In addressing the challenges of handwritten Arabic characters among children, a series of experiments were conducted and their outcomes are presented in this section. The results encompass both numerical evaluations and graphical representations. To offer a holistic understanding of the classifier’s efficacy, the performance metrics are delineated for both training and testing phases, facilitating a nuanced assessment of its capabilities across familiar and novel scenarios.
7.1. Experiment One—Pre-Trained CNN Models
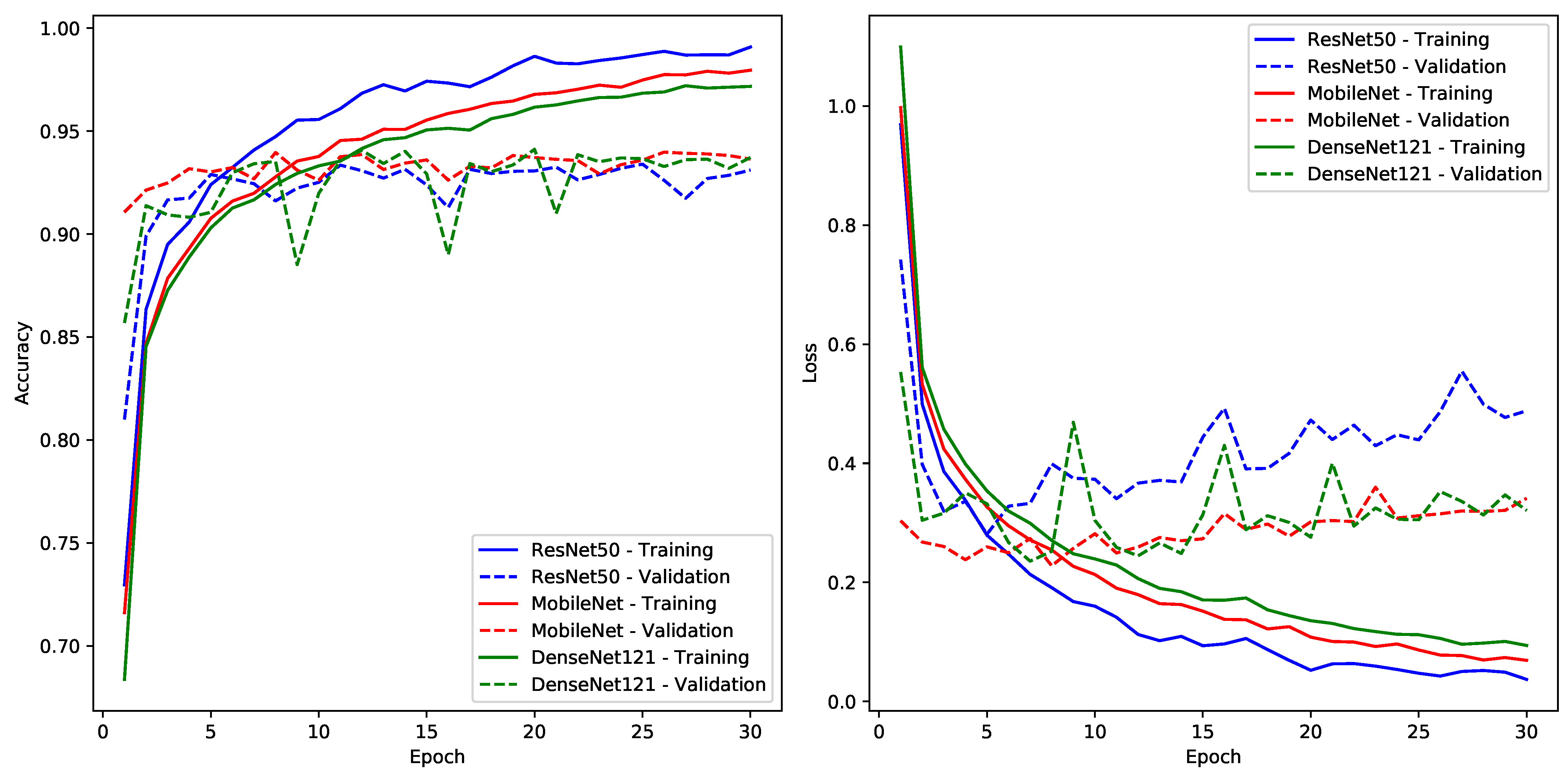
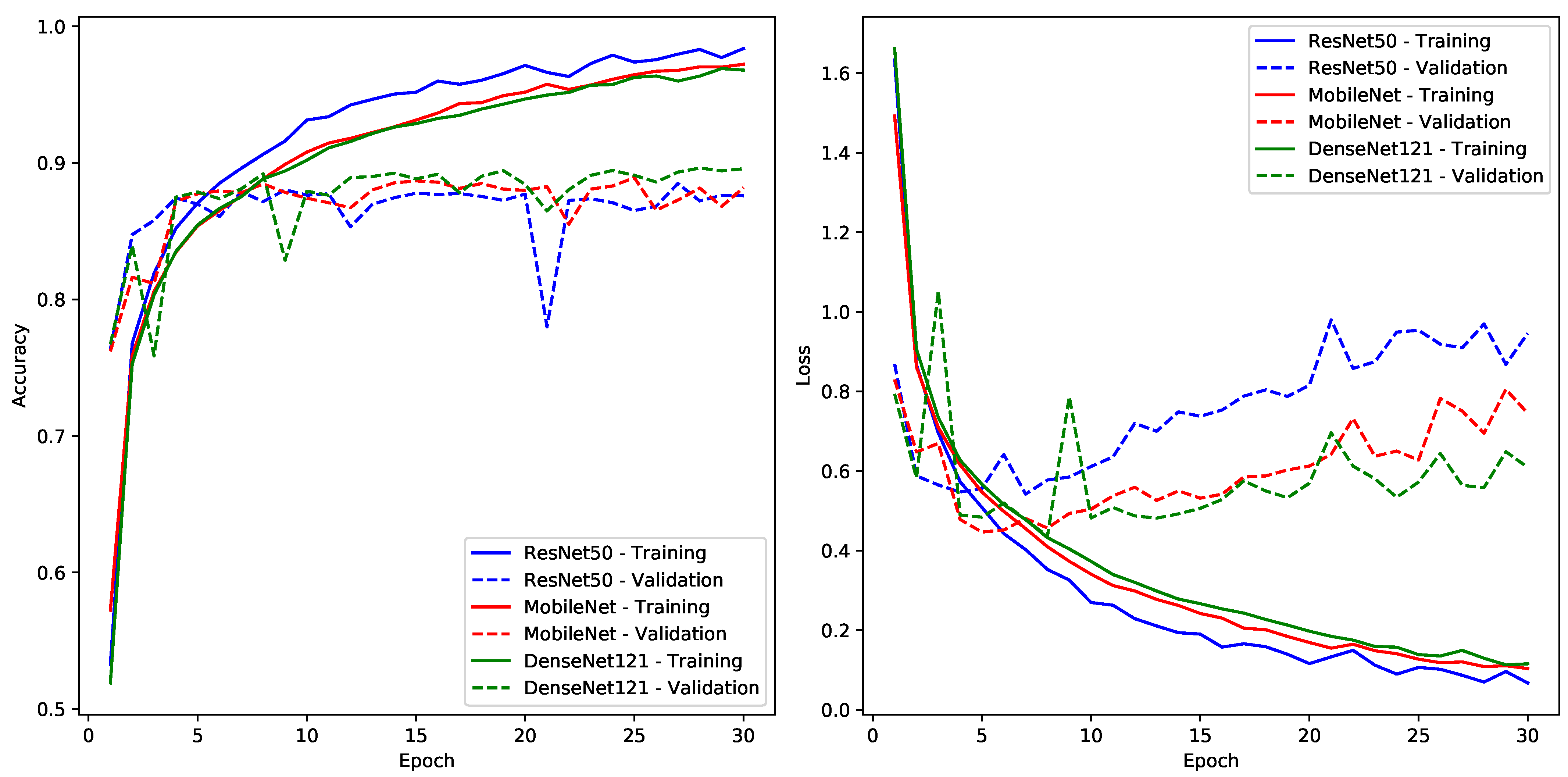
In Experiment One, where ResNet50, MobileNet, and DenseNet121 underwent fine-tuning on the Dhad and Hijja datasets, several intriguing training dynamics were observed (see
Figure 4 and
Figure 5). The training accuracy curves consistently exhibited a positive exponential trajectory, reflecting the models’ progressive refinement and learning. Concurrently, the training loss curves showcased a negative exponential pattern, suggesting a consistent reduction in training errors—both patterns emblematic of typical training behaviour. While a nuanced performance advantage was discerned in favor of ResNet50 from the training curves, this superiority was marginal. However, the validation phase painted a slightly different picture. Although the validation curves initially mirrored the training trajectories, a noticeable degradation in performance became evident after a certain epoch. This divergence, particularly conspicuous in the validation loss curves post-epoch 7, is a clear manifestation of overfitting—a phenomenon exacerbated by the datasets’ inherent simplicity. Such insights underscore the importance of leveraging validation metrics as they provide a clearer lens into the model’s generalization prowess. Intriguingly, when evaluating based on validation performance, DenseNet121 emerged marginally superior, although the performance disparities among the three models remained modest, positioning them comparably in terms of efficacy on these datasets.
