
A Multi-View Interactive Approach for Multimodal Sarcasm Detection in Social Internet of Things with Knowledge Enhancement

Abstract
:1. Introduction
- They overlook commonsense knowledge’s role in supplementing the information of graphic and textual features. For example, subtitles and background descriptions of images can be used as visual commonsense knowledge to enhance unimodal feature representations. Intuitively, visual commonsense knowledge provides additional semantic information.
- They lack effective modal interaction approaches. The current research on multimodal interaction is overly simple and needs to view multimodal sarcasm detection tasks from multiple perspectives.
- They do nottake into account the impact of the model size on mobile devices. Especially when processing multimodal data, it is necessary to extract each modality’s features and typically requires a larger modal fusion model.
- In this paper, we employ ResNet to acquire attribute information of images as visual commonsense knowledge and leverage visual commonsense knowledge to enhance the representation of each modality.
- The proposed method enhances the multimodal information interaction. The model can learn the inter-modal differences and mutual information through different modal views and improve the model’s robustness.
- A series of experiments and analyses indicate that the presented model can effectively utilize the information of text and image to improve the performance of multimodal sarcasm detection. Concurrently, the model we constructed has fewer parameters, reducing memory pressure and computational resources.
2. Related Work
2.1. Unimodal Sarcasm Detection
2.2. Multimodal Sarcasm Detection
3. Methodology
3.1. Feature Extract Module
3.1.1. Image Feature
3.1.2. Text Feature
3.1.3. Knowledge Feature
3.2. Multi-View Interaction Module
3.3. Late Fusion Module
3.4. Classification and Loss Function
4. Experiment Setup
4.1. Dataset and Evaluated Metrics
4.2. Hyper-Parameters Setting
4.3. Compared Baselines
- TextCNN [42]: It uses the 1D Convolutional Neural Network to extract text features with few parameters.
- TextCNN-RNN [42]: We add a recurrent neural network on the basis of TextCNN to further extract text features.
- BERT [40]: The BERT-based-uncased is utilized to extract textual features and fine-tune them for downstream sarcastic tasks.
- Image [43]: It purely employs the image vectors after the pooling layer of Desnet to predict the results of sarcasm detection.
- ViT [43]: Like BERT, the vision pre-trained model ViT extracts the image representation by inserting the [CLS] token for the image sarcasm detection.
- HFN [12]: This model utilizes GloVe and ResNet as feature extractors. Then, a simple attention mechanism layer fusion is adopted to fuse text, image, and attribute modularity.
- Attr-BERT [35]: It presents a self-attention structure focusing on the intra-modal information based on BERT architecture.
- HKE [34]: It exploits atomic-level congruity and composition-level congruity detection models based on the graph neural network through cross-modality attention.
5. Experiemental Result and Analysis
5.1. Main Experiment Result and Analysis
5.2. Ablation Study
5.3. Impact of Multi-View Layers
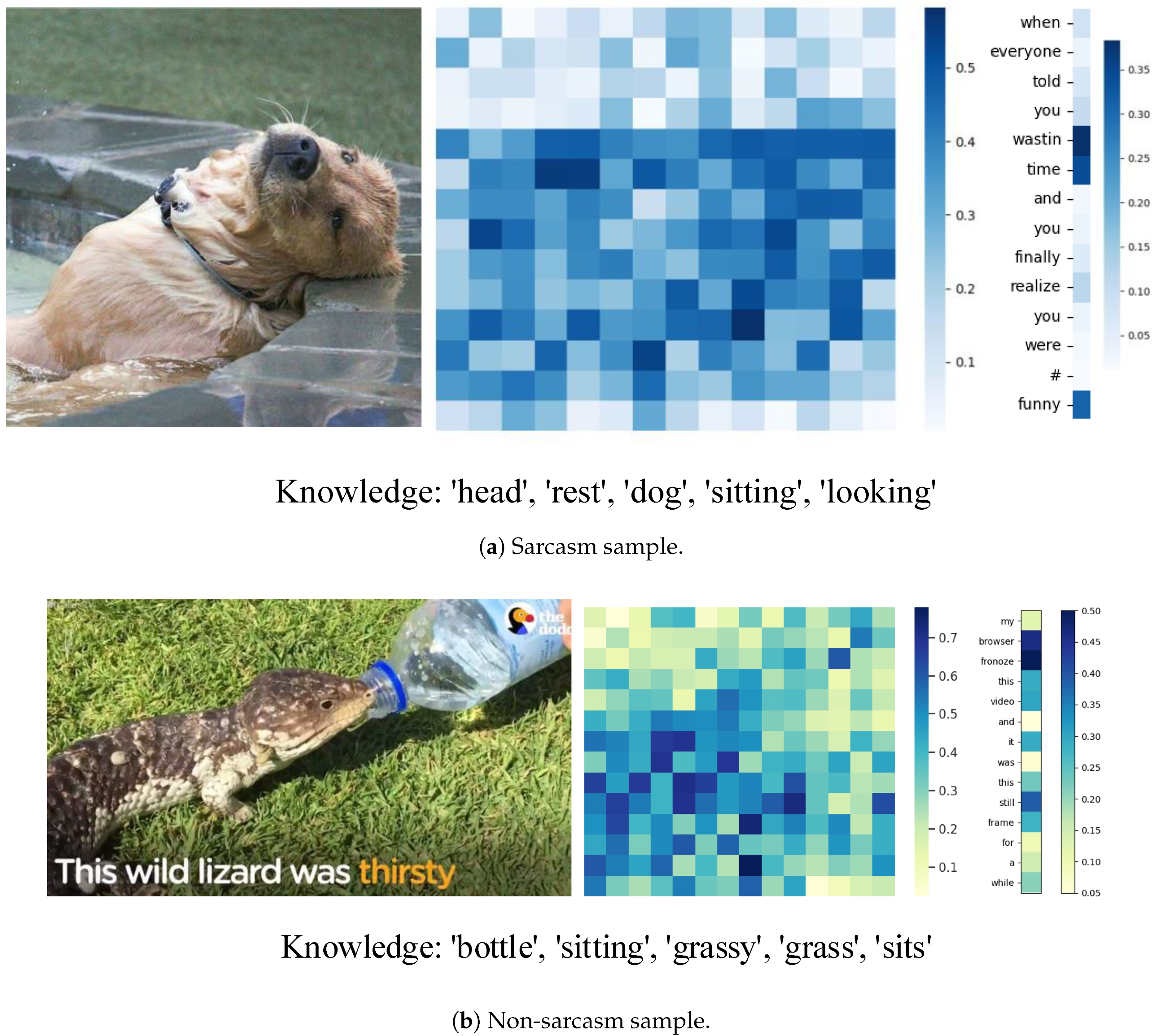
