
Application of Enhanced YOLOX for Debris Flow Detection in Remote Sensing Images
Abstract
:1. Introduction
2. Related Work
3. Data and Methodology
3.1. Data
3.1.1. Source of Data Sets
3.1.2. Production of Data Sets
3.2. Methodology
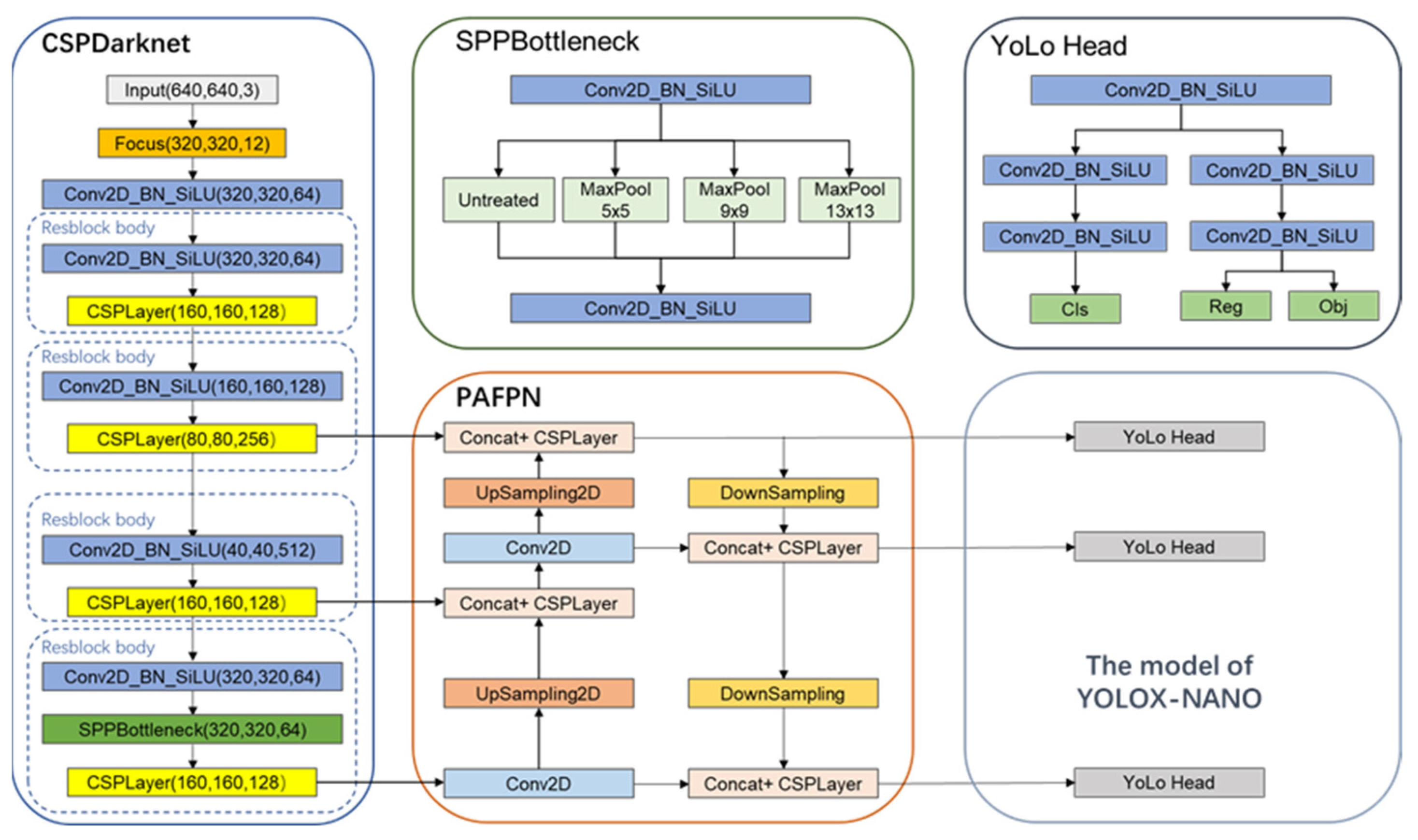
- Utilizing the meticulously prepared dataset, comparative analyses of the YOLO models in their varying sizes—nano, small, medium, large, and X-large—were conducted under identical environmental conditions. This comprehensive comparison led to the conclusion that the YOLOX-Nano model, among the variants assessed, demonstrated the most superior performance for our specific application in detecting mudslide geological disasters. Consequently, YOLOX-Nano, being a lightweight derivative of YOLOX, was chosen as the fundamental model for the accurate detection of mudslide geological disasters in expansive regions.