A nuanced perspective on the models’ training outcomes becomes apparent in the comparative analysis derived from
Table 2. MobileNet emerged as the frontrunner for the Dhad dataset, boasting a validation loss of 0.2278 and a commendable accuracy of 0.9396. Conversely, for the Hijja dataset, DenseNet121 showcased its prowess with metrics of 0.4359 for validation loss and an accuracy score of 0.8920.
Delving deeper into the model performances, both MobileNet and DenseNet121 exhibited closely matched capabilities, with only marginal differences in their efficacy. In stark contrast, ResNet50’s performance trajectory leaned more towards pruning, hinting at potential redundancy or inefficiencies in its architecture. This behaviour can be attributed to ResNet50’s heavier design, which might have rendered it more susceptible to overfitting, especially given the datasets’ inherent simplicity. In contrast, MobileNet’s leaner architecture seemingly conferred upon it a more adaptive and resilient nature, enabling it to outperform its counterparts.
A comparative examination between the Dhad and Hijja datasets further illuminates this discussion. Predominantly, the pre-trained models showcased superior performance metrics on the Dhad dataset, underscoring its superior quality and efficacy in facilitating model training. Such observations align with the hypothesis positing Dhad’s utilization of enhanced preprocessing methodologies, likely resulting in a cleaner, noise-attenuated dataset conducive for effective model learning. This superior data quality inherently empowered the models, enabling them to achieve heightened accuracies and reduced losses on the Dhad dataset compared to its Hijja counterpart.
The testing phase (see
Table 3) further substantiated the models’ capabilities, revealing outcomes that closely mirrored their validation performance. Such consistency underscores the models’ adeptness at capturing generalized features, enabling them to maintain consistent performance across previously unseen datasets. Specifically, for the Dhad dataset, MobileNet continued to demonstrate its efficacy, registering a test accuracy of 0.9359, a test loss of 0.2468, and an impressive
score of 0.94. On the other hand, for the Hijja dataset, DenseNet121 emerged as the optimal performer, achieving a test accuracy of 0.8883, a test loss of 0.4919, and an
-score of 0.89.
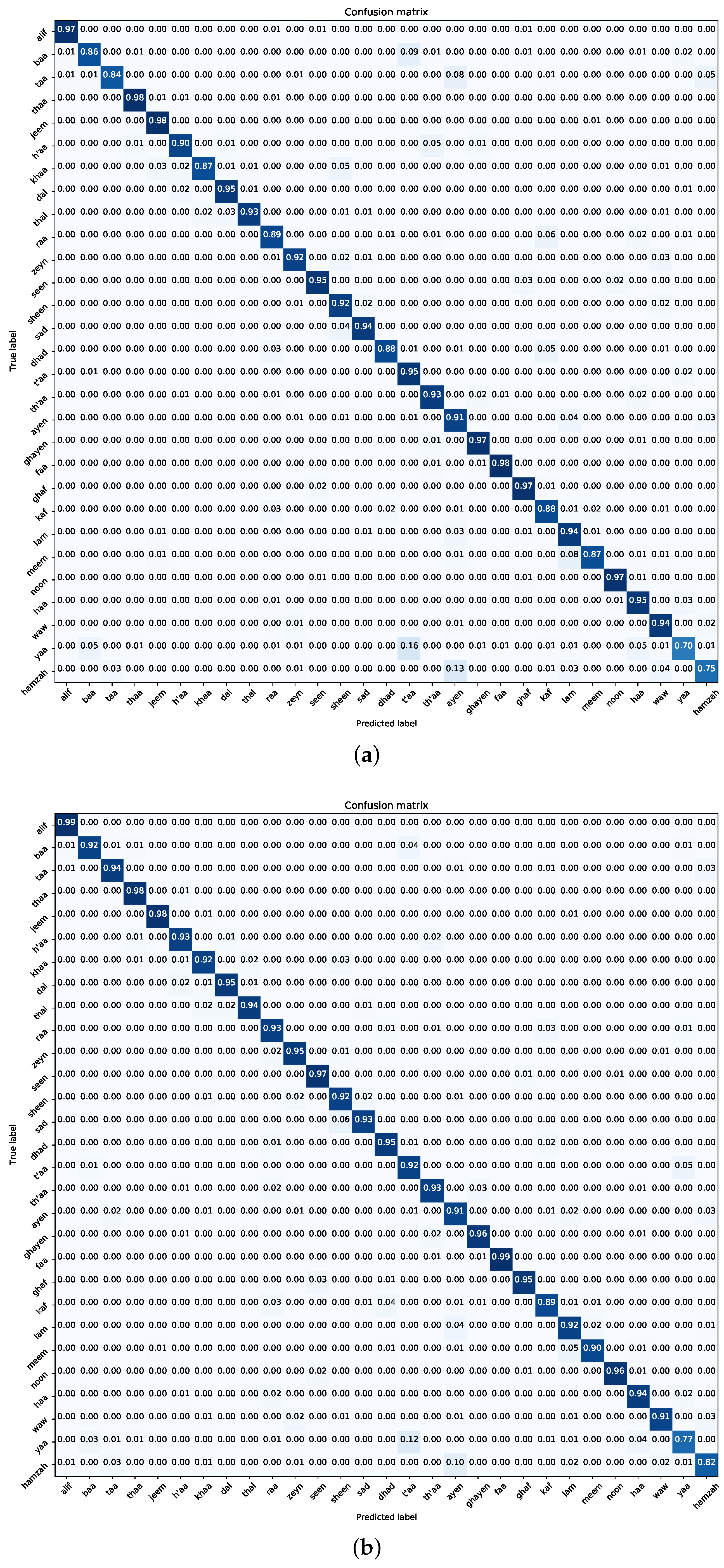
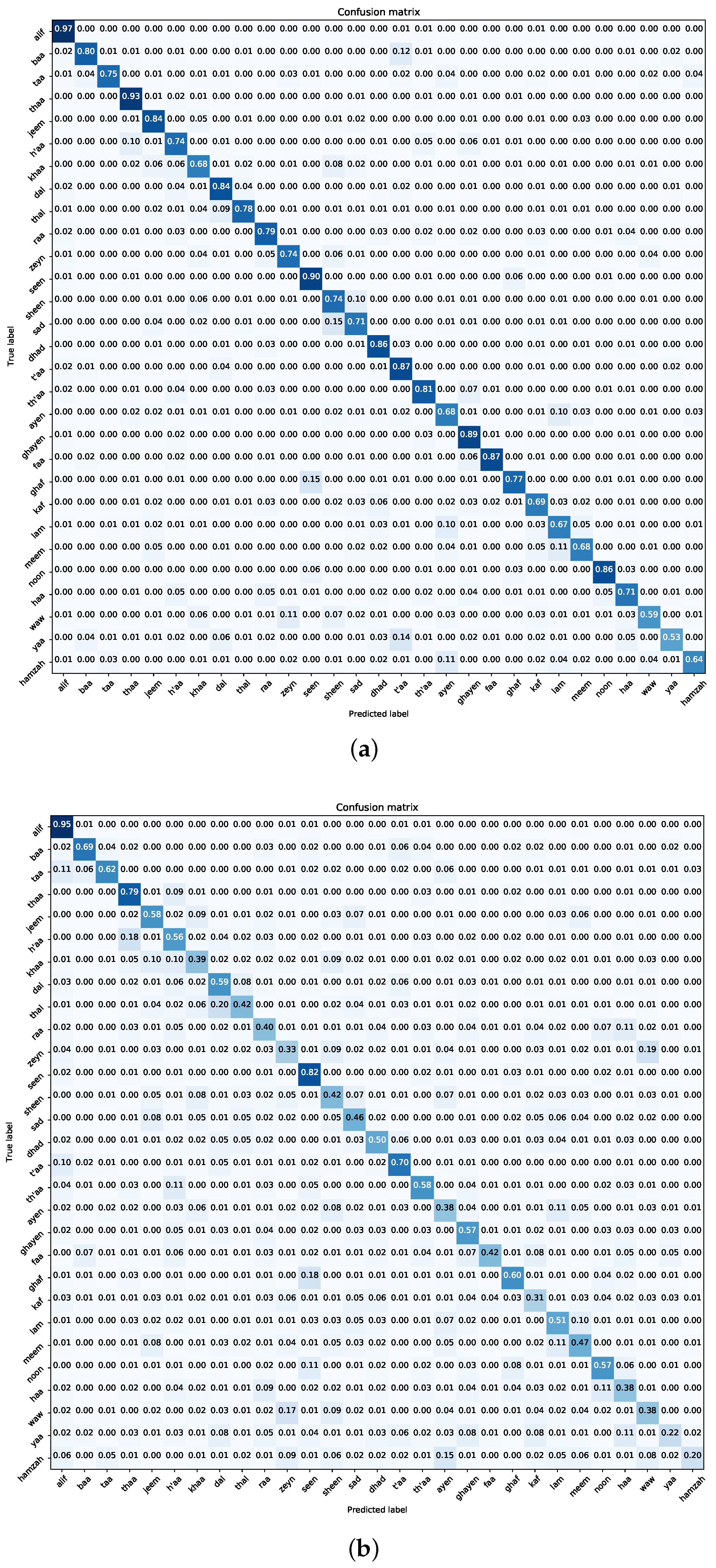
Figure 6 and
Figure 7 present the confusion matrices for the trained models on the Dhad and Hijja datasets, respectively. These matrices serve as pivotal tools for gauging the models’ class-specific performances and identifying potential areas of misclassification.
