.41 | 0.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, X.; Yan, C.; Wang, Y.; Wei, Q.; Wang, Y. A Vulnerability Scanning Method for Web Services in Embedded Firmware. Appl. Sci. 2024, 14, 2373. https://doi.org/10.3390/app14062373
Ma X, Yan C, Wang Y, Wei Q, Wang Y. A Vulnerability Scanning Method for Web Services in Embedded Firmware. Applied Sciences. 2024; 14(6):2373. https://doi.org/10.3390/app14062373
Chicago/Turabian StyleMa, Xiaocheng, Chenyv Yan, Yunchao Wang, Qiang Wei, and Yunfeng Wang. 2024. "A Vulnerability Scanning Method for Web Services in Embedded Firmware" Applied Sciences 14, no. 6: 2373. https://doi.org/10.3390/app14062373