5.4. Case Study
5.5. Error Analysis and Limitation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Atzori, L.; Iera, A.; Morabito, G.; Nitti, M. The Social Internet of Things (SIoT)—When social networks meet the Internet of Things: Concept, architecture and network characterization. Comput. Netw. 2012, 56, 3594–3608. [Google Scholar] [CrossRef]
- Atzori, L.; Iera, A.; Morabito, G. SIoT: Giving a Social Structure to the Internet of Things. IEEE Commun. Lett. 2011, 15, 1193–1195. [Google Scholar] [CrossRef]
- Jena, A.K.; Sinha, A.; Agarwal, R. C-net: Contextual network for sarcasm detection. In Proceedings of the Second Workshop on Figurative Language Processing, Online, 9 July 2020; pp. 61–66. [Google Scholar]
- Ravi, K.; Ravi, V. A survey on opinion mining and sentiment analysis: Tasks, approaches and applications. Knowl.-Based Syst. 2015, 89, 14–46. [Google Scholar] [CrossRef]
- Joshi, A.; Bhattacharyya, P.; Carman, M.J. Automatic sarcasm detection: A survey. ACM Comput. Surv. (CSUR) 2017, 50, 1–22. [Google Scholar] [CrossRef]
- Jiang, D.; Liu, H.; Tu, G.; Wei, R.; Cambria, E. Self-supervised utterance order prediction for emotion recognition in conversations. Neurocomputing 2024, 577, 127370. [Google Scholar] [CrossRef]
- Tu, G.; Xie, T.; Liang, B.; Wang, H.; Xu, R. Adaptive Graph Learning for Multimodal Conversational Emotion Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024. [Google Scholar]
- Alita, D. Multiclass SVM Algorithm for Sarcasm Text in Twitter. JATISI (J. Tek. Inform. Dan Sist. Inf.) 2021, 8, 118–128. [Google Scholar] [CrossRef]
- Eke, C.I.; Norman, A.A.; Shuib, L.; Nweke, H.F. Sarcasm identification in textual data: Systematic review, research challenges and open directions. Artif. Intell. Rev. 2020, 53, 4215–4258. [Google Scholar] [CrossRef]
- Castro, S.; Hazarika, D.; Pérez-Rosas, V.; Zimmermann, R.; Mihalcea, R.; Poria, S. Towards Multimodal Sarcasm Detection (An _Obviously_ Perfect Paper). In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4619–4629. [Google Scholar]
- Schifanella, R.; De Juan, P.; Tetreault, J.; Cao, L. Detecting sarcasm in multimodal social platforms. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 1136–1145. [Google Scholar]
- Cai, Y.; Cai, H.; Wan, X. Multi-modal sarcasm detection in twitter with hierarchical fusion model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2506–2515. [Google Scholar]
- Liang, B.; Lou, C.; Li, X.; Gui, L.; Yang, M.; Xu, R. Multi-modal sarcasm detection with interactive in-modal and cross-modal graphs. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 4707–4715. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, M.; Zhang, Y.; Fu, G. Tweet sarcasm detection using deep neural network. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2449–2460. [Google Scholar]
- Tay, Y.; Luu, A.T.; Hui, S.C.; Su, J. Reasoning with Sarcasm by Reading In-Between. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1010–1020. [Google Scholar]
- Jain, T.; Agrawal, N.; Goyal, G.; Aggrawal, N. Sarcasm detection of tweets: A comparative study. In Proceedings of the 2017 Tenth International Conference on Contemporary Computing (IC3), Noida, India, 10–12 August 2017; pp. 1–6. [Google Scholar]