In the context of the Dhad dataset, a detailed examination reveals MobileNet’s commendable class-wise equilibrium, characterized by minimal misclassifications across various categories. Notably, there’s a discernible pattern of misclassification, where 12% of the “yaa” samples are erroneously categorized as “t’aa” and 10% of the “hamzah” samples are mislabeled as “ayen”. Such misclassifications likely stem from the intricate visual similarities inherent to these characters, underscoring the inherent challenges of handwritten character recognition tasks.
Turning our attention to the Hijja dataset, DenseNet121 emerges as the model with the most consistent overall performance. However, a deeper dive into the confusion matrix reveals a higher incidence of misclassifications. Two salient observations include the misclassification of 10% of “lam” samples as “ayen” and 7% of “hamzah” instances being inaccurately labeled as “waw”. Such misclassifications further emphasize the intricacies and challenges posed by handwritten Arabic character recognition, necessitating continuous refinement and optimization strategies for enhanced accuracy.
Figure 8 provides an insightful glimpse into the inner workings of the trained models through layer visualizations, shedding light on their training efficacy and decision-making processes. The two visualization techniques employed, Grad-CAM and SmoothGrad, serve distinct purposes in elucidating model behaviour. While Grad-CAM accentuates the pivotal regions within images that significantly influenced predictions, SmoothGrad offers a more granular perspective by pinpointing the specific pixels most instrumental in the decision-making process.
Upon meticulous examination of the visualizations, certain patterns and discrepancies come to the fore. Notably, for characters such as “faa” and “jeem”, the models appear adept at capturing and leveraging the character-relevant pixels, indicative of robust training and feature extraction capabilities. However, a discernible shortfall becomes evident in the case of the “yaa” character. Here, the model seemingly overlooks or inadequately emphasizes crucial pixels during the prediction phase, suggesting potential areas for model refinement or additional training data augmentation to enhance accuracy and consistency.
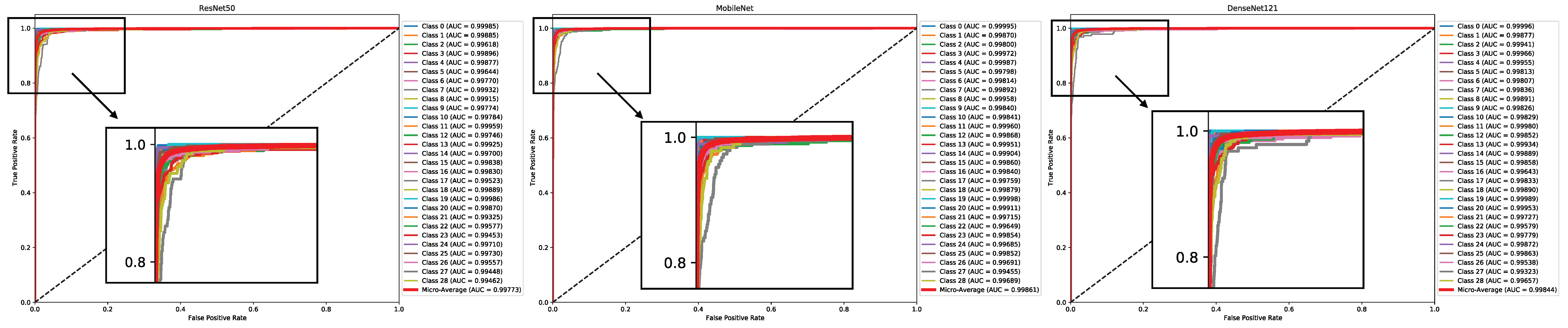
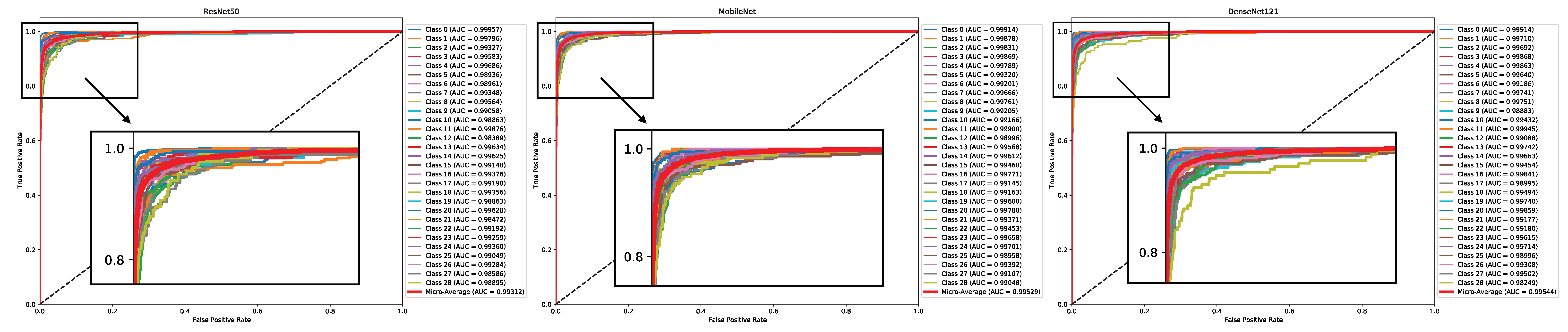
Figure 9 and
Figure 10 present the AUC curves, offering a comprehensive overview of the discriminatory power and overall performance of the pre-trained models on the Dhad and Hijja datasets, respectively. AUC serves as a robust metric, encapsulating the model’s ability to distinguish between different classes. Upon detailed examination of these curves, a pattern of closely matched performances across models emerges. Specifically, for the Dhad dataset, MobileNet slightly outperforms its counterparts, boasting an impressive AUC value of 0.9986. Conversely, on the Hijja dataset, DenseNet121 delivers a commendable performance, albeit marginally trailing behind MobileNet with an AUC of 0.9954.
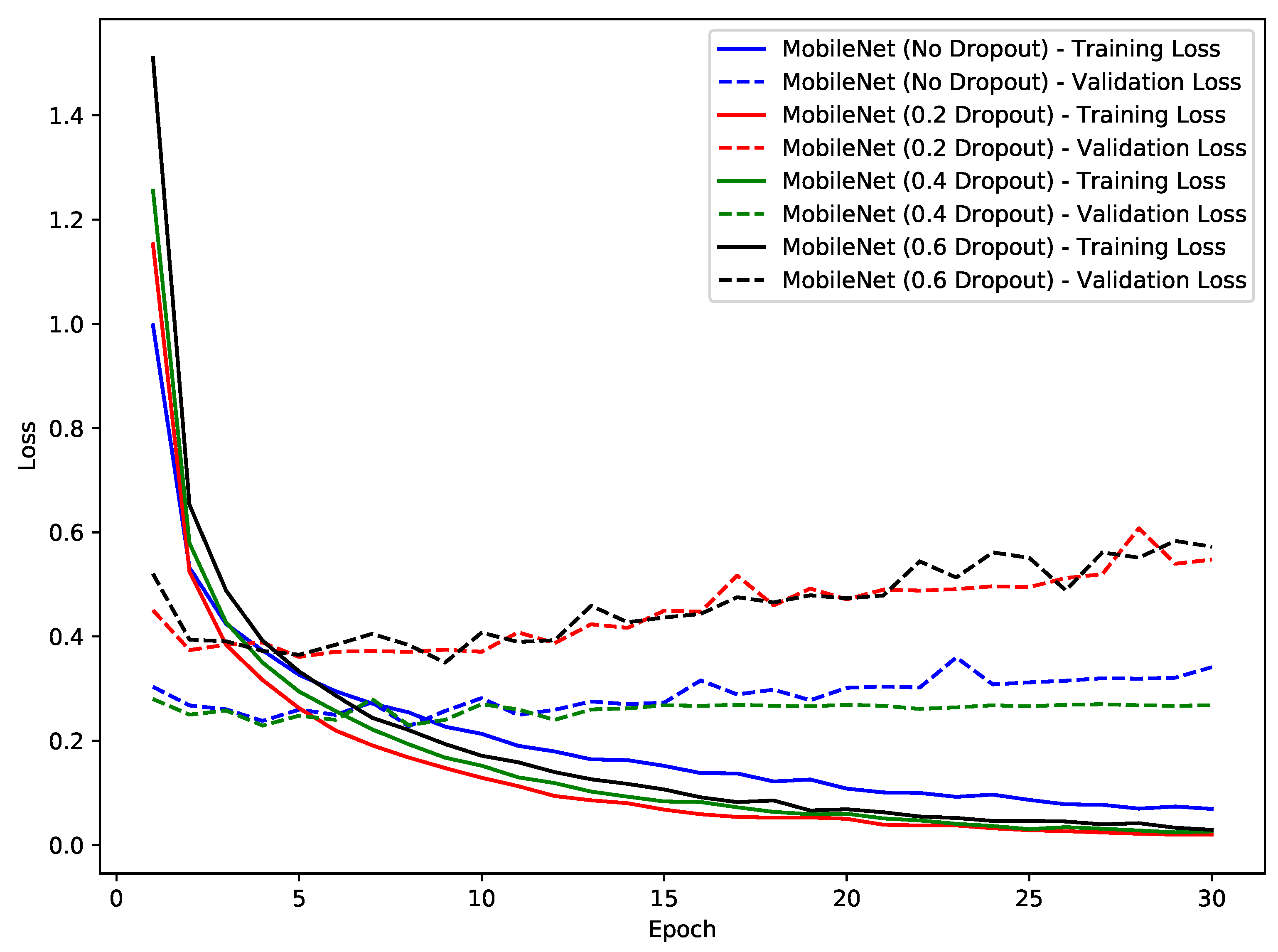
From the experiments, it can be clearly observed that the models exhibited overfitting during training for both the Dhad and Hijja datasets for almost all the implemented models. Although the superior performance of the pre-trained models was recorded, it is important to take into consideration the overfitting problem. In general, this problem usually occurs when either the dataset is too small in comparison to the model complexity or the dataset is way too simple for the model. The literature suggests that dropout and data augmentation techniques can be used to overcome the overfitting problem. To further investigate this, in this experiment, we scoped the problem for only the MobileNet model on the Dhad dataset as a use case. We have tried different dropout ratios to observe the performance. Furthermore, we have also used data augmentation with the dropout. To be specific, we trained the model using the 0.2, 0.4, and 0.6 dropout values. In terms of data augmentation, we used rotation, width shift, height shift, shear, zoom, and nearest fill.