- Attention mechanisms were integrated into the Focus, SPP, and PAFPN modules of the YOLOX-Nano network, thereby augmenting the accuracy of mudslide target detection and increasing the network’s sensitivity to smaller targets.
- The research incorporated an advanced regression loss function, known as , in lieu of the traditional function within the base model. This modification was aimed at intensifying the regression accuracy of predictive bounding boxes for smaller targets, consequently leading to an improvement in the model’s overall detection capabilities.
- Data augmentation was accomplished using and techniques, thereby enhancing the model’s capacity for generalization.
3.2.1. Network Structure
3.2.2. Enhancing Architectures with Integrated Attention Mechanisms
3.2.3. Loss Function
3.2.4. Data Augmentation
4. Experiments
4.1. Experimental Environment
4.2. Evaluation Indicators
4.3. Experimental Results and Analysis
4.3.1. Comparative Experiment of Mainstream Lightweight Network Performance
4.3.2. Comparative Experiments between the Original and Improved Models
4.3.3. Ablation Experiment
5. Discussion
5.1. Overall Performance Analysis of RS-YOLOX-Nano
5.1.1. Introducing Combined Data Augmentation Strategies of Mosaic and Mix-Up
5.1.2. Introducing the Loss Function
5.1.3. Introducing Various Attention Mechanisms
5.1.4. Actual Detection Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cui, P.; Gao, K.C.; Wei, F.-Q. The Forecasting of Debris Flow. Bull. Chin. Acad. Sci. 2005, 363–369. [Google Scholar]
- Zhang, P. Research on the Automatic Extraction of Remote Sensing Images of Earthquake-Induced Landslides; Institute of Geology, China Earthquake Administration: Beijing, China, 2021.
- Zheng, Y.; Chen, Q.; Zhang, Y. New Advances in Deep Learning and Its Application in Object and Behavior Recognition. J. Image Graph. 2014, 19, 175–184. [Google Scholar]
- Yin, B.; Wang, W.; Wang, L. A Survey of Deep Learning Research. J. Beijing Univ. Technol. 2015, 41, 48–59. [Google Scholar]
- Zhu, R. Research on Object Detection Based on Deep Learning; Beijing Jiaotong University: Beijing, China, 2018. [Google Scholar]
- Li, X.; Ye, M.; Li, T. A Survey of Object Detection Research Based on Convolutional Neural Networks. Appl. Res. Comput. 2017, 34, 2881–2886+2891. [Google Scholar]
- Wu, T.; Dong, Y. YOLO-SE: Improved YOLOv8 for Remote Sensing Object Detection and Recognition. Appl. Sci. 2023, 13, 12977. [Google Scholar] [CrossRef]
- Ren, J.; Xiong, W.; Wu, Z.; Jiang, M. Fire Detection and Recognition Based on Improved YOLOv3. Comput. Syst. Appl. 2019, 28, 171–176. [Google Scholar]
- Liu, B.; Wang, S.; Zhao, J.; Li, M. Ship Tracking and Recognition Based on Darknet Network and YOLOv3 Algorithm. Comput. Appl. 2019, 39, 1663–1668. [Google Scholar]
- Zheng, Z.; Hu, Y.; Qiao, Y.; Hu, X.; Huang, Y. Real-time detection of winter jujubes based on improved YOLOX-nano network. Remote Sens. 2022, 14, 4833. [Google Scholar] [CrossRef]
- Cheng, G.; Ma, C.; Zhou, P.; Yao, X.; Han, J. Scene classification of high resolution remote sensing images using convolutional neural networks. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 767–770. [Google Scholar] [CrossRef]
- Wang, Z.; Goetz, J.; Brenning, A. Transfer Learning for Landslide Susceptibility Modeling Using Domain Adaptation and Case-Based Reasoning. Geosci. Model Dev. 2022, 15, 8765–8784. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 26 February 2024).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Ultralytics. YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 26 February 2024).