- Riloff, E.; Qadir, A.; Surve, P.; De Silva, L.; Gilbert, N.; Huang, R. Sarcasm as contrast between a positive sentiment and negative situation. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 704–714. [Google Scholar]
- Ghosh, D.; Guo, W.; Muresan, S. Sarcastic or not: Word embeddings to predict the literal or sarcastic meaning of words. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1003–1012. [Google Scholar]
- Poria, S.; Cambria, E.; Hazarika, D.; Vij, P. A Deeper Look into Sarcastic Tweets Using Deep Convolutional Neural Networks. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 1601–1612. [Google Scholar]
- Xiong, T.; Zhang, P.; Zhu, H.; Yang, Y. Sarcasm detection with self-matching networks and low-rank bilinear pooling. In Proceedings of the The World Wide Web Conference, Toronto, ON, Canada, 11–14 May 2019; pp. 2115–2124. [Google Scholar]
- Ilic, S.; Marrese-Taylor, E.; Balazs, J.; Matsuo, Y. Deep contextualized word representations for detecting sarcasm and irony. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Brussels, Belgium, 31 October 2018; pp. 2–7. [Google Scholar]
- Jiang, D.; Liu, H.; Wei, R.; Tu, G. CSAT-FTCN: A Fuzzy-Oriented Model with Contextual Self-attention Network for Multimodal Emotion Recognition. Cogn. Comput. 2023, 15, 1082–1091. [Google Scholar] [CrossRef]
- Jiang, D.; Wei, R.; Liu, H.; Wen, J.; Tu, G.; Zheng, L.; Cambria, E. A Multitask Learning Framework for Multimodal Sentiment Analysis. In Proceedings of the 2021 International Conference on Data Mining Workshops (ICDMW), Auckland, New Zealand, 7–10 December 2021; pp. 151–157. [Google Scholar] [CrossRef]
- Tu, G.; Wen, J.; Liu, H.; Chen, S.; Zheng, L.; Jiang, D. Exploration meets exploitation: Multitask learning for emotion recognition based on discrete and dimensional models. Knowl.-Based Syst. 2022, 235, 107598. [Google Scholar] [CrossRef]
- Li, Z.; Tu, G.; Liang, X.; Xu, R. Developing Relationships: A Heterogeneous Graph Network with Learnable Edge Representation for Emotion Identification in Conversations. In CAAI International Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2022; pp. 310–322. [Google Scholar]
- Tu, G.; Liang, B.; Jiang, D.; Xu, R. Sentiment-Emotion-and Context-guided Knowledge Selection Framework for Emotion Recognition in Conversations. IEEE Trans. Affect. Comput. 2022, 14, 1803–1816. [Google Scholar] [CrossRef]
- Chen, H.; Ding, G.; Liu, X.; Lin, Z.; Liu, J.; Han, J. Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12655–12663. [Google Scholar]
- Nam, H.; Ha, J.W.; Kim, J. Dual attention networks for multimodal reasoning and matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 299–307. [Google Scholar]
- Jiang, D.; Liu, H.; Tu, G.; Wei, R. Window transformer for dialogue document: A joint framework for causal emotion entailment. Int. J. Mach. Learn. Cybern. 2023, 14, 2697–2707. [Google Scholar] [CrossRef]
- Sarsam, S.M.; Al-Samarraie, H.; Alzahrani, A.I.; Wright, B. Sarcasm detection using machine learning algorithms in Twitter: A systematic review. Int. J. Mark. Res. 2020, 62, 578–598. [Google Scholar] [CrossRef]
- Chauhan, D.S.; Singh, G.V.; Arora, A.; Ekbal, A.; Bhattacharyya, P. An emoji-aware multitask framework for multimodal sarcasm detection. Knowl.-Based Syst. 2022, 257, 109924. [Google Scholar] [CrossRef]