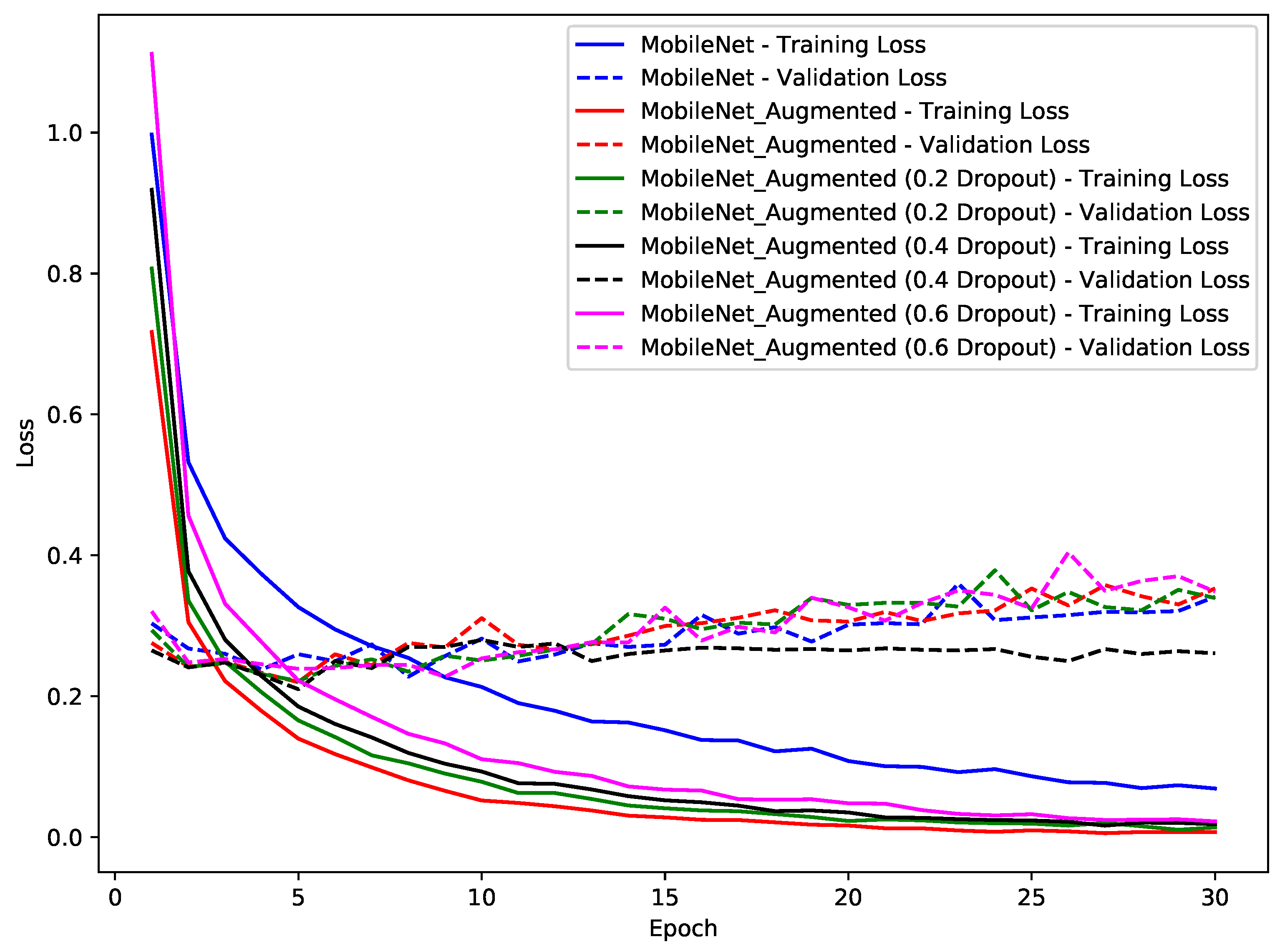
Figure 11 and
Figure 12 show the trends for training and validation loss curves for both cases to understand. First, talking about the dropout variations, it can be observed from
Figure 11 that a dropout percentage of 0.4 resulted in slightly better performance and a stable validation loss curve, whereas the dropout of 0.2 and 0.6 percentages degraded the performance. This suggests that not all the dropout percentages result in better performance; rather, an optimal value needs to be identified. It can be concluded that as suggested by the literature, dropout can be introduced to improve overfitting. In regard to the data augmentation and dropout variations, it can be observed from
Figure 12 that the introduction of data augmentation did improve the overall training performance and resulted in emergence at lower loss values, but it did not really address the overfitting problem. However, when data augmentation was used with optimal dropout values i.e., 0.4, it resulted in a stable and improved validation loss curve. As a summary of this investigation, it can be concluded that overfitting is very common for smaller and simpler datasets. Dropout and data augmentation approaches can be used to improve overfitting to some extent; however, on a larger scale, the dataset needs to be introduced with noise and challenges to avoid this problem.
7.2. Experiment Two—Custom CNN Model
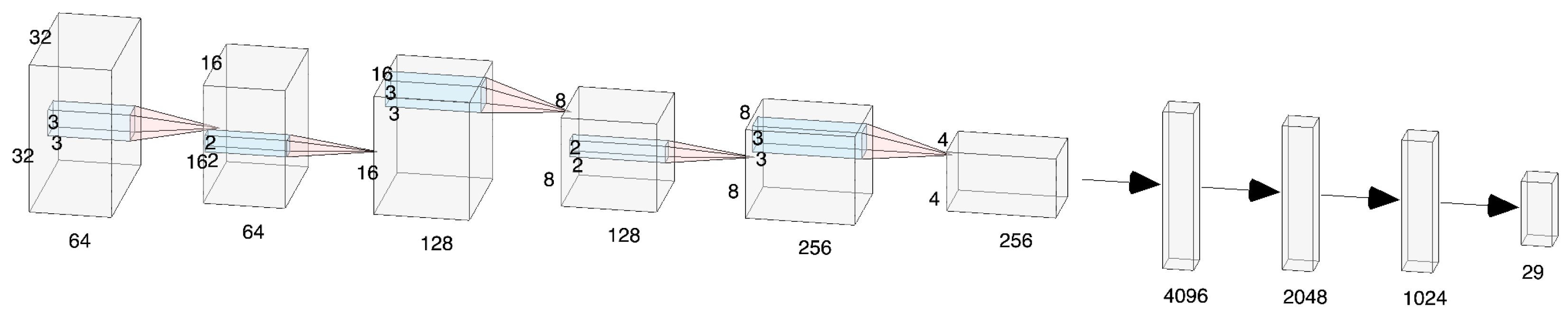
In Experiment Two, a custom CNN model, drawing inspiration from the existing literature [
4,
5,
13,
14,
15], was meticulously crafted and subsequently trained on both the Dhad and Hijja datasets. A detailed analysis of the model’s training dynamics, as depicted in
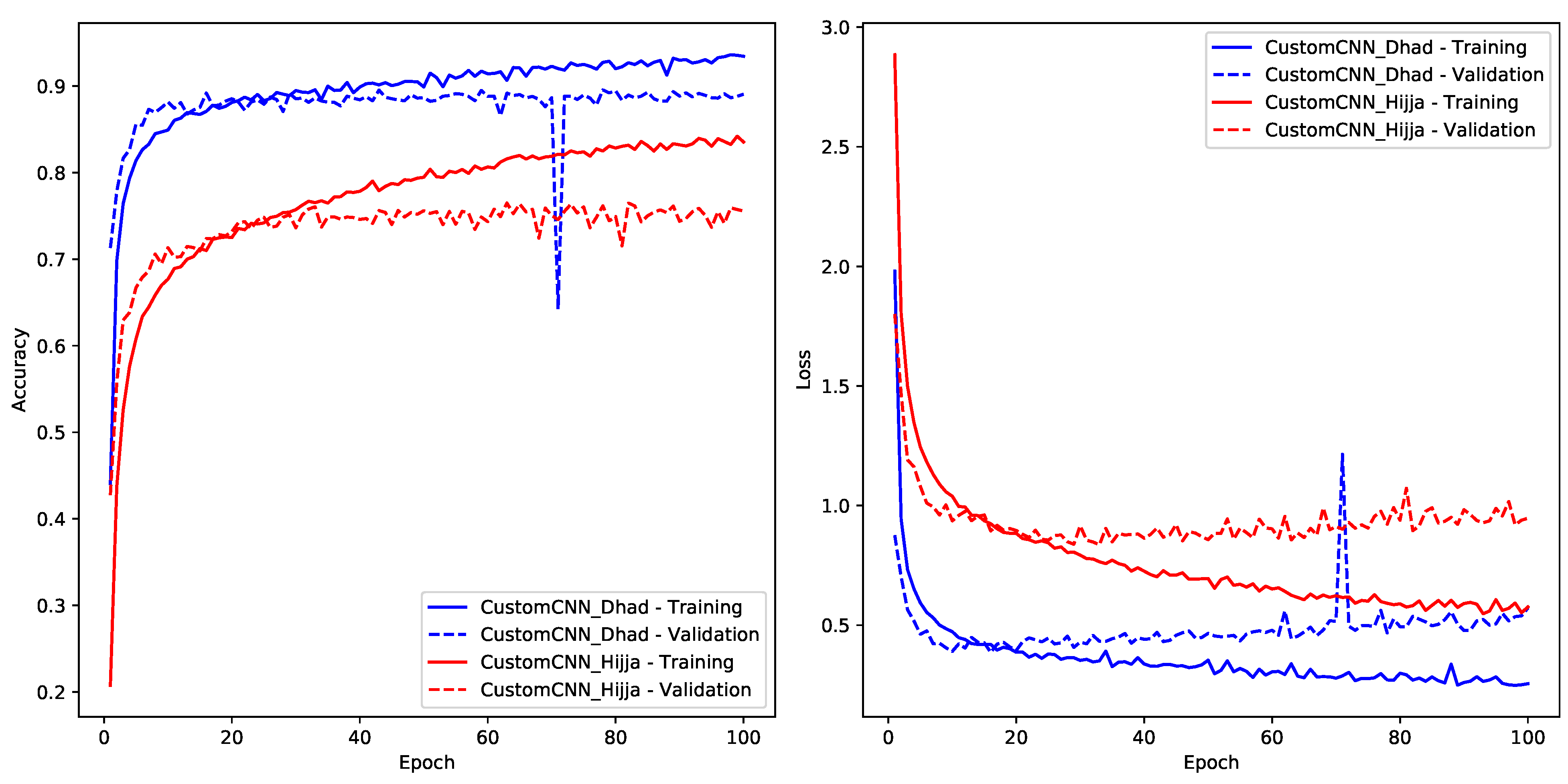
Figure 13, offers invaluable insights into its performance and adaptability.