- Ge, Z.; Liu, S.T.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.Y.; Marklao, H.Y.; Yeh, I.-H.; Wu, Y.H.; Chen, P.-Y.; Hsieh, J.-W. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Li, W.; Zhang, Y.; Mo, J.; Li, Y.; Liu, C. Field Pedestrian and Agricultural Machinery Obstacle Detection Based on Improved YOLOv3-tiny. J. Agric. Mach. 2020, 51, 1–8. [Google Scholar]
- Ying, B.; Xu, Y.; Zhang, S.; Shi, Y.; Liu, L. Weed Detection in Images of Carrot Fields Based on Improved YOLOv4. Trait. Du Signal 2021, 38, 341–348. [Google Scholar] [CrossRef]
- Yang, S.; Liu, Y.; Wang, Z. Recognition of Cow Faces Based on an Improved YOLOv4 Model Integrating Coordinate Information. J. Agric. Eng. 2021, 37, 129–135. [Google Scholar]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision–ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part VII; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Para/MB | FPS | Precision/% | Recall/% | /% | |
|---|---|---|---|---|---|---|
| YOLOv3 | 235.0 | 36.98 | 86.00 | 73.76 | 0.79 | 79.07 |
| YOLOv4-tiny | 22.5 | 162.05 | 80.43 | 64.84 | 0.72 | 72.34 |
| YOLOv5-s | 26.98 | 77.16 | 89.06 | 56.58 | 0.69 | 81.79 |
| YOLOv7-tiny | 23.12 | 92.46 | 88.93 | 59.80 | 0.72 | 81.24 |
| YOLOv8-Nano | 11.65 | 92.16 | 87.95 | 71.36 | 0.79 | 80.58 |
| YOLOX-Nano | 3.71 | 63.48 | 88.51 | 84.12 | 0.86 | 82.51 |
| Method | Para/MB | FPS | Precision/% | Recall/% | /% | |
|---|---|---|---|---|---|---|
| YOLOX-Nano | 3.71 | 63.48 | 88.51 | 84.12 | 0.86 | 82.51 |
| RS-YOLOX-Nano | 3.83 | 62.45 | 89.61 | 85.61 | 0.88 | 86.04 |
| Focus | SPP | PAFPN | /% | |||||
|---|---|---|---|---|---|---|---|---|
| ECA | SE | CBAM | ||||||
| √ | √ | 83.52 | ||||||
| √ | √ | √ | 83.99 | |||||
| √ | √ | √ | √ | √ | 85.31 | |||
| √ | √ | √ | √ | √ | √ | 80.32 | ||
| √ | √ | √ | √ | √ | √ | 83.19 | ||
| √ | √ | √ | √ | √ | √ | 86.04 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, S.; Wu, J.; Zhang, Z.; Tong, Y. Application of Enhanced YOLOX for Debris Flow Detection in Remote Sensing Images. Appl. Sci. 2024, 14, 2158. https://doi.org/10.3390/app14052158
Ma S, Wu J, Zhang Z, Tong Y. Application of Enhanced YOLOX for Debris Flow Detection in Remote Sensing Images. Applied Sciences. 2024; 14(5):2158. https://doi.org/10.3390/app14052158
Chicago/Turabian StyleMa, Shihao, Jiao Wu, Zhijun Zhang, and Yala Tong. 2024. "Application of Enhanced YOLOX for Debris Flow Detection in Remote Sensing Images" Applied Sciences 14, no. 5: 2158. https://doi.org/10.3390/app14052158