- Xu, N.; Zeng, Z.; Mao, W. Reasoning with multimodal sarcastic tweets via modeling cross-modality contrast and semantic association. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3777–3786. [Google Scholar]
- Liu, H.; Wang, W.; Li, H. Towards Multi-Modal Sarcasm Detection via Hierarchical Congruity Modeling with Knowledge Enhancement. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022). Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 4995–5006. [Google Scholar]
- Pan, H.; Lin, Z.; Fu, P.; Qi, Y.; Wang, W. Modeling intra and inter-modality incongruity for multi-modal sarcasm detection. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 1383–1392. [Google Scholar]
- Wen, C.; Jia, G.; Yang, J. DIP: Dual Incongruity Perceiving Network for Sarcasm Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 2540–2550. [Google Scholar]
- Liang, B.; Lou, C.; Li, X.; Yang, M.; Gui, L.; He, Y.; Pei, W.; Xu, R. Multi-modal sarcasm detection via cross-modal graph convolutional network. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Volume 1, pp. 1767–1777. [Google Scholar]
- Fu, H.; Liu, H.; Wang, H.; Xu, L.; Lin, J.; Jiang, D. Multi-Modal Sarcasm Detection with Sentiment Word Embedding. Electronics 2024, 13, 855. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Non-Sarcasm | Sarcasm | Total | Percentage | |
|---|---|---|---|---|
| Training set | 8642 | 11,174 | 19,816 | 80.44% |
| Val set | 959 | 1451 | 2410 | 9.78% |
| Test set | 959 | 1450 | 2409 | 9.78% |
| Hyper-Parameters | Value |
|---|---|
| Batch size | 256 |
| Number of knowledge words | 5 |
| Max length of text | 75 |
| Dropout rate | 0.25 |
| Learning rate | 0.00025 |
| Number of multi-view sublayers | 2 |
| Epoch | 15 |
| BERT embedding dimension | 768 |
| Modality | Model | Acc (%) | F1-Score | Parameters | ||
|---|---|---|---|---|---|---|
| Pre (%) | Rec (%) | F1 (%) | ||||
| Text | TextCNN | 79.54 | 73.57 | 78.78 | 76.09 | 6.0 M |
| TextCNN-RNN | 82.30 | 78.86 | 78.09 | 78.48 | 6.1 M | |
| BERT | 83.85 | 78.72 | 82.27 | 80.22 | 112.8 M | |
| MVK(ours) | 83.36 | 80.09 | 79.46 | 79.78 | 19.5 M | |
| Image | Image | 64.76 | 54.41 | 70.80 | 61.53 | 14.9 M |
| ViT | 67.83 | 57.93 | 70.07 | 63.43 | 86.6 M | |
| MVK (ours) | 72.44 | 67.24 | 64.93 | 66.06 | 19. 5M | |
| Text + Image | HFN | 83.44 | 76.57 | 84.15 | 80.18 | 14.9 M |
| Attr-BERT | 86.05 | 78.63 | 83.31 | 80.90 | 36.1 M | |
| HKE | 87.02 | 82.97 | 84.90 | 83.92 | 112.5 M | |
| MVK (ours) | 86.68 | 83.75 | 84.06 | 83.92 | 19.5 M | |
| Model | Acc (%) | F1 (%) |
|---|---|---|
| MVK | 86.68 | 83.92 |
| w/o V | 85.22 | 82.15 |
| w/o L | 84.25 | 82.04 |
| w/o V-L | 81.61 | 76.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Yang, B.; Yu, Z. A Multi-View Interactive Approach for Multimodal Sarcasm Detection in Social Internet of Things with Knowledge Enhancement. Appl. Sci. 2024, 14, 2146. https://doi.org/10.3390/app14052146
Liu H, Yang B, Yu Z. A Multi-View Interactive Approach for Multimodal Sarcasm Detection in Social Internet of Things with Knowledge Enhancement. Applied Sciences. 2024; 14(5):2146. https://doi.org/10.3390/app14052146
Chicago/Turabian StyleLiu, Hao, Bo Yang, and Zhiwen Yu. 2024. "A Multi-View Interactive Approach for Multimodal Sarcasm Detection in Social Internet of Things with Knowledge Enhancement" Applied Sciences 14, no. 5: 2146. https://doi.org/10.3390/app14052146