Upon scrutinizing the training accuracy plots, a discernible positive exponential trend is evident, aligning with typical training behaviour. However, an intriguing observation is the model’s accelerated convergence, achieving desirable accuracy at a slightly quicker pace compared to other models. Nevertheless, the validation phase unraveled some concerns. While the validation accuracy initially mirrored the training trajectory, a conspicuous divergence emerged after the 20th epoch, signaling the onset of overfitting.
This overfitting propensity is further accentuated in the loss curves. After the 20th epoch, a palpable uptick in validation loss becomes evident, corroborating the overfitting suspicions. Such concerns are further compounded upon examining the convergence metrics; as detailed in
Table 4, the model’s loss values upon convergence are unexpectedly elevated for both the Dhad and Hijja datasets. Specifically, for the Dhad dataset, the model managed to attain a validation accuracy of 89% but manifested a relatively elevated validation loss of 0.3862. Conversely, the Hijja dataset witnessed a more pronounced performance disparity, with the model registering a diminished accuracy of 75% accompanied by a markedly higher validation loss of 0.8382.
Table 5 provides a comprehensive overview of the custom model’s test performance metrics on both the Dhad and Hijja datasets. A cursory examination of these results reveals a coherent alignment with the model’s validation trajectory, reaffirming the standard train–validate–test paradigm, where the performances across validation and test phases remain largely congruent.
For the Dhad dataset, the custom model demonstrated a commendable test accuracy of 88%, coupled with a test loss metric of 0.3988. Additionally, the model’s score stood impressively at 0.89, underscoring its proficiency in maintaining a harmonious balance between precision and recall. Conversely, when evaluated on the Hijja dataset, the model’s performance exhibited a discernible decline, registering a test accuracy of 74%. The associated test loss and score metrics further elucidate this observation, standing at 0.8693 and 0.75, respectively.
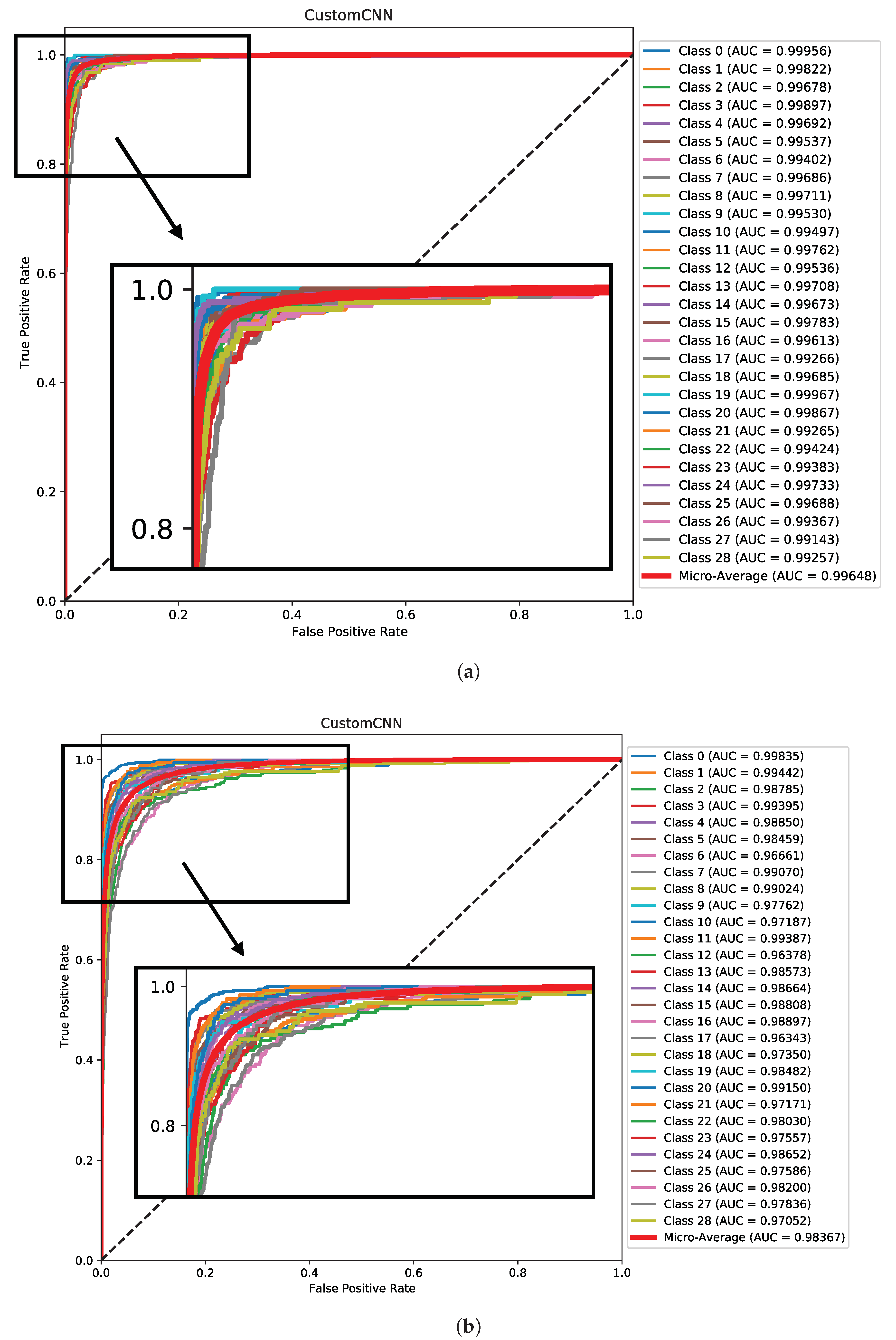
The nuanced performance trajectories across the two datasets are further corroborated by the AUC curves, meticulously depicted in
Figure 14. The Dhad dataset witnessed a marginally superior performance, with the model achieving an AUC of 0.99, indicative of its robust discriminatory prowess. In stark contrast, the Hijja dataset, although exhibiting a commendable AUC value of 0.98, revealed a more scattered performance distribution across classes, emphasizing the inherent challenges and intricacies associated with character recognition tasks on this dataset.
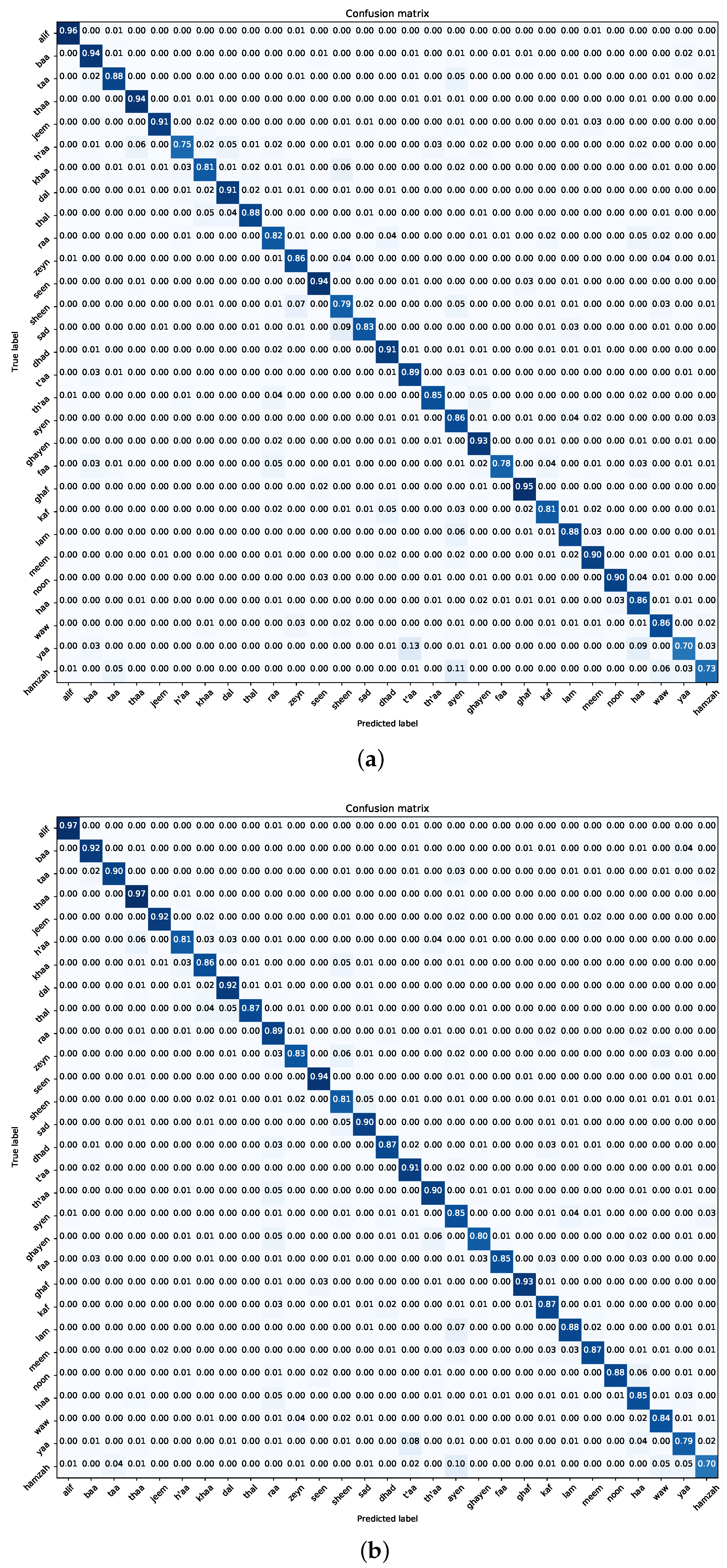
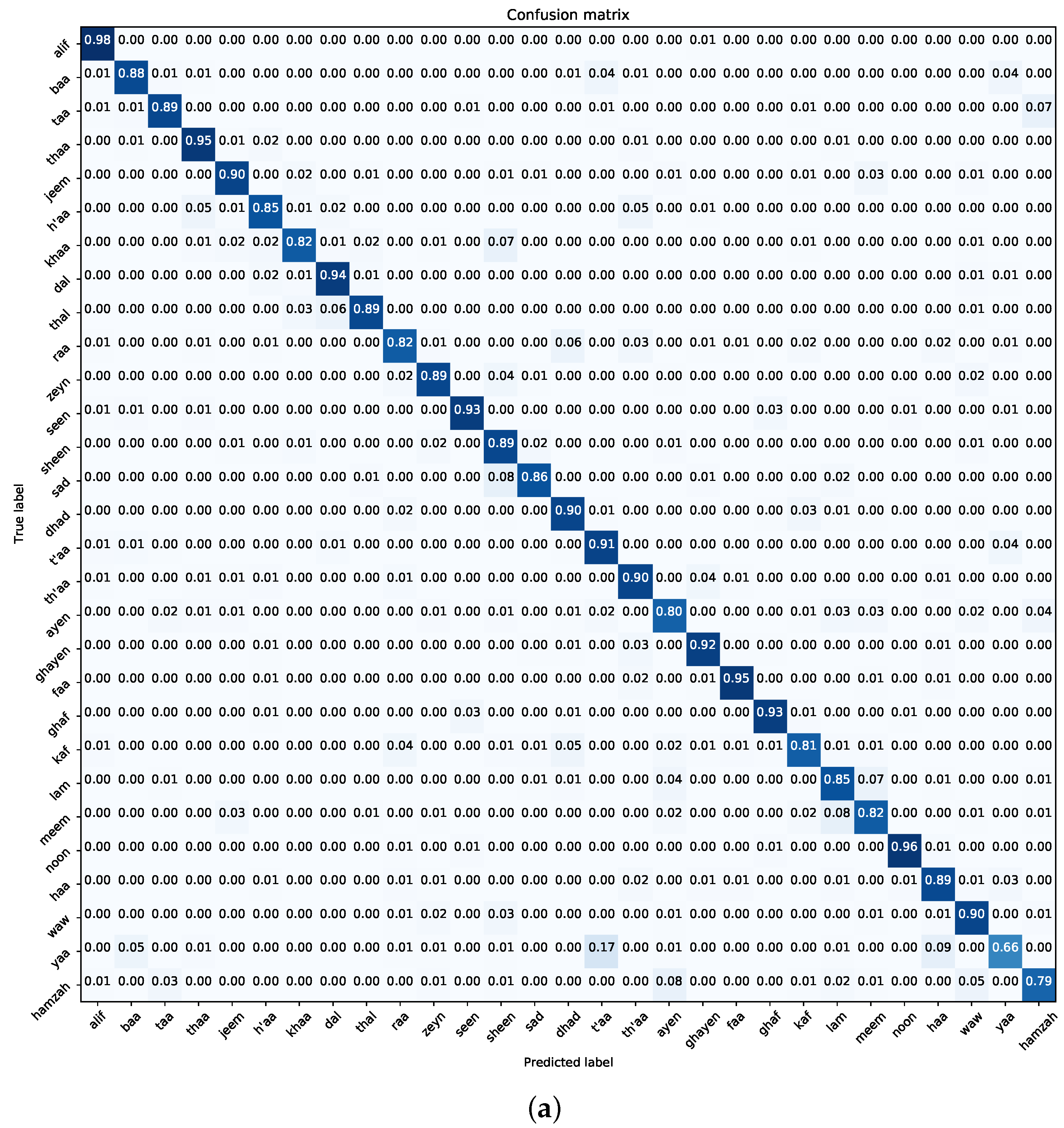
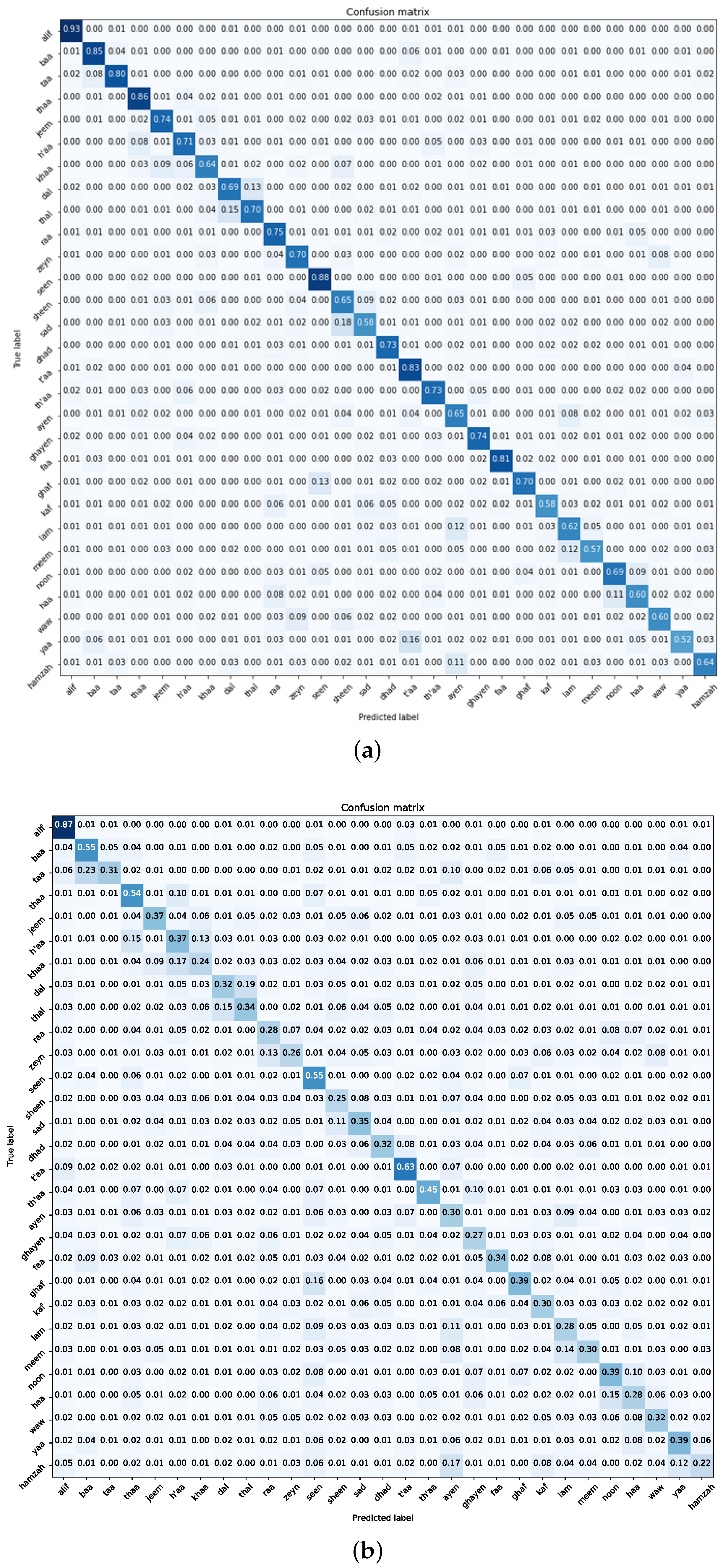
Figure 15 provides a comprehensive confusion matrix for both the Dhad and Hijja datasets. While the model’s performance on the Dhad dataset appears balanced with minimal misclassifications, a discernible decline is evident on the Hijja dataset, characterized by widespread misclassifications across various classes. Particularly challenging are the class pairs “t’aa–yaa” and “ayen–hamza”, likely due to their visual resemblance, underscoring the inherent complexities in Arabic character recognition and highlighting areas for potential model enhancement.
7.3. Experiment Three—Classification of Deep Visual Features
In Experiment Three, a sophisticated two-stage approach was devised to optimize the classification process, blending the strengths of deep learning feature extraction with the precision of traditional classifiers. The foundational component of this pipeline was the MobileNet architecture, renowned for its prowess in extracting intricate features from complex datasets. By utilizing MobileNet’s capabilities, the experiment aimed to transform the raw data into a more discernible and compact representation, thereby facilitating more effective subsequent classification. In this context, we have used the MobileNet model pre-trained over the ImageNet and MobileNet models trained in Experiment One.
Following the feature extraction phase, the extracted features were then subjected to three distinct conventional classifiers: SVM, RF, and MLP. SVM, a discriminative classifier, operates by finding the optimal hyperplane that best separates the data into distinct classes, making it particularly adept at handling high-dimensional feature spaces. Conversely, RF, an ensemble learning method, constructs multiple decision trees during training and outputs the class that is the mode of the classes of individual trees for classification tasks, thereby leveraging the wisdom of multiple trees to enhance accuracy and robustness. On the other hand, MLP is known for its fully connected neural architecture to extract the hidden patterns from the input feature vector.
Delving into the results encapsulated in
Table 6, a discernible pattern emerges. For the Dhad dataset, the MobileNet + SVM ensemble manifested as the optimal configuration, demonstrating its prowess with a validation accuracy of 89%, which was corroborated by the test accuracy standing at a commendable 88%. Further fortifying its performance credentials, the ensemble yielded an
score of 0.88, underscoring its balanced precision and recall capabilities. Similarly, when transposed to the Hijja dataset, the MobileNet+SVM configuration continued its dominance, albeit with slightly diminished metrics. A validation accuracy of 73% and a corresponding test accuracy of 72% were achieved, along with an
score of 0.73, signifying a robust performance despite the dataset’s inherent complexities. In context to the use of ImageNet pre-trained and Experiment One trained model, it can be observed that the ImageNet pre-trained model resulted in better performance.
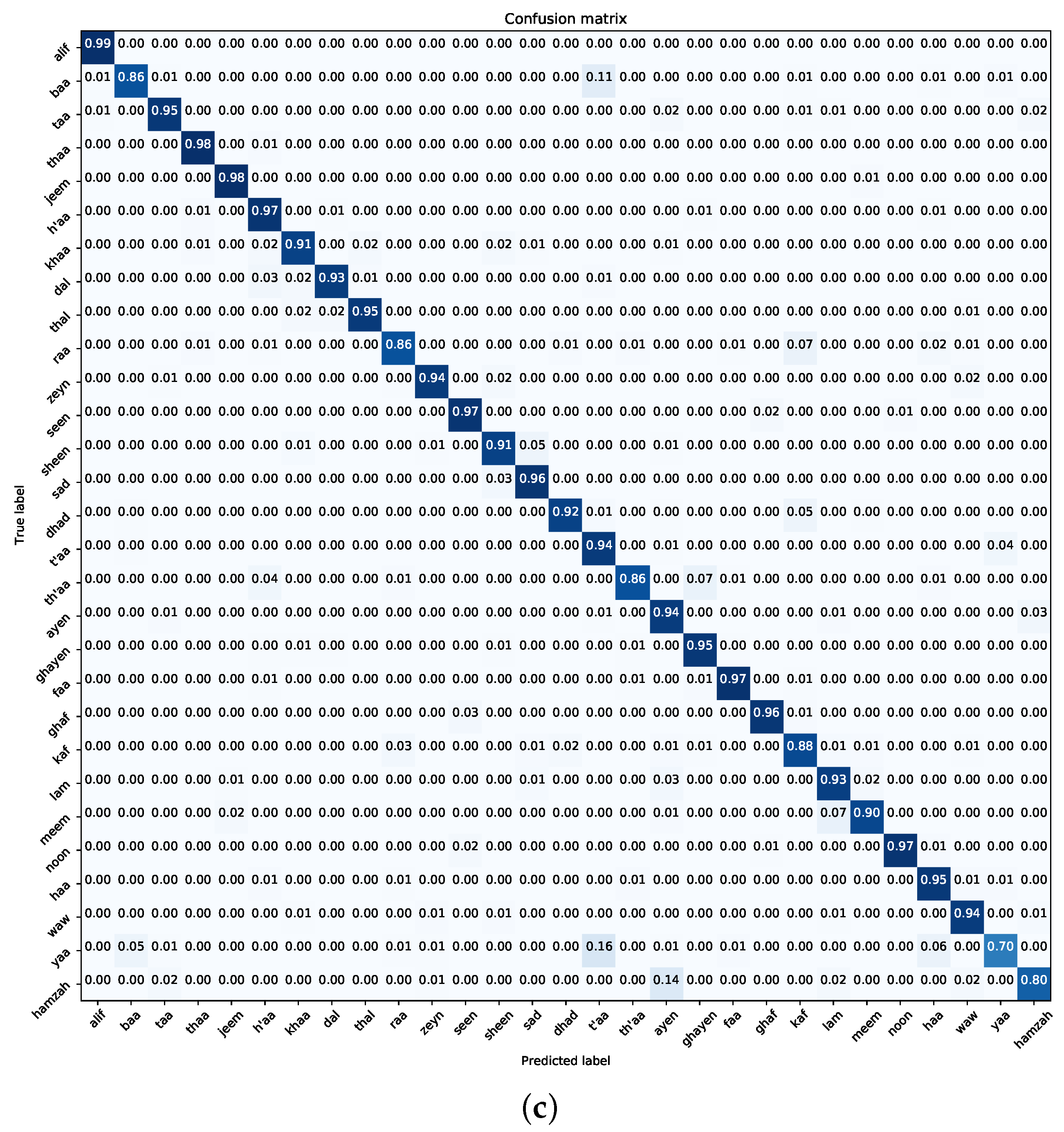
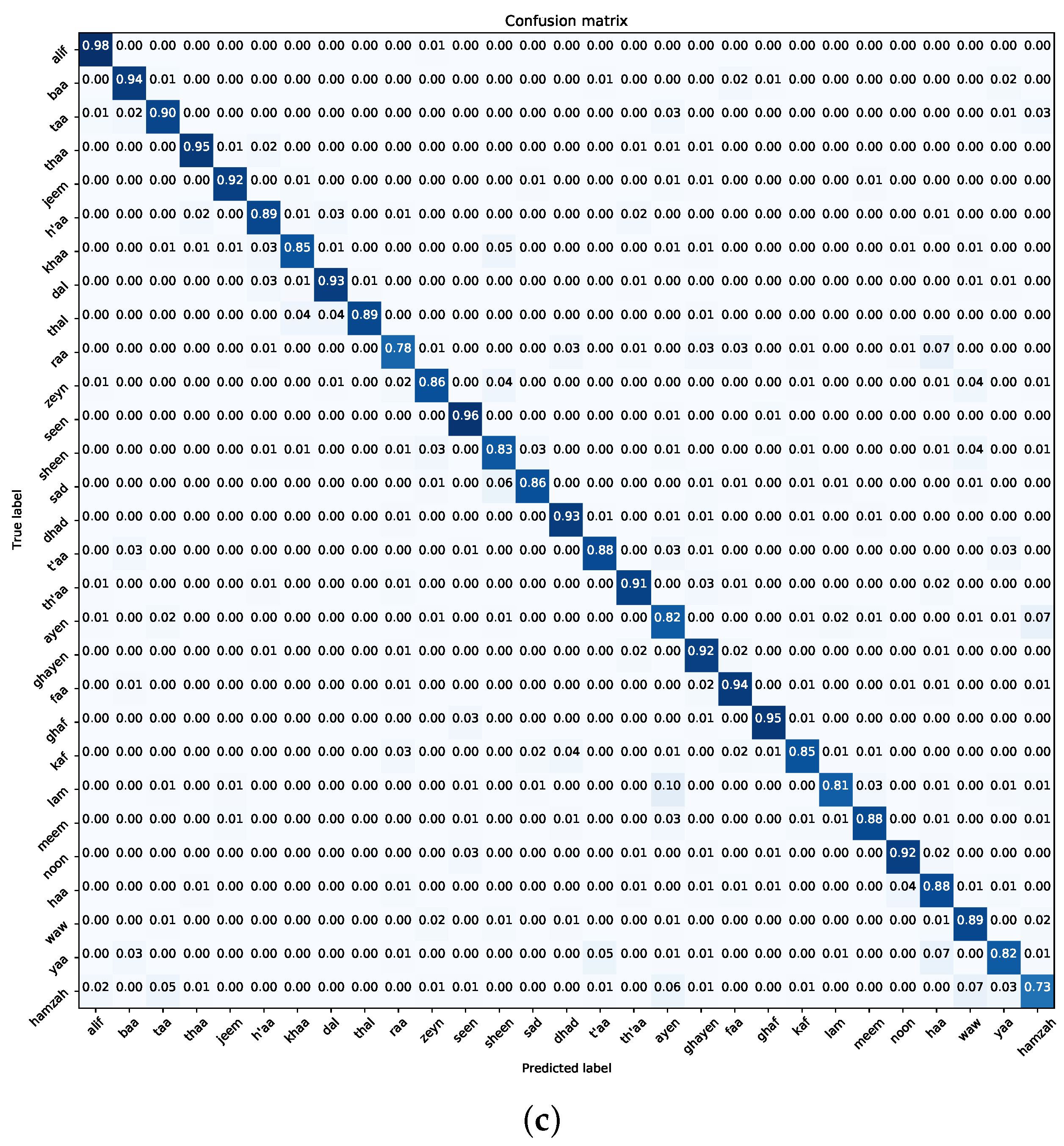
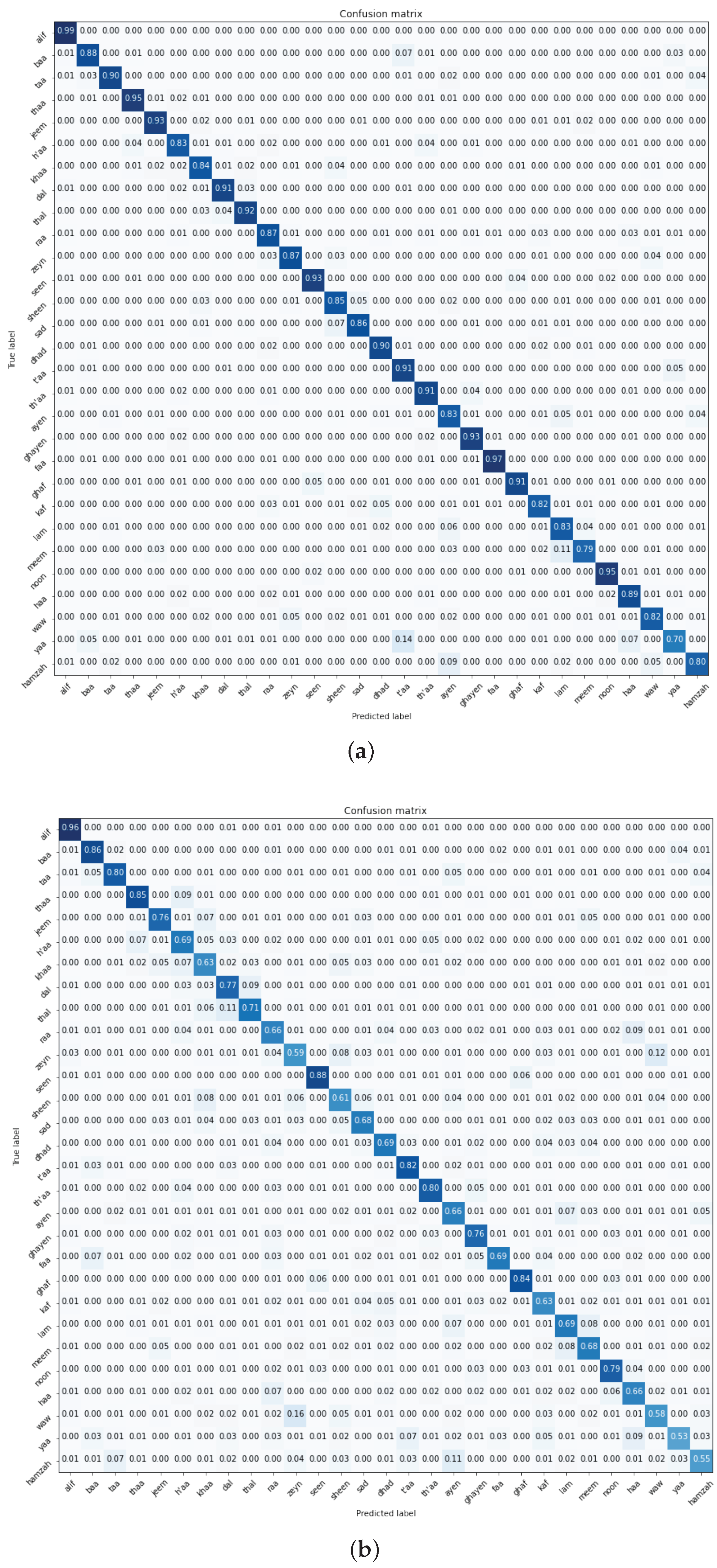
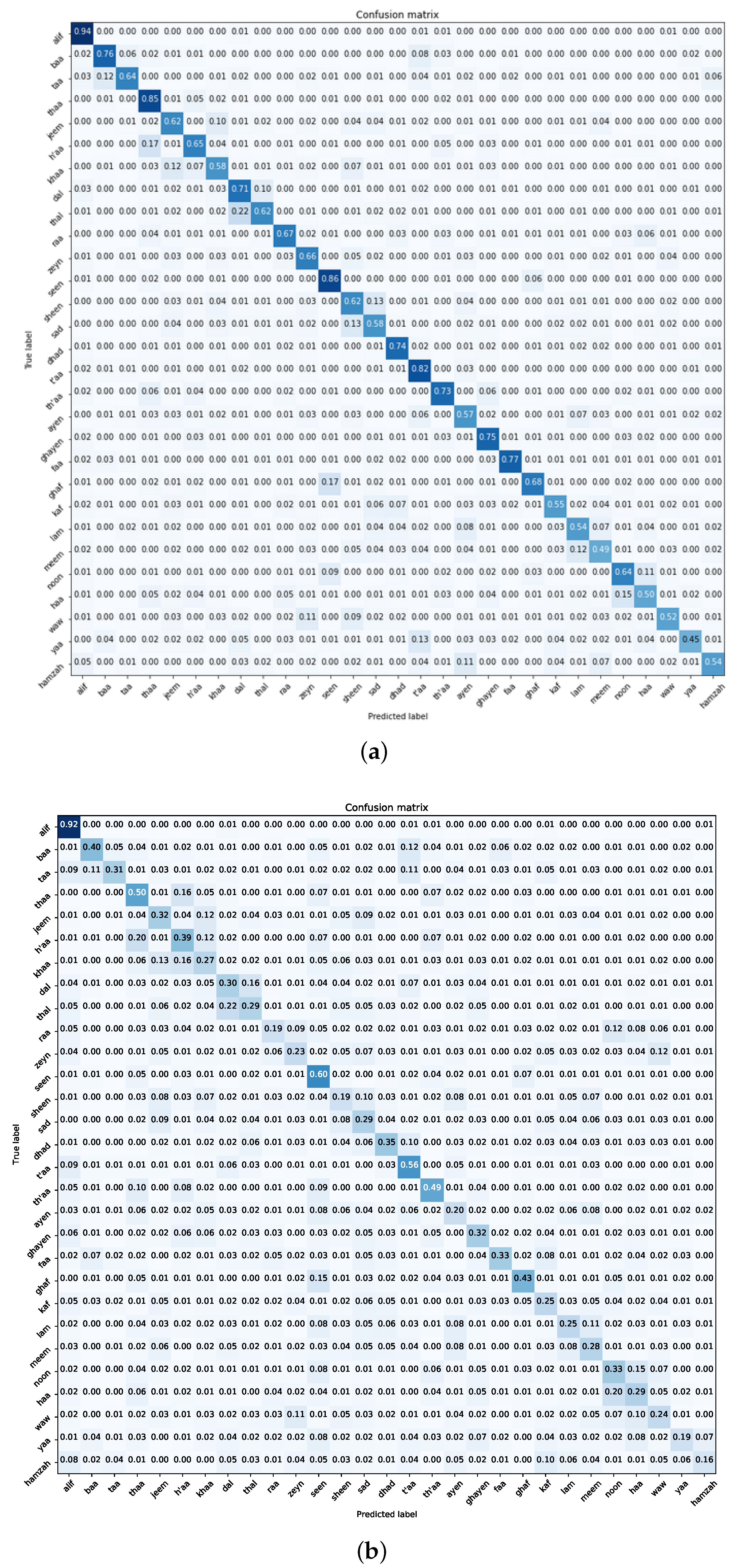
Figure 16,
Figure 17,
Figure 18,
Figure 19,
Figure 20 and
Figure 21 provide a detailed representation of the confusion matrices derived from the SVM, RF, and MLP classifiers when employed with deep visual features from the ImageNet pre-trained and Experiment One trained MobileNet model on both the Dhad and Hijja datasets. Complementing these visual representations, the findings elucidated in the table corroborate the classifiers’ performance metrics. Notably, SVM emerges as the superior performer across all the cases.
However, when contextualized within the datasets, a nuanced observation surfaces. The Dhad dataset consistently showcases enhanced performance metrics in comparison to its Hijja counterpart. This disparity in performance underscores the Dhad dataset’s superior quality, likely attributed to meticulous data curation, reduced noise levels, or other preprocessing enhancements. Such insights are pivotal, as they not only validate the efficacy of the classification pipeline but also emphasize the pivotal role of dataset quality in influencing model performance and outcomes.


 ,
, 
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}